12要素法:构建高效云原生应用
十二要素应用法是一套指导原则,旨在帮助开发团队构建可以高效部署、易于扩展和维护的云原生应用。主要内容包括:
- 代码库:一个代码库对应多个部署,所有资产都保存在同一个版本控制系统中
- 依赖关系:显式声明和隔离依赖项,避免与源代码一起存储
- 配置:将配置信息存储在环境变量或独立配置文件中
- 后端服务:将外部组件如数据库、邮件服务器等视为附加资源
- 构建、发布、运行:将部署过程严格分为三个独立阶段
- 进程:应用程序应作为无状态进程运行,便于扩展
- 端口绑定:通过端口号而非域名标识服务
- 并发:通过进程模型实现应用不同部分的独立扩展
- 易处置性:应用程序应能快速启动和优雅关闭
- 开发/生产环境一致性:保持所有环境的部署过程相似
- 日志:将日志作为事件流处理,与应用逻辑分离
- 管理进程:将管理任务作为应用程序生命周期的一部分处理
I. 代码库(Codebase)
原则:一个代码库,多处部署
所有与应用相关的内容(代码、配置、脚本等)都应存放在统一的版本控制系统(如Git)中,方便开发、测试、运维等人员访问,同时便于CI/CD自动化流程。例子:
- 一家 SaaS 公司将其主应用的全部源代码、依赖和配置脚本都存储在Git仓库。开发人员、测试人员、运维自动化工具比如Jenkins都从同一个仓库拉取代码,确保所有流程的一致性。
- 使用Git仓库管理代码,不同环境(生产、预发布、测试)通过分支或标签区分,确保所有环境的代码基线一致。
II. 依赖声明(Dependencies)
原则:明确声明并隔离依赖
项目依赖(如Node.js的npm包、Java的jar包、.NET的DLL等)需明确写在依赖清单(如package.json、pom.xml等),做到依赖声明和隔离,而不是将这些依赖代码或包直接存库。例子:
- 一个Node.js项目的第三方包不会直接放进Git库,而是在package.json中声明所有依赖。部署和运行时通过npm install自动安装依赖,保证一致性和轻便性。
-
// package.json示例 { "dependencies": { "graphql": "14.2.1", "lodash": "4.17.11" }, "devDependencies": { "chai": "4.2.0", "supertest": "3.4.2" } }
III. 配置(Config)
原则:通过环境变量保存配置
配置应与代码分离,比如用环境变量或单独的配置文件(如Java属性文件、Kubernetes配置清单、docker-compose.yml)。比如端口号、数据库连接字符串、调试开关等不写死在代码里,而在运行环境中注入。例子:
- 生产环境和测试环境用不同的数据库连接,只需要设置不同的环境变量,无需修改代码。
-
# 环境变量配置 APP_PORT=3030 DB_URL=http://mydb:3306 DEBUG=true
IV. 后端服务(Backing Services)
原则:把后端服务(数据库、消息队列等)当做附加资源
像数据库、缓存、消息队列等应被视为外部独立资源,可以灵活替换,比如用MySQL或Postgres,只需更改配置信息,不需修改应用核心代码。例子:
- 如果测试环境用SQLite、生产环境用Postgres,只需要切换配置即可,两者对应用而言是“可插拔的”。
- 应用通过 URL 连接 MySQL 数据库(如jdbc:mysql://db-host:3306/mydb),当数据库升级或迁移时,仅需修改配置即可,无需变更代码。
V. 构建、发布、运行(Build, Release, Run)
原则:构建、发布、运行阶段严格分离
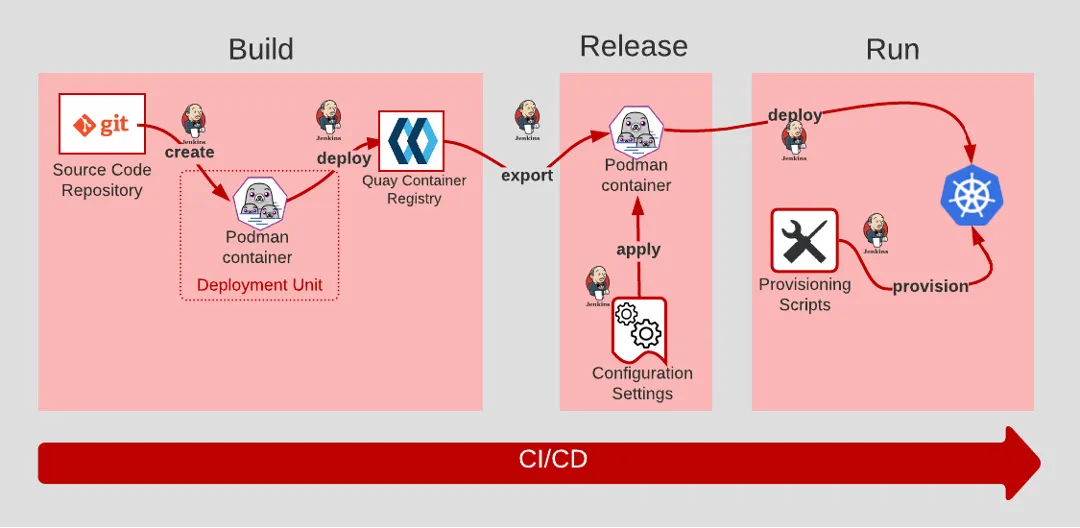
部署流程分为三个阶段:构建(编译打包)、发布(写入配置)、运行(启动进程)。每个阶段都可复现。从代码到可运行应用的每一步都可自动化,出错时可完整重建。例子:
- 开发者推代码至Git,CI系统将其编译为Docker镜像(构建),然后注入环境变量(发布),最终用Kubernetes启动容器(运行)。
VI. 进程(Processes)
原则:应用以无状态进程运行
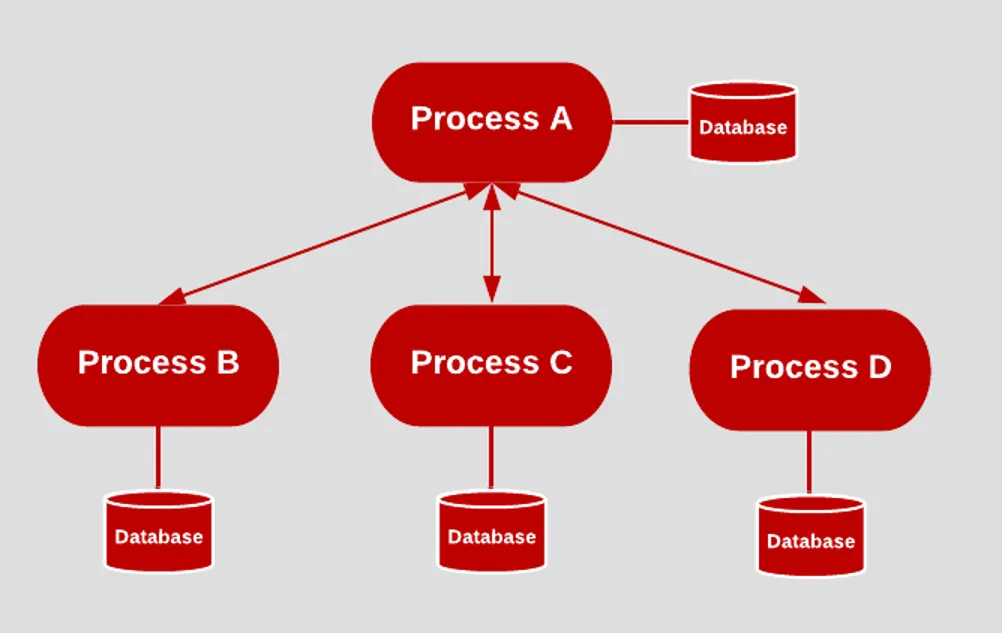
应用应作为一个或多个无状态进程运行。进程本身不记录用户状态(如登录Session),这样方便动态扩容、故障切换。例子:
- Web应用的登录状态保存在Redis等外部服务中,而不是存在本地内存,这样就能随时增加或减少进程实例。
- Web服务通过负载均衡器分配请求,每个实例独立处理请求,会话数据存储在共享缓存中。
VII. 端口绑定(Port Binding)
原则:通过端口绑定对外提供服务
应用不是依附于Web服务器(如Tomcat、IIS)中运行,而是自身作为服务监听端口并提供HTTP等协议。例如:
- HTTP服务监听80端口。
- HTTPS监听443端口。
- 数据库监听3306端口(MySQL)。
- 用Express.js做Web服务时,启动应用会直接监听指定端口(如3000),外部访问直接指向这个端口。
- Docker 容器通过EXPOSE 3000声明端口,主机通过端口映射(如-p 8080:3000)将容器端口暴露到外部网络。
VIII. 并发(Concurrency)
原则:通过进程模型进行(水平)扩展
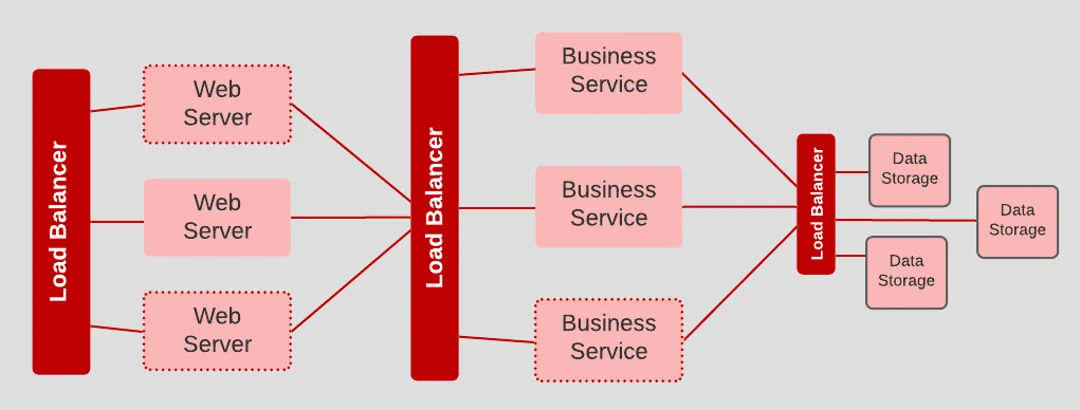
不同类型/功能的任务分为独立进程(如 Web 服务器、业务逻辑服务、数据存储服务),每个组件独立扩展,可以按照需要扩容。比如Web请求和后台任务分开运行,分别扩容,提高系统弹性和吞吐。例子:
- 负载高时Web服务器集群可以单独扩容,而不用和业务逻辑服务绑定在一起整体扩容。
IX. 易处理性(Disposability)
原则:最大化健壮性/鲁棒性,实现快速启动与优雅关停
应用需快速启动,关停时能优雅地释放资源、保存重要状态。例子:
- 关停前断开数据库和消息队列连接,并记录关停日志。
- Web服务收到关停信号后,触发清理函数断开数据库和外部接口,再关闭自身进程。
-
// 优雅关闭示例(Node.js) const shutdown = async (signal) => { logger.info(`断开消息代理连接:${new Date()}`); await messageBroker.disconnect(); logger.info(`断开数据库连接:${new Date()}`); await database.disconnect(); await server.close(); process.exit(0); };
X. 开发/生产环境一致性(Dev/Prod Parity)
原则:开发、测试、生产环境尽可能一致
所有环境的部署路径和流程(构建→发布→运行)一致,降低因环境差异产生的bug和风险,防止测试未覆盖的变更进入生产。例子:
- 开发环境用Docker容器保证与生产环境一致,配置和运行脚本完全复用,通过CI/CD工具自动部署到不同环境。
- 开发环境使用本地数据库(如 SQLite),生产环境使用云端数据库(如 AWS RDS),但两者通过相同的数据库连接接口访问。
XI. 日志(Logs)
原则:将日志视作事件流
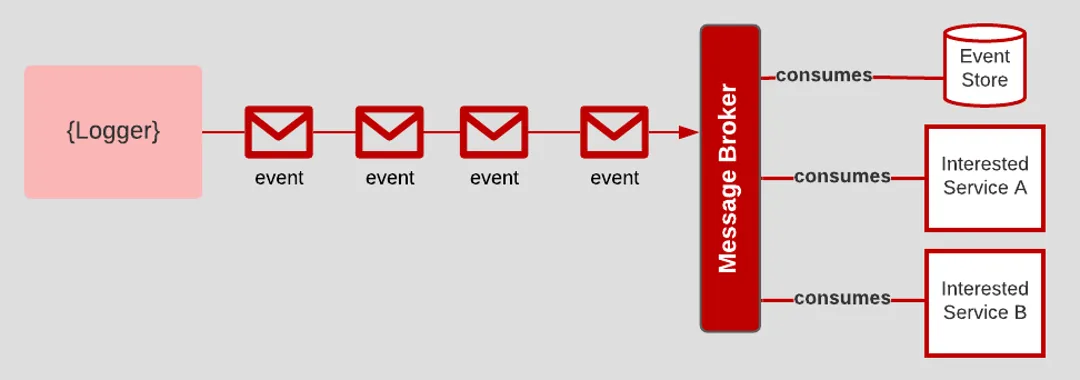
应用将日志当作事件流输出到标准输出,由外部服务(如ELK Stack、Fluentd、Splunk)收集处理。应用本身不关心日志的存储和检索,只专注于输出。例子:
- 应用通过console.log输出到终端,由Docker/Kubernetes收集,并转发到日志仓库,运维按需分析。
- 应用 → 日志流 → 日志收集器 → [存储(Elasticsearch)、分析(Kibana)、告警(Prometheus)]
XII. 管理进程(Admin Processes)
原则:一切管理操作作为一次性进程运行
是指管理和维护任务应该作为独立的一次性进程运行,而不是嵌入到应用程序的常规运行进程中。 管理和维护任务(如数据库迁移、数据清洗)应当以一次性任务(如临时容器、命令行脚本)运行,跟正常业务进程的部署流程一致。例子:
- 用临时容器运行数据库迁移脚本,每次需初始化数据或批量修改,都快速拉起一套环境做完即销毁。
- 运行数据库迁移(例如,在Django中使用manage.py migrate,在Rails中使用rake db:migrate)。
- 运行控制台(也称为REPL shell)以运行任意代码或检查应用程序的模型是否与实时数据库匹配。大多数语言通过在没有参数的情况下运行解释器提供REPL功能(例如python或perl),某些情况下也会有单独的命令(例如Ruby的irb,Rails的rails console)。
- 运行提交到应用程序代码库中的一次性脚本(例如,php scripts/fix_bad_records.php)。
- 所有类型的进程都应使用相同的依赖隔离技术。如果Ruby web进程使用bundle exec thin start命令,那么数据库迁移应该使用bundle exec rake db:migrate;使用Virtualenv的Python程序应该使用相同的vendored bin/python来运行web服务器和管理进程
参考1 redhat
参考2 官网