CentOS7下的大数据NoSQL数据库HBase集群部署
一、HBase 集群核心架构与应用场景
1.1 分布式 NoSQL 的核心价值
HBase 是基于 Hadoop HDFS 的分布式列存储 NoSQL 数据库,设计目标是支撑海量结构化数据的实时读写,核心特性包括:
- 海量存储:单表支持数十亿行、百万列,数据自动分片存储(Region)。
- 实时读写:基于内存缓存(MemStore)和磁盘存储(StoreFile)的分层架构,支持毫秒级随机读写。
- 高可用性:通过主备 Master、RegionServer 自动负载均衡实现故障转移(文档段落:3-752)。
- 生态兼容:无缝集成 Hadoop、Spark、Flink 等大数据组件,支持 MapReduce 批量处理。
典型应用场景:
- 海量日志存储(如用户行为日志、设备监控数据)。
- 实时数据查询(如电商订单状态查询、金融交易流水)。
- 高并发写入场景(如 IoT 设备数据上报、实时计数器)。
二、集群环境规划与前置准备
2.1 集群节点规划(3 节点方案)
| 节点名称 | IP 地址 | 角色分配 | 数据目录 | 依赖服务 |
|---|---|---|---|---|
| hbase-node1 | 192.168.88.130 | HMaster、HRegionServer | /data/hbase/data | HDFS、Zookeeper |
| hbase-node2 | 192.168.88.131 | HRegionServer | /data/hbase/data | HDFS、Zookeeper |
| hbase-node3 | 192.168.88.132 | HRegionServer | /data/hbase/data | HDFS、Zookeeper |
2.2 前置组件安装(所有节点)
- JDK 环境(需 1.8+,文档段落:3-248):
bash
yum install -y java-1.8.0-openjdk-devel java -version # 验证版本 - Hadoop 集群(HDFS 和 YARN 已部署,文档段落:3-633):
确保 HDFS 服务正常运行,创建 HBase 数据根目录:bash
hadoop fs -mkdir -p /hbase hadoop fs -chmod 777 /hbase - Zookeeper 集群(3 节点,文档段落:3-557):
确保 Zookeeper 服务正常,节点间通信正常。
三、HBase 单机安装与配置
3.1 下载与解压安装包
bash
# 下载HBase 2.1.0(文档段落:3-762)
wget http://archive.apache.org/dist/hbase/2.1.0/hbase-2.1.0-bin.tar.gz# 解压到指定目录
tar -zxvf hbase-2.1.0-bin.tar.gz -C /export/server/
ln -s /export/server/hbase-2.1.0 /export/server/hbase # 创建软链接
3.2 核心配置文件修改
3.2.1 hbase-env.sh(文档段落:3-763)
bash
vim /export/server/hbase/conf/hbase-env.sh
export JAVA_HOME=/export/server/jdk # 配置Java路径
export HBASE_MANAGES_ZK=false # 不使用HBase自带Zookeeper,使用外部集群
export HBASE_DISABLE_HADOOP_CLASSPATH_LOOKUP="true"
3.2.2 hbase-site.xml(文档段落:3-766)
xml
<configuration><!-- HBase数据在HDFS的根目录 --><property><name>hbase.rootdir</name><value>hdfs://hbase-node1:8020/hbase</value></property><!-- 分布式模式 --><property><name>hbase.cluster.distributed</name><value>true</value></property><!-- Zookeeper集群地址 --><property><name>hbase.zookeeper.quorum</name><value>hbase-node1,hbase-node2,hbase-node3</value></property><!-- Zookeeper数据存储目录 --><property><name>hbase.zookeeper.property.dataDir</name><value>/export/server/apache-zookeeper-3.5.9-bin/data</value></property><!-- 禁用流能力检查(HBase 2.1+需配置) --><property><name>hbase.unsafe.stream.capability.enforce</name><value>false</value></property>
</configuration>
3.2.3 regionservers(文档段落:3-769)
bash
vim /export/server/hbase/conf/regionservers
# 添加以下内容(每行一个节点)
hbase-node1
hbase-node2
hbase-node3
四、集群化部署:节点间配置同步
4.1 分发安装目录到其他节点
bash
# 在hbase-node1执行,复制到node2/node3
scp -r /export/server/hbase hbase-node2:/export/server/
scp -r /export/server/hbase hbase-node3:/export/server/
4.2 配置文件一致性验证
检查所有节点的hbase-site.xml和regionservers文件内容一致,确保:
hbase.rootdir指向正确的 HDFS 路径。hbase.zookeeper.quorum包含所有 Zookeeper 节点主机名。
五、集群启动与状态验证
5.1 启动 HBase 服务
5.1.1 单节点启动(hbase-node1 执行)
bash
# 启动HMaster和HRegionServer
/export/server/hbase/bin/start-hbase.sh
5.1.2 后台启动(生产环境推荐)
bash
nohup /export/server/hbase/bin/start-hbase.sh &
tail -f /export/server/hbase/logs/hbase-root-master-hbase-node1.log # 查看启动日志
5.2 验证集群状态
5.2.1 进程检查(所有节点执行)
bash
jps | grep -E "HMaster|HRegionServer"
# hbase-node1应显示HMaster和HRegionServer进程
# hbase-node2/node3应显示HRegionServer进程
5.2.2 网页管理界面
- HMaster 状态:访问
http://hbase-node1:16010,查看集群概述、Region 分布、服务器列表。 - HRegionServer 状态:在管理界面中点击节点名称,查看各节点负载、内存使用情况。
5.2.3 命令行验证(文档段落:3-783)
bash
# 进入HBase Shell
/export/server/hbase/bin/hbase shell# 创建测试表
create 'test_table', 'cf' # 创建表,列族为cf# 插入数据
put 'test_table', 'row1', 'cf:col1', 'value1'# 查询数据
get 'test_table', 'row1'# 扫描表
scan 'test_table'
六、核心功能测试与性能调优
6.1 数据读写测试
6.1.1 批量写入测试
使用 HBase 自带的Put命令或 Java API 进行批量写入,验证吞吐量:
java
// 示例代码:批量写入数据
Configuration config = HBaseConfiguration.create();
Connection connection = ConnectionFactory.createConnection(config);
Table table = connection.getTable(TableName.valueOf("test_table"));
List<Put> puts = new ArrayList<>();
for (int i = 0; i < 10000; i++) {Put put = new Put(Bytes.toBytes("row_" + i));put.addColumn(Bytes.toBytes("cf"), Bytes.toBytes("col"), Bytes.toBytes("value_" + i));puts.add(put);
}
table.put(puts);
6.1.2 随机读取测试
使用Get命令测试随机读取延迟:
bash
time hbase shell -e "get 'test_table', 'row_5000'"
# 预期响应时间在毫秒级别
6.2 性能优化策略
6.2.1 调整 Region 分布
- 预分区:创建表时指定预分区,避免热点问题:
bash
create 'test_table', 'cf', SPLITS => ['row1000', 'row2000', 'row3000'] - 自动拆分:通过
hbase.regionserver.region.split.policy配置拆分策略(如阶梯拆分)。
6.2.2 内存优化
- 调整 MemStore 大小:在
hbase-site.xml中配置:xml
<property><name>hbase.regionserver.global.memstore.size</name><value>0.4</value> <!-- 占堆内存40% --> </property> - 启用堆外内存:
xml
<property><name>hbase.regionserver.memstore.use堆.offheap</name><value>true</value> </property>
6.2.3 存储优化
- 压缩与合并:
xml
<property><name>hbase.regionserver.compactionThreshold</name><value>3</value> <!-- 触发合并的最小StoreFile数量 --> </property> <property><name>hbase.regionserver.StoreFile.compression.codec</name><value>org.apache.hadoop.hbase.io.compress.SnappyCodec</value> <!-- 使用Snappy压缩 --> </property>
七、常见故障排查与解决方案
7.1 集群无法启动
可能原因:
- HDFS 未启动:检查 Hadoop 集群状态,确保 NameNode 和 DataNode 运行正常(文档段落:3-733)。
- Zookeeper 连接失败:检查
hbase.zookeeper.quorum配置是否正确,Zookeeper 节点是否可达。 - 端口冲突:确保 HBase 默认端口(16000、16010 等)未被占用。
解决方法:
bash
# 示例:修复Zookeeper配置错误
vim /export/server/hbase/conf/hbase-site.xml
# 修正hbase.zookeeper.quorum为正确的节点列表
7.2 数据写入缓慢
可能原因:
- Region 热点:某个 RegionServer 承载过多请求,导致负载不均。
- MemStore 刷写频繁:内存不足导致频繁刷写到磁盘。
解决方法:
- 重新分配 Region:通过 HBase 管理界面手动移动 Region。
- 增加 RegionServer 内存:调整
hbase.regionserver.memstore.size和 JVM 参数。
7.3 节点掉线
可能原因:
- 磁盘故障:检查
/data/hbase/data目录所在磁盘是否正常。 - 网络分区:节点间网络延迟过高或断开。
解决方法:
- 更换故障磁盘,重启 HRegionServer 进程。
- 检查网络连接,确保节点间延迟 < 1ms。
八、生产环境最佳实践
8.1 高可用性配置
8.1.1 主备 HMaster
通过 Zookeeper 选举机制,自动故障转移,无需额外配置(文档段落:3-752)。
8.1.2 数据复制(Replication)
配置跨数据中心数据复制,确保容灾能力:
bash
# 在hbase-site.xml中启用复制
<property><name>hbase.replication.enabled</name><value>true</value>
</property>
8.2 安全与权限管理
8.2.1 启用 ACL 权限
bash
# 开启ACL(hbase-site.xml)
<property><name>hbase.security.authorization</name><value>true</value>
</property># 创建用户并授权
hbase shell> create_user 'user1', 'password1'
hbase shell> grant 'user1', 'RWX', 'test_table'
8.2.2 数据加密
- 传输加密:启用 SSL/TLS,配置
hbase.regionserver.secure.port。 - 存储加密:使用 HDFS 透明加密(HDFS Encryption Zones)。
九、总结:HBase 集群部署核心流程
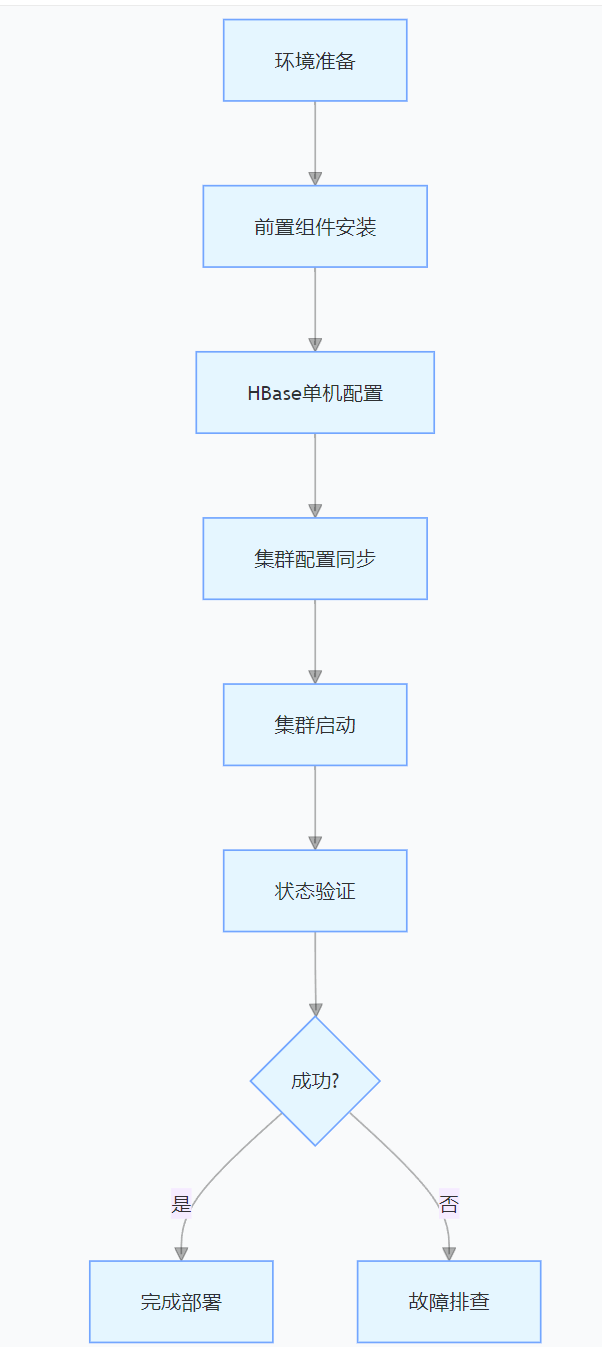
通过以上步骤,可构建一个基于 Hadoop 生态的高可用 HBase 集群,支撑海量数据的实时存储与查询。生产环境中需结合业务场景优化 Region 分布、内存配置及存储策略,并利用 HBase 生态工具(如 Phoenix、HBase Shell)提升开发效率。参考官方文档(HBase Documentation)可进一步学习二级索引、协处理器等高级特性。