【Day 30】Linux-Mysql数据库
一、Mysql
(一)Mysql安装
1、Mysql版本
MySQL 的归属经历了三次重要变更:最初由 MySQL AB 公司开发运营,后被 Sun 公司收购;2009 年,Sun 公司又被 Oracle 公司收购,自此 MySQL 归入 Oracle 旗下。
MySQL 5.5:2010 年发布,首次将 InnoDB 设为默认存储引擎,支持半同步复制,优化了 InnoDB 性能,为企业级应用打下基础。
MySQL 5.6:2013 年发布,引入 GTID 简化主从复制配置,提升 InnoDB 并发能力,支持 InnoDB 全文索引和慢查询日志微秒级计时,强化高可用与性能。
MySQL 5.7:2015 年发布,支持原生 JSON 类型、透明页压缩、增强半同步复制等,优化 Performance Schema 减少内存使用,新实例不再默认创建 test 数据库及匿名用户等。
MySQL 8.0:2018 年正式发布,引入原生数据字典,重构 INFORMATION_SCHEMA,支持降序索引、公用表表达式、资源组等,默认字符集改为 utf8mb4 等。
MySQL 9.0.0:2024 年 7 月发布,新增 JavaScript 存储程序、VECTOR 类型支持、内联和隐式外键约束等诸多新功能。
MySQL 9.2.0:最新记录显示于 2025 年 1 月发布,扩展 JavaScript 相关支持,像添加 JavaScript 事务 API、JavaScript ENUM 和 SET 支持等。
2、安装过程
(1)从 MySQL 官方下载并安装适用于 EL7(CentOS 7/RHEL 7)系统的 YUM 源配置包
//浏览器搜索

//选择适合版本复制
![]()
//该 RPM 包的核心功能是添加 MySQL 官方的 YUM 仓库配置
//使用rpm -ivh命令,粘贴,回车。将刚刚复制的rpm包安装上。

///etc/yum.repos.d/目录是包管理器用于存储软件仓库配置文件的目录,执行成功后会在此目录下生成 MySQL 相关的 repo 文件。

(2)通过 yum 安装 MySQL。

//确认软件安装
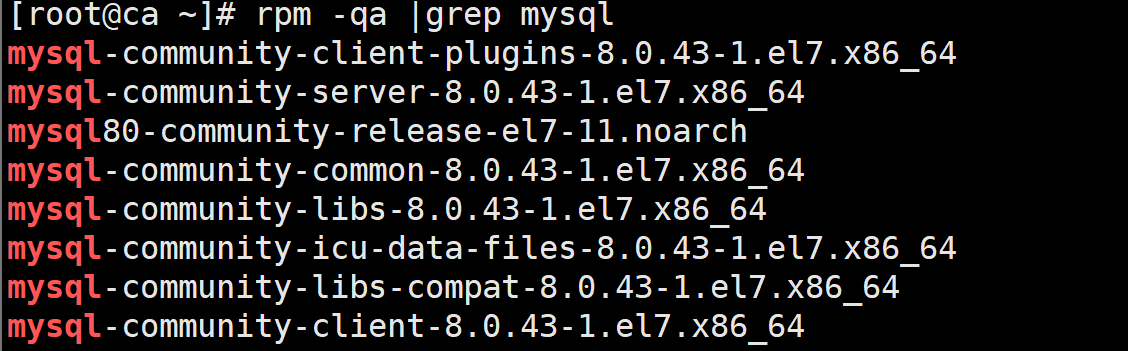
(3)启动服务并确认

//启动 MySQL 服务时,首次启动会自动完成数据库初始化,具体包括:
创建系统数据库:自动生成核心系统数据库及表结构。
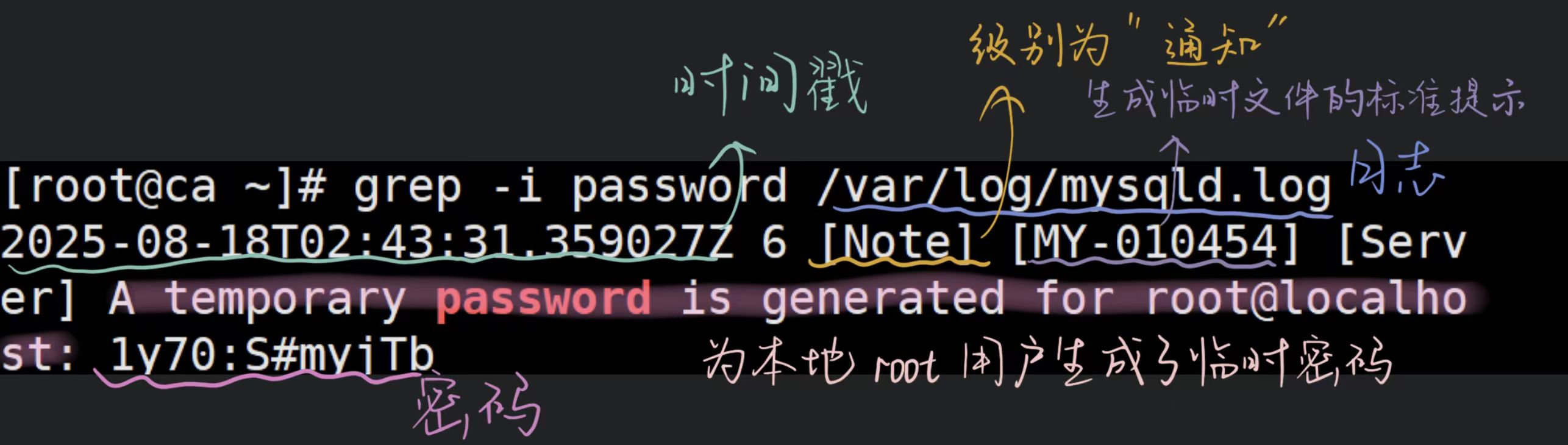
生成初始密码:为 root@localhost 生成随机临时密码,记录在 /var/log/mysqld.log 中。
初始化权限表:设置默认的用户权限、访问控制规则等基础安全配置。
创建必要目录:如数据目录、日志目录等,并设置正确的权限。
若是破坏了 MySQL 判断 “已初始化” 的依据(关键文件 / 目录存在性),导致服务启动时,会重新执行初始化流程。
- 触发初始化的例子:删除数据目录中的关键初始化文件、手动清空数据目录、首次安装后首次启动、使用 --initialize 或 --initialize-insecure 参数强制重新初始化(覆盖现有数据)、修改配置文件中数据目录路径为新空目录且新路径无初始化文件时。
(4)查看临时密码
//MySQL 5.7 及以上版本(包括正在安装的 MySQL 8.0)在首次启动时,会自动为 root 用户生成一个随机初始密码,并记录在日志文件中
(5)修改root密码。输入临时密码-修改新密码
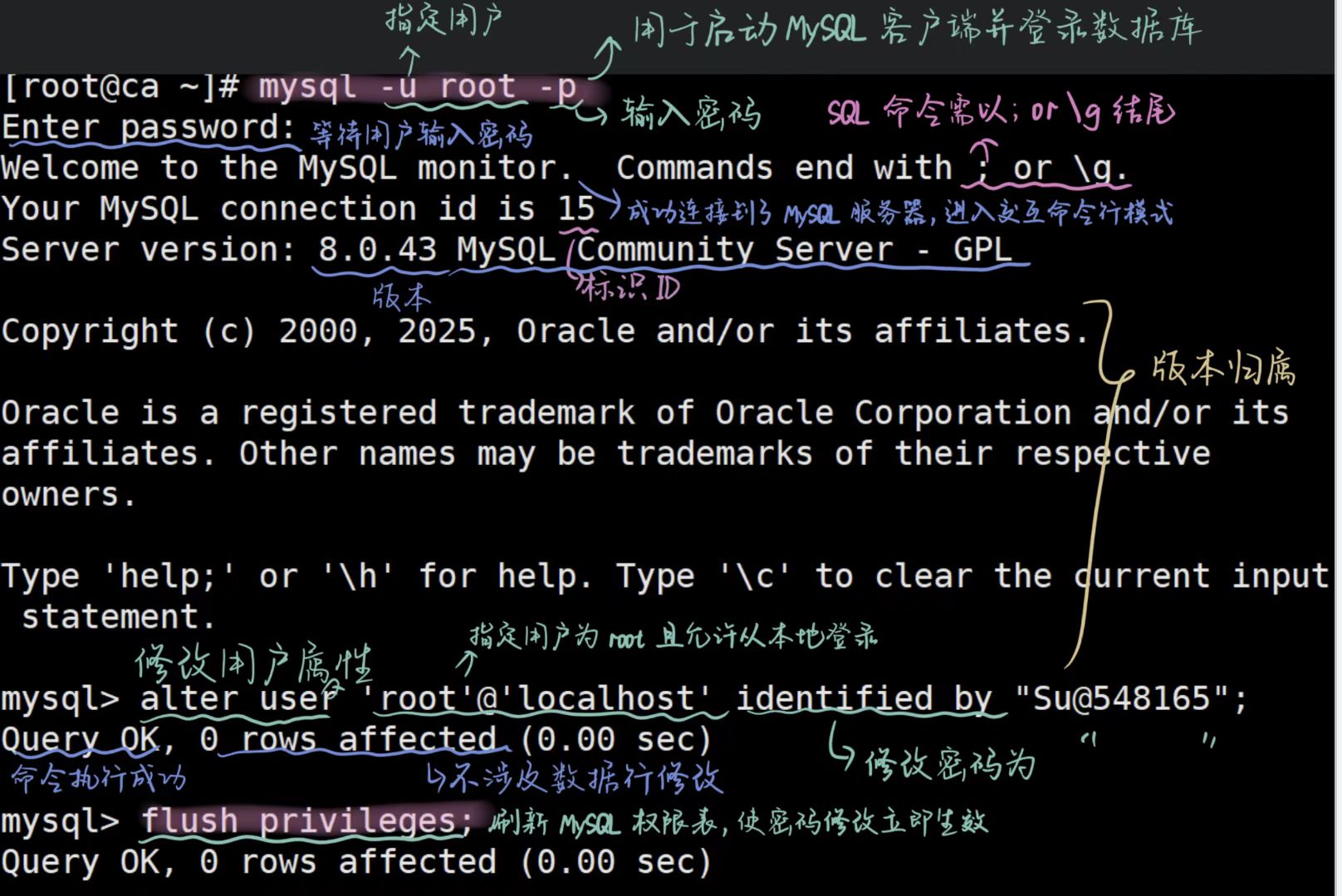
//MySQL(尤其是 5.7 及以上版本)默认启用了密码复杂度验证插件(validate_password)。
当插件件启用时,密码需满足:长度至少 8 字符、包含大写字母 、小写字母 、数字、特殊字符。
3、主要相关文件
/etc/my.cnf
// MySQL 的默认配置文件。当 MySQL 服务启动时,会优先读取此文件中的配置。
[mysqld] 段:所有 MySQL 服务器(mysqld 进程)相关的配置都需放在这个 section 下,确保参数被正确加载。
- port=3306 // 默认端口;
- character-set-server=utf8mb4
- max_connections=100

- socket:套接字文件。接收本地访问请求。仅用于同一台服务器上的客户端与服务器通信,不支持跨机器连接(远程程连接需用 TCP/IP 端口 3306)。本质是一个特殊的文件。
- 与 MySQL 相关的套接字文件:
- mysql.sock:实际用于通信的套接字文件,客户端通过读写此文件与服务器交换数据。
- mysql.sock.lock:套接字文件的锁文件,用于防止多个进程同时创建或修改 mysql.sock,确保通信唯一性。
修改配置前需停止服务,修改配置后需重启 MySQL 服务(systemctl restart mysqld)才能生效。
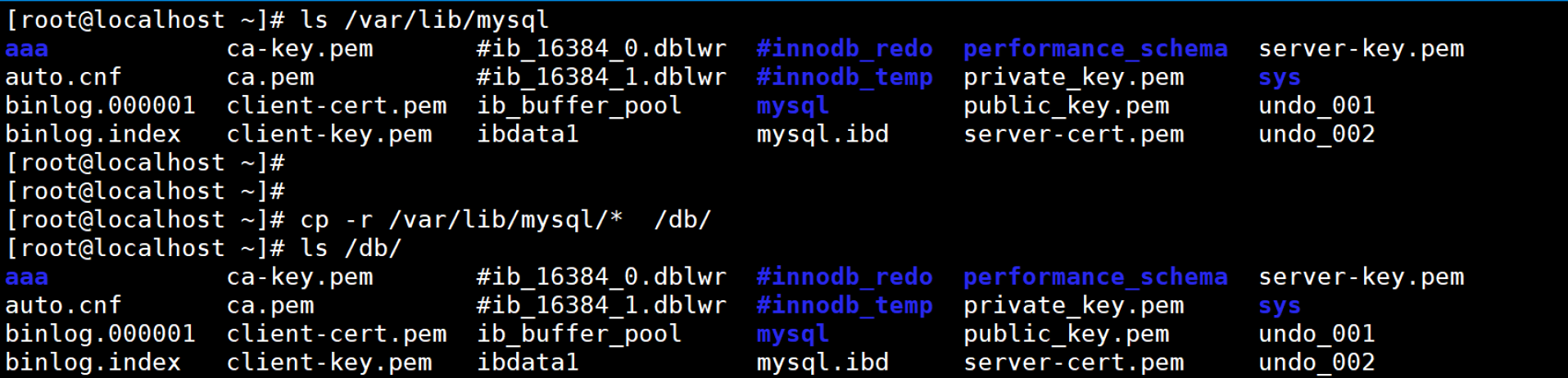
(1)更换存储目录且不需要旧的存储目录


(2)更换存储目录,仍需旧存储目录
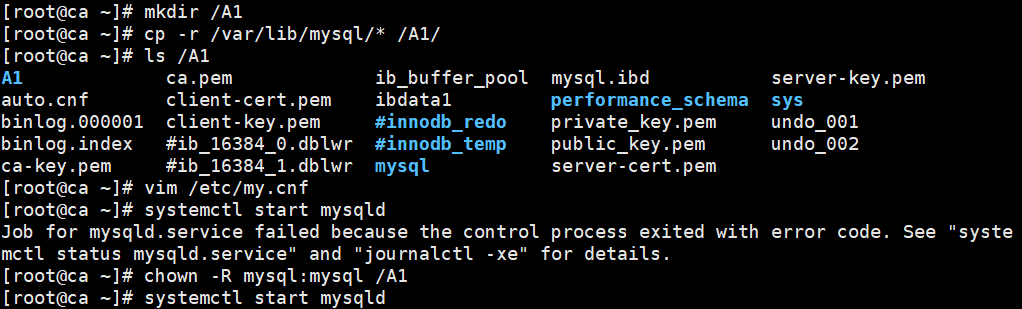
//注意一定要是 cp -r /旧目录/* /新目录/
若是修改配置文件后,未复制旧目录就启动了。需要将启动后新目录中自动生成的初始化文件删掉后,再复制。
(3)修改套接字文件

若改为/A1/mysql.sock
![]()
 配置文件指定的 socket 路径(socket=/A1/mysql.sock)与默认连接的 socket 路径(/var/lib/mysql/mysql.sock)不同。
配置文件指定的 socket 路径(socket=/A1/mysql.sock)与默认连接的 socket 路径(/var/lib/mysql/mysql.sock)不同。
(1)临时解决
![]()
(2)永久解决
- vim /etc/my.cnf //添加


/var/lib/mysql
// MySQL 的默认数据存储目录,所有数据库、表、索引、权限等核心数据都存储在此处。

- 每个数据库会在此目录下生成一个同名子目录,目录内包含该数据库的表文件。。
- 权限要求严格:通常属主为
mysql:mysql,普通用户无读写权限,避免数据被误修改或删除。 - 若需迁移数据,需严格复制此目录(需停止服务,确保数据一致性)。

/var/log/mysqld.log
// MySQL 服务的主要日志文件,记录服务器启动 / 关闭、错误信息、警告、连接日志等关键事件。
4、系统数据库
MySQL 首次启动初始化生成
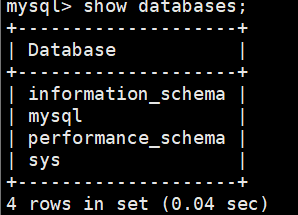
| 核心作用: | 存储内容: | |
(信息数据库) | 提供 MySQL 服务器的 “元数据目录”,即数据库自身的结构信息。 |
|
(系统权限数据库) | 存储 MySQL 服务器的用户管理和权限控制核心数据。 |
|
(性能监控数据库) | 实时监控 MySQL 服务器的运行状态,保存数据服务器性能相关的数据。 |
|
(简化诊断数据库) | 基于
的 “简化视图库”,降低性能分析门槛,方便数据库管理员查看。 |
|
(二)SQL语句
| 简称 | 全称 | 核心命令 | 主要功能 | 操作对象 / 影响范围 |
|---|---|---|---|---|
| DQL | 数据查询语言 | SELECT | 从数据库中查询数据(仅读取,不修改) | 表中的记录(返回查询结果集) |
| DML | 数据操作语言 |
| 新增、修改、删除表中的记录 | 表中的具体数据 |
| DDL | 数据定义语言 | CREATE、ALTER、DROP、TRUNCATE | 创建、修改、删除数据库对象;清空表数据 | 数据库结构 |
| DCL | 数据控制语言 | GRANT、REVOKE | 授予或收回用户对数据库对象的操作权限 | 用户权限 |
| TCL | 事务控制语言 | COMMIT、ROLLBACK、SAVEPOINT | 管理事务,确保操作的原子性、一致性等 | 事务 |
1、库
- > show databases; //查看数据库
- > create database 数据库名称; //创建数据库。
MySQL 8.0默认使用的字符集utf8,支持存储中文

//MySQL 5.7默认使用的字符集是latin,不支持存储中文;可在创建数据库时通过选项charset指定字符集为utf8,方便在表中存储中文

- > drop database 数据库名称; //删除数据库

2、表
- >use 数据库; //切换数据库
- >show tables; //查看所有表
- >desc 表名 //查看表结构
- 创建表

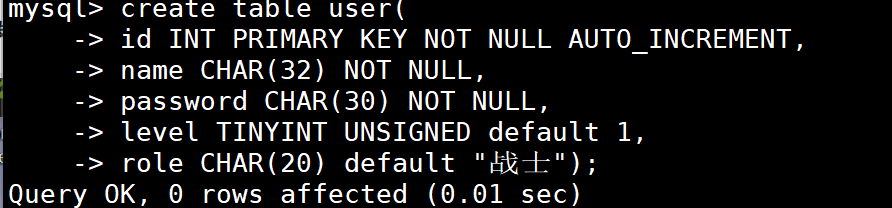
- >drop table 表名 ; //删除表
- >insert into 表名(字段1,字段2,...) values (值1,值2,...);
- >select * from 表名
- >update 表名 set 字段名=新数据 where条件
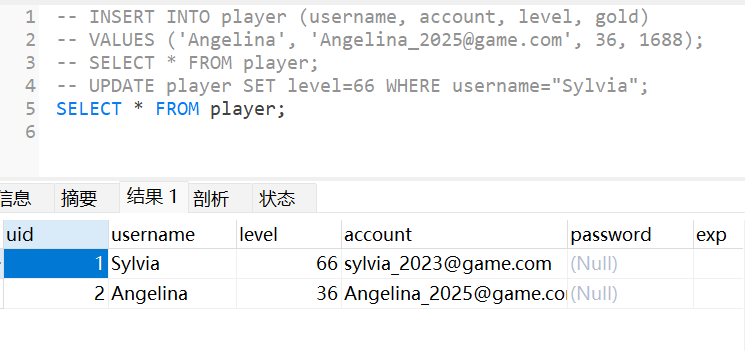
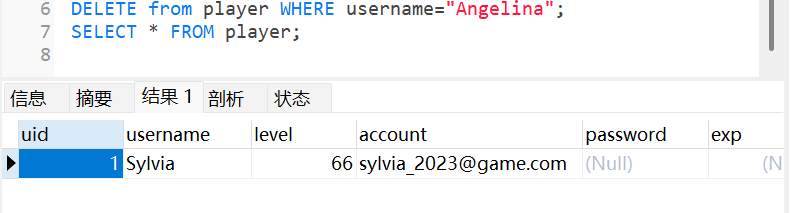
- >delete from 表名 where 条件
(1)数据类型(常用)
- 数值型
| 类型 | 存储大小 | 有效数字 / 范围 | 适用场景 | 精度损失 |
|---|---|---|---|---|
| 整数类型 | ||||
| TINYINT | 1 字节 | 范围:-128 ~ 127(有符号);0 ~ 255(无符号) | 小范围整数 | 无 |
| SMALLINT | 2 字节 | 范围:-32768 ~ 32767(有符号) | 中等范围整数(如班级人数) | 无 |
| INT | 4 字节 | 范围:-2^31 ~ 2^31-1 | 常用整数(用户 ID、年龄) | 无 |
| BIGINT | 8 字节 | 范围:-2^63 ~ 2^63-1 | 超大整数(订单号、海量数据 ID) | 无 |
| 浮点数 / 定点数 | ||||
| FLOAT | 4 字节 | 6-7 位有效数字,范围 ±3.4×10^38 | 精度要求低的小数(如温度) | 有 |
| DOUBLE | 8 字节 | 15-17 位有效数字,范围 ±1.8×10^308 | 较高精度的科学计算(如坐标) | 有 |
| DECIMAL(M,D) | 可变(M+2 字节) | M 为总位数(1-65) D 为小数位数(0-D) | 金额、汇率等需精确计算场景 (如 | 无 |
- 字符型
| 类型 | 存储特点 | 最大长度限制 | 适用场景 |
|---|---|---|---|
| VARCHAR(N) | 可变长度 (按需分配空间) | N 为字符数(最大 65535 字节,受行总长度限制) | 长度不固定的字符串(如姓名、地址) |
| CHAR(N) | 固定长度 占用 N 字符空间 | N 为字符数(最大 255) | 长度固定的字符串(如身份证号、手机号) |
| TEXT | 长文本 存储在独立空间 | 最大 65535 字节(约 64KB) | 较长文本(如文章摘要、备注) |
| LONGTEXT | 超长文本 | 最大 4GB | 极长文本(如全文、日志) |
- 日期型:
| 类型 | 格式示例 | 范围 | 适用场景 |
|---|---|---|---|
| DATE | 2025-8-18 | 1000-01-01 ~ 9999-12-31 | 仅需日期(如出生日期) |
| TIME | 11:11:11 | -838:59:59 ~ 838:59:59 | 仅需时间(如上下班时间) |
| DATETIME | 2025-8-18 11:11:11 | 1000-01-01 00:00:00 ~ 9999-12-31 23:59:59 | 日期 + 时间(如订单创建时间) |
- 其他:
| 类型 | 特点与取值 | 适用场景 |
|---|---|---|
| BOOLEAN | 等价于TINTINT(1) TRUE,FALSE=0 | 逻辑判断(如是否启用:1 = 是,0 = 否) |
| ENUM | 枚举值(如ENUM('男','女','沃尔玛购物袋')) | 固定可选值的场景(如性别、状态) |
| SET | 多选项(如SET('钢琴','长笛','竖琴')) | 多选场景(如用户兴趣标签) |
(2) 常用属性 / 约束(字段级)
约束 / 属性 | 作用说明 | 示例 |
|---|---|---|
NOT NULL | 字段值不能为NULL(强制必填) |
|
PRIMARY KEY | 设为主键(唯一标识一条记录,自带NOT NULL属性,一个表只能有一个主键) |
|
AUTO_INCREMENT | 数值自动递增(仅用于整数类型,配合主键使用,避免手动插入重复值) |
|
DEFAULT 值 | 未显式插入值时,自动填充默认值 |
|
UNIQUE | 字段值唯一(允许NULL,但非NULL值不能重复,可用于唯一标识非主键字段) |
|
COMMENT ' 说明' | 字段注释(用于说明字段含义,方便后期维护和协作) |
|
CHECK (条件) | 限制字段值必须满足指定条件(MySQL 8.0 + 支持,确保数据合法性) |
|
FOREIGN KEY | 关联其他表的主键(字段级外键) |
|
UNSIGNED | 仅用于整数类型,限制字段值为非负数 |
|
ZEROFILL | 整数类型专用,不足位数时用 0 填充 |
|
(3)表级约束(多字段关联)
- 复合主键:多个字段组合唯一标识记录
PRIMARY KEY (字段1, 字段2) - 外键关联:关联其他表的主键
FOREIGN KEY (字段) REFERENCES 主表名(主表字段)
(4)表选项(常用)
ENGINE = 存储引擎:如InnoDB(支持事务)、MyISAM(查询快)CHARSET = 字符集:如utf8mb4(支持中文和 emoji)
3、单表查询

(1)基础查询(SELECT)
// 选择表中的列
SELECT 列名1, 列名2, ... FROM 表名; //选择指定列
SELECT * FROM 表名; // 选择所有列(*)
SELECT DISTINCT 列名 FROM 表名; // DISTINCT去重,去除重复行
SELECT DISTINCT gender, age FROM student; //根据多列的组合去重
//DISTINCT必须放在所有列名之前,且若指定多列,会
(2)条件查询(WHERE)
// 筛选符合条件的行
①比较运算符
=(等于)、<>/!=(不等于)、>(大于)、<(小于)、>=(大于等于)、<=(小于等于)
SELECT name, age FROM student WHERE age > 18; //查询student表中age>18 的学生。
②逻辑运算符
AND(与)、OR(或)、NOT(非)。
- SELECT name, age, score FROM student WHERE age > 18 AND score > 80;
- //查询年龄大于 18 且分数大于 80 的学生
- SELECT name, age FROM student WHERE NOT (age BETWEEN 18 AND 22);
- //查询查询年龄不在 18-22 之间的学生
③范围查询(BETWEEN...AND...)
// 筛选某个范围内的值(闭区间,包含两端值)
- SELECT name, score FROM student WHERE score BETWEEN 80 AND 100;
- //查询分数在 80 到 100 之间的学生
④集合查询(IN / NOT IN)
// IN用于筛选 “值在指定集合中” 的行;NOT IN 则相反。
- SELECT name, age FROM student WHERE age IN (18, 20, 22);
- SELECT name, age FROM student WHERE age NOT IN (18, 20, 22);
- //年龄为/不为18、20、22 的学生
⑤模糊查询(LIKE / NOT LIKE)
// 用于字符串的模糊匹配,需配合通配符:
%:匹配任意多个字符(包括 0 个);_:匹配单个字符。- SELECT name FROM student WHERE name LIKE '张%'; //查询姓名以 “张” 开头的学生
- SELECT name FROM student WHERE name NOT LIKE '%李%'; //姓名中不含 “李” 的学生
- SELECT name FROM student WHERE name LIKE '_子%'; //姓名第二个字是 “子” 的学生
⑥空值查询(IS NULL / IS NOT NULL)
// NULL 表示 “未知”(非空字符串或 0),需用 IS 判断,不能用 = 或 != 判断。
- SELECT name, score FROM student WHERE score IS NULL;
- SELECT name, score FROM student WHERE score IS NOT NULL;
//查询student表内score为null/不为null的学生名
(3)排序查询
// 对查询结果排序
SELECT 列名 FROM 表名 ORDER BY 排序列1 [ASC|DESC], 排序列2 [ASC|DESC];
ASC :升序(默认,可省略);
DESC :降序;
支持多列排序(先按第一列排,第一列相同则按第二列排)。
SELECT name, age, score FROM student ORDER BY age DESC, score ASC;
//按年龄降序排列,年龄相同则按分数升序排列。
SELECT 列名 FROM 表名 LIMIT n; //返回前n行。
SELECT 列名 FROM 表名 LIMIT m, n; //从第m行(索引从0开始)起,返回n行
SELECT name, age FROM student ORDERBY age DESC LIMIT 2, 1; //年龄第三
(4)聚合查询
函数 | 作用 |
|---|---|
COUNT(字段) | 统计行数(非 NULL 值数量) |
SUM(字段) | 计算列的总和(仅数值型) |
AVG(字段) | 计算列的平均值(仅数值型) |
MAX(字段) | 求列的最大值 |
MIN(字段) | 求列的最小值 |
- COUNT(*):统计所有行数(包括 NULL 值);
- COUNT(字段名):统计该列非 NULL 值的行数;
- COUNT(DISTINCT 字段名):统计该列非 NULL 且不重复的值的行数。
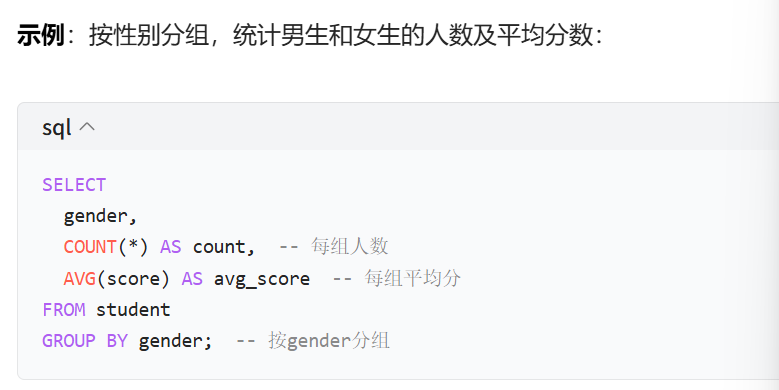
(5)分组查询
// 当需要按某个列 分组统计时,使用GROUP BY分组后,聚合函数会对每个组单独计算。
- SELECT 分组列, 聚合函数 FROM 表名 GROUP BY 分组列;
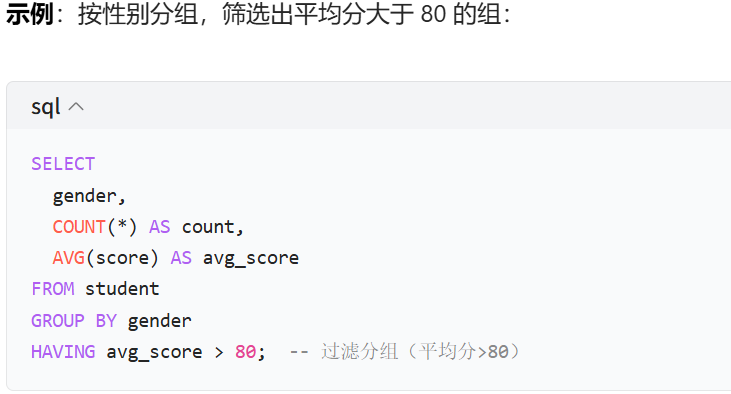
- HAVING用于过滤分组后的结果(需配合GROUP BY使用),且HAVING可使用聚合函数。

4、多表查询(关联查询)
(1)交叉连接(Cross Join):笛卡尔积
- 原理:将两张表的所有记录两两组合,结果行数 = 表 1 行数 × 表 2 行数。

(2)内连接(Inner Join):匹配关联记录
- 原理:只返回两张表中满足关联条件的记录(即外键值在主表中存在的记录)。

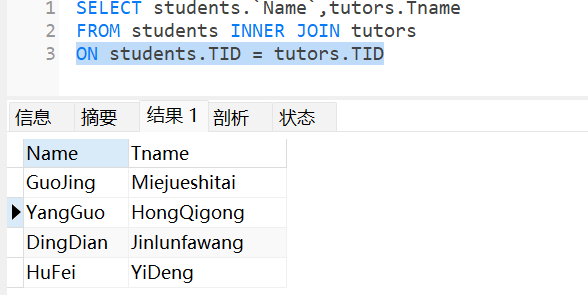
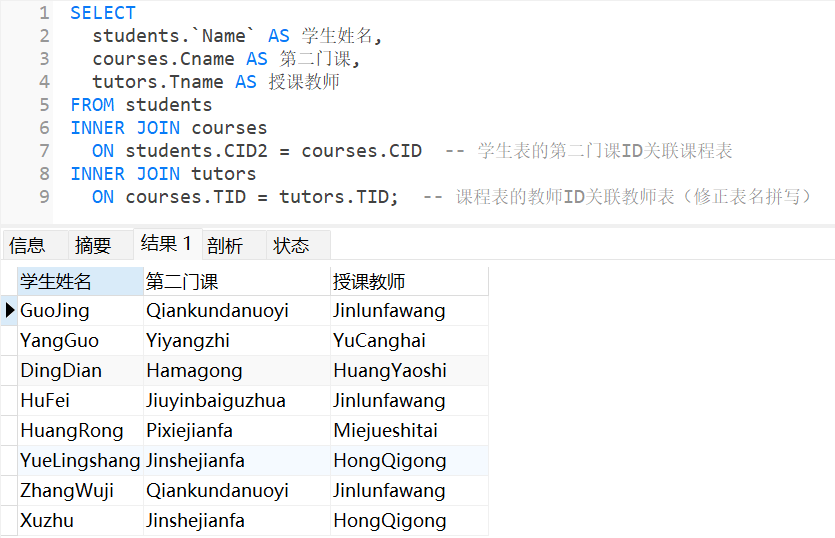
- 特点:只返回匹配的记录,不匹配的记录会被过滤掉。
(3) 外连接(Outer Join):保留不匹配的记录
外连接会保留其中一张表的所有记录,另一张表中不匹配的记录用NULL 填充。分为以下三种:
①左外连接(Left Outer Join)
- 原理:保留左表(JOIN 左侧的表)的所有记录,右表中不匹配的记录用NULL 填充语法:

②右外连接(Right Outer Join)
- 原理:保留右表(JOIN 右侧的表)的所有记录,左表中不匹配的记录用NULL 填充。

5、子查询
- 定义:子查询是一个独立的SELECT语句,嵌套在另一个 SQL 语句的WHERE,FHAVING等子句中。



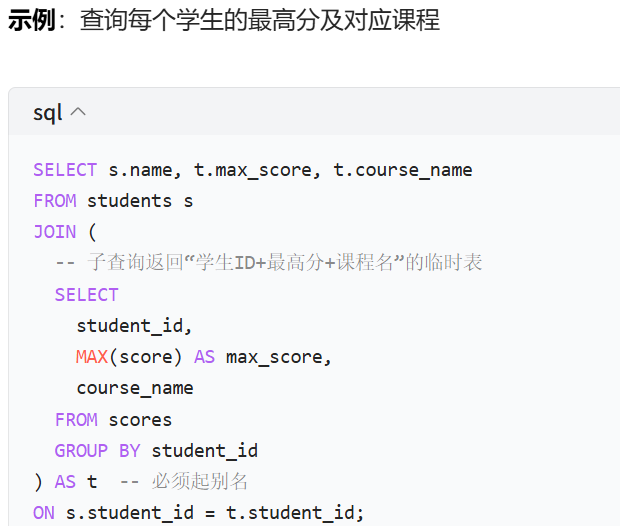
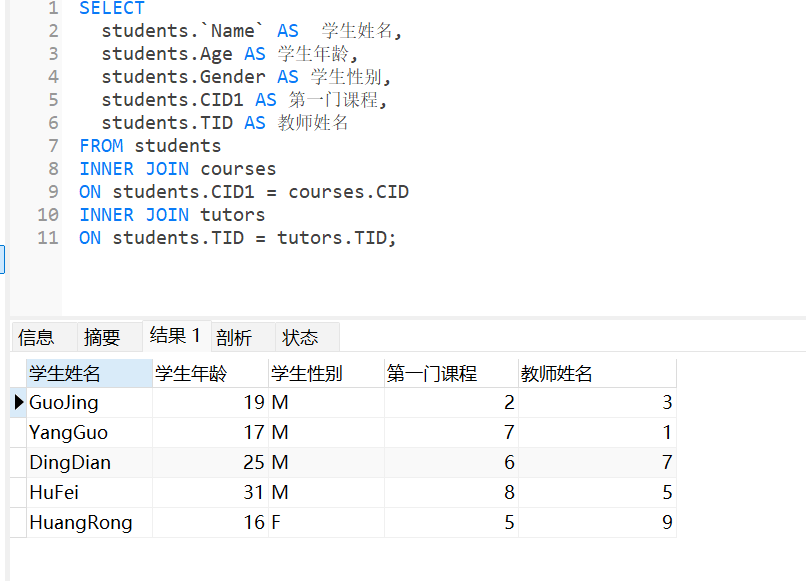
练习题
练习题 1:查询每个学生的基本信息、所选第一门课的名称及授课教师
练习题 2:查询每个教师的基本信息、所教课程中平均分最高的课程名称及该课程的学生

练习题3
练习题 3:查询所有选了 “数据库原理” 课程的学生姓名、该课程成绩、授课教师姓名及学生的指导教师姓名
- 表关联:
students(SID、Name、TID(指导教师 ID))、scores(SID、CID、Score)、courses(CID、Cname、TID(授课教师 ID))、tutors(TID、Tname)。 - 说明:需区分 “授课教师”(教该课程的老师)和 “指导教师”(学生的专属指导老师),两个
TID分别关联教师表。 - 提示:给教师表起两个别名(如
t1代表授课教师,t2代表指导教师),分别关联课程表和学生表。
练习题 4:查询每个班级(假设学生表有class_id字段)中年龄最小的学生姓名、班级编号、该学生所选所有课程的名称及对应成绩
- 表关联:
students(SID、Name、Age、class_id)、scores(SID、CID、Score)、courses(CID、Cname)。 - 说明:先按班级分组,找到每个班级中年龄最小的学生(可能有多个,用
MIN(Age)筛选),再查询该学生的所有选课记录。 - 提示:用子查询筛选每个班级的最小年龄学生 ID,再关联成绩表和课程表。
练习题 5:查询没有选任何课程的学生姓名、年龄及指导教师姓名(若有)
- 表关联:
students(SID、Name、Age、TID)、tutors(TID、Tname)、scores(SID)。 - 说明:“没有选任何课程” 即
students.SID在scores表中无匹配记录。 - 提示:用
LEFT JOIN关联学生表和成绩表,通过scores.SID IS NULL筛选无选课记录的学生,再关联教师表获取指导教师。
(三)连接图形化工具
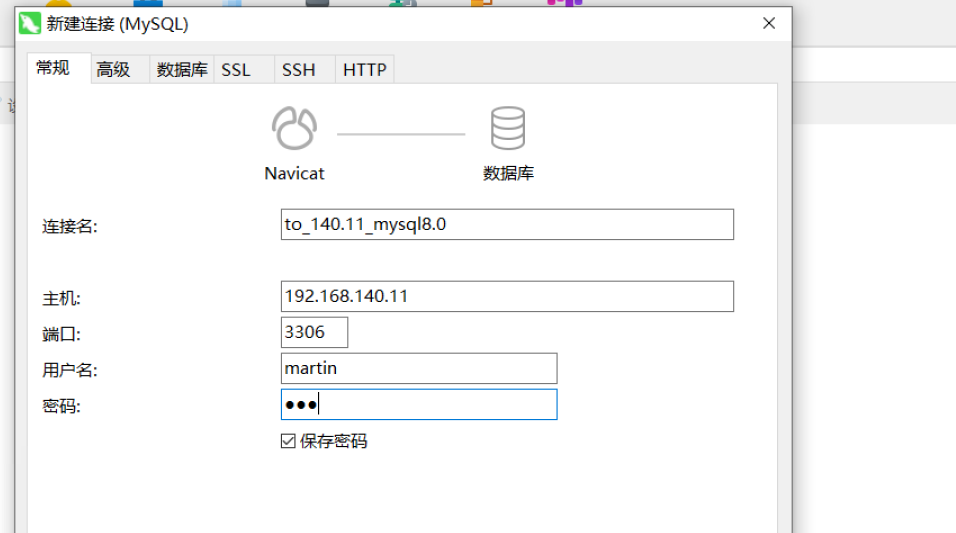
点击变绿就是可以正常使用了。
1、新建库
2、新建表
3、新建字段

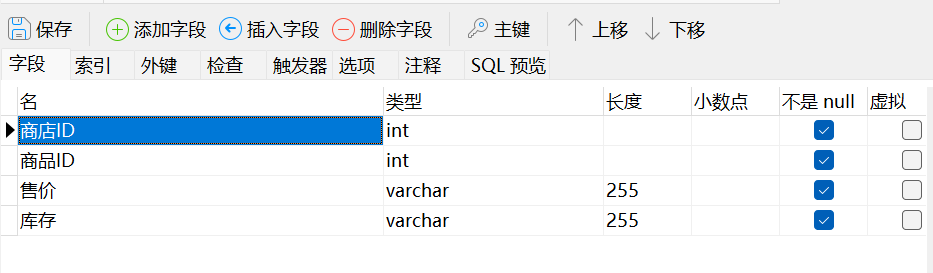
4、外键使用

5、新建记录

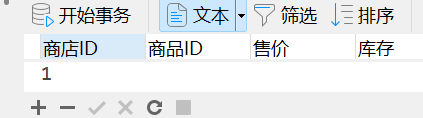
6、查询添加
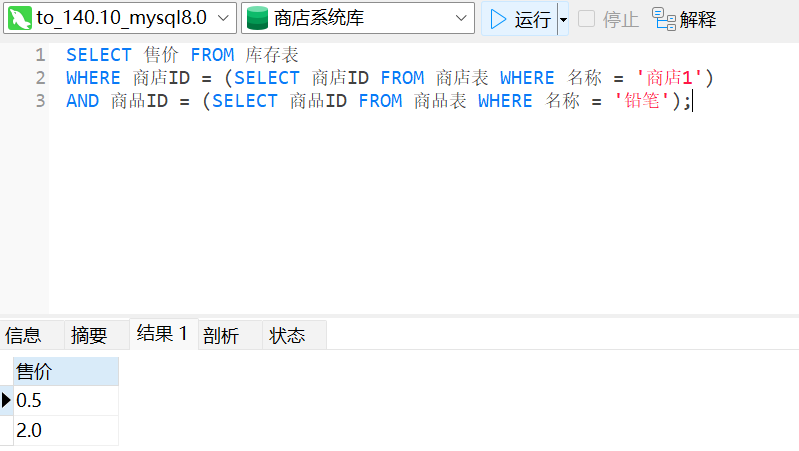
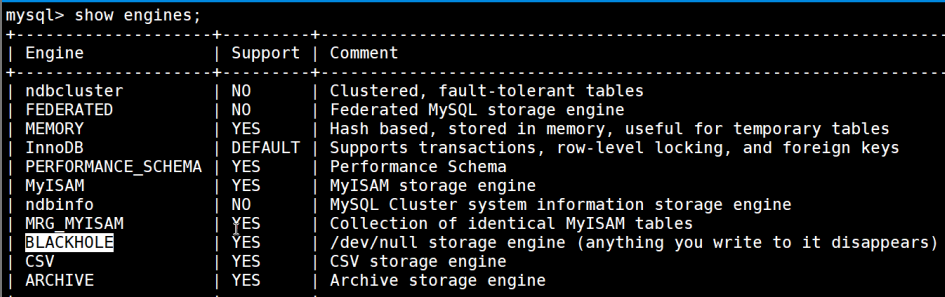
(四)存储引擎
MySQL 的存储引擎是负责数据存储、检索和管理的核心组件。
1. InnoDB(默认存储引擎)
- 核心特性:支持事务(ACID 特性)、行级锁、外键约束,具备崩溃恢复能力(依赖 redo/undo 日志),采用聚簇索引提升查询效率。
- 适用场景:需要事务保障(如电商订单、金融交易)、高并发读写、数据完整性要求高的业务。
事务(Transaction) :由一系列数据库操作(如查询、插入、更新、删除等)组成的不可分割的逻辑工作单元。简单来说,事务要么完整地执行所有操作,要么在某个操作失败时,所有操作都回滚到初始状态,以此保证数据的一致性和完整性。
2. MyISAM
- 核心特性:不支持事务和外键,仅表级锁,查询速度快,占用资源少,支持全文索引(早期版本)。
- 适用场景:读多写少、无事务需求的静态数据场景(如日志分析、报表系统)。
3.Memory(Heap)
- 核心特性:数据存于内存,读写速度极快,但服务器重启后数据丢失,支持哈希索引,表级锁。
- 适用场景:临时数据缓存(如会话数据、临时计算结果)、高频访问且可丢失的数据。
4. Archive
- 核心特性:专为归档设计,压缩率高,仅支持插入和查询(不支持更新 / 删除),无索引(除自增 ID)。
- 适用场景:大量历史数据归档(如用户行为日志、系统日志)。
修改存储引擎

- show create table user; //返回表的创建语句,包括表结构、字段类型、索引、存储引擎等
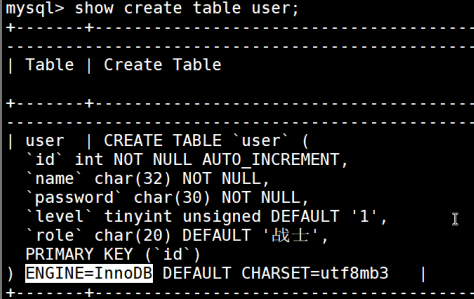
| 存储引擎 | 表结构文件 | 数据文件 | 索引文件 | 文件存储特点 |
|---|---|---|---|---|
| MyISAM | .sdi | .myd | .myi | 1. 表结构、数据、索引完全分离为 3 个独立文件 2. 所有文件在数据目录中直接可见 3. .sdi单独存储表结构定义 |
| InnoDB | 嵌入在.ibd 文件中(无独立文件 ) | .ibd | 嵌入在.ibd文件中(无独立文件 ) | 1. 数据和索引整合存储在.ibd 中 2. 表结构元数据嵌入.ibd 内部,不生成独立 .sdi 文件 3. 仅 .ibd 在数据目录中可见 |