【大模型文生图、文生音频实战Demo】基于Spring AI Alibaba和阿里百炼大模型实现文生图、文生视频
文章目录
- 大模型实现文生图
- 大模型实现文生音频
大模型实现文生图
使用阿里百炼大模型-wanx2.1-t2i-turbo,作为文生图调用的大模型
- 代码
@RestController
public class ImageModelController {private final ImageModel imageModel;ImageModelController(@Qualifier("dashScopeImageModel") ImageModel imageModel) {this.imageModel = imageModel;}@RequestMapping("/image")public String image(String input) {ImageOptions options = ImageOptionsBuilder.builder().model("wanx2.1-t2i-turbo").height(1024).width(1024).build();ImagePrompt imagePrompt = new ImagePrompt(input, options);ImageResponse response = imageModel.call(imagePrompt);String imageUrl = response.getResult().getOutput().getUrl();return "redirect:" + imageUrl;}
}
model指定模型,再指定生成图片的宽高
- postman调用接口
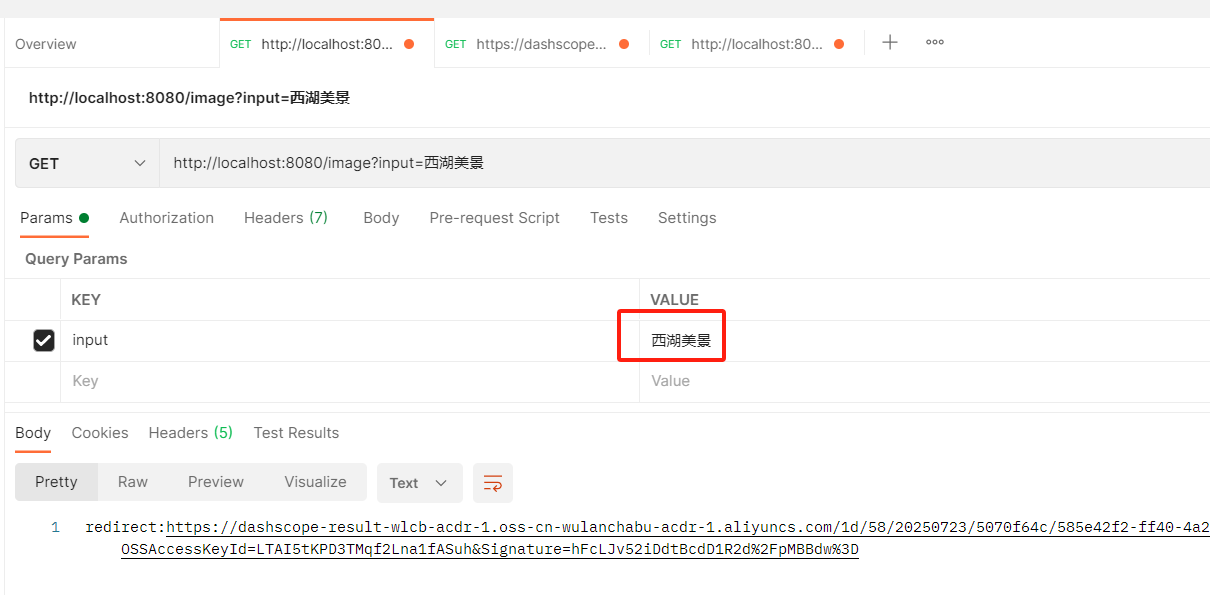
点击链接打开,下载图片可查看
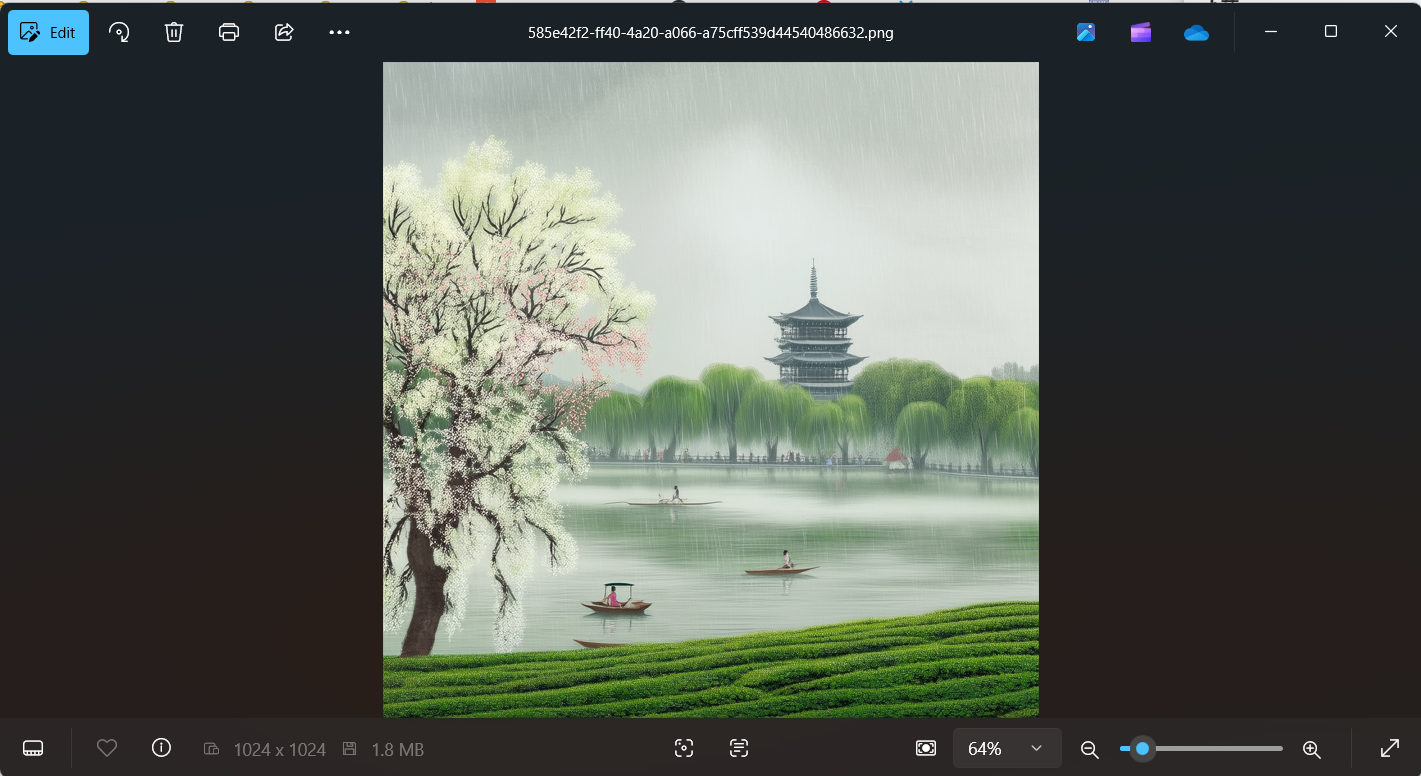
雨西湖,雷峰塔哈哈哈有品位
大模型实现文生音频
- 代码
@RestController
@RequestMapping("/audio")
public class AudioModelController {private final SpeechSynthesisModel speechSynthesisModel;@Autowiredpublic AudioModelController(SpeechSynthesisModel speechSynthesisModel) {this.speechSynthesisModel = speechSynthesisModel;}@GetMapping("/synthesize")public ResponseEntity<byte[]> synthesizeSpeech(@RequestParam String text) throws IOException {// 构建语音合成请求SpeechSynthesisPrompt prompt = new SpeechSynthesisPrompt(text);// 调用模型生成语音SpeechSynthesisResponse response = speechSynthesisModel.call(prompt);ByteBuffer audioData = response.getResult().getOutput().getAudio();// 将 ByteBuffer 转换为字节数组byte[] audioBytes = new byte[audioData.remaining()];audioData.get(audioBytes);// 返回音频流(MP3格式)return ResponseEntity.ok().contentType(MediaType.APPLICATION_OCTET_STREAM).header("Content-Disposition", "attachment; filename=output.mp3").body(audioBytes);}}
- 网页访问调用
http://localhost:8080/audio/synthesize?text=你好
下载后可以得到对应文本的音频
以上,完成了用Spring AI Alibaba和调用各类大模型的方式,实现了文生图和文生音频!