【LUT技术专题】带语义的图像自适应4DLUT

带语义的图像自适应4DLUT: 4D LUT: Learnable Context-Aware 4D Lookup Table for Image Enhancement(2023 TIP)
- 专题介绍
- 一、研究背景
- 二、4DLUT方法
- 2.1 Context map
- 2.2 Parameter Encoder
- 2.3 4D LUTs Fusion
- 2.4 Quadrilinear Interpolation以及损失函数
- 三、实验结果
- 四、总结
本文将围绕《4D LUT: Learnable Context-Aware 4D Lookup Table for Image Enhancement》展开完整解析。该研究针对 3DLUT 在局部处理效果上的局限性,提出优化方案。其核心亮点在于:通过引入图像上下文编码器提取上下文信息,并将该信息作为额外通道与原图组成 4 通道输入,从而使 4DLUT 能够基于上下文感知实现图像增强。参考资料如下:
[1]. 论文地址
[2]. 代码地址
专题介绍
Look-Up Table(查找表,LUT)是一种数据结构(也可以理解为字典),通过输入的key来查找到对应的value。其优势在于无需计算过程,不依赖于GPU、NPU等特殊硬件,本质就是一种内存换算力的思想。LUT在图像处理中是比较常见的操作,如Gamma映射,3D CLUT等。
近些年,LUT技术已被用于深度学习领域,由SR-LUT启发性地提出了模型训练+LUT推理的新范式。
本专题旨在跟进和解读LUT技术的发展趋势,为读者分享最全最新的LUT方法,欢迎一起探讨交流,对该专题感兴趣的读者可以订阅本专栏第一时间看到更新。
系列文章如下:
【1】SR-LUT
【2】Mu-LUT
【3】SP-LUT
【4】RC-LUT
【5】EC-LUT
【6】SPF-LUT
【7】Dn-LUT
【8】Tiny-LUT
【9】3D-LUT
一、研究背景
前面有讲到3D-LUT的局部表现不佳,需要搭配local tone mapping才能更好的使用,如下图所示。

本篇文章针对性地解决了这类问题,其提出的可学习上下文感知 4DLUT 方法能够实现每张图像中不同内容的自适应增强。作者通过图示直观诠释了这一核心机制。

可以看到图1(a)中,图像中的天空(橙色)和海洋(蓝色),他们的RGB值相同,在3DLUT的方法框架下输出的结果是一样的,但实际上他们应该用不同的变换来进行调整,使其变得更蓝和更绿。图1(b)中可以看到4DLUT额外引入了一个context map来实现这个4DLUT的输入,在这个情况下,可以做到对天空和海洋实现不同效果的增强,图(c)是跟3DLUT的效果对比,可以看到4DLUT局部的图像效果更好,注意天空和海洋的部分。
主要的贡献点如下:
1)4DLUT是第一个在图像增强中将查找表架构扩展到4D空间的方法,该方法实现了与内容相关的图像增强,并且在这个过程中不会显著增加计算成本。
2)大量的实验表明,在多个广泛使用的图像增强基准测试中,提出的4DLUT可以获得更准确的结果,并显著优于现有的sota方法。
二、4DLUT方法
方法图如下所示,整体流程可以分为4步:

- 首先使用上下文编码器(Context Encoder)通过端到端学习从输入图像生成表示像素级类别的上下文映射。
- 同时,利用参数编码器(Parameter Encoder)生成图像自适应系数,用于融合可学习的预定义基础4DLUTs(Basis 4D LUTs)。
- 然后基于参数编码器的输出,使用4D LUTs融合模块(4D LUTS Fusion)将可学习的基础4DLUTs整合成最终具有更多增强功能的上下文感知4D LUT。
- 最后,利用组合context map的RGBC通道图像使用4DLUT进行插值得到增强的图像。
2.1 Context map
上下文编码器能够在目标函数的约束下,以可学习的方式自适应生成与内容相关的上下文映射。作者使用一系列的残差块来构成这个编码器。这个网络结构在后续代码讲解中详细介绍。本质作用就是提取跟图像内容相关的信息并将其压缩为一个标量,这个作为context通道可以一并添加进原始的RGB通道中进行后续4DLUT的查找。用公式表示为:
C = E c o n t e x t ( I i n p u t ) C=E_{context}(I_{input}) C=Econtext(Iinput)
2.2 Parameter Encoder
参数编码器用于提取一组图像自适应的参数,这些参数用于多个基础4DLUT的融合,作用跟前面讲过的3DLUT是一样的,只不过4DLUT这里做了一些改进,添加了更多的加权系数以及偏差项。公式表示如下:
W , B = E p a r a m ( I I n p u t ) W,B=E_{param}(I_{Input}) W,B=Eparam(IInput)其中 W W W和 B B B的维度分别是 3 N l u t 2 3N_{lut}^2 3Nlut2和 N l u t N_{lut} Nlut, N l u t N_{lut} Nlut是基础4DLUT的个数。网络结构在后续代码讲解中详细讲解。
2.3 4D LUTs Fusion
以下是利用Parameter Encoder计算得到的参数融合多个基础的4DLUT的过程,融合后可以得到最后用于增强的4DLUT。融合过程如下式所示,以4DLUT的一个输出为例:
ψ ^ r = ∑ n = 1 N l u t ( w n ψ n r + w ( N l u t + n ) ψ n g + w ( 2 N l u t + n ) ψ n b + b n ) \begin{aligned} \hat{\psi}^{r} & =\sum_{n=1}^{N_{l u t}}\left(w_{n} \psi_{n}^{r}+w_{\left(N_{l u t}+n\right)} \psi_{n}^{g}\right. \\ & \left.+w_{\left(2 N_{l u t}+n\right)} \psi_{n}^{b}+b_{n}\right) \end{aligned} ψ^r=n=1∑Nlut(wnψnr+w(Nlut+n)ψng+w(2Nlut+n)ψnb+bn)其中, ψ ^ r \hat{\psi}^{r} ψ^r代表红色颜色空间的LUT, ψ n r \psi_{n}^{r} ψnr代表原红色颜色空间的LUT, ψ n g \psi_{n}^{g} ψng代表原绿色颜色空间的LUT, ψ n b \psi_{n}^{b} ψnb代表原蓝色颜色空间的LUT, w n w_{n} wn、 w N l u t + n w_{N_{lut}+n} wNlut+n、 w 2 N l u t + n w_{2N_{lut}+n} w2Nlut+n代表其相关的权重,权重的增加可以允许不同的色彩空间相互作用和融合,从而产生更合适的色温(类似于白平衡), b n b_n bn是一个偏置项,可以自适应调整图像的亮度,这种融合方式可以使得4DLUT有更优越的增强能力。相比于3DLUT,权重更多了,其加入了通道间的影响且补充了偏置。
2.4 Quadrilinear Interpolation以及损失函数
四次插值过程并不复杂,可基于3DLUT进一步向外推导。3DLUT的插值是寻找最近的8个点,而4DLUT是寻找最近的16个点。计算的公式如下:
r out ( x , y , z , u ) = ( 1 − o x ) ( 1 − o y ) ( 1 − o z ) ( 1 − o u ) r out ( i , j , k , l ) = o x ( 1 − o y ) ( 1 − o z ) ( 1 − o u ) r out ( i + 1 , j , k , l ) = ( 1 − o x ) o y ( 1 − o z ) ( 1 − o u ) r out ( i , j + 1 , k , l ) = ( 1 − o x ) ( 1 − o y ) o z ( 1 − o u ) r out ( i , j , k + 1 , l ) = ( 1 − o x ) ( 1 − o y ) ( 1 − o z ) o u r out ( i , j , k , l + 1 ) = o x o y ( 1 − o z ) ( 1 − o u ) r out ( i + 1 , j + 1 , k , l ) = ( 1 − o x ) o y o z ( 1 − o u ) r out ( i , j + 1 , k + 1 , l ) = ( 1 − o x ) ( 1 − o y ) o z o u r out ( i , j , k + 1 , l + 1 ) = o x ( 1 − o y ) o z ( 1 − o u ) r out ( i + 1 , j , k + 1 , l ) = o x ( 1 − o y ) ( 1 − o z ) o u r out ( i + 1 , j , k , l + 1 ) = ( 1 − o x ) o y ( 1 − o z ) o u r out ( i , j + 1 , k , l + 1 ) = o x o y o z ( 1 − o u ) r out ( i + 1 , j + 1 , k + 1 , l ) = ( 1 − o x ) o y o z o u r out ( i , j + 1 , k + 1 , l + 1 ) = o x o y ( 1 − o z ) o u r out ( i + 1 , j + 1 , k , l + 1 ) = o x ( 1 − o y ) o z o u r out ( i + 1 , j , k + 1 , l + 1 ) + o x o y o z o u r out ( i + 1 , j + 1 , k + 1 , l + 1 ) \begin{aligned} r_{\text {out }}^{(x, y, z, u)} & =\left(1-o_{x}\right)\left(1-o_{y}\right)\left(1-o_{z}\right)\left(1-o_{u}\right) r_{\text {out }}^{(i, j, k, l)} \\ & =o_{x}\left(1-o_{y}\right)\left(1-o_{z}\right)\left(1-o_{u}\right) r_{\text {out }}^{(i+1, j, k, l)} \\ & =\left(1-o_{x}\right) o_{y}\left(1-o_{z}\right)\left(1-o_{u}\right) r_{\text {out }}^{(i, j+1, k, l)} \\ & =\left(1-o_{x}\right)\left(1-o_{y}\right) o_{z}\left(1-o_{u}\right) r_{\text {out }}^{(i, j, k+1, l)} \\ & =\left(1-o_{x}\right)\left(1-o_{y}\right)\left(1-o_{z}\right) o_{u} r_{\text {out }}^{(i, j, k, l+1)} \\ & =o_{x} o_{y}\left(1-o_{z}\right)\left(1-o_{u}\right) r_{\text {out }}^{(i+1, j+1, k, l)} \\ & =\left(1-o_{x}\right) o_{y} o_{z}\left(1-o_{u}\right) r_{\text {out }}^{(i, j+1, k+1, l)} \\ & =\left(1-o_{x}\right)\left(1-o_{y}\right) o_{z} o_{u} r_{\text {out }}^{(i, j, k+1, l+1)} \\ & =o_{x}\left(1-o_{y}\right) o_{z}\left(1-o_{u}\right) r_{\text {out }}^{(i+1, j, k+1, l)} \\ & =o_{x}\left(1-o_{y}\right)\left(1-o_{z}\right) o_{u} r_{\text {out }}^{(i+1, j, k, l+1)} \\ & =\left(1-o_{x}\right) o_{y}\left(1-o_{z}\right) o_{u} r_{\text {out }}^{(i, j+1, k, l+1)} \\ & =o_{x} o_{y} o_{z}\left(1-o_{u}\right) r_{\text {out }}^{(i+1, j+1, k+1, l)} \\ & =\left(1-o_{x}\right) o_{y} o_{z} o_{u} r_{\text {out }}^{(i, j+1, k+1, l+1)} \\ & =o_{x} o_{y}\left(1-o_{z}\right) o_{u} r_{\text {out }}^{(i+1, j+1, k, l+1)} \\ & =o_{x}\left(1-o_{y}\right) o_{z} o_{u} r_{\text {out }}^{(i+1, j, k+1, l+1)} \\ & +o_{x} o_{y} o_{z} o_{u} r_{\text {out }}^{(i+1, j+1, k+1, l+1)} \end{aligned} rout (x,y,z,u)=(1−ox)(1−oy)(1−oz)(1−ou)rout (i,j,k,l)=ox(1−oy)(1−oz)(1−ou)rout (i+1,j,k,l)=(1−ox)oy(1−oz)(1−ou)rout (i,j+1,k,l)=(1−ox)(1−oy)oz(1−ou)rout (i,j,k+1,l)=(1−ox)(1−oy)(1−oz)ourout (i,j,k,l+1)=oxoy(1−oz)(1−ou)rout (i+1,j+1,k,l)=(1−ox)oyoz(1−ou)rout (i,j+1,k+1,l)=(1−ox)(1−oy)ozourout (i,j,k+1,l+1)=ox(1−oy)oz(1−ou)rout (i+1,j,k+1,l)=ox(1−oy)(1−oz)ourout (i+1,j,k,l+1)=(1−ox)oy(1−oz)ourout (i,j+1,k,l+1)=oxoyoz(1−ou)rout (i+1,j+1,k+1,l)=(1−ox)oyozourout (i,j+1,k+1,l+1)=oxoy(1−oz)ourout (i+1,j+1,k,l+1)=ox(1−oy)ozourout (i+1,j,k+1,l+1)+oxoyozourout (i+1,j+1,k+1,l+1)非常的长,但是实际上是存在规律的,即通过采样最近的16个顶点,每个点的权重跟到各个维度距离成反比,即越近采样权重越大。
4DLUT采用的损失函数跟3DLUT是一样的,包含以下三类损失:
-
4D smooth regularization:包含参数的正则损失和LUT的TV损失。
L s lut = ∑ ρ ∈ { r , g , b } i , j , k , l = 0 N bin − 1 ( ∥ P out ( i + 1 , j , k , l ) − P out ( i , j , k , l ) ∥ 2 + ∥ P out ( i , j + 1 , k , l ) − P out ( i , j , k , l ) ∥ 2 + ∥ P out ( i , j , k , l + 1 ) − P out ( i , j , k , l ) ∥ 2 + ∥ P out ( i , j , k + 1 , l ) − P out ( i , j , k , l ) ∥ 2 ) L_{s}^{\text{lut}} = \sum_{\substack{\rho \in \{r,g,b\} \\ i,j,k,l=0}}^{N_{\text{bin}} - 1} \bigg( \bigl\| P_{\text{out}}^{(i+1,j,k,l)} - P_{\text{out}}^{(i,j,k,l)} \bigr\|^2 + \bigl\| P_{\text{out}}^{(i,j+1,k,l)} - P_{\text{out}}^{(i,j,k,l)} \bigr\|^2 + \bigl\| P_{\text{out}}^{(i,j,k,l+1)} - P_{\text{out}}^{(i,j,k,l)} \bigr\|^2 + \bigl\| P_{\text{out}}^{(i,j,k+1,l)} - P_{\text{out}}^{(i,j,k,l)} \bigr\|^2 \bigg) Lslut=ρ∈{r,g,b}i,j,k,l=0∑Nbin−1( Pout(i+1,j,k,l)−Pout(i,j,k,l) 2+ Pout(i,j+1,k,l)−Pout(i,j,k,l) 2+ Pout(i,j,k,l+1)−Pout(i,j,k,l) 2+ Pout(i,j,k+1,l)−Pout(i,j,k,l) 2) L s coe = ∑ n = 1 N w ∥ w n ∥ 2 + ∑ m = 1 N b ∥ b n ∥ 2 L_s^{\text{coe}} = \sum_{n=1}^{N_w} \| w_n \|^2 + \sum_{m=1}^{N_b} \| b_n \|^2 Lscoe=n=1∑Nw∥wn∥2+m=1∑Nb∥bn∥2 L s = L s lut + L s coe L_s = L_s^{\text{lut}} + L_s^{\text{coe}} Ls=Lslut+Lscoe
这里的逻辑跟3DLUT是一样的,只不过多了1个维度,因此项数会多一些。 -
4D monotonicity regularization:4DLUT的单调性损失。 L m = ∑ i , j , k , l ρ ∈ { r , g , b } [ g ( P out ( i , j , k , l ) − P out ( i + 1 , j , k , l ) ) + g ( P out ( i , j , k , l ) − P out ( i , j + 1 , k , l ) ) + g ( P out ( i , j , k , l ) − P out ( i , j , k , l + 1 ) ) + g ( P out ( i , j , k , l ) − P out ( i , j , k + 1 , l ) ) ] L_m = \sum_{\substack{i,j,k,l \\ \rho \in \{r,g,b\}}} \bigg[ g\bigl(P_{\text{out}}^{(i,j,k,l)} - P_{\text{out}}^{(i+1,j,k,l)}\bigr) + g\bigl(P_{\text{out}}^{(i,j,k,l)} - P_{\text{out}}^{(i,j+1,k,l)}\bigr) + g\bigl(P_{\text{out}}^{(i,j,k,l)} - P_{\text{out}}^{(i,j,k,l+1)}\bigr) + g\bigl(P_{\text{out}}^{(i,j,k,l)} - P_{\text{out}}^{(i,j,k+1,l)}\bigr) \bigg]_{\substack{ }} Lm=i,j,k,lρ∈{r,g,b}∑[g(Pout(i,j,k,l)−Pout(i+1,j,k,l))+g(Pout(i,j,k,l)−Pout(i,j+1,k,l))+g(Pout(i,j,k,l)−Pout(i,j,k,l+1))+g(Pout(i,j,k,l)−Pout(i,j,k+1,l))]跟3DLUT一样,这里的 g g g是relu函数,即必须要满足单调性的约束,如果索引增大而值没有增大会有损失,否则为0。
-
成对数据的L2重建损失: L r = 1 N b s ∑ 1 N b s ( I G T − I o u t p u t ) 2 L_r = \frac{1}{N_{bs}} \sum_{1}^{N_{bs}} (I_{GT} - I_{output})^2 Lr=Nbs11∑Nbs(IGT−Ioutput)2
最后损失的总和表示为: L total = L r + α s L s + α m L m L_{\text{total}} = L_r + \alpha_s L_s + \alpha_m L_m Ltotal=Lr+αsLs+αmLm,其中 L r L_r Lr代表程度数据的重建损失, L s L_s Ls代表平滑损失, L m L_m Lm代表单调性损失, α \alpha α是他们的权重。
三、实验结果
首先讲一下定量实验,作者在两个数据集上进行了实验,因为作者将查找表扩展为4D,因此都取得了sota结果。
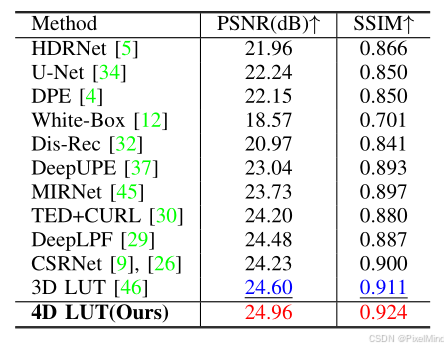
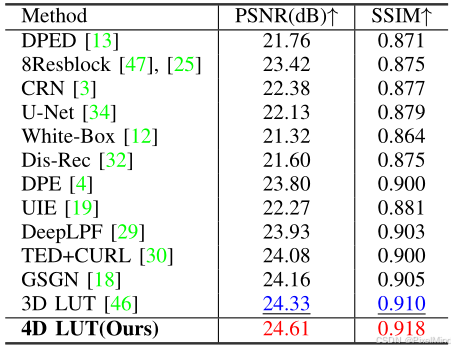 .
.
作者为了进一步验证4DLUT的泛化能力,在另一个更大规模的人像照片修图数据集上进行了实验,如下表所示。

可以看到4DLUT在与其他方法的对比中是有明显优势的,在耗时和参数量的对比中,耗时增加了3-4ms,参数量增大了400k,但整体还是一个极其轻量和实时的算法。
接下来是定性实验,对比效果图如下:


在多个数据集上的表现都是最好的。
最后是消融实验,包含两个讨论,一个是context encoder和param encoder的必要性,另一个是损失的必要性。
-
网络结构:作者做了以下的实验,其中CE是context encoder,而PE是param encoder,结果显而易见。

这里作者还做了效果图进行对比。

-
损失:损失的结论跟3DLUT基本一致,损失都很重要。

作者后续进行了更多的讨论环节,针对于4DLUT的其他变量。
-
上下文的有效性:作者将context图做了可视化。

使用了8种不同的颜色将生成的context图做可视化,可以看到生成的上下文图划分开了具有不同语义差距的区域,针对于红框的区域,3DLUT增强的结果就过于惨淡,而4DLUT可以根据context图有更好的效果。 -
4DLUT切分的bin数:这个应该是指4DLUT的量化个数,如下所示。

自然量化个数越大,效果会越好,但是这样会增大LUT的尺寸,同时也会使得结果更加过拟合,作者最后还是选择33。 -
LUT的个数:实验如下所示。

自然也是越大越好,但是越大带来更多的计算压力和尺寸压力,作者最后选择3个。 -
损失的权重大小:实验如下所示。
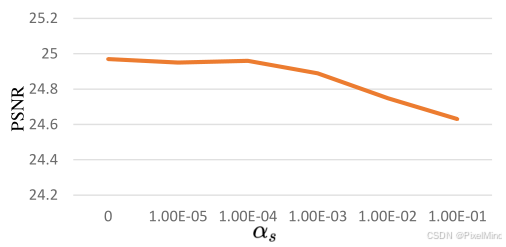
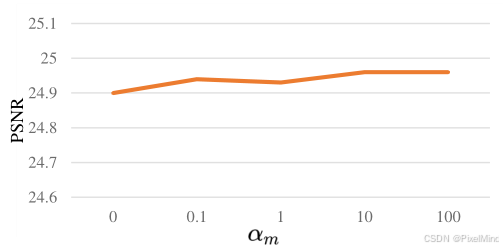 .
.
跟3DLUT的结论基本一致,最后作者选择的大小也是一样的,平滑和单调分别是1e-4和10。
四、总结
本文提出了一个4DLUT,将3DLUT扩充了一个维度,引入了一个上下文的信息,使得该方法可以对图像中不同语义的区域采用不同的增强,算是解决了3DLUT的部分不足。
代码部分将会单起一篇进行解读。(未完待续)
感谢阅读,欢迎留言或私信,一起探讨和交流,如果对你有帮助的话,也希望可以给博主点一个关注,谢谢。