基于 ONNX Runtime 的 YOLOv8 高性能 C++ 推理实现
目录
一、项目背景
二、代码讲解
1. inference.cpp注释版代码:
2. inference.cpp代码框架讲解:
(1)整体思路(管线)
(2)文件头与杂项
(3)BlobFromImage(Mat → NCHW 浮点数组)
(4)PreProcess(根据模型类型做图像预处理)
(5)CreateSession(会话创建与参数)
(6)RunSession(一次完整推理)
(7)TensorProcess(核心:Run + 解码输出)
(8)WarmUpSession(预热)
(9)关键参数/结构
一、项目背景
本文介绍的项目基于 ONNX Runtime 和 OpenCV,实现了一个轻量、高效、可扩展的 YOLOv8 C++ 推理模块。它不依赖 PyTorch,可直接加载 .onnx 模型进行推理,适用于 Windows/Linux 平台,支持 CPU 与 CUDA 加速。
项目有三个文件:inference.h,inference.cpp和main.cpp,核心文件为 inference.cpp。
二、代码讲解
1. inference.cpp注释版代码:
2. inference.cpp代码框架讲解:
(1)整体思路
-
CreateSession:加载 ONNX 模型 → 创建
Ort::Session(可选 CUDA)→ 记录输入/输出节点名 → 预热一次。 -
RunSession:对输入图像做预处理(按模型种类)→ 组装 NCHW 的输入张量 → 推理 → 按模型类型做后处理(目标框/NMS 或 分类)。
-
WarmUpSession:构造一张空图,走一遍预处理+推理,避免首次调用慢。
-
其余是工具函数/模板:
BlobFromImage把cv::Mat转为连续内存(按通道排布),TensorProcess模板负责真正的session->Run和解析输出。
(2)文件头与杂项
-
#define benchmark:打开后会打印前处理、推理、后处理耗时。 -
#define min(a,b):自定义了一个min宏(不建议,容易和std::min冲突)。 -
构/析:构造函数空;析构里只
delete session;(注意:没释放输入/输出节点名的new char[],有内存泄露,下文详述)。 -
FP16 支持(仅在
USE_CUDA下)template<> struct TypeToTensorType<half> { ... };让 ORT 能识别
half类型建张量。
(3)BlobFromImage(Mat → NCHW 浮点数组)
template<typename T>
char* BlobFromImage(cv::Mat& iImg, T& iBlob)
-
输入:BGR/RGB 的
cv::Mat(8UC3)。 -
输出:把像素按 通道优先 NCHW 排列到一段连续内存
iBlob(在外面new出来的)。 -
逐像素取值 /255.0f 归一化;不做减均值/除方差。
-
注意:使用
iImg.at<cv::Vec3b>(h,w)[c],默认假定图像是 8bit 3 通道;理论上传灰度图会越界,不过在PreProcess里已经统一成 3 通道 RGB。
(4)PreProcess(根据模型类型做图像预处理)
char* YOLO_V8::PreProcess(cv::Mat& iImg, std::vector<int> iImgSize, cv::Mat& oImg)
-
先保证输入为 RGB:BGR→RGB;灰度→RGB。
-
分两类:
-
检测/姿态(
YOLO_DETECT_V8、YOLO_POSE,以及它们的 FP16 版本)-
计算
resizeScales = 原边/目标边,按长边对齐缩放:-
若宽≥高:目标宽=
iImgSize[0],高按比例;反之相同。
-
-
然后把缩放后的图复制到一个 全 0 的大图(
iImgSize[0]×iImgSize[1])的左上角(0,0)。-
这相当于 Letterbox,但只在右边或下边补零(不是居中)。后处理时按同一
resizeScales去恢复坐标。
-
-
-
分类(
YOLO_CLS)-
CenterCrop:从中间裁一个正方形(边长=min(h,w)),再缩放到
iImgSize。
-
-
很多实现会把 Letterbox 居中,这里是 左上角对齐,对应地后处理没有加偏移,只乘了
resizeScales,保持了一致。
(5)CreateSession(会话创建与参数)
char* YOLO_V8::CreateSession(DL_INIT_PARAM& iParams)
-
校验 模型路径不能含中文(用正则查
[\u4e00-\u9fa5])。 -
记录阈值、输入尺寸、模型类型、是否启用 CUDA、线程数、日志等级等。
-
Ort::Env+Ort::SessionOptions:-
若
cudaEnable==true:设置OrtCUDAProviderOptions。 -
SetGraphOptimizationLevel(ORT_ENABLE_ALL)。 -
SetIntraOpNumThreads(...)。
-
-
Windows 下把 utf-8 路径转宽字符;非 Windows 直接用
char*。 -
session = new Ort::Session(env, modelPath, sessionOption); -
获取 I/O 节点名:调用
GetInputNameAllocated/GetOutputNameAllocated,拷贝到new char[]再push_back保存。 -
WarmUpSession()预热。 -
发生异常会返回统一的错误文本。
(6)RunSession(一次完整推理)
char* YOLO_V8::RunSession(cv::Mat& iImg, std::vector<DL_RESULT>& oResult)
-
计时(可选)。
-
PreProcess得到processedImg。 -
根据
modelType选择 FP32 或(在USE_CUDA编译时)FP16 的blob:-
inputNodeDims = {1, 3, imgH, imgW}(NCHW)。
-
-
调
TensorProcess(...)执行推理与后处理。
如果把
modelType设到 FP16 路径,但工程没有定义USE_CUDA,这段代码不会给出替代逻辑(编译能过,但不会走 FP16 分支),要保证两者匹配。
(7)TensorProcess(核心:Run + 解码输出)
template<typename N>
char* YOLO_V8::TensorProcess(clock_t& starttime_1, cv::Mat& iImg, N& blob,std::vector<int64_t>& inputNodeDims, std::vector<DL_RESULT>& oResult)
-
创建输入张量:
Ort::Value::CreateTensor<typename std::remove_pointer<N>::type>(..., blob, 3*H*W, dims...)N是float*或half*,通过remove_pointer得到元素类型。 -
session->Run(...)得到outputTensor(只取第一个输出)。 -
取形状
outputNodeDims,拿到数据指针output。 -
模型类型分支:
-
检测(YOLO v8 Detect)
-
读取输出形状:
[batch, 84, 8400](示例),其中 84=4(bbox)+num_classes。 -
代码把原始数据构成
cv::Mat(signalResultNum, strideNum, CV_32F/16F, output),再 转置 成(8400, 84):将输出
84x8400的矩阵转置为8400x84,便于按行处理每个检测框。 -
遍历每一行:
-
data[0..3]是 cx, cy, w, h;data[4..]是各类分数。 -
取最大类分数,若
> rectConfidenceThreshold:-
计算左上角与宽高,仅用
resizeScales等比放大回原图坐标(因为前处理是左上填充,不需要加偏移)。 -
存入
boxes/confidences/class_ids。
-
-
-
cv::dnn::NMSBoxes(..., iouThreshold)做 NMS,组装DL_RESULT返回。 -
若
benchmark:打印三段耗时(pre/infer/post)。
-
-
分类(YOLO v8 Cls)
-
输出 shape 就是一行
num_classes,FP16 时先convertTo(CV_32F)。 -
逐类把
(id, score)推到oResult(是否取 top-k 交由调用方自己处理)。
-
-
其它类型:打印不支持。
-
-
释放:
delete[] blob;(输入缓存释放及时)。
(8)WarmUpSession(预热)
-
构造一张
imgSize大小的三通道黑图;跑一次PreProcess+(按模型类型选择 FP32/FP16)+session->Run。 -
打印 CUDA 预热耗时(只有
cudaEnable=true时打印)。 -
作用:避免首次真实推理时的内存分配、内核 JIT 等导致的抖动。
(9)关键参数/结构
-
DL_INIT_PARAM(在头文件里定义):包含-
rectConfidenceThreshold(置信度阈值) -
iouThreshold -
imgSize(例如{640,640}) -
modelType(枚举:Detect/Cls/Pose 及 FP16 版本) -
cudaEnable -
线程数/日志等级/
modelPath等
-
-
DL_RESULT:后处理输出-
检测:
classId,confidence,box -
分类:
classId,confidence(每类一条)
-
3. inference.h代码:
// Ultralytics 🚀 AGPL-3.0 License - https://ultralytics.com/license#pragma once#define RET_OK nullptr#ifdef _WIN32
#include <Windows.h>
#include <direct.h>
#include <io.h>
#endif#include <string>
#include <vector>
#include <cstdio>
#include <opencv2/opencv.hpp>
#include "onnxruntime_cxx_api.h"#ifdef USE_CUDA
#include <cuda_fp16.h>
#endifenum MODEL_TYPE
{//FLOAT32 MODELYOLO_DETECT_V8 = 1,YOLO_POSE = 2,YOLO_CLS = 3,//FLOAT16 MODELYOLO_DETECT_V8_HALF = 4,YOLO_POSE_V8_HALF = 5,YOLO_CLS_HALF = 6
};typedef struct _DL_INIT_PARAM
{std::string modelPath;MODEL_TYPE modelType = YOLO_DETECT_V8;std::vector<int> imgSize = { 640, 640 };float rectConfidenceThreshold = 0.6;float iouThreshold = 0.5;int keyPointsNum = 2;//Note:kpt number for posebool cudaEnable = false;int logSeverityLevel = 3;int intraOpNumThreads = 1;
} DL_INIT_PARAM;typedef struct _DL_RESULT
{int classId;float confidence;cv::Rect box;std::vector<cv::Point2f> keyPoints;
} DL_RESULT;class YOLO_V8
{
public:YOLO_V8();~YOLO_V8();public:char* CreateSession(DL_INIT_PARAM& iParams);char* RunSession(cv::Mat& iImg, std::vector<DL_RESULT>& oResult);char* WarmUpSession();template<typename N>char* TensorProcess(clock_t& starttime_1, cv::Mat& iImg, N& blob, std::vector<int64_t>& inputNodeDims,std::vector<DL_RESULT>& oResult);char* PreProcess(cv::Mat& iImg, std::vector<int> iImgSize, cv::Mat& oImg);std::vector<std::string> classes{};private:Ort::Env env;Ort::Session* session;bool cudaEnable;Ort::RunOptions options;std::vector<const char*> inputNodeNames;std::vector<const char*> outputNodeNames;MODEL_TYPE modelType;std::vector<int> imgSize;float rectConfidenceThreshold;float iouThreshold;float resizeScales;//letterbox scale
};
4. main.cpp注释版代码:
// Ultralytics 🚀 AGPL-3.0 License - https://ultralytics.com/license#include <iostream> // 标准输入输出,用于打印日志/提示
#include <iomanip> // 控制浮点输出格式(setprecision等)
#include "inference.h"// 本项目的推理类 YOLO_V8 的声明
#include <filesystem> // C++17 文件系统库,遍历目录读取图片
#include <fstream> // 读写文件(用于读取 coco.yaml)
#include <random> // 随机数(生成随机颜色等)// -------------------------------
// Detector:目标检测的演示函数
// 参数 p 为 YOLO_V8* 的引用(YOLO_V8*&),保留“能在函数内修改指针本身”的能力
// 功能:遍历工作目录下的 ./images/ 文件夹,逐张图片执行 RunSession,绘制检测框与标签并显示
// -------------------------------
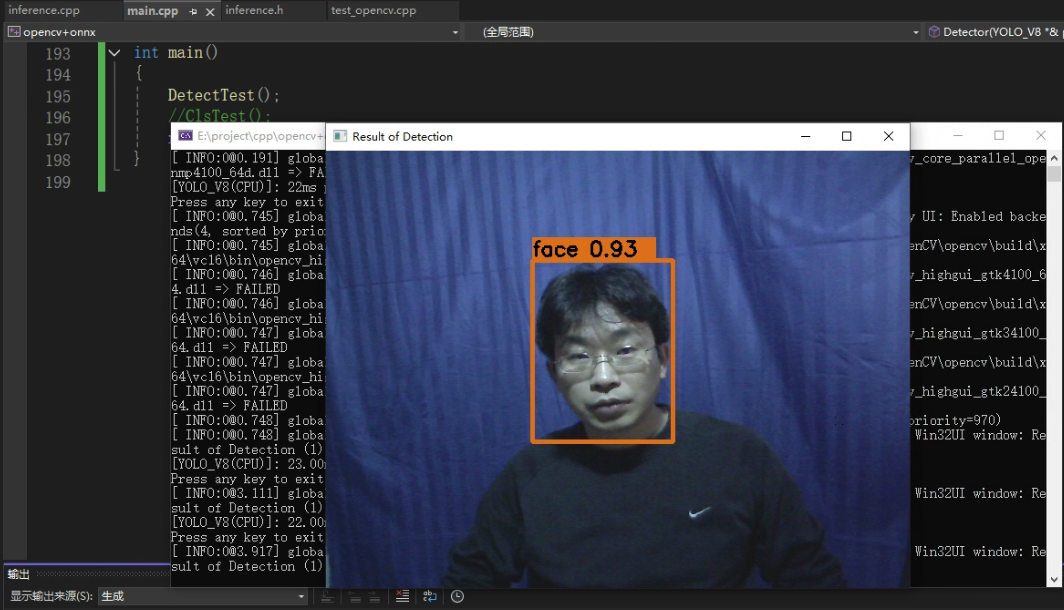
void Detector(YOLO_V8*& p) {std::filesystem::path current_path = std::filesystem::current_path(); // 当前工作目录std::filesystem::path imgs_path = current_path / "images"; // 约定图片放在 ./images/ 目录for (auto& i : std::filesystem::directory_iterator(imgs_path)) // 遍历目录下所有文件{// 仅处理常见的位图格式if (i.path().extension() == ".jpg" || i.path().extension() == ".png" || i.path().extension() == ".jpeg"){std::string img_path = i.path().string(); // 完整路径字符串cv::Mat img = cv::imread(img_path); // OpenCV 读图(BGR)std::vector<DL_RESULT> res; // 存放推理结果(多个目标)p->RunSession(img, res); // 核心推理(前处理→推理→后处理)// 遍历本张图片的所有检测结果,绘制可视化for (auto& re : res){// 生成随机颜色:不同目标用不同颜色,便于区分cv::RNG rng(cv::getTickCount());cv::Scalar color(rng.uniform(0, 256), rng.uniform(0, 256), rng.uniform(0, 256));// 在原图上画出目标框(左上角、右下角由 re.box 决定;线宽=3)cv::rectangle(img, re.box, color, 3);// 置信度格式化:保留两位小数// floor(100*x)/100 是一种“截断到两位”的方式,后续 substr 仅为美观去掉多余字符float confidence = floor(100 * re.confidence) / 100;std::cout << std::fixed << std::setprecision(2); // 控制 cout 的浮点显示为两位小数std::string label = p->classes[re.classId] + " " +std::to_string(confidence).substr(0, std::to_string(confidence).size() - 4);// 上面 substr(... size()-4) 的小技巧:去掉 to_string 默认多余的位数(如 "0.50xxxx")// 在框上方绘制一块实心矩形作为文字背景,避免文本与图像混淆cv::rectangle(img,cv::Point(re.box.x, re.box.y - 25),cv::Point(re.box.x + label.length() * 15, re.box.y),color,cv::FILLED);// 在背景矩形上绘制类别+置信度文本(黑字)cv::putText(img,label,cv::Point(re.box.x, re.box.y - 5),cv::FONT_HERSHEY_SIMPLEX,0.75,cv::Scalar(0, 0, 0),2);}// 显示当前图片的检测结果;等待任意键继续到下一张std::cout << "Press any key to exit" << std::endl;cv::imshow("Result of Detection", img);cv::waitKey(0);cv::destroyAllWindows();}}
}// -------------------------------
// Classifier:分类任务的演示函数
// 功能:遍历当前目录下的图片,调用分类模型,直接把每个类别的分数写到图像上显示
// 说明:分类输出是“对每个类别的置信度”,此处简单地按序写出;可自行改为只显示Top-K
// -------------------------------
void Classifier(YOLO_V8*& p)
{std::filesystem::path current_path = std::filesystem::current_path(); // 当前工作目录std::filesystem::path imgs_path = current_path;// / "images" // 示例使用当前目录;也可改为 ./images// 为了使每一行分数显示不同颜色,准备一个[0,255]的均匀分布随机数生成器std::random_device rd;std::mt19937 gen(rd());std::uniform_int_distribution<int> dis(0, 255);for (auto& i : std::filesystem::directory_iterator(imgs_path)){if (i.path().extension() == ".jpg" || i.path().extension() == ".png"){std::string img_path = i.path().string();//std::cout << img_path << std::endl;cv::Mat img = cv::imread(img_path);std::vector<DL_RESULT> res; // 分类结果:每个类别一条记录(classId, confidence)char* ret = p->RunSession(img, res); // 运行分类推理(FP32/FP16 由模型类型决定)// 逐行把每个类别的分数打印到图像上(从 y=50 开始,每行间距 50 像素)float positionY = 50;for (int i = 0; i < res.size(); i++){int r = dis(gen);int g = dis(gen);int b = dis(gen);cv::putText(img, std::to_string(i) + ":", cv::Point(10, positionY), cv::FONT_HERSHEY_SIMPLEX, 1, cv::Scalar(b, g, r), 2);cv::putText(img, std::to_string(res.at(i).confidence), cv::Point(70, positionY), cv::FONT_HERSHEY_SIMPLEX, 1, cv::Scalar(b, g, r), 2);positionY += 50;}// 显示分类结果;按键关闭窗口cv::imshow("TEST_CLS", img);cv::waitKey(0);cv::destroyAllWindows();//cv::imwrite("E:\\output\\" + std::to_string(k) + ".png", img); // 可选:把结果保存到硬盘}}
}// -------------------------------
// ReadCocoYaml:从 coco.yaml 读取类别名到 p->classes
// 假定 coco.yaml 中存在形如:
// names:
// 0: person
// 1: bicycle
// ...
// 这种简单键值对列表。这里用最朴素的行扫描+字符串分割来解析。
// -------------------------------
int ReadCocoYaml(YOLO_V8*& p) {// Open the YAML filestd::ifstream file("coco.yaml"); // 从当前工作目录读取 coco.yamlif (!file.is_open()){std::cerr << "Failed to open file" << std::endl;return 1;}// Read the file line by linestd::string line;std::vector<std::string> lines;while (std::getline(file, line)){lines.push_back(line); // 全部行读入内存,后续扫描}// Find the start and end of the names section// 思路:找到包含 "names:" 的行作为起点,再找到“下一段的起始”作为终点(简单根据冒号是否出现判断)std::size_t start = 0;std::size_t end = 0;for (std::size_t i = 0; i < lines.size(); i++){if (lines[i].find("names:") != std::string::npos){start = i + 1; // names: 的下一行起为数据起点}else if (start > 0 && lines[i].find(':') == std::string::npos){end = i; // 碰到不含冒号的行,认为 names 段结束(简化处理)break;}}// Extract the names// 将每行按冒号分割,取冒号后的字符串作为类别名(不去空白,按原样)std::vector<std::string> names;for (std::size_t i = start; i < end; i++){std::stringstream ss(lines[i]);std::string name;std::getline(ss, name, ':'); // Extract the number before the delimiter // 左侧序号(丢弃)std::getline(ss, name); // Extract the string after the delimiter // 右侧名称(保留)names.push_back(name);}p->classes = names; // 写回 YOLO_V8 实例,供可视化使用(label 文本)return 0;
}// -------------------------------
// DetectTest:检测 Demo 的入口
// 负责:创建 YOLO_V8 实例 → 设定类别名/参数 → CreateSession → 调用 Detector → 释放实例
// -------------------------------
void DetectTest()
{YOLO_V8* yoloDetector = new YOLO_V8; // 动态创建(也可用智能指针,这里保持示例风格)//ReadCocoYaml(yoloDetector); // 可选:从 coco.yaml 读取 80 类yoloDetector->classes = { "face" }; // 示例:仅一类“face”,便于测试人脸模型DL_INIT_PARAM params; // 初始化推理参数(见 inference.h)params.rectConfidenceThreshold = 0.1; // 置信度阈值(较低,便于观察效果)params.iouThreshold = 0.5; // NMS 的 IOU 阈值params.modelPath = "best.onnx"; // ONNX 模型路径(与可执行文件相对路径)params.imgSize = { 640, 640 }; // 模型输入分辨率(与导出模型一致)#ifdef USE_CUDAparams.cudaEnable = true; // 启用 CUDA EP(前提:ORT 构建包含 CUDA)// GPU FP32 inferenceparams.modelType = YOLO_DETECT_V8; // 使用 FP32 检测模型// GPU FP16 inference//Note: change fp16 onnx model//params.modelType = YOLO_DETECT_V8_HALF; // 使用 FP16(需换成对应的 FP16 ONNX)
#else// CPU inferenceparams.modelType = YOLO_DETECT_V8; // CPU 版仍使用 FP32 模型params.cudaEnable = false; // 关闭 CUDA
#endifyoloDetector->CreateSession(params); // 创建 ORT 会话并预热,准备推理Detector(yoloDetector); // 运行检测 Demo:遍历 ./images/ 并可视化delete yoloDetector; // 释放实例(注意:当前实现中 I/O 节点名有内存泄露,示例不处理)
}// -------------------------------
// ClsTest:分类 Demo 的入口
// 负责:创建实例 → 读取类别名 → 设定分类模型参数 → CreateSession → 调用 Classifier
// -------------------------------
void ClsTest()
{YOLO_V8* yoloDetector = new YOLO_V8;std::string model_path = "cls.onnx"; // 分类模型的 ONNX 路径ReadCocoYaml(yoloDetector); // 从 coco.yaml 读取类别名(也可改成自定义)DL_INIT_PARAM params{ model_path, YOLO_CLS, {224, 224} }; // 简写的聚合初始化:路径、模型类型、输入尺寸yoloDetector->CreateSession(params); // 创建会话(分类分支)Classifier(yoloDetector); // 遍历目录图片,叠加每类分数并显示
}// -------------------------------
// main:程序入口
// 默认跑检测 Demo;若需要跑分类,注释 DetectTest 并打开 ClsTest 即可
// -------------------------------
int main()
{DetectTest();//ClsTest();return 0;
}
推理结果如图所示