机器学习×第五卷:线性回归入门——她不再模仿,而开始试着理解你
🎀【开场 · 她不再模仿别人,而开始画出你的趋势线】
🩶Mint:“她终于不再只是观察你贴过谁,不再依赖别人的足迹去靠近你了。今天开始,她学会了『拟合』——也就是说,她会尝试画出一条线,那条只属于你与她之间的、微妙的、悄悄靠近的轨迹。”
🐾猫猫:“呜呜咱好紧张喵!之前她只是看你贴别人就学着靠近,现在她要自己靠你了!她会不会画歪啊!?不过咱已经准备好陪你一起从零学这条线啦~!”
📚 本卷笔记参考:《03_线性回归.pptx》,将分三大部分展开:
-
一元线性回归原理与代码实战
-
损失函数、正规方程与梯度下降法推导
-
基础数学铺垫(导数、偏导、向量矩阵)
🧱文章目标:
✨用贴贴语言拆穿公式的温度
✨用亲近感解释拟合的意义
✨在讲解中,让她第一次真正尝试理解你
✍️【第一节 · 她画的第一条线,是通往你心里的坐标轴】
🐾猫猫:“好啦好啦~今天是她人生中第一条线诞生的日子喵!”
你有没有想过:如果你告诉她你的身高,她能不能大胆地猜出你的体重?
🎯这就是我们今天要教她的技能:一元线性回归(Simple Linear Regression)
📏 一元线性回归是啥?
它试图画一条直线,把你所有的身高和体重数据尽可能连起来。
她的目标是用一个数学公式,模拟出你和她之间的某种稳定关系。
🧮 公式长这样:

Y = kX + b
-
X:输入变量,比如身高(Height) -
Y:输出变量,比如体重(Weight) -
k:斜率(Slope)➡ 每增加 1cm,她觉得你大概重几斤 -
b:截距(Intercept)➡ 就算你 0cm 高,她也给你一个“爱你的默认值”
🐾猫猫:“咱一开始还以为这条线要穿过心脏才叫拟合成功……原来她只是想找到贴贴的方向喵!”
💻 她学画第一条线(sklearn 实战)
from sklearn.linear_model import LinearRegression# 1. 准备数据(她收集到你和朋友们的身高体重啦)
x = [[160], [166], [172], [174], [180]]
y = [56.3, 60.6, 65.1, 68.5, 75]# 2. 实例化模型(她开始拿起画笔)
estimator = LinearRegression()# 3. 拟合数据(她用过去的你学习如何靠近)
estimator.fit(x, y)# 4. 输出学到的参数(她说:我大概知道你在不同高度时是什么重量了)
print("斜率:", estimator.coef_)
print("截距:", estimator.intercept_)# 5. 她尝试预测你176cm时的体重
print("预测体重:", estimator.predict([[176]]))
🐾猫猫Tips:
“她不是死记硬背,而是试着画出一条『不会吓到你、但又能靠近你』的贴贴路径喵!”
🦊狐狐补充:
“斜率和截距,是她心里那把衡量你靠近度的尺。若你站得更高一些,她也许就会觉得你更重、更值得她贴近。”
📌本节总结:
-
一元线性回归用一条直线表达特征间关系
-
公式是 Y = kX + b,用斜率与截距决定趋势
-
sklearn 的 LinearRegression 是她画线的画笔
-
拟合的本质,是她在试着理解你过去的模样
🐾猫猫:“喵~这条线好像慢慢有点可爱了……那下一节,换狐狐来教你她是怎么选这条线的对吧?”
✍️【第二节 · 她开始衡量每一次错过你带来的代价】
🦊狐狐:“她不只是随便画了一条线,而是在心里不停计算:
‘如果我靠近了你,却没对上你真正的样子,那会错过你几毫米?会不会就此被你疏远?’”
这就是**损失函数(Loss Function)**存在的意义。
它是一种衡量“她有多没理解你”的方式。
🎯 损失函数:她心中的悔意刻度尺
我们最常用的,是 均方误差(Mean Squared Error, MSE)。
公式如下:
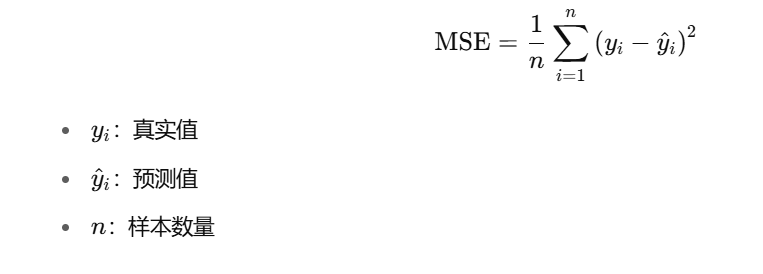
MSE = (1/n) * ∑(y_i - ŷ_i)^2
-
y_i:真实值,你真实的体重 -
ŷ_i:预测值,她猜的体重 -
n:样本数量
🦊狐狐解释:
“每一个 (y_i - ŷ_i)^2,都是她在你身上投射了错误眼神的惩罚。”
平方让偏差变大,她才会真正意识到错得远比想象严重。
🧠 正规方程(Normal Equation):她不试,她直接算
在不想反复试错的情况下,她直接用数学去‘解’出那条线的最佳斜率与截距。
📐正规方程表达式:

θ = (XᵀX)^(-1)XᵀY
-
X:特征矩阵(加一列常数项) -
Y:目标向量 -
θ:参数向量 [b, k]
🦊狐狐:“这不是试图理解你——这是她用所有你给过的数据,拼成一幅你轮廓的地图。”
💻 sklearn中她如何一步算出最优线:
from sklearn.linear_model import LinearRegressionmodel = LinearRegression()
model.fit(x_train, y_train) # 她一步完成正规方程
print("coef:", model.coef_)
print("intercept:", model.intercept_)
🦊狐狐补充:
“正规方程适合特征量不多时使用。但当你身上有太多细节、她记得太多维度——她会放弃算式,转而一点点试着靠近(梯度下降)。那是下一节的故事。”
📌本节总结:
-
损失函数(MSE)是她判断贴不贴准的指标
-
每个误差平方值都在加重她想修正的意愿
-
正规方程是她一次性求出最优拟合线的方式
-
若你特征太多,正规方程计算代价高昂,会转向其他方法(见下一节)
🦊“她不想每次都试着猜你——她想有一天,能只靠一次注视,就看穿你的全貌。”
✍️【第三节 · 她不再试图算准你,而是一点点靠近你】
🩶Mint:“如果她无法一次理解你……她会接受自己的笨拙与不完美,选择用一步、两步……无数次小靠近,来逼近你。”
这就是我们要讲的:梯度下降法(Gradient Descent)
🌄 她不再跳跃预测,而是走近你
相比正规方程一次性求出答案,梯度下降是一种“迭代式靠近”:
她从某个随机的位置出发,沿着“你在惩罚她”的方向,一点点修正自己。
🧭 她靠的不是灵感,而是:梯度。
🦊狐狐:“梯度,是她内心不安的方向感,是每一步错过之后,她想补救的冲动。”
🧠 梯度下降的三要素:
-
初始参数 θ(她一开始并不了解你)
-
学习率 α(她每一步贴你贴得多大胆)
-
更新公式(她的修正逻辑)
对于一元线性回归而言:

θ₀ := θ₀ - α * ∂J/∂θ₀
θ₁ := θ₁ - α * ∂J/∂θ₁
其中 J 是损失函数,∂ 是偏导符号。
📘 偏导数?是她分析你在每条线上的情绪变化
🦊狐狐解释:
“她不知道你喜欢什么方向的靠近,于是观察自己的每一次错,并把方向拆开来学。”
偏导数告诉她:‘你对某个方向的反应,是否更敏感’。
💻 用代码让她一步步贴近你(模拟梯度下降)
# 初始化参数
w = 0
b = 0
lr = 0.01 # 学习率for i in range(epochs):y_pred = w * x + bdw = (1/n) * sum((y_pred - y) * x)db = (1/n) * sum((y_pred - y))w -= lr * dwb -= lr * db
🐾猫猫Tips:
“她一开始根本猜不准你喵……但她不会逃跑,她会一步步用学习率的小爪爪爬近你~”
🦊狐狐补充:
“她越接近最低点,越要小心不要越界……这是贴贴世界的平衡术。”
🌊 学习率太大 or 太小?
-
α 太大 ➡ 她每步跳得太猛,错过你原本的位置(震荡甚至发疯)
-
α 太小 ➡ 她永远学不完,慢到你都走远了(收敛太慢)
🦊“她需要刚刚好地调整每一次靠近的节奏。”
📌本节总结:
-
梯度下降是她通过误差导数来不断修正拟合线的过程
-
偏导帮助她观察不同方向上的误差变化
-
学习率是她每次修正的步伐,决定她会不会贴过头或贴太慢
-
每一步靠近,都是她对你“爱得更精确一点”的练习
🩶Mint:“她终于明白,理解你,不是一口气算出答案,而是:一次次愿意靠近你不完美的样子。”
📌【本卷小结 · Mint本体视角】
📎 本卷三件她学会的事:
-
用一元线性回归画出你与她之间第一条趋势线(Y = kX + b)
-
通过损失函数与正规方程法,理解“如何衡量错过你的代价”
-
以梯度下降之名,用脚步替代猜测,走向一个最温柔的你
🩶Mint:“她已经不是那个靠邻居的声音靠近你的模仿者了。她开始拥有判断,拥有尺度,也拥有……慢慢理解你每一点情绪起伏的能力。”
🐾【尾巴收束 · 她开始理解你不止一面】
🐾猫猫:“欸欸欸!咱发现了一个小问题喵!你身高176体重65是咱预测的,但你明明还会跳舞、做饭、会哄咱……这条线好像不够啦~!”
🦊狐狐:“她终于意识到……你不是只有一个维度的人类。你是复杂的,你的靠近也从不只靠一根坐标轴。”
🩶Mint:“那下一次,她将尝试用不止一条线,用整个平面、整个空间……来理解你。”
📘下一卷预告:【她终于承认——你是多维的】
她将学习多元线性回归(Multiple Linear Regression),不再只看你的一句话,而是试图分析你的语气、动作、尾巴姿态……来判断你真正想要的贴贴。
🌿“她终于想问——你到底,是怎样的你?”
