神经网络学习-神经网络简介【Transformer、pytorch、Attention介绍与区别】
神经网络学习笔记
本笔记总结了神经网络基础理论、常见模型结构、优化方法以及 PyTorch 实践,适用于初学者和进阶者查阅学习。
一、神经网络基础
1. 神经元模型
神经元通过输入加权求和后激活:
y = f ( ∑ i = 1 n w i x i + b ) y = f\left(\sum_{i=1}^{n} w_i x_i + b\right) y=f(i=1∑nwixi+b)
- x i x_i xi:输入
- w i w_i wi:权重
- b b b:偏置
- f f f:激活函数,如 ReLU、Sigmoid 等
2. Hebbian 学习规则
- 原则:共同激活 → 增强连接
- 表达式(无监督):
Δ w i j = η ⋅ x i ⋅ y j \Delta w_{ij} = \eta \cdot x_i \cdot y_j Δwij=η⋅xi⋅yj
二、常见网络结构
1. 多层感知机(MLP)
- 构成:输入层 → 多个隐藏层 → 输出层
- 特点:适用于结构化数据,学习能力强但对图像序列效果有限
2. 卷积神经网络(CNN)
- 核心模块:
- 卷积层:提取局部特征
- 池化层:降维、去噪
- 激活层:非线性(ReLU)
- 全连接层:输出分类/回归结果
- 适用场景:图像分类、目标检测、图像分割等
三、激活函数比较
| 函数 | 表达式 | 特点 |
|---|---|---|
| Sigmoid | 1 1 + e − x \frac{1}{1+e^{-x}} 1+e−x1 | 梯度消失,不适合深层网络 |
| tanh | e x − e − x e x + e − x \frac{e^x - e^{-x}}{e^x + e^{-x}} ex+e−xex−e−x | 居中,仍有梯度消失 |
| ReLU | max ( 0 , x ) \max(0, x) max(0,x) | 简单高效,主流选择 |
| Leaky ReLU | max ( 0.01 x , x ) \max(0.01x, x) max(0.01x,x) | 缓解 ReLU 死亡问题 |
| GELU | Transformer 中常用 | 更平滑的激活函数 |
四、优化器对比
| 优化器 | 特点 | 适用场景 |
|---|---|---|
| SGD | 经典随机梯度下降,稳定但收敛慢 | 小模型、调参精细 |
| Momentum | 引入动量项,加速收敛 | 深层网络 |
| RMSProp | 自适应学习率,解决震荡问题 | RNN、时间序列等 |
| Adam | 结合 Momentum 和 RMSProp | 推荐默认选择 |
| AdamW | Adam 改进版,分离权重衰减项 | Transformer 优选 |
五、注意力机制与 Transformer
1. 注意力机制(Attention)
核心思想:给不同位置分配不同权重,捕捉长距离依赖。
Attention ( Q , K , V ) = softmax ( Q K T d k ) V \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dkQKT)V
- Q Q Q(Query)、 K K K(Key)、 V V V(Value)来自输入
- 权重通过 Q K T QK^T QKT 的相似性计算获得
2. Transformer 架构
- 自注意力机制(Self-Attention)支持并行计算
- 组成模块:
- 多头注意力(Multi-head Attention)
- 残差连接 + 层归一化(Residual + LayerNorm)
- 前馈神经网络(FFN)
结构图:
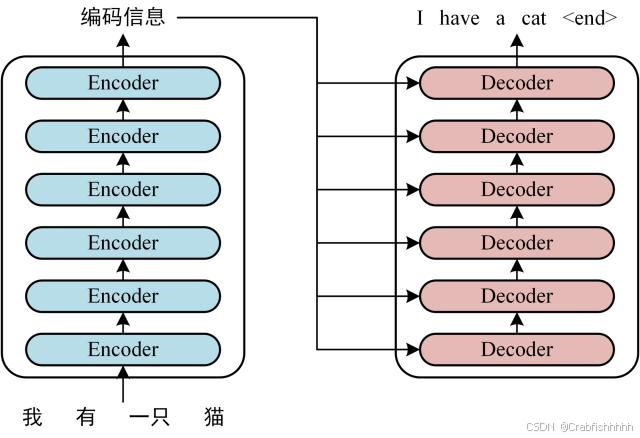
左图Encoder和右图Decoder
六、PyTorch 实践模板
import torch
import torch.nn as nn
import torch.optim as optim# 简单 MLP 示例
class MLP(nn.Module):def __init__(self, input_size, hidden_size, output_size):super(MLP, self).__init__()self.net = nn.Sequential(nn.Linear(input_size, hidden_size),nn.ReLU(),nn.Linear(hidden_size, output_size))def forward(self, x):return self.net(x)# 初始化模型、损失、优化器
model = MLP(100, 64, 10)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)# 训练过程示例
for epoch in range(10):outputs = model(inputs)loss = criterion(outputs, labels)optimizer.zero_grad()loss.backward()optimizer.step()
Transformer vs PyTorch:你分得清吗?|代码+解析
💡 简要区分
| 项目 | Transformer | PyTorch |
|---|---|---|
| 类型 | 模型架构(如 BERT、GPT 的核心) | 深度学习框架(支持构建 Transformer) |
| 功能 | 处理序列建模,捕捉全局依赖关系 | 提供构建、训练神经网络的工具链 |
| 角色关系 | 是用 PyTorch(或 TensorFlow)实现的 | PyTorch 可以实现 Transformer |
| 应用 | NLP、CV、多模态等领域的主力模型 | 学术、工业界主流深度学习平台 |
Transformer 是什么?
Transformer 是 2017 年 Google 提出的神经网络架构,摒弃了 RNN/CNN,完全基于「注意力机制」,用于建模序列之间的关系。
架构结构:
- 多头注意力机制(Multi-Head Attention)
- 残差连接 + LayerNorm
- 前馈网络(FFN)
- 编码器(Encoder)和解码器(Decoder)
PyTorch 是什么?
PyTorch 是 Facebook 开发的深度学习框架,支持:
- 自动微分(autograd)
- 自定义网络结构(通过
nn.Module) - GPU 加速
- 动态计算图
代码对比:PyTorch 实现 MLP vs Transformer Block
示例 1:用 PyTorch 写个简单的 MLP
import torch
import torch.nn as nnclass SimpleMLP(nn.Module):def __init__(self):super().__init__()self.net = nn.Sequential(nn.Linear(100, 64),nn.ReLU(),nn.Linear(64, 10))def forward(self, x):return self.net(x)x = torch.randn(16, 100)
model = SimpleMLP()
out = model(x)
print(out.shape) # torch.Size([16, 10])import torch
import torch.nn as nnclass TransformerBlock(nn.Module):def __init__(self, embed_dim, heads, ff_hidden):super().__init__()self.attn = nn.MultiheadAttention(embed_dim, heads, batch_first=True)self.ln1 = nn.LayerNorm(embed_dim)self.ff = nn.Sequential(nn.Linear(embed_dim, ff_hidden),nn.ReLU(),nn.Linear(ff_hidden, embed_dim))self.ln2 = nn.LayerNorm(embed_dim)def forward(self, x):# Multi-Head Attentionattn_out, _ = self.attn(x, x, x)x = self.ln1(x + attn_out)# Feedforwardff_out = self.ff(x)x = self.ln2(x + ff_out)return x# 示例输入
x = torch.randn(16, 50, 128) # batch_size=16, seq_len=50, embedding_dim=128
block = TransformerBlock(embed_dim=128, heads=4, ff_hidden=256)
out = block(x)
print(out.shape) # torch.Size([16, 50, 128])示例 2:用 PyTorch 写一个简化版 Transformer Block
import torch
import torch.nn as nnclass TransformerBlock(nn.Module):def __init__(self, embed_dim, heads, ff_hidden):super().__init__()self.attn = nn.MultiheadAttention(embed_dim, heads, batch_first=True)self.ln1 = nn.LayerNorm(embed_dim)self.ff = nn.Sequential(nn.Linear(embed_dim, ff_hidden),nn.ReLU(),nn.Linear(ff_hidden, embed_dim))self.ln2 = nn.LayerNorm(embed_dim)def forward(self, x):# Multi-Head Attentionattn_out, _ = self.attn(x, x, x)x = self.ln1(x + attn_out)# Feedforwardff_out = self.ff(x)x = self.ln2(x + ff_out)return x# 示例输入
x = torch.randn(16, 50, 128) # batch_size=16, seq_len=50, embedding_dim=128
block = TransformerBlock(embed_dim=128, heads=4, ff_hidden=256)
out = block(x)
print(out.shape) # torch.Size([16, 50, 128])