循环神经网络--NLP基础
一、简单介绍
NLP(Natural Language Processing):自然语言处理是人工智能和语言领域的一个分支,它涉及计算机和人类语言之间的相互作用。
二、NLP基础概念
词表(词库):文本数据集出现的所有单词的集合;
语料库:用于自然语言处理NLP的文本数据集合,可以是书籍、文章、网页等;
注意:
词库需去重:避免冗余,确保每个词汇的属性记录唯一。
语料库无需刻意去重:保留重复以反映真实语言使用规律,支撑统计分析。
词嵌入:将单词、文本映射到低维度的连续向量空间的技术,用于捕捉单词的语义和语法信息;
三、NLP的特征工程
3.0特征工程提出的必要
在NLP中,我们处理的对象通常是文本资料,但是计算机只能识别数字信息。因此,特征工程是一种必要的手段:特征工程将文本数据转换为适合机器学习模型使用的数值表示过程,即将文本信息转换为数字信息的过程。
3.1词向量
词向量也称为词嵌入(word embedding):指的是将文本资料转换为低维连续向量的过程。这些向量能够体现词语之间的语义关系。
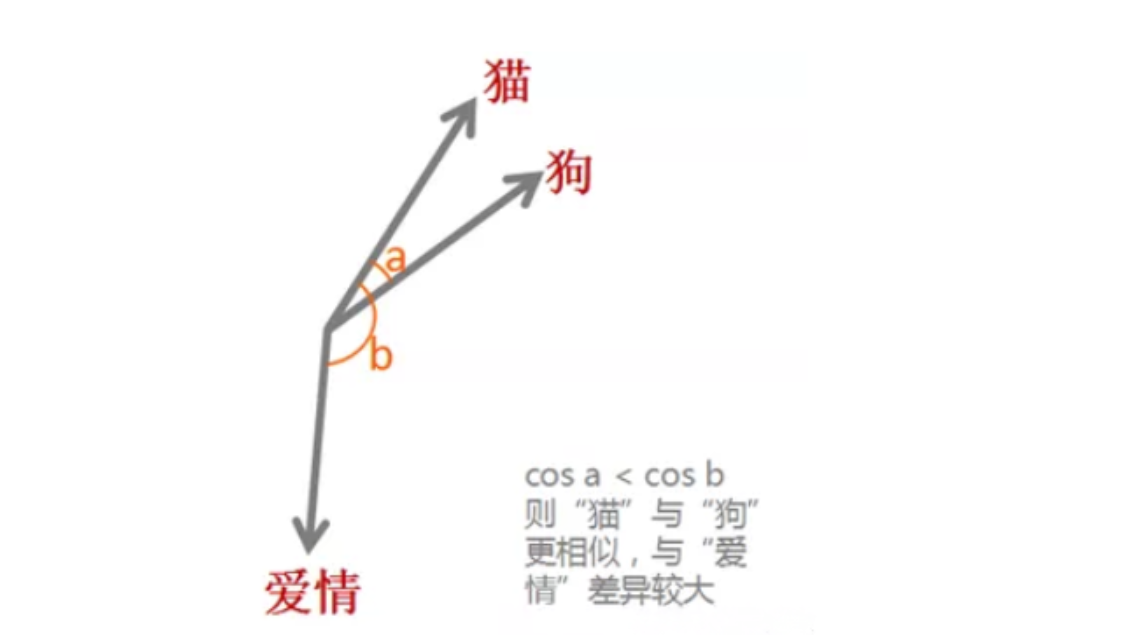
通过词嵌入这种方式,每一个单词都有唯一的词向量,将文本数据信息转换为了数字信息,这样机器就可以对单词进行计算,如利用余弦相似度公式,可以得出单词之间的相似度,相似度越高,两个单词在向量空间中靠的越近,夹角越小。
3.2传统的NLP特征工程
3.2.1one-hot独热编码
one-hot:将每一个类别表示为一个向量,它的组成只能由0,1组成,并且在表示一个单词的时候,只能有一个单词为1,其他单词必须全部为0。
因此,我们可以发现,如果单纯利用独热编码表示向量,
(1)我们写的文本资料多有少个字,那向量就有多长,这样会导致计算量巨大;
(2)想表示一段话的时候,最多不超过30个字,这时候其他的位置就必须全部为0,向量矩阵过于稀疏。
3.2.2词频-逆文档频率(TF-IDF)
词频TF:在给定文档中,单个单词在文章中出现的频率-----出现次数/该文档的总词数

逆文档频率IDF:用于衡量一个单词的重要程度,是将类似词频取倒数并取对数的值;

注意:
IDF 大的词,说明它在多数文档中不出现,仅在特定文档中出现,因此能有效区分不同主题的文档
TF-IDF:综合考虑了词频和逆文档频率,取值为词频与逆文档频率的乘积结果。
3.3深度学习中NLP的特征输入
3.3.1稠密编码
稠密编码的方式通常在特征嵌入中出现:将离散或高维稀疏数据转化为低维的连续、密集向量。
特点:
(1)低维度:转换为低维度的向量之后,减少了计算和存储成本;
(2)语义相似度:引入余弦相似度公式计算语义相似性;
(3)可微学习:通过神经网络进行学习,反向传播算法进行优化。
3.3.2词嵌入算法
3.3.2.1embedding layer
嵌入层用于神经网络的前端,并采用反向传播算法进行监督(更新优化)。向量矩阵以小的随机数进行初始化。
它主要是用来实现输入词的向量化的。
API:nn.Embedding(len(set_word),embedding_dim)

将输入词转换为词向量的步骤:
(1)对文本进行分词;
(2)构建映射词表,这里必须用去重的句子;
(3)使用嵌入层,调用nn.Embedding.
代码:
import torch
import torch.nn as nn
sentences = 'I like a dog , it is cute'
#分词
sentences = sentences.split(' ')#去重
sentences = list(set(sentences))#映射
word_index = {word:index for index,word in enumerate(sentences)}
index_word = {index:word for index,word in enumerate(sentences)}#向量化
embedding = nn.Embedding(len(sentences),4)
index = word_index['dog']
output = embedding(torch.tensor([index]))
print(output)
结果:
tensor([[-0.1077, -1.3688, -0.5193, -0.2856]], grad_fn=<EmbeddingBackward0>)
3.3.2.2word2vec
word2vec是一种高效训练词向量的模型。一般分为CBOW模型和Skip-Gram模型:
(1)CBOW:根据周围词来预测中心词;
(2)Skip-Gram:根据中心词预测周围词。
API:from gensim.model import Word2Vec
gensim库需要自行下载:pip install gensim
model = Word2Vec(sentences,vector_size,window,min_count,sg)
参数介绍:
sentences:二维list。
vector_size:特征信息维度。
window:当前词与预测词在一个句子中最大的距离。
min_count:可以对字典做截断,词频少于min_count次数的单词会被丢弃掉,默认值为5。
sg:设置为0,对应CBOW算法;设置为1对应Skip-Gram算法。
四、总结
大致了解了NLP的简单术语,以及如何通过嵌入层实现对文本进行向量化,还可以利用现成模型word2vec对单词向量化。主要是了解一下大致知识就行,过过代码就可以了。本节内容要求没有严格。