第1课、LangChain 介绍
LangChain 介绍
LangChain 是一个以大语言模型(LLM, Large Language Model)为核心的开发框架,旨在帮助开发者高效地将如 GPT-4 等大型语言模型与外部数据源和计算资源集成,构建智能化应用。
1.1 工作原理
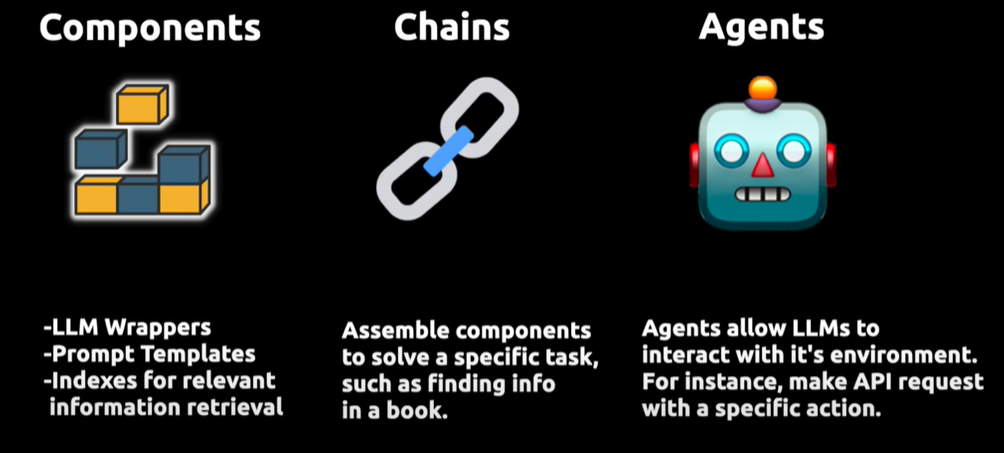
如上图所示,LangChain 通过三个核心组件提升了大型语言模型(LLMs)的能力:
- Components(组件):为 LLMs 提供接口封装、提示模板和信息检索索引。
- Chains(链):将不同组件组合,解决复杂任务,如在大规模文本中检索和处理信息。
- Agents(代理):使 LLMs 能与外部环境交互,例如通过 API 请求执行操作。
1.2 主要特性
- 支持多种数据源接入,如网页、PDF 文件、向量数据库等。
- 允许语言模型与外部环境实时交互。
- 封装了 Model I/O(输入/输出)、Retrieval(检索)、Memory(记忆)、Agents(决策与调度)等核心模块。
- 通过链式结构灵活组装各组件,满足多样化应用需求。
1.3 核心概念
LangChain 由以下核心概念构成:
- LLM Wrappers:对接主流大语言模型(如 GPT-4、Hugging Face 等)。
- Prompt Templates:支持动态变量插入,提升 Prompt 工程灵活性。
- Indexes:高效索引与检索大规模文本或数据库中的相关信息。
- Chains:将多个组件串联,完成多步推理与复杂任务。
- Agents:赋予模型自主决策能力,可调用外部工具或 API。
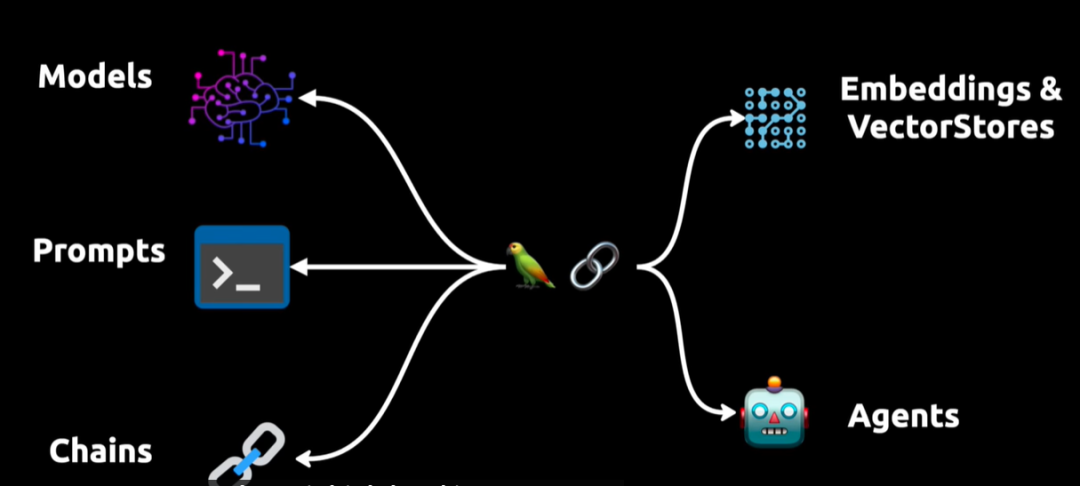
上图展示了一个复杂的自然语言处理系统,包括模型、提示、链、代理以及嵌入与向量存储:
- Models(模型):负责理解和生成自然语言。
- Prompts(提示):引导模型输出期望结果。
- Chains(链):将多个步骤串联,完成复杂任务。
- Agents(代理):实现模型与外部环境的动态交互,如 API 调用。
- Embedding & VectorStore(嵌入与向量存储):用于数据表示和高效检索,为模型提供语义理解基础。
1.4 工作流程
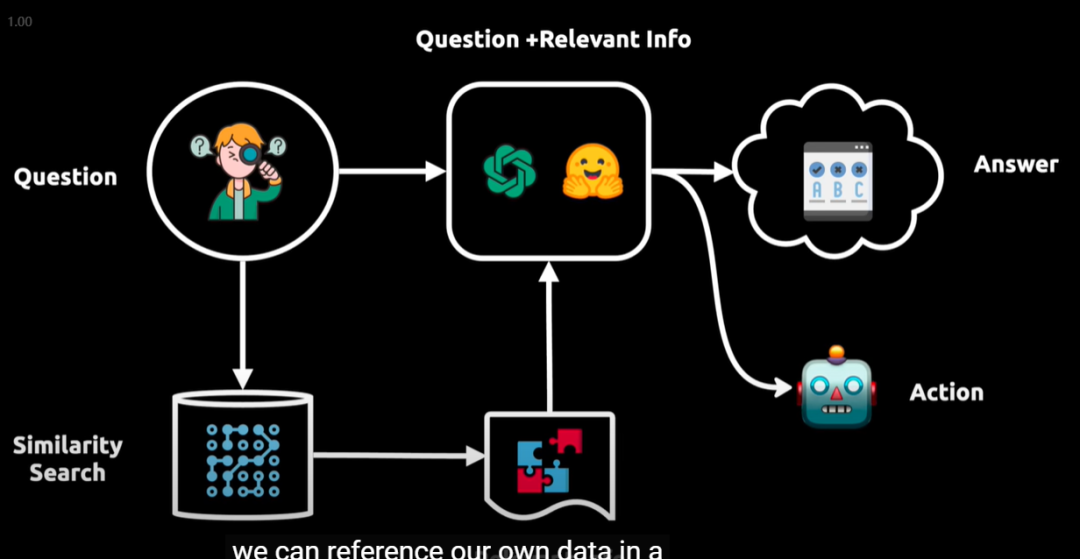
LangChain 的典型工作流程如下:
- 用户提出问题。
- 问题被向量化,用于在向量数据库中进行相似性检索。
- 检索到的相关信息与原始问题一同输入语言模型。
- 语言模型基于上下文生成答案或执行操作。
1.5 应用场景
LangChain 的应用场景涵盖但不限于:
- 智能个人助手:如自动预订、转账、缴税等。
- 数据分析与数据科学:连接企业内部或外部数据源,提升数据分析效率。
- 数据连接:将 LLM 与数据库、PDF、文档等私有数据源集成,实现专属知识检索。
- 自动化行动执行:不仅能检索信息,还可根据检索结果自动执行操作(如发送邮件),无需硬编码。
LangChain 为 AI 应用开发带来了高度的灵活性和扩展性,使机器学习系统能够更好地贴合实际业务需求,推动智能应用的多样化和个性化发展。
LangChain 简介
LangChain 是一个以大语言模型(LLM)为核心的开发框架,旨在让开发者能够更方便地将如 GPT-4 这样的模型与外部数据源和计算资源结合起来。框架目前支持 Python 和 JavaScript(TypeScript)两大主流开发语言,极大地降低了 LLM 应用开发的门槛。
版本介绍
LangChain 目前主要有两个官方维护的版本,分别面向 Python 和 JavaScript/TypeScript 生态:
-
LangChain (Python)
-
适用于数据科学、AI 应用、后端开发等场景。
-
社区活跃,文档与案例丰富。
-
支持主流 LLM(如 OpenAI、Anthropic、HuggingFace)、多种向量数据库(如 FAISS、Chroma、Weaviate),工具链和插件生态完善。
-
PyPI 包名:
langchain -
LangChain.js (JavaScript/TypeScript)
-
适用于前端、全栈、Node.js 服务端开发。
-
语法风格与 Python 版趋同,API 设计一致。
-
支持主流 LLM、向量数据库,兼容浏览器和 Node.js 环境。
-
npm 包名:
langchain
两个版本均在持续快速迭代,API 设计趋于统一,便于开发者跨语言迁移和经验复用。
类似框架对比
随着 LLM 应用开发的兴起,业界涌现出多款与 LangChain 类似的框架。下表对主流框架进行简要对比:
| 框架 | 语言 | 主要特点 | 适用场景 |
|---|---|---|---|
| LangChain | Python/JS | 生态完善,组件丰富,支持链式组合、Agent、Memory、插件众多,社区活跃 | 通用 LLM 应用开发 |
| LlamaIndex(原GPT Index) | Python/JS | 专注文档/知识库检索(RAG),文档加载与索引能力强,易与 LangChain 集成 | 知识库问答、RAG |
| Haystack | Python | 企业级,支持多种后端(Elasticsearch、FAISS、OpenSearch),可视化工具丰富 | 检索增强问答、企业知识库 |
| PromptFlow | Python/JS | 微软出品,强调可视化流程编排和 Prompt 工程,集成 Azure AI 服务 | 流程自动化、企业级集成 |
| Flowise | JS/可视化 | 基于 Node.js 的低代码/可视化 LLM 应用编排,拖拽式界面,易用性强 | 快速原型、非程序员用户 |
简要分析
- LangChain:适合需要高度自定义、复杂链路、Agent、插件扩展的开发者,生态最全,社区活跃。
- LlamaIndex:专注于知识库检索和文档增强生成(RAG),与 LangChain 可无缝集成。
- Haystack:偏向企业级生产环境,支持多种后端和可视化,适合大规模知识库和检索场景。
- PromptFlow/Flowise:适合需要可视化、低代码开发的团队,尤其适用于 Prompt 工程和流程自动化。
LangChain 的核心组件
LangChain 的设计高度模块化,主要包括以下核心组件:
- LLM Wrappers(模型包装器):无缝对接 OpenAI、Hugging Face 等主流大模型。
- Prompt Templates(提示模板):支持动态变量插入,提升 Prompt 工程灵活性。
- Indexes(索引):高效检索大规模文本或数据库中的相关信息。
- Chains(链):将多个组件串联,完成多步推理与复杂任务。
- Agents(代理):赋予模型自主决策能力,可调用外部工具或 API。
- Memory(记忆):支持对话历史和上下文记忆,提升智能化水平。
LangChain 的结构设计使 LLM 不仅能处理文本,还能在更广泛的应用环境中进行操作和响应,极大扩展了其应用范围和有效性。
[图片]
LangChain 的工作原理
LangChain 的典型工作流程如下:
- 用户提出问题。
- 问题被向量化,在向量数据库中检索相关内容。
- 检索到的信息与原始问题一同输入 LLM。
- LLM 生成答案,或由 Agent 进一步调用外部工具执行操作。
这种设计让 LLM 不再是"黑箱",而是能够与外部世界实时互动的智能体。
举例:如上图所示,智能问答系统从用户提问开始,通过相似性检索在数据库或向量空间中找到相关信息,结合原始问题由模型分析生成答案,并可由代理执行后续操作,实现数据驱动的自动化决策流程。
LangChain 的应用场景
LangChain 的应用非常广泛,包括但不限于:
- 智能问答系统(RAG,Retrieval Augmented Generation)
- 企业知识库检索
- 智能客服/个人助理
- 数据分析自动化
- 自动化办公(如自动发邮件、生成报告)
- 多轮对话机器人
- 代码自动生成与解释
- 数据连接:将 LLM 与数据库、PDF、文档等私有数据源集成,实现专属知识检索。
- 行动执行:不仅能检索信息,还可根据检索结果自动执行操作(如发送邮件),无需硬编码。
LangChain 为 AI 应用开发打开了全新可能,使机器学习系统更贴合实际需求,推动智能应用的多样化和个性化。
简单案例:用 LangChain 构建本地知识库问答
假设你有一段本地文本资料,希望让大模型基于这些资料进行智能问答。以下为最小可运行的 Python 示例:
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import RetrievalQA
from langchain.vectorstores import FAISS
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter# 1. 构建本地知识库
text = """
LangChain 是一个用于开发基于大语言模型(LLM)应用的开源框架。
它支持多种数据源接入,能够让 LLM 与外部世界无缝连接。
"""
# 文本切分
text_splitter = CharacterTextSplitter(chunk_size=100, chunk_overlap=0)
docs = text_splitter.create_documents([text])# 构建向量数据库
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(docs, embeddings)# 2. 构建问答链
llm = OpenAI(temperature=0)
qa = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=vectorstore.as_retriever()
)# 3. 提问
question = "LangChain 有什么用?"
answer = qa.run(question)
print("答案:", answer)
说明
- 需提前配置 OpenAI API Key(可通过环境变量
OPENAI_API_KEY设置)。 - 本案例将本地文本转为向量,用户提问后,LangChain 自动检索相关内容并调用大模型生成答案。
- 可将
text替换为自有知识库内容,或扩展为读取 PDF、网页等。
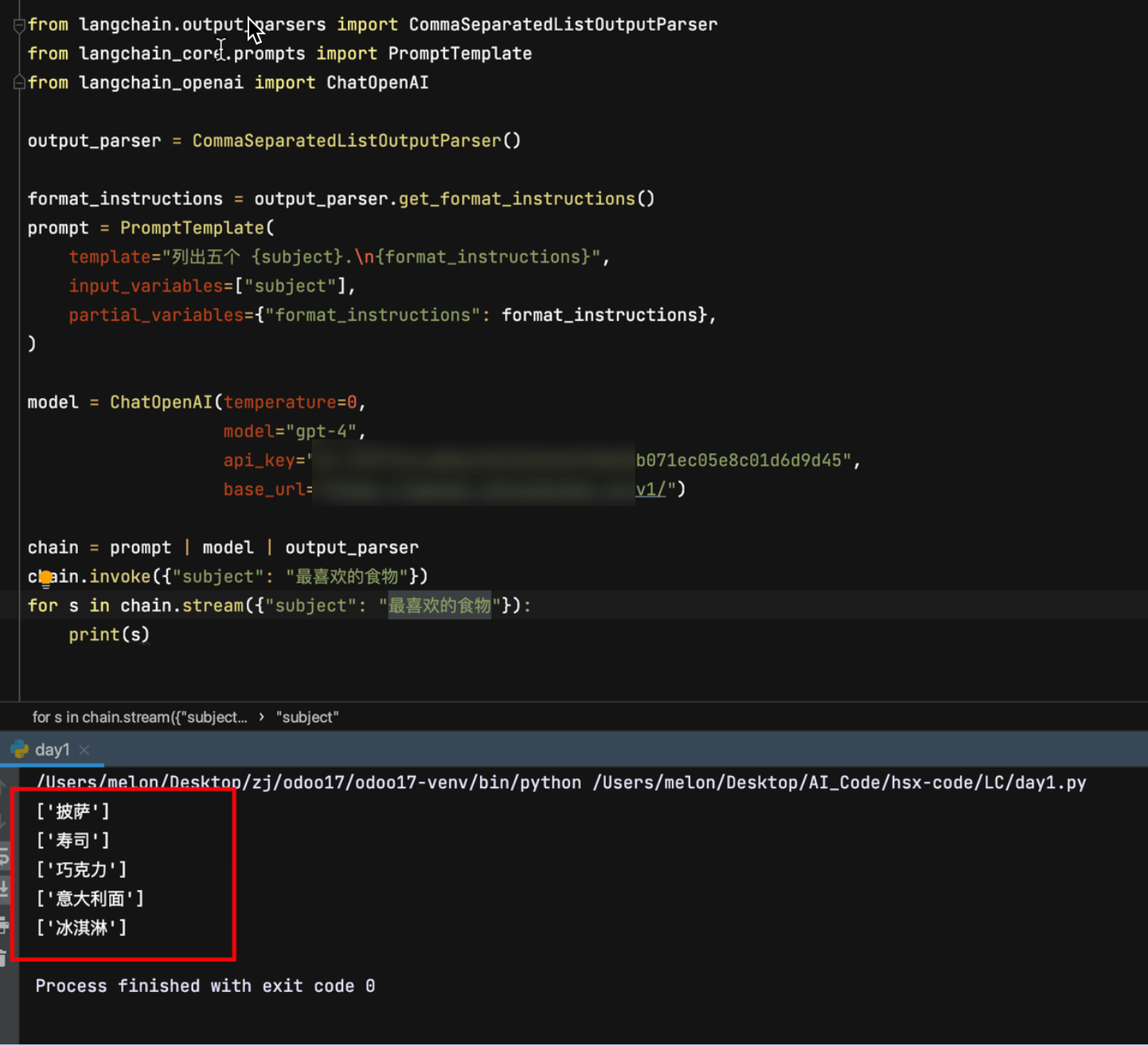
案例2:Prompt模版
from langchain.output_parsers import CommaSeparatedListOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_openai import ChatOpenAIoutput_parser = CommaSeparatedListOutputParser()format_instructions = output_parser.get_format_instructions()
prompt = PromptTemplate(template="列出五个 {subject}.\n{format_instructions}",input_variables=["subject"],partial_variables={"format_instructions": format_instructions},
)model = ChatOpenAI(temperature=0,model="gpt-4",api_key="xk-349774**********",base_url="https://**********/v1/")"""
这段代码定义了一个链式调用的过程,具体步骤如下:
prompt:生成初始提示。| model:将提示传递给模型进行处理。| output_parser:解析模型的输出结果。
"""
chain = prompt | model | output_parser
chain.invoke({"subject": "最喜欢的食物"})
for s in chain.stream({"subject": "最喜欢的食物"}):print(s)