Java从入门到精通!第十三天(IO 流)
一、IO流
1. File类(文件)
(1)java.io.File类:文件和文件目录的抽象表示形式,与平台无关。
(2)File 类能新建,删除,重命名文件,但是不能访问文件的内容,文件内容要有 IO 流来访问。
(3)想要在 Java 程序中表示一个真实的文件或目录,那么必须创建一个 File 对象来与之对应
2. File类常用的构造函数
(1)public File(String pathname):根据 pathname 指定的路径创建File对象,路径可以是相对路径也可以是绝对路径。
① 相对路径:相对于某一个位置的路径
② 绝对路径:一个固定的路径
(2)public File(String parent,String child):以parent为父路径,child为子路径创建File对象
(3)public File(File parent,String child):根据一个父File对象和子文件路径创建File对象。
注意:通过File的构造器创建File对象时需要注意:
Windows中的文件路径是以“\”来分割的,而Linux和Unix的路径是以“/”来分割,为了解决这个问题,File类提供了一个常量:public static final String separator,它会根据不同的操作系统,动态的提供分隔符。
示例:


3. File类型常用的方法
(1)File类的获取功能
public String getAbsolutePath():获取绝对路径
public String getPath():获取路径
public String getName():获取名称
public String getParent():获取上层文件目录路径,没有返回null。
public long length():获取文件长度(字节数),注意不能获取文件夹的长度
public long lastModified():获取最后一次修改的时间,毫秒值
public String[] list():获取指定目录下的所有文件或者文件目录的名称组成的数组
public File[] listFiles():获取指定目录下的所有文件或文件夹组成的File数组
(2)重命名
public boolean renameTo(File dest):将文件重命名成 des t指定的名称。
(3)判断的功能
public boolean isDirectory():是否是文件夹
public boolean isFile():是否是文件
public boolean isExists():判断文件是否存在
public boolean canRead():是否可读
public boolean canWrite():是否可写
public boolean isHidden():是否隐藏
(4)创建文件
public boolean createNewFile():创建文件,若文件存在,不创建,返回false。
public boolean mkdir():创建文件夹,若存在,则不创建,如果此文件目录的上层目录不存在,也不创建(不能递归创建)
public boolean mkdirs():创建文件目录,如果上层文件夹不存在,一并创建(可以递归创建)
注意:如果创建文件或目录没有写盘符,那么就默认在当前项目下面创建。
(5)删除
public boolean delete():删除文件或文件夹。
注意:Java删除文件不会去到回收站,要删除一个目录,必须确保这个目录下不能包含文件或文件夹,即目录要是一个空的目录才能删除。
示例:


示例2:

示例3:打印一个目录及其子目录中的所有文件路径(Windows 的目录属于树形结构,所以需要使用递归算法来一层一层深入进去打印)

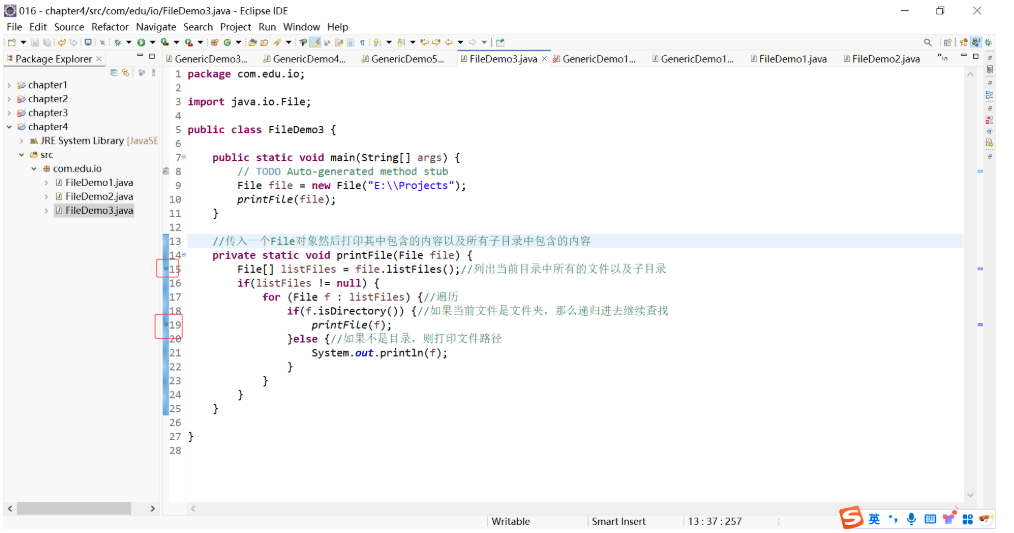
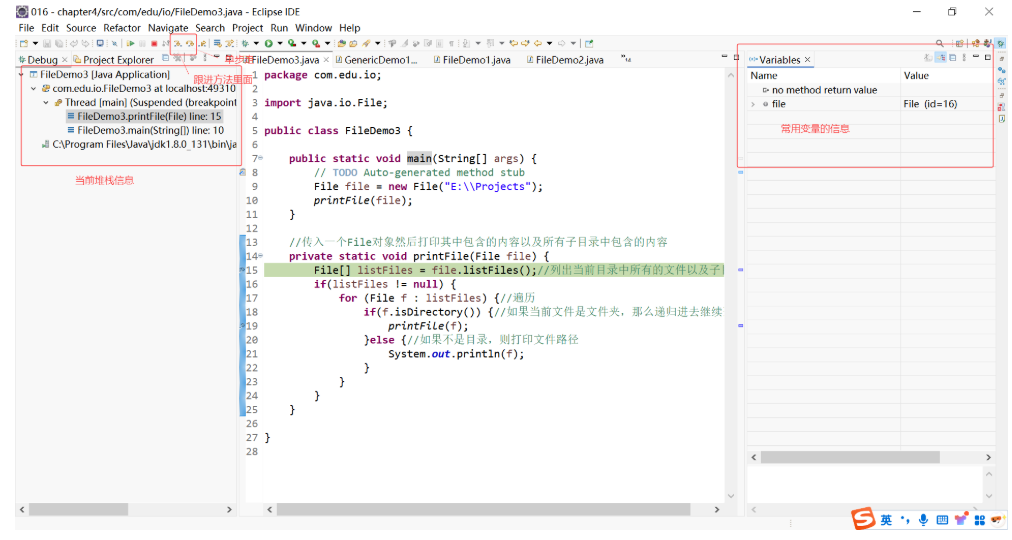
补充内容:在 Eclipse 中调试程序
打断点:程序走到断点处,就会停在这里等待执行,然后用户就可以单步走或者跟进去:
然后以调试模式执行:
4. IO 流原理
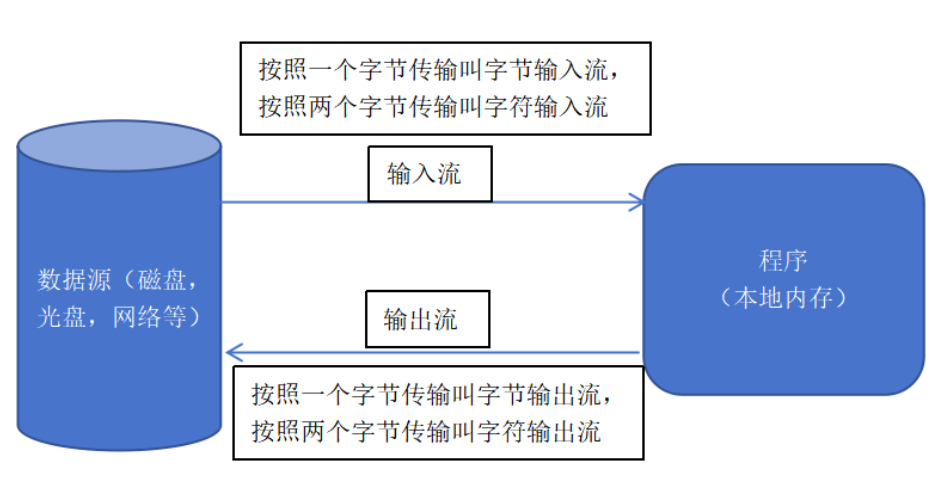
(1)IO流:Input/Output流,用于处理设备之间的数据传输,比如文件读写,网络通讯等等。
(2)在Java中,对数据的输入输出是以流(Stream)的方式来进行的。
(3)java.io包中提供了各种处理流的类和接口,用于获取不同的数据,并通过标准的方法输入或输出数据。
① 输入 Input:从磁盘,光盘,网络等设备中读取数据到程序中(本地内存)
② 输出 Output:从程序(本地内存)的数据写入到磁盘,光盘,网络等设备中
(4)流的分类
① 按照传输数据单位分为:字节流(8bit)、字符流(16bit)
② 按照数据流的流向不同分为:输入流、输出流
③ 按照流的角色不同分为:节点流、处理流
④ 流的抽象基类:所有的流的类都继承于以下的流的抽象基类:

输入输出流的图示:
(5)IO流的体系

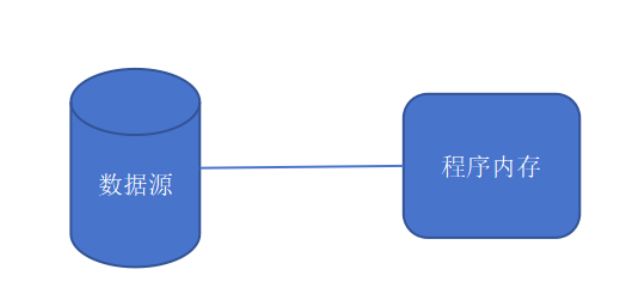
(6)节点流和处理流
按照流是否直接操作数据源或程序内存分为节点流和处理流
1)节点流:直接从数据源或程序内存中读写数据
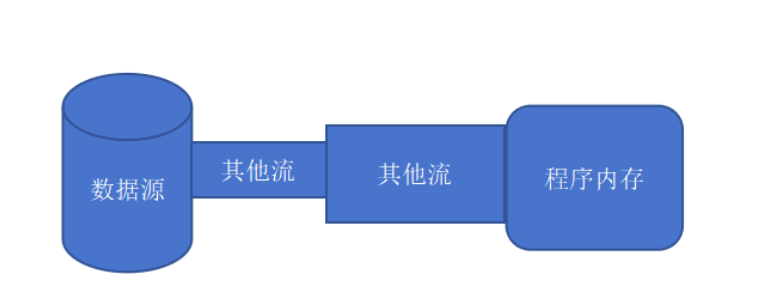
2)处理流:不直接操作数据源或程序内存,而是建立在已存在的流(可以是节点流或处理流)的基础之上,通过对数据的处理完成功能更强大的读写。
(7)抽象基类 InputStream(字节输入流)和 Reader(字符输入流)
1) InputStream 是所有字节输入流的抽象父类,典型的子类有 FileInputStream 类等,Reader 是所有字符输入流的抽象父类,典型的子类有 FileReader 类等。
注意:程序中打开的 IO 资源并不属于内存资源,所以 Java 虚拟机没有办法对这种 IO 资源进行垃圾回收,所以打开的 IO 资源必须显式关闭。
2) InputStream 的常用方法
int read():一次读取输入流中的下一个字节,返回 0~255 范围的 int 数据,将读到的一个字节的数据放在 int 返回值的低 8 位字节,忽略高位,如果读到流的末尾,返回 -1。
int read(byte[] b):最多读取输入流中 b.length 长度的数据到 byte 数组中,如果读到流的末尾,返回 -1,否则以整数的方式返回实际读到的字节数。
int read(byte[] b,int off,int len):从 off 指定的位置开始读取,将输入流中最多 len 个字节数据读入 byte 数组,尝试读取 len 个字节,但读取的字节可能小于该值,以整数形式返回实际读到的字节数,读到流的末尾,返回 -1.
public void close() throws IOException:关闭字节输入流
示例:
package com.edu.io;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStream;
public class InputStreamDemo1 {
public static void main(String[] args) {
// TODO Auto-generated method stub
InputStream in = null;
try {
File file = new File("d:/log/info.2025-07-21.log");
in = new FileInputStream(file);//通过 file 对象创建文件输入流,向上转型
int b;//用于接收读到的字节
//循环读取一个节点,赋予 b 的低8位,忽略高位,没有到达流的末尾(-1)继续读
while((b = in.read()) != -1) {
//把读到的b强转为 char 类型(字符类型) 来显示
System.out.print((char)b);
}
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}finally {
if(in != null) {
try {
in.close();//不管是否发生异常,始终要关闭输入流
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
}
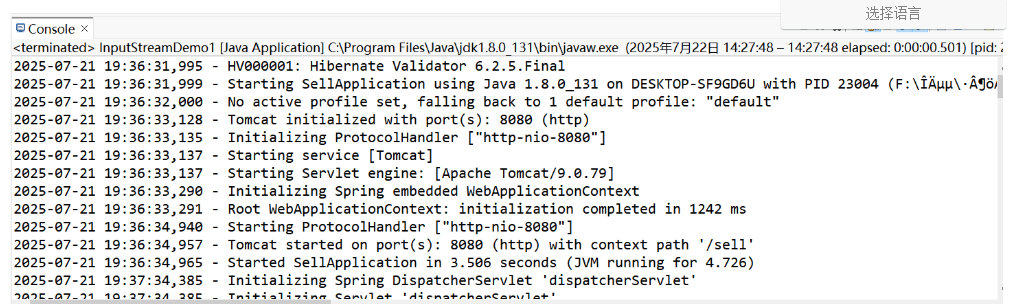
示例2:
package com.edu.io;
package com.edu.io;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStream;
public class InputStreamDemo2 {
public static void main(String[] args) {
// TODO Auto-generated method stub
InputStream in = null;
try {
File file = new File("d:/log/info.2025-07-21.log");
in = new FileInputStream(file);//通过 file 对象创建文件输入流,向上转型
byte[] buf = new byte[1024];//用于读取数据的缓冲区,1K
int len = 0;//表示实际读到的字节数
StringBuffer sb = new StringBuffer();//用于接收读到的数据
//每次将数据读到 buf 中,实际读到的字节数为 len,没有读到流的末尾(-1)继续循环读
while((len = in.read(buf)) != -1) {
//将读到的数据 buf,以及偏移量 0,和实际读到的字节数 len ,还有字符编码传给 String 来构造一个字符串
//再将构造的这个字符串附加到 s 字符串中
sb.append(new String(buf, 0, len, "UTF-8"));
System.out.print(sb.toString());
}
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}finally {
if(in != null) {
try {
in.close();//不管是否发生异常,始终要关闭输入流
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
}
我们读取的文件:info.2025-07-21.log,保存的时候指定的编码是 UTF-8,我们读取出来之后编码成字符串时也是 UTF-8,此时就不会出现中文乱码,文件的中文字符也能正确显示出来。
3) Reader:字符输入流的抽象基类,典型的实现有 FileReader 等
a. 常用方法
int read():读取单个字符(2个字节),作为整数读取的字符,放到低16位字节,忽略高位,返回值是0~65535之间,如果读到流的末尾,返回-1
int read(char[] buf):读取字符到字符数组buf中,如果读到流末尾,返回-1,否则返回实际读到的字符数
int read(char[] buf,int off,int len):从偏移量off位置开始一次读取len长度的数据到buf中,读到流的末尾返回-1,否则返回实际读到的字符数。
示例1:
package com.edu.io;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.io.Reader;
public class ReaderDemo1 {
public static void main(String[] args) {
// TODO Auto-generated method stub
Reader reader = null;
try {
reader = new FileReader("d:/p.txt");
int c;//实际读到的字符
//循环读取一个字符,放在 c 的低16位,没有到达流的末尾(-1)继续读
while((c = reader.read()) != -1) {
System.out.print((char)c);//将每次读到的字符强转为char字符输出
}
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}finally {
if(reader != null) {
try {
reader.close();//关闭字符输入流
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
}
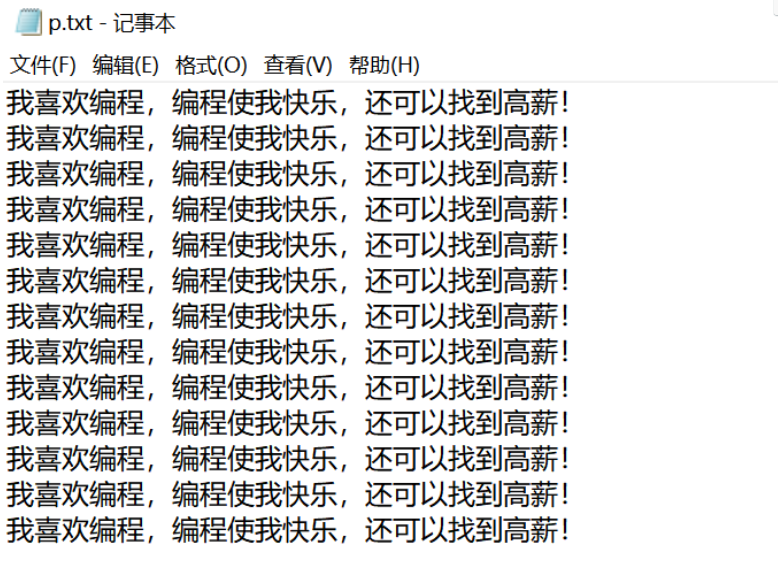
示例2:
package com.edu.io;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.io.Reader;
public class ReaderDemo2 {
public static void main(String[] args) {
// TODO Auto-generated method stub
Reader reader = null;
try {
reader = new FileReader("d:/p.txt");
char[] buf = new char[1024];//用于保存数据的字符缓冲区
int len;//实际读到的字符数
StringBuffer sb = new StringBuffer();
//一次读取 buf 的数据,len 表示实际读到的字符数,没有到达流的末尾(-1)继续循环读
while((len = reader.read(buf)) != -1) {
//将包含数据的 buf,每次的偏移量0,以及实际读到的字符数 len,传给 String 构造一个 String 对象,然后
//再附加给 StringBuffer
sb.append(new String(buf, 0, len));
System.out.print(sb.toString());
}
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}finally {
if(reader != null) {
try {
reader.close();//关闭字符输入流
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
}

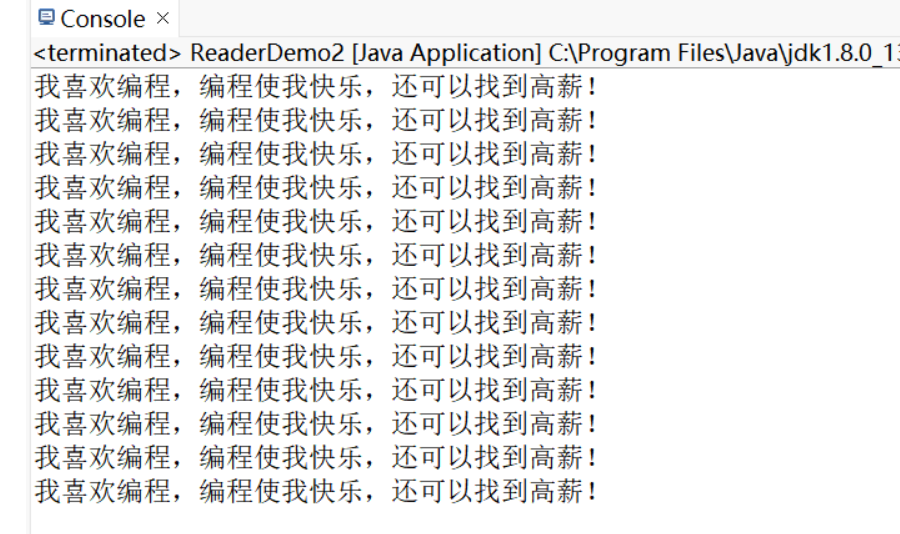
使用带缓冲(buf)的读比一个一个字符读的效率高,因为每读一次数据就会有一次磁盘的IO操作,这个IO操作是比较消耗资源的,很明显,带缓冲的读的磁盘IO次数会小于一个一个的读。
(8)OutputStream 和 Writer
1) OutputStream:字节输出流,把程序(内存中)的数据写入到外部设备中,典型的实现就是 FileOutputStream。
2) 常用的方法:
public void write(int b):向输出流输出一个字节,要写入的字节放在 int 的低 8 位,忽略高 24 位字节
public void write(byte[] b):将 b.length 长度的字节数组数据写入输出流。
public void write(byte[] b,int off,int len):从 off 的偏移量开始一次性写入 len 长度的 byte类型的数组数据到输出流
public void flush() throws IOException:刷新流,迫使输出缓冲区的数据全部写出,缓冲区的特点是缓冲区满了之后才会写入到对应设备。
public void close() throws IOException:刷新缓冲区并关闭输出流。
注意:如果在使用输出流写完数据之后没有调用flush()或close()方法,那么写出的数据有可能会出问题,原因就是可能还有部分数据在内部的缓冲区中没有写出。
示例:拷贝文件
package com.edu.io;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
public class CopyFile {
public static void main(String[] args) {
// TODO Auto-generated method stub
InputStream in = null;
OutputStream out = null;
try {
in = new FileInputStream("d:/p.txt");
File f = new File("f:/test.txt");
if(!f.exists()) {
f.createNewFile();
}
out = new FileOutputStream(f);//通过文件f创建输出流 out,向上转型
//定义接收数据的缓冲区
byte[] buf = new byte[1024];
int len = 0;//实际读到的字节数
//每次读取数据放入 buf,len 为实际读到的字节数,没有达到流的末尾(-1)就继续循环读
while((len = in.read(buf)) != -1) {
//每次写的时候从数据buf的偏移量0开始,写出的字节数就是上面读到实际字节数len
out.write(buf, 0, len);
}
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}finally {
if(in != null) {
try {
in.close();//关闭输入流
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
if(out != null) {
try {
out.close();//刷新流并关闭输出流
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
}
示例2:拷贝图片,注意:在拷贝图片,声音,视频,可执行程序等二进制文件的时候(即非文本文件),只能使用字节流来处理,不能使用字符流来处理,因为字符流是用于处理文本文件。
package com.edu.io;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
public class CopyFile {
public static void main(String[] args) {
// TODO Auto-generated method stub
InputStream in = null;
OutputStream out = null;
try {
in = new FileInputStream("C:\\Users\\Think\\Desktop\\temp\\images\\1.jpg");
File f = new File("f:/test.jpg");
if(!f.exists()) {
f.createNewFile();
}
out = new FileOutputStream(f);//通过文件f创建输出流 out,向上转型
//定义接收数据的缓冲区
byte[] buf = new byte[1024];
int len = 0;//实际读到的字节数
//每次读取数据放入 buf,len 为实际读到的字节数,没有达到流的末尾(-1)就继续循环读
while((len = in.read(buf)) != -1) {
//每次写的时候从数据buf的偏移量0开始,写出的字节数就是上面读到实际字节数len
out.write(buf, 0, len);
}
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}finally {
if(in != null) {
try {
in.close();//关闭输入流
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
if(out != null) {
try {
out.close();//刷新流并关闭输出流
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
}
3) Writer:字符输出的抽象基类,典型的实现有 FileWriter
a. 常用方法
public void write(int c):写入单个字符,这个字符位于int类型参数c的低16位字节,忽略高16位。
public void write(char[] buf):写出字符数组
public void write(char[] buf,int off,int len):从buf的偏移量off写出len长度的字符数组数据
public void write(String str):写出字符串
public void write(String str,int off,int len):写出字符串的某一部分内容
public void flush():刷新流
public void close():刷新流并关闭流。
示例:拷贝文件
package com.edu.io;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
import java.io.Reader;
import java.io.Writer;
public class WriterDemo {
public static void main(String[] args) {
// TODO Auto-generated method stub
Reader reader = null;
Writer writer = null;
try {
reader = new FileReader("d:/p.txt");
writer = new FileWriter("f:/p.txt");
char[] buf = new char[1024];
int len = 0;
while((len = reader.read(buf)) != -1) {
//writer.write(buf, 0, len);
//通过buf,偏移量0,实际读到的长度len构造字符串s
String s = new String(buf, 0, len);
writer.write(s);//直接将s写出去
}
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}finally {
if(writer != null) {
try {
writer.close();//刷新流并关闭输出流
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
if(reader != null) {
try {
reader.close();//关闭输入流
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
}
(9)缓冲流(带 buf 的流):处理流
1)为了提高读写数据的速度,IO 流提供了带缓冲的流,使用的时候,会在其内部创建一个缓冲数组,默认大小是8192 字节,即 8K 的缓冲区(如果一个字节一个字节的读,必然存在多次 IO 操作,性能比较低,如果带缓冲区,一次 IO 操作就可以处理多个数据到缓冲区,性能比较好)。
2)缓冲流属于处理流,自己不会直接去操作设备,而是建立在其他流的基础之上进行数据的高效读写。
3)常见的缓冲流有:
a. 字节缓冲流:BufferedInputStream 和 BufferedOutputStream
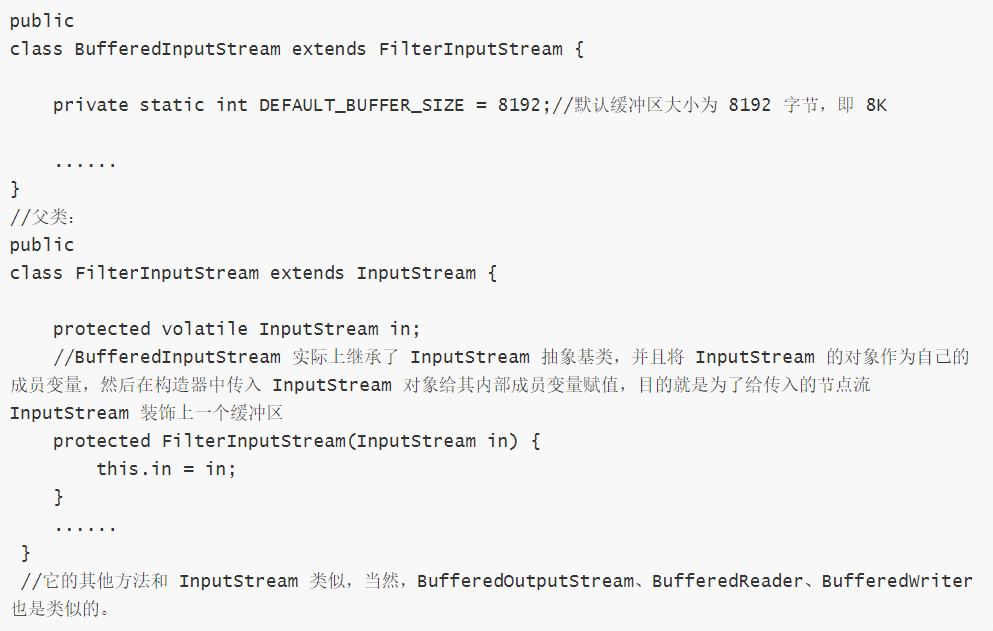
b. 字符缓冲流:BufferedReader 和 BufferedWriter
查看源码:
示例:
package com.edu.io;
import java.io.BufferedInputStream;
import java.io.BufferedOutputStream;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
public class BufferedInputStreamDemo {
public static void main(String[] args) {
// TODO Auto-generated method stub
BufferedInputStream bis = null;
BufferedOutputStream bos = null;
try {
bis = new BufferedInputStream(new FileInputStream("d:/p.txt")); //传入一个节点流给带缓冲的输入流
bos = new BufferedOutputStream(new FileOutputStream("f:/p.txt")); //传入一个节点流给带缓冲的输出流
byte[] buf = new byte[1024];
int len = 0;
while((len = bis.read(buf)) != -1) {
bos.write(buf, 0, len);
}
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}finally {
//关闭时只需要关闭处理流即可,节点流自动关闭
if(bis != null) {
try {
bis.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
if(bos != null) {
try {
bos.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
}
注意:我们在关闭流的时候只需要关闭处理流,节点流会自动关闭,原因是,我们可以分析 BufferedInputStream 的 close() 方法的源码:

示例2:BufferedReader 和 BufferWriter
package com.edu.io;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
public class BufferedReaderDemo {
public static void main(String[] args) {
// TODO Auto-generated method stub
//处理流:字符缓冲流
BufferedReader br = null;
BufferedWriter bw = null;
try {
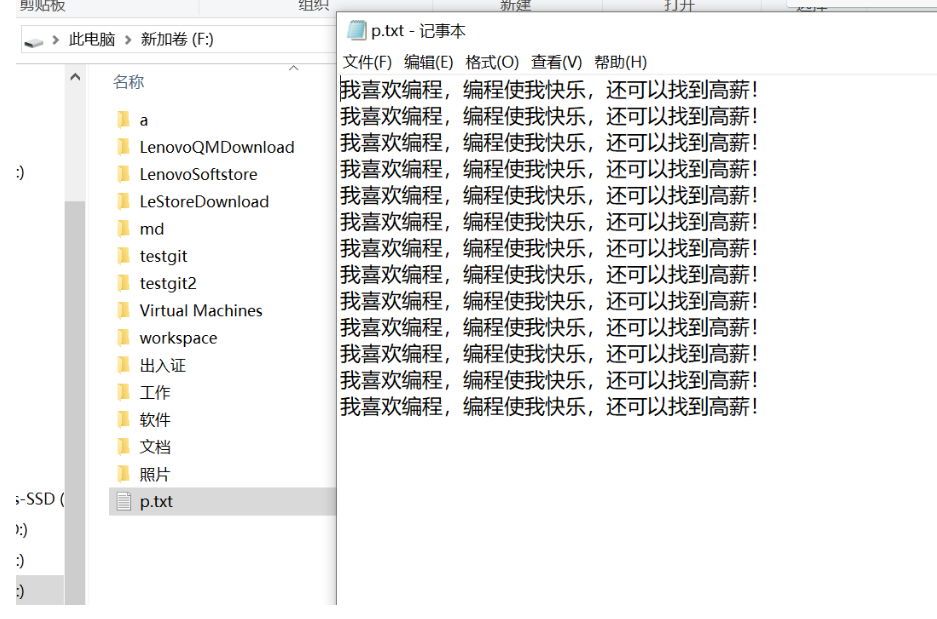
br = new BufferedReader(new FileReader("d:/p.txt"));//传入一个节点流给带缓冲的输入流装饰上缓冲区
bw = new BufferedWriter(new FileWriter("f:/b.txt"));//传入一个节点流给带缓冲的输出流装饰上缓冲区
String str = null;
/**
* BufferedReader 除了具有 Reader 的所有方法外,还有一个 String readLine() 方法,表示每次读取一行数据,
* 读到流的末尾返回 null
*/
while((str = br.readLine()) != null) {//每次读取一行内容,没有到达流的末尾(null)继续循环读
//一次写一行文本
bw.write(str);
//每写完一行要写出一个换行符
bw.newLine();
}
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}finally {
if(br != null) {
try {
br.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
if(bw != null) {
try {
bw.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
}
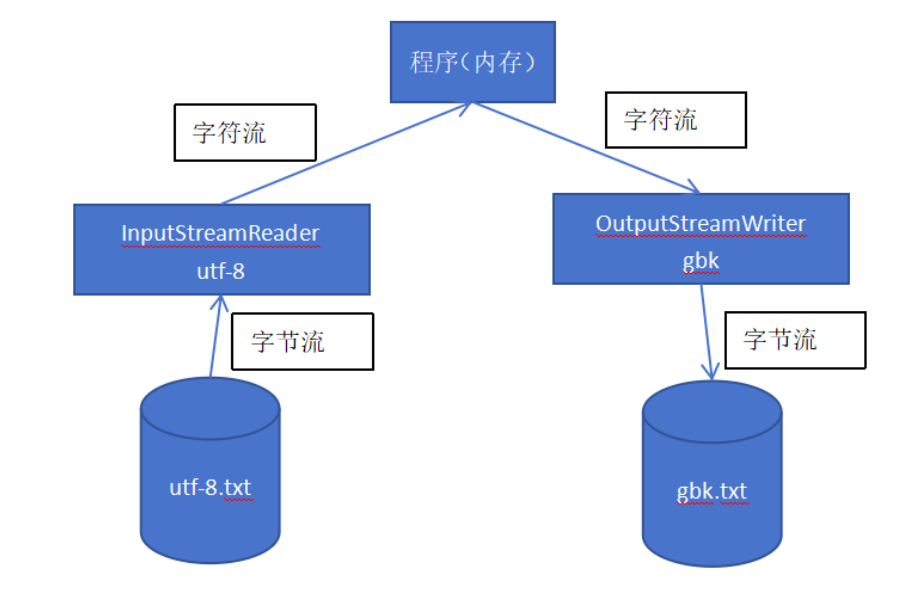
(10)转换流:InputStreamReader 和 OutputStreamWriter
① 转换流提供字节流到字符流的转换,比如将 InputStream 转换为 Reader,将 OutputStream 转换为 Writer,当字节流中的数据都是字符数据的时候,转换成字符流操作更高效。
② 转换流还有一个功能就是在读写的时候可以指定字符编码,实现编码和解码的功能。
③ InputStreamReader
1)构造器
public InputStreamReader(InputStream in)
public InputStreamReader(InputStream in, String charsetName)
2)方法同 Reader
④ OutputStreamWriter
3)构造器
public OutputStreamWriter(OutputStream out)
public OutputStreamWriter(OutputStream out, String charsetName)
4)方法同 Writer
⑤ 转换流的示意图:
示例:
package com.edu.io;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.OutputStream;
import java.io.OutputStreamWriter;
import java.io.UnsupportedEncodingException;
public class ConversionStreamDemo {
public static void main(String[] args) {
// TODO Auto-generated method stub
BufferedReader br = null;
BufferedWriter bw = null;
try {
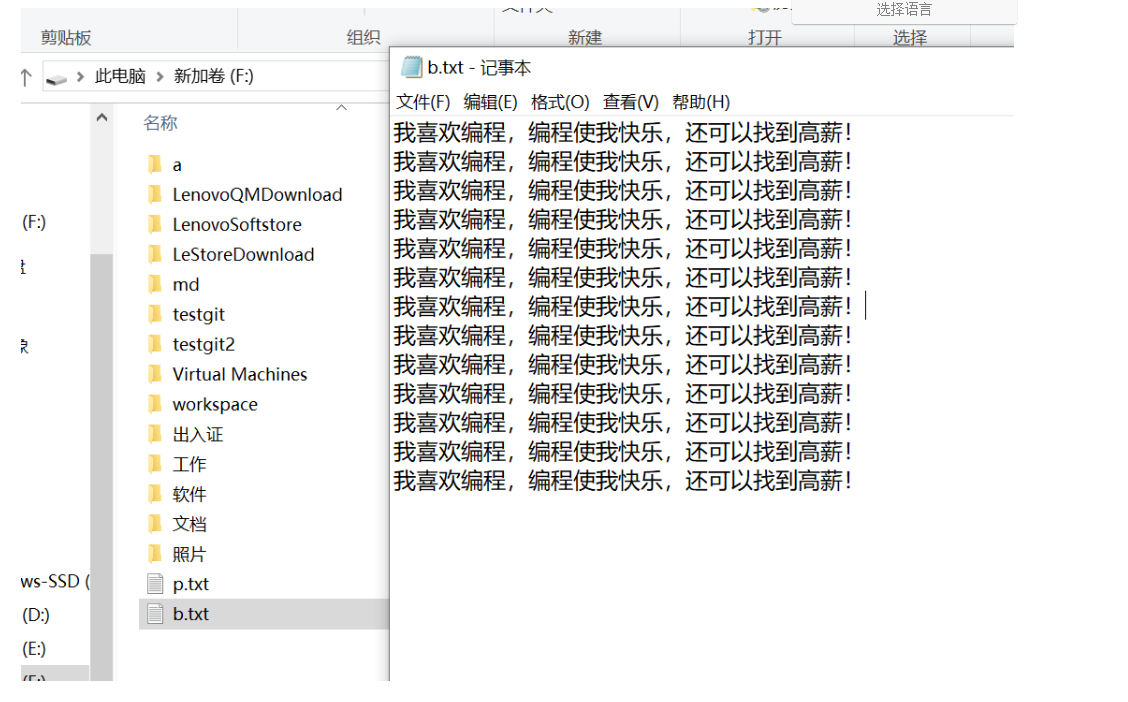
InputStream in = new FileInputStream("d:/p.txt");//文件字节输入流
OutputStream out = new FileOutputStream("f:/c.txt");//文件字节输出流
//转换流继承了 Reader 或 Writer
//将字节输入流转换为字符输入流,并指明字符编码为 UTF-8,因为此时p.txt文件的字符编码就是 UTF-8
InputStreamReader isr = new InputStreamReader(in, "UTF-8");
//将字节输出流转换为字符输出流,并指明当前的字符编码为GBK,所以生成的"f:/c.txt"文件的编码就成了 GBK
OutputStreamWriter osw = new OutputStreamWriter(out, "GBK");
//为了高效的读写,我们使用缓冲流
br = new BufferedReader(isr);//InputStreamReader继承了 Reader,所以可以将 isr 对象传进去,是向上转型
bw = new BufferedWriter(osw);//OutputStreamWriter继承了 Writer,所以可以将 osw 对象传进去,是向上转型
String str = null;
while((str = br.readLine()) != null) {//每次读取一行文本,没有读到流的末尾(null)继续循环读
bw.write(str);//写出一行文本
bw.newLine();//写出换行
}
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (UnsupportedEncodingException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}finally {
//只需要关处理流,节点流自动关闭
if(br != null) {
try {
br.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
if(bw != null) {
try {
bw.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
}
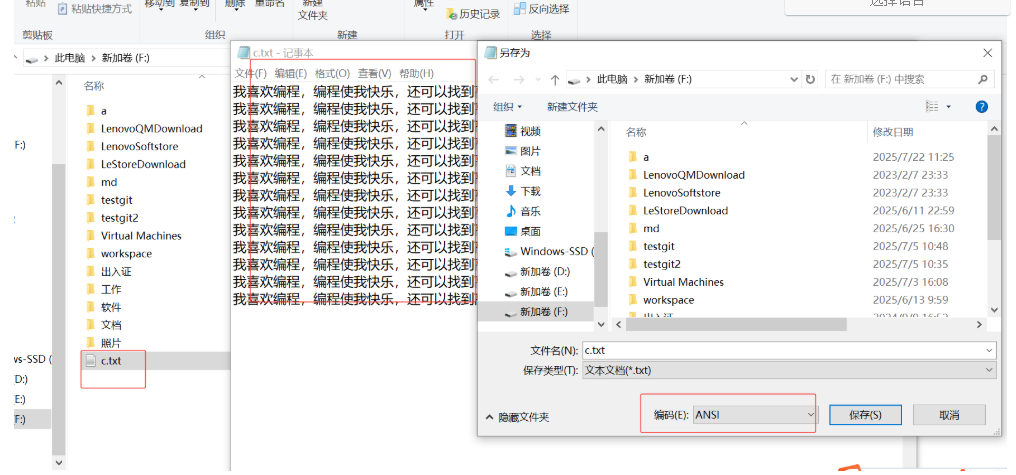
写出的文件c.txt 的编码为 ANSI,因为 GBK 就是 ANSI 字符集的一个子集。
(11)补充知识:字符编码
① 编码表的由来:计算机只能识别二进制数据,为了方便应用计算机,让它可以表示世界上各个国家的文字和符号,就将各个国家的文字和符号用数字来表示,并一一对应,形成一张表,称为编码表。
② 常见的编码表
1) ASCII:美国标准信息交换码,用一个字节的7位来表示
2) ISO8859_1:拉丁码表,欧洲码表,用一个字节的8位来表示,支持英文,不支持中文。
3) GBK:中国中文编码升级表,融合了更多的中文符号,最多两个字节编码,其中 GB2312 和 GBK 统称为 ANSI字符集。
4) Unicode:国际标准码,融合了目前人类使用的所有字符,为每个字符分配唯一的字符码,所有文字都使用两个字节来表示。
5) UTF-8:变长的编码方式,使用 1~4 个字节来表示一个字符
Unicode 编码设计不完美,主要有三个问题:一是英文字符只需要一个字节表示即可,第二个问题是如何才能区别 Unicode 和 ASCII,计算机如何才能知道两个字节表示一个字符还是两个字节分别表示两个字符,第三,如果和GBK 等双字节编码方法一致,最高位用1或0来表示两个字节或一个字节,就少了很多值来表示更多的字符,Unicode 字符集很长一段时间得不到推广,直到互联网的出现。
面向传输的 UTF 标准出现,所谓 UTF-8 即指每次传输 8 个位的数据,UTF-16 就是每次传输 16 个位的数据,这种编码是专用用于传输而设计,使编码无国界,可以显示世界上任何一个国家的文字符号,所以建议使用 UTF-8 编码格式,而 Unicode 字符集类似于 ANSI 字符集,是对 UTF-8 或 UTF-16 的一个统称,UTF-8 还有一个名字叫做万国码,缺点就是比较占用空间。
(12)System.in 和 System.out
① System.in 和System.out 分别代表系统标准输入和标准输出设备,默认是键盘和显示器。
② System.in 的类型是 InputStream 类型
③ System.out 的类型是 PrintStream 类型,是 OutputStream 的子类,也是 FilterOutputStream 的子类
④ 可以通过 System 类的 SetIn 和 SetOut 方法对默认的设备进行重定向(改变输出位置)
public static void setIn(InputStream in);
public static void setOut(OutputStream out);
示例:

(13)打印流:实现基本数据类型的数据格式化为字符串输出
① 分为 PrintStream(字节打印流)和 PrintWriter(字符打印流)
都提供了一系列的 print() 和 println() 重载方法,用于输出各种数据类型的数据,而且两个都具有自动 flush() 的功能(注意,自动刷新功能需要在其构造器中传入一个 boolean 类型参数说明是否要自动刷新缓冲区)。
autoFlush 传入 true 则会自动刷新缓冲区,源码:

PrintStream 和 PrintWriter 跟 BufferedOutputStream 等缓冲流一样,它们的内部也具有缓冲区,读写效率也比较高。
示例:输出 ASCII 码的字符到文件中
package com.edu.io;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.OutputStream;
import java.io.PrintStream;
public class PrintStreamDemo {
public static void main(String[] args) {
// TODO Auto-generated method stub
PrintStream ps = null;
try {
OutputStream out = new FileOutputStream("f:/test.txt");
///创建一个可自动刷新带缓冲的 PrintStream,第一个参数是字节输出流,第二个参数是自动刷新缓冲区
ps = new PrintStream(out, true);
System.setOut(ps);//将默认的输出位置改为输出到"f:/test.txt"
for (int i = 0; i <= 127; i++) {
System.out.print((char)i);//将 i 转换为 char 类型的 ASCII 码输出
if(i % 50 == 0) {//每 50 个字符换一行
System.out.println();
}
}
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}finally {
if(ps != null) {
ps.close();
}
}
}
}
练习:使用 PrintStream 输出各种数据类型的数据到文件中
(14)对象流:ObjectInputStream 和 ObjectOutputStream
① 作用:用于存储或读取基本数据类型数据或对象(因为其包含了很多读写基本数据类型和对象数据的方法)的处理流,它的强大的地方是可以将 Java 对象写入文件,也可以从文件中读出对象,这个过程称为序列化和反序列化。
② ObjectInputStream 和 ObjectOutputStream 不能序列化 static 和 transient 类型的成员变量。
③ 使用对象流序列化对象
1)如果某个类实现了 Serializable 接口,那么该类就可以序列化。注意:如果某个类的属性不是基本数据类型或String 类型,而是另一个引用数据类型,那么这个引用数据类型的成员变量对应的类也必须可序列化(即实现了Serializable 接口),否则用于该类型的成员变量不能序列化。
例如:

示例:对象的序列化和反序列化
Person.java:
package com.edu.io;
import java.io.Serializable;
public class Person implements Serializable{ //实现 Serializable 表示可序列化
private int id;
private String name;
private int age;
private double sal;
public Person() {
// TODO Auto-generated constructor stub
}
public Person(int id, String name, int age, double sal) {
super();
this.id = id;
this.name = name;
this.age = age;
this.sal = sal;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public double getSal() {
return sal;
}
public void setSal(double sal) {
this.sal = sal;
}
@Override
public String toString() {
return "Person [id=" + id + ", name=" + name + ", age=" + age + ", sal=" + sal + "]";
}
}
SerializableDemo.java:
package com.edu.io;
package com.edu.io;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.io.OutputStream;
public class SerializableDemo {
public static void main(String[] args) {
// TODO Auto-generated method stub
//对象流(处理流)
ObjectInputStream ois = null;
ObjectOutputStream oos = null;
try {
OutputStream out = new FileOutputStream("f:/person.ser"); //创建文件输出流,向上转型
//使用 out 对象创建对象输出流
oos = new ObjectOutputStream(out);
/**
* ObjectOutputStream 有多个重载的 writeXXX() 方法,其中 XXX 代表各种数据类型,可以写出多种数据类型的数据
*/
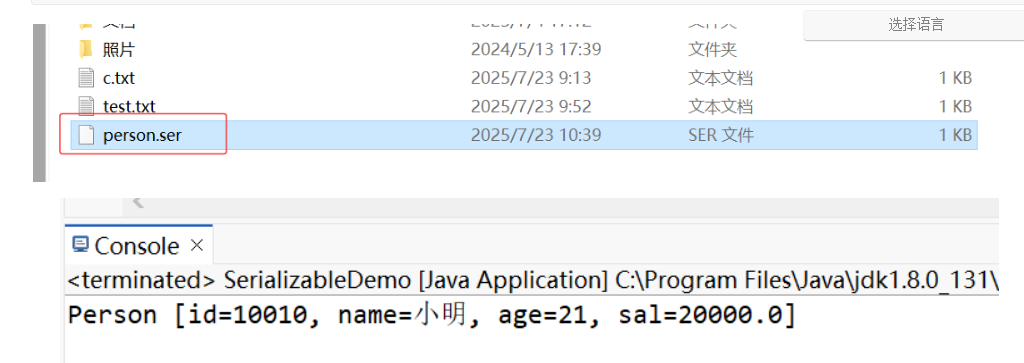
//序列化:调用 ObjectOutputStream 的 writeObject() 方法来序列化
oos.writeObject(new Person(10010, "小明", 21, 20000));
InputStream in = new FileInputStream("f:/person.ser");
//通过 in 对象创建对象输入流
ois = new ObjectInputStream(in);
/**
* ObjectInputStream 包含多个 readXXX() 方法,其中 XXX 代表各种数据类型,可以读取多种数据类型的数据
*/
//反序列化:调用 ObjectInputStream 的 readObject() 方法读取已经序列化的对象进行反序列化
Person person = (Person)ois.readObject();
System.out.println(person);
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (ClassNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}finally {
//关闭时只需要关闭处理流,节点流自动关闭
if(ois != null) {
try {
ois.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
if(oos != null) {
try {
oos.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
}
使用序列化的好处:
实现了 Serializable 接口的对象,可以将其转换为一系列的字节,并且可以在以后完整恢复成原来的样子,这个过程也可以通过网络进行,我们可以在 Windows 系统上创建一个对象,将其序列化,然后通过网络将序列化文件发送给一台 Linux 系统,然后通过反序列化得到该对象,我们不用关心数据在不同系统上如何表示,也不必关心字节的顺序或其他细节。
由于大部分类诸如 String 和 Integer等包装类都已经实现了 java.io.Serializable 接口,所以这种类型的数据作为类的成员变量就可以序列化。
④ 瞬态关键字 transient
当一个类的对象需要被序列化时,某些属性不需要被序列化,这时不需要序列化的属性可以使用关键字 transient修饰。只要被 transient 修饰了,序列化时这个属性就不会序列化了。
同时静态(static)修饰也不会被序列化,因为序列化是把对象数据进行持久化存储,而静态的属于类加载时的数据,不会被序列化。
代码修改如下,修改后再次写入对象,读取对象测试:
package com.edu.io;
package com.edu.io;
import java.io.Serializable;
public class Person implements Serializable{ //实现 Serializable 表示可序列化
private int id;
private static String name;//静态的
private transient int age;//瞬态的
private double sal;
public Person() {
// TODO Auto-generated constructor stub
}
public Person(int id, String name, int age, double sal) {
super();
this.id = id;
this.name = name;
this.age = age;
this.sal = sal;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public double getSal() {
return sal;
}
public void setSal(double sal) {
this.sal = sal;
}
@Override
public String toString() {
return "Person [id=" + id + ", age=" + age + ", sal=" + sal + "]";
}
}
测试代码不变,测试结果:

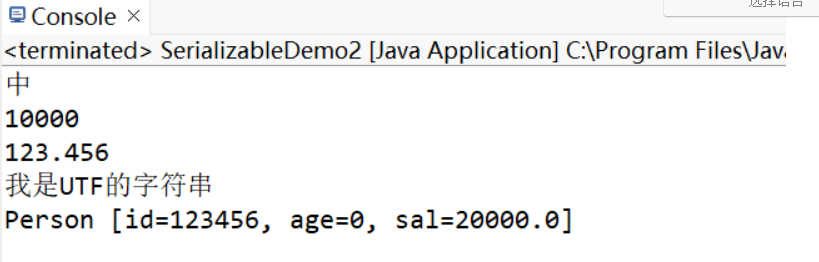
示例3:ObjectInputStream 包含多个 readXXX() 方法,可以读取各种类型的数据,ObjectOutputStream 也包含多个 writeXXX() 方法,可以写出各种类型的数据。
package com.edu.io;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.io.OutputStream;
public class SerializableDemo2 {
public static void main(String[] args) {
// TODO Auto-generated method stub
//对象流
ObjectInputStream ois = null;
ObjectOutputStream oos = null;
try {
//序列化
OutputStream out = new FileOutputStream("f:/oject.txt");
oos = new ObjectOutputStream(out);
oos.writeChar('中');
oos.writeInt(10000);
oos.writeDouble(123.456);
oos.writeUTF("我是UTF的字符串");
oos.writeObject(new Person(123456, "", 20, 20000));
//反序列化
InputStream in = new FileInputStream("f:/oject.txt");
ois = new ObjectInputStream(in);
System.out.println(ois.readChar());
System.out.println(ois.readInt());
System.out.println(ois.readDouble());
System.out.println(ois.readUTF());
System.out.println(ois.readObject());
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (ClassNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}finally {
//关闭时只需要关闭处理流,节点流自动关闭
if(ois != null) {
try {
ois.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
if(oos != null) {
try {
oos.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
}
5. 装饰器设计模式
(1) 装饰器设计模式的概念
1) 装饰器设计模式是在不改变原来的被装饰的类和使用继承的情况下,动态的扩展一个对象的功能,提供了比继承更多的灵活性。
2) 我们通过一个示例来掌握装饰器设计模式:
package com.edu.io;
public class DecorationDemo {
public static void main(String[] args) {
// TODO Auto-generated method stub
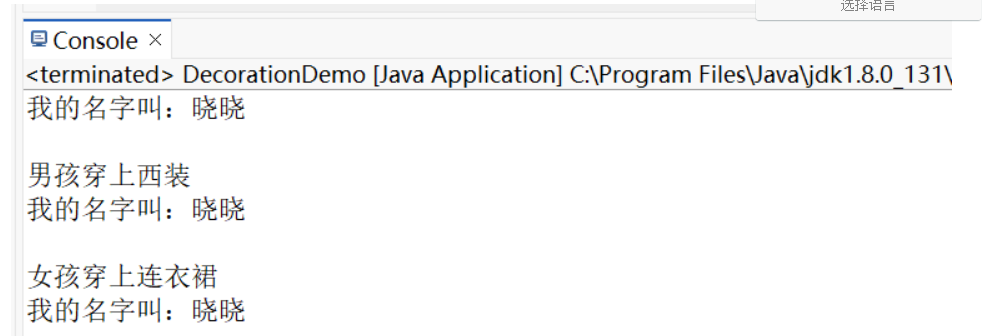
//创建没有被装饰的 Person 对象
Person person = new Person("晓晓");//类似于没有被 BufferedInputStream 装饰的 InputStream 对象
person.introduce();//没有被装饰的方法
System.out.println();
//对基础对象进行装饰
Boy boy = new Boy(person);
//通过已经装饰后的 boy 来调用方法,那么这个方法就是被装饰后的方法
boy.introduce();//相当于在调用 BufferedInputStream 的带缓冲的 read() 方法
System.out.println();
Girl girl = new Girl(person);
girl.introduce();
}
}
//人类
class Person {
private String name;
public Person() {
// TODO Auto-generated constructor stub
}
public Person(String name) {
super();
this.name = name;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public void introduce() {
System.out.println("我的名字叫:" + name);
}
@Override
public String toString() {
return "Person [name=" + name + "]";
}
}
//装饰器的抽象父类
abstract class Decorator {
//1. 装饰器内部要将被装饰的类作为自己的成员变量
private Person person;
public Decorator() {
// TODO Auto-generated constructor stub
}
public Decorator(Person person) {
super();
this.person = person;
}
public void introduce() {
person.introduce();
}
}
/**
* 定义装饰器类,它的特点:首先要继承装饰器的抽象父类,并且将被装饰的对象作为构造器参数以便在其内部进行装饰
*/
//男孩类
class Boy extends Decorator{
//类似于IO流中的 BufferedInputStream(InputStream in),缓冲流就是用到了装饰器设计模式
public Boy(Person person) {
super(person);
}
//进行装饰:比如穿上衣服
public void wear() {
System.out.println("男孩穿上西装");
}
@Override
public void introduce() {
// TODO Auto-generated method stub
wear();//对原来没有装饰的 introduce() 方法进行装饰,即穿上西装
super.introduce();
}
}
/**
* 定义装饰器类,它的特点:首先要继承装饰器的抽象父类,并且将被装饰的对象作为构造器参数以便在其内部进行装饰
*/
//女孩类
class Girl extends Decorator{
//类似于IO流中的 BufferedInputStream(InputStream in),缓冲流就是用到了装饰器设计模式
public Girl(Person person) {
super(person);
}
//进行装饰:比如穿上衣服
public void wear() {
System.out.println("女孩穿上连衣裙");
}
@Override
public void introduce() {
// TODO Auto-generated method stub
wear();//对原来没有装饰的 introduce() 方法进行装饰,即穿上西装
super.introduce();
}
}
装饰器设计模式的使用场景:
优点:
1. 需要扩展一个类的功能的时候可以使用装饰器
2. 动态的为一个对象增加功能,还可以动态的撤消功能,继承是无法做到的
缺点:
这种方式比继承更有灵活性,也意味着有更多的复杂性,装饰器设计模式会导致设计中出现许多小类,如果过度的使用,会使程序变的复杂。