数据库核心技术深度剖析:事务、索引、锁与SQL优化实战指南(第六节)-----InnoDB引擎
Introduction:收纳技术相关的数据库知识 事务、索引、锁、SQL优化 等总结!
文章目录
- InnoDB引擎
- 线程模型
- Master Thread
- I/O Thread
- Purge Thread
- Page Cleaner Thread
- 数据页
- File Header(文件头)
- Page Header(页头)
- Infimun+Supremum Records
- User Records(用户记录)
- Free Space(空闲空间)
- Page Directory(页目录)
- File Trailer(文件结尾信息)
- 行格式
- compact行格式
- redundant行格式
- dynamic行格式
- compressed行格式
- 内存结构
- Buffer Pool
- 缓存页
- 描述数据
- 缓存页哈希表
- Free链表
InnoDB引擎
线程模型
InnoDB存储引擎是多线程的模型,所以犹太有多个不同的后台线程,负责处理不同的任务,主要有:Master Thread、I/O Thread、Purge Thread、Page Cleaner Thread 四种。
Master Thread
核心后台线程,主要负责将缓冲池中的数据异步刷新到磁盘,保证数据的一致性,包括脏页的刷新、合并插入缓冲(Insert Buffer)、回滚页(UNDO PAGE)的回收等。
I/O Thread
**在InnoDB存储引擎中大量使用AIO来处理IO请求,而I/O Thread主要负责处理这些 I/O 请求的回调(call back)处理。**这里共有四类I/O线程,分别是:insert buffer thread、log thread、read thread、write thread。
mysql> show variables like "%innodb%io_threads%";
+-------------------------+-------+
| Variable_name | Value |
+-------------------------+-------+
| innodb_read_io_threads | 4 |
| innodb_write_io_threads | 4 |
+-------------------------+-------+
Purge Thread
purge thread线程用来回收事务提交后其被分配的undo页,默认是开启的,可以通过修改配置文件来配置多个Purge Thread线程。
mysql> show variables like "%purge_threads%";
+----------------------+-------+
| Variable_name | Value |
+----------------------+-------+
| innodb_purge_threads | 4 |
+----------------------+-------+
1 row in set (0.00 sec)
在提交了一个事务给数据库时,为了保证事务能够回滚,会在内存中缓存下该事务未执行时的状态(undo 日志),如果事务执行不成功,那么就恢复之前的状态;如果执行成功,undo日志就用不着了,要把它删除以腾出空间。Purge 线程就是做这个删除工作的。默认有4个线程。
Page Cleaner Thread
用于多版本控制功能中回收delete和update操作产生的脏页,用来执行将脏页刷新到磁盘。
MySQL 5.7 版本以后,支持设置多个刷脏页线程,提高脏页处理性能。设置命令,比如:
SET GLOBAL innodb_page_cleaner = 3
数据页
数据页主要是用来存储表中记录的,它在磁盘中是用双向链表相连的,方便查找,能够非常快速得从一个数据页,定位到另一个数据页。通常情况下,单个数据页默认的大小是16kb。当然也可以通过参数 innodb_page_size 来重新设置大小。不过,一般情况下,用它的默认值就够了。单个数据页包含内容如下:
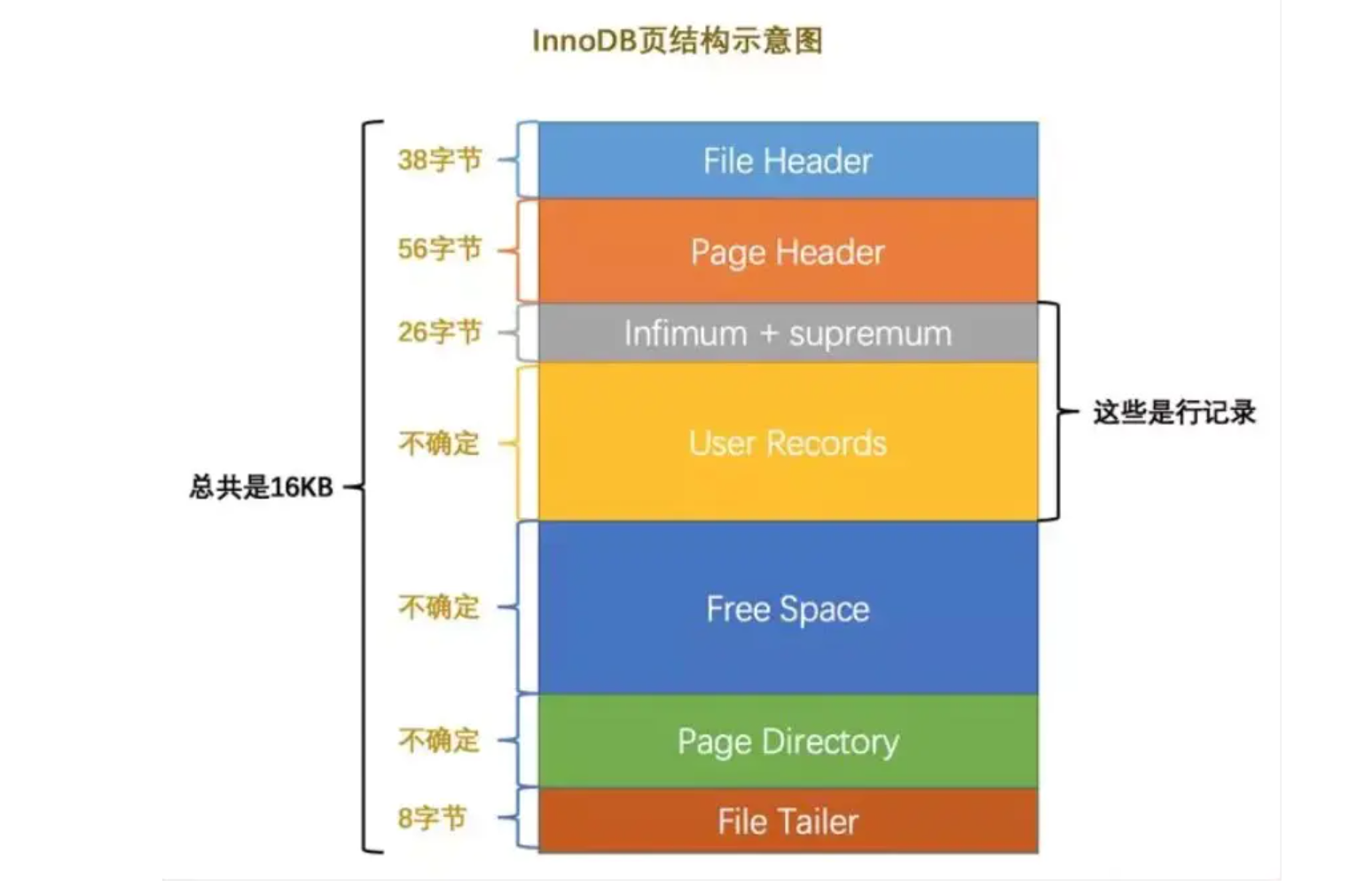
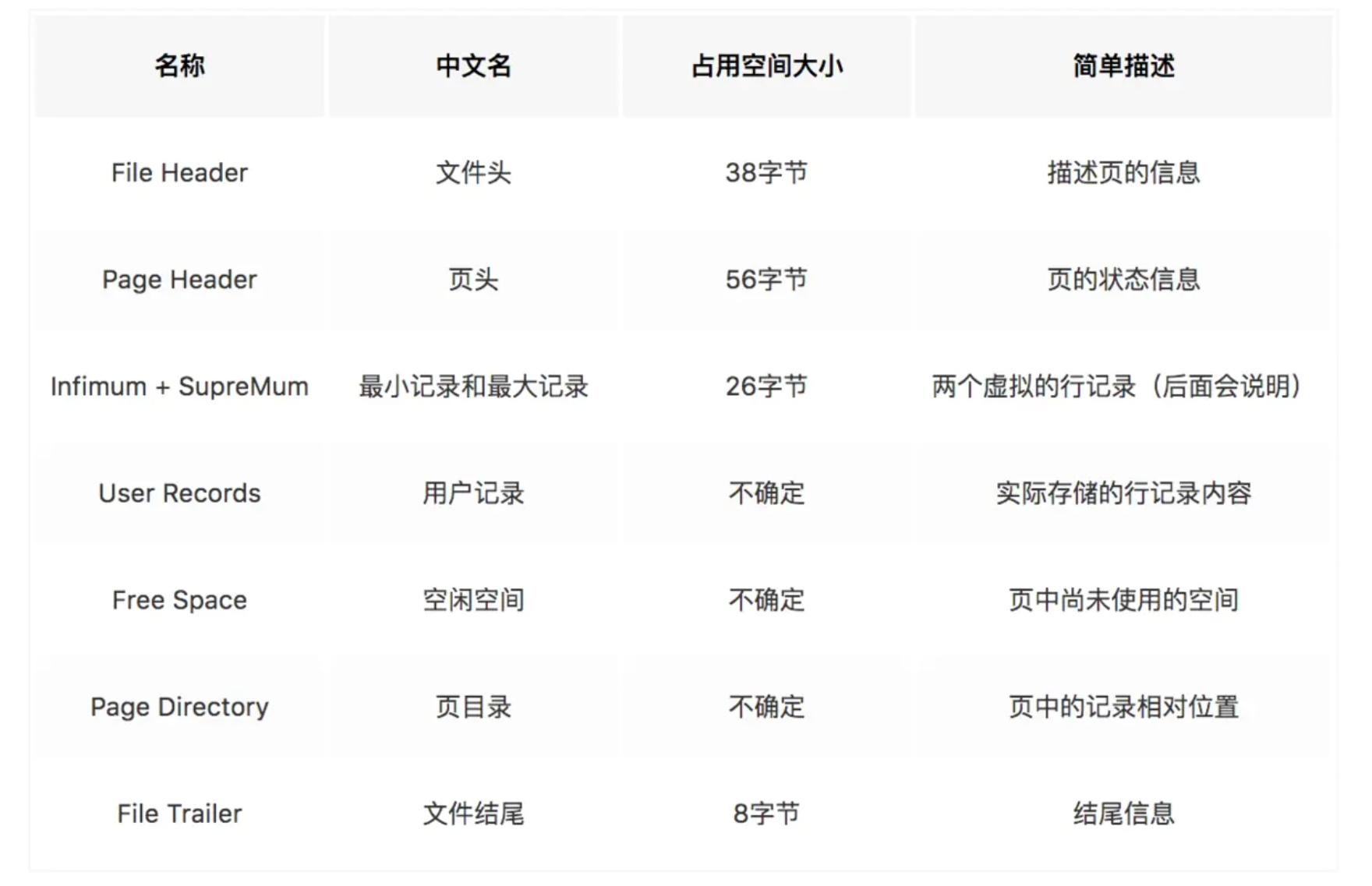
File Header(文件头)
用于记录页(Page)的信息,如页类型、上一页和下一页等,占固定的 38byte。重要字段结构如下:
-
FIL_PAGE_SPACE_OR_CHKSUM:校验和。为了快速比较、保证数据的完整性防止遭到破坏等 -
FIL_PAGE_OFFSET:页号。InnoDB通过页号来可以唯一定位一个页 -
FIL_PAGE_TYPE:页的类型。InnoDB为了不同的目的而把页分为不同的类型 -
FIL_PAGE_PREV、FIL_PAGE_NEXT:分别指向上一页和下一页
Page Header(页头)
存储页内的一些状态和汇总信息,如本页有多少条记录等,占固定的 56byte。重要字段结构如下:
-
PAGE_N_DIR_SLOTS:页内槽的个数,其占用2byte。新建空数据页初值为2,分别指向Infimum最小记录、Supremum最大记录 -
PAGE_HEAP_TOP:第一条记录地址 -
PAGE_N_HEAP:页内记录数,含最大最小记录及标记删除的记录
Infimun+Supremum Records
为了快速找到最大或最小记录,在保存用户记录时,数据库会自动创建两条额外的记录,最大记录保存到Supremum记录中,最小记录保存在Infimum记录中。如下图所示:
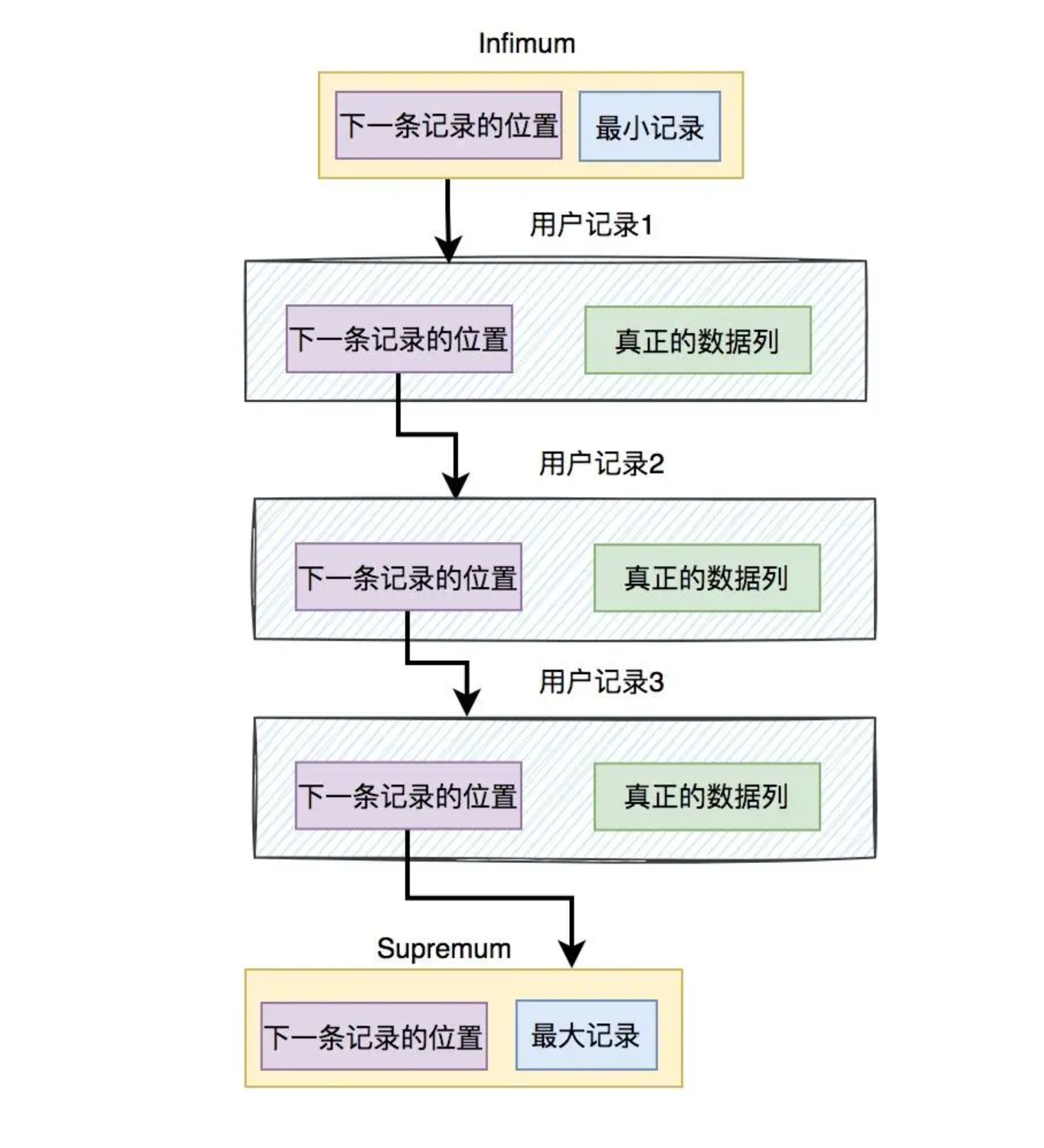
User Records(用户记录)
用来存储用户插入的数据记录。对于新申请的数据页,用户记录是空的。当插入数据时,Innodb会将一部分空闲空间分配给用户记录。我们平时保存到数据库中的数据,就存储在它里面。Innodb支持的数据行格式有四种:
- compact行格式
- redundant行格式
- dynamic行格式
- compressed行格式
以compact行格式为例:

一条用户记录主要包含三部分内容:
-
记录额外信息:它包含了变长字段、null值列表和记录头信息
记录头信息用于描述一些特殊的属性。它主要包含:
- deleted_flag:即删除标记,用于标记该记录是否被删除了
- min_rec_flag:即最小目录标记,它是非叶子节点中的最小目录标记
- n_owned:即拥有的记录数,记录该组索引记录的条数
- heap_no:即堆上的位置,它表示当前记录在堆上的位置
- record_type:即记录类型,其中0表示普通记录,1表示非叶子节点,2表示Infrimum记录, 3表示Supremum记录
- next_record:即下一条记录的位置
-
隐藏列:它包含了行id(
db_row_id)、事务id(db_trx_id)和回滚点(db_roll_ptr) -
真正的数据列:包含真正的用户数据,可以有很多列
Free Space(空闲空间)
为页面的剩余空间。User Records部分从上往下使用剩余空间,而Page Directory则从下往上使用剩余空间。
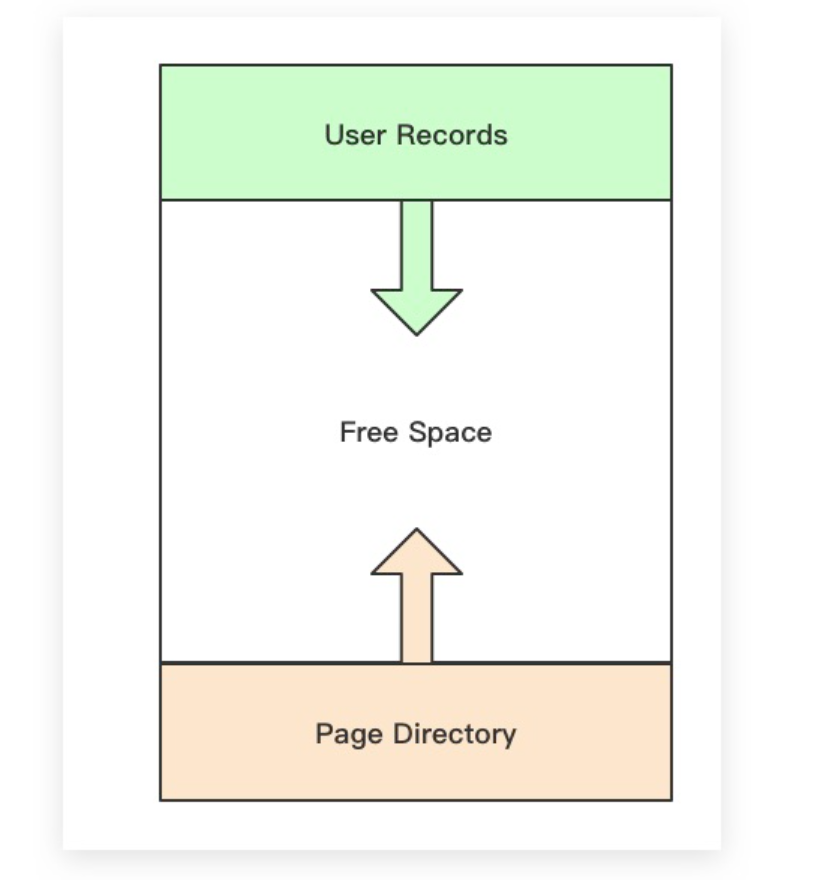
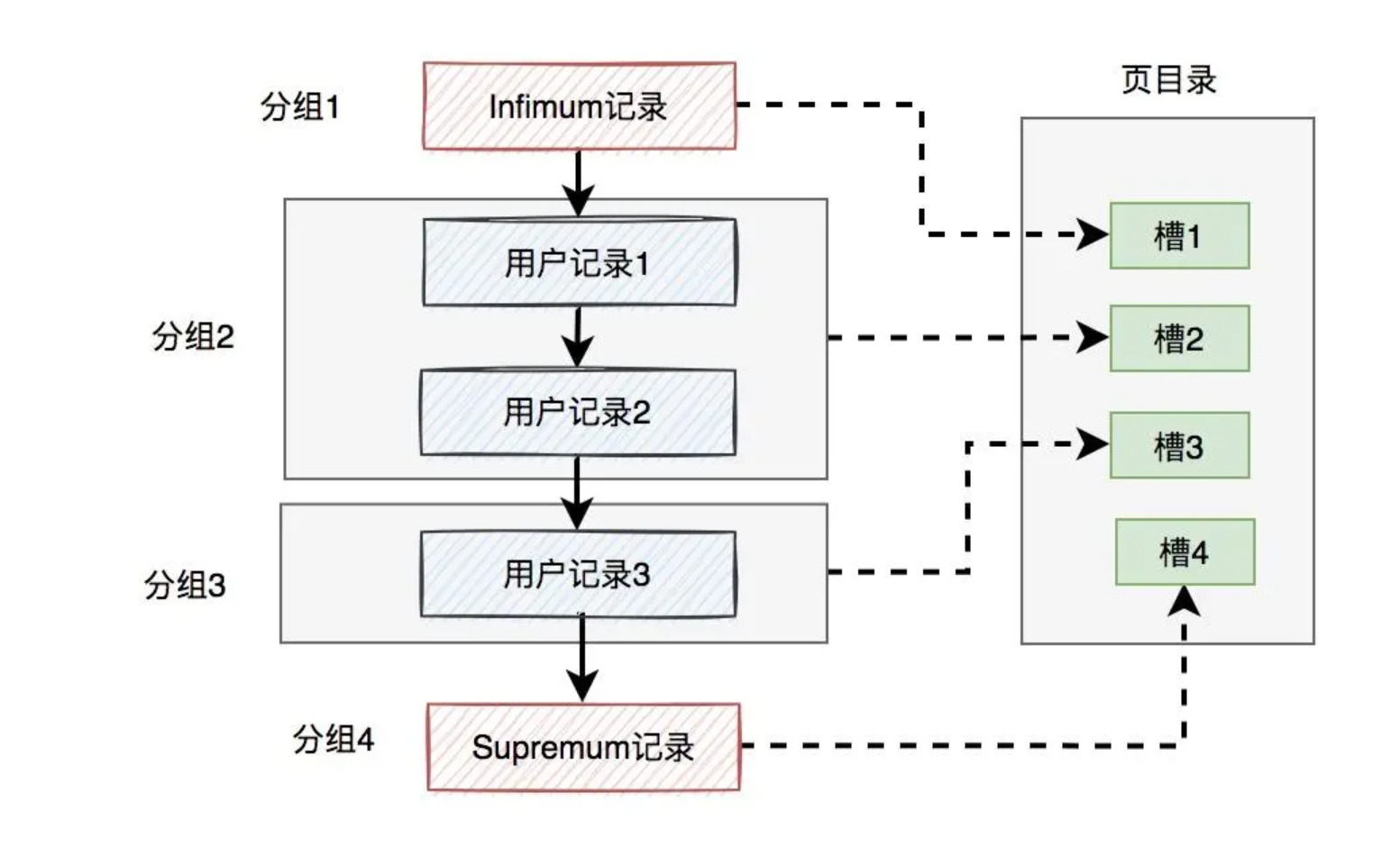
Page Directory(页目录)
为了在单页中能快速查找到对应的记录(最坏情况为全页扫描),把一页用户记录分为若干组,每一组的最大记录都保存到页目录,每一组的最大记录叫做槽,然后就能通过二分查找进行快速定位记录。所下图所示:
File Trailer(文件结尾信息)
用于检验当前页的完整性,主要记录了页面的校验和(checksum)。具体地其占用 8byte,前4byte为校验和(checksum),后4byte为页面被最后修改时相应的日志序列位置(LSN)。
行格式
compact行格式
redundant行格式
dynamic行格式
compressed行格式
内存结构
Buffer Pool
InnoDB 为了解决磁盘 I/O 频繁操作问题,MySQL 需要申请一块内存空间,这块内存空间称为Buffer Pool。
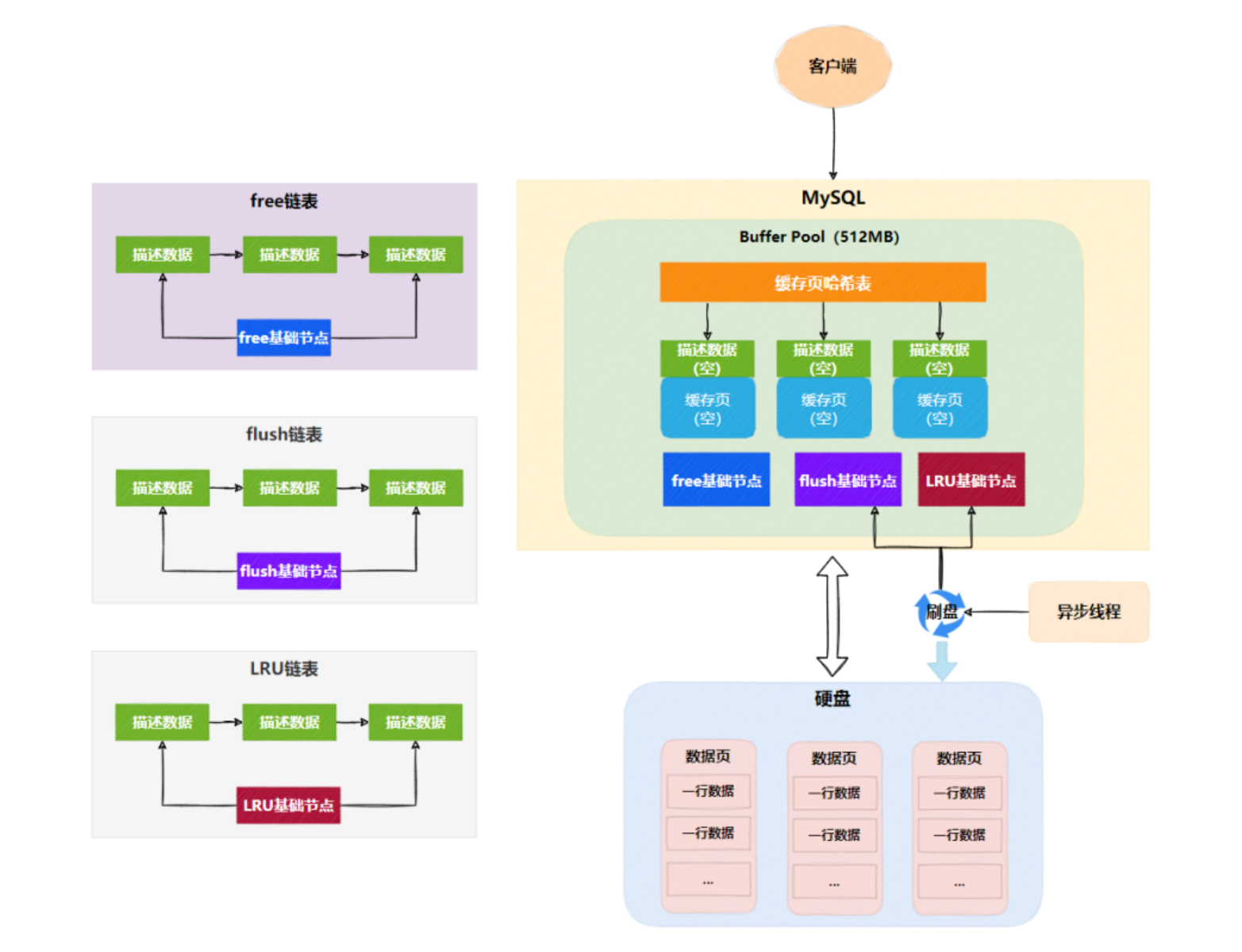
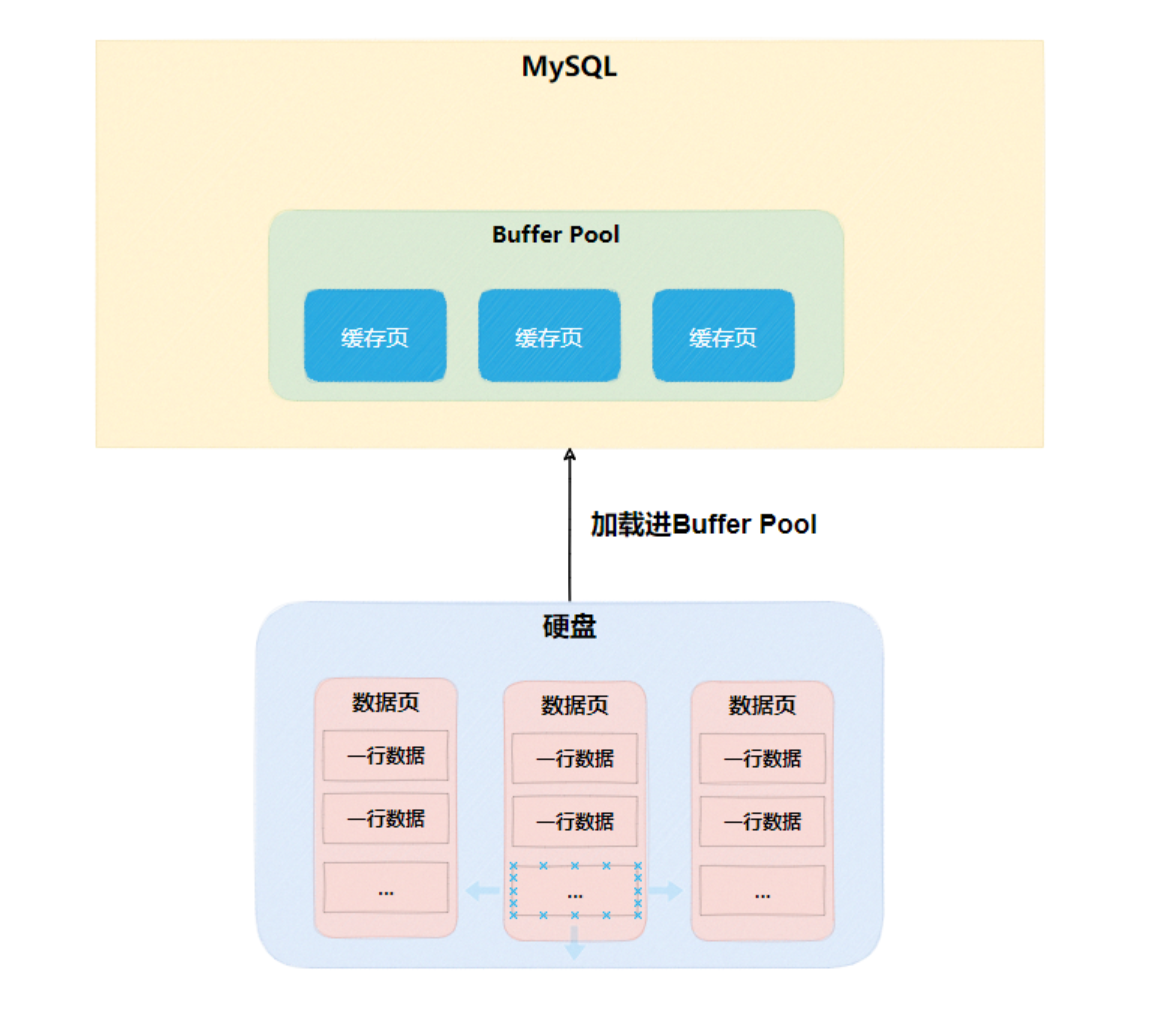
缓存页
MySQL数据是以页为单位,每页默认16KB,称为数据页。在Buffer Pool里面会划分出若干个缓存页与数据页对应。
描述数据
每个缓存页会有对应的一份描述数据(一一对应),里面存储了缓存页的元数据信息,包含一些所属表空间、数据页的编号、Buffer Pool中的地址等。可用于缓存页直接映射到对应的数据页。每个描述数据默认为 800Byte。
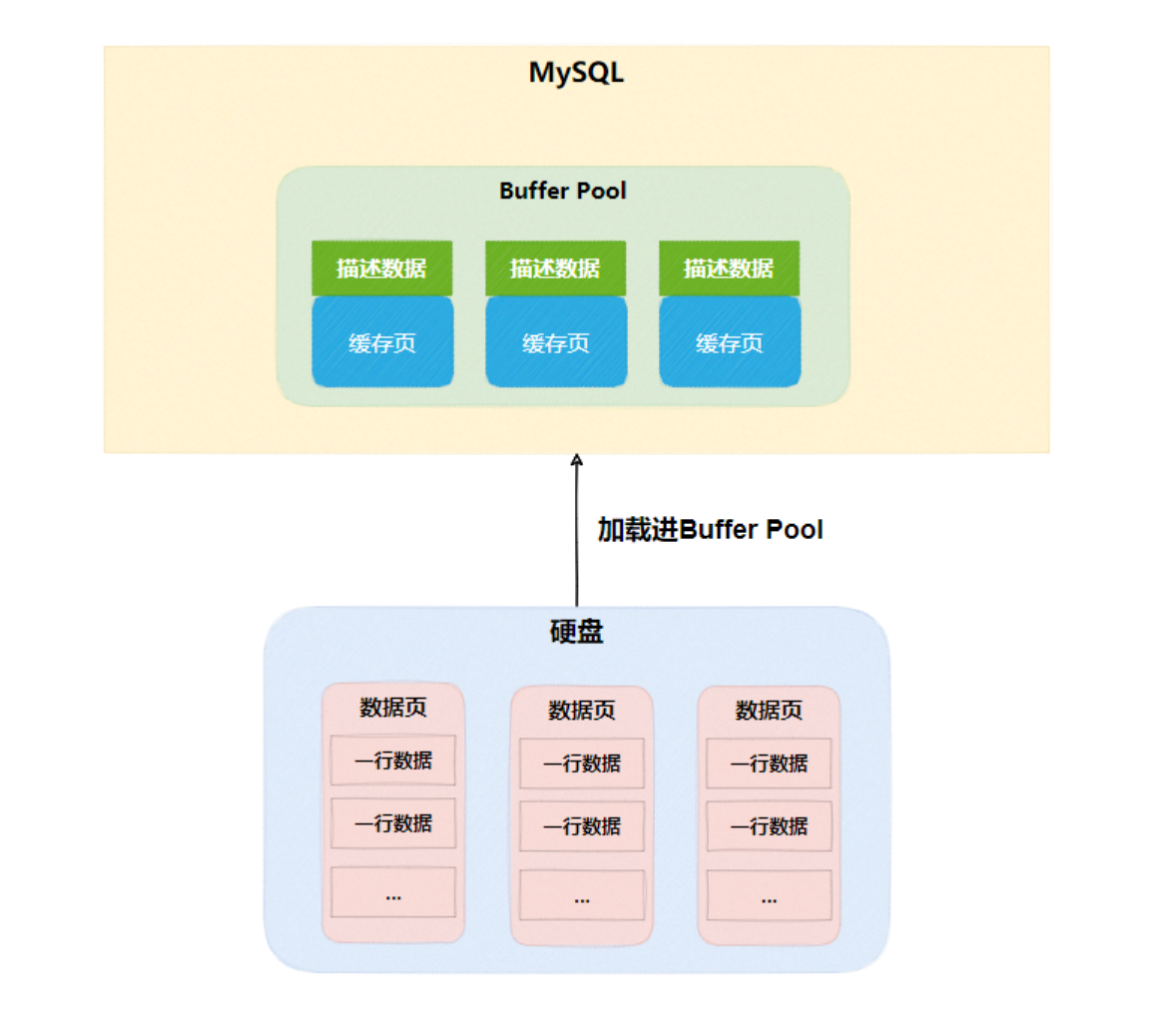
后续对数据的增删改查都是在Buffer Pool里操作
- 查询:从磁盘加载到缓存,后续直接查缓存
- 插入:直接写入缓存
- 更新删除:缓存中存在直接更新,不存在加载数据页到缓存更新
直接更新数据的缓存页称为脏页,缓存页刷盘后称为干净页。
缓存页哈希表
查询数据时,如何在Buffer Pool里快速定位到对应的缓存页呢?难道需要一个非空闲的描述数据链表,再通过表空间号+数据页编号遍历查找吗?这样做也可以实现,但是效率不太高,时间复杂度是O(N)。
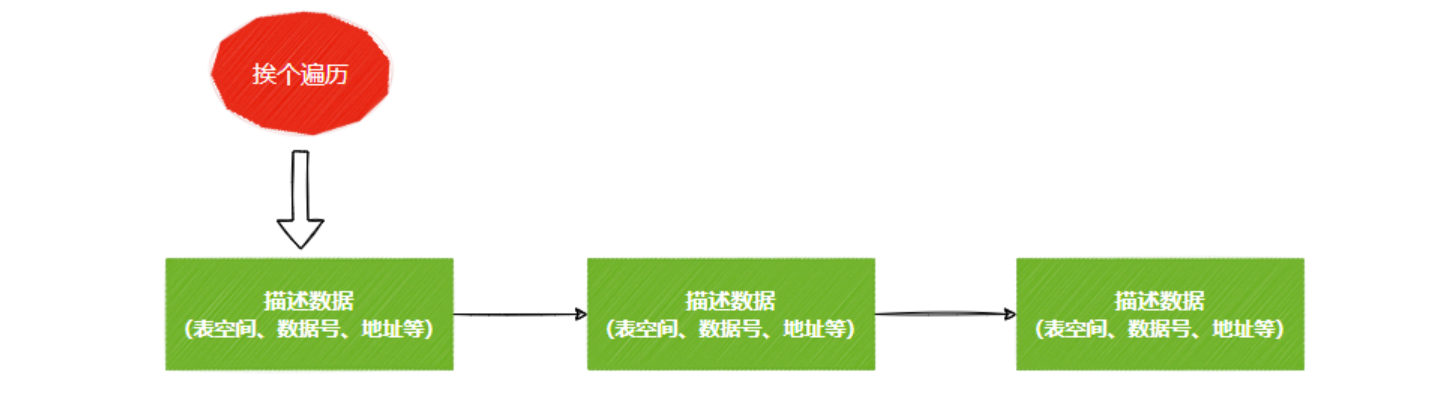
所以我们可以换一个结构,使用哈希表来缓存它们间的映射关系,时间复杂度是O(1)。
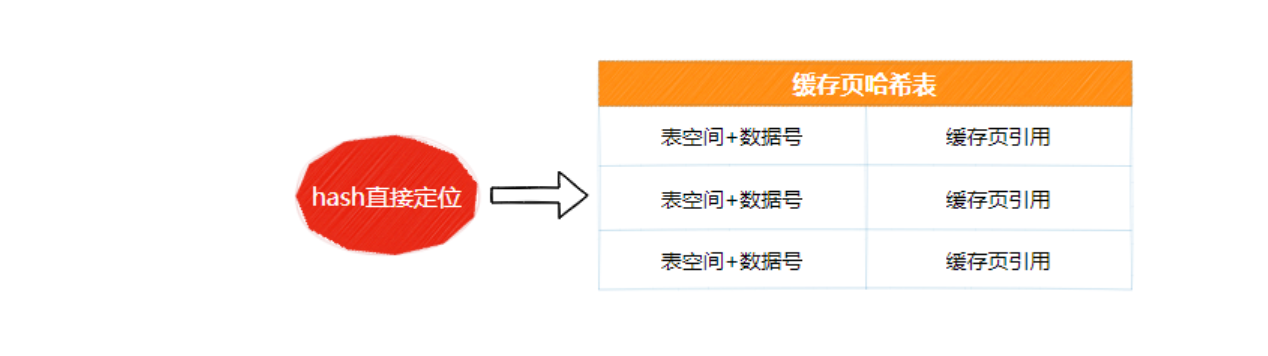
表空间号+数据页号,作为一个key,然后缓存页的地址作为value。每次加载数据页到空闲缓存页时,就写入一条映射关系到缓存页哈希表中。
后续的查询,就可以通过缓存页哈希表路由定位了。
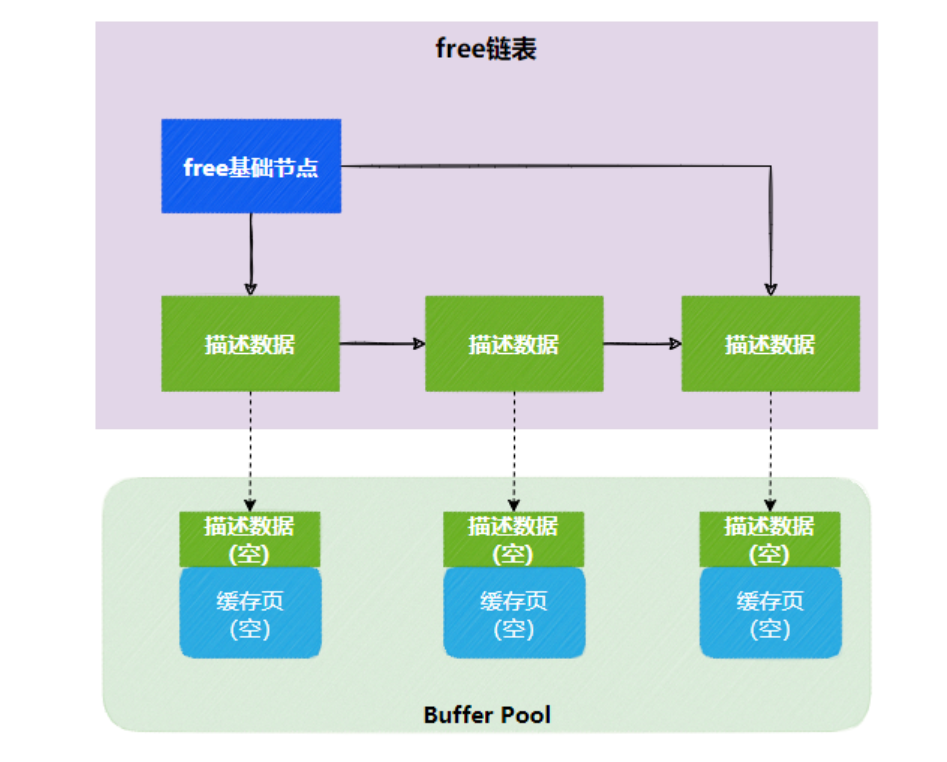
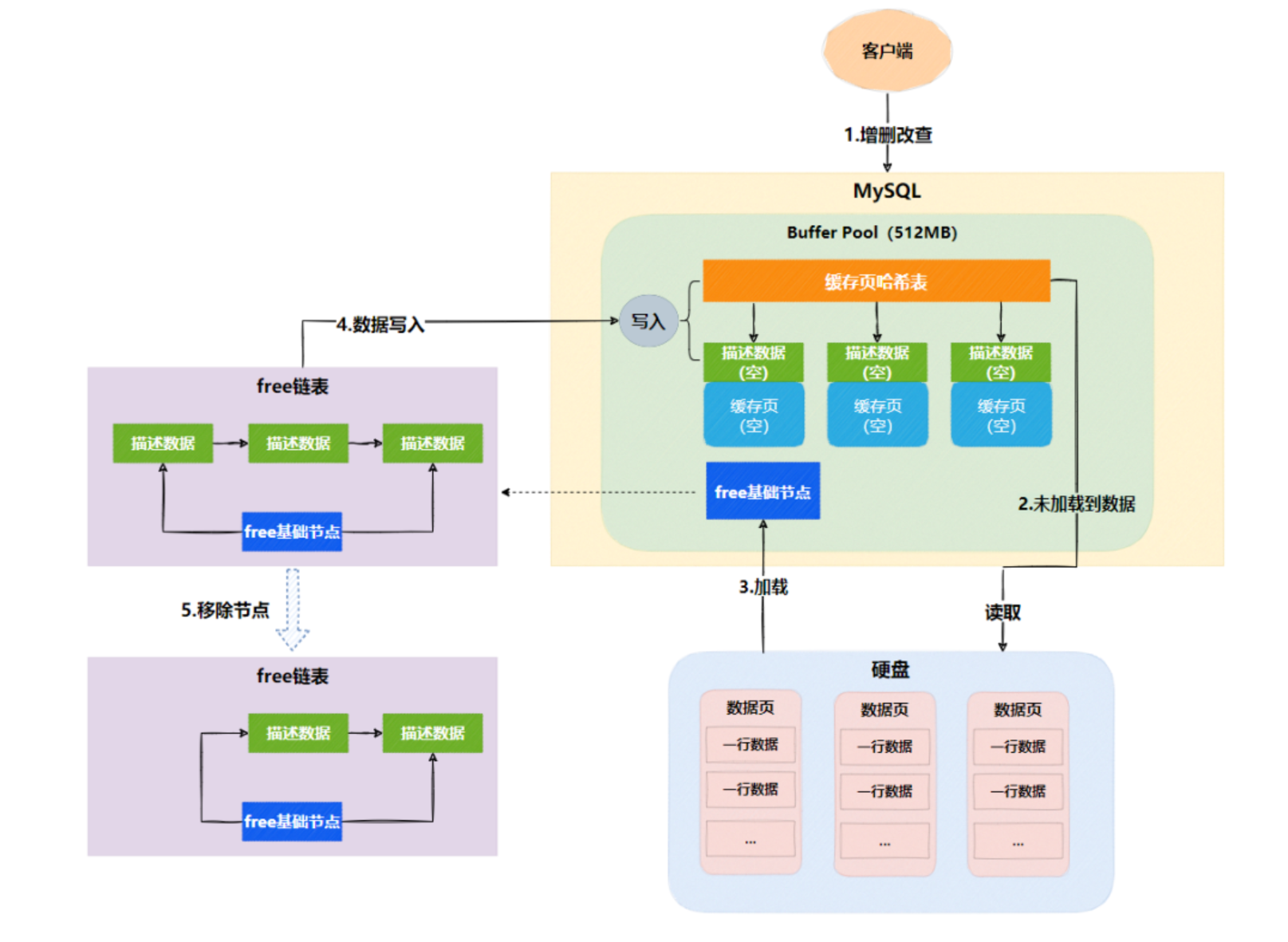
Free链表
Free链表可以帮助我们快速找到空闲的缓存页。当执行增删改查时,需要从数据页加载数据,然后从free链表(双向链表)中找到空闲的缓存页。把数据页的表空间号和数据页号写入描述信息块,加载数据到缓存页后,会把缓存页对应的描述信息块从free链表中移除。Free链表设计:
- 新增**
free基础节点** - 描述数据添加**
free节点指针**