检索召回率优化探究一:基于 LangChain 0.3集成 Milvus 2.5向量数据库构建的智能问答系统
背景
基于 LangChain 0.3集成 Milvus 2.5向量数据库构建的 NFRA(National Financial Regulatory Administration,国家金融监督管理总局)政策法规智能问答系统,第一个版本的检索召回率是 79.52%,尚未达到良好、甚至是优秀的水平,有待优化、提升。
具体的代码版本(可见);检索评估召回率详细说明(可见)
目标
检索召回率 >= 85%
实现方法
本次探究:把文件按法条逐条分块,不考虑块的大小,能否会提高分块文本的检索召回率。而本次探究实现的方法,则对应于 RAG系统整体优化思路图(见下图)的“文档分块”。
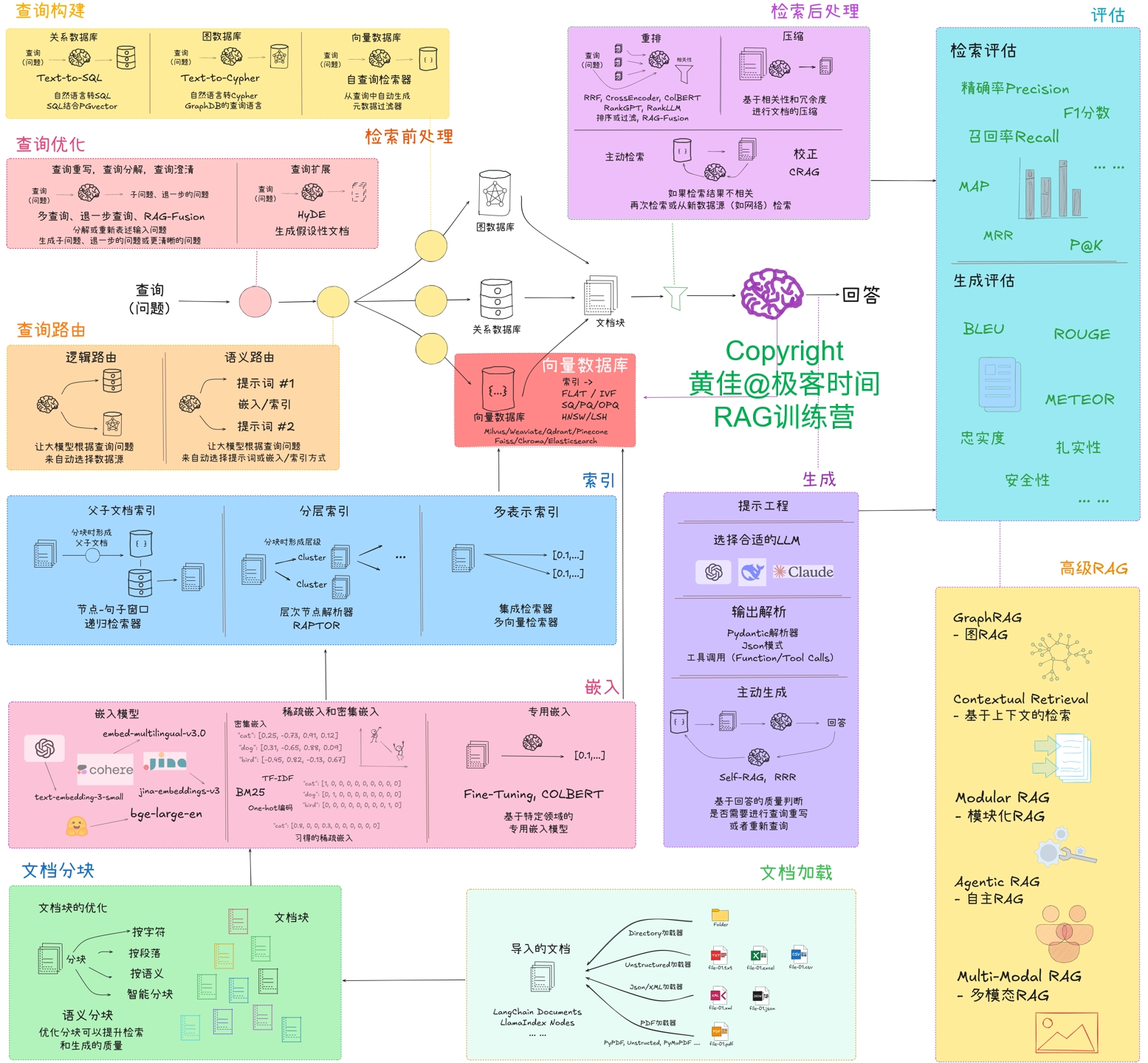
RAG系统整体优化思路图
实现思路:
- 了解 LangChain 的文本切分器是否支持不考虑块的大小,且使用正则表达式来分块的;
- 若上述方法行不通,就考虑不使用 LangChain 的切分器,通过常规的 Python编码来实现文件内容的分块。
执行过程
LangChain 文本切分器
一开始,尝试看官网的文档,发现它也不像平常看过的 Java帮助文档那样,具体介绍每一个类以及类中的方法等,它写的更加简单与实用。见下图:
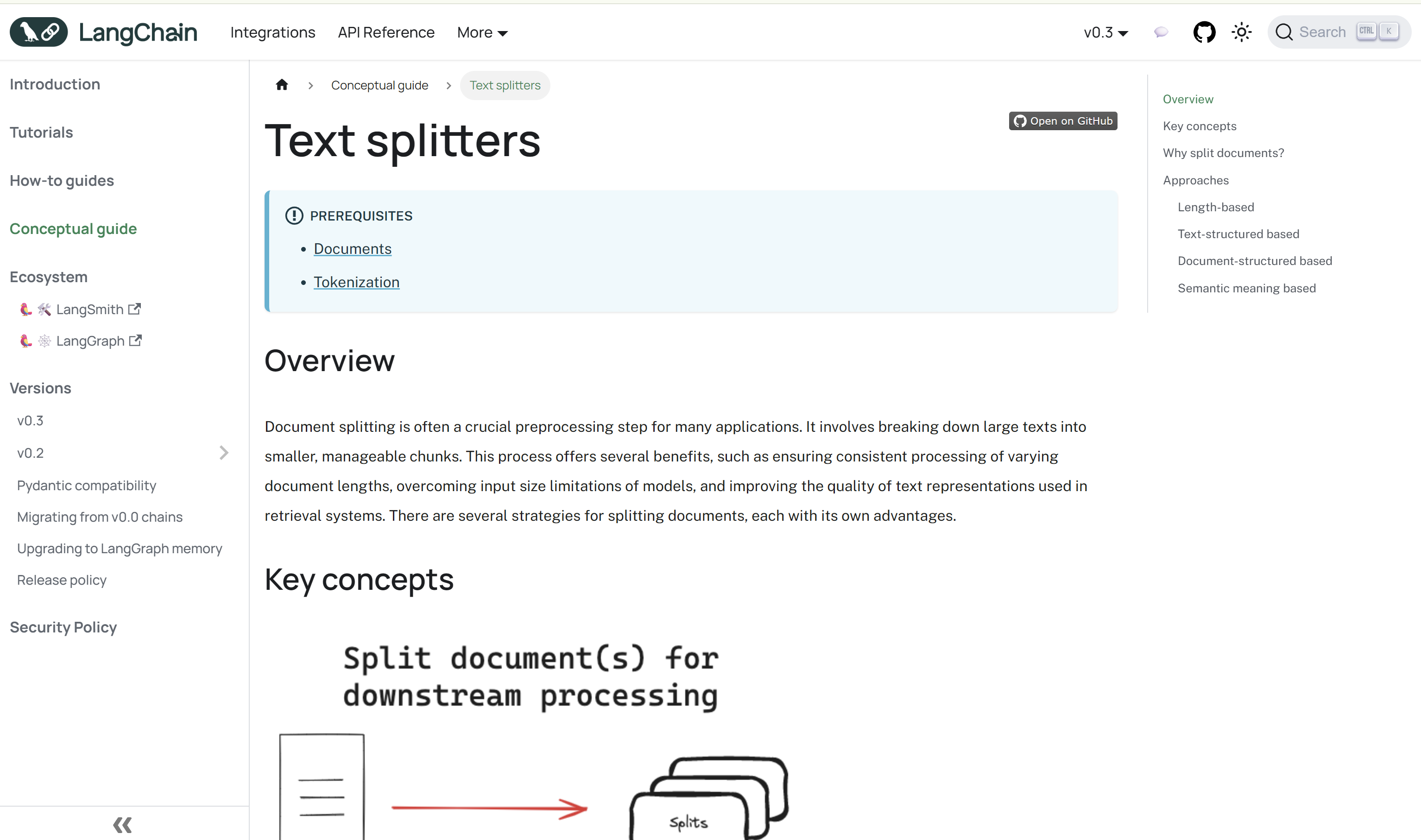
图片来源:Text splitters | 🦜️🔗 LangChain
从图中的右侧可知,LangChain 文本切分器的实现分类有:
- 基于长度的切分;
- 基于文本结构的切分;
- 基于文件结构的切分;
- 基于语义的切分。
从上述分类来看,第一类基于长度,就不用考虑了;基于文本结构的切分,是可以考虑的,这类应该就有关于正则表达式。而至于其他两类,显然不符合本次探究的内容,也是不用考虑的。
而进一步了解基于文本结构切分实现,可见下图:
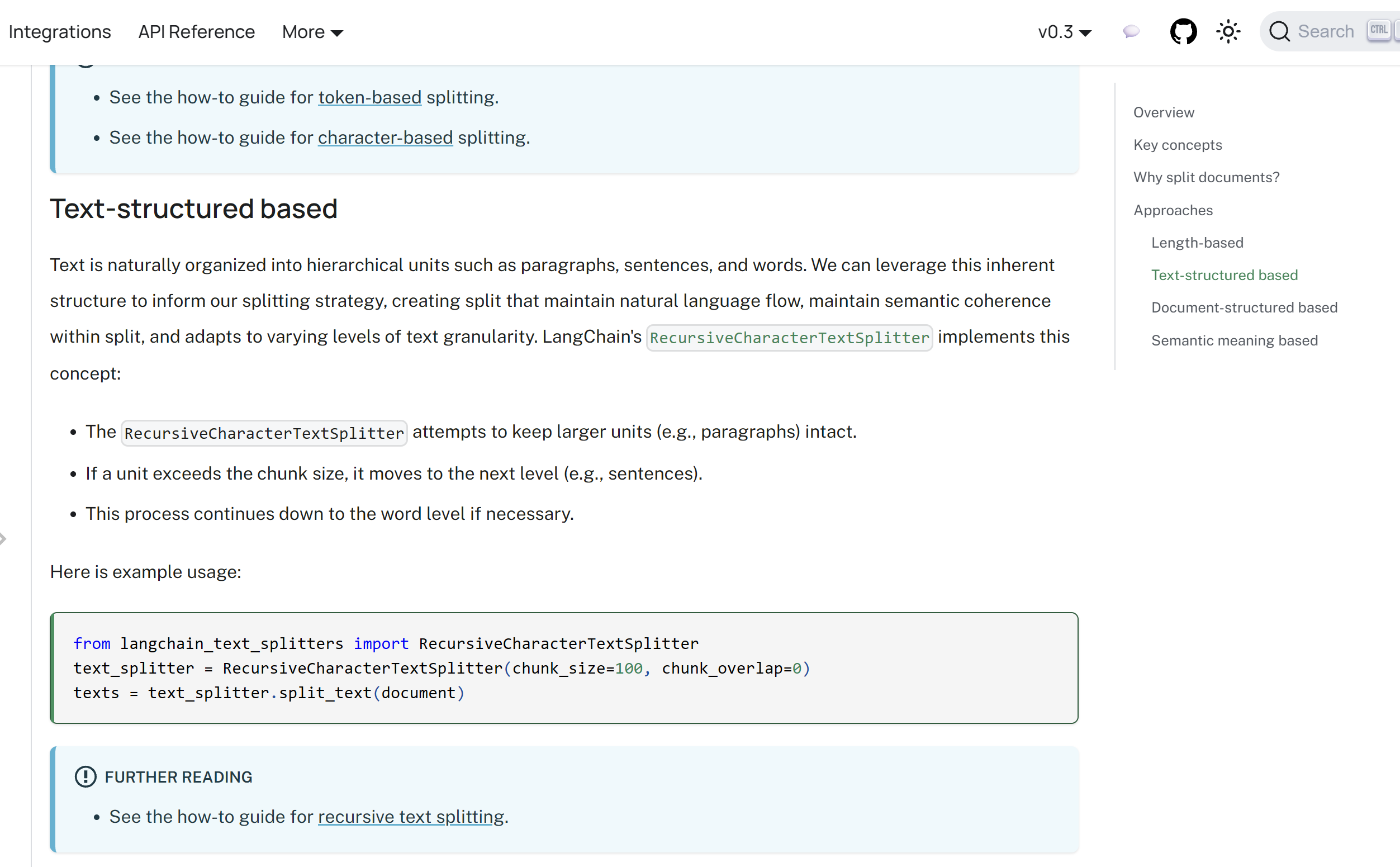
图片来源:Text splitters | 🦜️🔗 LangChain
(大家看这种英文技术文档,不要畏惧,刚开始不熟悉时,可以使用浏览器翻译插件来辅助,等熟悉其中的关键内容,不用翻译也大致能看懂了,也是一种“熟能生巧”)
从上图,可知实现文本结构分类的主要实现类是:RecursiveCharacterTextSplitter。
接着,再进一步了解这个类(具体内容可见)之后,大致上就觉得方法1(考虑基于 LangChain的文本切分器来实现)是行不通了。
不过,还想看看源代码,万一项目所使用的版本是支持的呢?但是,当看到下图的内容,方法1 就彻底放弃了。
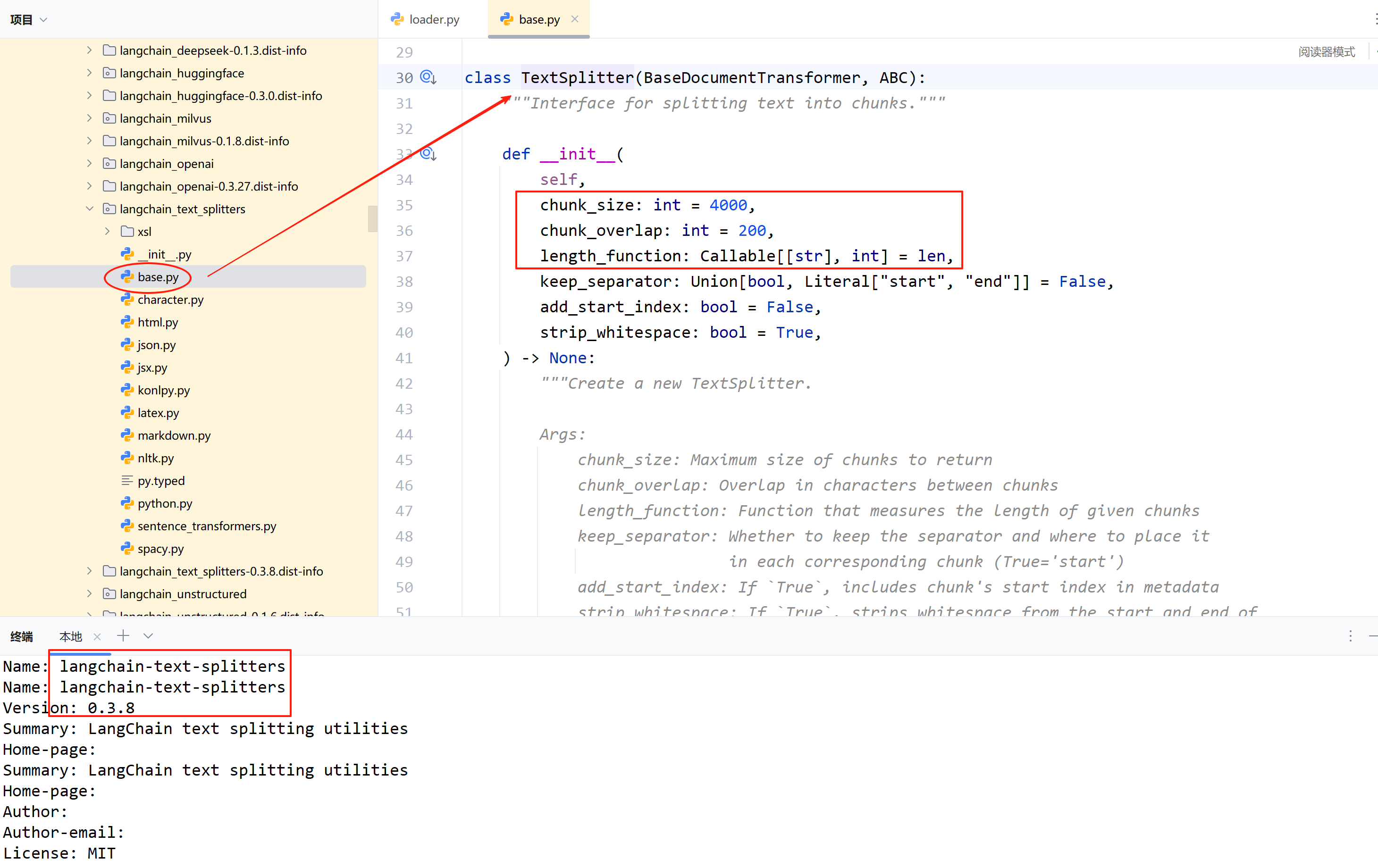
TextSplitter 类是 RecursiveCharacterTextSplitter 的基类,后者是继承前者实现的。因此,不考虑分块大小是不可行的。
Python 编码实现
Python编码实现,其实并不难,毕竟实现思路已比较明确。把从文件中读取的文本内容,根据法条的形式逐条分块。技术实现上,使用的是正则表达式。实现的过程,主要是在测试验证中写出合适的正则表达式来分块处理。
主要代码实现如下:
1. 根据文本内容按法条分块:
def split_by_pattern(content: str, pattern: str = r"第\S*条") -> List[str]:"""根据正则表达式切分内容:param content: 文本内容:param pattern: 正则表达式,默认是:r"第\S*条""""# 匹配所有以“第X条”开头的位置matches = list(re.finditer(rf"^{pattern}", content, re.MULTILINE))if not matches:return [content.strip()]result = []for i, match in enumerate(matches):start = match.start()end = matches[i + 1].start() if i + 1 < len(matches) else len(content)part = content[start:end].strip()if part:result.append(part)return result2. 从目录读取文件并分块:
class CustomDocument:def __init__(self, content, metadata):self.content = contentself.metadata = metadatadef load_and_split(directory: str) -> List[CustomDocument]:"""从指定文件目录加载 PDF 文件并提取、切分文本内容:param directory: 文件目录:return: 返回包含提取、切分后的文本、元数据的 CustomDocument 列表"""result = []# 从目录读取 pdf 文件pdf_file_list = get_pdf_files(directory)# 提取文本for pdf_file in pdf_file_list:document = fitz.open(pdf_file)text_content = ""for page_num in range(len(document)):page = document.load_page(page_num)text_content += page.get_text()# 去除无用的字符text_content = rm_useless_content(text_content)# 把文本保存为 txt 文件,便于优化output_path = os.path.join(config.FILE_OUTPUT_PATH, os.path.basename(pdf_file).replace('.pdf', '.txt'))save_text_to_file(text_content, output_path)# 切分文本内容split_list = split_by_pattern(text_content)# 元数据metadata = {"source": "《" + os.path.basename(pdf_file).replace('.pdf', '') + "》"}for split_content in split_list:result.append(CustomDocument(split_content, metadata))return result代码编写完成之后,实现方法也就完成了。
接下来对所有的文件进行读取分块、嵌入、存储到一个新的 Milvus 向量数据库集合(Collection)中,用于检索评估。(具体过程就不在这里展开了,感兴趣的朋友,可以基于第一版项目代码,再结合上述代码实现,修改 config 配置类的集合名称参数,就可以跑起来了。本次的代码会在后续更新到 Gitee项目上,具体时间暂时无法确定)
这里通过 Milvus 向量数据库可视化工具 Attu,可以看到分块嵌入向量化存储后的数据,如下图:
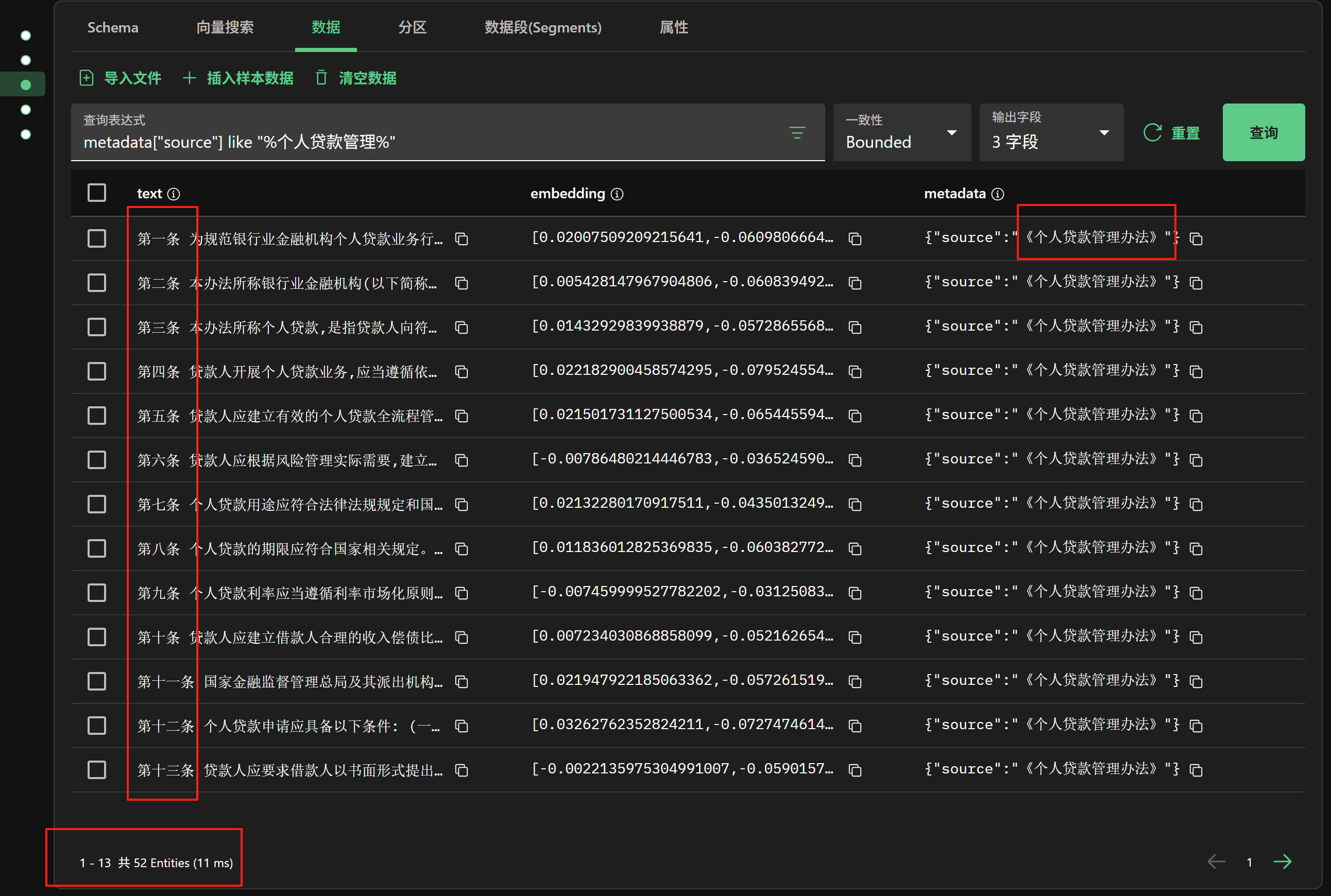
看到这个图,搞过开发的,应该有一种莫名的熟悉感吧…
安装 Attu,直接到官网 github 仓库下载下来,点击安装即可。
注意和自己代码中所使用的版本要一致。
安装成功后,运行如下图:
检索评估(召回率)
为了确定检索召回率是否真的提高了,采用的对比评估。因此,就要控制好变量与不变量。本次变的是文件文本的分块方式,其他的均保持不变,尤其是评估数据集,和上一版本检索召回率统计所使用的数据集是一致的。评估数据集和检索结果处理文件,均已上传到项目中。
RAG 相关处理说明
变量是:切分策略。
切分策略:直接使用(Python)正则表达式,[r"第\S*条 "],不区分块大小
嵌入模型:模型名称: BAAI/bge-base-zh-v1.5 (使用归一化)
向量存储:向量索引类型:IVF_FLAT (倒排文件索引+精确搜索);向量度量标准类型:IP(内积); 聚类数目: 100; 存储数据库: Milvus
向量检索:查询时聚类数目: 10; 检索返回最相似向量数目: 2
检索评估结果
| 数据表单 | 有效 问题个数 | TOP1 个数 | TOP1 平均相似度 | TOP1 召回率 | TOP2 个数 | TOP2 平均相似度 | TOP2 召回率 | TOP N策略个数 | TOP N策略召回率 |
| 通义 | 29 | 20 | 0.7305 | 68.97% | 2 | 0.6551 | 6.90% | 22 | 75.86% |
| 元宝 | 33 | 14 | 0.7121 | 42.42% | 9 | 0.7011 | 27.27% | 23 | 69.70% |
| 文心 | 21 | 18 | 0.6997 | 85.71% | 2 | 0.6622 | 9.52% | 20 | 95.24% |
| 总计 | 83 | 52 | 0.7141 | 62.65% | 13 | 0.6728 | 15.66% | 65 | 78.31% |
从表格数据来看,显然TOP N 策略召回率:78.31% 小于目标检索召回率:85%,而且它还比上一个版本的召回率 79.52%低。
为何检索召回率,会出现不升反而还下降呢?
以下是在核对检索结果的过程中发现的现象:
- 原来检索不到的法条,现在可以 top 1检索出来(见下图)。问题一样,分块变小,语义更集中,从而检索相似度会越高;

- 原来检索出来的法条,现在检索不出来(见下图)。问题一样,分块变小,语义更集中,并不只是问题与真正所需的法条相似度提高,其他法条的相似度可能会更高。这是因为在某个章节中,里面的法条主题是比较集中的。

- 原来检索不出来的,现在还是未能检索出来(见下图)。单个问题检索,不可避免会出现这样子的问题——双语义差(问题嵌入,语义损失;分块嵌入,语义损失)。

检索评估结论
本次实现方法检索召回率:78.31% 小于目标检索召回率:85%,同时小于上一次的检索召回率:79.52%,按法条逐条分块并不是一个能提升检索召回率的好方法。
(上述检索评估结论,仅代表文中提到的评估数据集,在文中提及的项目代码的处理方式下得到的对比结果,远不具备广泛性。)
总结
尽管结果未达到预期的目标,但整个过程下来,也是有收获的,至少知道把文件按条文分块并不是自己所预期的那样,会让检索召回率明显提升。而重要的收获应是:基于现有条件 -> 提出设想 -> 寻找实现方法 -> 实现并验证设想 -> 在验证中得出结论,这一整个流程下来所获得的。
接下来,会继续按 RAG系统整体优化思路图进行优化,提升检索召回率。根据本次检索结果所观察到的现象,接下来会进行检索前处理。
文中基于的项目代码地址:https://gitee.com/qiuyf180712/rag_nfra/tree/master
本文关联项目的文章:RAG项目实战:LangChain 0.3集成 Milvus 2.5向量数据库,构建大模型智能应用-CSDN博客