第五讲 基础IO
我们这章学的是IO流基础, 也就是我们操作系统所对应的读写这部分内容, 只不过是相对简单的去了解基础的这一部分. 那为了去了解这部分知识, 我们先来从文件切入, 前面可能会疑惑以文件进行切入, 我相信后面把整个基础IO学完之后就能理解了.
1. 文件操作
1.1. 简单回顾文件操作
我们先来写一个C语言的简单文件操作代码, 我们通过这个简短的, 我们C语言所熟悉的代码来揭开序幕:
#include <stdio.h>
#include <string.h>
int main()
{FILE *fp = fopen("myfile", "w");if(!fp){printf("fopen error!\n");}fclose(fp);return 0;
}好的, 上面就是我们C语言关于文件操作的简单代码.
首先, 我们看到这个代码中有FILE *fp = fopen("myfile", "w");这段代码, 是在打开文件. 那什么是打开文件呢? 在C语言阶段, 我们很难去理解打开文件这个概念, 真正理解相关概念, 我们必须深入到系统的角度去理解, 下面我们来重新认识一下:
1.1.1. 结论 1: 文件的概念: 文件 = 文件属性 + 文件内容.
理解: 什么是文件呢? 文件说白了就是一些数据的集合. 说人话, 计算机所有的东西都是数据(粗略理解). 这个文件内容啊, 很好理解, 就是文件里有什么东西呗, 这个文件属性怎么理解呢? 所谓的文件属性就是标志文件内容的一些东西, 比如说文件名, 比如说文件是二进制的还是十进制的? 文件属性十分重要, 举个例子来说, 同样是0000 0001这段数据内容, 计算机从二进制的视角去看, 他就是1, 但是计算机从字符的角度去看这个就是ASCII码对应的不可打印的一种字符.
1.1.2. 结论 2: 进程打开文件
理解: 我们的文件打开, 从来都不是我们程序员/写代码的人去直接打开文件的, 而是由进程去打开的. 说的详细一点, 就是我们写好的代码, 先被编译链接成为二进制可执行文件被保存在磁盘中, 之后加载到内存里, 操作系统生成对应的进程去执行这个代码, 这个进程再被CPU进行调度, CPU执行到上面代码fopen函数的时候, 才可以说是进程打开文件.
那么上面我的关于进程打开文件这段话其实就解释了一些问题. 比如说: 我们没有写全要打开的文件路径, 如果有文件在当前路径下的话, 文件就会被打开. 这实际上就是因为进程生成后有记录当前工作路径的属性罢了.
1.1.3. 结论 3: 打开的文件需要被操作系统管理起来.
理解: 同时, 还需要了解: 一个进程可以打开很多文件, 即进程与文件的关系是一对多的关系. 如此大量的文件被打开, 作为电脑软硬件的管理者, 操作系统必然要对打开的文件管理. 操作系统是如何对其进行管理的呢? 实际上类似于操作系统管理进程的方式, 为打开的文件生成一个个结构体对文件进行管理, (我们这里如何管理只是大体一说, 后面会画图详细解释.) 而到最后, 实际上就变成了进程的PCB结构体与文件结构体的指向关系.
1.1.4. 文件打开的方式: 读, 写, 追加
写: 文件可以以不同的方式打开一个文件. 以我们C语言的函数为例, 我们"w"就是以写的方式打开文件, 对应的代码就是fopen("myfile", "w");而C语言中的读有两个特点:
- 如果不存在这个文件 新建这个文件
- 如果存在这个文件 清空文件内容
追加: C语言也支持以追加的方式打开一个文件. 只不过不会像写一样一上来就清空文件内容就是了. 对应的代码是fopen("myfile.txt","a");
重定向 与 读写:
实际上, 我上面说的是C语言函数, 那除了C语言呢? 指令级别的读写呢? 我们指令有个>, 基本相当于C语言"写"的功能, >>类似于C语言追加的功能. 实际上, 这些都是因为>是一个输出重定向, 说白了重新定向写的位置, 既然要写, 那么就得打开文件啊, 你不打开你怎么写?(这里先暂且粗略理解, 实际上看到后文就知道, 打开文件究竟是个什么玩意).
1.2. 理解文件操作
首先我们需要明确: 操作文件是进程与文件之间的关系.
文件操作过程的理解: 向文件中写入数据, 本质上是向硬件写入. 因为文件在硬盘(硬件)中存储. 但又因为我们用户没有直接访问硬件的权力, 所以说我们必须通过操作系统提供的接口进行调用, 语言为了方便文件操作, 进一步封装了文件系统调用接口
我们下面来介绍一下文件操作的系统接口:
1.2.1. 文件操作的系统调用接口
既然谈到文件读写, 那就我们来介绍一个操作系统的读写接口: 下面开始重点介绍这个函数.
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>int open(const char *pathname, int flags);
int open(const char *pathname, int flags, mode_t mode);int open(const char *pathname, int flags, mode_t mode);
const char *pathname这个是文件名/文件路径, 默认是当前路径下文件.
int flags这个是一个标志参数, 用来把自己想要实现的功能传入函数内. 说到标志位, 下面说一下Linux常用的标识方法.
1.2.1.1. 标记位
Linux中的标识参数.
我们平时想要去告诉一个函数我想不想要这个功能, 通常是写一个int flag的变量, 来将这个变量设置为0或1来告诉对应的函数我想不想要这个功能. 但是有个问题, 一旦我想要表达要不要的选项多了, 那么参数也得跟着躲起来.
//比如, 我想表达5个要不要的选项
void func(int flag1, int flag2, ...);很显然, 这样会累死人的, 我们也不可能写一个有100个参数的函数吧? 所以Linux采用了一个很好的办法, 用比特位去标识标记位. 因此, 一个int变量就可以标志32个选项! 因此方便多了. 具体是怎么做到的呢? 下面提供一个举例:
#define ONE 1
#define TWO (1 << 1)
#define THREE ( 1 << 2)void func(int flags)
{if(flags & 1){printf("one\n");}if(flags & 2){printf("two\n");}if(flags & 4){printf("three\n");}
}int main()
{func(ONE); // onefunc(ONE | TWO); // one tworeturn 0;
}紧接着, 是第三个参数的介绍, mode_t mode是让我们设置初始权限值的, 不过会受到umask影响, 因此一半建议在程序里写上umask(0), 来避免被系统的权限掩码所影响.
然后是返回类型, 是int类型, 就是文件标识符的意思, 这个我们后面详细说.
1.2.1.2. fd的含义 -> 文件标识符
fd是Linux为了标识被打开的文件, 并对被打开的文件进行管理取的文件标识符, 类似于操作系统为了管理进程而为进程取的pid名字.
fd说白了就是文件映射关系的数组的下标而已, 在下面图解中的数组就是文件fd.
比较特殊的是, 0, 1, 2文件是默认被打开的, 就是我们的stdout, stdin, stderr, 分别对应键盘, 显示器, 显示器.
除此之外, 还有一些其他的系统调用接口:
1.2.2. 其他系统调用接口
1.2.2.1. wirte
#include <unistd.h>ssize_t write(int fd, const void *buf, size_t count);fd 指的是文件标识符, 用来对打开的文件(加载到内存的文件进行标识). 这里指的是要向哪个文件进行写入.
buf 内存缓存区, 即数据来源在哪
count 即要写入多少字节
ssize_t 是函数返回值, 如果写入成功, 就返回写入了多少字节数(有可能会比预期要小, 比如磁盘空间不足), 如果失败, 就返回-1. 并设置错误码. ssize_t是C语言当中的一个数据类型, 常用来作为IO流相关函数的返回类型. 然后这个返回类型通常情况下, 32系统下定义是int, 64系统下定义是long int.
注: 向文件中写入数据时候, 不需要在文件结尾加'\0', 因为'\0'属于C语言为了标识字符结束而做的规定, 但是文件并没有这样的规定.
1.2.2.2. read
#include <unistd.h>ssize_t read(int fd, void *buf, size_t count);1.3. 结合操作系统视角来理解文件操作
1.3.1. 结合图来理解
比如, 我调用open接口打开一个文件, 然后向上面写"hello world", 这整个过程是什么样子的呢?
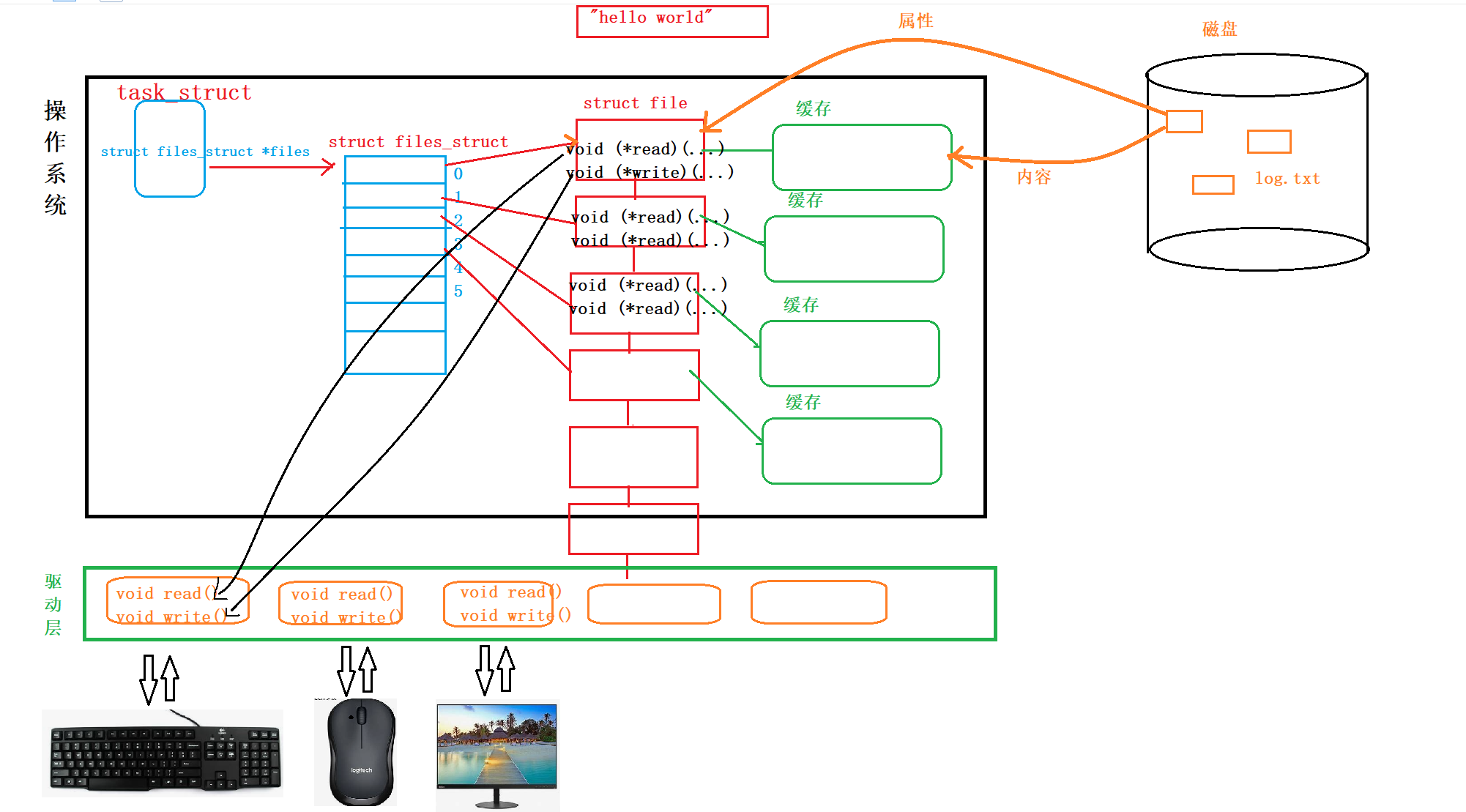
首先, 如果你调用open, 说明是进程调用的系统调用接口, 那肯定有一个task_struct了, 然后当代码执行到open的时候, 此时操作系统为你要打开的这个文件生成一个struct file结构体对象, 之后通过指针与task_struct建立指向关系, 并申请一块缓存, 存放文件内容. 整个这个过程就是文件打开的过程.
当我们写的时候, 我们会找到要写入的字符串地址"hello world", 然后把他拷贝对应缓存中, 之后刷新到磁盘中.
- 什么是读(read)呢?
就是拿着fd找到进程对应的文件数组下标里的指针,然后把文件内核级的缓存(如果数据不在内核级 缓存中,操作系统先阻塞你的进程,然后先把磁盘中的文件搬过来...)拷贝到用户层的缓存的一个做法而己. - 什么是写(修改)呢?
就是先在用户层读到我们要写的数据,此时数据暂时存放在用户层的缓冲区中,然后满足条件(碰到endl或者缓冲区满)的时候刷新到内核级的缓冲区中,之后再由操作系统把控把数据刷新到磁盘的文件当中. - 什么是打开文件呢?
创建对应的file,开辟空间,把磁盘中的文件加载到内存中.
因此, 我们总结一下, open是在做什么呢?
- 创建file实例
- 开辟文件缓冲区的空间, 加载文件数据
- 查进程的文件描述符表
- file地址, 填入对应的表下标中
- 返回下标
open 系统调用在做什么? (来自文心一言)
- 进程调用
open系统调用:
-
- 当一个进程调用
open函数时,它实际上是在请求操作系统内核执行一个名为open的系统调用。 - 此时,操作系统已经知道调用者的身份(通过
task_struct结构体,该结构体代表了进程在内核中的状态和信息)。
- 当一个进程调用
- 生成
struct file结构体对象:
-
- 内核会为要打开的文件或设备创建一个
struct file结构体实例。这个结构体包含了文件操作的相关信息,如文件描述符、文件偏移量、指向文件操作函数的指针等。 - 但请注意,
struct file并不是直接与task_struct建立指向关系的。而是task_struct中有一个文件描述符表(file descriptor table),该表中的每一项都指向一个struct file_struct(在某些内核版本中可能是files_struct结构体中的一部分),而struct file_struct则包含了指向打开的文件的struct file实例的指针。
- 内核会为要打开的文件或设备创建一个
- 申请缓存:
-
- 当文件被打开时,内核可能会为文件内容分配缓存(也称为页面缓存或缓冲区缓存)。这个缓存存储在内存中,用于加速对磁盘上文件的读写操作。
- 缓存的分配和管理是由内核的文件系统代码负责的,而不是由
open系统调用直接完成的。
- 写入过程:
-
- 当进程调用
write函数时,它指定了要写入的数据(在本例中是字符串"hello world")、数据的大小以及目标文件描述符。 - 内核接收这些参数,并找到对应的
struct file实例。 - 然后,内核将数据从用户空间(进程的地址空间)复制到内核空间(通常是页面缓存)。
- 如果页面缓存已满或达到某个阈值,内核可能会将数据从缓存刷新(或称写回)到磁盘上的文件中。这个刷新过程可能是同步的(立即发生),也可能是异步的(稍后发生,由内核的后台进程处理)。
- 当进程调用
- 文件关闭:
-
- 当进程调用
close函数时,它会关闭文件描述符,并释放与打开文件相关的资源。这包括可能仍在缓存中的数据(如果设置了适当的同步选项,则这些数据可能会被刷新到磁盘)。
- 当进程调用
请注意,这个过程涉及许多内核内部的操作和机制,包括内存管理、文件系统实现、I/O调度等。此外,不同的操作系统和文件系统实现可能会有所不同,但上述描述提供了一个基本的、跨平台的概述。
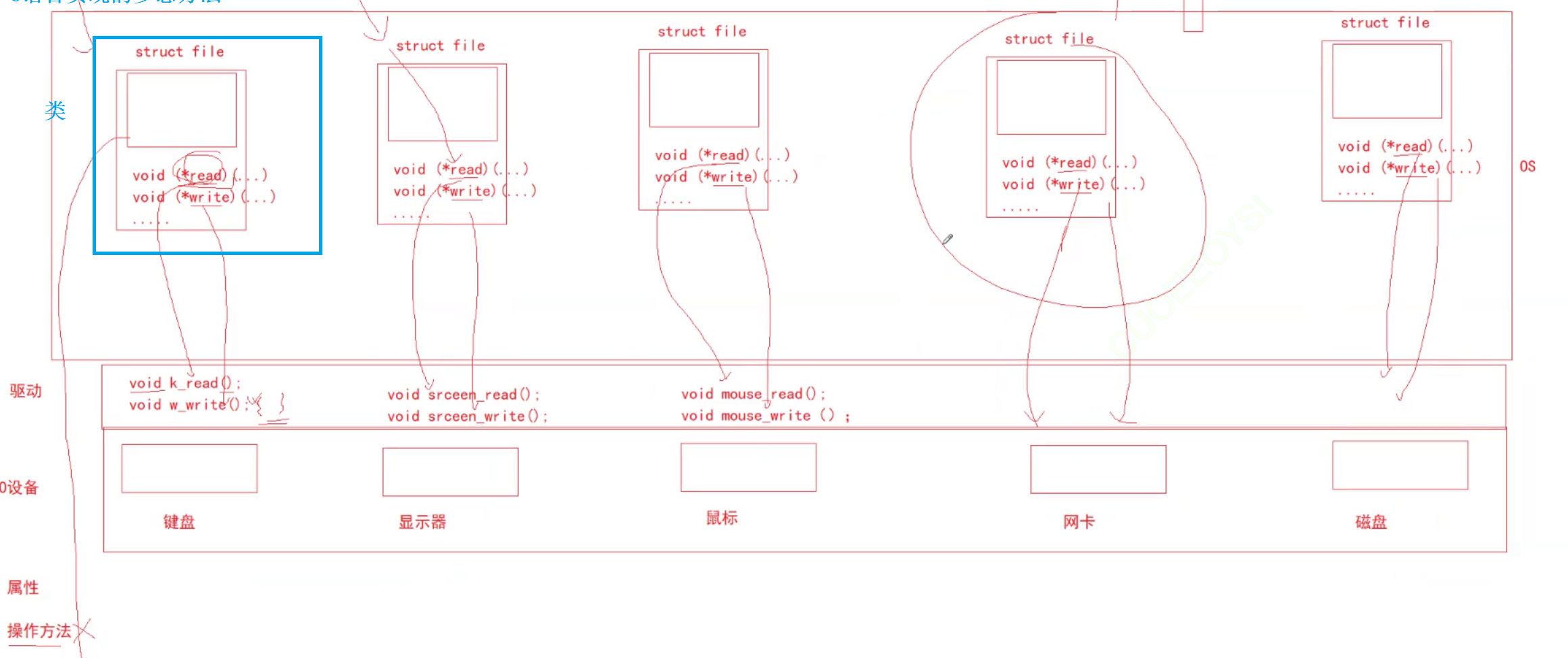
1.3.2. 作为硬件的键盘和显示器,如何被以文件的形式读写的?
现在还有一个问题:就是磁盘中的文件读写我懂了,但是显示器键盘是硬件,不是文件,是怎么读写文件内容的呢?--〉因此要理解Linux一切皆文件的问题
每一种硬件外设(I0),都有两个部分构成:一个是属性,另一个是操作方法.
属性可以是相似的,但是操作方法是不同的,需要由对应的硬件厂商的驱动工程师来写.
我们操作系统通过创建struct_file来把硬件设备抽象成为文件来进行管理,使得操作系统上层的用户层使用外设与读写文件一样,因此看来似乎是一切皆文件的.
1.4. C 文件操作库函数 与 系统调用接口关系
1.4.1. FILE 与 fd 的关系
FILE, 是C语言当中的一个结构体, 实际上FILE是C语言对操作系统中的fd一个封装.
FILE在不同的平台下均不同, 为了实现C语言的跨平台性, 往往windows, macos, linuxC语言都有不同的FILE定义, 只不过在用的层面上来讲是一样的, 从而实现的C语言的跨平台性问题. 换言之, 因为操作系统的不同, 对外提供了不同的系统调用接口, C语言/CPP语言通过库函数对系统调用进行封装, 实现了跨平台性.
1.4.2. C 中的文件操作函数 与 文件操作的系统调用接口
实际上, 文件操作函数是用系统调用接口的封装.
1.4.3. C 语言封装的意义?
- 使得代码具有跨平台性: 通过封装操作系统提供的系统调用, 我们可以使代码具有可平台性, 具有良好的可移植性.
1.5. 文件操作的应用
1.5.1. 重定向
1.5.1.1. 重定向原理解释
首先我们来看一个示例代码
#include<sys/stat.h>
#include<sys/types.h>
#include<fcntl.h>
#include<unistd.h>const char* filename = "log.txt";int main()
{
close(1);int fd = open(filename, O_CREAT | O_WRONLY | O_TRUNC, 0666);if(fd < 0){perror("open");return 1;}printf("printf, fd: %d\n", fd);fprintf(stdout, "fprintf, fd : %d\n", fd);fflush(stdout);close(fd);return 0;
}//cat log.txt
//printf, fd: 1
//fprintf, fd: 1解释: 之所以会发生这种情况, 我们来简单解释一下: 这是因为 printf 是默认向 1 号文件写入内容的, 但是我们代码第一步就把 1 号文件给关闭了, 然后又打开了一个文件, 这个文件是"log.txt", 显然他就是现在的 1 号文件.
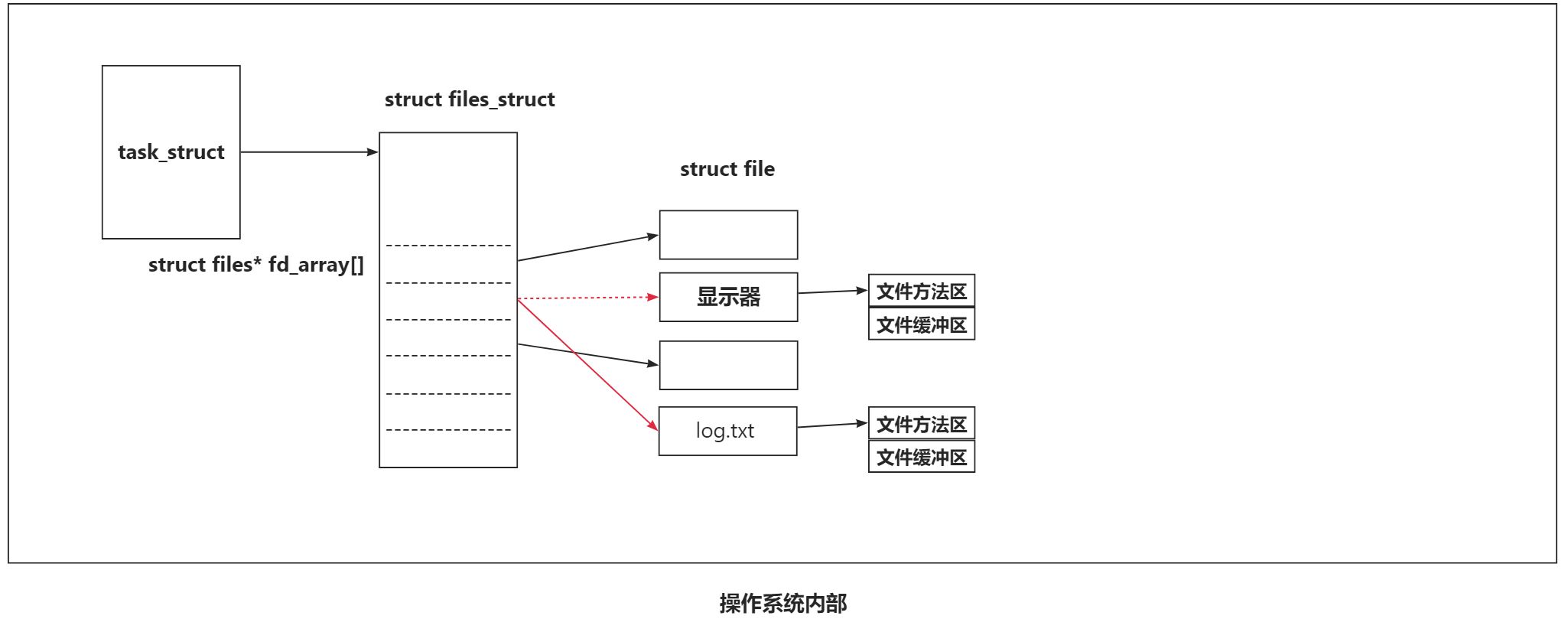
实际上, 这其实就类似于一种重定向操作~
但是, 如果把上面代码的 fflush给注释掉, 就不会打印到屏幕上, 这是为什么呢?
我们写的一些数据被 C 函数接口拿到之后是放在语言层级的一个缓冲区中, 正准备遇到 endl 或者缓冲区满刷新到内核级的文件缓冲区中, 但是因为我们上面代码 close 了, 还没来得及刷新文件就被关闭了~
1.5.1.2. 重定向接口介绍
好的, 上面是一个模拟"重定向", 是一种比较"巧合"的存在, 我们下面来真正认识一下重定向操作~
int dup2(int oldfd, int newfd);
描述: 让 newfd 成为 oldfd 的拷贝, 换言之, 就是替换掉 newfd.
我们举个例子来说: dup2(fd, 1); 就是把向显示器输出重定向到文件 fd 中.
1.5.1.3. 重定向例子
下面是一些测试(实际例子): 我们可以重定向显示器到一个文件中.
int main()
{int fd = open(filename, O_CREAT | O_WRONLY | O_TRUNC, 0666);dup2(fd, 1);printf("hello world\n");fprintf(stdout, "hello world\n");return 0;
}
//cat log.txt
//hello world
//hello worldint main()
{int fd = open("/dev/pts/3", O_CREAT | O_WRONLY | O_TRUNC, 0666);if(fd < 0){perror("open");return 1;}dup2(fd, 1);printf("hello world\n");fprintf(stdout, "hello world\n");return 0;
}
//另一个终端上:
//hello world
//hello world1.5.2. 语言级别的缓冲区
1.5.2.1. 缓冲区的概念
缓冲区: 说白了就是一块内存空间.
1.5.2.2. 缓冲区的意义
一句话: 给上层提供高效的 IO 体验, 简洁提高整体的效率.
实际上, 我们的 C 语言有自己的缓冲区, 当遇到'\n'或者 fflush 或者缓冲区满的时候才会把数据刷新到内核级别的缓冲区中.
一般缓冲区分为两种: 语言级别的缓冲区 和 内核级别的缓冲区, 我们这里重点说语言级别的缓冲区.
有两个意义:
- 解耦
- 提高效率
解耦? 啥意思?
这是什么意思呢?就是我们C语言与操作系统解耦的意思,就是我们只需要关心语言层面就好了,我们不用关心C语言怎么吧数据给到操作系统
多了一次拷贝,会提高效率吗?
这个效率指的是提高使用者的效率.确实对于计算机来说多干了活,多了一次拷贝嘛,但是对于用户来说,效率就高了,为啥呢?举个例子,你给你朋友送个东西,你俩相隔很远,有两种方式,种是你直接自己送,那么肯定浪费自己时间嘛,然后就是降低使用者的效率嘛.但是呢,我们发快递,确实对于我们所有人来说工作量是增加了,但是对于我来说效率提高了,因为我把走几千里把东西送过去变成了我只要扔到快递站就行了.然后快递站呢,人家是干买卖的,肯定不想亏钱是不是.所以呢,只有你自己一个快递肯定不会发,而是等待快递够一车的时候,这时候才发货.也就是说,假设说100个人发快递,那么自己做,需要来回跑100次,但是呢这一百个人发快递,快递发一次就够了.对于用户来说,这100个人效率提高了,因为路程从几千米变成了从家到快递站,对于快递站来说,也赚钱了,因为发一次快递成本可能要80块钱,但是因为有一百个人一人给了一块钱,所以自己赚钱了。所以说效率提高了.
说人话,到最后,提高了两个效率个是提高了使用者用户的效率第二是提高了I0流刷新的效率.
1.5.2.3. 缓冲区刷新策略
- 立即刷新
- 行刷新, 最典型的是终端显示.
- 全缓冲. 一般针对普通文件来说.
- 特殊情况: 进程退出 或者 强制刷新.
1.5.2.4. 缓冲区实际存在的体会
两段代码的对比:
int main()
{printf("hello printf\n");fprintf(stdout, "hello fprintf\n");const char* msg = "hello write\n";write(1, msg. strlen(msg));return 0;
}
//./myfile
//hello printf
//hello fprintf
//hello write
//./myfile > log.txt
//hello write
//hello printf
//hello fprintfint main()
{printf("hello printf\n");fprintf(stdout, "hello fprintf\n");const char* msg = "hello write\n";write(1, msg. strlen(msg));fork();return 0;
}
//./myfile
//hello printf
//hello fprintf
//hello write
//./myfile > log.txt
//hello write
//hello printf
//hello fprintf
//hello printf
//hello fprintf为什么会出现上面现象呢? 我们来解释一下.
首先我来解释一下上面第一个为啥打印顺序不一样哈 -> 这跟刷新策略有关.
当我们写入的文件是显示器的时候,是行刷新.行刷新所以printf刷新,fprintf刷新,write刷新但是换成普通文件呢?是全缓冲.printf,fprintf暂时不刷新到操作系统中,而是在用户层的缓存区存着.而write是系统调用直接到操作系统中,当C语言这个进程快结束的时候,才把printf,fprintf刷新到文件中.
然后我再来解释一下第二个为啥多了两行?
说白了后两行是fork(),子进程做的.前面我们说过,子进程直接共享父进程的数据,然后执行到fork的时候,两行数据printf,fprintf还在用户级的缓存区里,因此到最后两个进程结束的时候都要刷新到操作系统,所以说就刷新了两次咯.
将缓冲区添加到自己写的 shell 中去:
略.