HNSW - 分层可导航小世界
背景
上一篇《商家平台AI智能搜索工程实践》提到向量数据库索引使用的是HNSW,具体的相关历史可自己了解,本文主要尝试用最通用的语言阐述HNSW原理和数据结构。
基础技术
HNSW 最大的两项基本技术:概率跳跃表和可导航小世界图。
概率跳跃表
概率跳跃表像排序数组一样快速搜索,同时使用链表结构可以轻松(且快速)地插入新元素(这是排序数组无法实现的)。
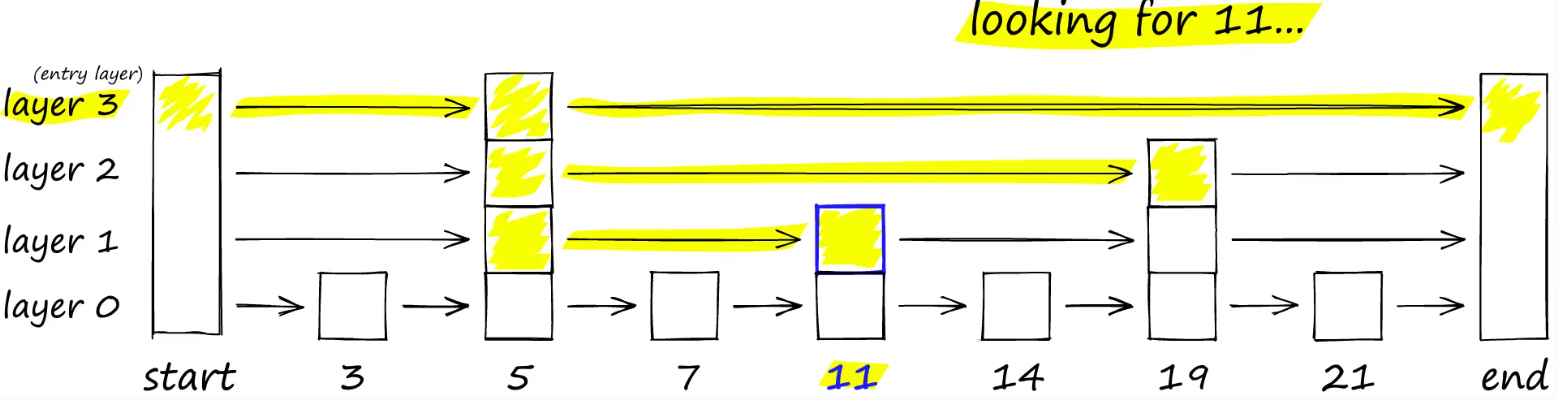
跳过列表的工作原理是构建多层链表。在第一层,我们找到跳过许多中间节点/顶点的链接。随着层级的下降,每个链接的“跳过”次数会减少。
要搜索跳跃表,我们从“跳跃”最长的最高层开始,沿着边缘向右(下方)移动。如果我们发现当前节点的“键”大于我们要搜索的键——我们就知道我们已经超出了目标,因此我们向下移动到下一层的上一个节点。
可导航小世界图
HNSW 继承了相同的分层格式,最高层的边较长(用于快速搜索),较低层的边较短(用于准确搜索)。
可导航小世界(NSW) 图采用一个邻近图,构建它时同时包含长距离和短距离链接,那么搜索时间就能降低到 (多/) 对数复杂度。
图中的每个顶点都与其他几个顶点相连。我们将这些相连的顶点称为“朋友”,每个顶点都维护一个“朋友”列表,构成了我们的图。
在搜索 NSW 图时,我们从一个预定义的入口点开始。该入口点连接到几个附近的顶点。我们确定这些顶点中哪个最接近我们的查询向量,然后移动到那里。
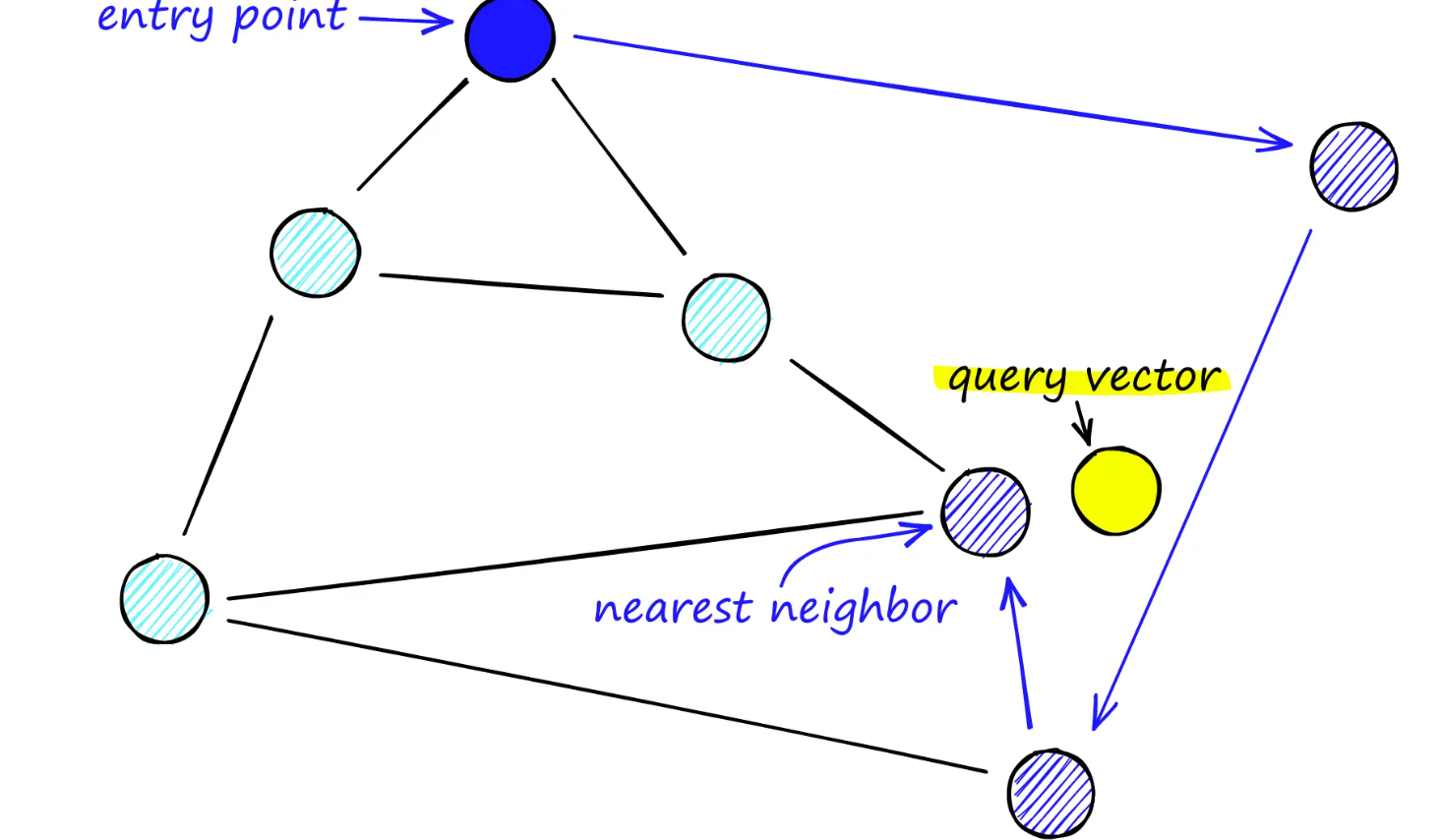
我们重复贪婪路由搜索过程,通过识别每个好友列表中最近的相邻顶点,从一个顶点移动到另一个顶点。最终,我们将找不到比当前顶点更近的顶点——这是一个局部最小值,并作为我们的停止条件。
可导航小世界模型被定义为任何使用贪婪路由且具有(多/)对数复杂度的网络。当图不可导航时,贪婪路由的效率对于较大的网络(1-10K+ 个顶点)会失效。
路由(字面意思是我们在图中的路径)由两个阶段组成。首先是“缩小”阶段,穿过低度顶点(度是指顶点的链接数);然后是“放大”阶段,穿过更高度顶点。
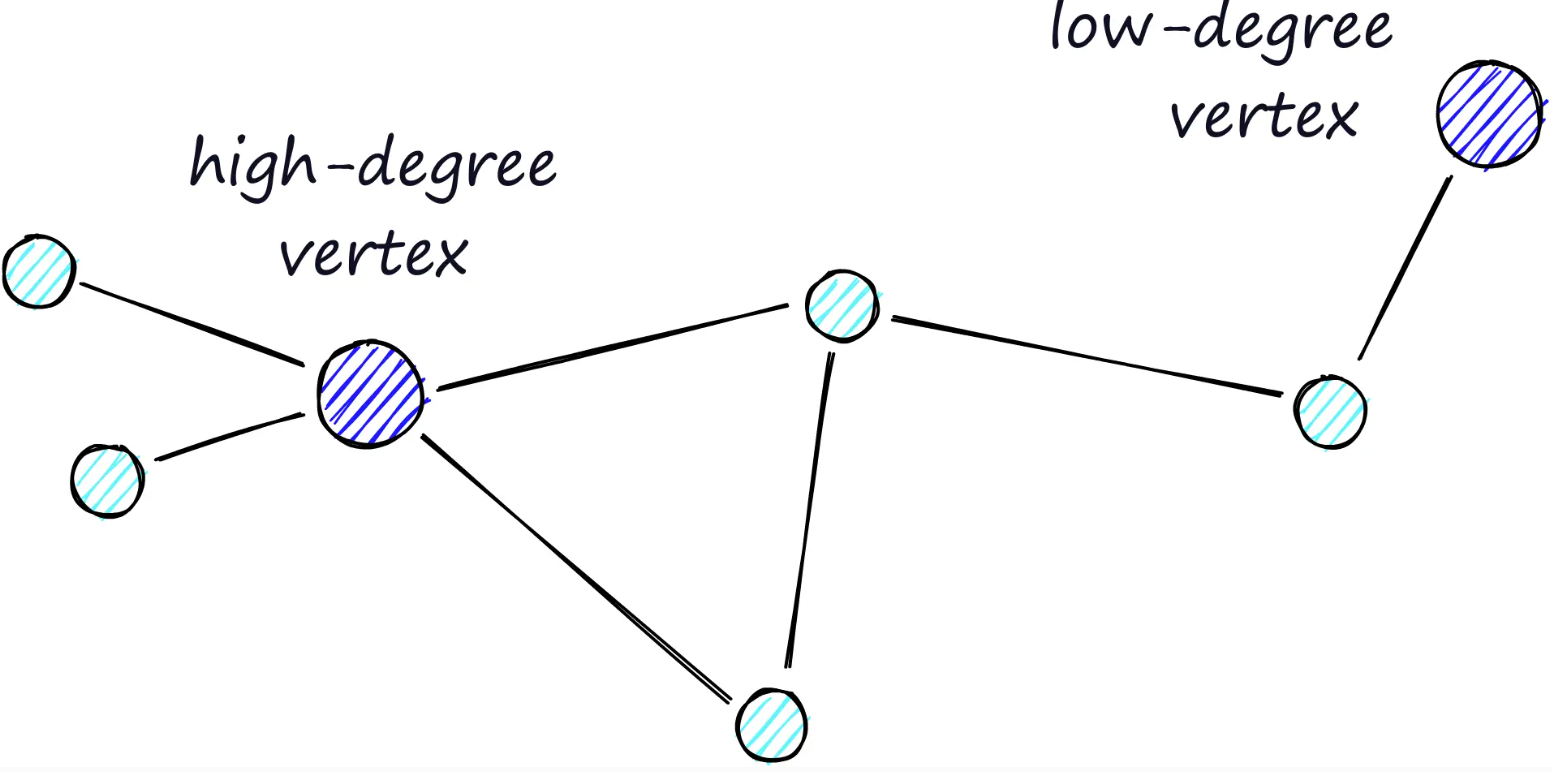
高度顶点具有许多链接,而低度顶点具有很少的链接。
我们的停止条件是在当前顶点的好友列表中找不到更近的顶点。因此,在缩小阶段(链接较少,找到更近顶点的可能性较小),我们更有可能陷入局部最小值并过早停止。
为了最大限度地降低提前停止的可能性(并提高召回率),我们可以增加顶点的平均度数,但这会增加网络复杂度(以及搜索时间)。因此,我们需要在召回率和搜索速度之间平衡顶点的平均度数。
另一种方法是从高维顶点开始搜索(先放大)。对于NSW,这确实提高了低维数据的性能。我们将看到,这也是HNSW结构中的一个重要因素。
HNSW 是 NSW 的自然演变,它借鉴了 Pugh 概率跳跃表结构的多层层次的灵感。
为 NSW 添加层级结构会生成一个图表,其中链接被分散在不同层级上。顶层包含最长的链接,底层包含最短的链接。
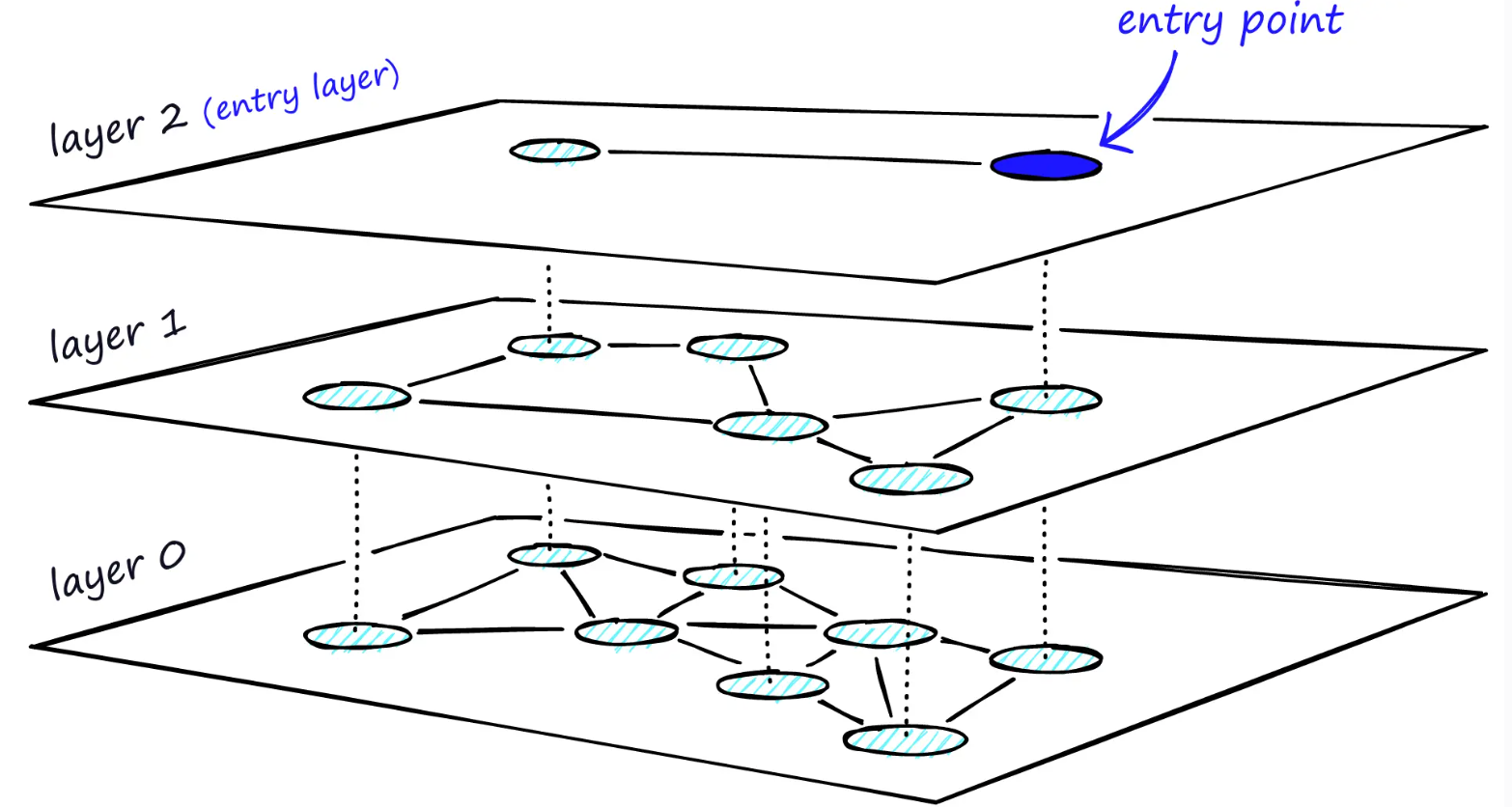
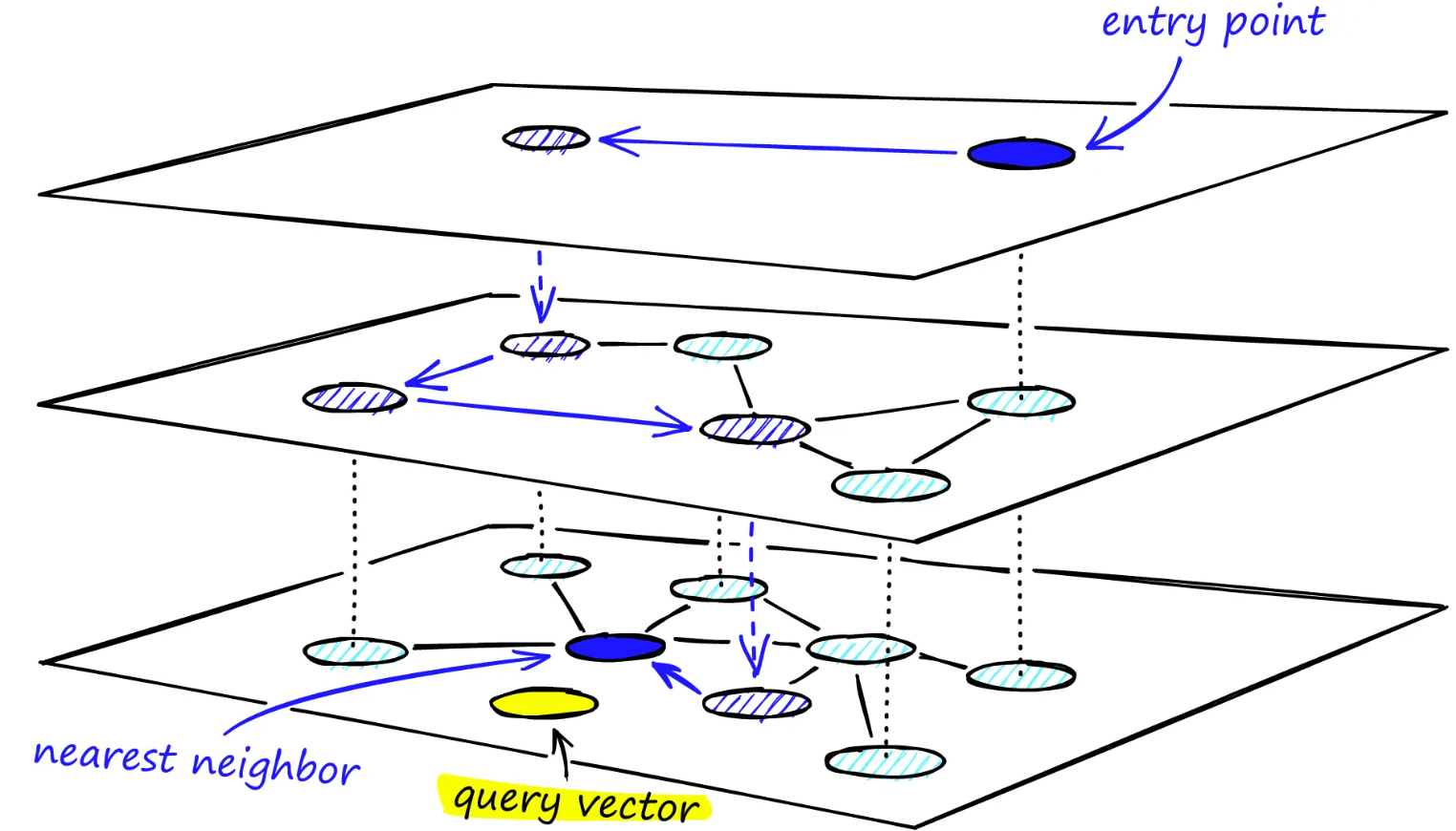
HNSW 的分层图,顶层是我们的入口点,仅包含最长的链接,随着我们向下移动层,链接长度变得更短且更多。
在搜索过程中,我们进入顶层,在那里找到最长的链接。这些顶点往往是度数较高的顶点(链接跨越多个层),这意味着我们默认从NSW 描述的放大阶段开始。
我们像在 NSW 中一样遍历每一层的边,贪婪地移动到最近的顶点,直到找到局部最小值。与 NSW 不同的是,此时,我们移动到较低层的当前顶点,并重新开始搜索。重复此过程,直到找到底层(即第 0 层)的局部最小值。
在构建图的过程中,向量会被逐个迭代插入。层数由参数L表示。向量插入到给定层的概率由概率函数给出,该概率函数经“层级乘数”m_L归一化,其中m_L = ~0表示向量仅插入到第 0 层。
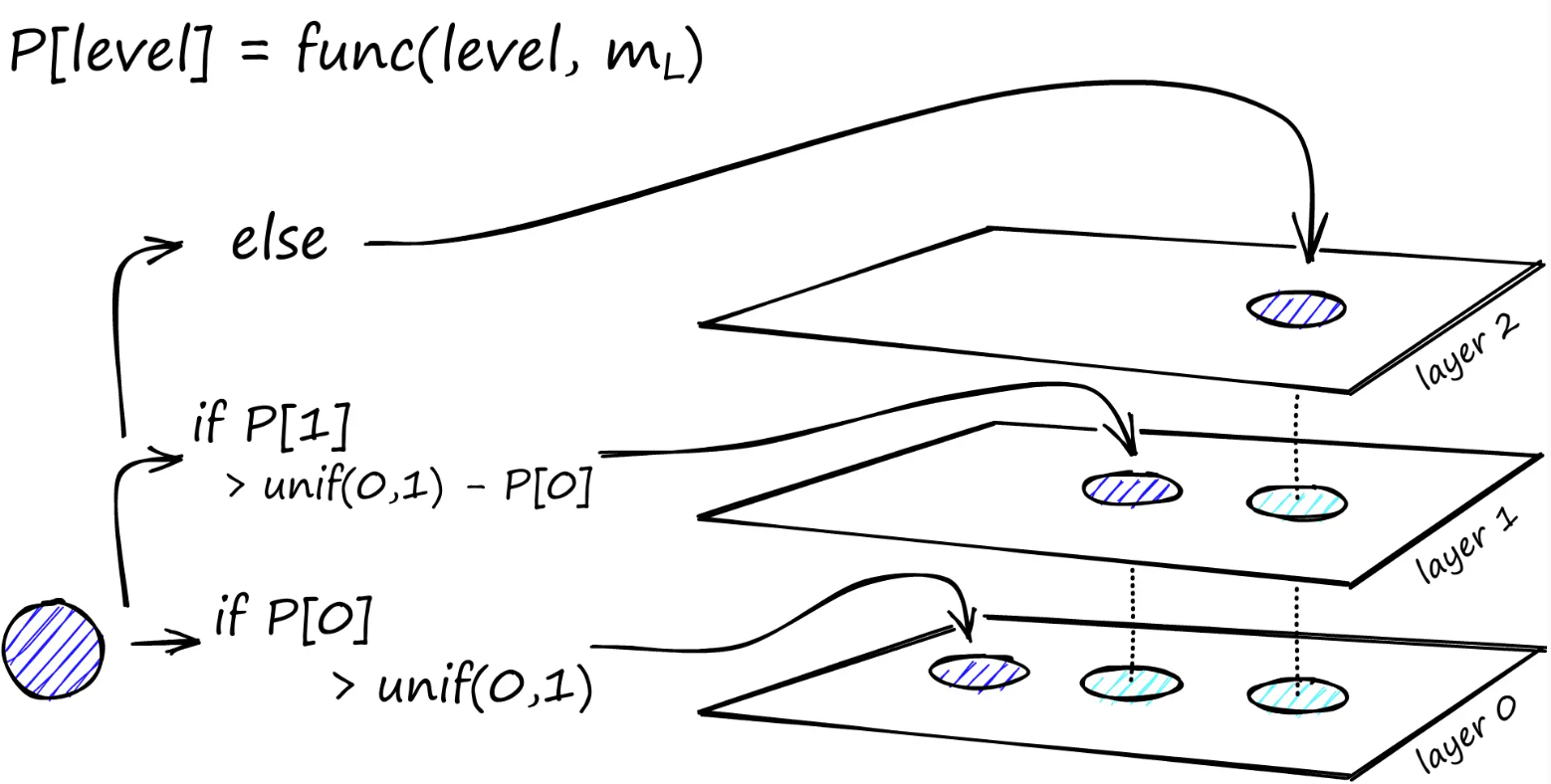
概率函数在每一层(第 0 层除外)重复执行。该向量被添加到其插入层及其下方的每一层。
HNSW 的创建者发现,当我们最小化跨层共享邻居的重叠时,可以获得最佳性能。降低 m_L有助于最小化重叠(将更多向量推送到第 0 层),但这会增加搜索过程中的平均遍历次数。因此,我们使用一个能够平衡两者的m_L值。此最佳值的经验法则是 [1]。1/ln(M)
图的构建从顶层开始。输入图后,算法贪婪地遍历边,找到插入向量q的ef个最近邻——此时ef = 1。
找到局部最小值后,它会向下移动到下一层(就像搜索过程中所做的那样)。这个过程不断重复,直到到达我们选择的插入层。从这里开始构建的第二阶段。
ef值增加到(我们设置的参数),意味着将返回更多最近邻。在第二阶段,这些最近邻将成为新插入元素qefConstruction的链接候选,并作为下一层的入口点。
从这些候选对象中添加M 个邻居作为链接——最直接的选择标准是选择最接近的向量。
经过多次迭代后,添加链接时需要考虑另外两个参数。M_max定义顶点可以拥有的最大链接数,M_max0定义相同的链接数,但针对的是第0 层的顶点。
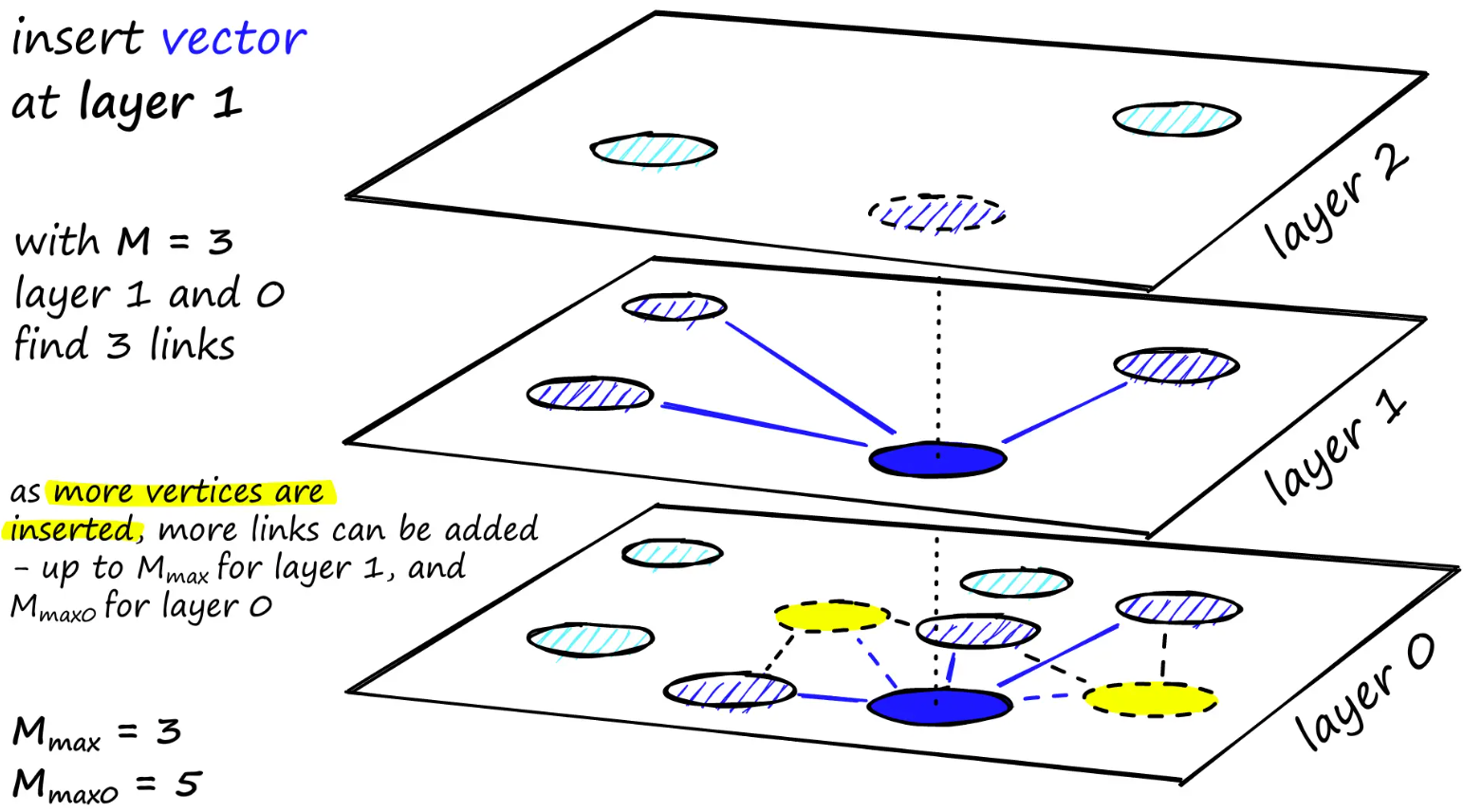
解释分配给每个顶点的链接数以及 M、M_max 和 M_max0 的影响。
插入的停止条件是达到第 0 层的局部最小值。
现在我们已经探索了 HNSW 背后的理论以及它在 Faiss 中的实现方式——让我们看看不同参数对我们的召回、搜索和构建时间以及每个参数的内存使用情况的影响。
我们将修改三个参数:M、、efSearch和efConstruction。
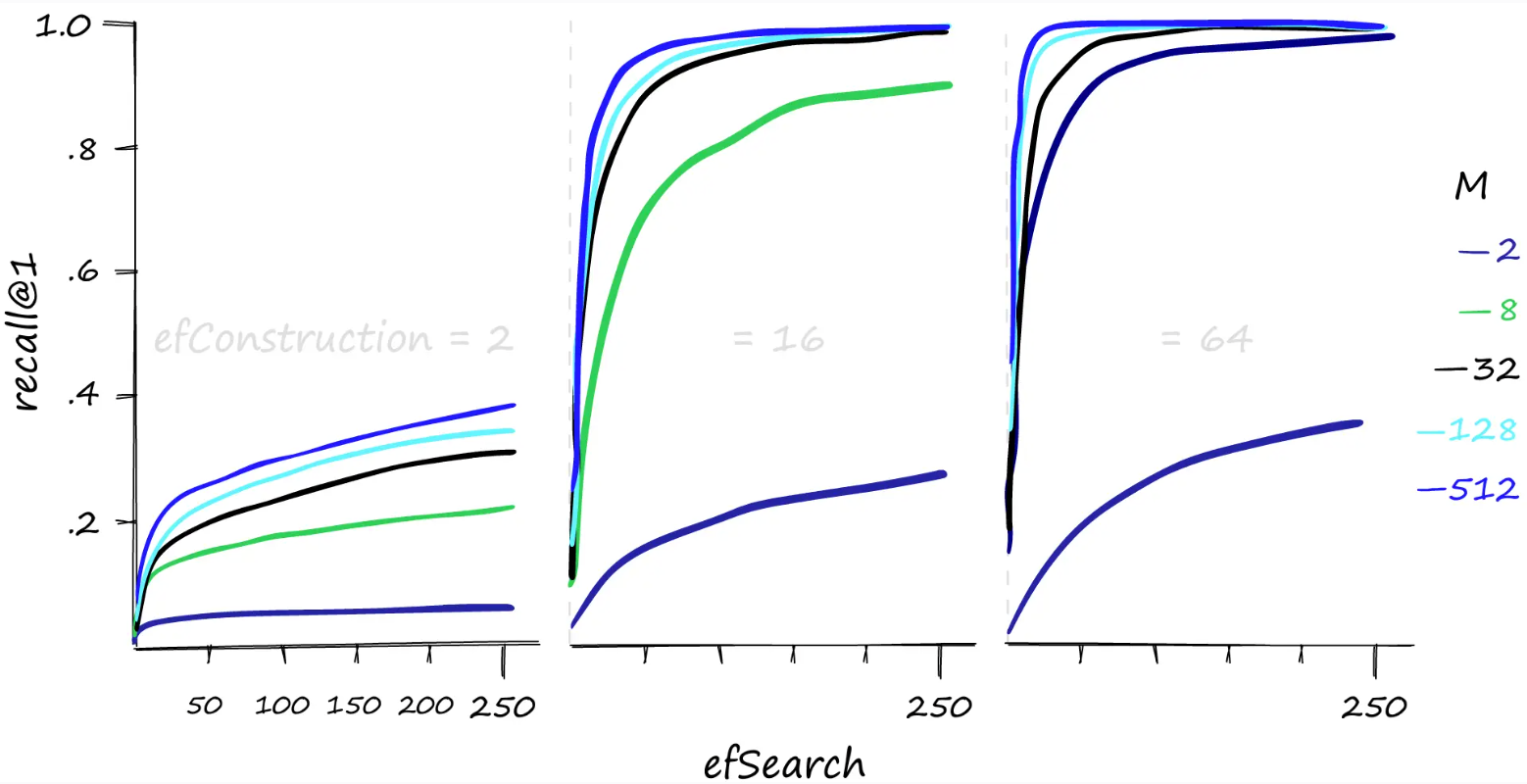
较高的M和efSearch值会对召回率产生很大影响——而且显然efConstruction需要一个合理的值。我们也可以增加 和 值,以在较低的和值efConstruction下实现更高的召回率。MefSearch
然而,这种性能并非免费。与往常一样,我们需要在召回率和搜索时间之间取得平衡——让我们来看看。
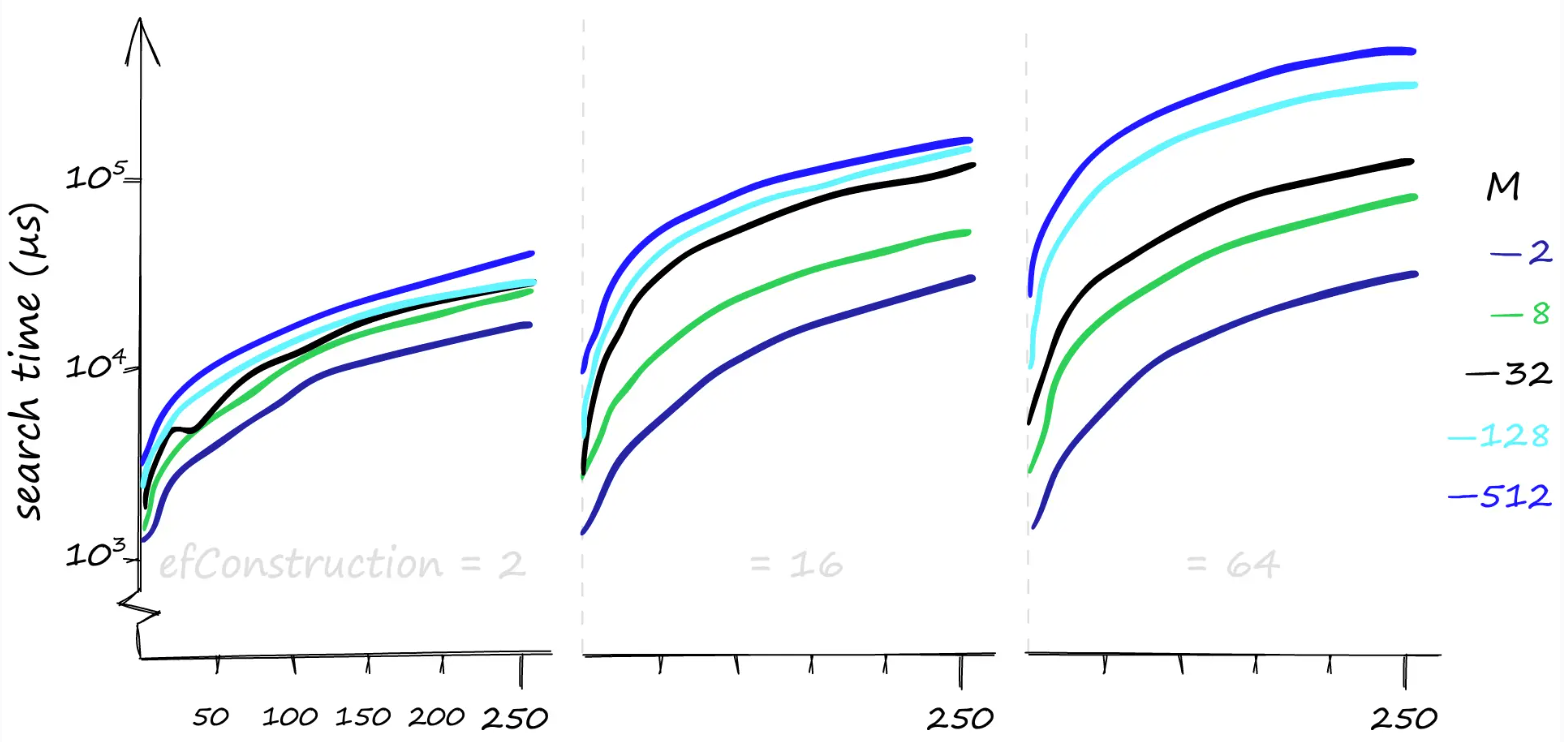
虽然较高的参数值可以提高召回率,但这对搜索时间的影响可能非常显著。这里我们搜索1000相似的向量(xq[:1000]),召回率/搜索时间可能在 80%(1 毫秒)到 100%(50 毫秒)之间变化。如果我们对一个不太好的召回率感到满意,搜索时间甚至可能达到 0.1 毫秒。
当我们使用少量查询进行搜索时,确实efConstruction对搜索时间影响不大。但对于这里1000使用的查询,的微小影响efConstruction就变得非常显著。
如果您认为您的查询量通常较低,efConstruction则这是一个值得增加的参数。它可以提高召回率,而对搜索时间的影响却很小,尤其是在使用较低M值时。
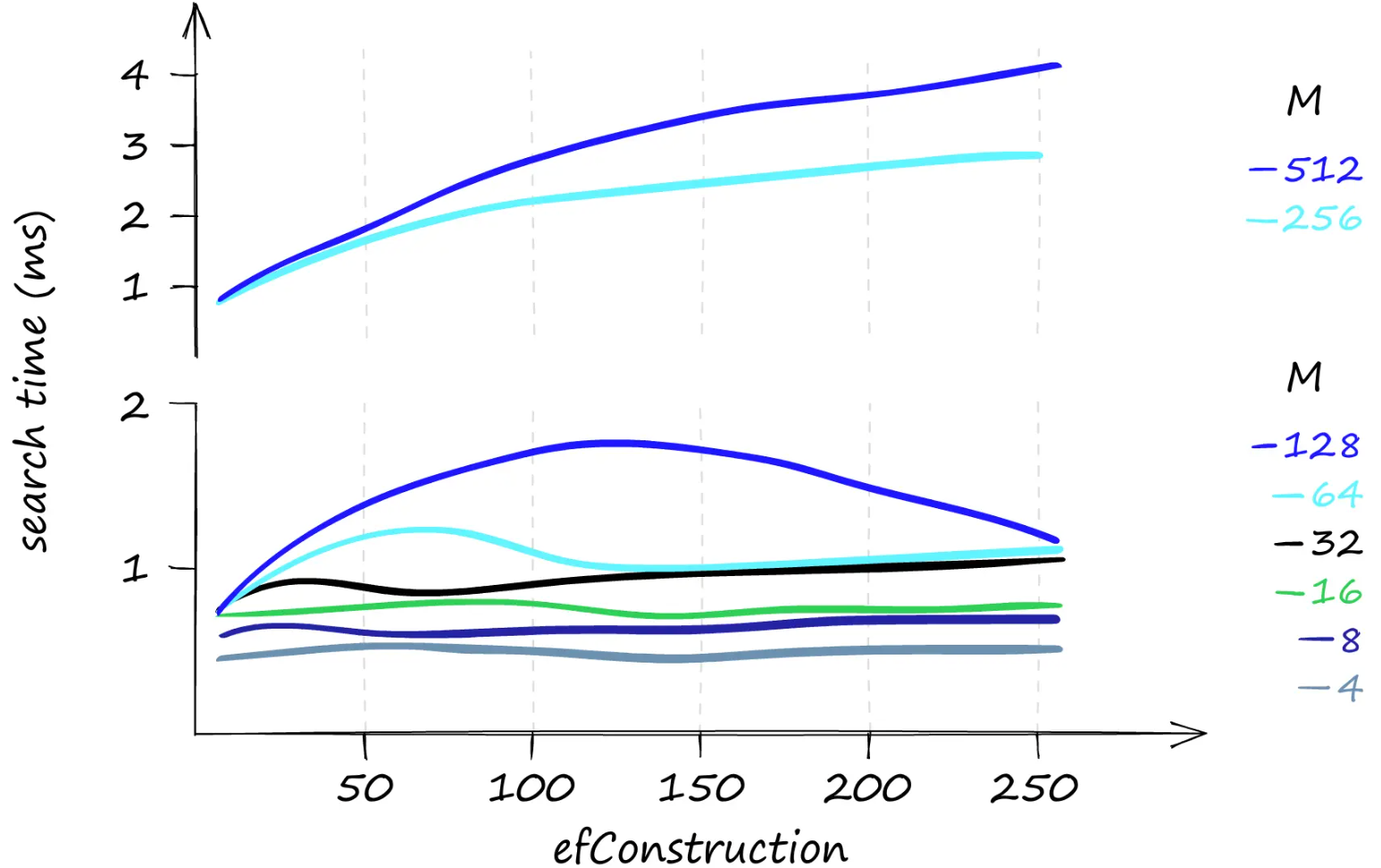
仅搜索一个查询时,efConstruction 和搜索时间。使用较低的 M 值时,对于不同的 efConstruction 值,搜索时间几乎保持不变。
这一切看起来都很棒,但是 HNSW 索引的内存使用情况怎么样呢?这里事情就变得不那么吸引人了。
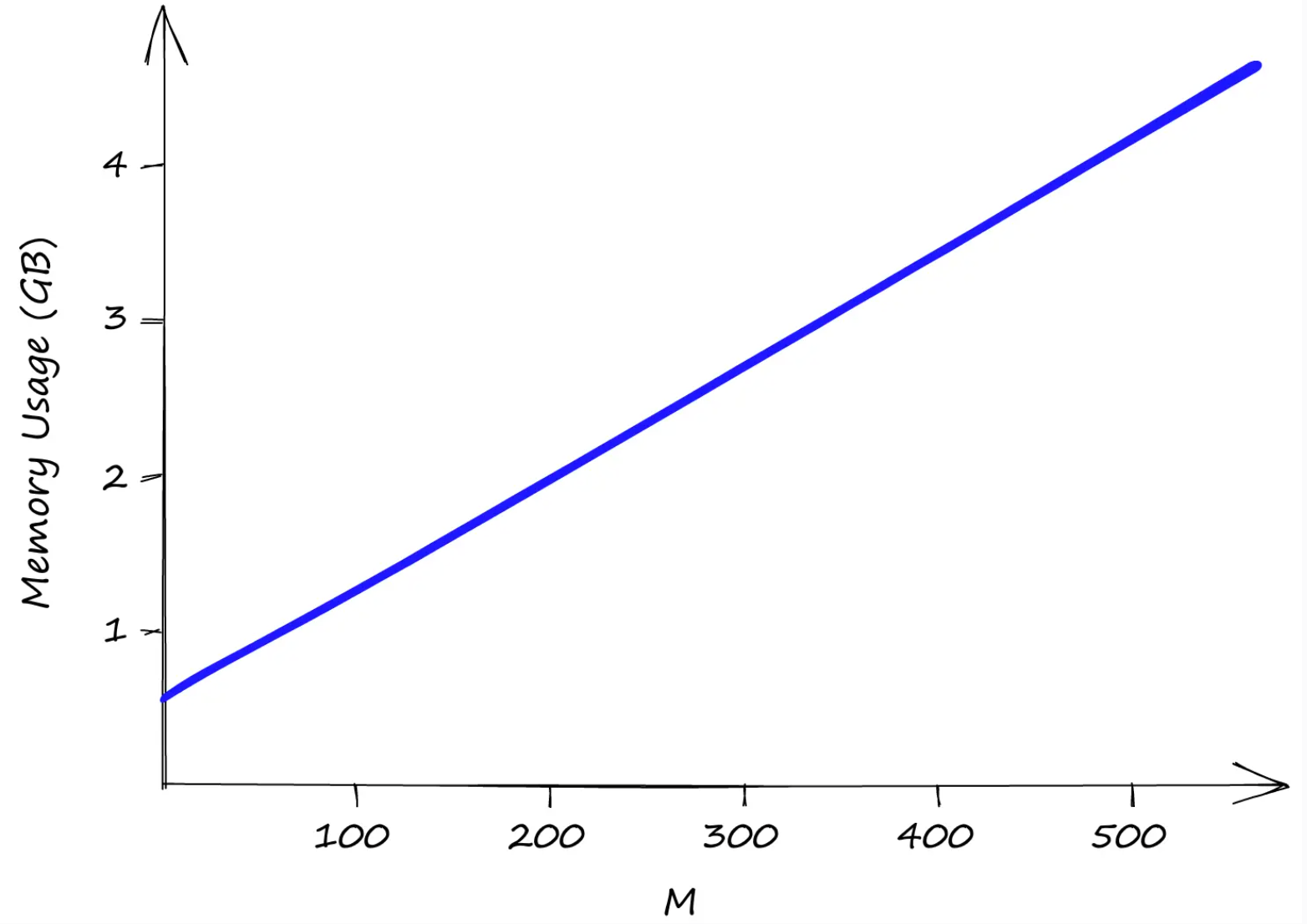
使用我们的 Sift1M 数据集,随着 M 值的增加,内存使用量也随之增加。efSearch 和 efConstruction 对内存使用量没有影响。
和efConstruction都efSearch不会影响索引内存的使用,只剩下M。即使M在 的较低值下2,我们的索引大小也已经超过 0.5GB,在M的情况下则达到了近 5GB 512。
因此,尽管 HNSW 具有令人难以置信的性能,但我们需要权衡其高内存使用率以及由此产生的不可避免的高基础设施成本。
提高内存使用率和搜索速度
就内存利用率而言,HNSW 并非最佳索引。但是,如果这一点很重要,并且无法使用其他索引,我们可以通过使用乘积量化 (PQ)压缩向量来改进它。使用 PQ 会降低召回率并增加搜索时间——但一如既往,ANN 的大部分工作都是在平衡这三个因素。
如果我们想提高搜索速度,也可以!只需在索引中添加一个 IVF 组件即可。
本文就介绍完了用于向量相似性搜索的分层可导航小世界图!现在您已经了解了 HNSW 背后的原理以及如何在 Faiss 中实现它,您可以继续在自己的向量搜索应用程序中测试 HNSW 索引,或者使用像Pinecone或 OpenSearch 这样已经具备向量搜索功能的托管解决方案!
参考
[1] E. Bernhardsson,人工神经网络基准(2021),GitHub
[2] W. Pugh,《跳过列表:平衡树的概率替代方案》(1990 年),《ACM 通讯》,第 33 卷,第 6 期,第 668-676 页
[3] Y. Malkov、D. Yashunin,《使用分层可导航小世界图进行高效稳健的近似最近邻搜索》(2016),《IEEE 模式分析与机器智能学报》
[4] Y. Malkov 等人,近似最近邻搜索小世界方法(2011),国际信息与通信技术与应用会议
[5] Y. Malkov 等人,高维通用度量空间中近似最近邻搜索问题的可扩展分布式算法(2012),相似性搜索与应用,第 132-147 页
[6] Y. Malkov 等人,基于可导航小世界图的近似最近邻算法(2014),信息系统,第 45 卷,第 61-68 页
[7] M. Boguna 等人,《复杂网络的可导航性》(2009),《自然物理》,第 5 卷,第 1 期,第 74-80 页
[8] Y. Malkov, A. Ponomarenko,不断增长的同质网络是可自然导航的小世界(2015), PloS one