基于RocketMQ源码理解顺序写、刷盘机制与零拷贝
顺序写加速文件写入磁盘
通常应用程序往磁盘写文件时,由于磁盘空间不是连续的,会有很多碎片。所以我们去写一个文件时,也就无法把一个文件写在一块连续的磁盘空间中,而需要在磁盘多个扇区之间进行大量的随机写。这个过程中有大量的寻址操作,会严重影响写数据的性能。而顺序写机制是在磁盘中提前申请一块连续的磁盘空间,每次写数据时,记录下次开始地址,就可以避免这些寻址操作,直接在之前写入的地址后面接着写就行。
在RocketMQ实现的DefaultMappedFile中就是用顺序写,并且在CommitLog.asyncPutMessage使用自适应自旋锁(AdaptiveBackOffSpinLockImpl)putMessageLock.lock();
public class DefaultMappedFile extends AbstractMappedFile {...public AppendMessageResult appendMessagesInner(final MessageExt messageExt, final AppendMessageCallback cb,PutMessageContext putMessageContext) {assert messageExt != null;assert cb != null;int currentPos = WROTE_POSITION_UPDATER.get(this);//获取文件写入地址到哪了if (currentPos < this.fileSize) {ByteBuffer byteBuffer = appendMessageBuffer().slice();byteBuffer.position(currentPos);AppendMessageResult result;if (messageExt instanceof MessageExtBatch && !((MessageExtBatch) messageExt).isInnerBatch()) {// traditional batch messageresult = cb.doAppend(this.getFileFromOffset(), byteBuffer, this.fileSize - currentPos,(MessageExtBatch) messageExt, putMessageContext);} else if (messageExt instanceof MessageExtBrokerInner) {// traditional single message or newly introduced inner-batch messageresult = cb.doAppend(this.getFileFromOffset(), byteBuffer, this.fileSize - currentPos,(MessageExtBrokerInner) messageExt, putMessageContext);} else {return new AppendMessageResult(AppendMessageStatus.UNKNOWN_ERROR);}WROTE_POSITION_UPDATER.addAndGet(this, result.getWroteBytes());//维护下次文件写入地址this.storeTimestamp = result.getStoreTimestamp();return result;}log.error("MappedFile.appendMessage return null, wrotePosition: {} fileSize: {}", currentPos, this.fileSize);return new AppendMessageResult(AppendMessageStatus.UNKNOWN_ERROR);}
}
刷盘机制保证消息不丢失
在操作系统层面,为了提升性能,写文件的操作通常不会立即写入磁盘,而是先写入内存缓冲区(Page Cache),由操作系统或应用程序在合适的时机统一写入磁盘。这样虽然快,但有个问题:如果系统突然宕机,缓冲区中的数据会丢失。所以,我们就需要“刷盘”,确保数据已经真正写入磁盘,而不是还停留在内存里。
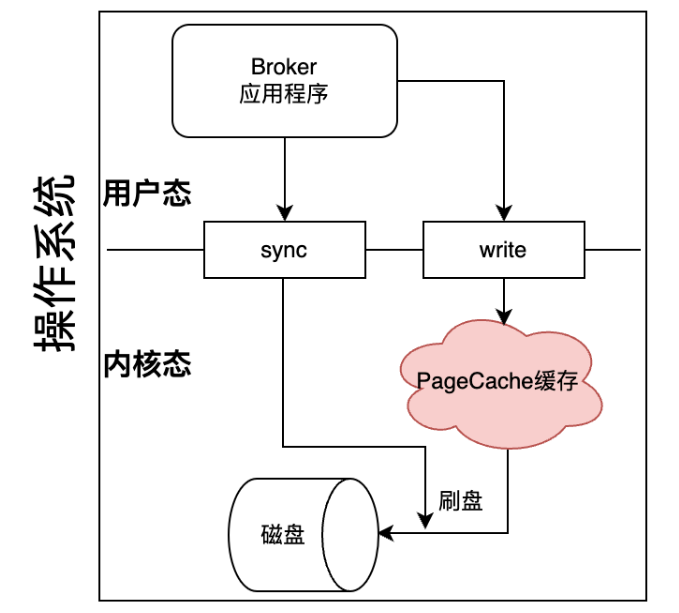
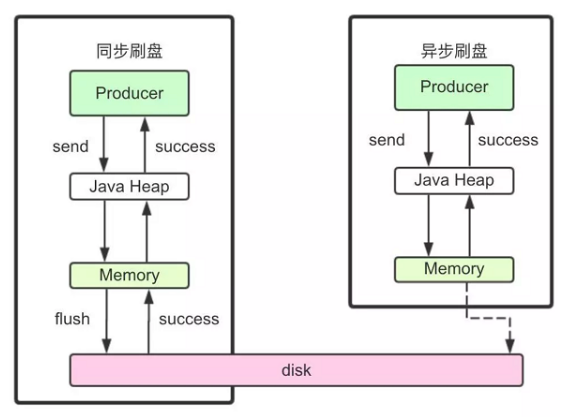
RocketMQ中,commitLog的异步刷盘服务是FlushRealTimeService,GroupCommitService是同步刷盘(间隔短的异步刷盘并且采用双缓冲(间隔10ms一刷))
public DefaultFlushManager() {if (FlushDiskType.SYNC_FLUSH == CommitLog.this.defaultMessageStore.getMessageStoreConfig().getFlushDiskType()) {this.flushCommitLogService = new CommitLog.GroupCommitService();} else {this.flushCommitLogService = new CommitLog.FlushRealTimeService();}this.commitRealTimeService = new CommitLog.CommitRealTimeService();}
FlushRealTimeService刷盘关键代码
class FlushRealTimeService extends FlushCommitLogService {@Overridepublic void run() {CommitLog.log.info(this.getServiceName() + " service started");while (!this.isStopped()) {boolean flushCommitLogTimed = CommitLog.this.defaultMessageStore.getMessageStoreConfig().isFlushCommitLogTimed();int interval = CommitLog.this.defaultMessageStore.getMessageStoreConfig().getFlushIntervalCommitLog();//获取刷盘间隔500int flushPhysicQueueLeastPages = CommitLog.this.defaultMessageStore.getMessageStoreConfig().getFlushCommitLogLeastPages();int flushPhysicQueueThoroughInterval =CommitLog.this.defaultMessageStore.getMessageStoreConfig().getFlushCommitLogThoroughInterval();boolean printFlushProgress = false;// Print flush progresslong currentTimeMillis = System.currentTimeMillis();if (currentTimeMillis >= (this.lastFlushTimestamp + flushPhysicQueueThoroughInterval)) {this.lastFlushTimestamp = currentTimeMillis;flushPhysicQueueLeastPages = 0;printFlushProgress = (printTimes++ % 10) == 0;}try {if (flushCommitLogTimed) {Thread.sleep(interval);//休眠刷盘间隔} else {this.waitForRunning(interval);//等待刷盘间隔}if (printFlushProgress) {this.printFlushProgress();}long begin = System.currentTimeMillis();CommitLog.this.mappedFileQueue.flush(flushPhysicQueueLeastPages);//参数控制刷盘的最小页数,避免频繁小数据量刷盘long storeTimestamp = CommitLog.this.mappedFileQueue.getStoreTimestamp();if (storeTimestamp > 0) {CommitLog.this.defaultMessageStore.getStoreCheckpoint().setPhysicMsgTimestamp(storeTimestamp);}long past = System.currentTimeMillis() - begin;CommitLog.this.getMessageStore().getPerfCounter().flowOnce("FLUSH_DATA_TIME_MS", (int) past);if (past > 500) {log.info("Flush data to disk costs {} ms", past);}} catch (Throwable e) {CommitLog.log.warn(this.getServiceName() + " service has exception. ", e);this.printFlushProgress();}}// Normal shutdown, to ensure that all the flush before exitboolean result = false;for (int i = 0; i < RETRY_TIMES_OVER && !result; i++) {result = CommitLog.this.mappedFileQueue.flush(0);CommitLog.log.info(this.getServiceName() + " service shutdown, retry " + (i + 1) + " times " + (result ? "OK" : "Not OK"));}this.printFlushProgress();CommitLog.log.info(this.getServiceName() + " service end");}}RocketMQ对于何时进行刷盘,也设计了两种刷盘机制,同步刷盘和异步刷盘。只需要在broker.conf中进行配置就行。
零拷贝加速文件读写
零拷贝(Zero-Copy) 是一种优化技术,旨在减少数据在用户态(User Space)和内核态(Kernel Space)之间的拷贝次数,从而提高 I/O 性能,尤其在处理大数据量(如网络传输、文件传输)时效果显著。
所谓的零拷贝技术,其实并不是不拷贝,而是要尽量减少CPU拷贝
- CPU拷贝和DMA拷贝
操作系统对于内存空间,是分为用户态和内核态的。用户态的应用程序无法直接操作硬件,需要通过内核空间进行操作转换,才能真正操作硬件。这些IO接口都是由CPU独立负责,所以当发生大规模的数据读写操作时,CPU的占用率会非常高。
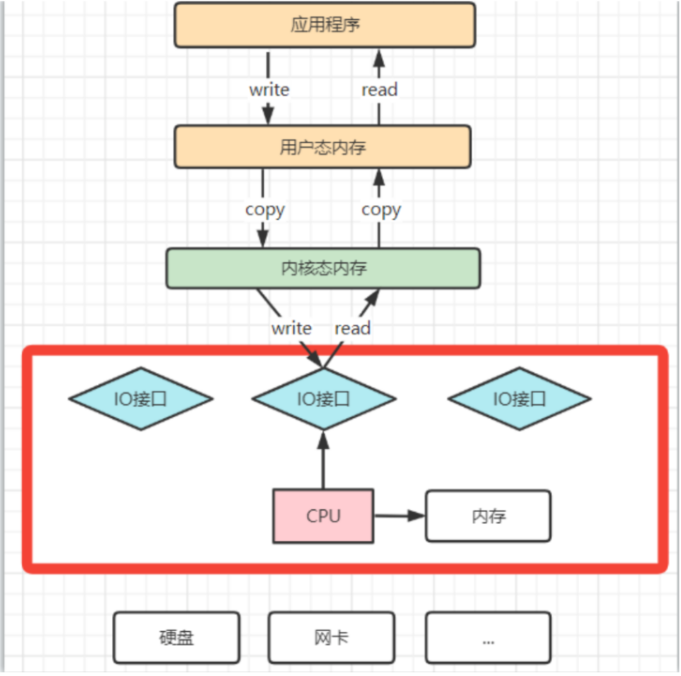
操作系统为了避免CPU完全被各种IO调用给占用,引入了DMA(直接存储器存储)。由DMA来负责这些频繁的IO操作。DMA是一套独立的指令集,不会占用CPU的计算资源。这样,CPU就不需要参与具体的数据复制的工作,只需要管理DMA的权限即可。
DMA在拷贝数据的过程cpu就可以继续工作了
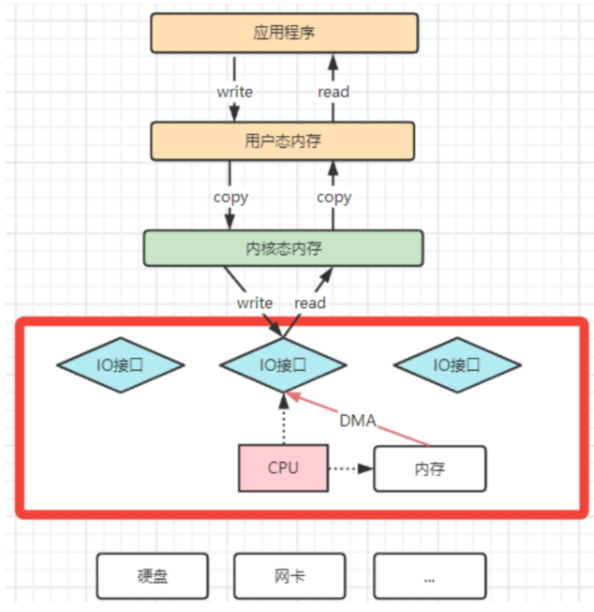
引入DMA拷贝之后,在读写请求的过程中,CPU不再需要参与具体的工作,DMA可以独立完成数据在系统内部的复制。但是,数据复制过程中,依然需要借助数据总进线。当系统内的IO操作过多时,还是会占用过多的数据总线,造成总线冲突,最终还是会影响数据读写性能。在早期大型计算机中,为了减轻 CPU I/O 负担,引入了专门的 I/O Channel(硬件处理器)来执行 I/O 操作。现代编程语言如 Java 中的 Channel 继承了这一思想,提供了更高效的 I/O 抽象,但它本质是一个软件接口,不具备硬件通道的能力。
- mmap文件映射机制
mmap 是一种操作系统提供的内存映射机制,允许进程将一个文件或设备的内容直接映射到进程的虚拟内存空间。
主要是通过java.nio.channels.FileChannel的map方法完成映射。以一次文件的读写操作为例,应用程序对磁盘文件的读与写,都需要经过内核态与用户态之间的状态切换,每次状态切换的过程中,就需要有大量的数据复制。
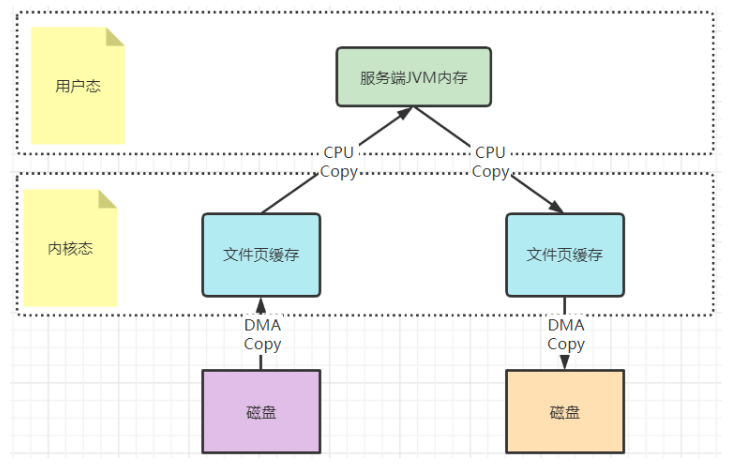
在这个过程中,总共需要进行四次数据拷贝。而磁盘与内核态之间的数据拷贝,在操作系统层面已经由CPU拷贝优化成了DMA拷贝。而内核态与用户态之间的拷贝依然是CPU拷贝。所以,在这个场景下,零拷贝技术优化的重点,就是内核态与用户态之间的这两次拷贝。
而mmap文件映射的方式,就是在用户态不再保存文件的内容,进程可以像访问普通内存一样,通过指针访问文件内容,只保存文件的映射,包括文件的内存起始地址,文件大小等。真实的数据也不需要在用户态留存,可以直接通过操作映射,在内核态完成数据复制。
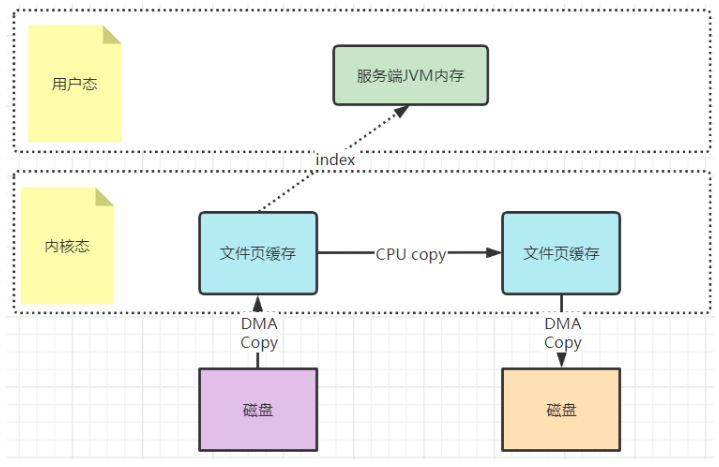
在JDK的NIO包中,java.nio.HeapByteBuffer映射的就是JVM的一块堆内内存,在HeapByteBuffer中,会由一个byte数组来缓存数据内容,所有的读写操作也是先操作这个byte数组。这其实就是没有使用零拷贝的普通文件读写机制。
HeapByteBuffer(int cap, int lim) { // package-privatesuper(-1, 0, lim, cap, new byte[cap], 0);/*hb = new byte[cap];offset = 0;*/}
而NIO把包中的另一个实现类java.nio.DirectByteBuffer则映射的是一块堆外内存。在DirectByteBuffer中,并没有一个数据结构来保存数据内容,只保存了一个内存地址。所有对数据的读写操作,都通过unsafe魔法类直接交由内核完成,这其实就是mmap的读写机制。可以看到没有直接获取文件的数据
// DirectByteBuffer构造函数核心逻辑
DirectByteBuffer(int cap) {// 判断虚拟机是否要求直接内存地址页对齐(Page Aligned)boolean pa = VM.isDirectMemoryPageAligned();// 获取系统页面大小(通常4KB)int ps = Bits.pageSize();// 计算申请内存大小:如果需要页对齐,则多申请一个页面大小的空间以方便对齐// Math.max确保至少分配1字节,避免0字节申请异常long size = Math.max(1L, (long)cap + (pa ? ps : 0));// 预先申请直接内存配额,防止超出允许的直接内存限制Bits.reserveMemory(size, cap);long base = 0;try {// 通过Unsafe调用本机接口,分配size字节的堆外内存,返回内存起始地址base = UNSAFE.allocateMemory(size);} catch (OutOfMemoryError x) {// 如果分配失败,撤销之前的内存配额申请,防止配额泄漏Bits.unreserveMemory(size, cap);// 抛出内存不足错误throw x;}// 将申请的内存全部置零,避免使用到未初始化的脏数据UNSAFE.setMemory(base, size, (byte) 0);// 计算页对齐后的起始地址:// (base & (ps - 1)) 获取内存地址的页内偏移,// ps - 页内偏移即对齐到下一个页边界的偏移量,// base + 偏移值即对齐后的内存地址address = (base + ps - (base & (ps - 1)));// 创建Cleaner对象,绑定一个Deallocator回调任务,用于在DirectByteBuffer对象回收时释放本机内存cleaner = Cleaner.create(this, new Deallocator(base, size, cap));
}
- sendFile机制
sendFile 是一种高效的文件传输机制,允许将文件直接从文件系统传输到网络套接字,而不需要经过用户空间缓冲区的拷贝。
sendFile机制的具体实现参见配套示例代码。主要是通过java.nio.channels.FileChannel的transferTo方法完成。
早期的sendfile实现机制其实还是依靠CPU进行页缓存与socket缓存区之间的数据拷贝。
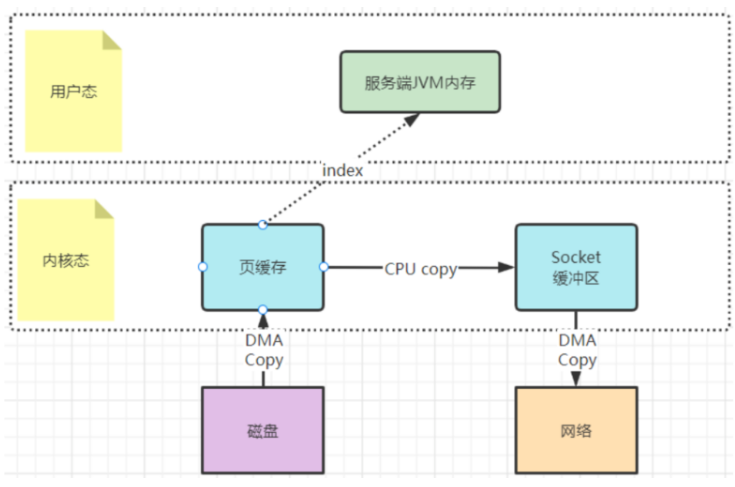
在后期的不断改进过程中,sendfile优化了实现机制,在拷贝过程中,并不直接拷贝文件的内容,而是只拷贝一个带有文件位置和长度等信息的文件描述符FD,这样就大大减少了需要传递的数据。而真实的数据内容,会交由DMA控制器,从页缓存中打包异步发送到socket中。

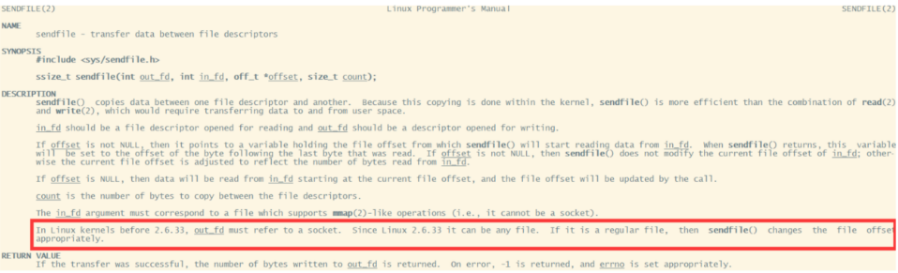
2.6.33版本以前的Linux内核中,out_fd只能是一个socket。但是现在版本已经没有了这个限制。
since linux 2.6.33 it can be any file. if it is a regular file, then sendfile() changes the file offset appropriately