Redis相关知识总结(缓存雪崩,缓存穿透,缓存击穿,Redis实现分布式锁,如何保持数据库和缓存一致)
文章目录
- 1.什么是Redis?
- 2.为什么要使用redis作为mysql的缓存?
- 3.什么是缓存雪崩、缓存穿透、缓存击穿?
- 3.1缓存雪崩
- 3.1.1 大量缓存同时过期
- 3.1.2 Redis宕机
- 3.2 缓存击穿
- 3.3 缓存穿透
- 3.4 总结
- 4. 数据库和缓存如何保持一致性
- 5. Redis实现分布式锁
1.什么是Redis?
redis是基于内存读写的数据库,因此它的读写速度非常快。常用于缓存、队列、分布式锁等场景。Redis中还有很多数据结构类型:String 、Set、 Hash、 List、ZSet(有序集合)、Bitmaps(位图) HyperLogLog(基数统计)、GEO(地理信息)、Stream(流)。
2.为什么要使用redis作为mysql的缓存?
是因为Redis具有[高性能]和[高并发]的特性。
高性能:由于redis是基于内存读写,其速度远远超过MySQL,因此我们可以将MySQL当中的数据存入到redis当中,下一次直接从redis中读,速度会快很多。
高并发:直接访问redis能承受的请求是远远大于MySQL的。
3.什么是缓存雪崩、缓存穿透、缓存击穿?
3.1缓存雪崩
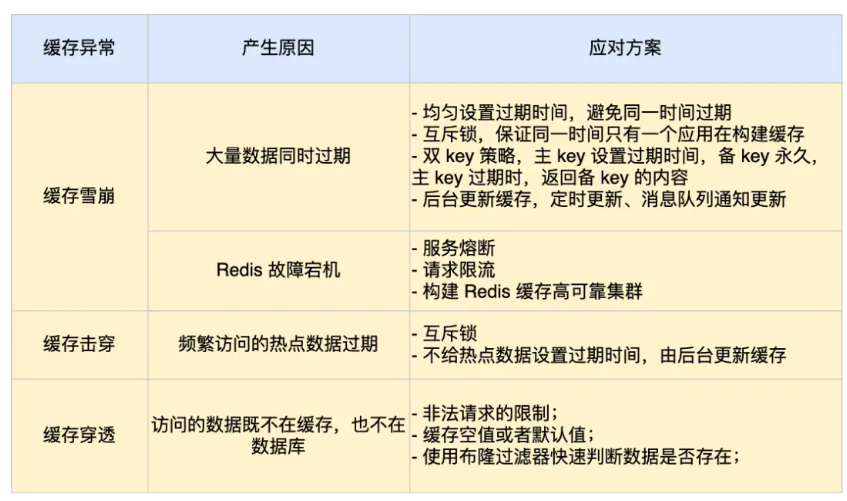
我们将数据存入到redis当中,之后的每次请求都先去redis当中找是否存在数据。从而提高了查询速度也降低了数据库的压力。为了保证redis和数据库的数据一致性,我们通常会给其设置过期时间。但是如果大量缓存数据在同一时间过期,或者redis宕机,会使得大量请求进入数据库,给数据库带来巨大压力。这就是缓存雪崩。造成这一现象的原因有两个大量缓存同时过期,redis宕机。
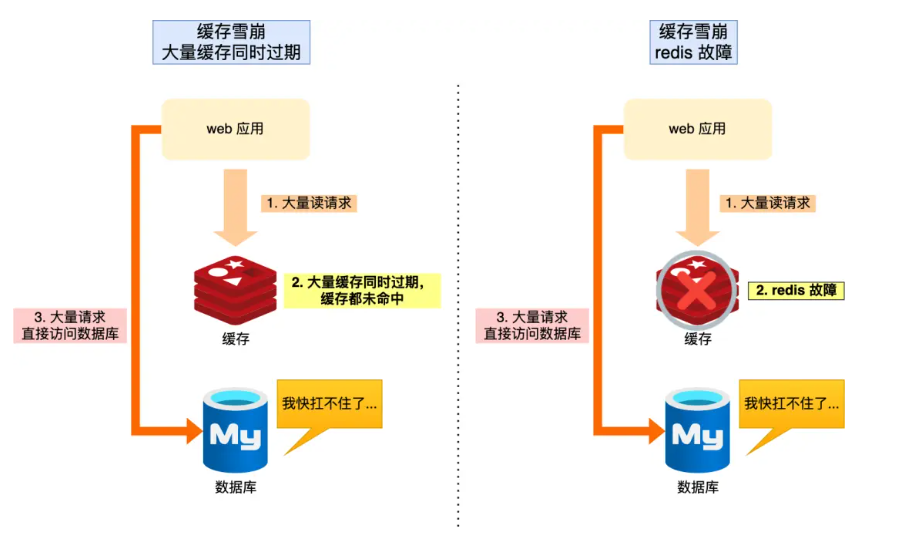
3.1.1 大量缓存同时过期
- 设置不同的过期时间
- 互斥锁
我们可以通过互斥锁来解决大量请求进入数据库的现象。即当发现redis当中没有想要的数据后,先尝试获取锁,如果获取成功就进行查询数据库。而其他线程此时尝试获取锁是会失败的。这样其他线程就必须等查询数据库结束或者直接返回默认值。
- 不设置过期时间
我们可以不设置过期时间,而是让后台进程进行定时更新数据。但是这也造成了另一个现象:当redis中的数据存储过多,会将一部分数据淘汰,这样业务线程就会读取缓存失败。这有两个解决方案,一是让后台线程同时也监测数据是否失效,一旦失效就去数据库从获取。二是在线程业务发现数据淘汰后,通过消息队列发送一条消息告诉后台线程更新数据
3.1.2 Redis宕机
- 服务熔断或限流机制
当Redis宕机之后我们可以将服务熔断,暂停业务应用对缓存服务的访问,并返回错误。等Redis恢复正常再允许访问。或者利用限流机制,可以允许部分请求访问进入数据库,而其他的直接拒绝服务。
- 构建Redis缓存高可靠集群
服务熔断和限流机制是在Redis宕机之后采取的措施。我们最好通过主从节点的方式构建Redis缓存高可靠集群。如果Redis缓存的主节点故障宕机,从节点可以切换为主节点,继续提供缓存服务。
3.2 缓存击穿
缓存击穿指的是热点key失效,导致大量请求进入数据库,给数据库造成巨大压力。
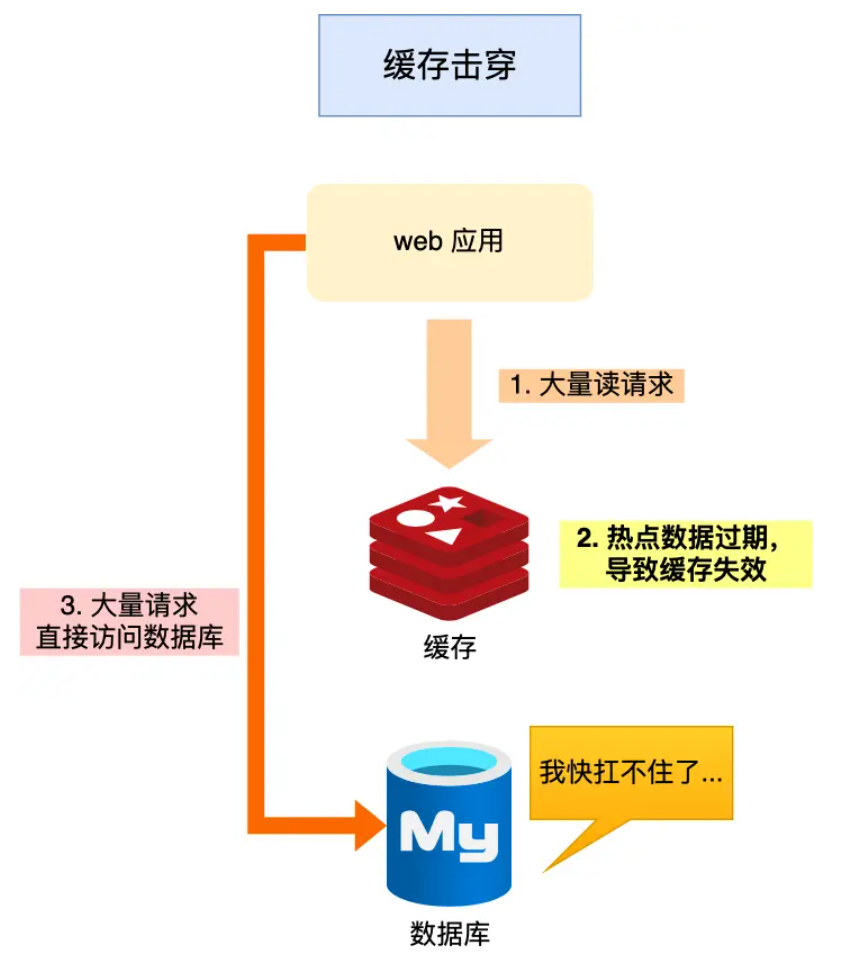
缓存击穿与缓存雪崩很相似,可以看作是缓存雪崩的一个子集。它的解决方案也有两种
- 互斥锁
只有一个进程可以进行数据库的访问,其他进程都需要等待。
- 不设置过期时间
同样也是通过后台进程进行定时更新数据
3.3 缓存穿透
缓存穿透是指,当我们查询redis时发现没有数据,则该线程查询数据库,结果发现数据库中也不存在该信息,又发送了许多不存在的数据查询,导致这些查询全部都穿透过redis,都去访问数据库,给数据库带来巨大压力 。解决方案有三种:
- 限制非法请求
直接在API入口处就对信息进行验证,判断是否是恶意非法信息
- 返回空值或默认值存入redis当中
当我们从数据库中没有查到相关结果后,直接将空值或默认值存入到Redis中,这样,接下来的请求再次到Redis中查询,就能查询到结果。
- 布隆过滤
3.4 总结
4. 数据库和缓存如何保持一致性
首先我们要确定的是,我们在对数据库修改时,是修改缓存还是删除缓存呢?毫无疑问一定是删除缓存,这样可以减少大量不必要的操作。
接下来我们要考虑的是先删缓存,在更新数据库,还是先更新数据库,再删除缓存。
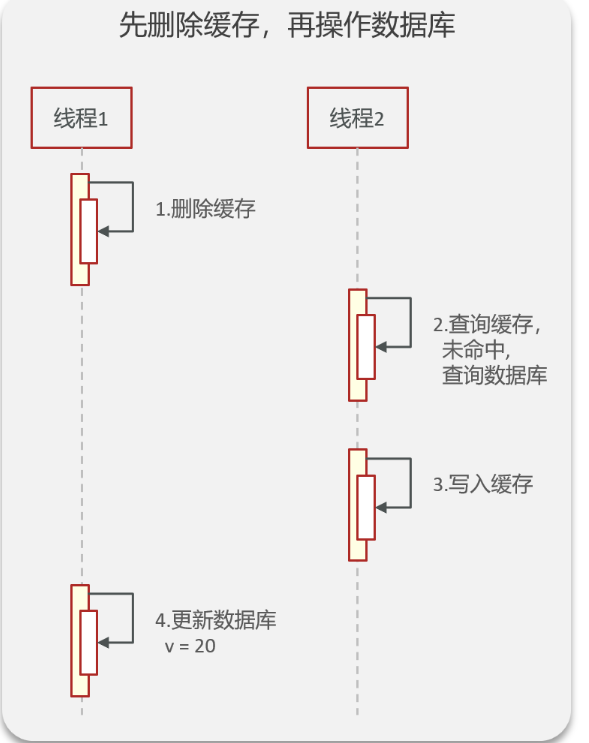
先删缓存,在更新数据库:考虑极端情况,我们在删除完缓存后,数据库还没有更新完成时,又来了一个线程,进行查询缓存,结果没有查到。接着去查询数据库,此时数据库还是旧数据。查到后,又将旧数据存到Redis中,之后数据库完成了修改,这时数据库和缓存就不一致了。
先更新数据库,再删除缓存:考虑极端情况,我们在线程一查询Redis结果没有查到,那么继续查询数据库,并将信息写入Redis,此时出现了线程2对数据库进行修改。这导致存入Redis的是旧数据,而数据库中的是新数据。
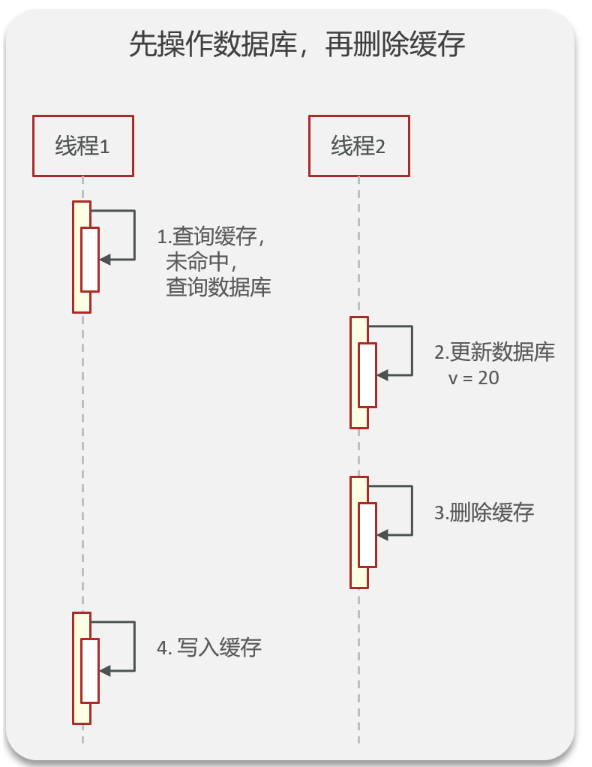
表面上两者都可能出现数据不一致问题,但是写入redis的速度很快,所以在写入之前又更新数据这种情况发生的概率很低。因此我们选择先更新数据库,再删除缓存
5. Redis实现分布式锁
分布式锁是用于分布式环境下并发控制的一种机制,用于控制某个资源在同一时刻只能被一个应用所使用。如下图所示:

由于Redis本身可以被多个客户端共享访问,因此可以作为存储锁的容器。而且Redis中set还有个NX选项,作用是如果集合中存在key就插入失败,如果不存在,则插入成功。我们可以基于这个实现分布式锁。即当集合中不存在该key时,插入成功,表示获取到锁了,如果插入失败,说明此时没有获取到锁。
同时还需要有以下注意点:
- 锁变量需要设置过期时间,以免该线程获取到锁之后由于某些原因造成堵塞,其他进程也无法进行。
- 锁变量的值需要能区分来自不同客户端的加锁操作,以免在释放锁时,出现误释放操作,所以,我们使用 SET 命令设置锁变量值时,每个客户端设置的值是一个唯一值,用于标识客户端;
SET lock_key unique_value NX PX 10000
lock_key:代表锁的key
unique_value:代表该锁的唯一value
同时我们删除锁时需要判断这个value是否是当前客户端的。但是由于先判断再删除,这是两步操作,为保证原子性。我们采用lua脚本实现
// 释放锁时,先比较 unique_value 是否相等,避免锁的误释放
if redis.call("get",KEYS[1]) == ARGV[1] thenreturn redis.call("del",KEYS[1])
elsereturn 0end