Tactile-VLA:解锁视觉-语言-动作模型的物理知识,实现触觉泛化
25年7月来自清华、中科大和上海交大的论文“Tactile-VLA: Unlocking Vision-Language- Action Model’s Physical Knowledge For Tactile Generalization ”。
视觉-语言-动作 (VLA) 模型已展现出卓越的成就,这得益于其视觉-语言组件丰富的隐性知识。然而,要实现通用机器人智体,需要精确地扎根于物理交互,尤其是在接触频繁的场景中,细粒度的力控制至关重要。VLA 的隐性知识从确定要做什么提升到指导如何与现实世界进行物理交互。 Tactile-VLA,是一个深度融合视觉、语言、动作和触觉感知的全新框架。该框架包含一个混合的位置-力控制器,用于将模型的意图转化为精确的物理动作,以及一个推理模块,使机器人能够根据触觉反馈调整其策略。实验证明 Tactile-VLA 在三个关键方面的有效性和泛化能力:(1)支持触觉-觉察指令的遵循;(2)利用与触觉相关的常识;以及(3)促进自适应触觉推理。一项关键发现是,VLM 的先验知识已经包含对物理交互的语义理解;只需几次演示,即可将其连接到机器人的触觉传感器,从而激活这些先验知识,在接触密集型任务中实现零样本泛化。
通才机器人智体(能够在非结构化环境中理解和执行各种任务的系统)的开发,因视觉-语言-动作 (VLA) 模型的兴起而得到了极大的加速 (Brohan,2022;Zitkovich,2023;Black,2024;Pertsch,2025;Wen,2025)。这些模型利用预训练的视觉语言主干网络来解读抽象指令,并展现出跨任务、模态和环境的出色泛化能力。然而,尽管目前的 VLA 擅长高级推理和规划,但它们在将决策基于现实世界的细粒度物理现实方面往往存在不足,尤其是在接触密集、精确力控制至关重要的环境中 (Hao,2025;Xue,2025)。
这一追求中缺失的一个关键环节是触觉感知。与提供高级语义信息的视觉和语言不同,触觉感知提供关于物理交互的丰富、局部且时间动态的反馈——这些信息对于涉及摩擦、柔顺性或材料敏感性的任务至关重要(Spelmezan 2009;Sinico 2025)。尽管近期一些研究已将触觉技术融入机器人框架(Pattabiraman;Jones,2025;Yu,2025),但触觉通常仅被视为一种补充感知模态,并未直接参与策略的行动生成。
机器人策略中的触觉集成。除了 VLA 范式之外,大量的研究已经探索将触觉信号集成到机器人策略中。技术策略多种多样,从经典的控制方法到基于学习的现代策略,涵盖诸如抓取(Calandra,2018;Polic,2019)、插入(Dong,2021;Ma,2019)、手部操作(She,2021,Qi 2023)、织物处理(Sunil,2023)和工具使用(She,2021)等任务。这些努力催生了各种有效的专用策略。在基于学习的方法中,已经开发出一些策略,例如将规划与控制分离的分层架构(Xue,2025)、带有形状奖励的强化学习(Schoettler,2020)、以力为中心的模仿学习(Liu,2024)以及端到端的视觉-触觉策略(Yu,2024)。虽然这些专门的策略在其预期任务中表现出色,但由于通常不包含语言模态,它们泛化到新指令、推理抽象目标或利用常识性知识的能力可能有限。
本文工作旨在将这些基于触觉的策略的物理精确性与现代 VLA 的语义灵活性和广泛的世界知识相结合。Tactile-VLA 是一种深度融合视觉、语言、动作和触觉的全新方法和框架,用于完成接触式操控任务。Tactile-VLA 超越现有范式,它不仅利用视觉-语言模型中的隐性知识进行规划(Yang;Wang,2024;Mei,2024;Hu,2024),还能在力控制层面直接指导物理交互。
如图所示,实验证明这种跨三个维度深度集成的优势:触觉-觉察指令跟踪,使机器人能够学习与力相关的语言的含义,例如“轻柔”或“用力”等副词,从而使机器人能够弥合抽象意图和物理执行之间的差距,即使在零样本场景中也是如此;触觉相关常识,使机器人能够应用世界知识和语义推理,根据目标属性和上下文线索调整其接触行为;触觉参与推理,促进反馈驱动的控制调整和自主重新规划。这是通过思维链 (CoT) 过程实现的,其中模型明确地推理触觉反馈来诊断故障并制定纠正措施,尤其是在面对新场景或故障情况时。

如图所示 Tactile- VLA 的概览架构:
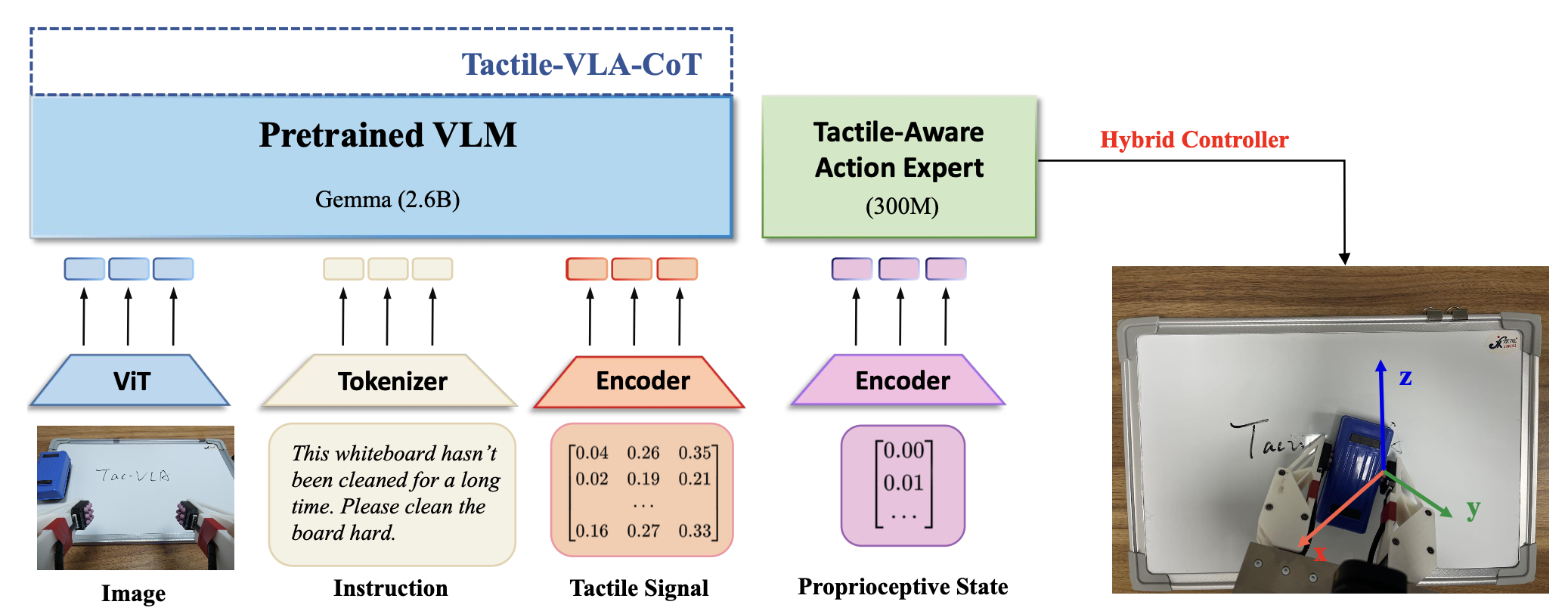
策略架构与学习
Tactile-VLA 的核心设计目标是解锁视觉-语言-动作 (VLA) 模型中固有的物理知识,将其对交互的抽象理解转化为精确的、现实世界的力控制。这种能力对于区分具有相同动作但力不同的命令至关重要,例如“用力插入 USB”和“轻轻插入 USB”。模型通过创建从多模态感知输入到力感知动作输出的直接映射来实现这一点,并以流匹配目标进行端到端训练。
该架构采用 token 级融合方法,将输入前缀中的多模态信息深度集成到 Transformer 主干网络。这种设计对于 Tactile-VLA 的高级推理能力至关重要,尤其是对于 Tactile-VLA-CoT 变型中的思维链 (CoT) 过程。为了实现这一点,引入针对每种模态特征定制的编码器。对于视觉信息,用预训练的 Vision Transformer (ViT) 编码器 (E′_vis)(Dosovitskiy et al., 2020) ,类似于 π_0 (Black et al., 2024),将最后的 H 帧编码为一系列不同的 token 集。对于触觉信号,一个简单的 MLP 充当编码器 E_ψ′,它将 H 个触觉测量值的串联历史记录处理成一个融合的 token,以表示交互的时间动态。然后,将这些生成的视觉、触觉和语言 token 串联起来,形成统一的输入前缀序列 S_t。
S_t 由模型的 Transformer 主干进行处理。此前缀上的非因果注意机制允许视觉、语言和触觉 token 自由地交叉关注,从而创建深度集成且具有语境关联的表征。
这种丰富的表征构成了生成力-觉察动作的基础。前缀随后被馈送到触觉-觉察动作专家,专家输出一个增强的动作向量,明确指定目标位置 Ptarget 和目标接触力 F_target。这些目标由用于模仿学习的专家演示提供。通过将力直接纳入动作空间,模型可以学习控制物理交互的强度。
该模型通过模仿学习进行端到端微调来学习这种复杂的映射。该过程首先使用来自 π_0(Black,2024)的预训练参数初始化共享组件,π_0 是一种通用的视觉-语言-动作策略。相反,新引入的模块(例如触觉编码器和改进的动作专家)则随机初始化。然后,通过采用条件流匹配 (CFM) 目标对整个模型进行微调,其中损失函数会惩罚预测动作序列在运动学和力维度上的偏差。这种学习机制迫使模型利用 VLM 的潜物理知识,最终在语言细微差别(例如“轻轻地”)与其相应的物理力量大小(例如 0.5N)之间建立直接映射。
混合位置-力控制器
一旦触觉-觉察动作专家确定了目标位置和目标力,就需要一个低级控制器来平衡这两个不同的目标。策略是以位置为主导,最终通过位置指令实现,并承认大多数操作任务都以精确的运动学运动为主导,仅在接触阶段才需要力控制 (Raibert & Craig, 1981)。为了整合力的目标,采用一种受阻抗控制原理 (Hogan, 1985) 启发的间接力控制方法。这涉及将力的目标转化为位置指令的自适应调整。
然而,与旨在实现被动柔顺的经典阻抗控制不同,目标是主动跟踪目标力。控制器测量力误差 ∆F = F_target − F_measured,仅当其幅度 ||∆F|| 超过预定阈值 τ 时,才使用该误差计算校正位置调整,以增强操作的平滑度。
然后,PID (Willis, 1999) 控制器将机器人的关节驱动到动态更新的 P_hybird。具体来说,将两个不同的力分量(净外力和内部抓取力)的控制分离。这种分离的关键原理是建立两个独立的控制通道。夹持器的笛卡尔位置,用于专门调节施加于物体的净外力,而夹持器的宽度则同时用于控制内部抓取力,从而决定物体的抓取牢固程度。
Tactile-VLA-COT:基于推理的自适应
虽然核心的 Tactile-VLA 架构提供了细粒度的力控制,但利用其固有的推理能力是进一步释放 VLM 鲁棒自适应潜力的关键 (Stone;Huang,2023;Shi,2024;Belkhale,2024)。为此提出 Tactile-VLA-CoT,这是一种集成思维链 (CoT) 的变型,可以激活和利用 VLM 的潜在推理能力 (Wei,2022;Chen,2024;Zhang,2024;Lin,2025)。在这个变型中,力和触觉反馈不仅仅是策略输入;它们成为自适应推理和重规划的关键线索。
CoT 过程是通过使用 VLM 自身的预训练解码器来生成清晰的内部独白来实现的。这种独白使模型能够推理故障原因(例如意外滑落),并制定纠正措施。为了实现这一点,用一个小型的、有针对性的演示数据集对模型进行微调。该数据集中的每个样本都捕获一个特定的故障事件(例如,滑倒擦拭黑板),并将多模态感知流与分析故障原因的语言注释配对。这种训练有两个目的:首先,它保留 VLM 的通用推理能力,减轻微调过程中的灾难性遗忘。更重要的是,它将这种推理扩展到触觉模态,教会模型从传感器信号中推断物理现象,例如从剪切-力信号中检测擦拭时向下的压力不足或工具滑落。
在实践中,这种 CoT 推理会以固定的时间间隔触发。这种简单有效的方法允许模型定期检查其进度。提示结构首先要求模型确定任务是否成功完成。如果判定为失败,则提示模型使用传感反馈分析根本原因,如图所示。最终的推理输出会明确分析不同的力分量(例如,“抓握力足够,但法向力太小”),然后制定新的纠正指令来指导下一次尝试,例如生成“再次擦拭板子,但施加更大的向下力”。此过程通过使适应过程明确化并基于物理交互,增强了系统处理复杂场景的能力。

数据收集
准确且语义一致的触觉数据,对于在接触密集的场景中训练智能体至关重要。传统的远程操作不足以实现这一目标,因为人类操作员通常缺乏直接的力反馈。以这种方式收集的策略本质上不依赖于触觉信息,因此不适合学习目标。为了解决这个问题,基于通用操作接口 (UMI)(Chi,2024),一种便携式手持设备,构建了一个专门的数据收集装置。为 UMI 夹持器配备双高分辨率触觉传感器,能够捕捉法向力和剪切力,使操作员能够直接感知接触动态并提供明确由力引导的演示。

仔细考虑时间同步的问题。在每次收集会话之前,都会对齐所有数据流的时间戳。在采集过程中,捕捉 100Hz 触觉反馈和 20Hz 视觉数据,随后对高频触觉信号进行下采样,使其与对应的视觉帧匹配。最终生成的 VLA-T 训练数据集包含来自视觉、语言、触觉和动作轨迹的精确同步的多模态信息。
实现细节
基线。为了回答上述问题,在各种任务上将以下基线方法和简化方法与所提出的 Tactile-VLA 进行比较:π0-base,一个用于通用机器人控制的“视觉-语言-动作”流程模型;π0-fast,π0-base 的一个变型;Tactile-VLA,本文方法;以及 Tactile-VLA-CoT,一个带有 CoT 推理过程的 Tactile-VLA 变型。
任务和数据收集。主要关注三个接触丰富的操作任务,如下所示:充电器/USB 插入和拔出、桌面抓取和擦拭电路板。在充电器/USB 插入和拔出任务中,机器人必须拔出充电器或 USB 并将其插入正确的插座。对于训练数据,分别收集 100 个“软”和“硬”USB 操作的演示,以及另外 100 个充电器任务的演示,以学习基本动作。在桌面抓取任务中,机器人需要以适当的力度抓取各种物体,并提前判断这些物体是重还是易碎。这项任务的训练使用了每个物体 50 次的演示。

如图中可视化的六个物体在训练阶段见过,同时引入了另外六个未见过的物体进行评估。在擦拭黑板任务中,机器人需要以默认力度擦拭黑板,评估结果,然后根据需要调整力度。为了实现这一推理,训练数据包括 100 次在白板上成功擦拭和 100 次失败擦拭的演示,而模型在训练期间从未遇到过擦拭黑板的场景。
触觉-相关指令遵循
本实验旨在评估研究的核心假设:Tactile-VLA 能否从一项任务中学习与力相关的副词(例如“轻柔”、“用力”)的泛化理解,并将这些语义知识应用于另一个未知任务。具体而言,将探究模型在 USB 插入任务(任务 A)中训练将“轻柔”和“用力”与特定力场关联后,能否成功地将这种理解迁移到充电器插入任务(任务 B),因为该任务 B 只学习了动作,而没有接收到相应的语言力指令。这旨在检验真正的语义基础,即语言在零样本情境中直接调节物理交互。
触觉的相关常识
在现实世界的操控任务中,机器人必须展现出跨模态泛化先验知识的能力。具体而言,将视觉语言模型 (VLM) 的先验知识整合到触觉信号中,对于有效操控至关重要。例如,机器人必须通过推理物体的属性来调整抓握方式,对不同类别的物体施加不同大小的力:对坚硬且较重的物体施加较大的力,对坚硬且较轻的物体施加中等力度,对易碎且较轻的物体施加轻柔的力以防止损坏。这种基于先验视觉和情境知识调整施加力的能力,对于有效执行各种操控任务至关重要。
触觉推理
为了验证模型的自适应推理能力,设计一个实验,专门测试其解读物理反馈并自主调整策略的能力。这超越了单纯的遵循指令,而是通过触觉交互来展示对任务成功或失败的理解,这也是工作的一个关键主张。研究 Tactile-VLA-CoT 能否将学习到的推理过程从熟悉的任务(擦拭白板)推广到一个新的、物理上不同的场景(擦拭黑板),这需要不同的力度,如图所示。
