对比学习入门
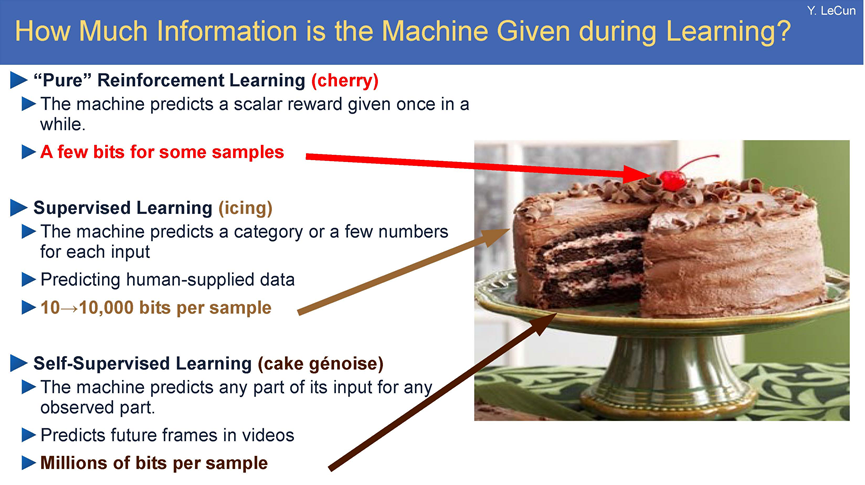 Yann Lecun在NIPS 2016上提出了著名的“蛋糕比喻”:如果智能是一个蛋糕,蛋糕上的大部分是无监督学习(unsupervised learning),蛋糕上的糖霜是监督学习(supervised learning),而蛋糕上的樱桃是强化学习(reinforcement learning)。
Yann Lecun在NIPS 2016上提出了著名的“蛋糕比喻”:如果智能是一个蛋糕,蛋糕上的大部分是无监督学习(unsupervised learning),蛋糕上的糖霜是监督学习(supervised learning),而蛋糕上的樱桃是强化学习(reinforcement learning)。
这张图用蛋糕的比喻形象地对比了三种机器学习方法在训练过程中接收的信息量差异:
-
强化学习(樱桃)
-
机器通过与环境互动获得稀疏的标量奖励信号(比如游戏得分或机器人动作的反馈)。
-
信息量极低,每个样本仅几比特,因为反馈频率低且内容简单(如“对/错”或分数)。
-
-
监督学习(糖霜)
-
机器根据人工标注的数据(如图像分类标签、翻译文本)进行学习。
-
信息量中等,每样本10~10,000比特,取决于标注复杂度(如分类标签比像素预测的信息少)。
-
-
自监督学习(蛋糕胚)
-
机器通过数据自身的结构学习,例如预测视频的下一帧、补全文本或图像的缺失部分。
-
信息量极高,每样本数百万比特,因为模型需要理解原始数据的完整分布(如像素、时间序列等)。
-
核心结论:
-
自监督学习能利用海量未标注数据(如互联网文本、视频),信息密度远超依赖人工标注的监督学习或稀疏反馈的强化学习。
-
这解释了为何自监督学习(如GPT、BERT)在大模型时代成为主流——它更接近人类通过观察世界自主学习的方式。
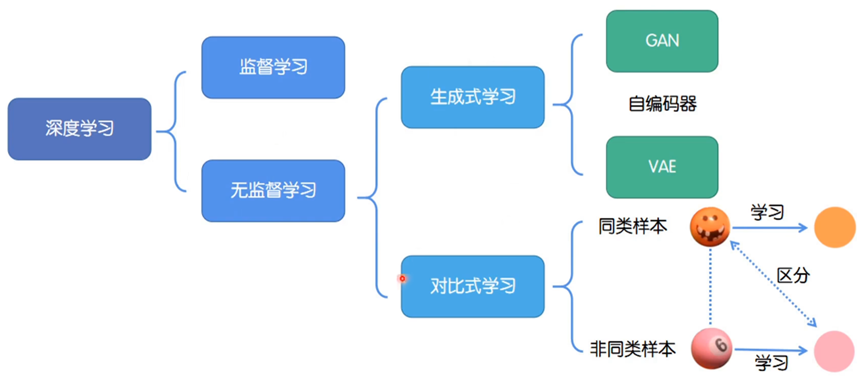
- 深度学习分类:深度学习分为监督学习和无监督学习。
- 监督学习:是利用标注数据进行模型训练的方式,通过输入数据和对应的标签来学习映射关系,以实现预测等任务 。
- 无监督学习:使用未标注数据进行学习,旨在发现数据中的内在结构、模式和规律。该部分又细分为生成式学习和对比式学习:
- 生成式学习:目标是学习数据的分布,从而能够生成类似的新数据。常见方法有生成对抗网络(GAN)、自编码器、变分自编码器(VAE) 。
- 对比式学习:核心是学习同类样本的相似性和非同类样本的差异性,通过对比不同样本,让模型更好地捕捉样本特征,提升表征能力 。
这两个图都可以看出对比学习的重要性。
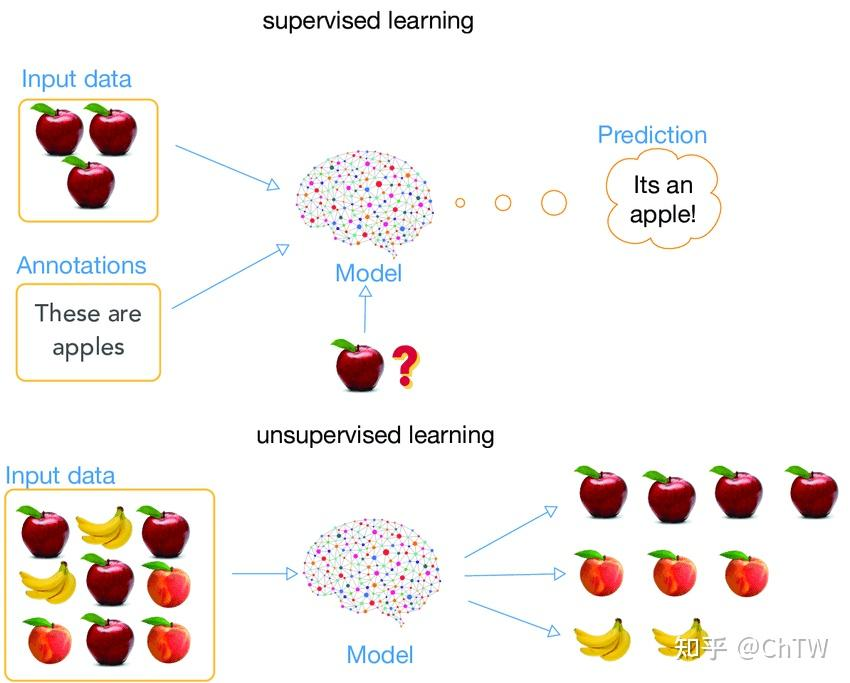
监督学习(Supervised Learning)
-
输入数据:带有明确的人工标注(Annotations)。
-
例如:图片上标注“These are apples”(这些是苹果)。
-
-
模型任务:学习从输入数据到标注的映射关系。
-
输出结果:模型根据学到的规律,对新数据预测标签(如“It's an apple!”)。
-
特点:
-
依赖标注数据,类似“老师教学生”。
-
适用于分类、回归等任务。
-
无监督学习(Unsupervised Learning)
-
输入数据:无任何标注,只有原始数据。
-
例如:一堆未标注的苹果和橘子图片。
-
-
模型任务:自行发现数据中的模式(如聚类、关联规则)。
-
输出结果:模型可能将相似数据分组(如自动区分苹果和橘子)。
-
特点:
-
无监督,类似“学生自学”。
-
适用于聚类、降维、异常检测等。
-
因为对比学习也是无监督学习的一种所以按照无监督进行理解。
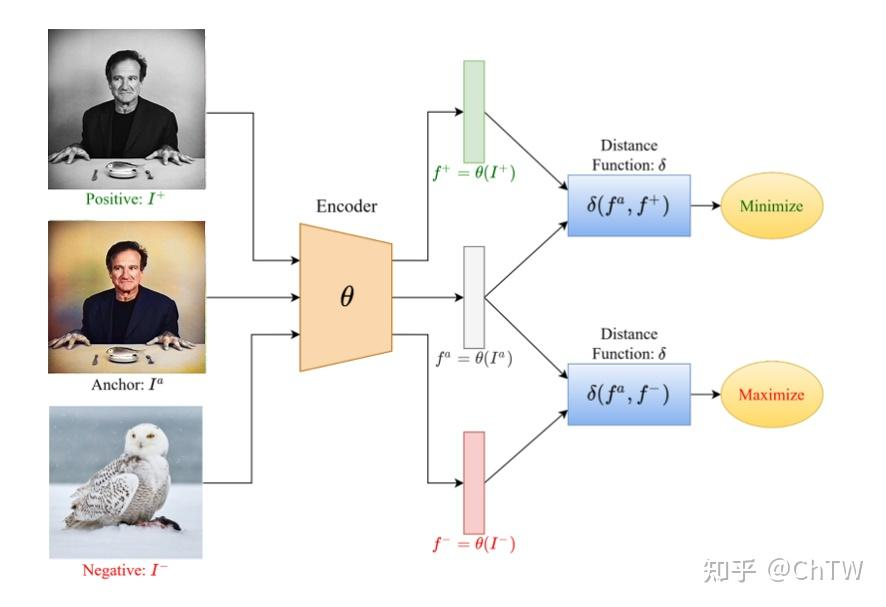
这张图展示了一个基于对比学习(或三元组损失)的特征学习框架,具体解释如下:
-
输入图像:
- Positive (
):与 Anchor 同类的样本(如同一人的另一张照片)。
- Anchor (
):作为基准的样本。
- Negative (
):与 Anchor 不同类的样本(如其他人的照片)。
- Positive (
-
编码器(Encoder,θ):
- 对三张图像进行特征提取,输出对应的特征向量:
(Positive 的特征),
(Anchor 的特征),
(Negative 的特征)。
- 对三张图像进行特征提取,输出对应的特征向量:
-
距离函数(Distance Function,δ):
- 计算
与
的距离,目标是最小化(Minimize)该距离,使同类样本特征更接近。
- 计算
的距离,目标是最大化(Maximize)该距离,使不同类样本特征更远离。
- 计算
这种方法常用于人脸识别、图像检索等任务,通过迫使模型学习到具有判别性的特征表示,增强同类样本的相似性和不同类样本的区分度。
论文链接:1503.03832
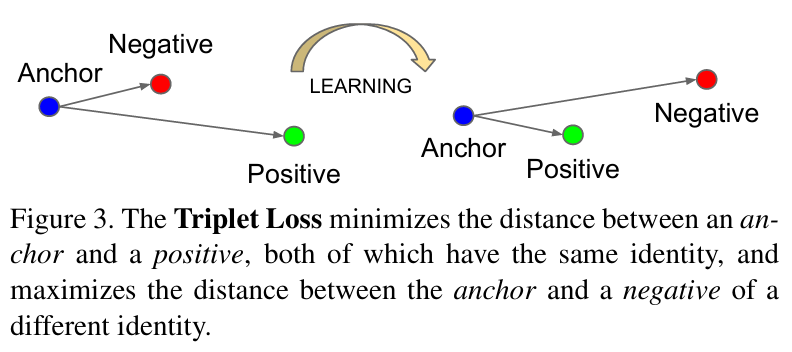
核心概念
-
三元组(Triplet)
由三部分组成:-
Anchor(锚点):基准样本(如一张人脸图片)。
-
Positive(正样本):与锚点同类的样本(如同一个人的另一张照片)。
-
Negative(负样本):与锚点不同类的样本(如另一个人的照片)。
-
-
目标
-
拉近锚点与正样本的距离(相似性↑)。
-
推远锚点与负样本的距离(差异性↑)。
-
这些就是最基本的概念,简单来说就是:拉近锚点与正样本的距离(相似性↑),推远锚点与负样本的距离(差异性↑)。