OneTwoVLA——基于π0实现类π0.5:一个模型中完成原来双系统下的慢思考、快执行,且具备自适应推理能力和自我纠错能力
前言
我们在实际实验的过程中,发现openpi的指令遵循能力较弱,当然,PI公司在他们「π0.5的KI改进版」的技术报告中 也明确指出了这一点
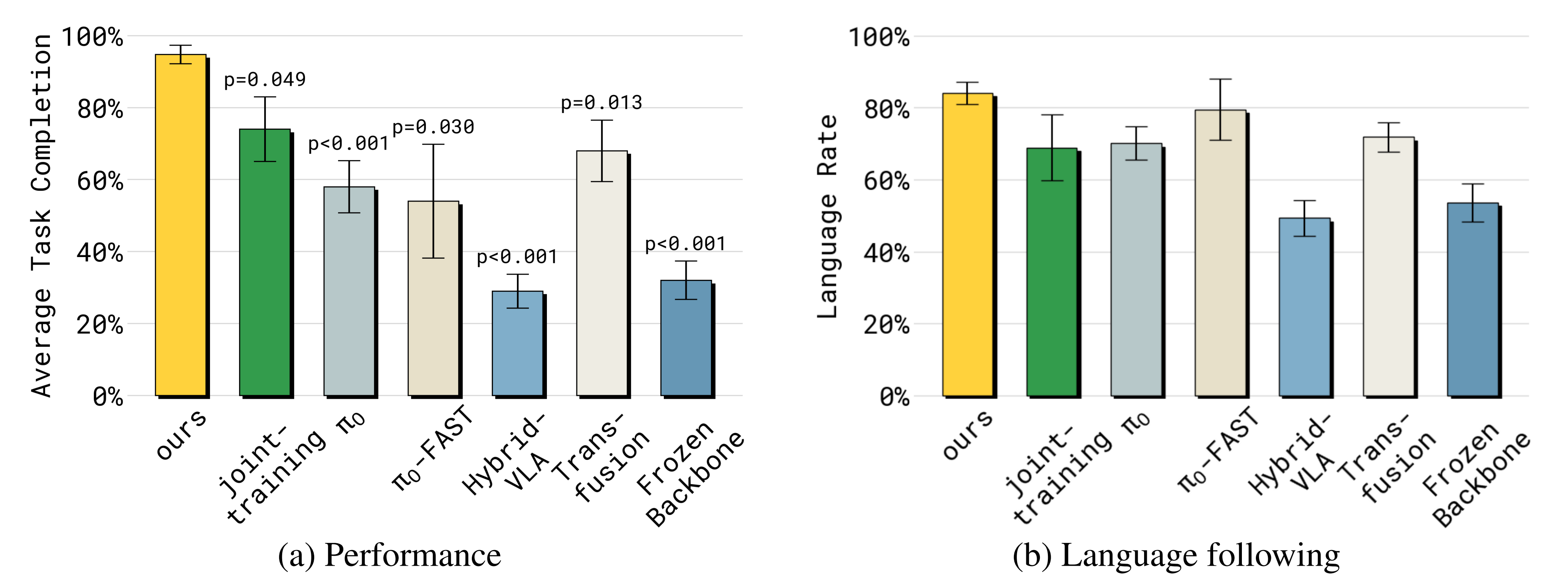
然无论是π0.5,还是π0.5的KI改进版,截止到25年7.23日,它两都没开源
但现实中,还是有不少语言交互的场景,故便关注到了本文要介绍的OneTwoVLA
更何况越来越多的中国具身er看我博客,让我更新博客的动力也就越来越大了
第一部分
1.1 引言、相关工作
1.1.1 引言
如原论文所说,人类物理智能的一个显著特征是能够同时进行推理和行动[1,2]。关键在于,这两个过程并非彼此独立,而是灵活地交替进行,从而形成强大的协同效应——推理指导我们的行动,而行动又为后续的推理提供反馈
以烹饪为例
- 推理使人能够制定全面的对场景和目标的理解(例如,解读食谱、规划步骤顺序)属于推理范畴
- 而执行则对应于实际操作(例如,切菜、搅拌),将抽象推理落实到现实世界中
OneTwoVLA旨在赋予机器人类似于推理与执行协同作用的能力
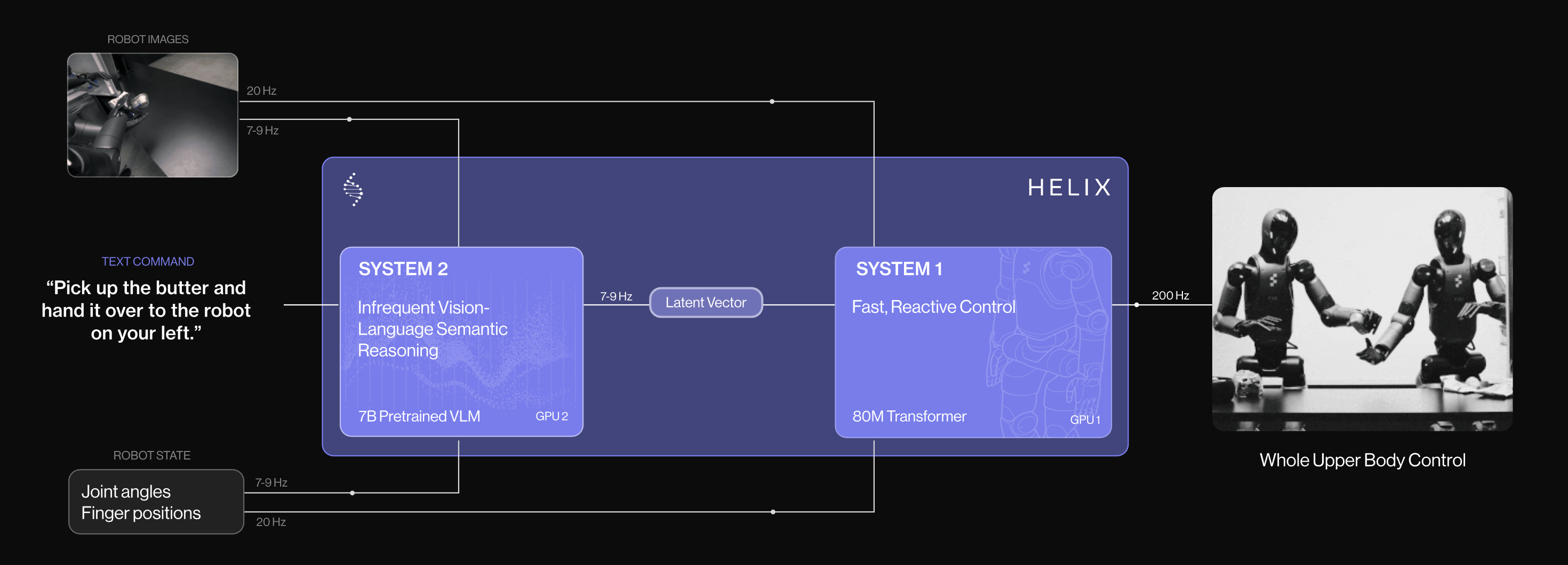
当前的方法[3-Do as i can, not as i say, 4-Look before you leap, 5-Hi robot ,7-Helix]
比如Hi robot 详见此文《Hi Robot——大脑加强版的π0:基于「VLM的高层推理+ VLA低层任务执行」的复杂指令跟随及交互式反馈》
通常借鉴了Kahneman的双系统框架[8-Thinking, fast and slow]
- 一般来说,SystemTwo(如互联网预训练的视觉-语言模型VLMs
9-Paligemma
10-Prismatic vlms
负责缓慢的高层次推理,生成中间推理内容- 与此同时,System One(如视觉-语言-动作模型VLAs)
11–Openvla
12-π0
13-Gr00t n1
则将这些中间内容转化为精确的低层级机器人动作
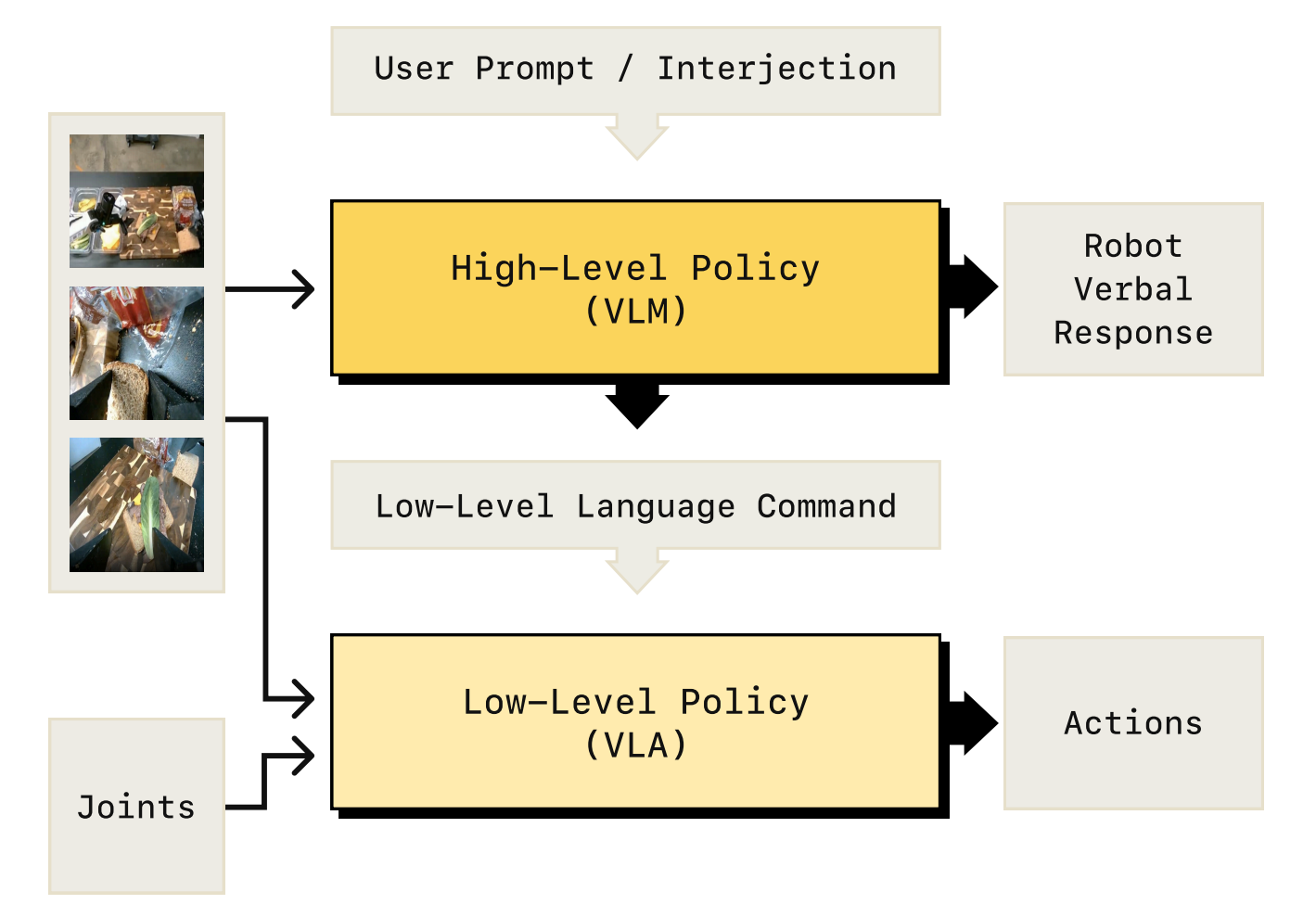
然而,这种显式的解耦导致两个系统之间缺乏对彼此能力的认知;推理系统System Two可能生成执行系统System One无法执行的中间内容[5-Hi robot]
此外,在实际部署中,诸如延迟等问题可能导致System Two响应滞后,进而提供过时或无关的指导
因此,作者认为,实现更强的推理与行动协同需要一个统一的模型。实际上,近期将多种能力整合到单一模型中的趋势已被证明对推动人工智能发展至关重要[14-React,15-Transfusion,16-Introducing 4o image generation,17-Experiment with gemini 2.0 flash native image generation],作者相信这种方法对机器人学习尤为有前景
再比如发布于25年4月份的π0.5『详见《π0.5——离散化token自回归训练,推理时则用连续动作表示,且加强推理(同一个模型中先高层拆解出子任务,后低层执行子任务)》』
基于此,25年5月,来自1Tsinghua University, 2Shanghai Qi Zhi Institute, 3Shanghai AI Lab, 4Fudan University, 5Spirit AI 的研究者提出了OneTwoVLA,这是一种统一的视觉-语言-行动模型,能够同时执行行动(系统一)和推理(系统二)。重要的是,该模型能够自适应地决定何时切换不同模式
- 其paper地址为:OneTwoVLA: A Unified Vision-Language-Action Model with Adaptive Reasoning
- 其项目地址为:one-two-vla.github.io
其GitHub地址为:github.com/Fanqi-Lin/OneTwoVLA
如图1所示
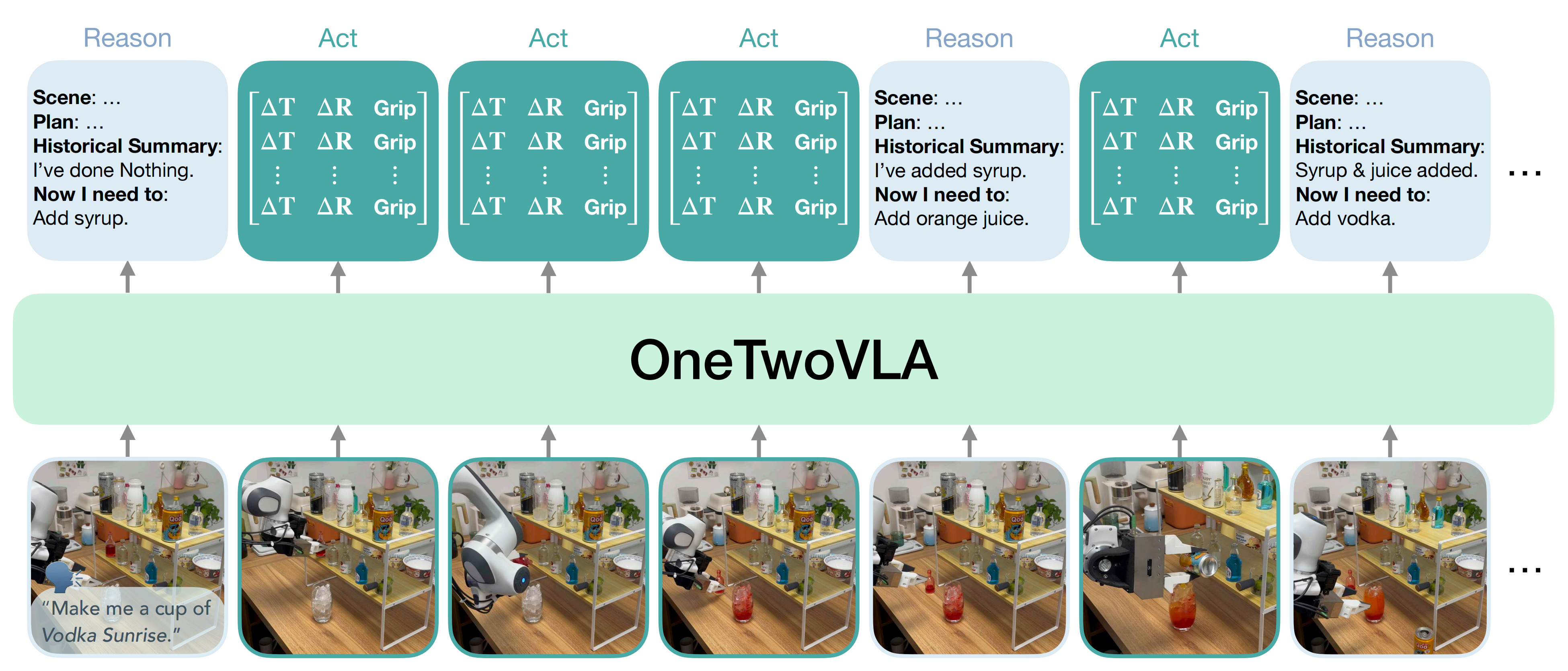
- OneTwoVLA会在关键步骤(如完成子任务、检测到错误或需要人类输入时)触发自然语言推理,输出包括场景描述、任务计划、历史摘要和下一步指令等内容
- 在其他情况下,它则根据最近的推理结果生成行动
该统一模型的一个主要优势是能够自然地支持与视觉-语言数据的联合训练,从而显著提升推理能力和泛化能力
视觉-语言联合训练进一步使其能够泛化到新的任务指令(例如,为“帮我保持清醒”规划咖啡制作流程
且其具备
- 错误检测与恢复能力:OneTwoVLA能够实时检测执行错误,推理纠正策略,并灵活地执行恢复操作
- 以及自然的人机交互能力:OneTwoVLA在人工干预时能够立即调整动作,并在遇到歧义时主动寻求澄清
- 和可泛化的视觉定位:OneTwoVLA在空间关系、物体属性和语义特征理解方面表现优异,甚至能够泛化到其机器人训练数据中未出现的物体
1.1.2 相关工作
第一,对于视觉-语言-动作模型
- 视觉-语言-动作模型VLA
6-Gemini robotics
11-Openvla
12-π0
13-Gr00t n1
22-Palm-e
23-Rt-2
24-Fast
25-Dexvla
26-Otter
是在预训练视觉-语言模型VLM
9-Paligemma
18-Pali-3 vision language models: Smaller, faster, stronger
19-Improved baselines with visual instruction tuning
20-Qwen2-vl
21-Deepseek-vl: towards real-world vision-language understanding
基础上初始化而来,已成为构建通用机器人的一种有前景的方法。这些VLA在大规模机器人数据集
27-Roboturk
28-Robot learning in homes
29-Robonet
30-Scaling data-driven robotics with reward sketching and batch reinforcement learning
31-Graspnet-1billion
32-Rt-1
33-Bc-z
34-Bridgedata v2
35-OpenX
36-Droid: A large-scale in-the-wild robot manipulation dataset
37-Data scaling laws in imitation learning for robotic manipulation
上训练,能够应对各种真实世界中的操作任务 - 然而,这些VLA的推理能力有限
4-Look before you leap: Unveiling the power of gpt-4v in robotic vision-language planning
5-Hi robot
13-Gr00t n1
在面对长周期任务或复杂动态环境时表现出脆弱性
此外,它们的泛化能力依然受限,通常需要针对具体任务进行微调[11-Openvla,12-π0]
相比之下,OneTwoVLA的工作通过统一的模型架构和协同训练框架,提升了推理与泛化能力
第二,对于机器人控制中的推理
- 已有研究
38-Open-world object manipulation using pre-trained vision-language models
39-Grounded decoding: Guiding text generation with grounded models for embodied agents
40-Interactive task planning with language models
41-Rt-h: Action hierarchies using language
42-Ok-robot
43-Yell at your robot
44-Closed-loop open-vocabulary mobile manipulation with gpt-4v
45-Cot-vla
46-Hamster: Hierarchical action models for open-world robot manipulation
表明,高层推理能够提升机器人控制中低层策略的性能
具体而言,许多研究
3-Do as i can, not as i say
4-Look before you leap
5-Hi robot
6-Gemini robotics: Bringing ai into the physical world
7-Helix
13-Gr00t n1
47-Copa: General robotic manipulation through spatial constraints of parts with foundation models
探讨了双系统框架,其中基础模型(如视觉语言模型,VLM)作为系统二,负责高层推理,而低层策略作为系统一,根据推理结果生成动作 - 尽管该双系统框架在完成长时序操作任务时表现出较高的有效性,但其本质上存在诸如两套系统缺乏——增强彼此能力的相互认知 [5-Hi robot],以及 System Two 的延迟问题
另一个并行工作 [48-π0.5] 使用单一模型在每个动作前预测子任务,但其推理过程简单且信息受限。如果这种僵化的范式在每一步都进行大量推理,将会显著影响推理效率[49-Robotic control via embodied chain-of-thought reasoning] - 为了解决这些局限性,作者提出了一种统一模型,能够自适应地决定何时进行推理、何时直接行动,从而兼顾信息丰富的推理和高效的执行
第三,对于机器人学习的协同训练
- 来自多样化数据源的协同训练已被证明有助于机器人学习
22-Palm-e
50-OpenX
51-Vision-language foundation models as effective robot imitators
52-Glso: Grammar-guided latent space optimization for sample-efficient robot design automation
53-Rtaffordance: Reasoning about robotic manipulation with affordances
54-Re-mix: Optimizing data mixtures for large scale imitation learning
55-Pushing the limits of cross-embodiment learning for manipulation and navigation
56-Scaling cross-embodied learning: One policy for manipulation, navigation, locomotion and aviation
57-Robopoint: A vision-language model for spatial affordance prediction for robotics
58-Sim-and-real co-training: A simple recipe for vision-based robotic manipulation
具体而言,已有多项研究
23-Rt-2
59-Embodiedgpt: Vision-language pre-training via embodied chain of thought
60-Objectvla: End-to-end open-world object manipulation without demonstration
61-Chatvla: Unified multimodal understanding and robot control with vision-languageaction model
探索了将无动作的视觉-语言数据与机器人数据协同训练机器人策略,展示了策略泛化能力的提升
然而,这些方法
23-Rt-2
59-Embodiedgpt
61-Chatvla
通常依赖于现有的视觉-语言数据集,但这些数据集由于与机器人应用场景存在显著领域差异,导致数据质量有限;或者通过人工收集视觉-语言数据集[60-Objectvla],但这类数据集规模有限,难以扩展 - 为了解决这些局限性,作者提出了一套可扩展的流程,用于合成富含具身推理的视觉-语言数据。他们声称,他们的流程兼顾高质量和可扩展性,显著提升了策略的推理与泛化能力
1.2 OneTwoVLA的完整方法论
1.2.1 OneTwoVLA框架
首先,对于问题表述
本研究的核心问题是如何开发一种能够同时进行推理与行动的机器人控制策略,并具备在每个时间步t自主决定是进行推理还是行动的关键能力
形式上,该策略有两种运行模式
- 在推理模式下
策略以来自多台摄像头的当前图像观测为输入(记作
,其中 n 表示摄像头数量),参考图像来自最近推理时刻的参考图像
(记作
,引入了观测历史为了防止出现歧义状态),包括语言指令
,以及最新的推理内容
该策略以文本输出的形式进行推理,生成更新后的推理内容 - 在执行模式下,策略π还会结合机器人的本体感知状态,并基于最新的推理内容生成一个动作块
:
其次,对于OneTwoVLA 的自适应推理
在算法1中,作者详细展示了 OneTwoVLA 如何自主决定进行推理还是采取行动的过程

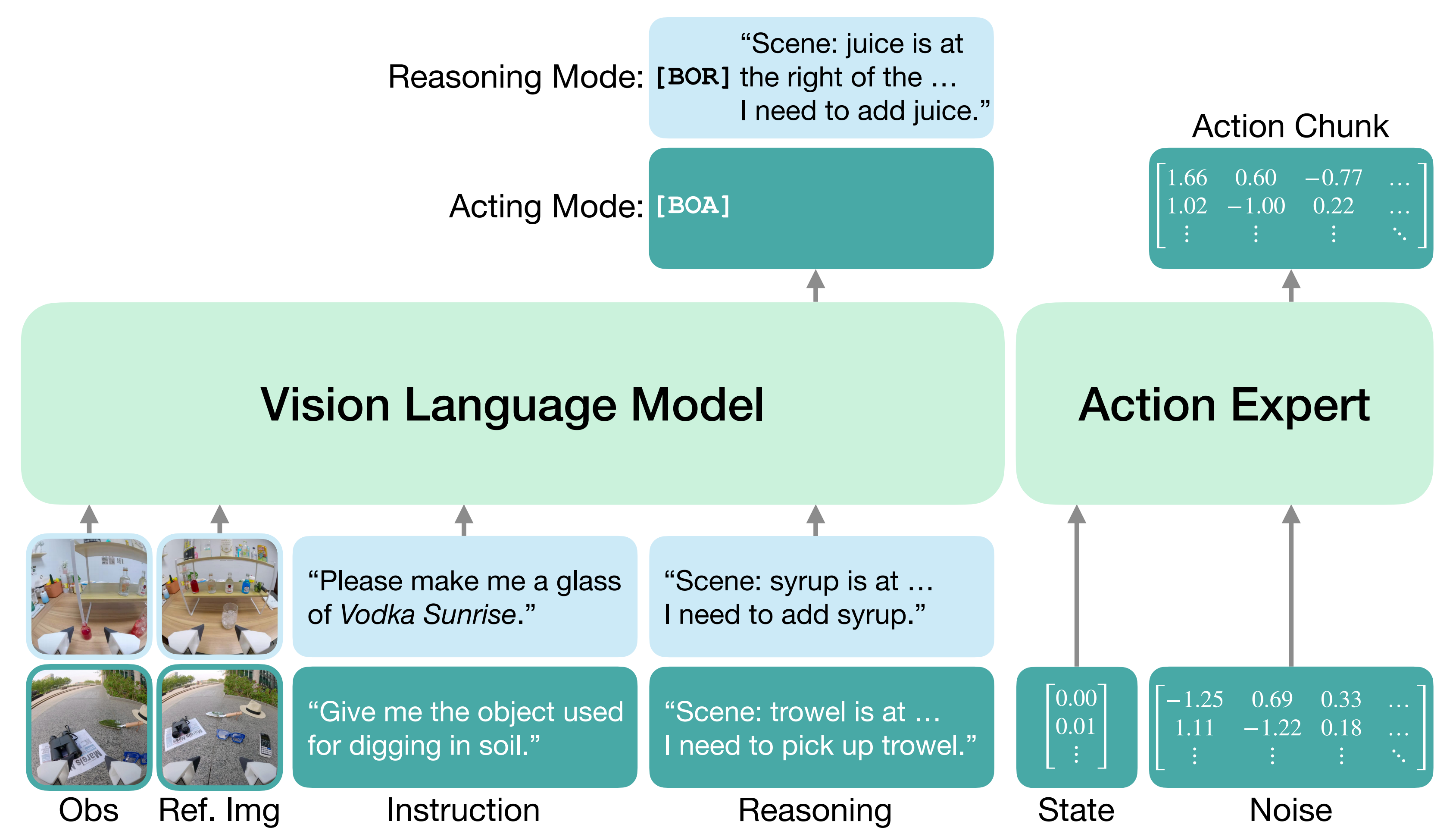
- 他们引入了两个特殊的决策token(DT):推理开始([BOR])和行动开始([BOA])
给定前缀(包括图像观测),模型首先预测[BOR]或[BOA]
- 当预测为[BOR]时,模型进入推理模式,并生成文本推理内容
由于模型只在少数关键步骤进入推理模式,因此额外增加的推理时间可以忽略不计(见附录D.3) - 相反,当预测到[BOA]时,模型会进入执行模式,直接生成动作片段
如此,该自适应框架既支持信息丰富的推理,又保证了高效的执行
要知道,以往的方法要么存在推理过于简单的问题[48],要么推理效率较低[49]
此外,OneTwoVLA的框架本身支持错误恢复与人机交互:
- 当策略检测到错误(例如,未能抓取物体)时,会自动切换到推理模式,以确定纠正策略并执行灵活的恢复操作
- 当发生人机交互时,任何交互文本都会在后续步骤中持续添加到语言指令
最后,模型实例化
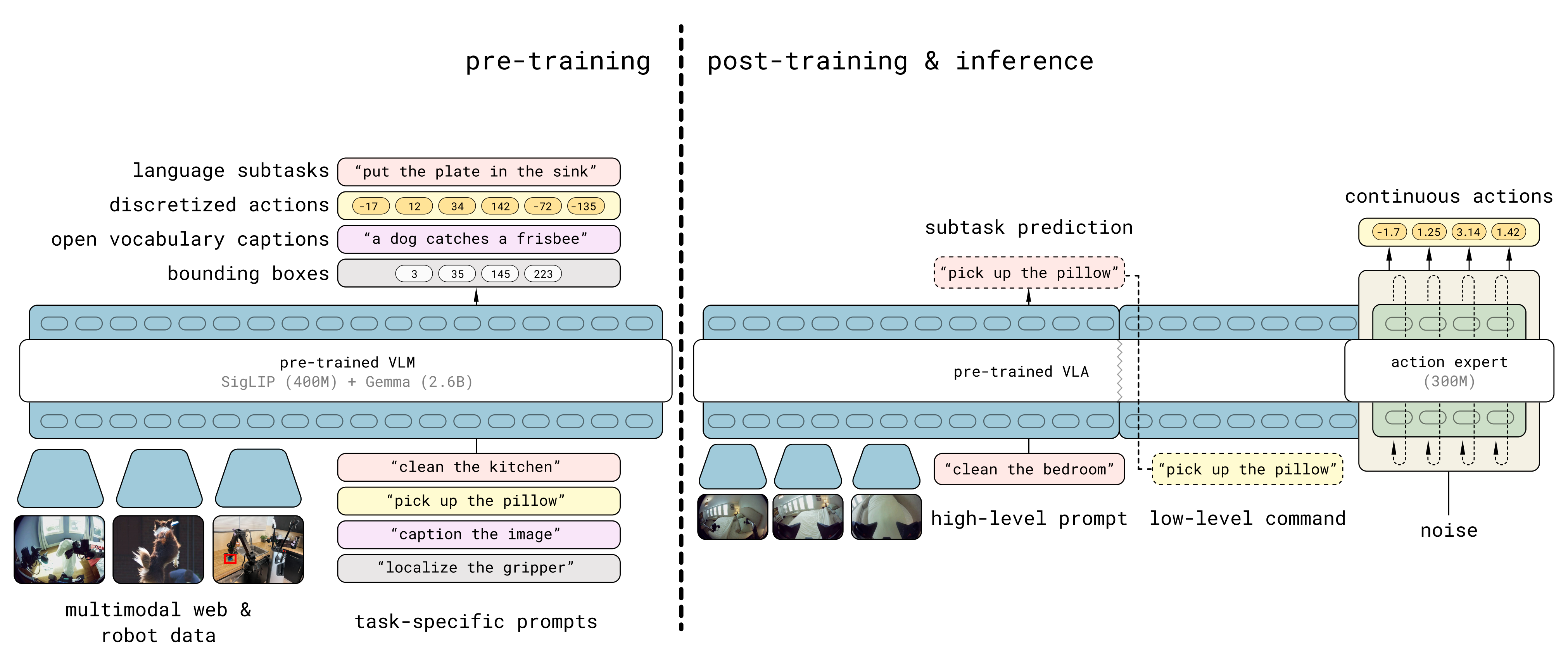
OneTwoVLA 被设计为通用型,可以让大多数现有的 VLA 以极少的修改集成其中。针对具体实例,作者采用 π0[12]作为基础 VLA,该模型在各类任务中展现出强劲性能
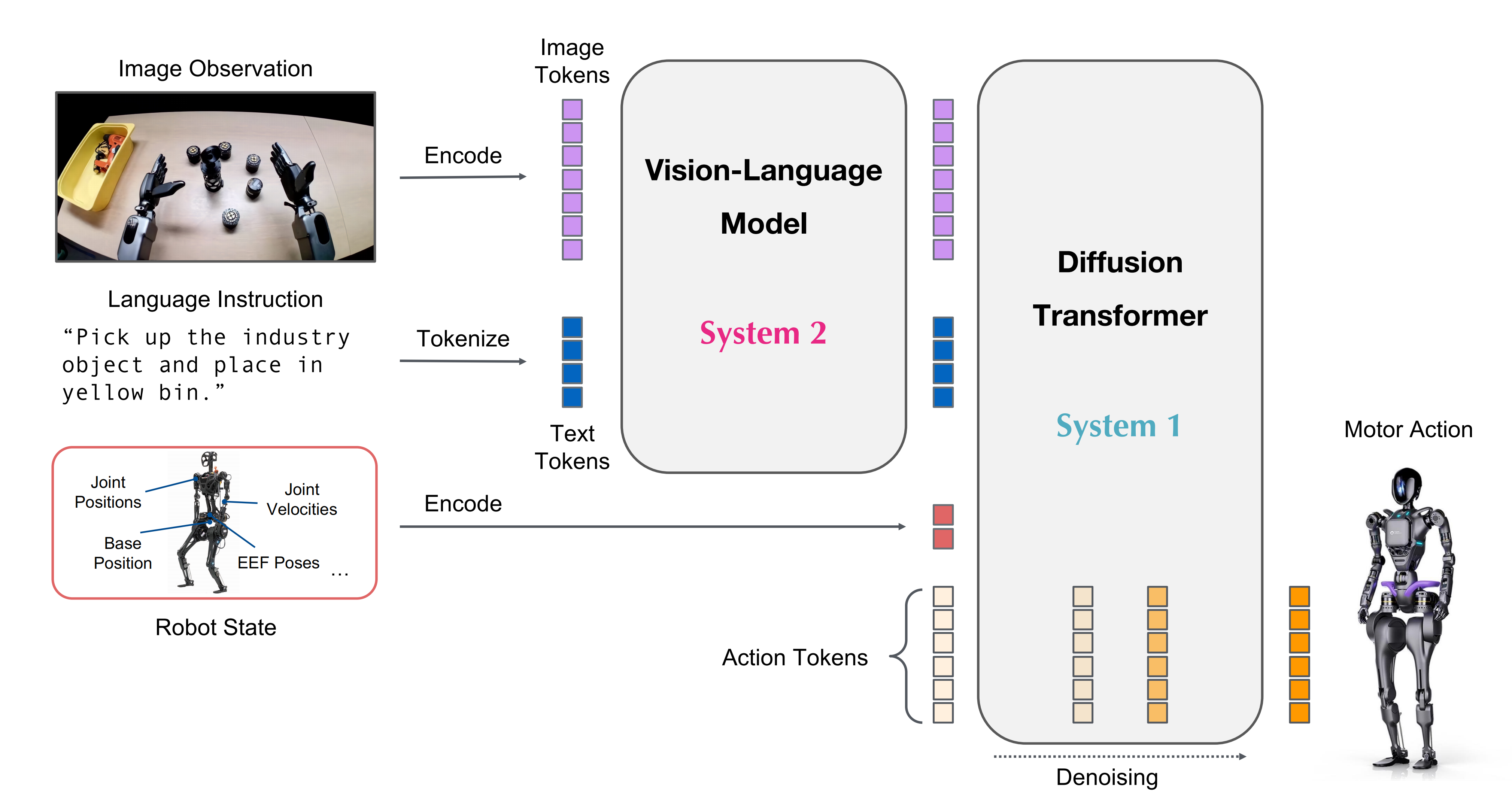
π0 的视觉-语言模型在推理过程中以自回归方式生成文本推理,并在训练阶段通过交叉熵损失进行监督
为了建模复杂的连续动作分布,作者继承了来自π0的动作专家架构,并使用流匹配损失函数[62,63]进行训练。OneTwoVLA的推理流程详见图2。更多训练细节请参见附录D.2
1.2.2 通过具身推理整理机器人数据
大多数现有的机器人操作数据集主要由观测-动作对组成,缺乏相关的推理信息
为了解决这一问题,作者提出了一种新颖的机器人数据格式
- 针对特定任务,作者首先收集由人类专家提供的演示轨迹
- 随后,将每条轨迹分割为一系列区间
这些区间分为两类:
推理区间,用于捕捉需要模型推理的关键步骤(例如,完成子任务、检测错误或需要人机交互时),并在此基础上进一步添加文本推理注释;
接下来,详细阐述具身推理的内容,如图3左所示『左侧。机器人数据示例,包含推理内容。推理内容包括场景描述、高层规划、历史摘要Historical Summary以及下一步指令。交互文本(如机器人提问和人类回答)附加在指令之后。右侧。合成的以推理为中心的具身视觉-语言数据示例。前两个示例展示了视觉定位任务,后两个则展示了长时序任务』

具身推理包含四个部分:
- 详细的场景描述,主要关注与任务相关物体的位置
- 高层次的计划,概述完成任务所需的顺序步骤
- 简明的历史摘要,用于让模型随时了解任务进展
- 机器人需要立即执行的下一步操作
如此全面的推理内容促使模型理解视觉世界、学习高层次的规划,并跟踪任务进度
此外,为了使策略具备错误检测与恢复能力,作者专门收集并标注了聚焦于从失败状态恢复的机器人数据。为了实现自然的人机交互,还为演示过程中的特定区间添加了交互上下文注释(例如,图3左所示的机器人提问和人类回答)

1.2.3 具备具身推理能力的视觉-语言数据的可扩展合成
如上一节所述,精心筛选的机器人数据能够让模型直接学习所需任务,但其数据量与昂贵的人力投入呈线性增长,导致大规模数据集的构建变得不可行
为使OneTwoVLA具备更强的泛化能力并能应对高度多样化的场景,作者利用现成的基础模型,设计了一套完全可扩展的流程,用于合成富含具身推理的视觉-语言数据
该流程包括三个步骤:
- 使用 Gemini 2.5 Pro [64] 生成多样化的桌面布局文本描述,涉及常见家用物品
- 基于这些文本描述,利用文本到图像生成模型 FLUX.1-dev [65] 合成高质量的桌面布局图像
且进一步通过随机应用鱼眼畸变或将自适应亮度的机器人夹爪合成到图像中,对合成图像进行增强,从而使视觉效果更加丰富 - 最后,再次利用 Gemini 2.5 Pro 为每一张合成图像生成任务指令及相应的推理内容。通过该流程,作者自动生成了16,000个数据样本,示例如图3右所示
最终,生成的任务指令分为两类:
- 视觉定位任务[66–68],在此类任务中,指令通过空间关系、属性或语义特征隐含地指向图像中的某一对象。相应的推理过程必须明确指出该对象的名称,并可选择性地给出其位置
- 长周期任务,在此类任务中,指令描述了一个持续的、多步骤的目标。推理过程必须提供一个高层次的、逐步的计划以完成该任务
// 待更