使用LDA进行主题建模:发现文本中的隐藏主题 - 父亲节特别版
大家好,周日快乐,父亲节快乐!雨停了,天空又晴朗了。让我们以R开始这个早晨!
首先让我们了解主题建模背后的概念。主题建模是一种强大的文本挖掘技术,用于发现文档集合中的隐藏主题。在这个博客中,我们将学习**潜在狄利克雷分配(LDA)**背后的概念,并展示其在R中的应用。“狄利克雷”指的是以德国数学家约翰·彼得·古斯塔夫·勒让德·狄利克雷(1805-1859)命名的狄利克雷分布。他在数论、分析和数学物理领域做出了重大贡献。单词“潜在”指的是隐藏或未知,如潜在变量。在主题建模中,这意味着主题不是直接观察到的,而是从文档中词语共现的模式中推断出来的。
什么是主题建模?
主题建模识别代表文档集合信息的最佳词语组(主题)。它是一种用于数据探索的统计方法,揭示文本数据中的模式或类别,无需人工干预。LDA是一种流行的主题建模算法,假设文档是主题的混合,主题是词语的混合。通过使用主题建模,我们可以快速了解文本数据的结构,并识别嵌入在文本中的类别。例如,我们可以有以下主题及其相关词语:
- 主题1(逃亡者):词语如“仆人”、“奖励”、“逃跑”。
- 主题2(政府):词语如“国家”、“法律”,“总统”。
LDA是一种建模文本中主题的特定方法(算法)。LDA通过特定的概率过程假设文档是如何生成的来实现这一点。这些假设包括主题的混合以及主题作为词语分布。LDA的优势在于它能够很好地处理大型文本集合,并且可以在没有标记数据的情况下工作(无监督)。缺点是它对指定的主题数量敏感,并且可能计算成本高。
例如,我们有一个输入文档:
文档: “猫 玩“狗”水“食物”猫“植物”狗“玩”猫”
LDA将执行以下步骤:
- 初始化:随机分配:为每个词语分配主题
- 猫 §, 玩 §, 狗 §, 水 (Q), 食物 §,
猫 §, 植物 (Q), 狗 §, 玩 §, 猫 §
- 猫 §, 玩 §, 狗 §, 水 (Q), 食物 §,
- 迭代过程:
- 对于每个词语,暂时移除它,然后:
- 查看其他词语的当前主题分配
- 计算两个概率:
- 这个文档中的词语被分配到每个主题的频率
- 这个词在所有文档中每个主题的出现频率
- 根据这些概率重新分配该词到主题
- 对于每个词语,暂时移除它,然后:
- 多次迭代后:
- 算法收敛到发现:
- 一些主题(词语的分布)
- 对于每个文档,主题的混合
- 算法收敛到发现:
示例输出:
发现的主题:
- 主题1: 猫 (0.3), 狗 (0.25), 玩 (0.2), 食物 (0.15), 鱼 (0.1)
- 主题2: 植物 (0.3), 水 (0.25), 土壤 (0.2), 生长 (0.15), 太阳 (0.1)文档主题混合:
- 文档1: 70% 主题1, 30% 主题2
这里是一个使用topicmodels和tidytext的更现实的例子:
library(topicmodels)
library(tm)
library(tidytext)
library(ggplot2)# 创建一个有明确主题的语料库用于演示目的 :)
文档 = c("机器学习算法需要训练数据来做出预测","深度神经网络对于图像识别任务很强大","园艺需要良好的土壤、水和阳光来促进植物生长","玫瑰和郁金香是需要定期浇水的美丽花朵","机器学习模型可以通过梯度下降进行训练","早晨浇水植物有助于防止真菌疾病")# 创建文档-术语矩阵 (DTM)
corpus语料 <- VCorpus(VectorSource(文档))
dtm <- DocumentTermMatrix(corpus,control = list(tolower = TRUE,removePunctuation = TRUE,removeNumbers = TRUE,stopwords = TRUE))# 移除稀疏术语
dtm <- removeSparseTerms(dtm, 0.7)# 使用2个主题运行LDA
set.seed(123)
lda_model <- LDA(dtm, k = 2, control = list(seed = 123))# 提取并显示主题及其概率
topics主题 <- tidy(lda_model, matrix = "beta")# 显示每个主题的前5个术语
top_terms前术语 <- topics主题 %>%group_by(主题) %>%top_n(5, beta) %>%ungroup() %>%arrange(主题, -beta)# 可视化前术语
top_terms前术语 %>%mutate(term = reorder_within(term术语, beta, topic)) %>%ggplot(aes(beta, term术语, fill = factor(主题))) +geom_col(show.legend = FALSE) +facet_wrap(~ 主题,scales = "free") +scale_y_reordered() +labs(title = "每个主题中的顶级术语",x = "概率 (Beta)",y = "术语") +theme_minimal()# 文档-主题混合
doc_topics文档主题 <- tidy(lda_model, matrix = "gamma") %>%group_by(document文档) %>%top_n(1, gamma) %>%ungroup()# 打印文档-主题分配
doc_topics文档主题
输出为:
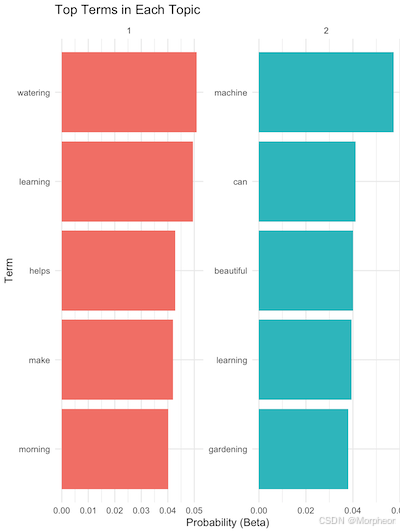
# 一个主题的表格:10 × 3主题 术语 beta<int> <chr> <dbl>1 1 浇水 0.05092 1 学习 0.04953 1 帮助 0.04284 1 做出 0.04205 1 早晨 0.04026 2 机器 0.05747 2 可以 0.04128 2 美丽 0.04019 2 学习 0.0394
10 2 园艺 0.0381
# 一个主题的表格:6 × 3文档 主题 gamma<chr> <int> <dbl>
1 1 1 0.514
2 3 1 0.505
3 6 1 0.510
4 2 2 0.509
5 4 2 0.507
6 5 2 0.514
第一个表格是每个主题的前术语:
- 模型识别了2个主题(主题1和主题2)
- 主题1似乎是关于“园艺/植物护理”(顶级术语:浇水,帮助,早晨)
- 主题2似乎是关于“机器学习”(顶级术语:机器,学习,可能)
beta值表示该词出现在该主题的概率(越高 = 越具代表性)- 注意:主题没有完美分离,因为:
- 单词“学习”出现在两个主题中
- 样本量很小(仅6个文档)
第二个表格是文档-主题混合:
- 显示每个文档最可能的主题
gamma值对于所有文档都非常接近0.5,意味着:- 模型对主题分配不确定
- 文档与任一主题没有强烈关联
- 这在小型数据集或主题未很好分离时经常发生
我们可以通过使用更多文档和更长文档来改进模型,或者使用更大且更多样化的数据集。
这向我们展示了发现的主题以及每个文档是如何由这些主题混合而成的,有效地“逆转”了我们开始的文档生成过程。关键洞察是,虽然前向过程从主题生成文档,LDA从文档反向工作以发现底层主题及其混合。
使用现实世界数据集可视化主题建模
在我们的最后一个例子中,我们将使用ggplot2可视化美联社主题。AssociatedPress数据集内置于R中,因此无需下载。它包含2,246篇来自美联社的新闻文章。这些文章已预处理为DTM,其中每行代表一个文档,每列代表一个术语。值是术语频率:
<<DocumentTermMatrix (documents文档: 2246, terms术语: 10473)>>
非-/稀疏条目: 302031/23220327
稀疏度 : 99%
最大术语长度: 18
权重 : 术语频率 (tf)
步骤:
- 预处理数据:转换为小写,移除符号、标点和停用词。
- 创建文档-术语矩阵(DTM)。
- 运行LDA提取主题。
- 可视化结果。
示例:美联社数据的LDA
library(topicmodels)
library(tidytext)
library(tidyr)
library(ggplot2)
library(dplyr)data("AssociatedPress")
set.seed(1234)
ap_lda <- LDA(AssociatedPress, k = 2, control = list(seed = 1234)) # 2-主题LDA
ap_topics <- tidy(ap_lda, matrix = "beta") # 每个主题的词概率# 每个主题的前10个术语
ap_top_terms <- ap_topics %>%group_by(主题) %>%top_n(10, beta) %>%ungroup() %>%arrange(主题, -beta)# 可视化顶级术语
ap_top_terms %>%mutate(term = reorder(term术语, beta)) %>%ggplot(aes(term术语, beta, fill = factor(主题))) +geom_col(show.legend = FALSE) +facet_wrap(~主题,scales = "free") +coord_flip()
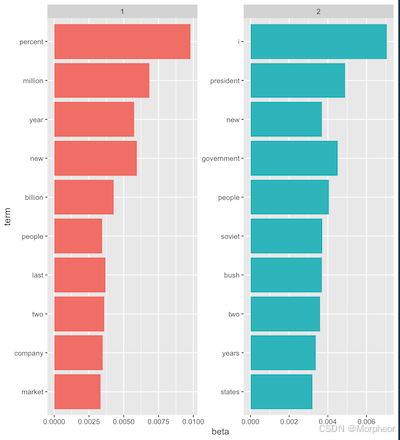
这段代码创建了一个双主题LDA模型,提取词概率(beta),并可视化每个主题的前10个术语。例如,主题1可能包括“百分比”、“百万”(商业新闻),而主题2包括“总统”、“政府”(政治新闻)。
比较主题
为了突出主题之间的差异,计算词概率的对数比率:
beta_spread <- ap_topics %>%mutate(主题 = paste0("主题", topic))spread(topic主题, beta) %>%filter(topic1主题1 > 0.001 | topic2 主题2 > 0)mutate(log_ratio对数比率 = log2(topic2主题2 / topic1主题1))beta_spread() %>%mutate(term术语 = reorder(term术语,log_ratio对数比率)) %>%ggplot(aes(term术语,log_ratio对数比率)) +geom_col(show.legend = FALSE) +coord_flip()
这可视化了主题间概率差异最大的词。
文档-主题概率
提取每个文档中每个主题的比例:
ap_documents <- tidy(ap_lda,matrix = 文档) -> "gamma" # 每个文档-主题的主题概率
检查文档词语
检查特定文档中的频繁词语:
tidy(AssociatedPress) %>%filter(document文档 == 6) %>%arrange(desc(count计数))
这可能显示像“诺列加”和“巴拿马”这样的词,表明文档的内容。
LDA的优势
与硬聚类不同,LDA允许主题共享词语(例如,“人们”在商业和政治主题中),反映自然语言的重叠。它非常适合定性分析,例如研究文学或社交媒体中的趋势。
结论
LDA是一种强大的方法,用于发现文本数据中的潜在主题。使用R的topicmodels和tidytext包,你可以预处理文本,应用LDA,并可视化结果,以深入了解文档集合。尝试使用你自己的数据来发现隐藏模式!