逆向--进阶
进阶来喽~ crypto的期末周
--25届高考完的第一天
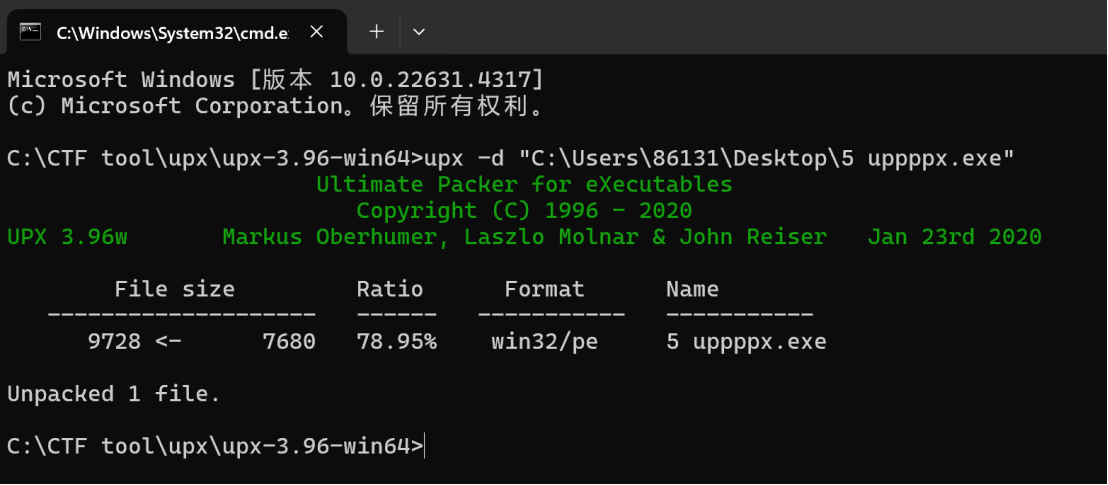
upx改特征值
题
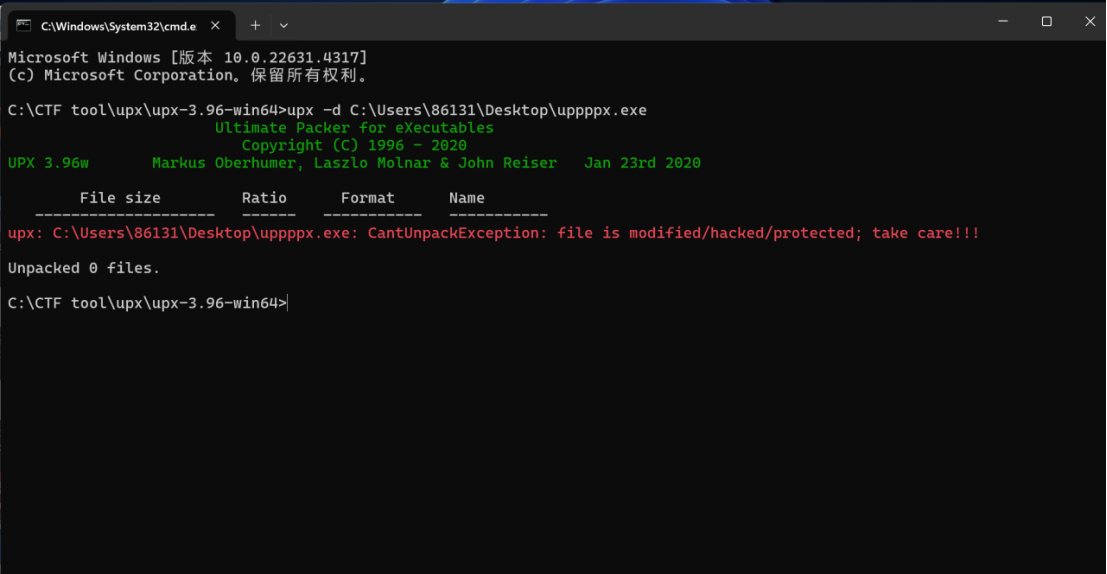
如果直接进行脱壳就会这样
(upx壳被改了区段名,无法直接进行脱壳)
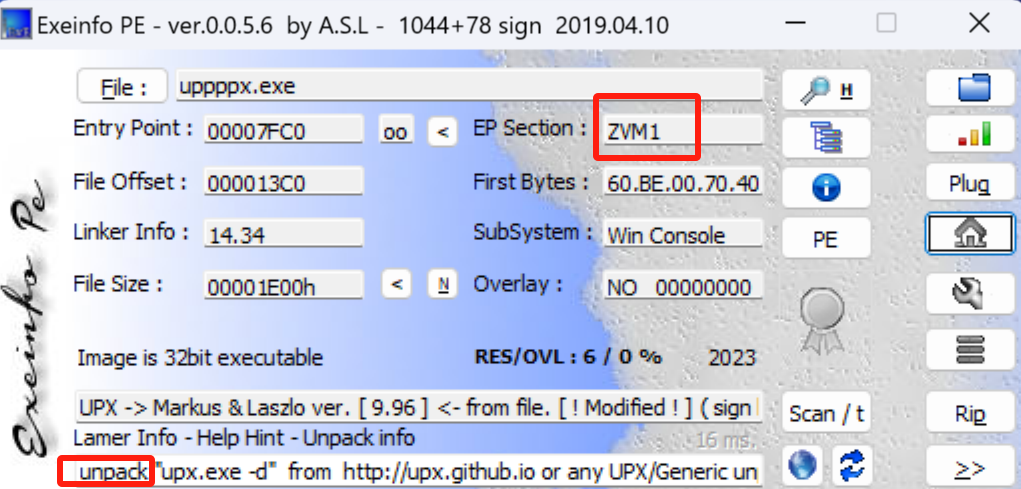
同时他也是有壳的
正常情况下这个地方应该是UPX
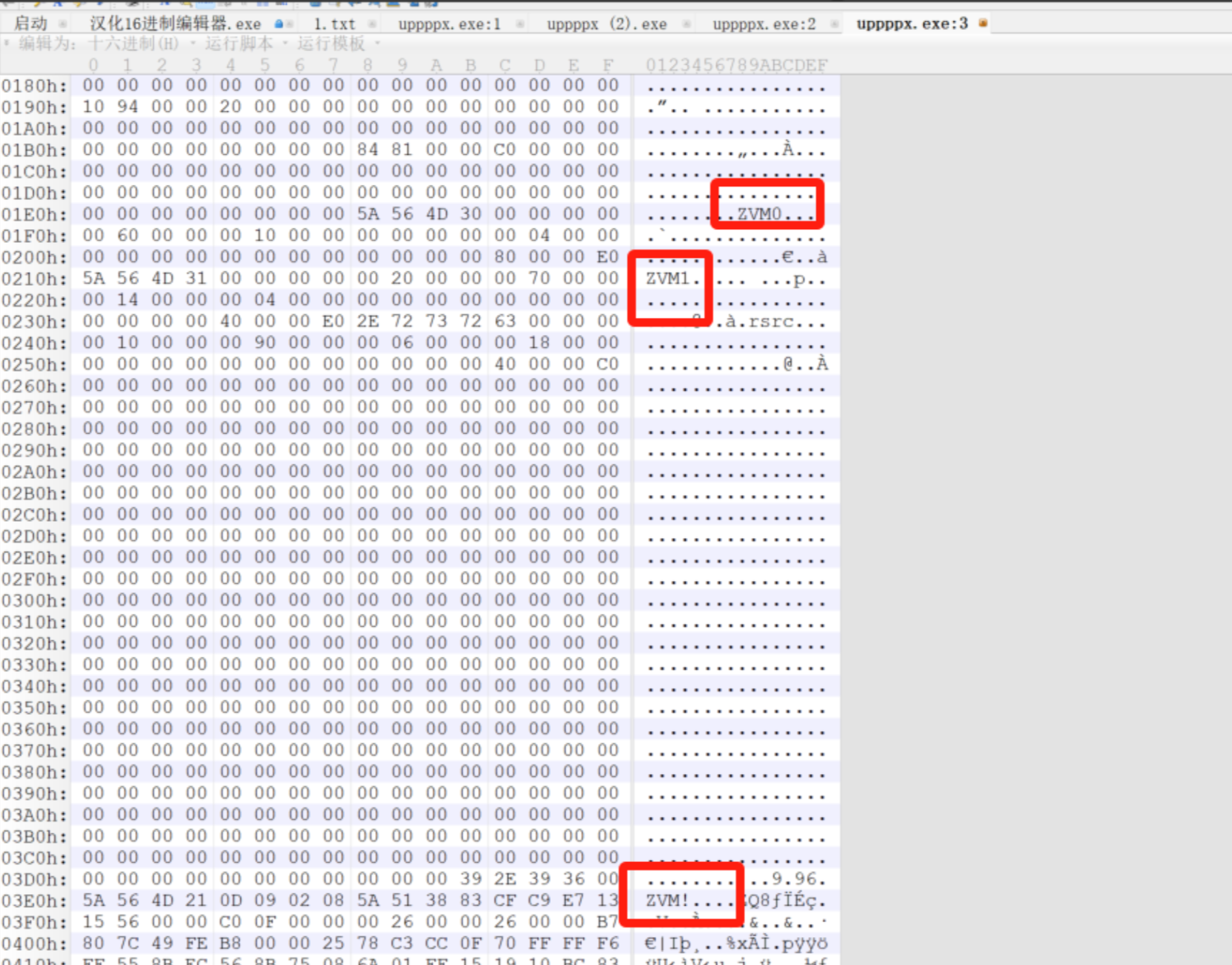
将其放入010中
找ZVM,将这三个对应部分改为555058
就改回了UPX,另存为
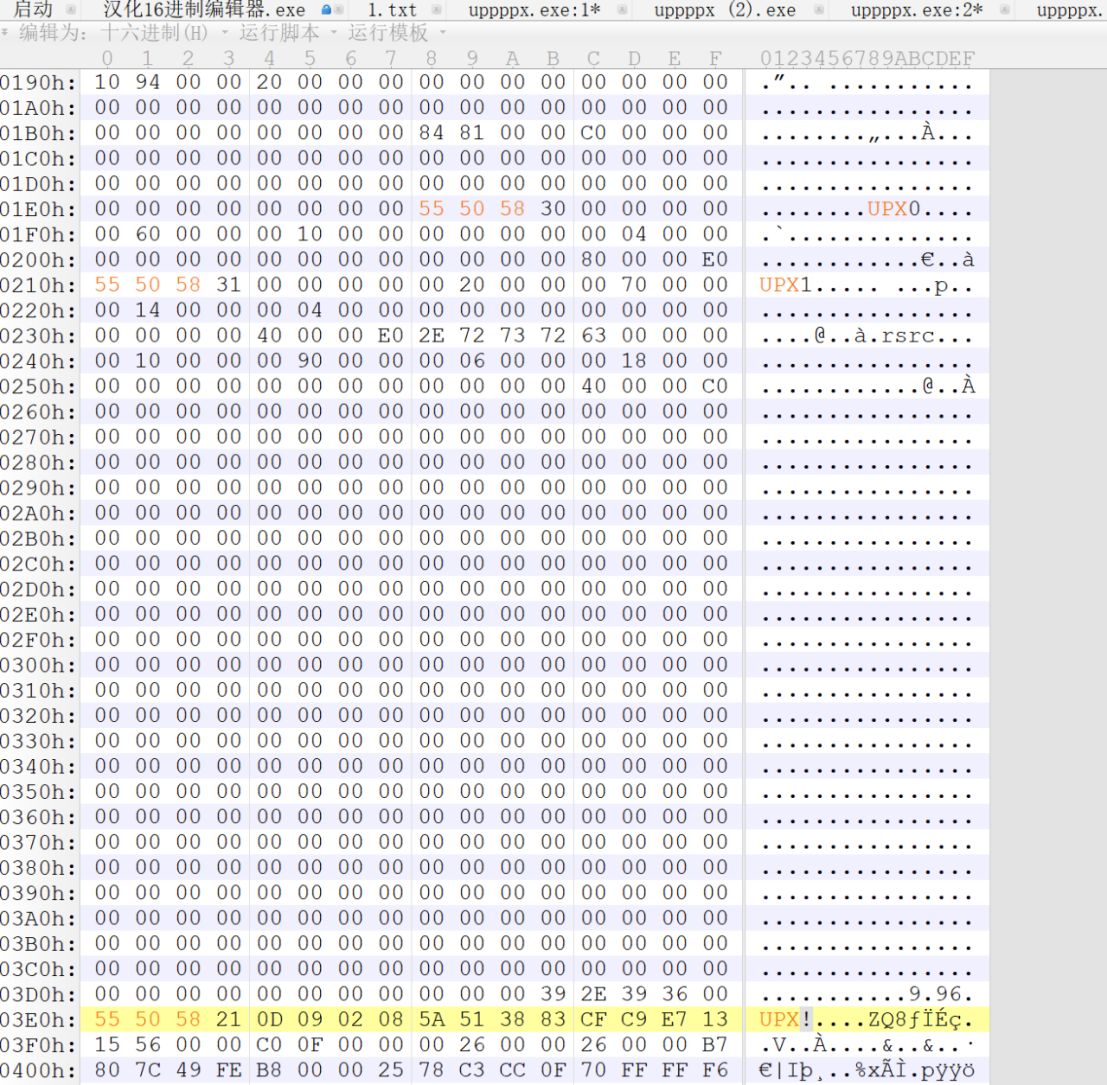
Ok,这就改完了
然后保存一下
跟正常脱壳一样的操作
最后脱壳
z3
应用
现在的CTF逆向中,求解方程式或者求解约束条件是非常常见的一种考察方式,而ctf比赛都是限时的,当我们已经逆向出来flag的约束条件时,可能还需要花一定的时间去求解逆过程。而Z3求解器就给我们提供了一个非常便利求解方式,我们只需要定义未知量(x,y等),然后为这些未知量添加约束方式即可求解。Z3求解器能够求解任意多项式,但是要注意的是,当方程的方式为2**x这种次方运算的时候,方程式已经不是多项式的范畴了,Z3便无法求解。
语法:
z3中有3种类型的变量,分别是整型(Int)/实型(Real)和向量(BitVec)
基本API:Ints (names, ctx=None),创建多个整数变量,names是空格分隔名字
BitVecs(name,bv,ctx=None),创建一个有多变量的位向量,name是名字,bv表示大小
基础例子:
from z3 import *x, y = Reals('x y')
solve(x-y == 3, 3*x-8*y == 4)#[y = 1, x = 4]常用函数:
s=solver():创建一个解的对象。
s.add(条件):为解增加一个限制条件
s.check():检查解是否存在,如果存在,会返回"sat"
modul():输出解得结果
安装z3库:
在pycharm中输入命令
pip install z3-solver
题
[HNCTF 2022 WEEK2] 来解个方程?
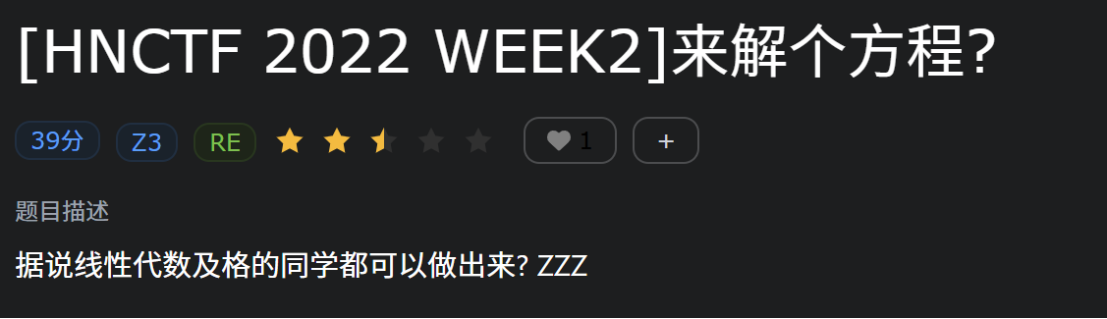
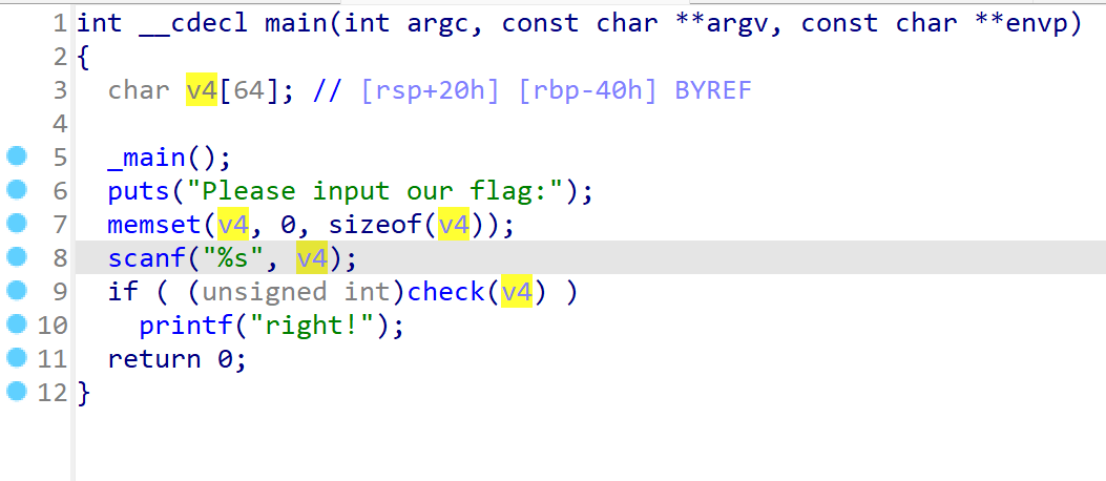
看check函数

from z3 import *
s = Solver()
v2,v3,v4,v5,v6,v7,v8,v9,v10,v11,v12,v13,v14,v15,v16,v17,v18,v19,v20,v21,v22,v23 = Ints("v2 v3 v4 v5 v6 v7 v8 v9 v10 v11 v12 v13 v14 v15 v16 v17 v18 v19 v20 v21 v22 v23")
s.add( 245 * v6 + 395 * v5 + 3541 * v4 + 2051 * v3 + 3201 * v2 + 1345 * v7 == 855009)
s.add(3270 * v6 + 3759 * v5 + 3900 * v4 + 3963 * v3 + 1546 * v2 + 3082 * v7 == 1515490)
s.add(526 * v6 + 2283 * v5 + 3349 * v4 + 2458 * v3 + 2012 * v2 + 268 * v7 == 854822)
s.add(3208 * v6 + 2021 * v5 + 3146 * v4 + 1571 * v3 + 2569 * v2 + 1395 * v7 == 1094422)
s.add(3136 * v6 + 3553 * v5 + 2997 * v4 + 1824 * v3 + 1575 * v2 + 1599 * v7 == 1136398)
s.add(2300 * v6 + 1349 * v5 + 86 * v4 + 3672 * v3 + 2908 * v2 + 1681 * v7 == 939991)
s.add(212 * v22 + 153 * v21 + 342 * v20 + 490 * v12 + 325 * v11 + 485 * v10 + 56 * v9 + 202 * v8 + 191 * v23 == 245940)
s.add(348 * v22 + 185 * v21 + 134 * v20 + 153 * v12 + 460 * v9 + 207 * v8 + 22 * v10 + 24 * v11 + 22 * v23 == 146392)
s.add(177 * v22 + 231 * v21 + 489 * v20 + 339 * v12 + 433 * v11 + 311 * v10 + 164 * v9 + 154 * v8 + 100 * v23 == 239438)
s.add(68 * v20 + 466 * v12 + 470 * v11 + 22 * v10 + 270 * v9 + 360 * v8 + 337 * v21 + 257 * v22 + 82 * v23 == 233887)
s.add(246 * v22 + 235 * v21 + 468 * v20 + 91 * v12 + 151 * v11 + 197 * v8 + 92 * v9 + 73 * v10 + 54 * v23 == 152663)
s.add( 241 * v22 + 377 * v21 + 131 * v20 + 243 * v12 + 233 * v11 + 55 * v10 + 376 * v9 + 242 * v8 + 343 * v23 == 228375)
s.add(356 * v22 + 200 * v21 + 136 * v11 + 301 * v10 + 284 * v9 + 364 * v8 + 458 * v12 + 5 * v20 + 61 * v23 == 211183)
s.add(154 * v22 + 55 * v21 + 406 * v20 + 107 * v12 + 80 * v10 + 66 * v8 + 71 * v9 + 17 * v11 + 71 * v23 == 96788)
s.add(335 * v22 + 201 * v21 + 197 * v11 + 280 * v10 + 409 * v9 + 56 * v8 + 494 * v12 + 63 * v20 + 99 * v23 == 204625)
s.add(428 * v18 + 1266 * v17 + 1326 * v16 + 1967 * v15 + 3001 * v14 + 81 * v13 + 2439 * v19 == 1109296)
s.add(2585 * v18 + 4027 * v17 + 141 * v16 + 2539 * v15 + 3073 * v14 + 164 * v13 + 1556 * v19 == 1368547)
s.add(2080 * v18 + 358 * v17 + 1317 * v16 + 1341 * v15 + 3681 * v14 + 2197 * v13 + 1205 * v19 == 1320274)
s.add(840 * v18 + 1494 * v17 + 2353 * v16 + 235 * v15 + 3843 * v14 + 1496 * v13 + 1302 * v19 == 1206735)
s.add( 101 * v18 + 2025 * v17 + 2842 * v16 + 1559 * v15 + 2143 * v14 + 3008 * v13 + 981 * v19 == 1306983)
s.add(1290 * v18 + 3822 * v17 + 1733 * v16 + 292 * v15 + 816 * v14 + 1017 * v13 + 3199 * v19 == 1160573)
s.add(186 * v18 + 2712 * v17 + 2136 * v16 + 98 * v13 + 138 * v14 + 3584 * v15 + 1173 * v19== 1005746)
if s.check() == sat:flag = []ans = s.model()flag.append(ans[v2])flag.append(ans[v3])flag.append(ans[v4])flag.append(ans[v5])flag.append(ans[v6])flag.append(ans[v7])flag.append(ans[v8])flag.append(ans[v9])flag.append(ans[v10])flag.append(ans[v11])flag.append(ans[v12])flag.append(ans[v13])flag.append(ans[v14])flag.append(ans[v15])flag.append(ans[v16])flag.append(ans[v17])flag.append(ans[v18])flag.append(ans[v19])flag.append(ans[v20])flag.append(ans[v21])flag.append(ans[v22])flag.append(ans[v23])for x in flag:print(x, end=",")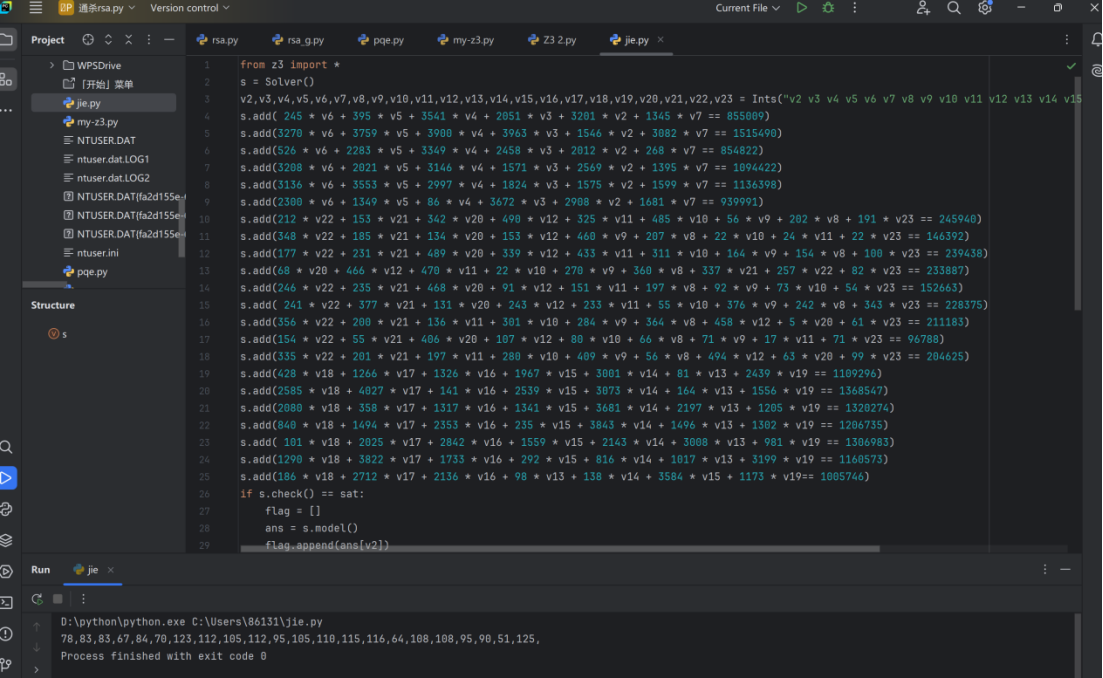
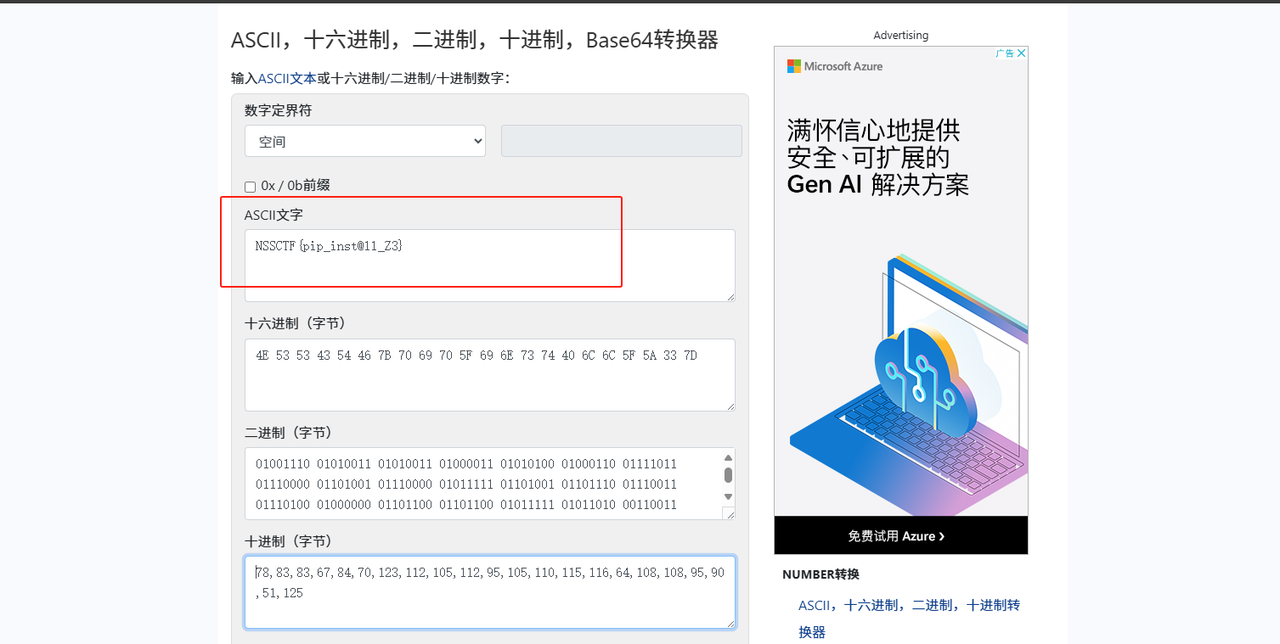
得到78,83,83,67,84,70,123,112,105,112,95,105,110,115,116,64,108,108,95,90,51,125
十进制转字符串
不想写代码的去找在线网站
https://www.rapidtables.org/zh-CN/convert/number/ascii-hex-bin-dec-converter.html
迷宫
题型:
模拟一个迷宫,要求选手找到从起点到终点的路径。
做题方法:
拖到ida看main函数(基本上),找到迷宫是几乘几的,然后找到迷宫。
写脚本或者手搓。
题:
下载完没有后缀,拖入010
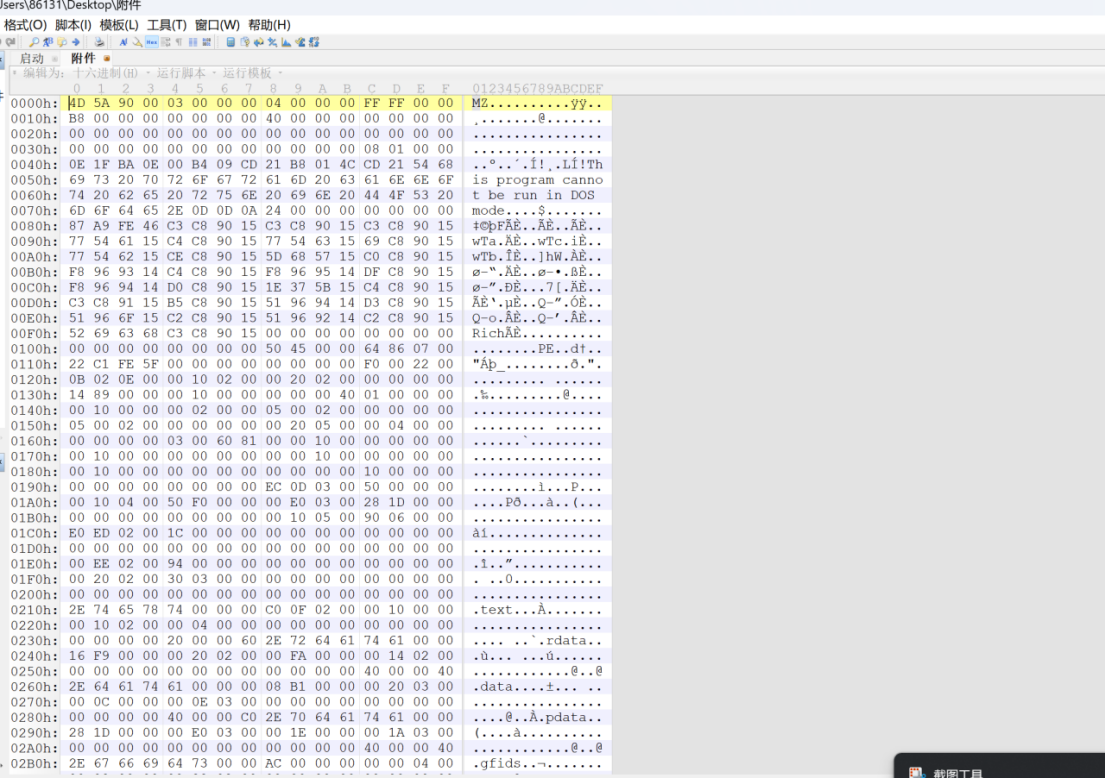
搜一下MZ开头是什么文件
MZ文件是DOS中的.exe可执行文件格式。
添加后缀
然后我们需要将exe转化为py
将其放到pyinstxtractor.py这个工具下面
cmd打开终端
输入命令 python pyinstxtractor.py 文件名

将这两个pyc文件拖入010中,将struct的前16位十六进制数复制到5.pyc开头
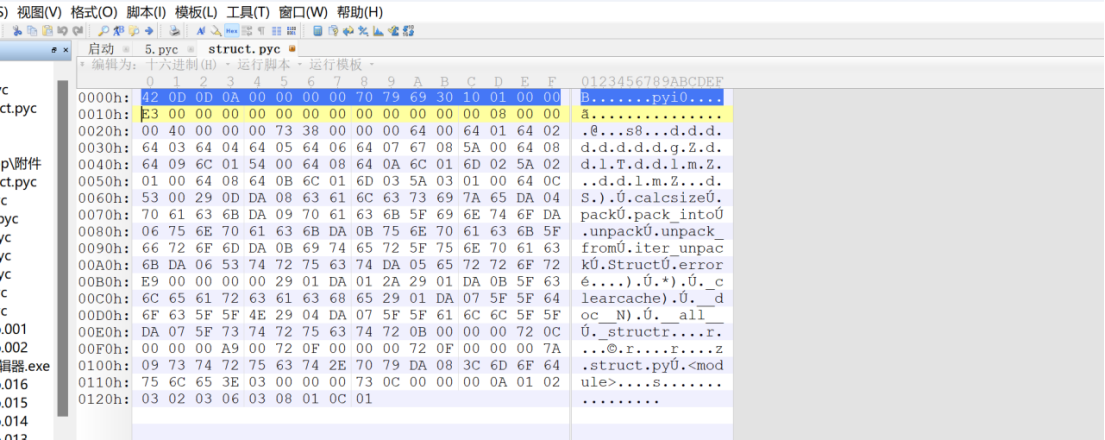
另存为
然后使用在线网站
套脚本
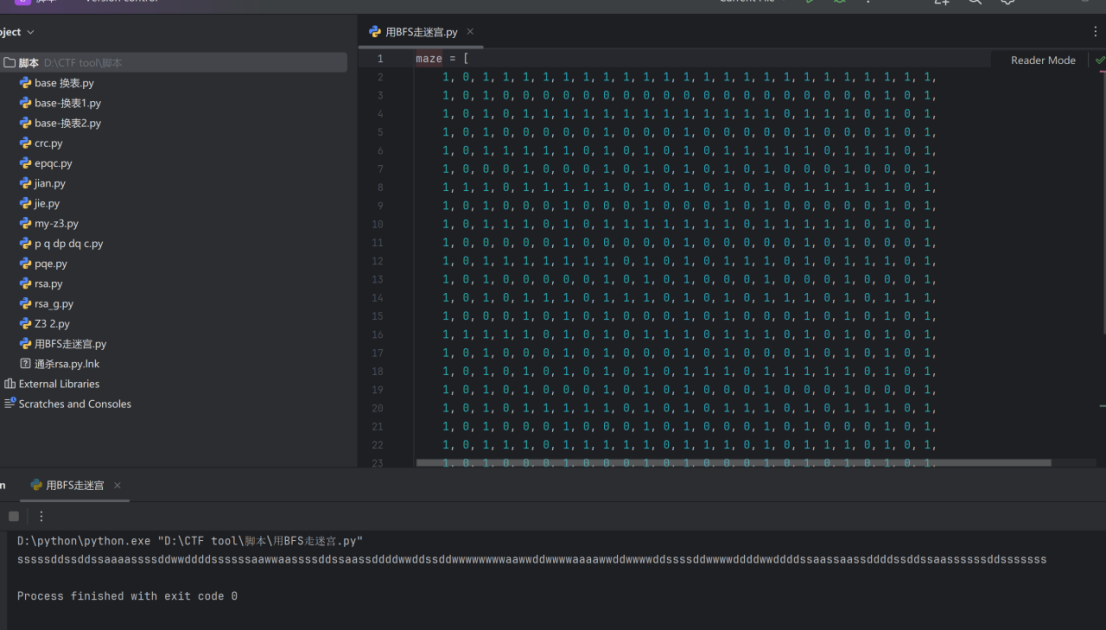
得到sssssddssddssaaaassssddwwddddssssssaawwaassssddssaassddddwwddssddwwwwwwwwaawwddwwwwaaaawwddwwwwddssssddwwwwddddwwddddssaassaassddddssddssaassssssddsssssss
Md5解密
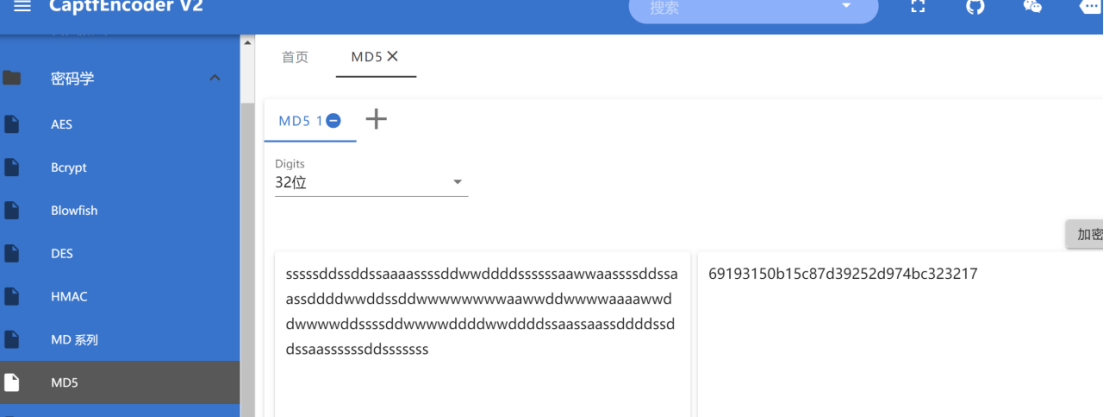
就得到了
69193150b15c87d39252d974bc323217
所以flag就是NSSCTF{69193150b15c87d39252d974bc323217}
pyc转py
定义:
pyc文件:是由Python文件经过编译后所生成的文件,它是一种字节码 byte code,因此我们直接查看就是乱码的,也对源码起到一定的保护作用,但是这种字节码byte code是可以反编译的
工具:使用uncomplye6
pip install uncomplye6
命令:
uncompyle6 文件名.pyc > 文件名.py
或
uncompyle6 -o 文件名.py 文件名.pyc
题
[HUBUCTF 2022 新生赛] ezPython
附件下载完
打开终端,输入命令
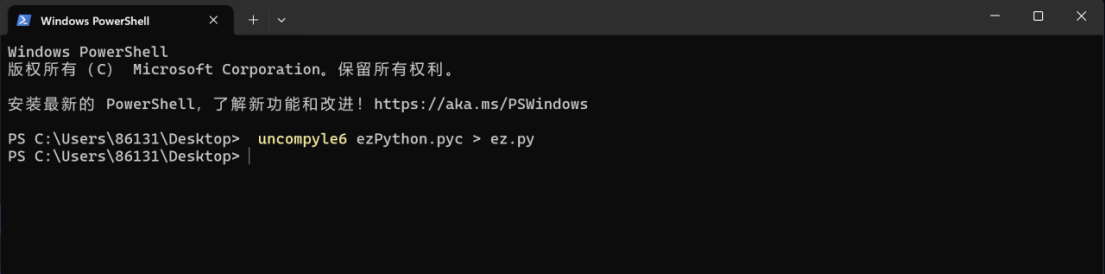
然后就得到了py文件
(当然你也可以使用在线网站,防止线下赛封外网还是学一下命令比较好)
exe转py
步骤:
先把exe转pyc,再把pyc转py
方法:
用pyinstxtractor.py工具
cmd打开终端
输入命令 python pyinstxtractor.py 文件名
注意要把需要转换的文件拖到这个工具下
题:
将其放到pyinstxtractor.py这个工具下面
cmd打开终端
输入命令 python pyinstxtractor.py 文件名
然后会生成一个 文件夹,在里面找struct和src文件
把struct.pyc和src.pyc拖到010
把struct.pyc的这些内容复制到src.pyc
至于为什么要这样做
因为
使用010工具把struct的头八字节替换到1.pyc的最上面,为什么要替换?
因为用PyInstaller打包后,字节表面的前8个字节会被抹掉,所以最后要自己添加回去。前四个字节为python编译的版本,后四个字节为时间戳。想要获得编译版本可以查看打包文件里struct的信息,我这里还是提取出struct这个文件,有struct作为对照就方便多了,不用特定下载对应版本的python来生成特定的pyc文件来取前8个字节。
然后另存为pyc文件
下面就是pyc转py了,自己去试试吧
伪随机数
概念:
伪随机数是通过算法生成的数字序列,与真正的随机数相比,它们具有确定性的特点。这意味着,给定相同的初始种子,伪随机数生成器(PRNG)每次都会产生相同的数字序列。尽管这些数字看起来是随机的,但它们实际上是由初始种子和算法共同决定的。
rand函数,即伪随机数生成器,该函数返回类型为整型,没有参数,即产生一个在(0-rand_max(十六进制的ox7ffff转化为整数即32767)的一个随机数),在调用时不会出现函数返回错误的情况;然后我们看一下最后的这一句话:再调用rand函数之前,我们需要使用srand函数为随机数生成器设定种子。
那么问题来了,为什么一定需要使用srand函数呢?如果没有srand 又会怎么样呢?
(伪随机数生成器是一个电脑固定的运算程序,并且前一个输出是下一个运算的输入,但计算机的数值储存是有限的,因此必然会再循环的某一时刻产生于前面相同的结果,从此开始重复前面的一个循环。)
题:
[SWPUCTF 2021 新生赛]fakerandom
附件下载完是一个python文件
先分析一下
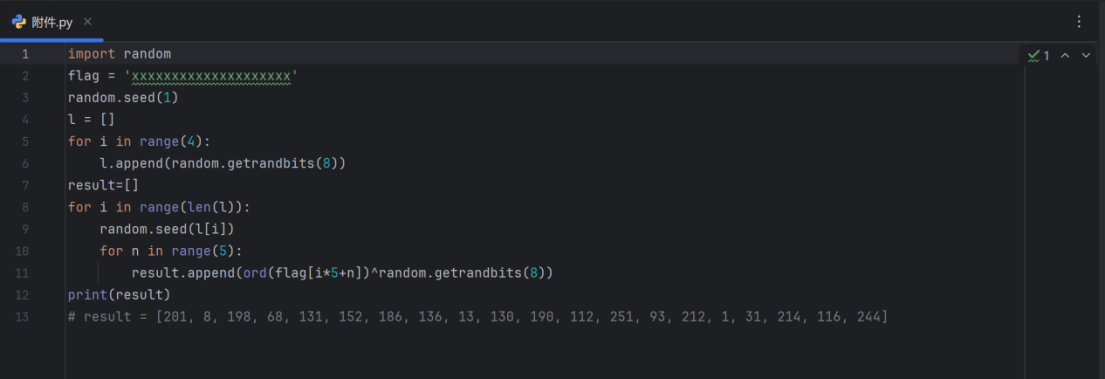
import random flag = 'xxxxxxxxxxxxxxxxxxxx' random.seed(1) //设置一个全局随机种子为1,确保每次运行代码时生成的随机数序列相同。
l = [] //创建一个空列表 for i in range(4): l.append(random.getrandbits(8)) //使用循环生成4个随机数,每个随机数是8位的(即0到255之间的整数),并添加到列表 l 中 result=[] for i in range(len(l)): random.seed(l[i]) for n in range(5):
//对于 l 中的每个随机数,设置随机种子,然后生成5个新的随机数。
result.append(ord(flag[i*5+n])^random.getrandbits(8))
//对 flag 字符串中对应的字符进行加密,使用XOR操作(^),其中 ord(flag[i*5+n]) 获取字符的ASCII值,random.getrandbits(8) 生成一个新的随机数。
print(result)
上代码
import random
flag = ''
random.seed(1)#产生种子1对应的序列。
l = []
for i in range(4):l.append(random.getrandbits(8))#random.getrandbits(8)输出一个0~2^8-1范围内的一个随机整数,8表示的是2进制的位数
result=[201, 8, 198, 68, 131, 152, 186, 136, 13, 130, 190, 112, 251, 93, 212, 1, 31, 214, 116, 244]
for i in range(len(l)):random.seed(l[i])for n in range(5):flag+= chr(result[i*5+n]^random.getrandbits(8))
print(flag)RC4
加密(解密)原理:
RC4由伪随机数生成器和异或运算组成。RC4的密钥长度可变,范围是[1,255]。RC4一个字节一个字节地加解密。给定一个密钥,伪随机数生成器接受密钥并产生一个S盒。S盒用来加密数据,而且在加密过程中S盒会变化。
由于异或运算的对合性,RC4加密解密使用同一套算法。
RC4算法中的几个关键变量:
1:S-Box 也就是所谓的S盒,是一个256长度的char型数组,每个单元都是一个字节,算法运行的任何时候,S都包括0-255的8比特数的排列组合,只不过值的位置发生了变换。
2:密钥K char key[256] 密钥的长度keylen与明文长度、密钥流的长度没有必然关系
3:临时向量k 长度也为256,每个单元也是一个字节。如果密钥的长度是256字节,就直接把密钥的值赋给k,否则,轮转地将密钥的每个字节赋给k
RC4代码介绍:
rc4初始化介绍:
1:初始化存储0-255字节的Sbox(其实就是一个数组)
2:填充key到256个字节数组中称为Tbox(你输入的key不满256个字节则初始化到256个字节)
3:交换s[i]与s[j] i 从0开始一直到255下标结束. j是 s[i]与T[i]组合得出的下标。
包含三个参数:
参数1是一个256长度的char型数组,定义为: unsigned char sBox[256];
参数2是密钥,其内容可以随便定义:char key[256];
参数3是密钥的长度,Len = strlen(key);
RC4的逆向小技巧
1:逆向特征
| 首先根据原理我们可以看到会初始化一个256字节的数组 其次会将一个key也填充到数组中 函数的话大概率都是两个参数,一个是key 一个是keylen |
2:魔改RC4
其实RC4魔改还是比较难的,稍有改变,整个算法就完全不同了。因此,大多数赛题将rc4与其他算法进行组合来加密flag
常见变化位置:
| 密钥经过上一步的其他加密后传入 s盒内部数据固定 rc4加密后数据进行重加密 |
注意: 我们在逆向rc4加密时候,所用的代码是一样的
因为 RC4 算法使用异或运算来加密和解密数据,所以加密和解密所使用的代码是一样的。这是因为异或运算具有可逆性,即对同一数据进行两次异或运算,结果会还原为原始数据。
因此,在 RC4 加密算法中,加密和解密过程使用相同的代码,只需要提供相同的密钥和待加密/解密的数据即可。通过将密文与相同的伪随机流进行异或运算,可以还原出原始的明文。
请注意,密钥在加密和解密过程中必须保持一致,否则无法正确解密数据。因此,在进行 RC4 加密和解密时,请确保使用相同的密钥。
题:
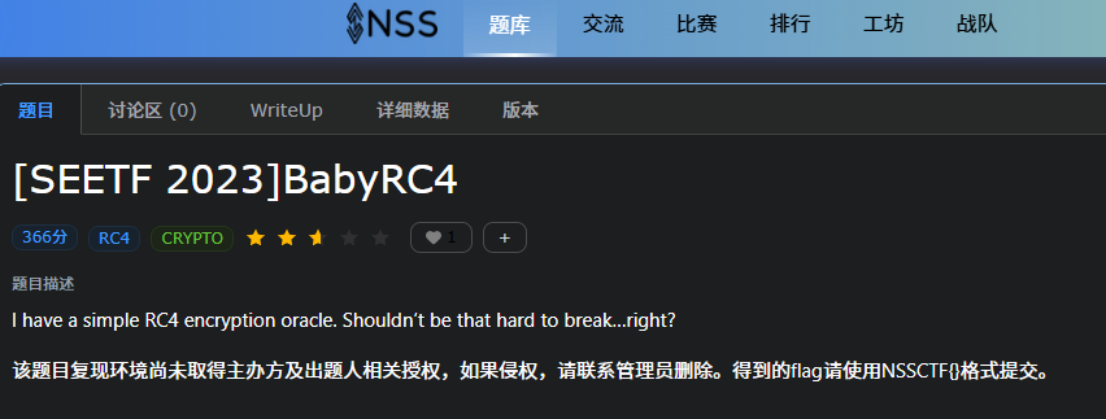
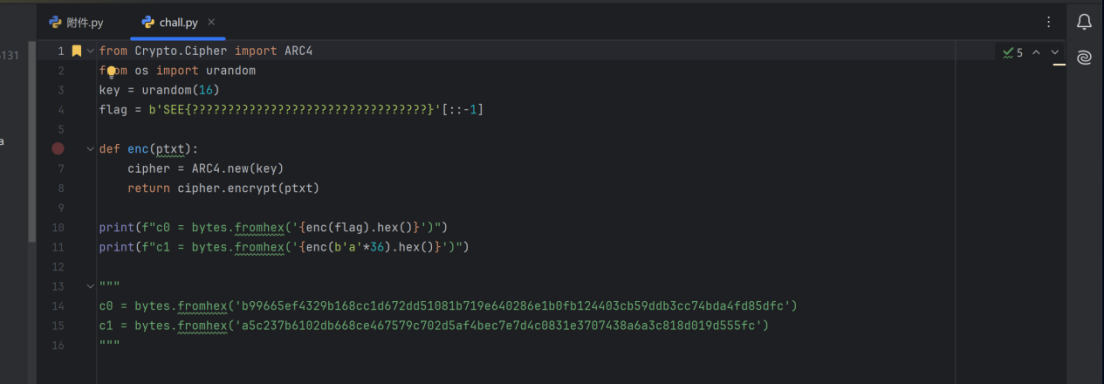
分析一下
from Crypto.Cipher import ARC4
from os import urandom
key = urandom(16)
flag = b'SEE{?????????????????????????????????}'[::-1]
#使用[::-1]将其反转
def enc(ptxt):cipher = ARC4.new(key)return cipher.encrypt(ptxt)
print(f"c0 = bytes.fromhex('{enc(flag).hex()}')")
#这行代码首先对flag进行加密,然后将加密后的数据转换为十六进制字符串,并打印出一个bytes.fromhex的调用,这个调用将十六进制字符串转换回字节字符串。c0是加密后的flag。
print(f"c1 = bytes.fromhex('{enc(b'a'*36).hex()}')")
#这行代码对一个由36个字符'a'组成的字节字符串进行加密,然后将加密后的数据转换为十六进制字符串,并打印出一个bytes.fromhex的调用,这个调用将十六进制字符串转换回字节字符串。c1是加密后的36个'a'字符。"""
c0 = bytes.fromhex('b99665ef4329b168cc1d672dd51081b719e640286e1b0fb124403cb59ddb3cc74bda4fd85dfc')
c1 = bytes.fromhex('a5c237b6102db668ce467579c702d5af4bec7e7d4c0831e3707438a6a3c818d019d555fc')
"""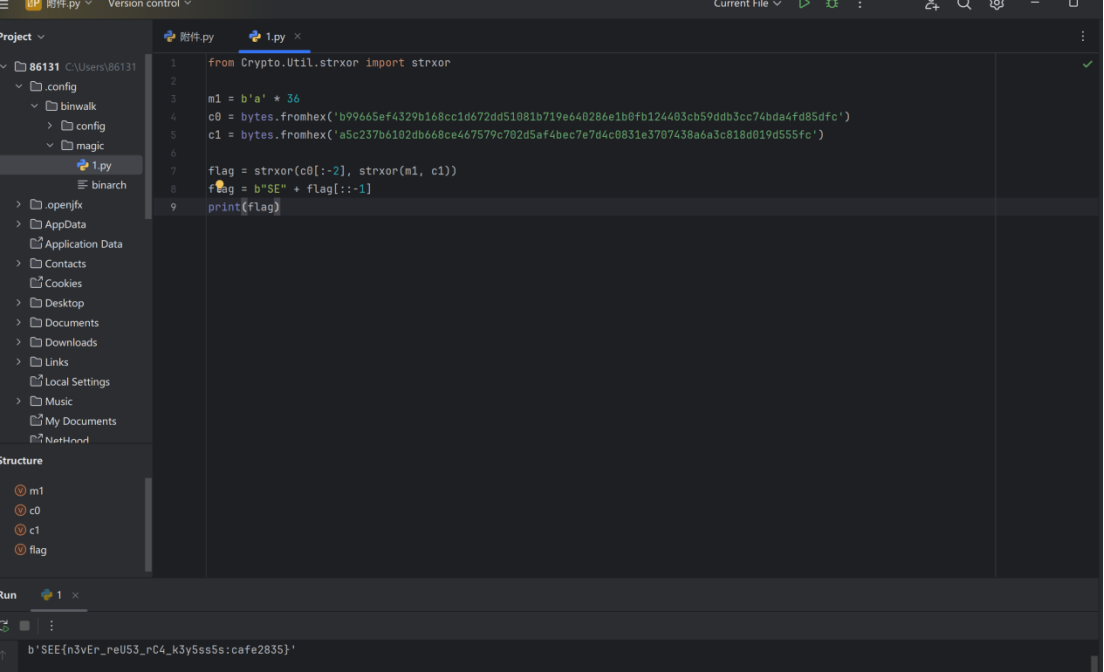
from Crypto.Util.strxor import strxorm1 = b'a' * 36
c0 = bytes.fromhex('b9965ef4329b168cc1d672d51081b719e648286e16bf8124603cb59ddb3cc74bda4f485dfc')
c1 = bytes.fromhex('a5c237b6102db668c67579c702d5af4becf7e7d4c083fe3707438aabc818d019d555fc')flag = strxor(c0[-2:], strxor(m1, c1))
f_flag = b'SE' + flag[::1]
print(flag)动态调试
调试命令:
| ida快捷键 | 功能 |
| F7 | 单步步进 |
| F8 | 单步步过 |
| F9 | 继续运行程序 |
| F4 | 运行到光标所在行 |
| Ctrl + F7 | 直到该函数返回时才停止 |
| Ctrl + F2 | 终止一个正在运行的进程 |
| F2 | 设置断点 |
优势:
-
直观性
-
动态调试可以直观地观察程序的执行过程。通过查看寄存器和内存的变化,可以清晰地了解程序的每一步操作。例如,当程序执行一个复杂的算法时,动态调试可以让我们看到算法每一步的中间结果,这比单纯阅读代码更容易理解程序的逻辑。
-
灵活性
-
调试器允许我们对程序进行各种操作,如修改寄存器值、修改内存内容等。这种灵活性使得我们可以在调试过程中进行各种假设测试。例如,我们可以修改程序的输入数据或者修改程序的执行路径,观察程序在不同情况下的行为,从而更好地发现程序的隐藏逻辑和漏洞。
-
对复杂程序的有效性
-
对于一些经过混淆或者加密的复杂程序,动态调试是一种非常有效的分析手段。即使程序的代码很难阅读,我们也可以通过跟踪程序的执行过程来理解其真正的作用。例如,一个使用了花指令(用于混淆代码的指令)的程序,静态分析可能很难理解其逻辑,但动态调试可以忽略这些花指令的影响,直接观察程序的正常执行流程。
题:
main函数
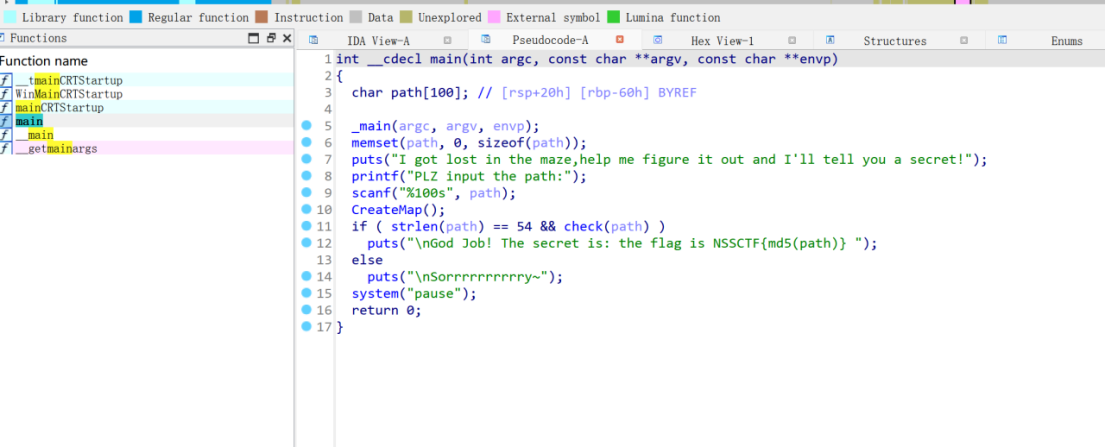
最后要md5
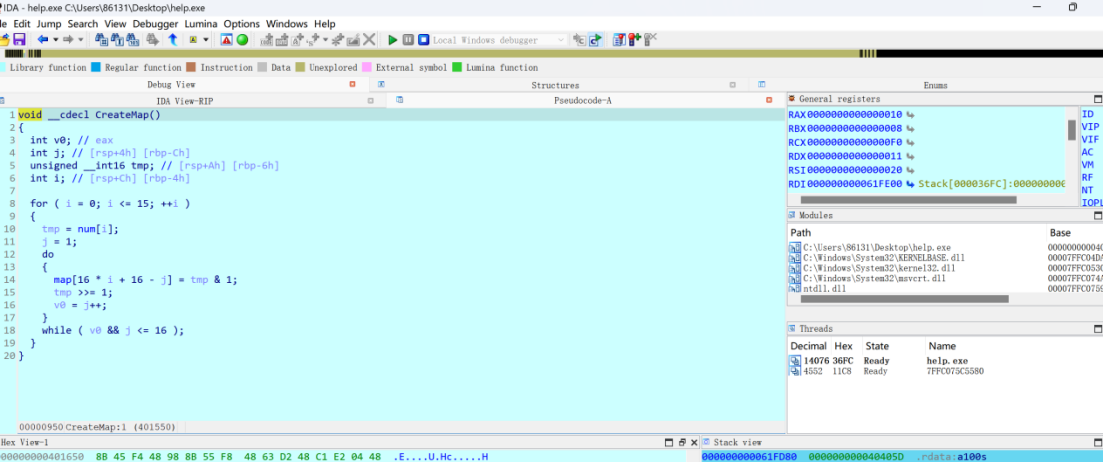
CreateMap创造地图,点开看看
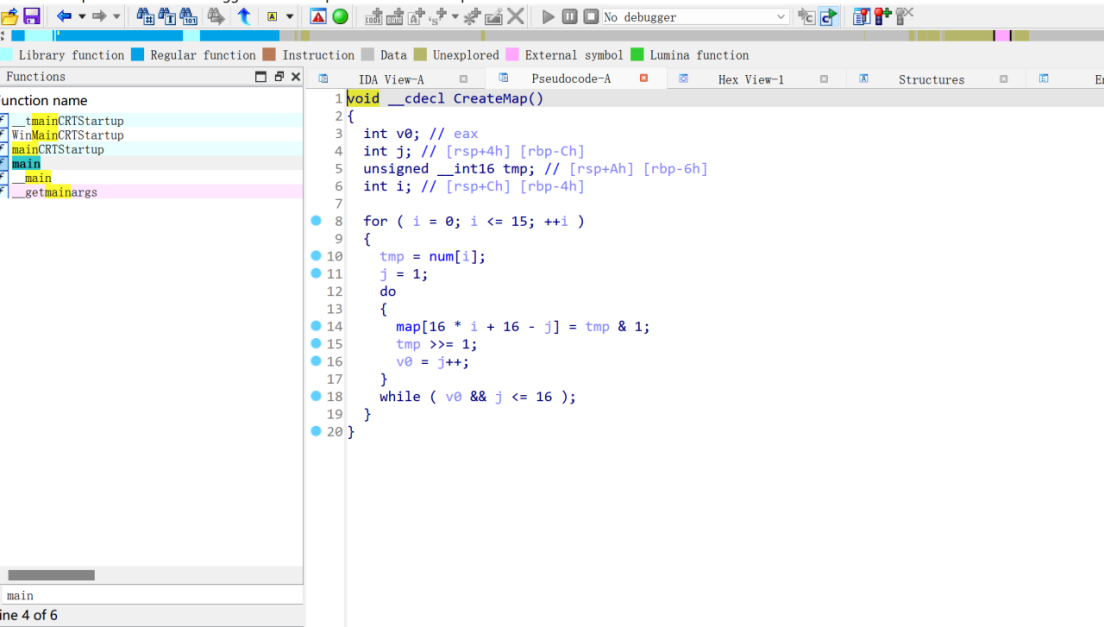
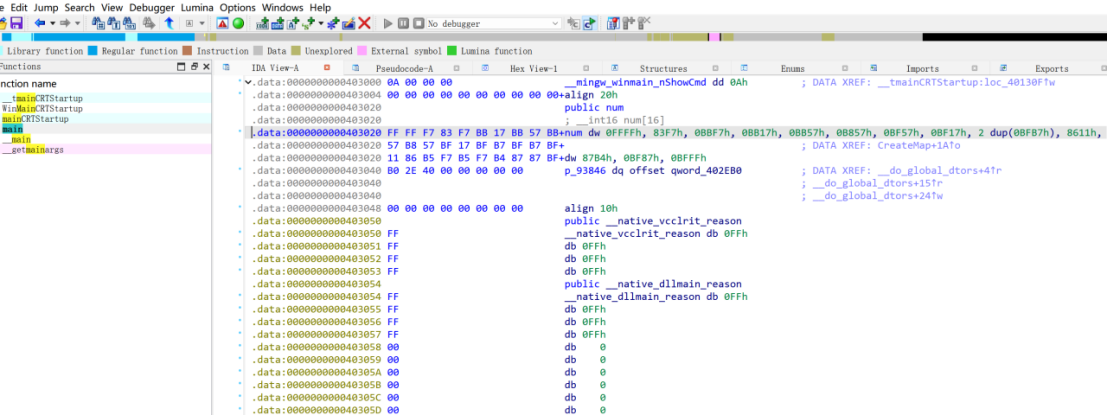
地图是16*16
动态调试
先设一个断点

F5
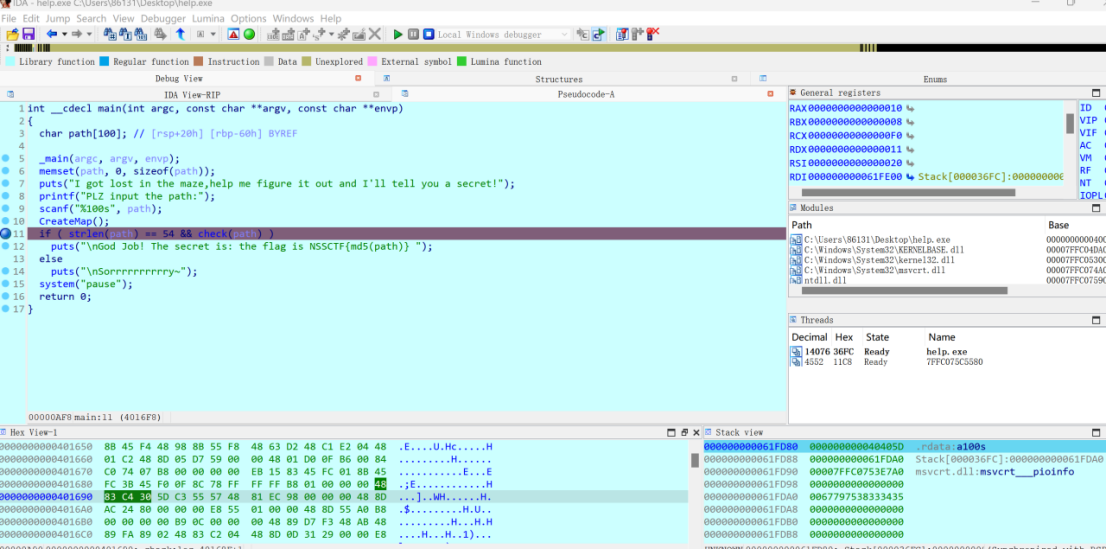
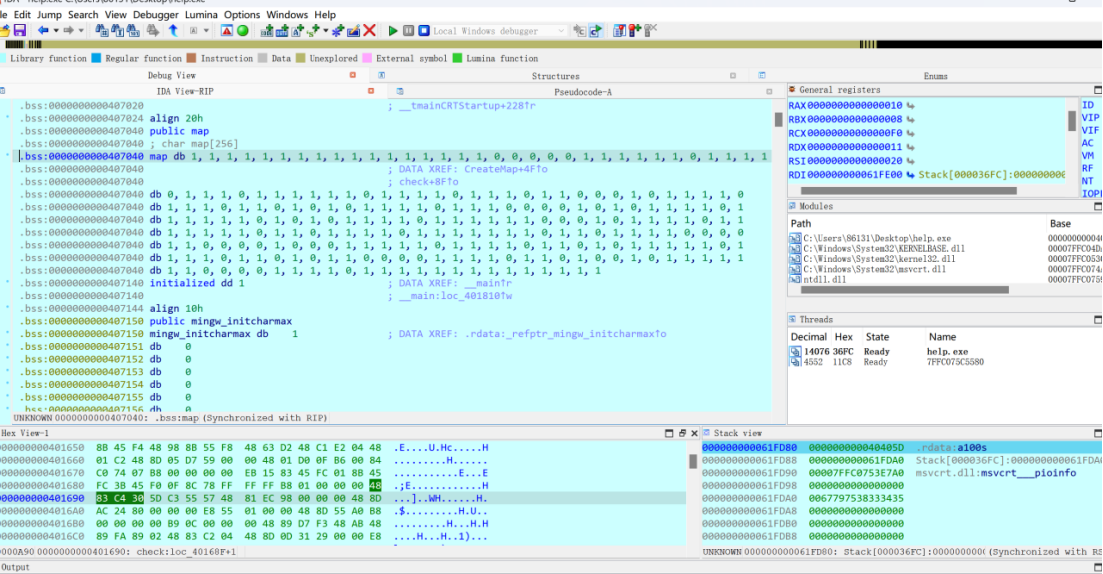
Shift+e把迷宫导出来
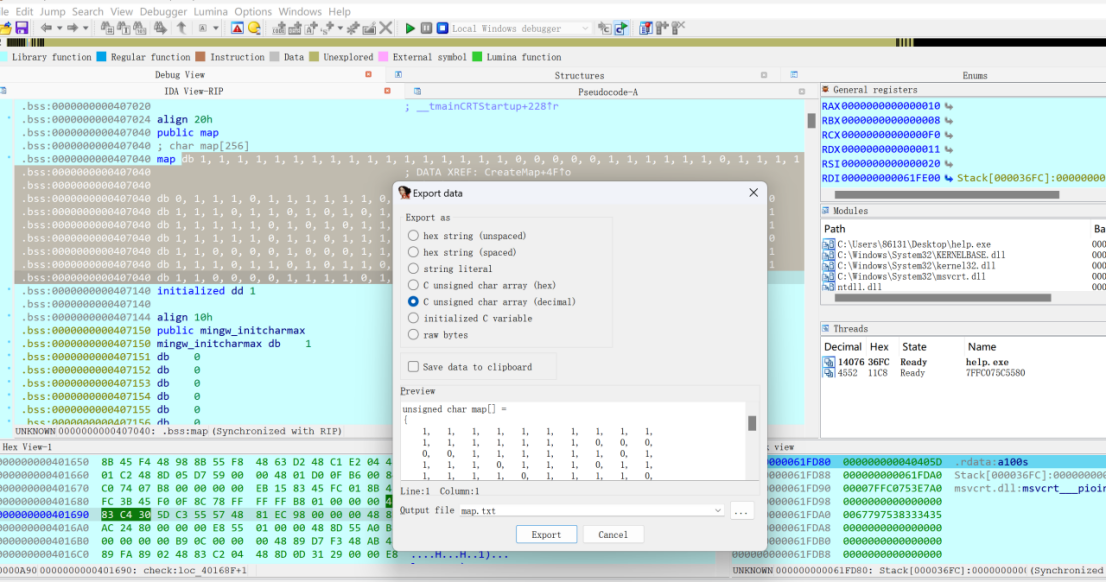
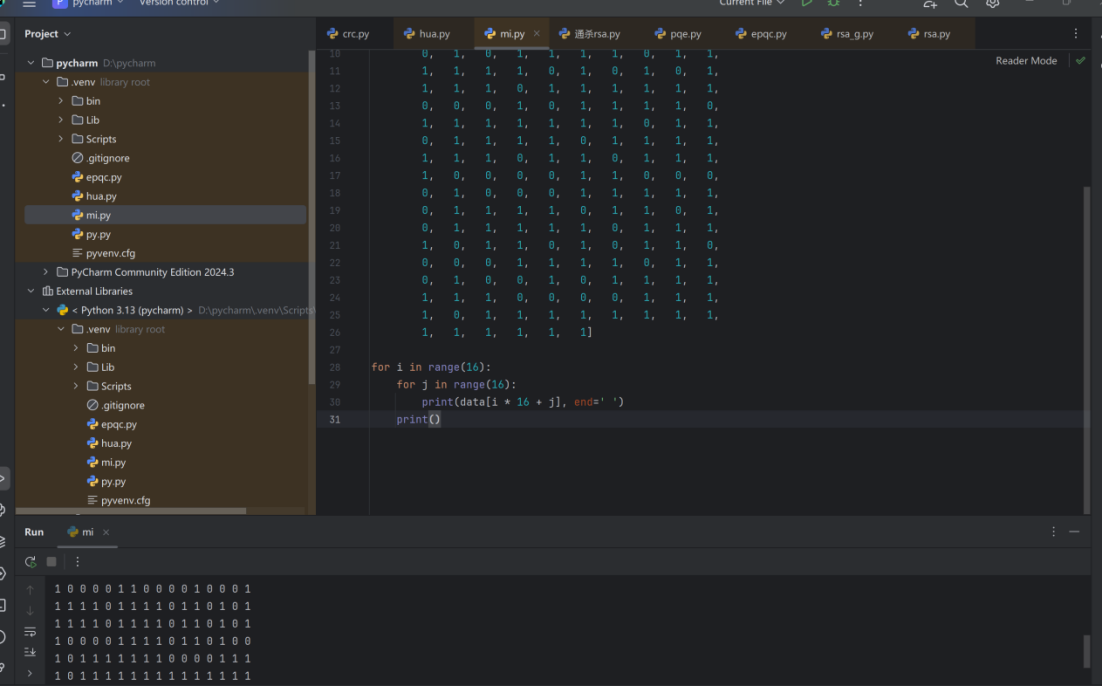
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 0 0 0 0 0 1 1 1 1 1 1 0 1 1 1
1 0 1 1 1 0 1 1 1 1 1 1 0 1 1 1
1 0 1 1 1 0 1 1 0 0 0 1 0 1 1 1
1 0 1 1 1 0 1 1 0 1 0 1 0 1 1 1
1 0 1 1 1 0 0 0 0 1 0 1 0 1 1 1
1 0 1 1 1 1 1 1 0 1 0 1 0 1 1 1
1 0 1 1 1 1 1 1 0 0 0 1 0 1 1 1
1 0 1 1 1 1 1 1 1 0 1 1 0 1 1 1
1 0 1 1 1 1 1 1 1 0 1 1 0 1 1 1
1 0 0 0 0 1 1 0 0 0 0 1 0 0 0 1
1 1 1 1 0 1 1 1 1 0 1 1 0 1 0 1
1 1 1 1 0 1 1 1 1 0 1 1 0 1 0 1
1 0 0 0 0 1 1 1 1 0 1 1 0 1 0 0
1 0 1 1 1 1 1 1 1 0 0 0 0 1 1 1
1 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1
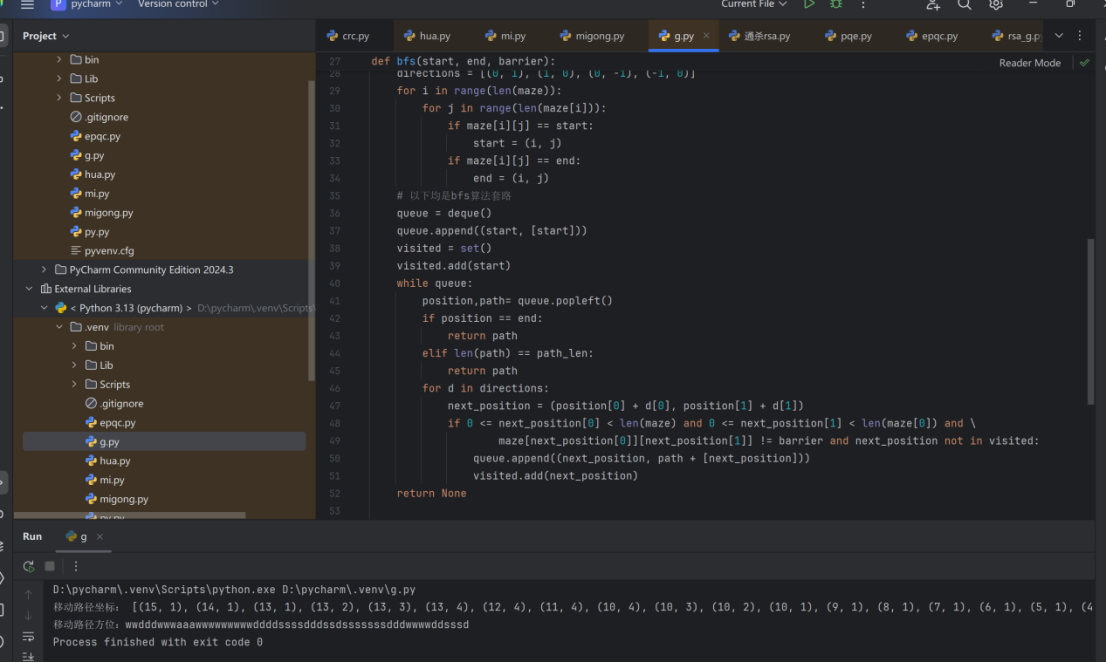
wwdddwwwaaawwwwwwwwwddddssssdddssdsssssssdddwwwwddsssd
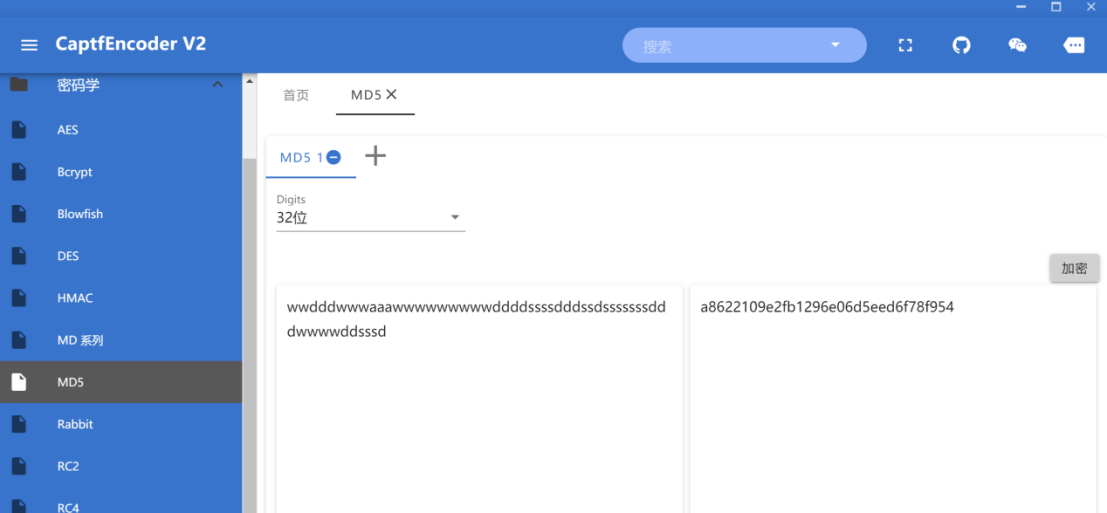
a8622109e2fb1296e06d5eed6f78f954
所以flag就是NSSCTF{a8622109e2fb1296e06d5eed6f78f954}
花指令的识别与消除
概念:
花指令又名垃圾代码、脏字节,英文名是junk code。花指令就是在不影响程序运行的情况下,往真实代码中插入一些垃圾代码,从而影响反汇编器的正常运行;或是起到干扰逆向分析人员的静态分析,增加分析难度和分析时间。
简单的花指令 0xe8是跳转指令,可以对线性扫描算法进行干扰,但是递归扫描算法可以正常分析。
花指令:目的是干扰ida和od等软件对程序的静态分析。使这些软件无法正常反汇编出原始代码。
常用的两类反汇编算法:
1.线性扫描算法:逐行反汇编(无法将数据和内容进行区分)
2.递归行进算法:按照代码可能的执行顺序进行反汇编程序。
简单的花指令 0xe8是跳转指令,可以对线性扫描算法进行干扰,但是递归扫描算法可以正常分析。
花指令分类:
a: (不会被执行)花指令是操作码,花指令后面原本的机器码会被误认为操作数,从而导致反汇编解析错误。
b: (不会被执行)花指令是平衡堆栈的代码,ida解析时,会由于该指令是堆栈操作而认为堆栈不平衡,使得F5失效。
c: (会被执行)花指令是正常的汇编指令,可以改变堆栈操作,但不会改变原来程序的堆栈寄存器,但是能起到干扰静态分析的作用。
d: (会被执行)利用call增加复杂度。call执行是会向堆栈中压入返回地址,可以修改返回地址配合ret跳转到任意地方。参考2018网鼎杯_give_a_try
花指令实现:
1.简单jmp
这是最简单的花指令。OD还是能被骗过去。但是因为ida采用的是递归扫描的办法所以能够正常识别
__asm{jmp label1db junkcode
label1:
}2.多层跳转
本质上和简单跳转是一样的,只是加了几层跳转。显然无法干扰ida
start://花指令开始jmp label1DB junkcode
label1:jmp label2DB junkcode
label2:jmp label3DB junkcode
label3 3.jnx和jx条件跳转
利用jz和jnz的互补条件跳转指令来代替jmp。竟然没有骗过OD(是因为吾爱的这个有插件吗)。但是ida竟然没有正常识别
_asm{jz label1jnz label1db junkcode
label1:
}
4.永真条件跳转
通过设置永真或者永假的,导致程序一定会执行,由于ida反汇编会优先反汇编接下去的部分(false分支)。也可以调用某些函数会返回确定值,来达到构造永真或永假条件。ida和OD都被骗过去了
__asm{push ebxxor ebx,ebxtest ebx,ebxjnz label1jz label2
label1:_emit junkcode
label2:pop ebx//需要恢复ebx寄存器
}__asm{clcjnz label1:_emit junkcode
label1:
}
5.call&ret构造花指令
这里利用call和ret,在函数中修改返回地址,达到跳过thunkcode到正常流程的目的。可以干扰ida的正常识别
__asm{call label1_emit junkcode
label1:add dword ptr ss:[esp],8//具体增加多少根据调试来ret_emit junkcode
}call指令:将下一条指令地址压入栈,再跳转执行
ret指令:将保存的地址取出,跳转执行
去除花指令:
第一种办法:
Edit--Patch program--change bytr...
把E9改为90
第二种办法:
d--ctrl+n--c
题:
无壳,拖进ida
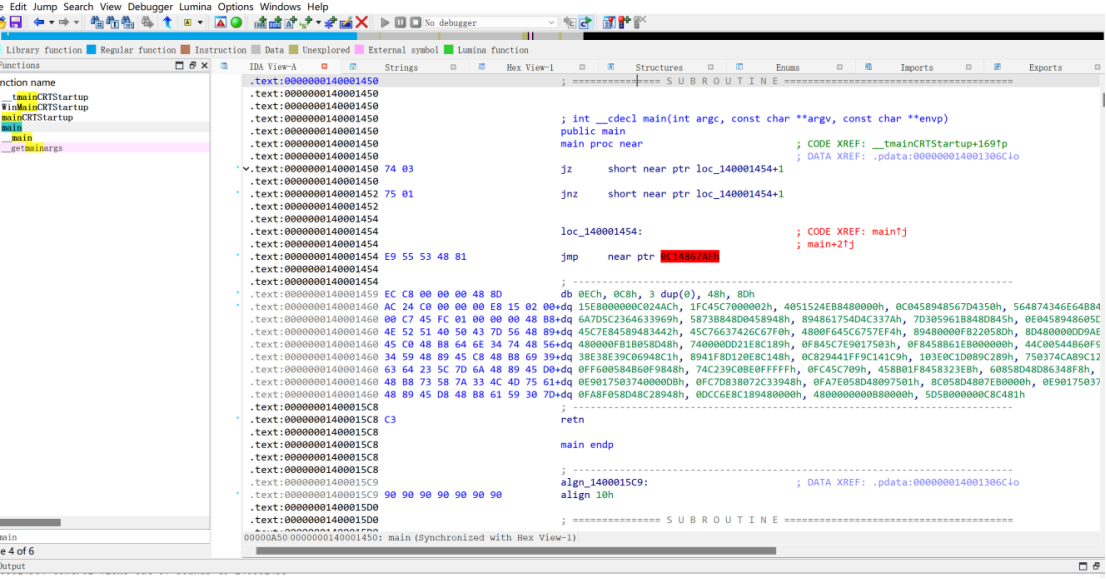
花指令
手动消除花指令
1.
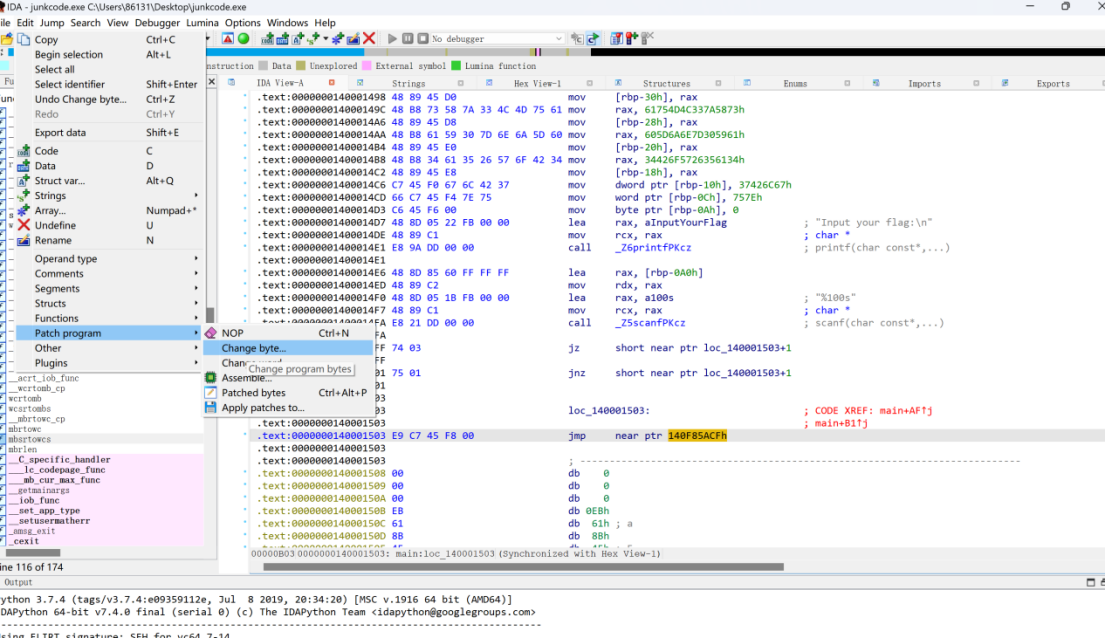
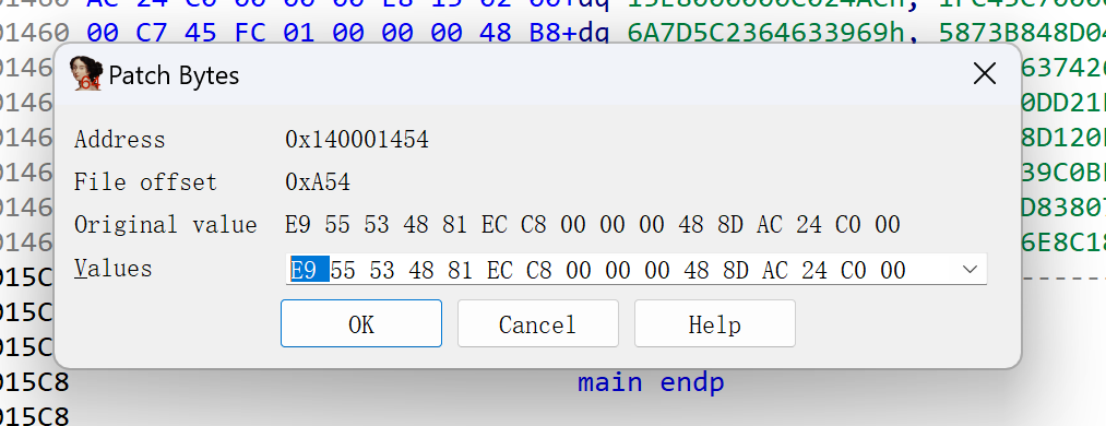
把E9改为90(要把所有都改完)
2.
或者可以
d ctrl+n c也可以去除花指令
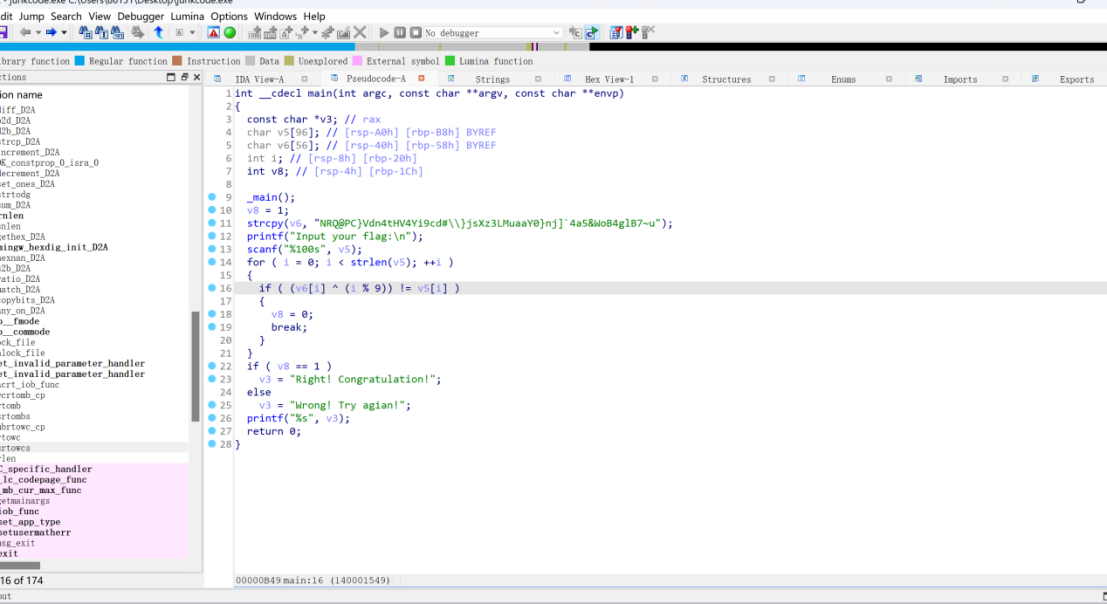
_main();v8 = 1;strcpy(v6, "NRQ@PC}Vdn4tHV4Yi9cd#\\}jsXz3LMuaaY0}nj]`4a5&WoB4glB7~u");printf("Input your flag:\n");scanf("%100s", v5);for ( i = 0; i < strlen(v5); ++i ){if ( (v6[i] ^ (i % 9)) != v5[i] ){v8 = 0;break;}}if ( v8 == 1 )v3 = "Right! Congratulation!";elsev3 = "Wrong! Try agian!";printf("%s", v3);return 0;
}写解密脚本
这又是一道异或
#include <stdio.h>
int main()
{char flag[] = "NRQ@PC}Vdn4tHV4Yi9cd#\\)jsXz3LMuaaY0)nj]'4a5&NoB4g1B7-u";int i = 0;int len = strlen(flag);for (i = 0; i < strlen(flag); ++i){flag[i] = flag[i] ^ (i % 9);}for (i = 0; i < strlen(flag); i++)printf("%c", flag[i]);return 0;
}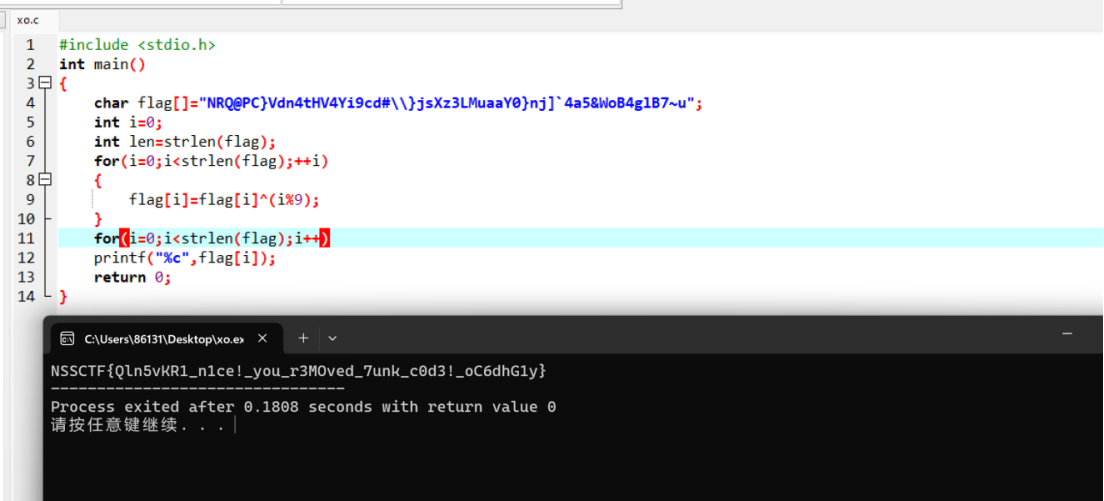
所以flag就是 NSSCTF{Qln5vKR1_n1ce!_you_r3MOved_7unk_c0d3!_oC6dhG1y}
TEA
TEA加密简介:
TEA是Tiny Encryption Algorithm的缩写,以加密解密速度快,实现简单著称。TEA算法每一次可以操作64bit(8byte),采用128bit(16byte)作为key,算法采用迭代的形式,推荐的迭代轮数是64轮,最少32轮。(可以改变)TEA系列算法中均使用了一个DELTA常数,但DELTA的值对算法并无什么影响,只是为了避免不良的取值,推荐DELTA的值取为黄金分割数(5√-2)/2与232的乘积,取整后的十六进制值为0x9e3779b9(也可以改变),用于保证每一轮加密都不相同。为解决TEA算法密钥表攻击的问题,TEA算法先后经历了几次改进,从XTEA到BLOCK TEA,直至最新的XXTEA。
XTEA:使用与TEA相同的简单运算,但四个子密钥采取不正规的方式来进行混合以阻止密钥表攻击。
Block TEA算法可以对32位的任意整数倍长度的变量块进行加解密的操作,该算法将XTEA轮循函数依次应用于块中的每个字,并且将它附加于被应用字的邻字。
XXTEA使用跟Block TEA相似的结构,但在处理块中每个字时利用了相邻字,且用拥有两个输入量的MX函数代替了XTEA轮循函数。上面提到的相邻字其实就是数组中相邻的项。
只要会处理TEA,XTEA和XXTEA也是同理。
TEA特征识别
1. delta的值:通常delta的值是0x9e3779b9
2. TEA每轮的加密特征,左移4、异或、右移5,以及一个变量sum会迭代+=delta32次
sum += delta;
v0 += (((v1<<4) + k0) ^ (v1 + sum) ^ (((v1>>5) + k1));
v1 += (((v0<<4) + k2) ^ (v0 + sum) ^ (((v0>>5) + k3));XTEA每轮的加密特征,左移4,右移5,与TEA不同的是对key和sum的处理,key[(sum >> 11) & 3],key[sum & 3]
v0 += (((v1 << 4) ^ (v1 >> 5)) + v1) ^ (sum + key[(sum & 3)]);
sum += delta;
v1 += (((v0 << 4) ^ (v0 >> 5)) + v0) ^ (sum + key[(sum>>11) & 3]);XXTEA每轮的加密特征
sum += delta;
e = (sum >> 2) & 3;
((z>>5^y<<2) + (y>>3^z<<4)) ^ ((sum^y) + (key[(p&3)^e] ^ z))TEA加密需要先找到四个模块:
1-key值,2-tea模块,3-加密后的数据(包括delta),4-wheel,
然后就可以进行逆向工程了
脚本先添加key数组,unsigned int result数组,添加变量i,wheel(轮数),sum(和),dalte。然后开始写逆算法
题:

从另一个文件中得到运行结果:0x17, 0x65, 0x54, 0x89, 0xed, 0x65, 0x46, 0x32, 0x3d, 0x58, 0xa9, 0xfd, 0xe2, 0x5e, 0x61, 0x97, 0xe4, 0x60, 0xf1, 0x91, 0x73, 0xe9, 0xe9, 0xa2, 0x59, 0xcb, 0x9a, 0x99, 0xec, 0xb1, 0xe1, 0x7d
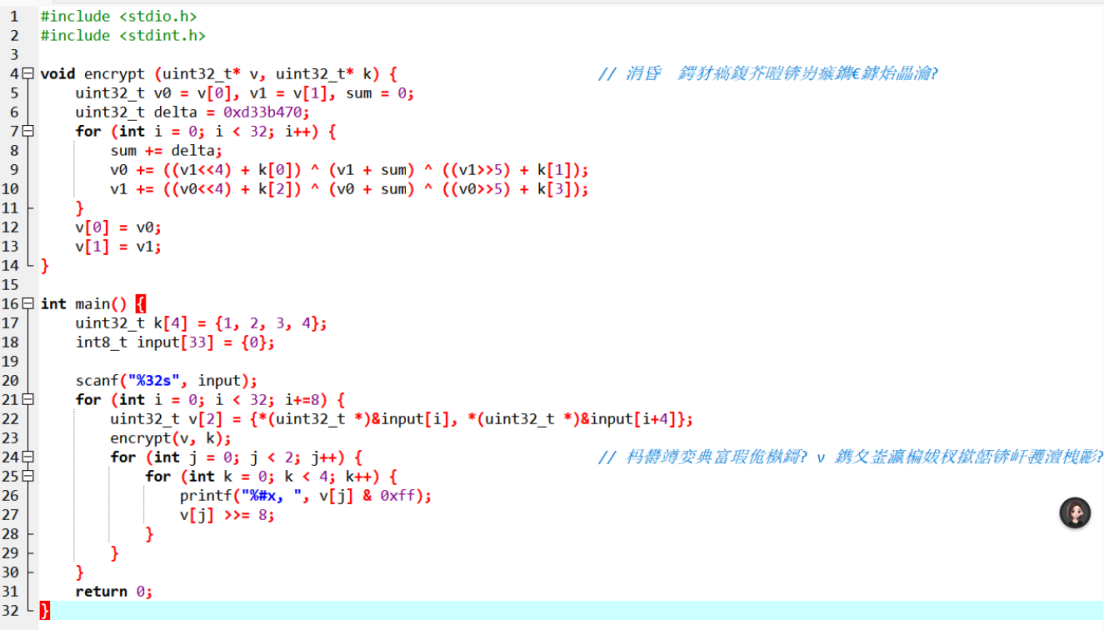
#include <stdio.h>
#include <stdint.h>void decrypt(uint32_t* v, uint32_t* k)
{
uint32_t v0 = v[0], v1 = v[1], sum = 0xd33b470*32; //因为加密32轮,所以最后一轮sum等于delta的32倍uint32_t delta = 0xd33b470;for (int i = 0; i < 32; i++){v1 -= ((v0 << 4) + k[2]) ^ (v0 + sum) ^ ((v0 >> 5) + k[3]);v0 -= ((v1 << 4) + k[0]) ^ (v1 + sum) ^ ((v1 >> 5) + k[1]);sum -= delta;}v[0] = v0;v[1] = v1;
}int main()
{uint32_t k[4] = { 1, 2, 3, 4 };//uint32_t——4字节,uint8_t——1字节int8_t input[] = { 0x17, 0x65, 0x54, 0x89, 0xed, 0x65, 0x46, 0x32, 0x3d, 0x58, 0xa9, 0xfd, 0xe2, 0x5e,0x61, 0x97, 0xe4, 0x60, 0xf1, 0x91, 0x73, 0xe9, 0xe9, 0xa2, 0x59, 0xcb, 0x9a, 0x99,0xec, 0xb1, 0xe1, 0x7d };for (int i = 0; i < 32; i += 8){uint32_t v[2] = { *(uint32_t*)&input[i], *(uint32_t*)&input[i + 4] };//1字节强制转换为4字节decrypt(v, k);//加密for (int j = 0; j < 2; j++)//一字节一字节打印出来{for (int k = 0; k < 4; k++){printf("%c", v[j] & 0xff);v[j] >>= 8;}}}return 0;
}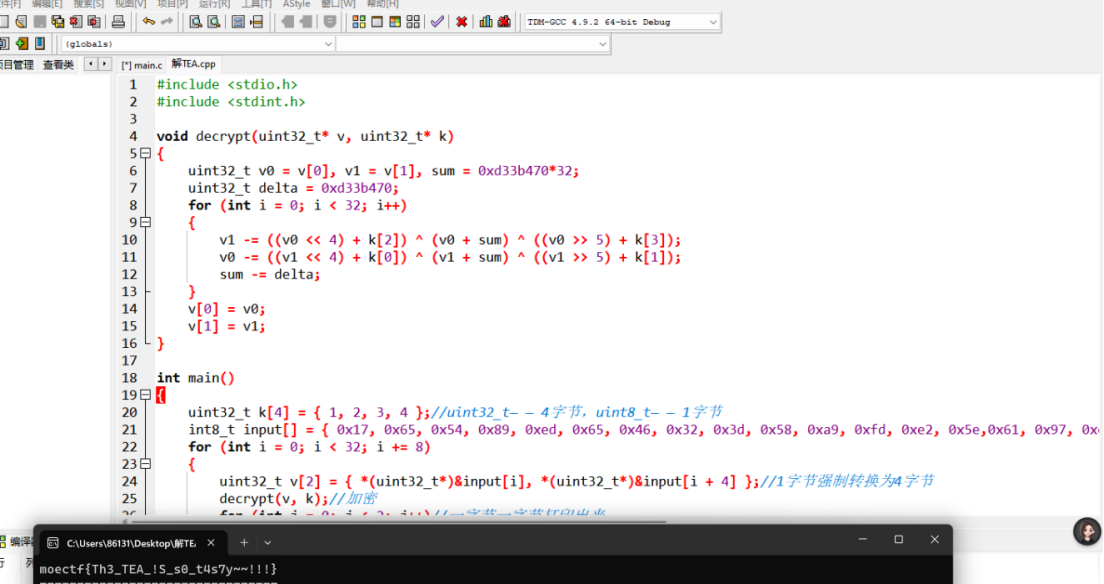
moectf{Th3_TEA_!S_s0_t4s7y~~!!!}
欢迎各位师傅批评指正。