【RAGFlow代码详解-1】概述
什么是 RAGFlow
RAGFlow 是一个生产就绪的 RAG 引擎,它将大型语言模型 (LLM) 与高级文档理解相结合,从非结构化数据中提供准确的、有引文支持的响应。系统通过基于模板的分块和多模态检索机制处理多种文档格式(PDF、DOCX、Excel、图像、网页)。
主要技术特点包括:
- 深度文档理解 :通过 deepdoc/ 模块对复杂布局进行视觉驱动的文档解析
- 基于模板的分块 :rag/nlp/ 中的可配置文本分割策略
- 多后端存储 :通过 DOC_ENGINE 配置支持 Elasticsearch、Infinity 和 OpenSearch
- 代理工作流系统 :带有代理/canvas.py 执行引擎的可视化工作流构建器
- 多语言支持 :web/src/locales/ 中的 11 种语言本地化
该平台公开 Web 界面 (web/) 和编程 API (api/apps/),支持无缝集成到现有业务工作流程中。
高级系统架构
RAGFlow 实现了分层架构,前端接口、API 服务、处理引擎和存储后端之间进行了明确的分离。
整体系统架构
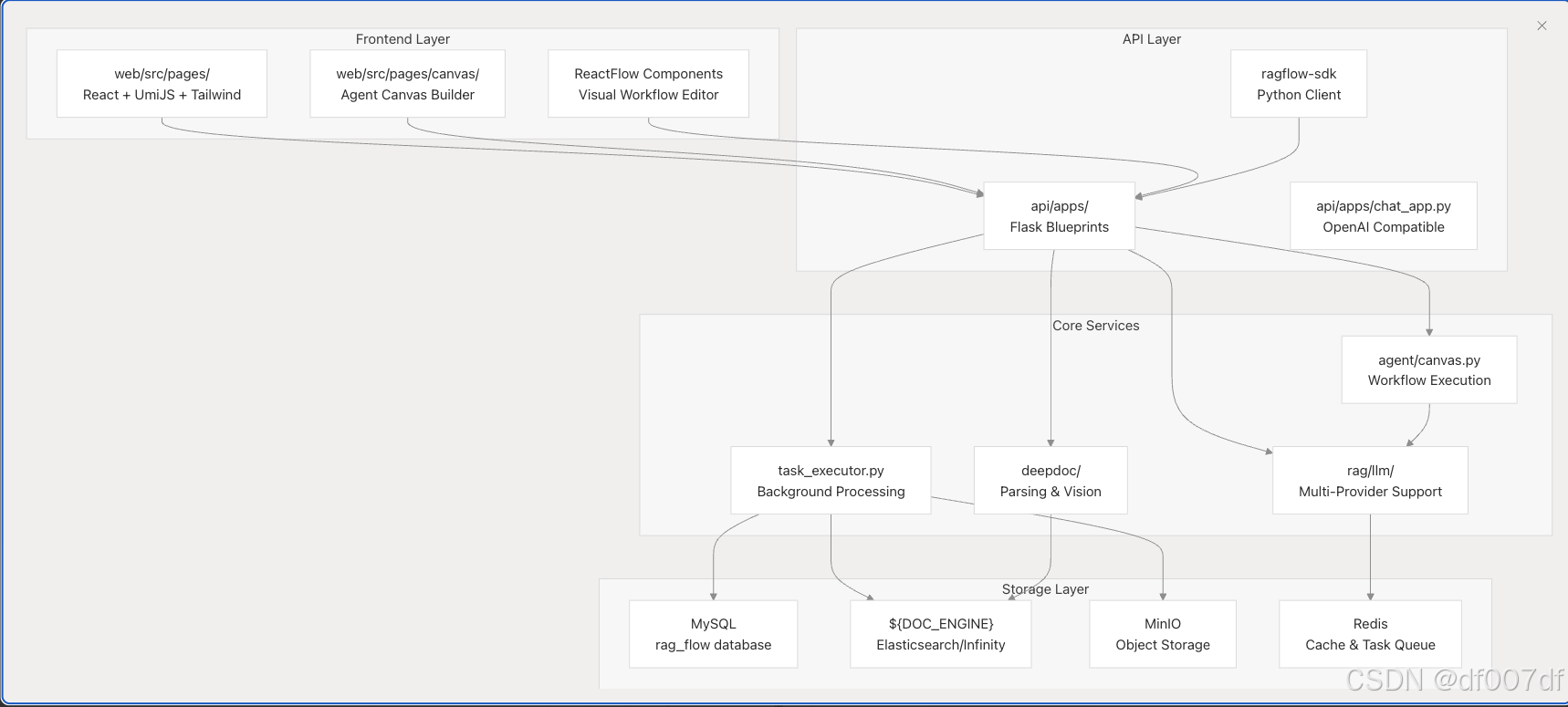
该架构支持通过容器化服务进行水平扩展,并通过 docker/.env 中的环境变量支持可配置的存储后端。
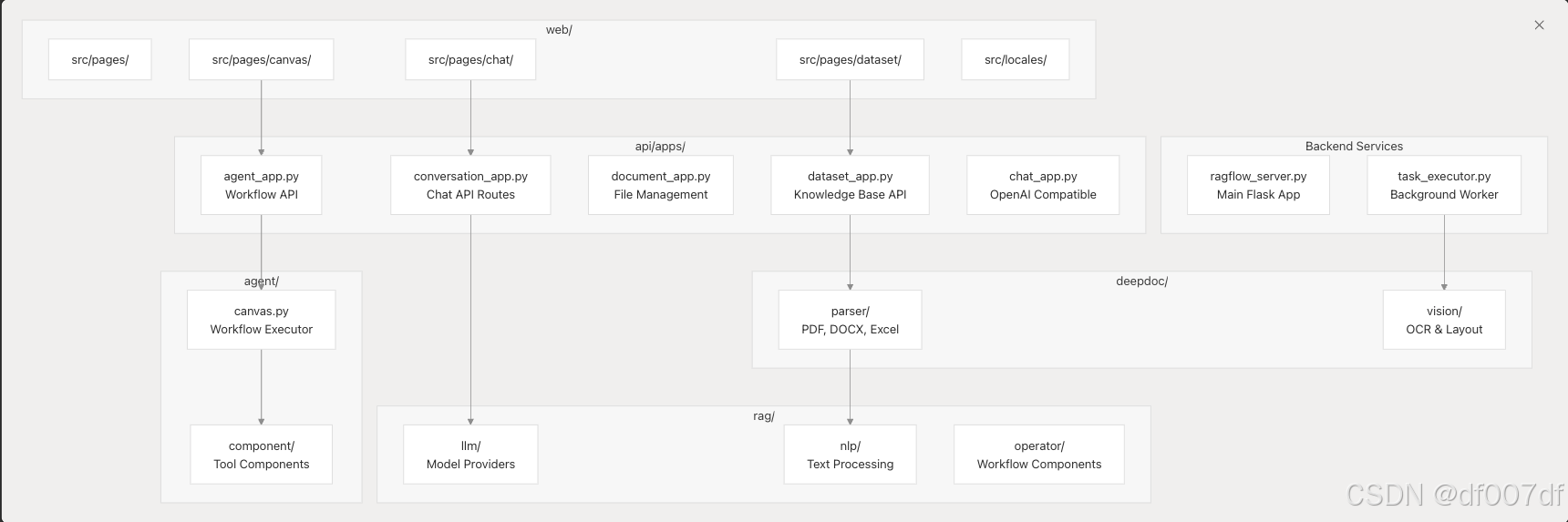
组件到代码映射
该图将 RAGFlow 的功能组件映射到其特定的代码实现,从而实现从系统概念到实际文件位置的导航。
核心组件架构
文件处理管道

核心处理工作流程
RAG 数据处理管道
RAGFlow 通过多阶段管道处理文档,将非结构化内容转换为语义上可搜索的知识。
| 阶段 | 实现 | 主要功能 | 配置 |
|---|---|---|---|
| 上传 | api/apps/document_app.py | upload()、create() | .env 中的 MAX_CONTENT_LENGTH |
| 解析 | deepdoc/parser/ | 块()、extract_table_figure() | 文档类型检测 |
| 视觉 | deepdoc/vision/ | layout_recognize()、ocr() | 多模态模型支持 |
| 块 | rag/nlp/rag_tokenizer.py | tokenize()、naive_merge() | 基于模板的策略 |
| 嵌入 | rag/llm/embedding_model.py | 编码()、encode_queries() | 特定于提供程序的模型 |
| index | ${DOC_ENGINE} 存储 | 矢量 + 全文索引 | Elasticsearch/Infinity/OpenSearch |
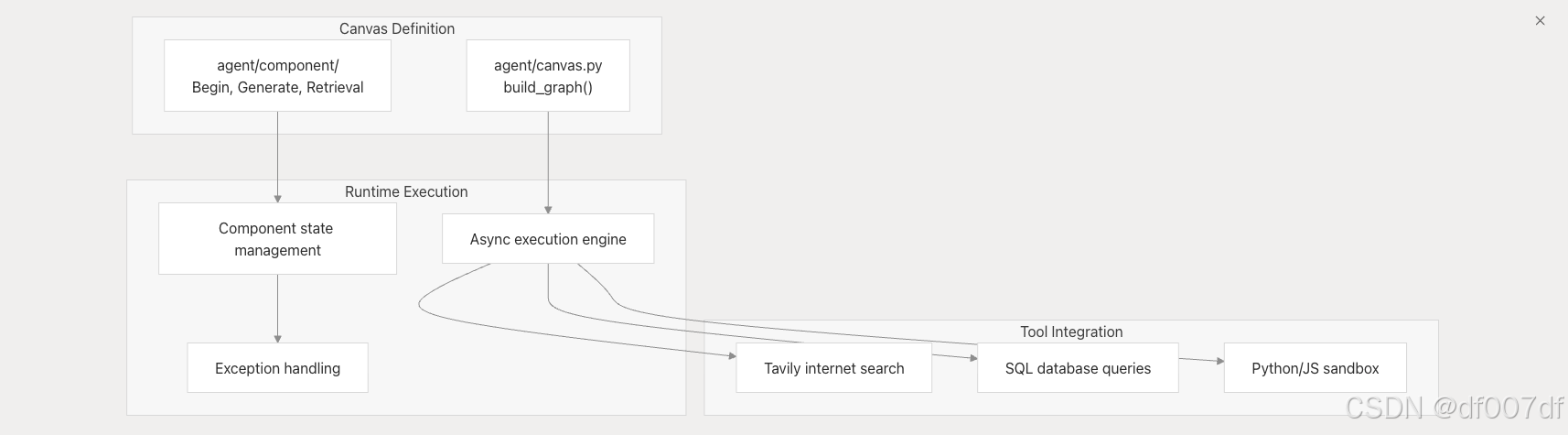
代理工作流执行
RAGFlow 的代理系统通过基于组件的处理来执行可视化工作流程。
代理画布执行流程
技术栈和部署
核心技术
前端堆栈:
- web/src/ 中的 React + TypeScript
- 用于构建系统和路由的 UmiJS 框架
- Ant Design + Tailwind CSS for UI 组件
- 用于代理画布可视化的 ReactFlow
- i18next 支持 11 种语言的本地化
后端堆栈:
-
Python 3.10+ 带 Flask (ragflow_server.py)
-
支持 MySQL/PostgreSQL 的 SQLAlchemy ORM
-
用于缓存和任务队列的 Redis
-
基于 Asyncio 的后台处理 (task_executor.py)
存储后端:
-
矢量搜索 :DOC_ENGINE 可配置(Elasticsearch/Infinity/OpenSearch)
-
对象存储 :MinIO(兼容 S3)、Azure Blob、阿里云 OSS
-
元数据 :具有可配置连接池的 MySQL
-
缓存 :具有会话管理的 Redis
集成点和 API
RAGFlow 公开了多个集成接口,以支持不同的使用模式:
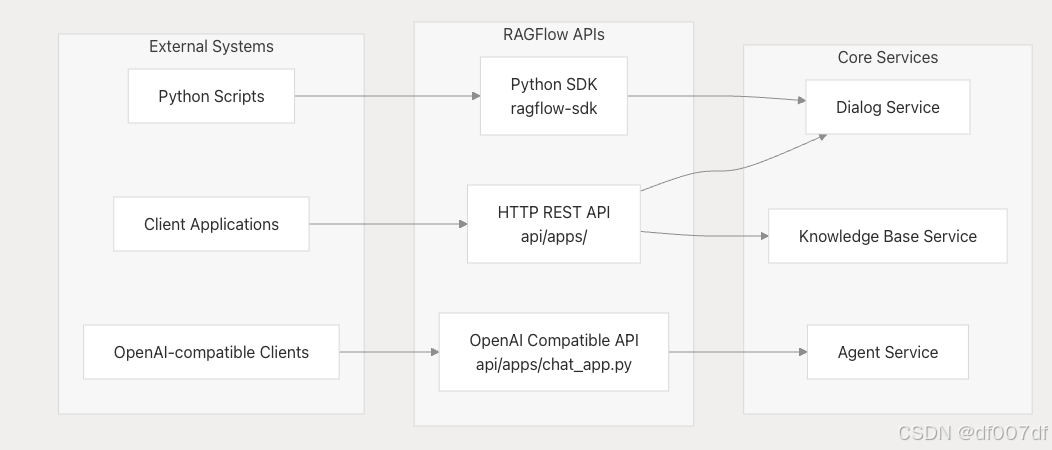
API 端点:
- 知识库管理:api/apps/dataset_app.py
- 文档作:api/apps/document_app.py
- 聊天对话:api/apps/conversation_app.py
- 代理工作流:api/apps/agent_app.py
身份验证和安全:
- 用于编程访问的基于 API 密钥的身份验证
- 对第三方身份验证提供程序的 OAuth2 支持
- 基于团队的访问控制和资源共享