Spark04-MLib library01-机器学习的介绍
一. 什么是机器学习?
定义:机器学习(Machine Learning, ML)就是让计算机能够从数据中学习规律,并根据规律做出预测或决策。
区别于传统编程:
传统编程:我们写规则 → 计算机执行
机器学习:我们给数据 → 计算机自己总结出规则
日常应用举例:
淘宝/亚马逊的商品推荐
Netflix/抖音的视频推荐
支付宝/银行的欺诈检测
Siri/小爱同学的语音识别
Google Photos 的人脸识别
一句话理解:机器学习就是“数据驱动的自动经验总结”。
广义上讲,机器学习是一个利用统计学、线性代数和数值优化,从数据中提取模式model的过程。
应用价值
根据麦肯锡的一项研究:消费者在 Amazon 上 35% 的购买行为,以及他们在 Netflix 上 75% 的观看行为,都是由基于机器学习的产品推荐所驱动的。
商业
电商:个性化推荐 → 提高销量
金融:欺诈检测 → 降低风险
医疗:疾病预测 → 辅助诊断
社会
教育:个性化学习路径
环境:气候预测、污染监测
二. 机器学习的工作流程
收集数据:获取训练数据(有或无标签)。
提取特征:把现实数据(文字、图片、语音)转化成计算机能理解的数字。
例:垃圾短信 → 特征可能是“出现了多少次 free、win、discount”
训练模型:让算法在训练数据中学习规律。
测试模型:用没见过的测试数据来检验模型表现。
部署应用:把模型用在现实中(推荐、预测、检测)。
重点:训练数据和测试数据必须分开,否则模型只会“死记硬背”,而不是“真正学会”。
三、机器学习的分类
机器学习有几种类型,包括:
监督学习(supervised)、半监督学习(semi-supervised)、无监督学习(unsupervised)以及强化学习(reinforcement learning)。
本章将主要聚焦于监督学习,同时只会简要涉及无监督学习。
我们先简要讨论一下 监督学习 和 无监督学习 之间的区别:
- Supervised Machine Learning
监督机器学习- Classification and Regression
分类和回归
- Classification and Regression
- Unsupervised Machine Learning
无监督机器学习- Clustering and Association
聚类和关联
- Clustering and Association
3-1. 监督学习(Supervised Learning)
基本思想
监督学习就像老师带着学生做题:
老师给出题目(输入)+ 答案(标签label)
学生学会后,再给新题,看看能不能答对。
Goal: Learn a function from labelled training data to predict the output label(s) given a new unlabeled input.
这些labels可以是离散的,或者连续的,这就有了监督学习的两个types:
classification + regression
两大任务
分类(Classification)
目标:把输入数据归到“离散的类别”。
二分类(Binary):只有两个结果
例子:垃圾邮件 vs 非垃圾邮件
例子:肿瘤是否恶性(是/否)
多分类(Multiclass):结果有三个或更多
例子:识别狗的品种(哈士奇/金毛/柴犬)
例子:预测考试成绩等级(A/B/C/D)
回归(Regression)
目标:预测连续数值
例子:预测房价(50万、80万,而不是“贵/便宜”)
例子:预测气温(27.5°C,而不是“冷/热”)
对比记忆:
分类 → 预测“标签/类别”
回归 → 预测“数值/连续量”

3-2. 无监督学习(Unsupervised Learning)
1. 基本思想
无监督学习就像学生自学:
老师不给答案,只给一堆题。
学生需要自己发现规律:哪些题相似、哪些题可以归为一类。
无监督学习(Unsupervised Machine Learning, 无监督ML)主要不是为了直接给你一个预测结果,而是帮助你“看清数据内部的结构和模式”。
为什么这么说?
在 监督学习 (Supervised ML) 中,你有 输入特征 (X) 和 目标标签 (Y),模型的目标是学会从 X 预测 Y。
而在 无监督学习 (Unsupervised ML) 中,数据里没有标签 Y,模型的任务就是“探索”数据本身的分布和关系。如何“理解数据结构”?
聚类 (Clustering)
比如用 K-means 或 层次聚类,可以把相似的数据点自动分到一类,帮你发现“数据中有哪些潜在群体”。
👉 例子:电商用户分群,高消费 vs 低消费。降维 (Dimensionality Reduction)
比如 PCA, t-SNE, UMAP,可以把高维数据投影到低维空间,让你发现数据之间的相似性和整体分布。
👉 例子:基因表达数据可视化,看哪些基因模式相似。异常检测 (Anomaly Detection)
无监督方法也能帮你发现与整体模式不同的数据点。
👉 例子:检测银行交易里的欺诈行为。
Unsupervised ML 并不是直接回答“结果是什么”,而是帮你回答“数据中藏着怎样的结构/模式/群体”。
2. 两大任务
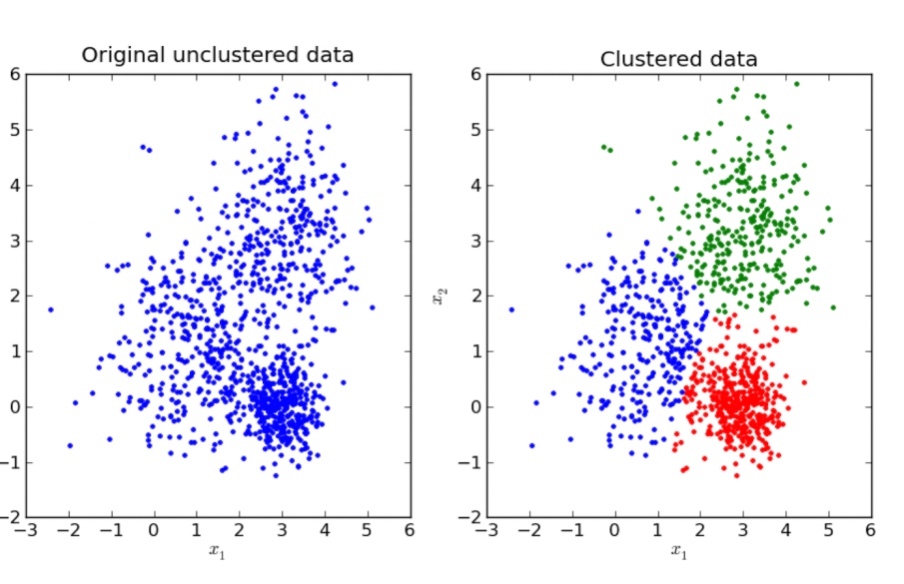
聚类(Clustering)
目标:把相似的数据分组
例子:根据购买行为,把顾客分成“爱买奢侈品的”“喜欢打折的”“只买必需品的”
应用:
异常检测(发现“和大家不一样”的情况 → 欺诈检测、机器故障)
数据降维(减少变量数量,方便存储和后续分析)
关联规则(Association Rules)
目标:发现“X 和 Y 常常一起出现”
例子:啤酒和尿布的经典案例(超市发现:买尿布的人也常买啤酒 → 货架调整提升销量)
例子:买新房的人大概率会买家具、电器
一句话理解:
监督学习 → “有答案的考试”
无监督学习 → “没答案的自学”
3. 常见算法
K-means:把数据点自动分成 K 类。
LDA (Latent Dirichlet Allocation):常用于文本主题建模,发现文章里“潜在的主题”。
GMM (Gaussian Mixture Models):假设数据来自多个高斯分布,帮你找到不同“分布成分”。
无监督学习不仅能独立完成任务(聚类、主题建模、异常检测),还能作为“数据清理和压缩工具”,为监督学习提供更简洁、更高效的数据输入。
3-3. 监督学习 vs 无监督学习对比表
| 特点 | 监督学习 | 无监督学习 |
|---|---|---|
| 数据 | 有标签(X → y) | 无标签(只有 X) |
| 学习方式 | “老师带着学” | “自学” |
| 典型任务 | 分类、回归 | 聚类、关联规则 |
| 输出 | 预测类别或数值 | 发现结构/规律 |
| 应用 | 垃圾邮件过滤、房价预测 | 客户分群、购物篮分析 |
3-4. 总结
机器学习的本质:从数据中学习规律 → 用规律做预测或决策。
两大分支:
监督学习(有答案 → 分类、回归)
无监督学习(无答案 → 聚类、关联)
学习机器学习,要先理解 “数据–特征–模型–预测” 这一链条。
四、常见的机器学习算法以及它们典型的应用场景
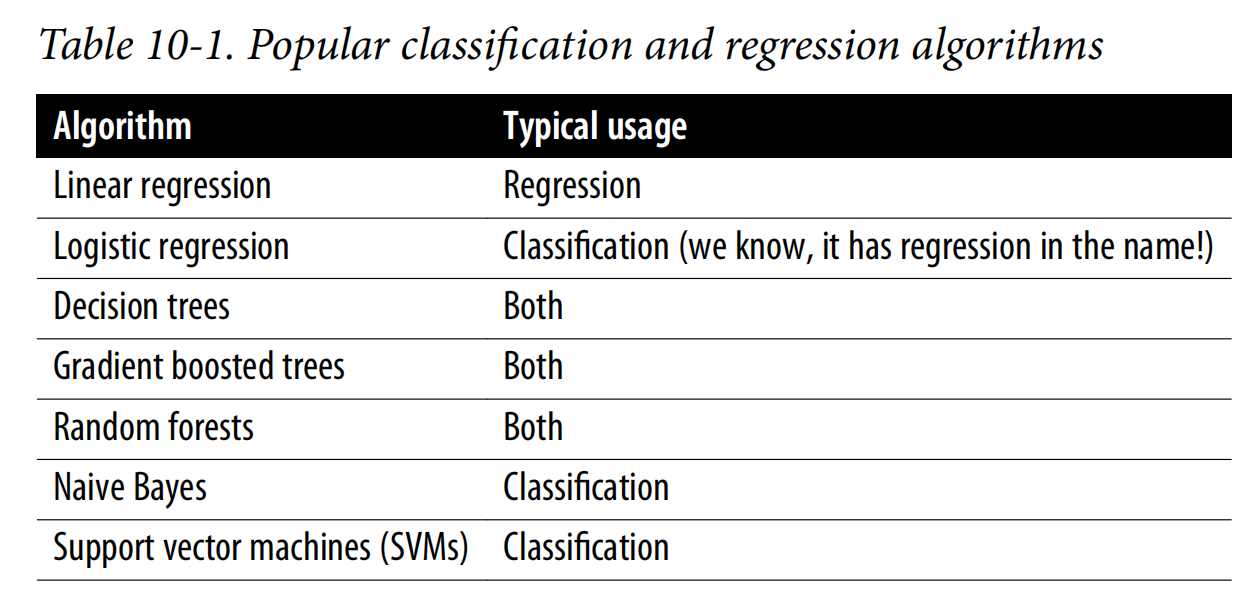
这张表 Table 10-1 总结了常见的机器学习算法以及它们典型的应用场景。
1. Linear Regression(线性回归)
用途:主要用于 回归任务,也就是预测一个连续型变量(如房价、销售额)。
特点:假设输入特征与输出变量之间存在线性关系,公式形式简单,但对数据分布和线性假设要求较高。
2. Logistic Regression(逻辑回归)
用途:尽管名字里有“回归”,它实际上是用于 分类任务,特别是二分类(如判断是否患病、是否会违约)。
特点:利用 sigmoid 函数将结果映射到 0–1 之间,从而输出概率。常用于二元分类,也可以扩展为多分类。
3. Decision Trees(决策树)
用途:既可以做 回归,也可以做 分类。
特点:通过树形结构逐步划分数据,解释性强,容易可视化,但容易过拟合。适合非线性关系。
4. Gradient Boosted Trees(梯度提升树, GBDT)
用途:同样可以做 回归和分类。
特点:一种集成学习方法,将多个弱学习器(通常是小的决策树)逐步提升,效果通常优于单一决策树,常用于 Kaggle 等竞赛。
5. Random Forests(随机森林)
用途:也可以同时用于 回归和分类。
特点:通过集成多棵决策树(每棵树在样本和特征上都有随机性)来减少过拟合,稳定性和准确率较高。
6. Naive Bayes(朴素贝叶斯)
用途:主要用于 分类。
特点:基于贝叶斯定理和“特征条件独立性”的假设,计算速度快,适合文本分类、垃圾邮件检测等,但独立性假设往往过于理想化。
7. Support Vector Machines (SVM, 支持向量机)
用途:主要用于 分类。
特点:通过最大化分类间隔来找到最优决策边界,可以处理高维数据和非线性问题(利用核函数),但计算成本较高。
总结
只用于回归:Linear regression
只用于分类:Logistic regression, Naive Bayes, SVM
两者都能用:Decision Trees, Gradient Boosted Trees, Random Forests
这张表相当于一张 速查表(cheat sheet),帮助你快速判断在不同问题(回归 vs 分类)下常用的算法选择。
五、Spark中的机器学习
5-1、为什么在机器学习中选择 Spark?
Spark 是一个统一的分析引擎,提供了一个涵盖 数据摄取、特征工程、模型训练和部署 的生态系统。
如果没有 Spark,开发人员就需要许多不同的工具来完成这一系列任务,而且仍然可能在可扩展性上遇到困难。
Spark 有两个机器学习包:spark.mllib 和 spark.ml。
spark.mllib 是最初的机器学习 API,基于 RDD API(自 Spark 2.0 以来已进入维护模式);
spark.ml 是较新的 API,基于 DataFrame。
本章的其余部分将重点介绍 如何使用 spark.ml 包 以及 如何在 Spark 中设计机器学习流水线。
不过,我们仍然使用 “MLlib” 作为统称,指代 Apache Spark 中的这两个机器学习库包。
使用 spark.ml,数据科学家可以在一个生态系统中完成 数据准备和模型构建,而无需将数据下采样以适配单机。
spark.ml 专注于 O(n) 的横向扩展,即模型能够随着数据点数量线性扩展,因此它可以扩展到 海量数据。
5-2、向量 (Vector)
1. 什么是向量 (Vector)?
在机器学习中,向量是最基本的数据结构之一,可以理解为一组数值的有序集合(数学上的一维数组)。
每个数值就是一个 特征 (feature) 的取值。
一个样本(比如一条训练数据)通常可以用一个向量来表示。
2. 稠密向量 (Dense Vector)
定义:每一个元素(不管是 0 还是非 0)都被显式存储。
例子:
Dense Vector (1.0, 0.0, 5.4, 0.0)就是直接存储为数组:
[1.0, 0.0, 5.4, 0.0]。特点:
直观,容易实现。
但如果维度非常大,且大部分值是 0,就会浪费大量存储空间。
3. 稀疏向量 (Sparse Vector)
定义:只存储非零元素的位置(index)和数值(value),用来节省空间。
例子:
Sparse Vector (4, [0, 2], [1.0, 5.4])4→ 向量的总长度为 4[0, 2]→ 非零元素所在的位置索引[1.0, 5.4]→ 对应索引的值
等价于稠密形式:
[1.0, 0.0, 5.4, 0.0]特点:
节省内存(尤其在高维特征空间中,大多数值是 0 的时候,比如文本处理)。
机器学习库(如 Spark MLlib, Scikit-learn)中广泛使用。
4. 图中流程说明
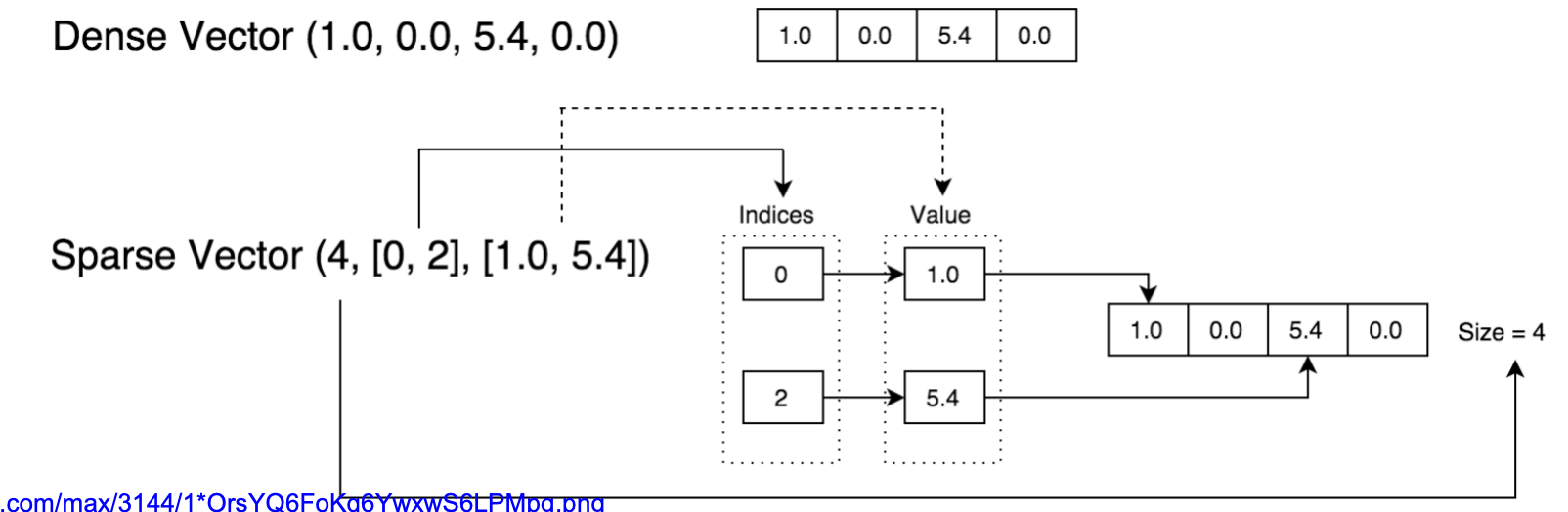
上方展示的是 稠密向量:完整存储
[1.0, 0.0, 5.4, 0.0]。下方展示的是 稀疏向量:
Indices(索引):
0, 2Value(值):
1.0, 5.4结合 Size=4,还原后就是
[1.0, 0.0, 5.4, 0.0]。
总结一句话:
Dense Vector → 适合低维数据,直接存储所有数值。
Sparse Vector → 适合高维稀疏数据,只存储非零值和索引,更节省空间和计算资源。
5. 举例说明:词袋模型 (Bag-of-Words, BoW)
假设我们有一个很小的语料库:
文档1: "I love data"
文档2: "I love machine learning"
1). 构建词典 (Vocabulary)
我们从所有文档中提取唯一单词:
["I", "love", "data", "machine", "learning"]
总共有 5 个词,所以每个文档都会表示成一个 长度为 5 的向量。
2). 稠密向量表示 (Dense Vector)
文档1: "I love data" →
[1, 1, 1, 0, 0]文档2: "I love machine learning" →
[1, 1, 0, 1, 1]
这里每个元素都显式存储(即使是 0)。
3). 稀疏向量表示 (Sparse Vector)
存储时只保存非零值的索引和对应的值:
文档1:
[5, [0,1,2], [1,1,1]]向量总长 = 5
索引
[0,1,2]对应的值[1,1,1]等价于
[1,1,1,0,0]
文档2:
[5, [0,1,3,4], [1,1,1,1]]等价于
[1,1,0,1,1]
4). 为什么稀疏向量更实用?
在真实 NLP 应用中:
词典可能有 50,000 或 100,000 个词。
但一篇文章只包含其中几十或几百个。
稠密向量:存储 全部 50,000 个值(绝大多数是 0)。
稀疏向量:只存储 少量非零值及其索引,大大节省内存和计算量。
5-3、偏差(Bias)与方差(Variance)
1、偏差(Bias)
衡量预测值与真实值的接近程度。
偏差低 → 模型准确;偏差高 → 模型不准。
2、方差(Variance)
Variance 关注的是:预测结果稳定不稳定(分散)。
方差主要描述:同一个模型如果在不同的数据集(或不同的样本划分)上训练,预测结果会相差多大。
如果差异很大,说明模型对数据非常敏感,稳定性差;
如果模型在不同情况下产生了很大的结果差异(高方差),说明模型把数据学得“太细了”。
也就是说,它过度拟合了训练数据中的噪声和细节。
换句话说,数据的分布特性被模型“放大”了,导致预测结果很不稳定。
在机器学习里,这通常意味着模型过拟合(overfitting)。
在机器学习中,既不能只追求低偏差(Bias,避免欠拟合),也不能让方差(Variance)过高(避免过拟合)。 我们需要在两者之间找到一个 平衡点 (Bias-Variance Tradeoff)。 最佳情况:稳定且接近目标(低偏差 + 低方差)。
5-4、过拟合与欠拟合
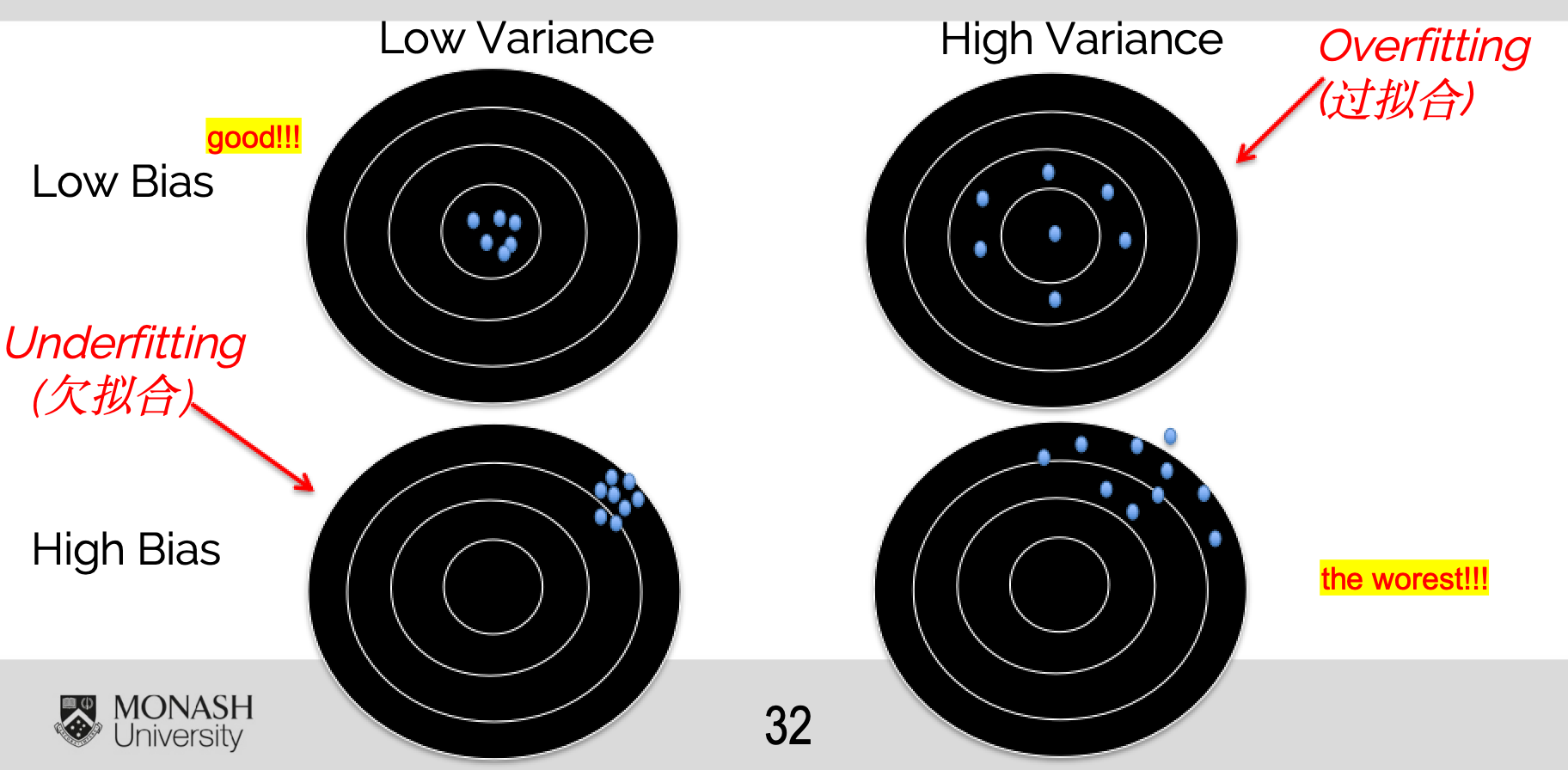
过拟合(Overfitting)
高方差、低偏差
模型“死记硬背”训练数据 → 对新数据表现差(在训练集上表现良好)。
欠拟合(Underfitting)
高偏差、低方差
模型过于简单 → 连训练集表现都不好。
5-5、防止过拟合的方法
1、增加训练数据
更多样本 → 更好捕捉规律
⚠️ 如果数据噪声多,不干净或者不想干,则无效!
2、删除无关特征
一些算法(如随机森林)自带特征选择;
人工筛选方法:“讲故事法”
能解释为什么特征与目标相关 → 保留
无法解释 → 可能是无关特征 → 删除
这里的“讲故事”并不是随便编,而是一种 解释性推理:能不能把特征与预测目标合理地联系起来。
提供一些具体方法:
🔹 1. 从 业务/常识 出发
问自己:这个特征和目标变量有没有直觉上的逻辑关系?
例子:预测房价时
“房子面积” → 很合理(面积越大,价格可能越高)
“邮编” → 合理(不同区域房价差异大)
“房东喜欢的颜色” → 就很难解释 → 可以考虑删掉
📌 方法:对每个特征写一句话解释:“它为什么可能影响目标?”
🔹 2. 用 可视化 来“讲故事”
画图来看看特征和目标变量的关系。
散点图(数值型特征 vs 目标)
箱线图(分类特征 vs 目标)
相关系数/热力图
📌 如果在图上完全看不出任何趋势,说明这个特征可能没啥用。
🔹 3. 用 统计方法 检验
数值型特征 → 计算与目标的相关性(Pearson/Spearman)。
分类特征 → 用卡方检验、ANOVA 等方法,看它对目标有没有显著性。
📌 如果相关性几乎为 0,或者统计检验不显著,可以考虑删除。
🔹 4. 用 模型解释 来“讲故事”
先训练一个模型(比如决策树、随机森林、逻辑回归)。
看特征重要性(feature importance)或回归系数。
如果某些特征几乎没有权重/重要性,说明它们贡献很小。
📌 比如用 SHAP/LIME 工具,可以直观解释每个特征对预测的影响。
🔹 5. 做“结对调试”
就像老师说的 debug代码:
把特征解释一遍给别人听。
如果别人听完觉得“这个特征和预测目标没啥关系”,那它大概率是无关特征。
✅ 总结:怎么“讲故事”?
可以用以下模板:
“我认为 [特征X] 对预测 [目标Y] 有用,因为 [逻辑/数据依据]。
从图/统计结果来看,它确实和目标有关系(或没有)。
如果我完全说不出理由,或者数据验证没有支持,那这个特征可能要删除。”
3、提前停止(Early Stopping)
训练迭代过程中监控性能
一旦性能下降,提前停止训练
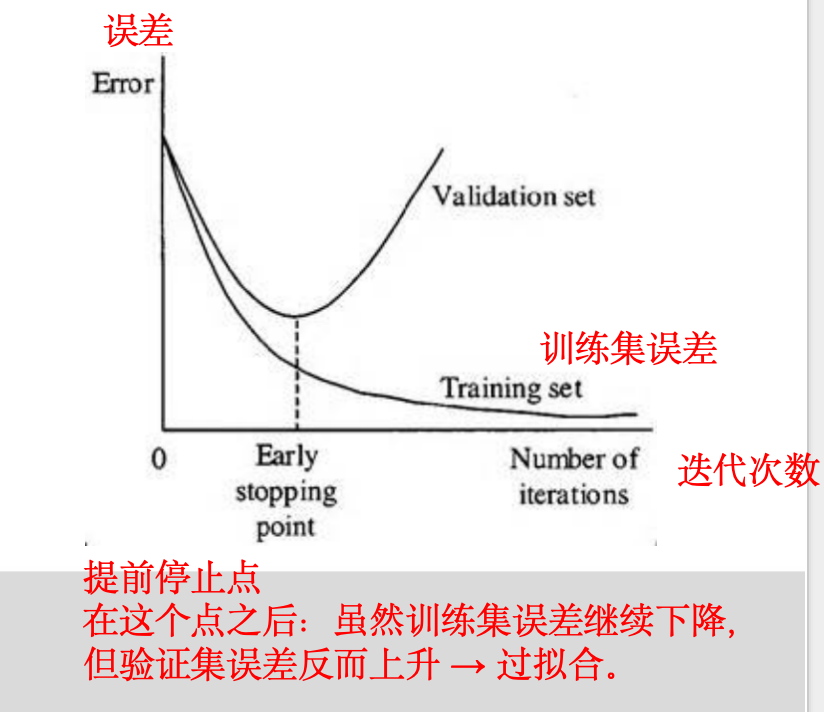
两条曲线:
Training set(训练集误差):随着迭代次数增加,误差不断下降(模型在训练集上学得越来越好)。
Validation set(验证集误差):一开始也在下降,但到达某个点后开始上升(说明模型开始过拟合)。
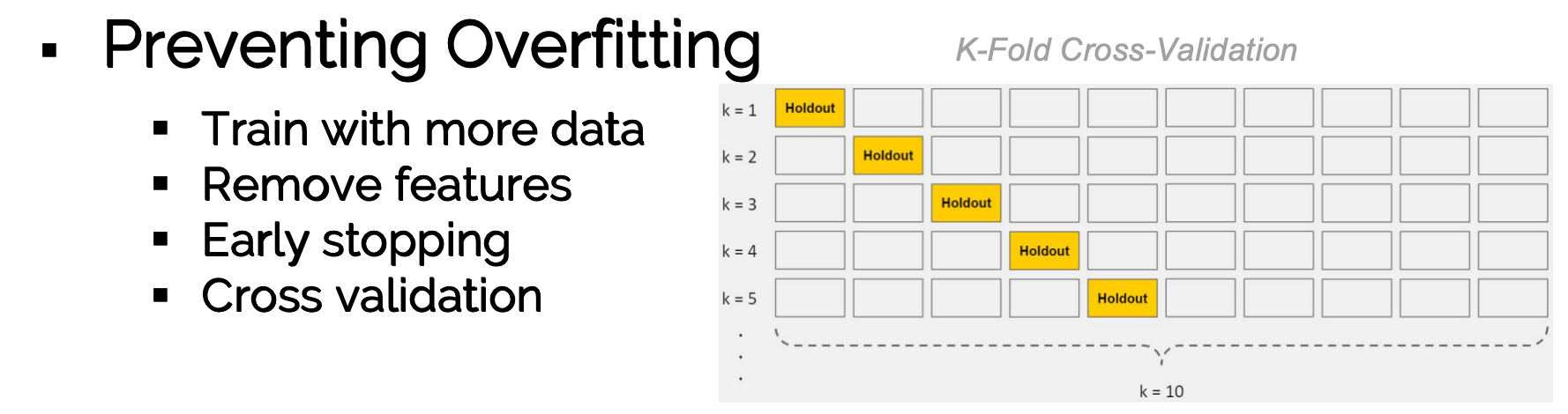
4、交叉验证(Cross-Validation)
将训练集划分为 K 份(K-Fold)(迭代K次)
反复训练 + 验证 → 调参
保证测试集真正未见过,提高泛化能力
5-6、模型评估指标
在分类问题中,Accuracy(准确率) 有时并不够,因为数据往往不平衡(比如欺诈检测,1% 是正例,99% 是负例,模型全预测负例也有 99% 准确率,但毫无意义)。
所以我们会用 Precision、Recall、F1 作为更细粒度的指标。
1. Precision(精确率)
公式:
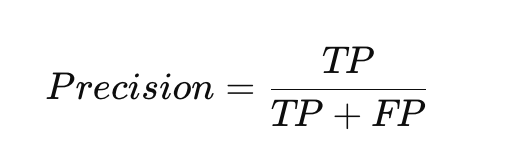
解释:在所有被预测为“正类”的样本中,真正是正类的比例。
重点:看预测的正样本里,有多少是真的。
应用场景:
医疗检测:预测为“有病”的人,确实有病的比例。
信息检索:搜索引擎返回的结果里,相关文档占比。
高 Precision:意味着“预测正类”时很谨慎,宁可少报也不想错报。
2. Recall(召回率)
公式:
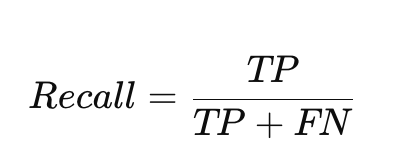
解释:在所有实际为“正类”的样本中,模型成功识别出的比例。
重点:看正样本里有多少被模型找出来了。
应用场景:
欺诈检测:所有真实欺诈交易中,被模型成功检测出来的比例。
医学检测:所有患病者中,能被检测出来的比例。
高 Recall:意味着“宁可多报,也不能漏掉”。
3. F1 分数
公式:
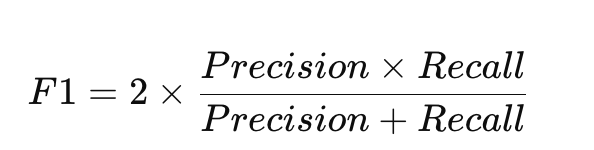
解释:是 Precision 和 Recall 的 调和平均数。
作用:在 Precision 和 Recall 之间找到一个平衡。
特点:
当 Precision 很高但 Recall 很低,或 Recall 高但 Precision 很低时,F1 都不会太高。
只有两者同时高,F1 才高。
总结类比
Precision → 你推荐的电影里,有多少真的是用户喜欢的(质量)。
Recall → 用户喜欢的电影里,有多少被你推荐出来(覆盖率)。
F1 → 既要质量高,又要覆盖面大。
混淆矩阵 (Confusion Matrix):
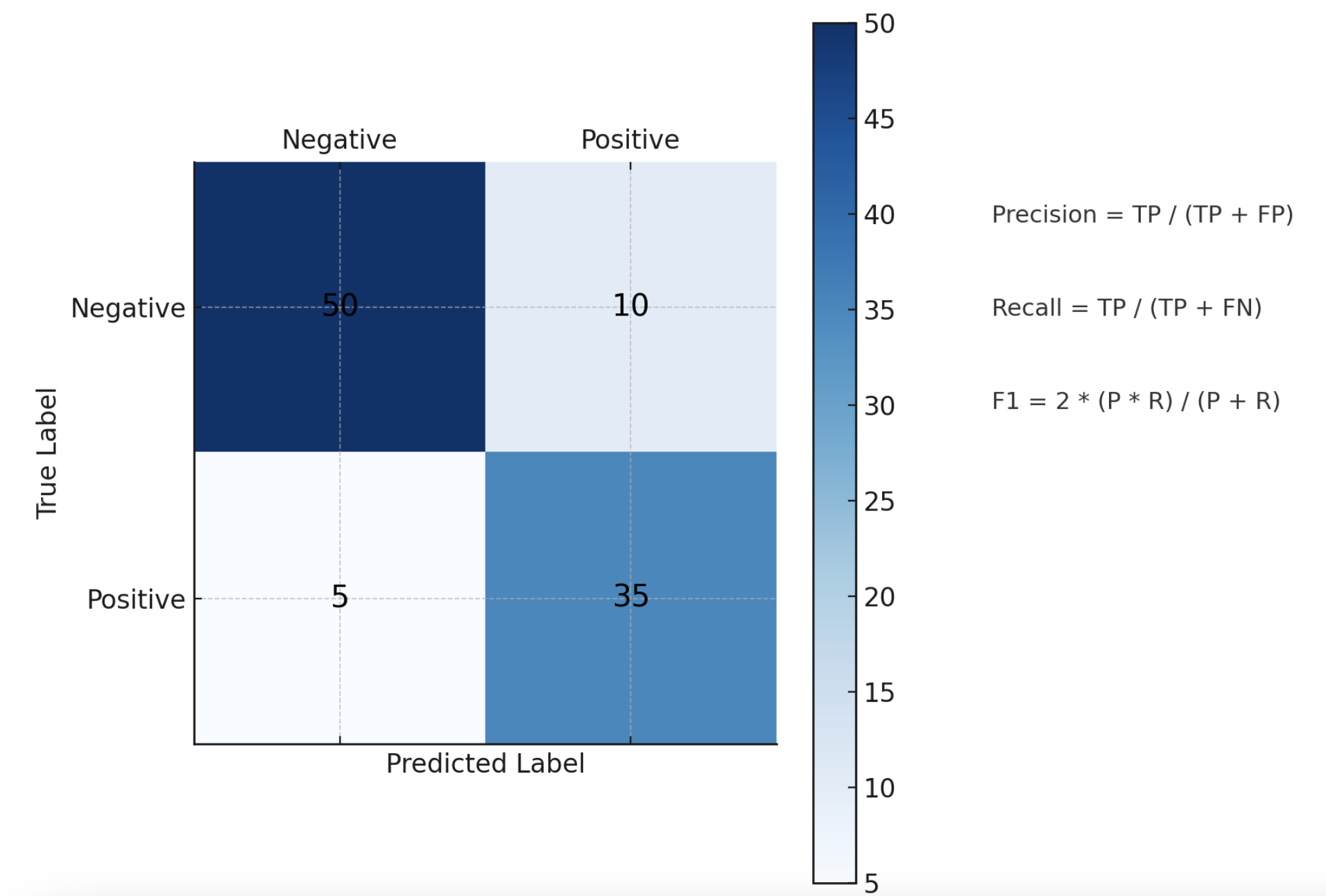
1、混淆矩阵解释
左上角 50 = True Negative (TN):真实为负,预测也为负。
右上角 10 = False Positive (FP):真实为负,但预测为正(“误报”)。
左下角 5 = False Negative (FN):真实为正,但预测为负(“漏报”)。
右下角 35 = True Positive (TP):真实为正,预测也为正。
2、指标公式对应
Precision = TP / (TP + FP)
= 35 / (35 + 10) = 0.78
在所有被预测为正的 45 个样本里,有 78% 真的是正的。Recall = TP / (TP + FN)
= 35 / (35 + 5) = 0.875
在所有真实正类 40 个样本里,87.5% 被模型成功找出来。F1 = 2 * (Precision * Recall) / (Precision + Recall)
= 2 * (0.78 * 0.875) / (0.78 + 0.875) ≈ 0.824
F1 在 Precision 和 Recall 之间做了一个平衡。