MySQL存储引擎--深度解析
写在前面
在 MySQL 数据库体系中,存储引擎是决定数据存储、管理及访问效率的核心组件。下面博主给大家分享一下本人对mysql存储引擎的理解。话不多说!
博主总结 (方便有基础的同学食用)
- 存储引擎
- 存储引擎的选择
- 大多数情况下,使用默认的 InnoDB 就可以了,InnoDB 可以提供事务、行级锁、外键、B+ 树索引等能力。
- MyISAM 适合读多写少的场景。
- MEMORY 适合临时表,数据量不大的情况。因为数据都存放在内存,所以速度非常快。
- InnoDB 和 MyISAM 主要有什么区别?
- 根据图中的角度来说
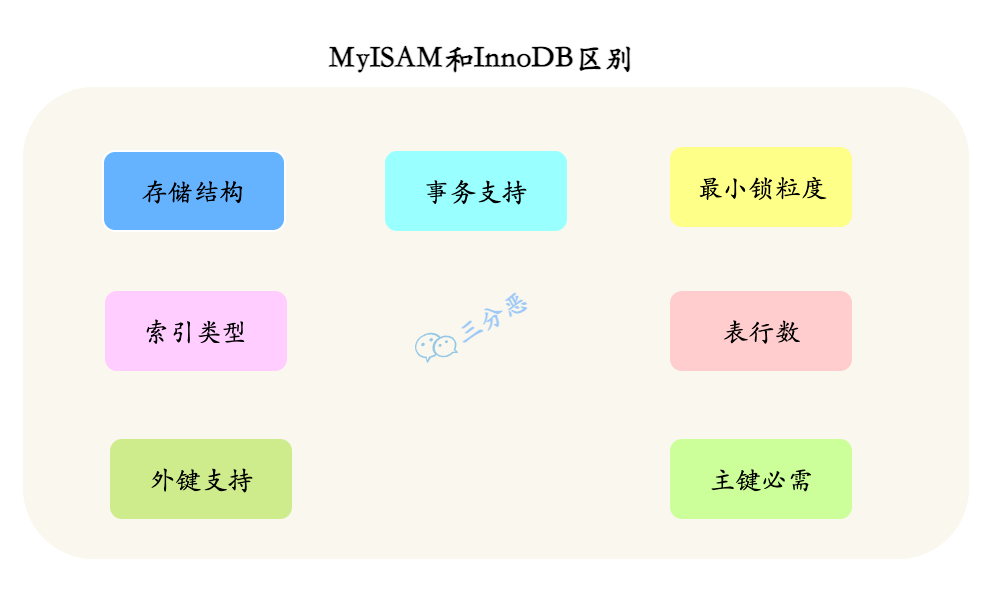
- InnoDB 和 MyISAM 的最大区别在于事务支持和锁机制。InnoDB 支持事务、行级锁,适合大多数业务系统;而 MyISAM 不支持事务,用的是表锁,查询快但写入性能差,适合读多写少的场景。
- 另外,从存储结构上来说,MyISAM 用三种格式的文件来存储,.frm 文件存储表的定义;.MYD 存储数据;.MYI 存储索引;而 InnoDB 用两种格式的文件来存储,.frm 文件存储表的定义;.ibd 存储数据和索引。
- 从索引类型上来说,MyISAM 为非聚簇索引,索引和数据分开存储,索引保存的是数据文件的指针。
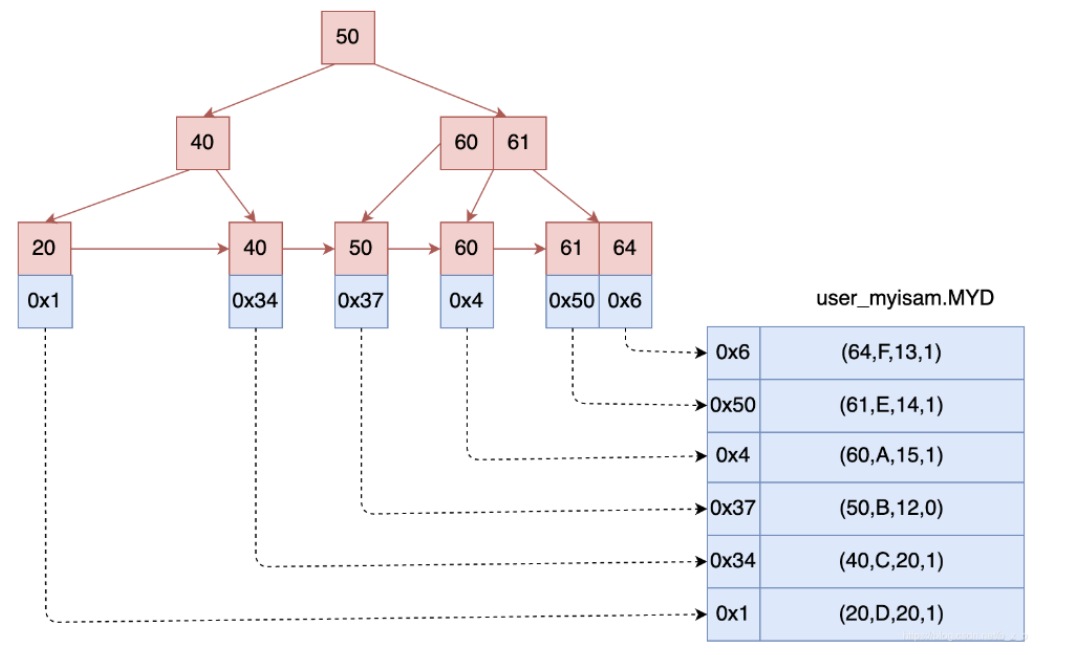
- InnoDB 为聚簇索引,索引和数据不分开。
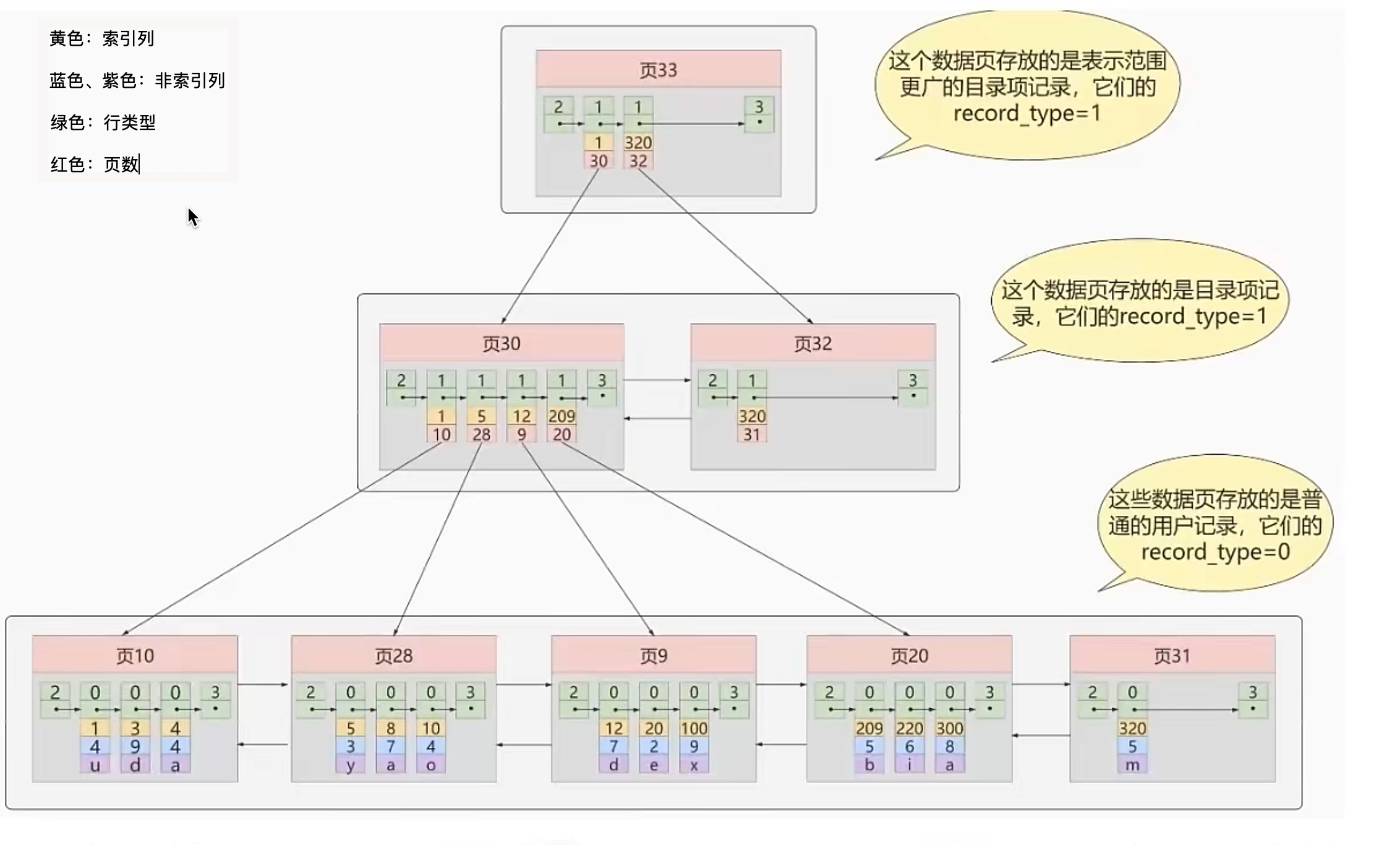
- 更细微的层面上来讲,MyISAM 不支持外键,可以没有主键,表的具体行数存储在表的属性中,查询时可以直接返回;InnoDB 支持外键,必须有主键,具体行数需要扫描整个表才能返回,有索引的情况下会扫描索引。
- 根据图中的角度来说
- InnoDB 的 Buffer Pool了解吗?(补充)
- Buffer Pool 是什么?作用?
- Buffer Pool 是 InnoDB 存储引擎中的一个内存缓冲区,它会将经常使用的数据页、索引页加载进内存,读的时候先查询 Buffer Pool,如果命中就不用访问磁盘了。 如果没有命中,就从磁盘读取,并加载到 Buffer Pool,此时可能会触发页淘汰,将不常用的页移出 Buffer Pool。写操作时不会直接写入磁盘,而是先修改内存中的页,此时页被标记为脏页,后台线程会定期将脏页刷新到磁盘。 Buffer Pool 可以显著减少磁盘的读写次数,从而提升 MySQL 的读写性能。
- Buffer Pool 的默认大小是多少?
- 我本机上 InnoDB 的 Buffer Pool 默认大小是 128MB。可以通过改命令查看:SHOW VARIABLES LIKE 'innodbbufferpool_size';
- 另外,在具有 1GB-4GB RAM 的系统上,默认值为系统 RAM 的 25%;在具有超过 4GB RAM 的系统上,默认值为系统 RAM 的 50%,但不超过 4GB。
- buffer_pool 的默认大小 InnoDB 对 LRU 算法的优化了解吗?
- 了解,InnoDB 对 LRU 算法进行了改良,最近访问的数据并不直接放到 LRU 链表的头部,而是放在一个叫 midpoiont 的位置。默认情况下,midpoint 位于 LRU 列表的 5/8 处。 当页数据被频繁访问后,再将其移动到 young 区,这样做的好处是热点页能长时间保留在内存中,不容易被挤出去。
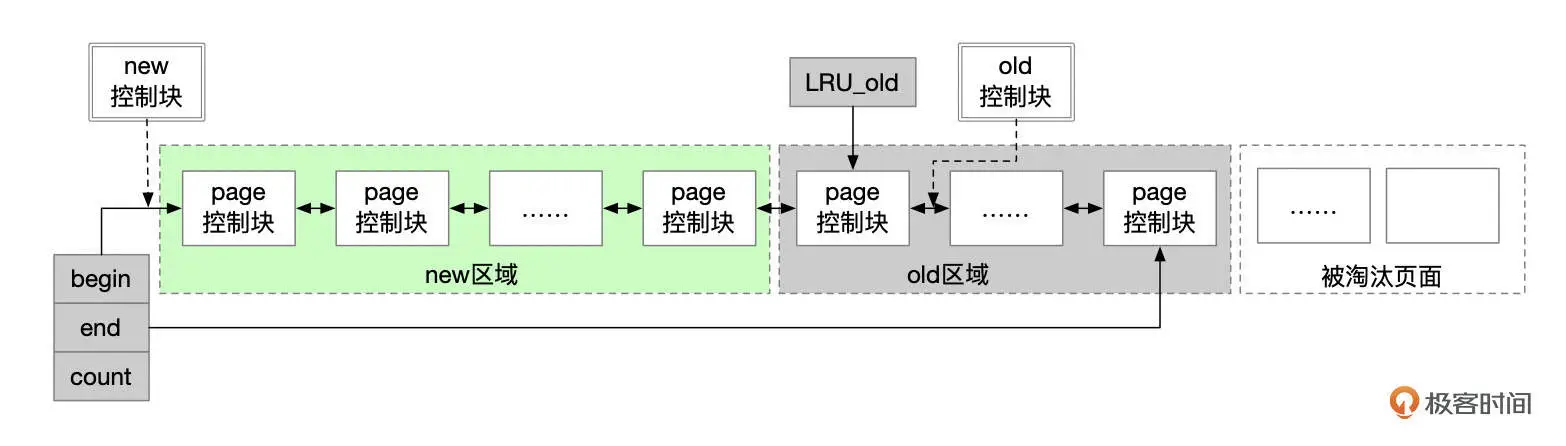
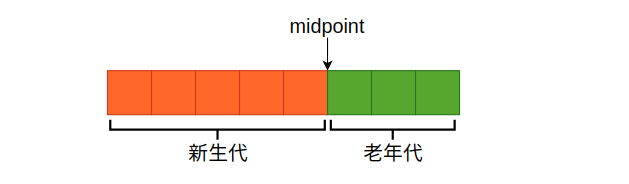
- 了解,InnoDB 对 LRU 算法进行了改良,最近访问的数据并不直接放到 LRU 链表的头部,而是放在一个叫 midpoiont 的位置。默认情况下,midpoint 位于 LRU 列表的 5/8 处。 当页数据被频繁访问后,再将其移动到 young 区,这样做的好处是热点页能长时间保留在内存中,不容易被挤出去。
- Buffer Pool 是什么?作用?
- 存储引擎的选择
一、MySQL 存储引擎概述
MySQL 的架构设计使其具备插件式存储引擎特性,这一设计极大地提升了数据库的灵活性和扩展性。用户可以根据具体的业务需求,在同一数据库实例中选用不同的存储引擎,为不同的表定制专属的数据管理方案。这种模块化的设计理念,让 MySQL 能够广泛适配各类复杂的业务场景,无论是高并发事务处理,还是海量数据查询分析,都能找到合适的存储引擎与之匹配。
二、常见 MySQL 存储引擎深度解析
1. InnoDB:事务处理的黄金标准
InnoDB 是 MySQL 5.5 之后的默认存储引擎,以强大的事务处理能力和数据完整性保障著称。它支持完整的 ACID 事务特性,通过事务日志(重做日志和回滚日志)实现崩溃恢复,确保在系统故障时数据不丢失且一致性得以维持。在锁机制方面,InnoDB 采用行级锁,大大降低了锁冲突的概率,显著提升了高并发场景下的读写性能。此外,InnoDB 还支持外键约束,能够有效维护表与表之间的关联关系,避免数据不一致问题。
在实际应用中,电商系统的订单处理模块就是 InnoDB 的典型应用场景。订单创建、支付处理、库存扣减等操作都需要保证原子性和一致性,InnoDB 通过事务机制确保这些操作要么全部成功,要么全部回滚。同时,高并发的订单请求下,行级锁能够减少锁等待时间,提升系统响应速度。
2. MyISAM:高效查询的轻量级选择
MyISAM 是 MySQL 早期常用的存储引擎,以其简单高效的存储结构和出色的查询性能闻名。它不支持事务和外键约束,采用表级锁机制,虽然在高并发写入场景下可能出现性能瓶颈,但在以读为主的应用中表现优异。MyISAM 的表由.frm(表结构文件)、.MYD(数据文件)和.MYI(索引文件)三个文件组成,这种存储方式使得数据读取速度极快,并且支持全文索引,在文本搜索场景中具有天然优势。
例如,新闻资讯类网站的文章存储就非常适合使用 MyISAM。这类网站的业务特点是文章的读取操作远多于写入操作,且对数据一致性要求不高。MyISAM 的快速查询性能和轻量级存储结构,能够高效支撑海量文章的存储和检索需求。
3. Memory:内存中的极速数据处理
Memory 存储引擎将数据完全存储在内存中,这使其具备了极快的读写速度,适用于临时数据存储和高速缓存场景。它支持哈希索引和 B 树索引,能够快速定位和检索数据。然而,由于数据存储在内存中,一旦 MySQL 服务重启,所有数据都会丢失,因此 Memory 引擎通常用于存储临时计算结果、缓存热门数据等对数据持久性要求不高的场景。
以在线游戏的排行榜系统为例,玩家的实时排名数据需要频繁更新和查询,使用 Memory 引擎可以将这些数据存储在内存中,实现快速的读写操作,提升游戏的响应速度和用户体验。同时,当游戏服务器重启时,排行榜数据可以通过其他方式重新生成,不会对系统造成严重影响。
4. Archive:海量历史数据的存储利器
Archive 存储引擎专门设计用于存储大量历史数据,以其超高的压缩比和较低的存储成本成为历史数据归档的首选。它采用行级压缩算法,能够将数据压缩到原始大小的几分之一甚至更低,大大节省了磁盘空间。Archive 引擎只支持插入和查询操作,不支持事务和索引,适合用于存储日志文件、历史交易记录等只需要追加写入和偶尔查询的数据。
例如,金融机构的交易日志每天都会产生海量数据,这些数据在短期内可能需要查询分析,但随着时间推移,查询频率逐渐降低。使用 Archive 引擎存储这些历史交易日志,既能满足数据长期保存的需求,又能有效降低存储成本,同时在需要查询时也能快速定位到相关数据。
5. CSV:数据交换的便捷桥梁
CSV(Comma-Separated Values)存储引擎以逗号分隔值的文本格式存储数据,具有良好的兼容性和易读性。它的表数据以纯文本形式保存,无需复杂的存储结构,便于与其他应用程序进行数据交换,如 Excel 等办公软件。CSV 引擎不支持索引和事务,适用于简单的数据存储和临时数据交换场景。
在实际工作中,当需要将数据库中的部分数据导出到 Excel 进行分析时,使用 CSV 引擎存储相关数据可以直接通过文件读取的方式导入 Excel,无需进行复杂的数据格式转换。同样,从 Excel 中整理好的数据也可以方便地导入到 CSV 表中,实现数据的快速交换和共享。
三、MySQL 存储引擎选型策略
1. 业务需求分析
- 事务要求:如果业务涉及大量的事务操作,如金融交易、订单处理等,需要保证数据的原子性、一致性、隔离性和持久性,那么 InnoDB 是不二之选。
- 读写模式:对于以读为主的应用,如新闻网站、数据报表系统等,MyISAM 的高效查询性能能够满足需求;而对于读写并发较高的场景,InnoDB 的行级锁和事务支持则更具优势。
- 数据一致性:如果数据一致性要求严格,外键约束和事务机制是必不可少的,此时应选择 InnoDB。
- 数据量和存储成本:对于海量历史数据存储,Archive 引擎的高压缩比能够有效降低存储成本;而对于内存充足且对读写速度要求极高的临时数据,Memory 引擎是更好的选择。
2. 性能测试与优化
在确定初步的存储引擎选型后,建议通过性能测试来验证其在实际业务场景中的表现。可以使用 MySQL 自带的基准测试工具,如 mysqlslap、sysbench 等,模拟真实的业务负载,对不同存储引擎进行性能测试。根据测试结果,进一步调整存储引擎的参数配置或优化数据库设计,以达到最佳的性能表现。
3. 案例分析
- 电商平台:订单表、用户表等核心业务表使用 InnoDB,以保证事务完整性和高并发处理能力;商品展示表等以读为主的表可以考虑使用 MyISAM,提升查询性能。
- 日志分析系统:日志表使用 Archive 引擎进行存储,既能满足海量日志数据的长期保存需求,又能节省存储空间;对于实时日志分析,可结合 Memory 引擎存储临时计算结果,提高分析效率。