MySQL 8 窗口函数详解
MySQL 8 引入了强大的窗口函数功能,允许在查询中执行计算,同时保留原始行的详细信息。这与常规聚合函数不同,窗口函数不会将多行合并为单个输出行。
常用窗口函数类型
排名函数:ROW_NUMBER(), RANK(), DENSE_RANK(), NTILE()分析函数:LEAD(), LAG(), FIRST_VALUE(), LAST_VALUE(), NTH_VALUE()聚合函数作为窗口函数:SUM(), AVG(), COUNT(), MAX(), MIN()
核心语法结构
窗口函数的核心是 OVER() 子句,它定义了计算所基于的“窗口”。
<窗口函数> OVER ([PARTITION BY <分区列>][ORDER BY <排序列> [ASC|DESC]][<窗口帧>]
)
-
<窗口函数>:要执行的具体函数,例如 ROW_NUMBER(), SUM(), RANK() 等。
-
PARTITION BY:
a. 类似于 GROUP BY,用于将数据集划分成不同的分区。b. 窗口函数会独立地在每个分区内进行计算。
c. 如果省略,整个结果集将作为一个大分区。
-
ORDER BY:
a. 用于指定分区内数据的排序顺序。b. 这对排名函数(如 RANK())和计算累计值(如 SUM(…) ORDER BY date)至关重要。
-
<窗口帧>:
a. 在分区内,进一步定义一个滑动的子窗口,用于进行移动平均、累计求和等计算。b. 语法通常为:ROWS BETWEEN AND
UNBOUNDED PRECEDING:分区的第一行N PRECEDING:当前行之前的第 N 行CURRENT ROW:当前行N FOLLOWING:当前行之后的第 N 行UNBOUNDED FOLLOWING:分区的最后一行例如:ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW(从第一行到当前行,用于累计求和)
准备工作
示例表结构
假设我们有以下表结构:
-- 学生表
CREATE TABLE students (student_id INT PRIMARY KEY,name VARCHAR(50)
);-- 教师表
CREATE TABLE teachers (teacher_id INT PRIMARY KEY,name VARCHAR(50)
);-- 课程表
CREATE TABLE courses (course_id INT PRIMARY KEY,name VARCHAR(50),teacher_id INT,FOREIGN KEY (teacher_id) REFERENCES teachers(teacher_id)
);-- 成绩表
CREATE TABLE grades (grade_id INT PRIMARY KEY,student_id INT,course_id INT,score INT,FOREIGN KEY (student_id) REFERENCES students(student_id),FOREIGN KEY (course_id) REFERENCES courses(course_id)
);
示例数据
INSERT INTO students VALUES
(1, '张三'), (2, '李四'), (3, '王五'), (4, '赵六');INSERT INTO teachers VALUES
(1, '刘老师'), (2, '陈老师');INSERT INTO courses VALUES
(1, '数学', 1), (2, '英语', 2), (3, '物理', 1);INSERT INTO grades VALUES
(1, 1, 1, 85), (2, 1, 2, 90), (3, 1, 3, 78),
(4, 2, 1, 95), (5, 2, 2, 88), (6, 2, 3, 95),
(7, 3, 1, 76), (8, 3, 2, 82), (9, 3, 3, 88),
(10, 4, 1, 95), (11, 4, 2, 79), (12, 4, 3, 91);MySQL 8 窗口函数示例
使用ROW_NUMBER()为每个课程的学生成绩排名
SELECT c.name AS course_name,s.name AS student_name,g.score,ROW_NUMBER() OVER (PARTITION BY g.course_id ORDER BY g.score DESC) AS rank_in_course
FROM grades g
JOIN students s ON g.student_id = s.student_id
JOIN courses c ON g.course_id = c.course_id;
窗口函数详解
ROW_NUMBER()
这是一个窗口函数,它会为结果集中的每一行分配一个唯一的序号(从1开始)。
OVER()
这是窗口函数的关键字,定义了窗口的范围或框架。
PARTITION BY g.course_id
这是窗口定义的核心部分:
按课程ID进行分区:将数据分成不同的组,每个课程形成一个独立的组在每个分区内,ROW_NUMBER()会重新从1开始计数相当于SQL中的"GROUP BY",但不会将多行合并为一行
ORDER BY g.score DESC
这指定了在每个分区内如何排序:
按成绩(score)降序排列(高分在前)在每个课程组内,成绩最高的学生将获得排名1
查询结果如下
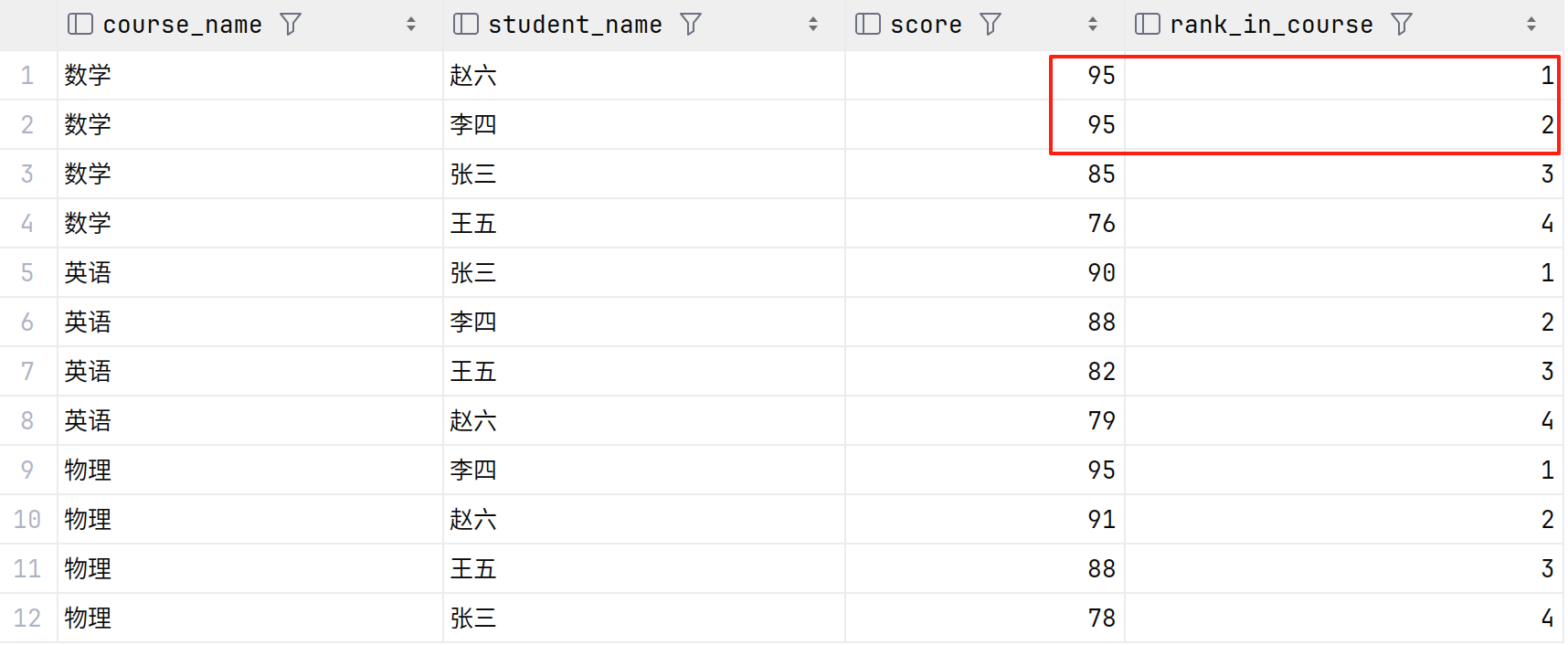
使用RANK()和DENSE_RANK()排名
SELECT c.name AS course_name,s.name AS student_name,g.score,RANK() OVER (PARTITION BY g.course_id ORDER BY g.score DESC) AS rank_with_gaps,DENSE_RANK() OVER (PARTITION BY g.course_id ORDER BY g.score DESC) AS dense_rank_no_gaps
FROM grades g
JOIN students s ON g.student_id = s.student_id
JOIN courses c ON g.course_id = c.course_id;
窗口函数详解
RANK() OVER (PARTITION BY g.course_id ORDER BY g.score DESC)
RANK(): 排名函数,为每一行分配一个排名PARTITION BY g.course_id: 按课程ID分区,为每门课程单独计算排名ORDER BY g.score DESC: 在每个课程分区内,按成绩降序排列(高分在前)特点: 当有相同分数时,会给相同排名,但会跳过后续的排名数字
DENSE_RANK() OVER (PARTITION BY g.course_id ORDER BY g.score DESC)
DENSE_RANK(): 密集排名函数分区和排序规则与RANK()相同特点: 当有相同分数时,会给相同排名,但不会跳过后续的排名数字
查询结果如下
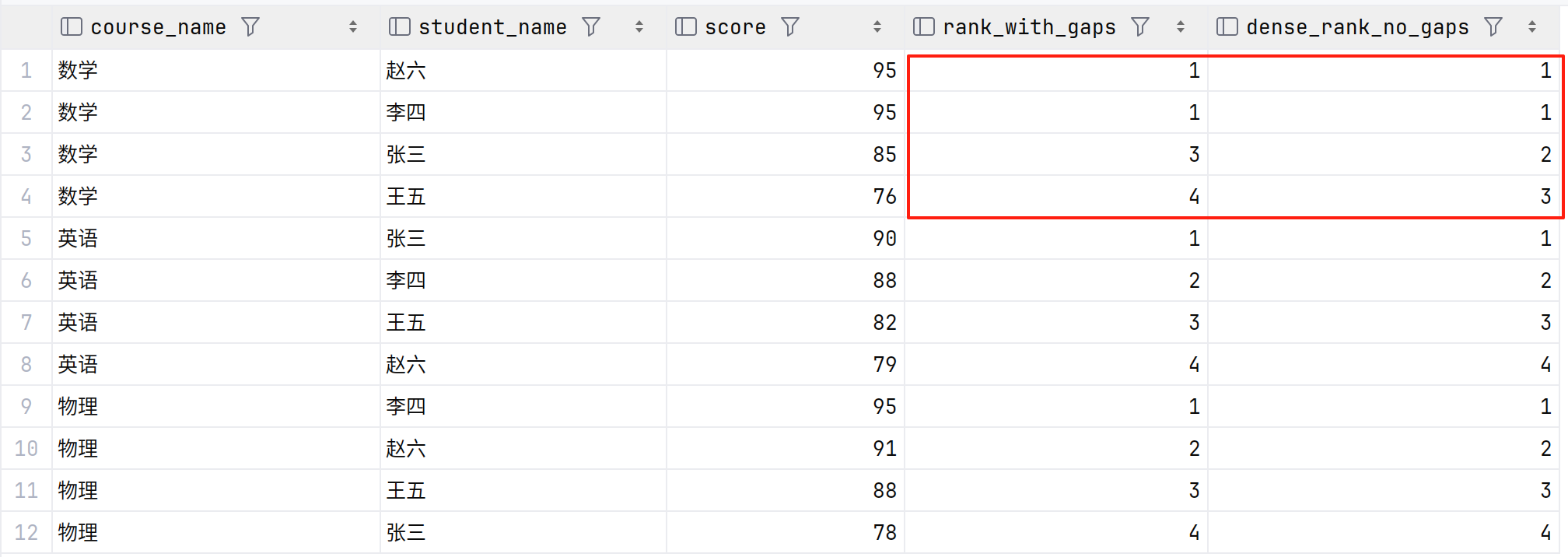
小结:
ROW_NUMBER():总是产生连续的序号(1,2,3,4...)RANK():相同值会有相同排名,但会跳过后续序号(1,2,2,4...)DENSE_RANK():相同值有相同排名,但不跳过后续序号(1,2,2,3...)
使用LEAD()和LAG()访问前后行数据
SELECT s.name AS student_name,c.name AS course_name,g.score,LAG(g.score) OVER (PARTITION BY g.student_id ORDER BY g.course_id) AS prev_course_score,LEAD(g.score) OVER (PARTITION BY g.student_id ORDER BY g.course_id) AS next_course_score
FROM grades g
JOIN students s ON g.student_id = s.student_id
JOIN courses c ON g.course_id = c.course_id;
查询结果如下
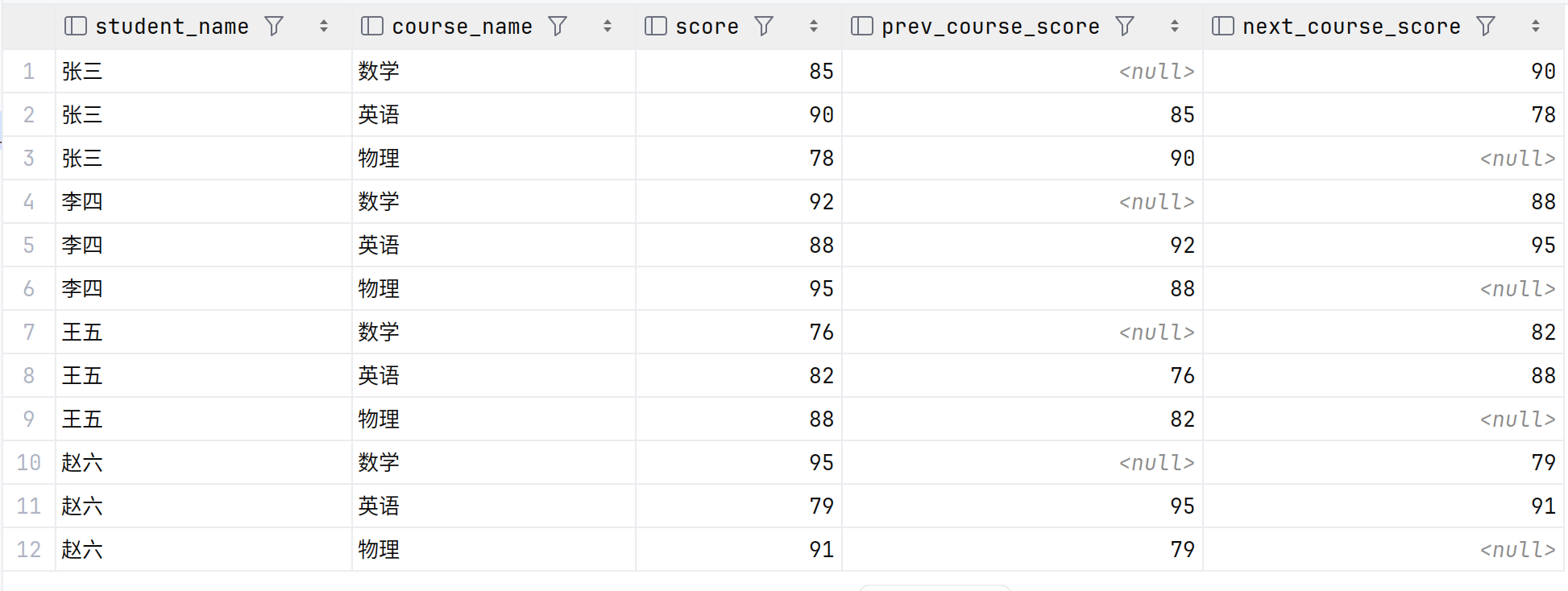
使用SUM()作为窗口函数计算累计总分
SELECT s.name AS student_name,c.name AS course_name,g.score,SUM(g.score) OVER (PARTITION BY g.student_id ORDER BY g.course_id) AS running_total
FROM grades g
JOIN students s ON g.student_id = s.student_id
JOIN courses c ON g.course_id = c.course_id;
查询结果如下
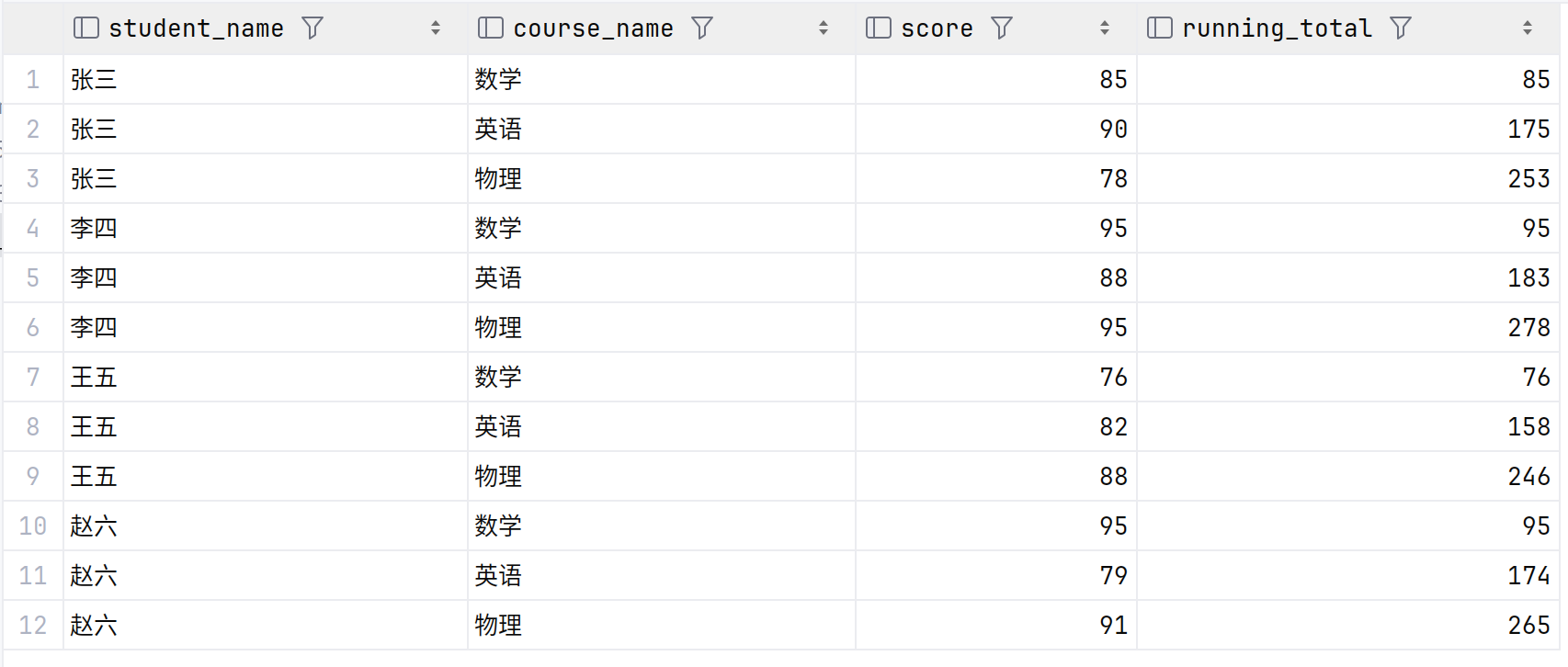
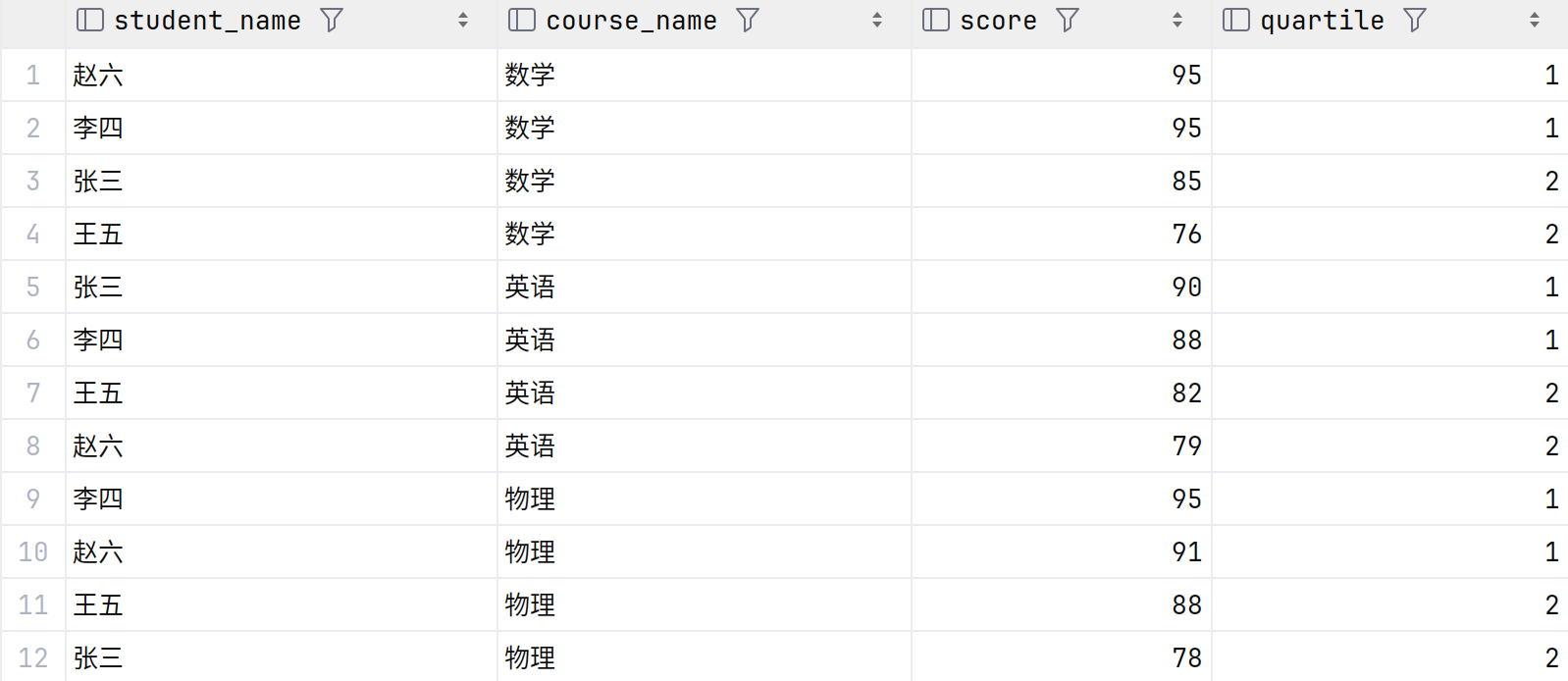
使用NTILE()将成绩分为4个等级
SELECT s.name AS student_name,c.name AS course_name,g.score,NTILE(2) OVER (PARTITION BY g.course_id ORDER BY g.score DESC) AS quartile
FROM grades g
JOIN students s ON g.student_id = s.student_id
JOIN courses c ON g.course_id = c.course_id;
窗口函数详解
NTILE(2)
将数据分成指定数量的桶(buckets),这里是2个桶每个桶包含大致相同数量的行常用于将数据分成百分位数(如四分位、十分位等)
OVER (PARTITION BY g.course_id ORDER BY g.score DESC)
PARTITION BY g.course_id: 按课程分区,每门课程独立计算ORDER BY g.score DESC: 在每个课程内按成绩降序排列
查询结果如下
MySQL 5.7 等效查询
在MySQL 5.7中,由于没有窗口函数,我们需要使用变量和子查询来模拟类似功能:
使用变量模拟ROW_NUMBER()
SELECT c.name AS course_name,s.name AS student_name,g.score,@row_number := CASE WHEN @current_course = g.course_id THEN @row_number + 1ELSE 1END AS rank_in_course,@current_course := g.course_id
FROM grades g
JOIN students s ON g.student_id = s.student_id
JOIN courses c ON g.course_id = c.course_id
CROSS JOIN (SELECT @row_number := 0, @current_course := 0) AS vars
ORDER BY g.course_id, g.score DESC;
使用子查询模拟RANK()
SELECT c.name AS course_name,s.name AS student_name,g.score,(SELECT COUNT(DISTINCT g2.score) FROM grades g2 WHERE g2.course_id = g.course_id AND g2.score > g.score) + 1 AS rank_with_gaps
FROM grades g
JOIN students s ON g.student_id = s.student_id
JOIN courses c ON g.course_id = c.course_id
ORDER BY g.course_id, g.score DESC;
使用自连接模拟LEAD()/LAG()
SELECT s.name AS student_name,c.name AS course_name,g.score,(SELECT g2.score FROM grades g2 WHERE g2.student_id = g.student_id AND g2.course_id < g.course_id ORDER BY g2.course_id DESC LIMIT 1) AS prev_course_score,(SELECT g2.score FROM grades g2 WHERE g2.student_id = g.student_id AND g2.course_id > g.course_id ORDER BY g2.course_id ASC LIMIT 1) AS next_course_score
FROM grades g
JOIN students s ON g.student_id = s.student_id
JOIN courses c ON g.course_id = c.course_id
ORDER BY g.student_id, g.course_id;
使用变量模拟累计总和
SELECT s.name AS student_name,c.name AS course_name,g.score,@running_total := CASE WHEN @current_student = g.student_id THEN @running_total + g.scoreELSE g.scoreEND AS running_total,@current_student := g.student_id
FROM grades g
JOIN students s ON g.student_id = s.student_id
JOIN courses c ON g.course_id = c.course_id
CROSS JOIN (SELECT @running_total := 0, @current_student := 0) AS vars
ORDER BY g.student_id, g.course_id;
总结
窗口函数特别适用于以下场景:
排名和分页计算移动平均和累计总和比较当前行与前后行计算百分比和比例