DAX权威指南9:DAX 查询分析与优化1
文章目录
- 一、使用DAX Studio捕获DAX查询
- 1.1 准备Power BI报告
- 1.2 捕获查询
- 1.3 分析查询
- 二、DAX查询计划
- 2.1 逻辑查询计划
- 2.2 物理查询计划
- 2.3 存储引擎查询
- 三、Vertipaq 存储引擎查询详解
- 3.1 xmSQL 语法基础
- 3.1.1 隐含的 GROUP BY
- 3.1.2 特殊的 RowNumber 列
- 3.1.3 聚合函数
- 3.1.4 算术运算
- 3.1.5 筛选操作
- 3.1.6 连接操作
- 3.1.7 使用批处理事件 和 临时表 优化查询性能
- 3.2 SE引擎的扫描时间
- 3.3 内部子查询
- 3.4 并行性
- 3.4 Vertipaq 缓存
- 3.5 CallbackDataID(待补)
- 四、DirectQuery 存储引擎查询详解
- 4.1 DirectQuery SE查询
- 4.2 复合模型中的混合 SE 查询
- 4.3 使用聚合优化 SE 查询
- 五、深入解析 DAX 查询计划
- 5.1 逻辑查询计划
- 5.2 SE查询
- 5.3 物理查询计划
- 5.4 FE查询
- 5.5 查询优化
- 5.5.1 使用 INTERSECT 建立虚拟关系
- 5.5.2 使用 TREATAS 建立虚拟关系
参考《分析 DAX 查询计划》
一、使用DAX Studio捕获DAX查询
参考《Capturing Power BI queries using DAX Studio》
DAX Studio 是一个开源工具,专门用于编辑、测试和优化 DAX 查询。它能够连接到 Power BI、Analysis Services 和 Power Pivot for Excel 等工具,并捕获 DAX 查询的执行事件。与 SQL Server Profiler 等通用工具相比,DAX Studio 能够以更直观和高效的方式显示查询计划和性能数据,是 DAX 查询优化的首选工具。
1.1 准备Power BI报告
在Power BI中,每个报告页面通过刷新DAX查询更新视觉对象,切换页面、更改切片器或点击刷新视觉对象按钮,都会触发新查询。但Power BI有缓存机制,会避免重复发送相同查询。因此,捕获查询前需清空缓存。

假设有一个单页报告,打开报告时会立即生成DAX查询,此时可能来不及启动DAX Studio捕获所有查询。解决方法是在报告中添加一个空白页面作为默认打开页,这样重新打开PBIX文件时,系统会先显示空白页而不触发任何查询。
1.2 捕获查询
-
使用DAX Studio连接数据源:保持Power BI Desktop打开(停留在空白页),启动DAX Studio,选择选择已打开的 PBI/SSDT 模型

-
开启查询跟踪:单击功能区的 Traces 部分中的 All Queries 按钮,开始捕获发送到 Tabular 引擎的所有查询。确认输出面板显示"Query Trace Started"(查询跟踪已启动)

-
刷新查询:在DAX Studio保持运行状态下,切换到Power BI的数据页面,此时所有生成的查询将显示在All Queries面板中(每个视觉对象至少一个查询)。

- Duration列:显示查询耗时(毫秒),如果总查询时间与页面刷新时间差异较大,可能由于页面视觉对象过多
- Query 列:执行查询的完整文本
-
测试查询:
- 在All Queries 窗格中找出最慢的查询,双击它,查询将自动复制到编辑器窗口中。
- 点击 Run 按钮可再次执行此查询(先清除缓存),分析其查询计划和其他指标。
- 点击 Formatter Web Query可格式化查询,方便查看查询的结构。
1.3 分析查询
我们将Continent切片器选项改为欧洲,可以看到生成的新查询:

双击此查询并格式化,可以看到此查询详细内容:
DEFINEVAR __DS0FilterTable =TREATAS ( { "Europe" }, 'Customer'[Continent] )VAR __DS0Core =SUMMARIZECOLUMNS (ROLLUPADDISSUBTOTAL ( 'Product'[Product Name], "IsGrandTotalRowTotal" ),__DS0FilterTable,"Customers", 'Sales'[Customers])VAR __DS0PrimaryWindowed =TOPN (502,__DS0Core,[IsGrandTotalRowTotal], 0,[Customers], 0,'Product'[Product Name], 1)EVALUATE
__DS0PrimaryWindowed
ORDER BY[IsGrandTotalRowTotal] DESC,[Customers] DESC,'Product'[Product Name]
此查询非常耗时,实际上是由于Customers 度量引起的:
Customers :=
CALCULATE(DISTINCTCOUNT(Sales[CustomerKey]),FILTER(Sales, Sales[Quantity] > 0)
)
在PowerBI中将这个度量进行优化,查询时间降到16ms:
Customers :=
CALCULATE(DISTINCTCOUNT(Sales[CustomerKey]),Sales[Quantity] > 0
)

VertiPaq 性能与查询中所涉及的列的大小有关,而不仅仅与表的行数有关 。不同的列在内存中可以有不同的压缩率和大小,从而导致不同的扫描时间
二、DAX查询计划
DAX引擎在执行查询时,会生成详细的查询计划。查询计划是DAX引擎如何执行查询的详细描述。在第 17 章 “ DAX 引擎 ” 中,我们解释了 DAX 查询引擎中有两层: 公式引擎(Formula Engine) 和 存储引擎(Storage Engine)。
-
公式引擎(FE):主要负责处理复杂的逻辑和计算,这些计算不能直接由存储引擎(SE)执行。FE 的主要职责包括:
- 解析 DAX 表达式:将 DAX 查询解析为内部的逻辑查询计划。
- 执行复杂的逻辑:处理如条件逻辑、数学函数、用户定义的函数等复杂的计算。
- 调用存储引擎:将部分计算任务委托给存储引擎(SE),并处理 SE 返回的结果。
-
存储引擎(SE):主要负责高效地存储和检索数据,以及执行简单的聚合和筛选操作。SE 的主要职责包括:
- 数据存储和索引:管理数据的物理存储,包括列存储和索引。
- 执行聚合和筛选:处理如
SUM、COUNT、MIN、MAX等简单的聚合操作,以及基于条件的筛选。 - 返回数据缓存:将查询结果以数据缓存的形式返回给公式引擎(FE)。
每当执行一个 DAX 查询时,都会执行以下步骤:
- FE 解析 DAX 查询:公式引擎(FE)解析 DAX 查询,将查询从字符串转换为表达式树,这是一种易于处理的数据结构,以便进一步优化 。
- 生成逻辑查询计划:FE 将解析后的 DAX 查询转换为逻辑查询计划。逻辑查询计划是一个高级的、抽象的查询描述,它定义了查询的逻辑结构。
- 生成物理查询计划:引擎将逻辑查询计划转换为一组物理操作(物理查询计划)。物理查询计划是一个详细的执行步骤,描述了如何在物理层面上执行查询。
- FE生成 xmSQL 查询:FE 根据物理查询计划生成 xmSQL 查询,这些查询将被发送到存储引擎(SE)。
- SE 执行
xmSQL查询:存储引擎(SE)接收到xmSQL查询后,执行这些查询,生成数据缓存。 - FE 处理 SE 的结果:公式引擎(FE)接收 SE 返回的数据缓存,并进一步处理这些数据,完成复杂的逻辑和计算。
- 返回最终结果:FE 将最终结果返回给用户。
在上述过程中,xmSQL 查询是由VertiPaq SE执行的,而不是公式引擎(FE)。xmSQL 是 SE 的内部语言,用于描述 SE 需要执行的具体操作,如聚合、筛选和连接等。
不同引擎,如 DirectQuery 模式下的 SQL Server SE,可能生成其他语言的查询(如 T-SQL)
2.1 逻辑查询计划
逻辑查询计划使用xmSQL语言详细描述了DAX引擎计划执行的操作,以便计算查询结果。考虑在 DAX Studio 中执行以下查询,其结果是一个一行一列的表,表示Sales 表 Quantity 列之和(14018)。
EVALUATE
{ SUM ( Sales[Quantity] ) }-- value 14018
打开Traces 选项卡的Query Plan选项,切到查询计划视图。

Query Plan 窗格上半部分显示物理查询计划,下半部分显示逻辑查询计划。上述查询的逻辑查询计划如下:

这个逻辑查询计划清晰地展示了DAX引擎如何解析和理解查询。其中,每一行是一个运算符,下面缩进的行是运算符的参数。
- AddColumns:最外层的运算符,用于构建最终的结果表。
- RelLogOp和ScaLogOp:分别表示关系逻辑运算符(处理表级别的数据)和标量逻辑运算符(处理单个值);
- DependOnCols()():表示这个运算符不依赖于任何特定的列。
- 0-0:表示这个运算符的输入和输出列的范围。
- RequiredCols(0)(‘’[Value]):表示这个运算符需要生成一个新列[Value],但在这个阶段还没有具体的列数据(0列)。
- Sum_Vertipaq:标量逻辑运算符,用于计算SUM操作。
- Integer:表示操作的结果是整数类型。
- DominantValue=BLANK:表示在这个操作中,空白值(BLANK)是主要的值。
- Scan_Vertipaq:关系逻辑运算符,用于扫描Sales表。
- RequiredCols(7)(‘Sales’[Quantity]):表示这个运算符需要Sales表中的第7列,即Quantity列。
- ‘Sales’[Quantity]:标量逻辑运算符,表示Sales表中的Quantity列
- DominantValue=NONE:表示在这个操作中,没有特定的主要值。
这个逻辑查询计划的总体含义是:
- 构建一个只有一列([Value])的结果表。
- 计算SUM操作,对Sales表中的Quantity列进行求和。
- 扫描Sales表,提取Quantity列。
- 使用Quantity列的值进行求和操作。
2.2 物理查询计划
物理查询计划的格式与逻辑查询计划类似,但它使用完全不同的运算符:

-
第一行:
- IterPhyOp:表示这是一个迭代物理运算符,它会逐行处理数据。
- LogOp=AddColumns:表示这个物理运算符对应于逻辑查询计划中的
AddColumns操作。 - IterCols(0)(‘’[Value]):表示这个运算符会创建一个新列
[Value],但在这个阶段还没有具体的列数据(0列)。
-
第二行
- SingletonTable:表示生成一个只包含一行的表。
-
第三行
- SpoolLookup:表示在数据缓存中查找特定的数据。
- LookupPhyOp:表示这是一个查找物理运算符。
- LogOp=Sum_Vertipaq:表示这个物理运算符对应于逻辑查询计划中的
Sum_Vertipaq操作,即对Sales[Quantity]进行求和。 - #Records=1:表示这个运算符处理了1行数据。
- #KeyCols=32:表示有32个关键列(可能与内部实现有关,具体含义需要更深入的引擎知识)。
- #ValueCols=1:表示返回了1个值列。
-
第四行:
- ProjectionSpool:表示对查询结果进行投影操作,即选择特定的列。
- ProjectFusion:表示投影操作的具体实现方式,这里是一个简单的复制操作。
- SpoolPhyOp:表示这是一个缓存物理运算符。
-
第5行:
- Cache:表示将数据缓存起来,以便后续操作可以快速访问。
- IterPhyOp:表示这是一个迭代物理运算符。
- #FieldCols=0:表示没有字段列(可能与内部实现有关)。
- #ValueCols=1:表示有1个值列被缓存。
这个物理查询计划的总体含义是:
- 构建一个只有一列(
[Value])的结果表。 - 生成一个只包含一行的表。
- 在数据缓存中查找
Sales[Quantity]的总和,处理了1行数据,返回1个值列。 - 对查询结果进行投影操作,选择特定的列。
- 将结果缓存起来,以便后续操作可以快速访问。
ProjectionSpool 运算符表示发送到存储引擎的查询,它迭代查询结果。#Records=1 表示迭代结果的行数为1,嵌套缓存运算符返回的行数也是1。Records数(也叫运算符基数)很重要,因为:
- 数据缓存大小:记录数反映了由 VertiPaq 或 DirectQuery 创建的数据缓存的大小(以行为单位)。大型数据缓存会增加查询时的内存消耗和扫描时间。
- 性能瓶颈:Records数显示了由公式引擎通过 Datacache 迭代的记录数,这有助于快速识别在复杂查询计划中哪些操作迭代了大量记录。由于 ProjectionSpool 的迭代是在单线程中运行的,如果查询速度慢且记录数较大,可能表示存在性能瓶颈。
逻辑查询计划描述了DAX引擎如何解析和理解查询,而物理查询计划描述了DAX引擎如何实际执行查询。理解DAX查询计划对于优化查询性能至关重要:
- 记录数的重要性:记录数表示数据缓存的大小,大型数据缓存可能导致查询性能下降。优化查询时,应尽量减少数据缓存的大小。
- 存储引擎查询的执行时间:度量每个SE查询的执行时间是优化过程的重要部分。VertiPaq性能与查询中所涉及的列的大小有关,而不仅仅与表的行数有关。
- 逻辑与物理查询计划的差异:逻辑查询计划描述了DAX引擎如何理解查询,而物理查询计划描述了DAX引擎如何实际执行查询。优化查询时,应重点关注物理查询计划。
2.3 存储引擎查询
存储引擎(SE)接收并执行物理查询计划中定义的查询。打开Traces 选项卡的 Server Timings选项以显示存储引擎查询信息。
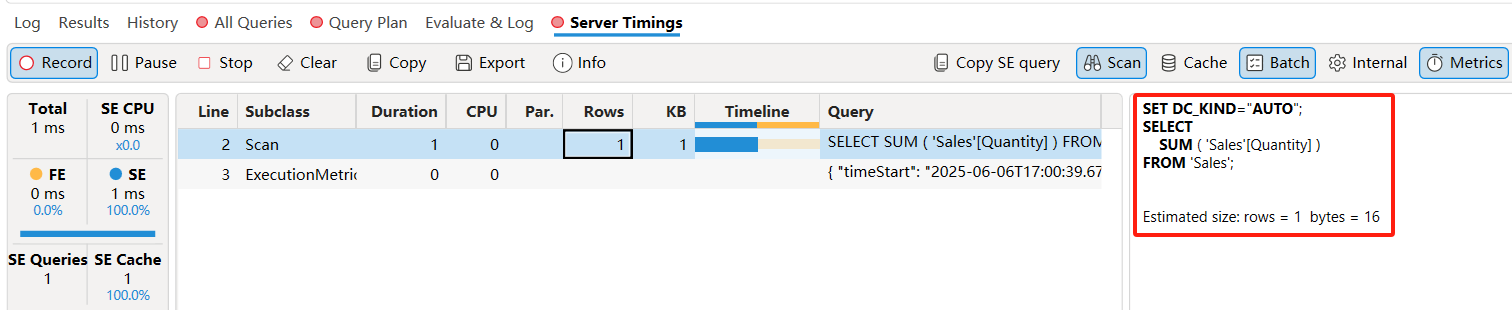
-
Server Timings窗格左侧:显示查询执行的详细时间信息。
进行DAX性能分析时,通常先查看Server Timings窗格。FE耗时 >50% → 分析查询计划,定位FE瓶颈(如复杂迭代、低效计算);如果以SE耗时为主,则在Server Timings窗格中查找最耗时的SE查询。- Total:查询总用时,对应于 Query End 事件的持续时间。
- SE CPU : SE 查询的 CPU 时间,以及并行使用的内核数(并行度)。
- FE :公式引擎(FE)执行时间(ms)及其占总时间的百分比。
- SE :存储引擎(SE)执行时间(ms)及其占总时间的百分比。
- SE Queries :发送到存储引擎的查询数量。
- SE Cache :存储引擎缓存解析的查询数量,及其占 SE 查询的百分比。
-
Server Timings窗格中间部分:
- Duration(持续时间):SE 请求的开始到结束的时间,单位为毫秒。
- CPU:一个核心消耗的总时间,单位为毫秒。如果 CPU > Duration,说明查询并行使用了多个内核。
- 并行性(仅适用于 SE 操作):通过
CPU / Duration计算。接近服务器核心总数时,无法通过增加并行性提升性能。例如,在 8 核系统中,并行度为 7.5 时,查询已达硬件限制,更多核心可提升速度;若并行性远小于核心数,增加内核无益。 - Rows 和 KB:分别显示 SE 查询返回的估计行数和结果大小(Datacache)。大基数数据缓存可能导致 FE 操作变慢,因为 FE 是单线程的。Datacache 的大小表示未压缩数据的内存成本,减少物化数据缓存可以降低 SE 和 FE 之间的数据交换量,减少内存压力,提升查询性能和可伸缩性。
Server Timings 的 Rows/KB 是估算值,适用于快速定位 SE 瓶颈。物理计划的 Records 是确切值,用于验证 FE 处理量。至于数据缓存的确切大小(即查询结果的实际内存占用),可通过查询计划中的记录数与 SE 查询的估计行数之间的比例来近似估算。
-
Server Timings窗格中间右侧:点击中间部分的SE查询,右侧会显示完整代码:
SET DC_KIND="AUTO"; SELECT SUM ( 'DaxBook Sales'[Quantity] ) FROM 'DaxBook Sales'; 'Estimated size ( volume, marshalling bytes ) : 1, 16'-
这个查询使用 VertiPaq 存储引擎(SE)来聚合 Sales 表中的所有行,计算 Quantity 列的总和。查询返回一个很小的数据缓存(只有一行一列,物化成本很低),不管 Sales 表有多大。
-
此外,查询只读取 Sales 表中存储 Quantity 列的数据结构,表中的其他几百个列不会影响这个 xmSQL 查询,因为 VertiPaq SE 只扫描 xmSQL 查询中涉及的列。如果是DirectQuery的模型,生成的查询将是类似于以下的SQL查询:
SELECT SUM ( [Quantity] ) FROM Sales -
-
Server Timings选项区:窗格右上部分,列举了一些选项。DAX Studio 默认隐藏 VertiPaq 内部扫描和其他缓存事件等详细信息,因为这些通常不是性能分析的必需内容。如果需要查看,可以通过启用 Server Timings 组的 Cache、Internal 等按钮来显示或隐藏。
- Cache:显示或隐藏与缓存相关的事件,例如缓存命中或缓存未命中的事件。
- Internal:显示或隐藏内部事件,例如 VertiPaq 扫描的内部细节。
- Batch:显示或隐藏与批处理相关的事件,例如多个查询的批量执行。
三、Vertipaq 存储引擎查询详解
上一节介绍过 xmSQL 查询,它是由 存储引擎(SE) 执行的,是VertiPaq SE的内部语言,专为列式存储优化,用于描述 SE 需要执行的具体操作(聚合、筛选和连接等)。虽然 xmSQL 查询是由 SE 执行的,但阅读这些查询对于理解 FE 的行为仍然非常有用:
- 优化性能:通过分析
xmSQL查询,可以了解 SE 的执行效率。SE 可以并行执行多个 xmSQL 查询(如多核扫描),而 FE 是单线程的。了解这些有助于优化 DAX 查询的性能。 - 识别瓶颈:当 SE 无法高效处理某些操作(如复杂迭代、跨表逻辑)时,FE 会接管这些操作,直接处理SE返回的基础数据缓存,这可能导致性能下降。通过分析
xmSQL查询,可以识别这些潜在的瓶颈。 - 理解数据流:了解 SE 和 FE 之间的数据交互,有助于优化整个查询的执行过程。
3.1 xmSQL 语法基础
xmSQL 是一种类似于 SQL 的查询语言,用于与 VertiPaq SE交互。它在功能和结构上与标准 ANSI SQL 有许多相似之处,但也有一些独特的特点。(如 JOIN 可能被转换为物理层批处理操作)。一个简单的 xmSQL 查询如下所示:
SELECT
SUM ( Sales[Quantity] )
FROM Sales;
这个查询计算了 Sales 表中 Quantity 列的总和。与标准 SQL 类似,xmSQL 也使用 SELECT 语句来指定要计算的表达式,并通过 FROM 子句指定数据来源。
3.1.1 隐含的 GROUP BY
在 xmSQL 中,即使没有显式声明 GROUP BY,每个查询也隐含了分组逻辑。这是因为 xmSQL 查询的结果总是唯一的。例如,以下 DAX 查询返回“产品”表中“颜色”列的唯一值列表:
EVALUATE VALUES ( 'Product'[Color] )
发送给 SE 的 xmSQL 查询为:
SELECT Product[Color]
FROM Product;
虽然没有显式的 GROUP BY,但 xmSQL 会自动处理分组逻辑,确保返回的结果是唯一的。在 ANSI SQL 中,相应的查询会显式包含 GROUP BY:
SELECT Color
FROM Product
GROUP BY Color;
xmSQL 查询通常不使用 DISTINCT,而是通过隐含的 GROUP BY 来确保结果的唯一性。这是因为 xmSQL 查询大多数时候还包含聚合计算。例如:
EVALUATE
SUMMARIZECOLUMNS (Sales[Order Date],"Revenues", CALCULATE ( SUM ( Sales[Quantity] ) )
)
生成的 xmSQL 查询是:
SELECT Sales[Order Date], SUM ( Sales[Quantity] )
FROM Sales;
在 ANSI SQL 中,Order Date列会显式包含 GROUP BY条件:
SELECT [Order Date], SUM ( Quantity )
FROM Sales
GROUP BY [Order Date];
3.1.2 特殊的 RowNumber 列
当 DAX 查询在没有唯一键的表上运行时,xmSQL 查询会自动添加一个特殊的 RowNumber 列,以确保每一行的唯一性。这个 RowNumber 列在 xmSQL 中用于内部处理,但在 DAX 中是不可见的。例如:
EVALUATE Sales
生成的 xmSQL 查询为:
SELECT Sales[RowNumber], Sales[column1], Sales[column2], ... ,Sales[columnN]
FROM Sales
这个 RowNumber 列在 xmSQL 中用于内部处理,确保即使表中没有唯一键,每一行结果也是唯一的。此列在 DAX 中是不可见。
3.1.3 聚合函数
xmSQL 支持多种聚合函数,包括:
SUM:计算列值的总和。MIN和MAX:返回列中的最小值和最大值。COUNT:计算当前分组的行数。DCOUNT:计算列中唯一值的数量。
-
SUM,MIN,MAX 和 DCOUNT 的行为类似。 例如,以下 DAX 查询返回每个订单日期的唯一客户数:
EVALUATE SUMMARIZECOLUMNS ( Sales[Order Date], "Customers", DISTINCTCOUNT ( Sales[CustomerKey] ) )它生成以下 xmSQL 代码:
SELECT Sales[Order Date], DCOUNT ( Sales[CustomerKey] ) FROM Sales;对应于以下 ANSI SQL 查询:
SELECT [Order Date], COUNT ( DISTINCT CustomerKey ) FROM Sales GROUP BY [Order Date] -
COUNT 函数没有参数,只计算当前组的行数。考虑以下 DAX 查询,该查询计算每种颜色的产品数量:
EVALUATE SUMMARIZECOLUMNS ( 'Product'[Color], "Products", COUNTROWS ( 'Product' ) )-- xmSQL 查询 SELECT Product[Color], COUNT ( ) FROM Product;-- ANSI SQL 查询 SELECT Color, COUNT ( * ) FROM Product GROUP BY Color -
DAX 中的其他聚合函数没有相应的 xmSQL 聚合函数。例如使用AVERAGE 的DAX查询:
EVALUATE SUMMARIZECOLUMNS ( 'Product'[Color], "Average Unit Price", AVERAGE ( 'Product'[Unit Price] ) )相应的 xmSQL 代码包括两个聚合:一个用于分子,一个用于除法的分母,这将在 FE 中计算简单的平均值:
SELECT Product[Color], SUM ( Product[Unit Price] ), COUNT ( ) FROM Product WHERE Product[Unit Price] IS NOT NULL;对应ANSI SQL查询为:
SELECT Color, SUM ( [Unit Price] ), COUNT ( * ) FROM Product WHERE Product[Unit Price] IS NOT NULL GROUP BY Color
3.1.4 算术运算
xmSQL 支持基本的算术运算符(+, -, *, /),这些运算符仅在单行上进行计算。例如,以下 DAX 查询:
EVALUATE
{ SUMX ( Sales, Sales[Quantity] * Sales[Unit Price] ) }
生成的 xmSQL 查询为:
WITH
$Expr0 := ( Sales[Quantity] * Sales[Unit Price] )
SELECT
SUM ( @$Expr0 )
FROM Sales;
这里,WITH 语句定义了一个临时表达式 $Expr0,用于计算每一行的 Quantity 和 Unit Price 的乘积,然后对这些乘积求和。这些表达式稍后在查询的其余部分中被引用(本例中被SUM函数引用)。
对应的ANSI SQL 查询为:
SELECT SUM ( [Quantity] * [Unit Price] )
FROM Sales
xmSQL 还可以在数据类型之间执行强制转换以执行算术运算。 重要的是要记住,从 DAX 表达式的角度来看,这些操作仅在 行上下文中发生。
3.1.5 筛选操作
xmSQL 查询可以通过 WHERE 子句添加筛选条件,筛选操作性能取决于所应用条件的基数( 稍后将在“了解扫描时间”部分中对此进行详细讨论)。
-
基础筛选:以下查询返回单价等于 42 的所有销售的“数量”列的总和:
EVALUATE CALCULATETABLE ( ROW ( "Result", SUM ( Sales[Quantity] ) ), Sales[Unit Price] = 42 )生成的
xmSQL查询为:SELECT SUM ( Sales[Quantity] ) FROM Sales WHERE Sales[Unit Price] = 420000;注意 : WHERE 条件中的值乘以 10,000 的原因是因为“单价”列存储为“货币”数据类型(在 Power BI 中也称为“固定十进制数”)。 该数字作为整数存储在 VertiPaq 中,因此 FE 通过将结果除以 10,000 来转换为十进制数。 这一除法操作在查询计划和 xmSQL 代码中都不可见。
-
OR筛选:对数量列中单价等于16 或 42 的销售额进行求和。
EVALUATE CALCULATETABLE ( ROW ( "Result", SUM ( Sales[Quantity] ) ), OR ( Sales[Unit Price] = 16, Sales[Unit Price] = 42 ) )xmSQL 使用 IN 运算符包含值列表:
SELECT SUM ( Sales[Quantity] ) FROM Sales WHERE Sales[Unit Price] IN ( 160000, 420000 ); -
引擎优化:xmSQL 是 SE 查询的文本表示形式,实际执行结构经过优化。比如以下 DAX 查询返回一年销售的数量总和:
EVALUATE CALCULATETABLE ( ROW ( "Result", SUM ( Sales[Quantity] ) ), Sales[Order Date] >= DATE ( 2006, 1, 1 ) && Sales[Order Date] <= DATE ( 2006, 12, 31 ) )
-
旧版引擎:在旧版本的 DAX 引擎中,这个查询可能会被转换为一个包含多个值的 IN 条件。生成的 xmSQL 查询如下:
SELECT SUM ( Sales[Quantity] ) FROM Sales WHERE Sales[Order Date] IN ( 38732.000000, 38883.000000, 38846.000000, 38997.000000, 38809.000000, 38960.000000, 38789.000000, 38923.000000, 39074.000000, 38752.000000..[365 total values, not all displayed] ) ;在这个查询中,xmSQL 列出了2006年每一天的日期值(以浮点数表示)。但是,为了避免列出所有365个值,xmSQL 只显示了一部分值作为示例,并且在最后注明了总共有365个值。 时间智能函数经常发生这种情况。这种表示方式虽然详细,但查询的复杂性和执行时间会显著增加。
-
新版引擎:在新版本的 DAX 引擎中,这个查询会被转换为一个范围条件:
SELECT SUM ( Sales[Quantity] ) FROM Sales WHERE Sales[Order Date] >= 38718.000000 VAND Sales[Order Date] <= 39082.000000VAND 是 xmSQL 中的一个操作符,表示 “AND”。两个浮点数对应于 DAX 表达式中使用的日期范围(2006-01-01 到 2006-12-31),这种表示方式更加简洁。
3.1.6 连接操作
当 DAX 查询涉及多个表时,xmSQL 会使用 JOIN 操作来连接这些表。例如以下 DAX 查询,返回产品表中每个产品颜色对应的总销量:
EVALUATE
SUMMARIZECOLUMNS (
'Product'[Color],
"Sales", SUM ( Sales[Quantity] )
)
当数据模型中存在一对多关系时,xmSQL 会通过 LEFT OUTER JOIN 将相关表连接起来,生成的 xmSQL 查询为:
SELECT Product[Color], SUM ( Sales[Quantity] )
FROM Sales
LEFT OUTER JOIN Product ON Sales[ProductKey] = Product[ProductKey];
这里,JOIN 的 ON 条件会自动引用定义关系的列。对于查询中涉及的每个关系,xmSQL 都会生成一个相应的 JOIN。
3.1.7 使用批处理事件 和 临时表 优化查询性能
本节模型文件是
Model for queries in Chapter 19.pbix
当一个复杂的 DAX 查询需要多个步骤来完成时,VertiPaq 引擎会使用 批处理事件 来组织这些步骤。每个步骤的结果会被保存在 临时表 中,这些临时表不会返回给公式引擎(FE),而是供后续的查询步骤使用。这种机制可以显著提高查询性能,因为它减少了重复计算和数据传输的开销。考虑以下 DAX 查询,该查询计算在相应年份中至少进行一次购买的客户的平均年收入:
EVALUATE
CALCULATETABLE (SUMMARIZECOLUMNS ('Date'[Calendar Year],"Yearly Income", AVERAGE ( Customer[Yearly Income] )),CROSSFILTER ( Sales[CustomerKey], Customer[CustomerKey], BOTH )
)
在这个查询中,Sales 和 Customer 表之间存在 双向筛选器,这会激活存储引擎(SE)的特殊行为,生成一系列的 xmSQL 查询,并将这些查询分组在批处理事件中执行。在Server Timings窗格中,可以看到详细的批处理事件:
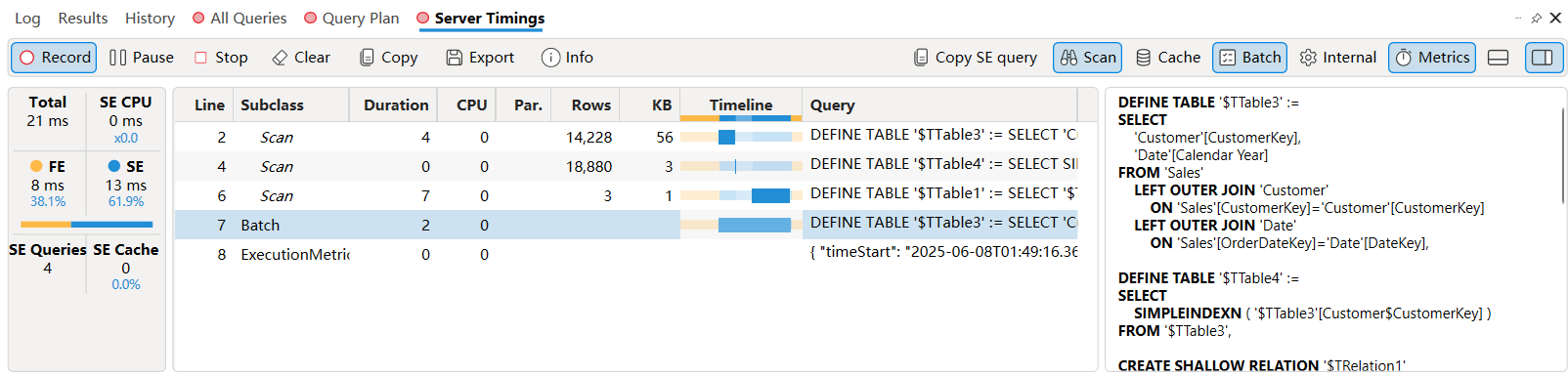
-
创建临时表
$TTable3:它包含了 Sales 表和 Customer 表的连接结果,以及 Date 表的相关信息。-- This query is also the first Scan event processed DEFINE TABLE '$TTable3' := SELECT Customer[CustomerKey], Date[Calendar Year] FROM Sales LEFT OUTER JOIN Customer ON Sales[CustomerKey]=Customer[CustomerKey] LEFT OUTER JOIN Date ON Sales[OrderDateKey]=Date[DateKey]; -
创建浅层关系
$TRelation1:它定义了 Customer 表和临时表 $TTable3 之间的多对多关系。这个关系用于优化双向筛选器的行为。-- This directive does not generate any Scan event CREATE SHALLOW RELATION '$TRelation1' MANYTOMANY FROM Customer[CustomerKey] TO '$TTable3'[Customer$CustomerKey]; -
创建索引
$TTable4:$TTable4包含了 $TTable3 中 Customer$CustomerKey 的索引。这个索引用于后续查询中的筛选操作。-- This query is the second Scan event processed DEFINE TABLE '$TTable4' := SELECT SIMPLEINDEXN ( '$TTable3'[Customer$CustomerKey] ) FROM '$TTable3'; -
最终查询
$TTable1:计算每个年份的平均年收入。REDUCED BY 子句定义了一个子查询 $TTable2,它计算了每个客户的年收入总和。这个子查询的结果被用于最终的聚合计算。-- This query is the third and last Scan event processed for this batch DEFINE TABLE '$TTable1' := SELECT '$TTable3'[Date$Calendar Year], SUM ( '$TTable2'[$Measure0] ), SUM ( '$TTable2'[$Measure1] ) FROM '$TTable2' INNER JOIN '$TTable3' ON '$TTable2'[Customer$CustomerKey]='$TTable3'[Customer$CustomerKey] REDUCED BY '$TTable2' := SELECT Customer[CustomerKey], SUM ( Customer[Yearly Income] ), SUM ( ( PFDATAID ( Customer[Yearly Income] ) <> 2 ) ) FROM Customer WHERE Customer[CustomerKey] ININDEX '$TTable4'[$Index1];
总结:
- 批处理事件:将多个 xmSQL 查询分组在一起,以优化性能。
- 临时表:保存中间结果,供后续查询使用。
- 浅层关系:优化双向筛选器的行为。
- 索引:提高筛选操作的效率。
- 最终查询:基于中间结果计算最终结果。
通过使用批处理事件和临时表,VertiPaq 引擎可以显著减少重复计算和数据传输的开销。这种机制特别适用于复杂的查询,比如涉及双向筛选器的查询。
3.2 SE引擎的扫描时间
VertiPaq 存储引擎在执行查询时,会对涉及的每个列进行完整扫描。因为没有索引,扫描时间的长短取决于列的内存占用量。占用量又取决于列的基数(唯一值数量)、行的分布以及表中的行数,它们共同决定了扫描操作的效率。
假设我们有一个包含 40 亿行的大表,表中有四列:日期、时间、年龄和分数。我们将对每一列执行以下 DAX 查询,以测量扫描时间:
EVALUATE
ROW ( "Sum", SUM ( Example[<column name>] ) )EVALUATE
ROW ("Distinct Count", CALCULATE (DISTINCTCOUNT ( Example[<column name>] ),NOT ISBLANK ( Example[<column name>] ))
)
注意: 第二个查询包括获取 SE 查询以执行查询所需的 NOT ISBLANK 条件。 如果查询没有筛选器,则将从模型的元数据中检索出一列中不同值的数量,而无需实际执行任何 SE 请求。

Memory (MB)与Distinct Values:分别表示列的内存占用量和列的基数SUM (ms)与DISTINCTCOUNT (ms):该列执行SUM 函数或DISTINCTCOUNT的查询时间。
结果分析:
- 日期列性能最优:尽管日期列的唯一值数量(1588)多于年龄列(96),但其执行时间最短。这是因为数据按日期排序,这意味着数据在物理存储时,相同日期的行是连续存放的。大量重复的日期值使得每个日期段内的行都具有极高的压缩率,显著减少了内存占用和扫描时间。
- 年龄列次之:年龄列的内存占用量大于日期列,因为每个日期下都有不同的年龄值,且数据先按日期排序,导致其压缩率低于日期列,执行时间稍长。
- 时间列性能较差(压缩率差异):时间列的唯一值数量与日期列相似,但其内存占用量更大,执行时间也更长,因为时间列没有像日期列那样按顺序排列,其压缩率较低。
- 分数列性能最差:对比时间列可以看出,对于
SUM操作,内存占用量是主要影响因素;而DISTINCTCOUNT操作对基数更为敏感,这是因为两种聚合的计算算法不同。
优化建议:
- 减少列的内存占用量:选择具有较少唯一值的列,或调整数据源的排序顺序以提高压缩率,从而减少内存占用。
- 减少表中的行数:通过数据过滤或聚合等手段,减少需要扫描的行数,进而降低查询时间。
3.3 内部子查询
DISTINCTCOUNT 函数在执行过程中对单个 VertiPaq 扫描( VertiPaq Scan )会触发多个内部扫描事件(VertiPaq Scan Internal,中间结果),例如以下DAX查询,统计Net Price 列非零值的唯一值数量:
EVALUATE
ROW ("Distinct Count", CALCULATE ( DISTINCTCOUNT (Sales[Net Price] ), Sales[Net Price] <> 0 )
)
启用 DAX Studio 的Server Timings组中的Internal按钮,可以查看这些事件:

第四行是 FE 请求的 SE 查询:
SELECTDCOUNT ( 'Sales'[Net Price] )
FROM 'Sales'
WHERE'Sales'[Net Price] NIN ( null ) ;Estimated size: rows = 1 bytes = 12
但是在内部,SE将其分为了多个子查询:
-
子查询1:从Sales 表中检索 Net Price 列所有非零值的唯一值列表
SELECT'Sales'[Net Price] FROM 'Sales' WHERE'Sales'[Net Price] INB ( 1759600, 758400, 39920, 2392000, 639600, 4704000, 3020000, 4450000, 4290000, 4800000..[1,768 total values, not all displayed] ) ; -
子查询2:
SELECT'Sales'[Net Price] FROM 'Sales' WHERE'Sales'[Net Price] NIN ( null ) ;Estimated size: rows = 1,768 bytes = 7,072 -
子查询3:计算上一步生成的唯一值列表中的行数。$DCOUNT_DATACACHE 是一个特殊的表,它引用了上一个子查询的结果。
SELECTCOUNT () FROM $DCOUNT_DATACACHE;
- 扫描事件的持续时间:上图显示了扫描事件的持续时间与两个内部事件的持续时间之和相对应(子查询1的结果被复制到了子查询2中,重复事件只计数一次)。
- CPU 时间和并行度:在同一查询的所有事件中,CPU 时间是相同的。通过将 CPU 时间除以持续时间(Duration),可以评估并行度比率(见本文2.3章节)。
3.4 并行性
VertiPaq 存储引擎支持并行执行查询,这可以显著提高查询性能。
- 多线程执行:VertiPaq 引擎可以将查询分解为多个子任务,每个线程处理查询的一部分数据,从而加快整个查询的执行速度。线程数取决于硬件配置(如 CPU 核心数)和查询的复杂性(复杂查询将启用更多额线程)。
- 线程分配:对于每个查询,VertiPaq 引擎会根据查询涉及的列和表的物理结构,动态分配线程。例如,如果一个表被分成了多个段(segment),每个段可以分配一个线程进行扫描。
- 结果合并:并行执行完成后,各个线程生成的结果合并到一个最终的数据缓存中。然后FE 将在单个线程中使用数据缓存。

如果段太小,合并的开销可能会超过并行化的收益,所以小型表不需要进行并行化处理。
3.4 Vertipaq 缓存
VertiPaq 缓存是 VertiPaq 存储引擎(SE)中一个关键的性能优化机制,它的主要作用有两个:
- 同一查询中复用计算结果:一个查询可能需要对同一表或列进行多次聚合计算,使用数据缓存可以直接读取之前执行的结果,避免重复计算
- 不同查询复用计算结果:不同的 DAX 查询可能需要调用相同的数据,通过共享缓存可以提高性能。
在一个简单的场景中,我们执行以下步骤:
- SE 收到一个 xmSQL 查询。
- SE 可能在多个线程上执行扫描操作,从而每个线程创建一个数据缓存。
- SE 将不同的数据缓存合并到一个最终数据缓存中。
- FE 在单个线程中使用数据缓存。
- FE 可以在查询计划的不同步骤中使用相同的数据缓存。
假设我们有以下 DAX 查询:
EVALUATE
ADDCOLUMNS (VALUES ( Example[Date] ),"A", CALCULATE ( SUM ( Example[Amt] ) ),"Q", CALCULATE ( SUM ( Example[Qty] ) )
)
这个查询的目的是对每个日期的 Example 表的 Amt 和 Qty 列求和,并生成两列结果 A 和 Q。默认情况下,缓存事件和内部事件不会显示,此时只有两个扫描事件:

开启显示后:
- 首次执行:VertiPaq 引擎会从数据源中读取数据,并将其存储在缓存中。这个过程涉及到对数据的扫描和计算,因此首次执行的时间相对较长。

- 第二次执行:当再次执行相同的查询时,如果缓存中已经存在所需的数据,VertiPaq 引擎会直接从缓存中检索结果,而无需再次扫描数据源。因此,第二次执行的时间会显著减少,甚至是0 ms:

注意事项:
- 缓存结构:VertiPaq 缓存存储在内存中,是一个未压缩的表结构。缓存中的数据是查询结果的直接表示,可以快速访问和使用。
- 缓存大小:缓存的大小是有限的,因此 VertiPaq 引擎会根据需要自动管理缓存中的数据。如果缓存满了,旧的数据可能会被替换掉。
- 缓存调用条件:VertiPaq 引擎仅在以下条件下重用缓存中的数据:
- 基数相同:即数据的唯一值数量相同。
- 列是先前查询的子集:即当前查询的列是之前查询中已经缓存的列的子集
- 行级安全:缓存不考虑行级安全设置。DAX 公式引擎(FE)负责管理基于角色的安全性,并根据安全性设置和用户凭据生成不同的 VertiPaq 查询。因此,缓存中的结果是全局共享的(不同的用户和会话之间共享),但 FE 会确保结果的正确性。
在分析性能时,清除缓存是一个重要的步骤。为了找到查询计划的瓶颈和需要改进的地方,最好观察完成内存扫描所需的时间,以模拟最坏情况(空缓存)。DAX Studio 提供了两种缓存清除方式:
- 清除缓存按钮:在执行查询之前,点击 DAX Studio 的“清除缓存”按钮,可以清除 DAX 引擎的缓存。
- 清除缓存并运行:选择“清除缓存并运行”按钮,可以在每次运行查询之前自动清除缓存。

在引擎内部,DAX Studio 使用以下 XMLA 命令发送清除缓存命令,删除与指定数据库相关的结果的缓存。比如以下代码清除Contoso 数据库的缓存:
<ClearCache xmlns="http://schemas.microsoft.com/analysisservices/2003/engine">
<Object>
<DatabaseID>Contoso</DatabaseID>
</Object>
</ClearCache>
3.5 CallbackDataID(待补)
VertiPaq 存储引擎(SE)擅长处理大规模数据的快速扫描和聚合操作,但它支持的运算符和函数有限。例如,SE 支持基本的数学运算(加、减、乘、除),但不支持如平方根(SQRT)或条件逻辑(IF)等复杂函数,此时将调用FE执行复杂运算。
当 DAX 查询中包含 SE 不支持的表达式时,查询计划会生成一个包含 CallbackDataID 函数的 xmSQL 查询。在迭代过程中,SE 会为每一行调用 FE,并将 DAX 表达式及其成员的值作为参数传递给 FE。考虑以下 DAX 查询,计算销售表中每行的 Line Amount 列值的四舍五入结果之和:
EVALUATE
ROW (
"Result", SUMX ( Sales, ROUND ( Sales[Line Amount], 0 ) )
)
在这个查询中,ROUND 函数是 SE 不支持的。因此,查询计划会生成以下 xmSQL 语句:
WITH
$Expr0 := [CallbackDataID ( ROUND ( Sales[Line Amount]] ), 0 ) ]
( PFDATAID ( Sales[Line Amount] ) )
SELECT
SUM ( @$Expr0 )
FROM Sales;
在这个例子中,SE 会为 Sales 表的每一行调用 CallbackDataID,将 Sales[Line Amount] 列的值传递给 FE 进行四舍五入计算(DAX 表达式)。尽管 FE 是单线程的,但 SE 的并行性不会受影响,因为每个 SE 线程可以有自己的 FE 实例并行执行。最终,xmSQL 查询结果是一个包含汇总值的单行数据缓存。
如果不使用 CallbackDataID机制,SE 需要为 Sales 表中每行的 Line Amount 列值创建一个包含所有行的数据缓存,这会占用更多内存且需要在单线程中迭代处理,导致性能下降。
SELECT
Sales[Line Amount], COUNT( )
FROM Sales;
而使用 CallbackDataID 可以显著减少内存占用(仅需单行数据缓存),并且由于 SE 的多线程支持,可提高可伸缩性。不过,CallbackDataID 的调用本身会带来额外开销,且其结果不会被 SE 缓存,因此CPU 时间可能会增加。
四、DirectQuery 存储引擎查询详解
4.1 DirectQuery SE查询
DirectQuery 模式中DAX直接从数据源(如 SQL Server)查询数据,而不是将数据加载到内存中。这种方式在处理大规模数据集时可以显著减少内存占用,但查询性能可能会受到数据源性能的限制。考虑以下 DAX 查询:
EVALUATE
SUMMARIZECOLUMNS (Sales[Order Date],"Total Quantity", SUM ( Sales[Quantity] )
)
在 DirectQuery 模式下,DAX 引擎会将此查询转换为 SQL 查询并发送到数据源。生成的 SQL 查询如下:
SELECTTOP (1000001) [t4].[Order Date],SUM ( CAST ( [t4].[Quantity] as BIGINT ) ) AS [a0]
FROM (SELECT [StoreKey], [ProductKey], ... // other columns of the tables omitted hereFROM [dbo].[Sales] AS [$Table]
) AS [t4]
GROUP BY [t4].[Order Date]
TOP 条件:在 DirectQuery 模式下,DAX 引擎为了防止从数据源获取过多数据而占用过多内存,在生成 SQL 查询时会添加一个 TOP 条件来限制返回的行数。如果实际返回的行数刚好等于 TOP 条件的参数值,那么 DAX 查询会认为数据可能不完整(因为可能还有更多数据没有被返回),从而导致查询失败。
默认情况下,DirectQuery 模式接受的行数限制为
1,000,000,多出的1行是为了检测是否还有更多数据。这个限制可以在 Analysis Services 中通过MaxIntermediateRowsetSize配置设置进行修改,但在 Power BI 中无法修改。更多内容详见《Tuning query limits for DirectQuery》
性能监控:下图显示了发送到 DirectQuery 数据源的 SQL SE 查询的信息示例,其中 Duration 列显示了等待数据源提供 SQL 查询结果所花费的时间(以毫秒为单位)。CPU通常是0或者一个很小的数,这是由于 DirectQuery 引擎忽略了数据源的实际成本,因此需要通过工具(如 SQL Server Profiler)分析数据源上的实际 CPU 消耗。

不返回的Rows和KB信息:
- 在 VertiPaq 模式下,DAX 查询被转换为 xmSQL 查询并发送到存储引擎(如内存中的 VertiPaq 引擎)。这些查询的执行信息会记录返回的行数(Rows)和占用的内存(KB)。
- 在 DirectQuery 模式下,DAX 查询被转换为 SQL 查询并发送到数据源(如 SQL Server)。这些 SQL 查询的执行信息被称为 SQL 事件。这些事件记录了查询的执行时间(Duration),但不会记录返回的行数(Rows)和占用的内存(KB),因为DAX 引擎无法直接获取数据源内部的行数和内存使用情况。
不缓存查询结果:在 DirectQuery 模式下,每次查询都是直接从数据源获取数据,查询结果不会被存储在存储引擎(SE)的缓存中。这意味着每次执行查询时,都会重新从数据源获取数据,而不是从缓存中读取。因此对于 DirectQuery 数据模型,SE 缓存计数器(SE Cache Counter)始终为零。
4.2 复合模型中的混合 SE 查询
在复合模型中,同一个DAX 查询可以同时生成 VertiPaq 和 DirectQuery 的 混合 SE 查询。当 Sales 表为 DirectQuery 模式,其他表为双存储模式时,以下 DAX 查询会生成两种 SE 查询
EVALUATE
ADDCOLUMNS (VALUES ( 'Date'[Calendar Year] ),"Quantity", CALCULATE ( SUM ( Sales[Quantity] ) )
)
- SQL 查询:按 Calendar Year 计算 Quantity 之和,发送到 DirectQuery 数据源。
- xmSQL 查询:VALUES 函数请求的 Calendar Year 名称列表,由 VertiPaq 引擎处理。

Subclass 列用于区分 SE 查询类型。SQL 查询对应 DirectQuery 数据源,通常比 VertiPaq 慢,但可通过聚合优化。
4.3 使用聚合优化 SE 查询
在第 18 章“优化 VertiPaq ”中讲过,聚合可以提升 SE 查询性能,无论是 VertiPaq 还是 DirectQuery 模式。当存在可用聚合时,引擎会尝试用聚合重写原始 SE 查询。若聚合兼容(也就是能够使用聚合数据完成查询),重写成功;否则,执行原始查询。
DAX Studio 能展示聚合的重写尝试,有助于理解聚合为何未按预期工作。例如,在复合模型中执行以下查询:
EVALUATE
SUMMARIZECOLUMNS ('Date'[Calendar Year],"Qty", SUM ( Sales[Quantity] ),"Qty Red", CALCULATE (SUM ( Sales[Quantity] ),'Product'[Color] = "Red")
)
该模型中 Sales 表有按 Date 和 Customer 粒度的聚合。查询计算每个年份的 Qty(总订单量)和 Qty Red(红色产品订单量)。DAX 引擎会在生成 SE 查询之前尝试匹配聚合。如果找到匹配的聚合,查询将被重写为使用聚合的查询。例如,Qty 计算与现有聚合(按日期和客户分组)兼容,因此引擎会生成以下 VertiPaq SE 查询:
SELECT
'Date'[Calendar Year],
SUM ( 'Sales_Agg'[Quantity] )
FROM 'Sales_Agg'
LEFT OUTER JOIN 'Date' ON 'Sales_Agg'[Order Date]='Date'[Date];
如果未找到匹配的聚合,引擎将执行原始 SE 查询(直接查询原始 Sales 表)。下图DAX Studio 报告显示,Qty 计算因与现有聚合(按日期和客户分组)兼容,触发了重写尝试。

聚合通常对 SE 的瓶颈有优化作用,但对 FE(前端)的瓶颈通常没有帮助。
五、深入解析 DAX 查询计划
一开始,我们介绍了逻辑查询计划和物理查询计划。不过,实际中我们较少直接使用这些查询计划,而是更关注SE(存储引擎)查询。因为通过分析SE查询的性能,可以更有效地发现由SE或内存中大数据缓存实现导致的问题,且SE查询比DAX查询计划更易读。但是理解查询计划与SE查询之间的关系对于发现瓶颈、提升查询性能也很重要。
由于逻辑和物理查询计划中的运算符太多,超出了本文的主题,所以不会详细解释。
通常,一个查询计划会生成多个SE查询,而FE(公式引擎)则负责组合不同数据缓存的结果,并执行临时表之间的联接等操作。考虑以下查询,它返回所有Net Price>1000的产品中,每种颜色的产品数量。
EVALUATE CALCULATETABLE (
ADDCOLUMNS (
ALL ( Product[Color] ),
"Units", CALCULATE ( SUM ( Sales[Quantity] ) )
),
Sales[Net Price] > 1000
)
ORDER BY Product[Color]

5.1 逻辑查询计划
逻辑查询计划显示了查询的高级结构,以下是常用操作符:
| 操作符 | 说明 |
|---|---|
| Order | 对结果进行排序操作,根据指定的列对数据进行排序 |
| Scan_Vertipaq | 扫描存储在 VertiPaq(即 Power BI 的列存储引擎)中的数据表,获取指定列的数据 |
| Sum_Vertipaq | 对存储在 VertiPaq 中的数值列进行求和操作 |
| AddColumns | 在表中添加新列,新列的值通过计算得出 |
| Filter_Vertipaq | 对存储在 VertiPaq 中的数据表进行筛选操作,根据指定的条件过滤数据 |
| CalculateTable | 对表进行计算操作,通常用于在筛选上下文等特定条件下对表进行处理 |
| GreaterThan | 比较操作,用于判断一个值是否大于另一个值。 |
| Constant | 常量值,用于表示一个固定的值,例如数字、字符串等。 |
| ColPosition | 列位置操作,用于获取某个列在表中的位置信息。 |
本例生成的逻辑计划查询如下:
Line Logical Query Plan
-- 对最终结果表进行排序(Order),依赖于 Product[Color] 和动态生成的 Units 列。
1 Order: RelLogOp DependOnCols()() 1-2 RequiredCols(1, 2)('Product'[Color], ''[Units])
-- 计算一个表,通常是为了生成一个中间结果,同样依赖于 Product[Color] 和动态生成的 Units 列
2 CalculateTable: RelLogOp DependOnCols()() 1-2 RequiredCols(1, 2)('Product'[Color], ''[Units])
-- 向表中添加新列 Units
3 AddColumns: RelLogOp DependOnCols()() 1-2 RequiredCols(1, 2)('Product'[Color], ''[Units])
-- 扫描 Product[Color] 列的数据
4 Scan_Vertipaq: RelLogOp DependOnCols()() 1-1 RequiredCols(1)('Product'[Color])
-- 对 Sales[Quantity] 列进行求和操作,计算每个 Product[Color] 对应的销售数量总和。
-- Integer DominantValue=BLANK表示结果是整数类型,且在数据中空白值(BLANK)是占主导地位的。
5 Sum_Vertipaq: ScaLogOp DependOnCols(1)('Product'[Color]) Integer DominantValue=BLANK
-- 扫描 Product[Color] 和 Sales[Quantity] 列的数据
6 Scan_Vertipaq: RelLogOp DependOnCols(1)('Product'[Color]) 2-28 RequiredCols(1, 9)('Product'[Color], 'Sales'[Quantity])
-- 获取 Sales[Quantity] 列的数据(整数类型,没有特别占主导地位的值)
7 'Sales'[Quantity]: ScaLogOp DependOnCols(9)('Sales'[Quantity]) Integer DominantValue=NONE
-- 筛选操作,根据 Sales[Net Price] > 1000 的条件对数据进行筛选。
8 Filter_Vertipaq: RelLogOp DependOnCols()() 0-0 RequiredCols(0)('Sales'[Net Price])
-- 扫描 Sales[Net Price] 列的数据。
9 Scan_Vertipaq: RelLogOp DependOnCols()() 0-0 RequiredCols(0)('Sales'[Net Price])
-- 比较操作,判断 Sales[Net Price] 是否大于(GreaterThan) 1000。,结果是布尔类型(Boolean)
10 GreaterThan: ScaLogOp DependOnCols(0)('Sales'[Net Price]) Boolean DominantValue=NONE
-- 获取Net Price列的值,为货币类型(Currency),没有特别占主导地位的值。
11 'Sales'[Net Price]: ScaLogOp DependOnCols(0)('Sales'[Net Price]) Currency DominantValue=NONE
-- 常量值 1000(Constant),用于与 Sales[Net Price] 进行比较。
12 Constant: ScaLogOp DependOnCols()() Currency DominantValue=1000
-- ColPosition<'Product'[Color]> 表示获取 Color 列的位置信息(字符串类型),用于最终排序,
13 ColPosition<'Product'[Color]>: ScaLogOp DependOnCols(1)('Product'[Color]) String DominantValue=NONE
以第一行为例,逻辑查询计划标准格式,通常由以下几个部分组成:
- 操作名称:描述操作的类型,如
Order、Filter、Scan等。 - 操作类型:描述操作的类别
RelLogOp表示关系逻辑操作(Relational Logical Operation),即对表(关系)进行的操作,例如排序、筛选、连接等。ScaLogOp表示标量逻辑操作(Scalar Logical Operator ),用于处理单个值
- 依赖列:描述操作依赖的列,
DependOnCols()()表示不依赖任何列。 - 输入输出范围:描述操作的输入和输出列的范围(从1开始计数)。 1-2 表示输入列的起始索引为1,输出列的结束索引为2。这一行的1-2表示排序操作的输入和输出都涉及两列,具体是哪些列由后面的 RequiredCols 定义。
- 所需列:描述操作需要的列,
RequiredCols(1, 2)('Product'[Color], ''[Units])表示需要第1列和第2列,分别是Product 表中的 Color 列,以及动态生成的列 Units列。
在此示例中,逻辑查询计划包括三个 Scan_Vertipaq 操作,两个数据缓存。
- 第 4 行的 Scan_Vertipaq:扫描产品颜色列,获取所有产品颜色的列表。
- 第 6 行的 Scan_Vertipaq:扫描产品颜色和销售数量两列。这个操作的目的是计算每种颜色的销售数量。由于数据来自不同表中的两列,所以需要在两个或多个表之间进行联接。
- 第 9 行的 Scan_Vertipaq:用于过滤,它不会生成单独的数据缓存。
5.2 SE查询
在逻辑查询计划之后,分析器从存储引擎(SE)接收事件,生成两个xmSQL 查询,这两个查询生成两个不同的数据缓存。
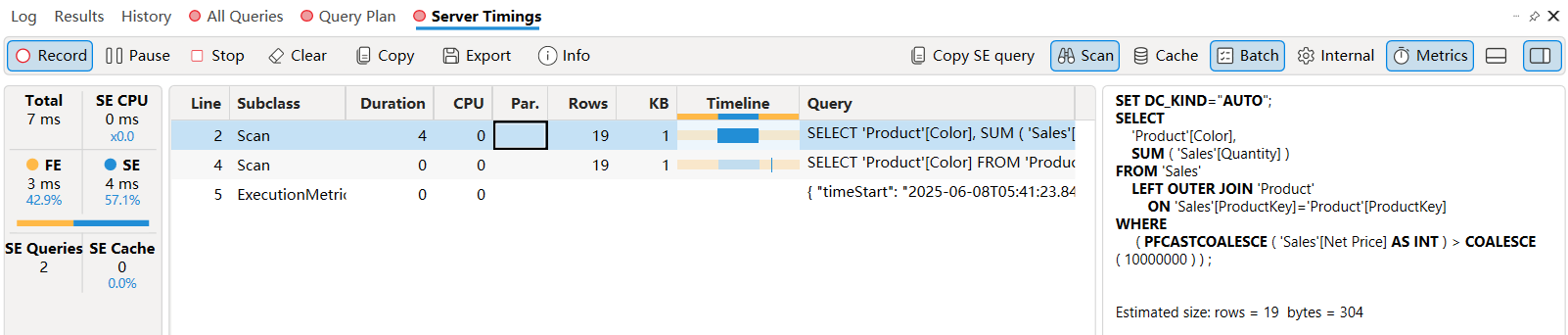
SELECT'Product'[Color],SUM ( 'Sales'[Quantity] )
FROM 'Sales'LEFT OUTER JOIN 'Product'ON 'Sales'[ProductKey]='Product'[ProductKey]
WHERE( PFCASTCOALESCE ( 'Sales'[Net Price] AS INT ) > COALESCE ( 10000000 ) ) ;
SELECT'Product'[Color]
FROM 'Product';
第一个查询用于生成一个表,包括产品颜色和销售数量的总和两列。因为数据涉及两个表,所以查询使用 ProductKey 列将 Sales 和 Product 表连接起来。由于此查询使用LEFT OUTER JOIN(左外连接,左表所有行+右表匹配行),这意味着只有在 Sales 表中存在记录的产品颜色才会被包含在结果中。
为了确保结果中包含所有产品颜色(即使某些颜色在 Sales 表中没有记录),我们需要第二个查询来获取完整的颜色列表,即第二个查询返回所有产品颜色的列表,与 Sales 表无关。
如果用普通的 SQL 代码,我们会这样写:
SELECT Product.Color, SUM(Sales.Quantity)
FROM Product
LEFT OUTER JOIN Sales
ON Sales.ProductKey = Product.ProductKey
WHERE Sales.NetPrice > 1000
GROUP BY Product.Color
ORDER BY Product.Color;
在这个查询中,Product 表放在左联接的左侧,这样可以确保结果中包含所有产品颜色,即使某些颜色在 Sales 表中没有记录。
SE查询的限制:存储引擎只能在数据模型中具有关系的表之间生成xmSQL查询,并且进行表连接的时候,总是把关系中“多”的那一端的表放在连接条件的左侧。这样可以保证即使 Product 表中缺少ProductKey ,结果仍将包括那些缺少产品的销售额;这些销售额会在结果里以空白值的形式给出。
5.3 物理查询计划
上一节介绍了为何会生成两个SE查询,这一节结合物理查询计划,进行更深入的分析。
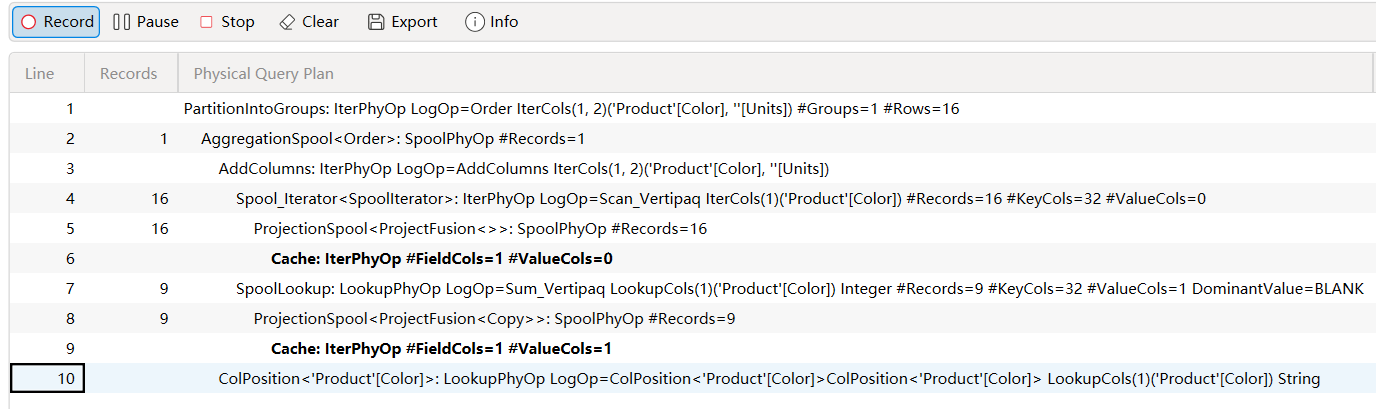
| 行号 | 记录数 | 操作符 | 说明 |
|---|---|---|---|
| 1 | PartitionIntoGroups | 将数据分组,准备进行排序操作。 | |
| 2 | 1 | AggregationSpool | 执行排序操作,返回1条记录。 |
| 3 | AddColumns | 添加新列(Units),准备进行计算。 | |
| 4 | 16 | Spool_Iterator | 加载所有产品颜色(16种),并将其存储在缓存中。 |
| 5 | 16 | ProjectionSpool<ProjectFusion<>> | 处理缓存中的数据,返回16条记录。 |
| 6 | Cache | 缓存所有产品颜色(16种)。 | |
| 7 | 9 | SpoolLookup | 执行聚合操作(如数量总和),返回10条记录和两列。 |
| 8 | 9 | ProjectionSpool<ProjectFusion> | 处理缓存中的数据,返回10条记录。 |
| 9 | Cache | 缓存筛选后的数据(10条记录,两列)。 | |
| 10 | ColPosition<‘Product’[Color]> | 获取产品颜色列的位置信息,用于排序操作。 |
- Cache 操作符:表示查询引擎在何处使用了存储引擎(SE)提供的数据缓存。虽然我们无法直接看到每个操作对应的SE查询,但可以通过分析其他信息来推断这些操作的具体内容。
- 第6行:Cache 操作符返回一列,包含16种产品颜色名称。这表示在没有筛选条件的情况下,所有产品颜色都被加载到缓存中。
- 第9行:Cache 操作符返回10行和两列,仅包含在“净价”大于1000的条件下,在 Sales 表中至少有一笔交易的产品颜色名称。这表示筛选后只有部分产品颜色被加载到缓存中。
- ProjectionSpool 操作符:用于处理缓存中的数据。它返回的记录数(#Records)表示缓存中的行数。这个数字在物理查询计划的 #Records 属性中显示,也在DAX Studio的“记录”列中报告。
- Spool_Iterator操作符(第4行):Spool_Iterator 操作符加载了所有产品颜色(16种),并将其存储在缓存中。
- SpoolLookup操作符(第7行):执行聚合操作(如数量总和),并将结果存储在缓存中。这个操作返回10行和两列:一列是产品颜色,另一列是聚合结果。
最终总结:
-
加载所有产品颜色
- 第4行:查询引擎加载了所有16种产品颜色,并将其存储在缓存中。
- 第6行:这些数据被缓存起来,以便后续操作使用。
-
执行聚合操作
- 第7行:查询引擎对筛选后的数据(净价大于1000的销售记录)进行聚合操作,计算每个产品颜色的销售数量总和。
- 第9行:聚合结果被缓存起来,包含10条记录和两列:产品颜色和销售数量总和。
-
排序操作
- 第10行:查询引擎获取产品颜色列的位置信息,准备对结果进行排序。
5.4 FE查询
FE负责组合不同数据缓存的结果,并执行临时表之间的联接等操作。回顾一下在查询计划和 SE 查询中的信息,可以知道:
- FE消耗两个数据缓存,对应物理查询计划中的Cache节点
- 第一个数据缓存包含 16 种产品颜色名称。
- 第二个数据缓存包含 10 行和两列,分别是产品颜色和销售数量的总和。
- 迭代产品颜色列表,执行查找操作
- FE 迭代产品颜色列表(缓存1),对于每种颜色,执行查找操作,从缓存2中获取相应的销售数量。
5.5 查询优化
虽然 SE 查询可以并行化执行,但 FE 是单线程的。这意味着 FE 一次只能处理一个请求。因此,在设计查询时,应尽量减少 FE 的工作负载,以提高查询性能。为了识别这些潜在的性能瓶颈,可以通过查看逻辑查询计划中记录数最多的操作符来定位问题。DAX Studio 提供了方便的工具来提取和排序这些记录数,帮助优化查询。
5.5.1 使用 INTERSECT 建立虚拟关系
数据模型中关系的存在对于查询性能至关重要。当关系不可用时,查询会变得更加复杂。例如,考虑一个查询,它返回与上一节示例查询相同的结果,但数据模型中 Product 和 Sales 表之间没有关系。此时,可以使用INTERSECT 建立虚拟关系(第15 章“高级关系”中“使用 INTERSECT 传输过滤器”部分)
DEFINEMEASURE Sales[Units] =CALCULATE (SUM ( Sales[Quantity] ),INTERSECT ( ALL ( Sales[ProductKey] ), VALUES ( 'Product'[ProductKey] ) ),CROSSFILTER ( Sales[ProductKey], 'Product'[ProductKey], NONE ))EVALUATE
ADDCOLUMNS ( ALL ( 'Product'[Color] ), "Units", [Units] )
ORDER BY 'Product'[Color]
CROSSFILTER:设置 Sales 表和Product表的ProductKey键列交叉筛选方向为NONE,即禁用关系INTERSECT:取Sales[ProductKey]集合和当前上下文中’Product’[ProductKey]集合的交集,在两个表之间建立一个虚拟的筛选关系,确保只计算与当前 Product 表上下文中的产品键值对应的销售数量。
此DAX查询生成四个SE 查询:

-- 检索所有销售记录中的 ProductKey
SELECT'Sales'[ProductKey]
FROM 'Sales';-- 检索所有产品颜色
SELECT'Product'[Color]
FROM 'Product';-- 检索产品表中的 ProductKey 和颜色。
SELECT'Product'[ProductKey],'Product'[Color]
FROM 'Product';-- 对特定 ProductKey 的销售数量进行汇总
SELECT'Sales'[ProductKey],SUM ( 'Sales'[Quantity] )
FROM 'Sales'
WHERE'Sales'[ProductKey] IN ( 2184, 2331, 222, 1282, 572, 1625, 307, 393, 443, 679..[1,050 total values, not all displayed] ) ;
在上述 查询中,有一个
WHERE条件,它看起来似乎没有实际作用,因为在 DAX 查询中并没有对产品应用任何过滤器。然而,在现实世界的应用场景中,通常会有其他活动的过滤器作用于产品表或其他表。这个 WHERE 条件的存在,目的是为了提取与查询相关的销售记录,从而减少返回给公式引擎(FE)的数据缓存的大小。
5.5.2 使用 TREATAS 建立虚拟关系
使用INTERSECT 建立虚拟关系只是为了演示,一般来说,使用TREATAS是更优的方案。它将更多的操作移至 SE,从而减少 FE 的负担。
DEFINEMEASURE Sales[Units] =CALCULATE (SUM ( Sales[Quantity] ),TREATAS ( VALUES ( 'Product'[ProductKey] ), Sales[ProductKey] ),CROSSFILTER ( Sales[ProductKey], 'Product'[ProductKey], NONE ))EVALUATE
ADDCOLUMNS ( ALL ( 'Product'[Color] ), "Units", [Units] )
ORDER BY 'Product'[Color]
使用 TREATAS 的优势在于:
- 减少 SE 查询的数量:仅生成三个 SE 查询,而不是四个。
- 减少数据缓存的大小:返回给 FE 的数据缓存更小,从而提高了性能。

批处理事件是对之前扫描事件的总结。在第 7 行的批处理事件中,包含了前三个扫描事件的内容。这意味着,这些操作被合并到了一个批处理中,从而减少了与 SE 的交互次数:
DEFINE TABLE '$TTable3' :=
SELECT'Product'[ProductKey],'Product'[Color]
FROM 'Product',DEFINE TABLE '$TTable4' :=
SELECTRJOIN ( '$TTable3'[Product$ProductKey] )
FROM '$TTable3'REVERSE BITMAP JOIN 'Sales' ON '$TTable3'[Product$ProductKey]='Sales'[ProductKey],-- 建立浅层关系
CREATE SHALLOW RELATION '$TRelation1'MANYTOMANYFROM 'Sales'[ProductKey]TO '$TTable3'[Product$ProductKey],DEFINE TABLE '$TTable1' :=
SELECT'$TTable3'[Product$Color],SUM ( '$TTable2'[$Measure0] )
FROM '$TTable2'INNER JOIN '$TTable3'ON '$TTable2'[Sales$ProductKey]='$TTable3'[Product$ProductKey]
REDUCED BY
'$TTable2' :=
SELECT'Sales'[ProductKey],SUM ( 'Sales'[Quantity] )
FROM 'Sales'
WHERE'Sales'[ProductKey] ININDEX '$TTable4'[$SemijoinProjection];
CREATE SHALLOW RELATION语句创建了一个浅层关系,这是一个临时的关系,用于在查询执行过程中连接不同的表。在这个例子中,它创建了一个从 Sales 表到临时表 $TTable3 的多对多关系。REDUCED BY:在 SE 中执行聚合操作,直接返回每个 ProductKey 的销售数量总和。
使用INTERSECT时,要执行4个SE查询,增加了 FE 的负担。TREATAS 通过在 SE 中创建一个临时表,并在 SE 中执行聚合操作,减少了需要返回给 FE 的数据量(减少数据缓存),以及物理查询计划的行数.
物理计划行数从37减为10。考虑到此示例查询计划非常复杂,所以本文没有详细介绍。有关查询计划内部的更多详细信息,详见《White paper: Understanding DAX Query Plans》、《White paper: Understanding Distinct Count inDAX Query Plans》。