【动手学深度学习】3.4. softmax回归
目录
- 3.4. softmax回归
- 1)分类问题
- 2)网络架构
- 3)全连接层的参数开销
- 4)softmax运算
- 5)小批量样本的矢量化
- 6)损失函数
- (1)对数似然
- (2)softmax及其导数
- (3)交叉熵损失
- 7)信息论基础
- (1)熵
- (2)信息量
- (3)交叉熵
- 8)模型预测和评估
.
3.4. softmax回归
回归可以用于预测多少的问题。事实上,我们也对分类问题感兴趣:不是问“多少”,而是问“哪一个”。
通常,机器学习实践者用分类这个词来描述两个有微妙差别的问题:
-
- 我们只对样本的“硬性”类别感兴趣,即属于哪个类别;
-
- 我们希望得到“软性”类别,即得到属于每个类别的概率。
这两者的界限往往很模糊。其中的一个原因是:即使我们只关心硬类别,我们仍然使用软类别的模型。
.
1)分类问题
我们从一个图像分类问题开始,输入为 2 x 2 的灰度图像,每个图像对应四个像素,表示为四个特征 x_1, x_2, x_3, x_4。此外,假设每个图像属于类别“猫”“鸡”和“狗”中的一个。
标签表示,两种常见方式:
-
整数编码:用 y ∈ { 1 , 2 , 3 } y \in \{1, 2, 3\} y∈{1,2,3} 表示类别(1 代表狗,2 代表猫,3 代表鸡)。这种格式适用于有自然顺序的类别。
-
独热编码(one-hot encoding):用一个向量表示标签,类别对应的分量为 1,其他为 0。例如,(1, 0, 0) 对应“猫”,(0, 1, 0) 对应“鸡”,(0, 0, 1) 对应“狗”。
独热编码不依赖类别间的自然顺序,适用于一般的分类问题。
.
2)网络架构
为估计所有可能类别的条件概率,我们需要一个有多个输出的模型,每个类别对应一个输出。为了解决线性模型的分类问题,我们需要和输出一样多的仿射函数(affine function)。
下例中,有4个特征和3个可能的输出类别, 需要12个标量来表示权重(带下标的), 3个标量来表示偏置(带下标的)。 下面我们为每个输入计算三个未规范化的预测(logit):o_1、o_2和o_3。
o 1 = x 1 w 11 + x 2 w 12 + x 3 w 13 + x 4 w 14 + b 1 , o 2 = x 1 w 21 + x 2 w 22 + x 3 w 23 + x 4 w 24 + b 2 , o 3 = x 1 w 31 + x 2 w 32 + x 3 w 33 + x 4 w 34 + b 3 . \begin{split}\begin{aligned} o_1 &= x_1 w_{11} + x_2 w_{12} + x_3 w_{13} + x_4 w_{14} + b_1,\\ o_2 &= x_1 w_{21} + x_2 w_{22} + x_3 w_{23} + x_4 w_{24} + b_2,\\ o_3 &= x_1 w_{31} + x_2 w_{32} + x_3 w_{33} + x_4 w_{34} + b_3. \end{aligned}\end{split} o1o2o3=x1w11+x2w12+x3w13+x4w14+b1,=x1w21+x2w22+x3w23+x4w24+b2,=x1w31+x2w32+x3w33+x4w34+b3.
用神经网络图来描述这个计算过程。
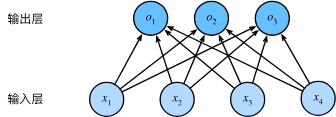
由于计算每个输出取决于所有输入, 所以softmax回归的输出层也是全连接层。
为简洁表达模型,我们仍然使用线性代数符号。 通过向量形式表达为 o = W x + b \mathbf{o} = \mathbf{W} \mathbf{x} + \mathbf{b} o=Wx+b, 这是一种更适合数学和编写代码的形式。
.
3)全连接层的参数开销
-
参数数量:输入维度 d,输出维度 q 时,参数量为 O ( d q ) \mathcal{O}(dq) O(dq)
-
优化策略:引入超参数 n,将计算复杂度降至 O ( d q / n ) \mathcal{O}(dq/n) O(dq/n)
超参数可以由我们灵活指定,以在实际应用中平衡参数节约和模型有效性。
.
4)softmax运算
不能将未规范化的预测o直接视作我们感兴趣的输出,因为将线性层的输出直接视为概率时存在一些问题:
-
一方面,我们没有限制这些输出数字的总和为1。
-
另一方面,根据输入的不同,它们可以为负值。
softmax 函数将未规范化的预测转换为非负且总和为 1 的概率分布,保持可导性:
-
首先对每个未规范化的预测求幂,这样可以确保输出非负。
-
为了确保最终输出的概率值总和为1,我们再让每个求幂后的结果除以它们的总和。
y ^ = s o f t m a x ( o ) 其中 y ^ j = exp ( o j ) ∑ k exp ( o k ) \hat{\mathbf{y}} = \mathrm{softmax}(\mathbf{o})\quad \text{其中}\quad \hat{y}_j = \frac{\exp(o_j)}{\sum_k \exp(o_k)} y^=softmax(o)其中y^j=∑kexp(ok)exp(oj)
因此,在预测过程中,我们仍然可以用下式来选择最有可能的类别。
argmax j y ^ j = argmax j o j \operatorname*{argmax}_j \hat y_j = \operatorname*{argmax}_j o_j argmaxjy^j=argmaxjoj
尽管softmax是一个非线性函数,但softmax回归的输出仍然由输入特征的仿射变换决定。 因此,softmax回归是一个线性模型(linear model)。
.
5)小批量样本的矢量化
为了提高计算效率并充分利用 GPU,对小批量样本进行矢量化计算。
假设,读取一批样本X, 其中特征维度(输入数量)为d,批量大小为n,输出有q个类别。
那么小批量样本的特征为 X ∈ R n × d \mathbf{X} \in \mathbb{R}^{n \times d} X∈Rn×d,权重为 W ∈ R d × k \mathbf{W} \in \mathbb{R}^{d \times k} W∈Rd×k,偏置为 b ∈ R 1 × k \mathbf{b} \in \mathbb{R}^{1 \times k} b∈R1×k,softmax 回归的矢量计算表达式为:
O = X W + b , Y ^ = s o f t m a x ( O ) . \begin{split}\begin{aligned} \mathbf{O} &= \mathbf{X} \mathbf{W} + \mathbf{b}, \\ \hat{\mathbf{Y}} & = \mathrm{softmax}(\mathbf{O}). \end{aligned}\end{split} OY^=XW+b,=softmax(O).
相对于一次处理一个样本, 小批量样本的矢量化加快了X和W的矩阵-向量乘法。 由于X中的每一行代表一个数据样本, 那么softmax运算可以按行(rowwise)执行: 对于的每一行,我们先对所有项进行幂运算,然后通过求和对它们进行标准化。 XW+b求和会使用广播机制, 小批量的未规范化预测O和输出概率 Y ^ \hat{\mathbf{Y}} Y^都是形状为n x q的矩阵。
.
6)损失函数
接下来,我们需要一个损失函数来度量预测的效果。 我们将使用最大似然估计,这与在线性回归 中的方法相同。
(1)对数似然
softmax函数给出向量 y ^ \hat{\mathbf{y}} y^是“对给定任意输入 x \mathbf{x} x的每个类的条件概率”。 例如, y ^ 1 = P ( y = 猫 ∣ x ) \hat{y}_1=P(y=\text{猫} \mid \mathbf{x}) y^1=P(y=猫∣x)。 设整个数据集{X, Y}具有 n 个样本, 索引 i 的样本由特征向量 x ( i ) \mathbf{x}^{(i)} x(i)和独热标签向量 y ( i ) \mathbf{y}^{(i)} y(i)组成。 我们可以将估计值与实际值进行比较:
- 由独立性,联合概率等于各概率的乘积:
P ( Y ∣ X ) = ∏ i = 1 n P ( y ( i ) ∣ x ( i ) ) P(\mathbf{Y} \mid \mathbf{X}) = \prod_{i=1}^n P(\mathbf{y}^{(i)} \mid \mathbf{x}^{(i)}) P(Y∣X)=i=1∏nP(y(i)∣x(i))
-
根据最大似然估计,我们最大化P(Y | X),相当于最小化负对数似然;
-
定义样本级损失 l ( y ( i ) , y ^ ( i ) ) = − log P ( y ( i ) ∣ x ( i ) ) l(\mathbf{y}^{(i)}, \hat{\mathbf{y}}^{(i)}) = -\log P(\mathbf{y}^{(i)} \mid \mathbf{x}^{(i)}) l(y(i),y^(i))=−logP(y(i)∣x(i)), 则:(对数特性:log(ab)=loga+logb)
− log P ( Y ∣ X ) = ∑ i = 1 n − log P ( y ( i ) ∣ x ( i ) ) = ∑ i = 1 n l ( y ( i ) , y ^ ( i ) ) -\log P(\mathbf{Y} \mid \mathbf{X}) = \sum_{i=1}^n -\log P(\mathbf{y}^{(i)} \mid \mathbf{x}^{(i)}) = \sum_{i=1}^n l(\mathbf{y}^{(i)}, \hat{\mathbf{y}}^{(i)}) −logP(Y∣X)=i=1∑n−logP(y(i)∣x(i))=i=1∑nl(y(i),y^(i))
其中,对于任何标签 y \mathbf{y} y和模型预测 y ^ \hat{\mathbf{y}} y^,
- 基于独热编码的性质:由于 y \mathbf{y} y 是独热编码,仅 y k = 1 y_k=1 yk=1,其余 y j = 0 y_j=0 yj=0:
P ( y ∣ x ) = ∏ j = 1 q ( y ^ j ) y j = ( y ^ 1 ) 0 × ⋯ × ( y ^ k ) 1 × ⋯ × ( y ^ q ) 0 = y ^ k P(\mathbf{y} \mid \mathbf{x}) = \prod_{j=1}^q (\hat{y}_j)^{y_j} = (\hat{y}_1)^0 \times \cdots \times (\hat{y}_k)^1 \times \cdots \times (\hat{y}_q)^0 = \hat{y}_k P(y∣x)=j=1∏q(y^j)yj=(y^1)0×⋯×(y^k)1×⋯×(y^q)0=y^k
- 则损失函数为:
l ( y , y ^ ) = log P ( y ∣ x ) = − log ( ∏ j = 1 q ( y ^ j ) y j ) = − ∑ j = 1 q y j log y ^ j l(\mathbf{y}, \hat{\mathbf{y}}) = \log P(\mathbf{y} \mid \mathbf{x}) = -\log \left( \prod_{j=1}^q (\hat{y}_j)^{y_j} \right) = - \sum_{j=1}^q y_j \log \hat{y}_j l(y,y^)=logP(y∣x)=−log(j=1∏q(y^j)yj)=−j=1∑qyjlogy^j
上式的损失函数,通常被称为交叉熵损失(cross-entropy loss)。
.
(2)softmax及其导数
利用softmax的定义和前面公式,我们得到损失函数初步公式,经过以下步骤化简:
-
由对数性质 log A B = log A − log B \log \frac{A}{B} = \log A - \log B logBA=logA−logB 得第一步;
-
由对数性质 log exp ( o j ) = o j \log \exp (o_j) = o_j logexp(oj)=oj 得第二步;
-
因独热标签向量 ∑ j = 1 q y j = 1 \sum _ {j=1} ^q y_j = 1 ∑j=1qyj=1 得第三步;
l ( y , y ^ ) = − ∑ j = 1 q y j log exp ( o j ) ∑ k = 1 q exp ( o k ) = − ∑ j = 1 q y j [ log exp ( o j ) − log ∑ k = 1 q exp ( o k ) ] = − ∑ j = 1 q y j o j + ∑ j = 1 q y j log ∑ k = 1 q exp ( o k ) = log ∑ k = 1 q exp ( o k ) − ∑ j = 1 q y j o j \begin{split}\begin{aligned} \\ l(\mathbf{y}, \hat{\mathbf{y}}) &= - \sum_{j=1}^q y_j \log \frac{\exp(o_j)}{\sum_{k=1}^q \exp(o_k)} \\ &= - \sum _ {j=1} ^q y_j [\log \exp (o_j) - \log \sum _ {k=1} ^q \exp (o_k) ] \\ &= - \sum _ {j=1} ^q y_j o_j + \sum _ {j=1} ^q y_j \log \sum _ {k=1} ^q \exp (o_k) \\ &= \log \sum _ {k=1} ^q \exp (o_k) - \sum _ {j=1} ^q y_j o_j \end{aligned}\end{split} l(y,y^)=−j=1∑qyjlog∑k=1qexp(ok)exp(oj)=−j=1∑qyj[logexp(oj)−logk=1∑qexp(ok)]=−j=1∑qyjoj+j=1∑qyjlogk=1∑qexp(ok)=logk=1∑qexp(ok)−j=1∑qyjoj
求损失函数对未规范化预测 o j o_j oj 的偏导 ∂ o j l ( y , y ^ ) \partial_{o_j} l(y, \hat{y}) ∂ojl(y,y^)。
∂ o j l ( y , y ^ ) = exp ( o j ) ∑ k = 1 q exp ( o k ) − y j = s o f t m a x ( o ) j − y j \partial_{o_j} l(\mathbf{y}, \hat{\mathbf{y}}) = \frac{\exp(o_j)}{\sum_{k=1}^q \exp(o_k)} - y_j = \mathrm{softmax}(\mathbf{o})_j - y_j ∂ojl(y,y^)=∑k=1qexp(ok)exp(oj)−yj=softmax(o)j−yj
化简步骤如下:
a.损失函数的第一部,可看作复合函数: log ∑ k = 1 q exp ( o k ) = g ( f ( o ) ) \log \sum_{k=1}^q \exp(o_k) = g(\ f(o)\ ) log∑k=1qexp(ok)=g( f(o) )
-
外层函数的导数 : g ( f ) = log f g(f) = \log f g(f)=logf 对 f 的导数是 1 f \frac{1}{f} f1。
-
内层函数导数 : f ( o ) = ∑ k = 1 q exp ( o k ) f(\mathbf{o}) = \sum_{k=1}^q \exp(o_k) f(o)=∑k=1qexp(ok) 对 o j o_j oj 的导数是 exp ( o j ) \exp(o_j) exp(oj)。
-
根据链式法则,外层函数通过内层函数对 o j o_j oj 的导数是两者的乘积:
∂ ∂ o j log ∑ k = 1 q exp ( o k ) = 1 ∑ k = 1 q exp ( o k ) ⋅ exp ( o j ) = exp ( o j ) ∑ k = 1 q exp ( o k ) \frac{\partial}{\partial o_j} \log \sum_{k=1}^q \exp(o_k) = \frac{1}{\sum_{k=1}^q \exp(o_k)} \cdot \exp(o_j) = \frac{\exp(o_j)}{\sum_{k=1}^q \exp(o_k)} ∂oj∂logk=1∑qexp(ok)=∑k=1qexp(ok)1⋅exp(oj)=∑k=1qexp(ok)exp(oj)
b.损失函数的第二部分,是 − ∑ j = 1 q y j o j -\sum_{j=1}^q y_j o_j −∑j=1qyjoj。
-
对 o j o_j oj 求导时,只有项 y j o j y_j o_j yjoj 会有贡献,其他项的导数为 0 ;
-
所以这部分对 o j o_j oj 的导数为:
∂ ∂ o j ( − ∑ j = 1 q y j o j ) = − y j \frac{\partial}{\partial o_j} \left( -\sum_{j=1}^q y_j o_j \right) = -y_j ∂oj∂(−j=1∑qyjoj)=−yj
softmax 模型中损失函数对未规范化预测值的导数,等于模型分配的预测概率与独热标签表示的真实情况之间的差异。这一形式与回归问题中 “观测值与估计值的梯度差异” 具有一致性,其本质源于指数族分布模型的对数似然梯度性质 —— 该性质使得梯度可直接由预测值与真实值的偏差表示,从而简化了实际优化过程中的梯度计算。
.
(3)交叉熵损失
当处理多结果分类问题时,标签可表示为概率向量(而非二元独热向量),此时损失函数沿用 l ( y , y ^ ) = − ∑ j = 1 q y j log y ^ j l(\mathbf{y}, \hat{\mathbf{y}}) = - \sum_{j=1}^q y_j \log \hat{y}_j l(y,y^)=−∑j=1qyjlogy^j 定义为所有标签分布的预期损失,该损失称为交叉熵损失,是分类任务中最常用的损失函数之一。理解交叉熵损失需借助信息论基础(详见本书附录信息论相关内容)。
.
7)信息论基础
信息论(information theory)涉及编码、解码、发送以及尽可能简洁地处理信息或数据。
(1)熵
信息论的核心思想是量化数据中的信息内容。 在信息论中,该数值被称为分布的熵(entropy)。可以通过以下方程得到:
H [ P ] = ∑ j − P ( j ) log P ( j ) H[P] = \sum_j - P(j) \log P(j) H[P]=j∑−P(j)logP(j)
信息论的基本定理之一指出,为了对从分布p中随机抽取的数据进行编码, 我们至少需要H[P]“纳特(nat)”对其进行编码。 “纳特”相当于比特(bit),但是对数底为e而不是2。因此,一个纳特是 1 log ( 2 ) ≈ 1.44 \frac{1}{\log(2)} \approx 1.44 log(2)1≈1.44比特。
.
(2)信息量
压缩与预测的关系:数据的可预测性决定其压缩难度
-
高可预测性:如数据流中所有数据完全相同,此时下一个数据完全确定,无需传输任何信息(“无信息量”)。
-
低可预测性:事件难以预测时,传递数据需要更多信息。
信息量的定义(克劳德・香农):
-
量化指标:用 信息量 衡量观察事件时的 “惊异程度”。
-
信息量公式: log 1 P ( j ) = − log P ( j ) \log \frac{1}{P(j)} = -\log P(j) logP(j)1=−logP(j), P ( j ) P(j) P(j)是事件 j j j 的主观概率。事件概率越低,信息量越大。
熵的定义:
-
在 H [ P ] = ∑ j − P ( j ) log P ( j ) H[P] = \sum_j - P(j) \log P(j) H[P]=∑j−P(j)logP(j) 中定义的熵,是当概率分配与数据生成过程真正匹配时,信息量的期望值。
-
熵反映了数据的平均不确定性,熵越大,数据的平均不确定性越高。
.
(3)交叉熵
核心概念
-
熵 H( P) :“知道真实概率 P 的人所经历的惊异程度”
-
交叉熵 H(P, Q):“主观概率为 Q 的观察者看到 P 生成数据时的预期惊异”
关键性质
-
当主观概率 Q 匹配真实概率 P 时:H(P, Q) 最小化,且H(P, P) = H( P);
-
交叉熵是熵的上界:H(P, Q) ≥ H( P) ;
在机器学习中的双重意义
-
统计视角:最大化观测数据的似然
-
信息论视角:最小化传达标签所需的惊异
.
8)模型预测和评估
在训练softmax回归模型后,给出任何样本特征,我们可以预测每个输出类别的概率。
通常我们使用预测概率最高的类别作为输出类别。 如果预测与实际类别(标签)一致,则预测是正确的。
在接下来的实验中,我们将使用精度(accuracy)来评估模型的性能。
- 精度 = 正确预测数 / 预测总数
.
声明:资源可能存在第三方来源,若有侵权请联系删除!