外部排序全解析:从基础到优化策略(王道)
外部排序全解析:从基础到优化策略
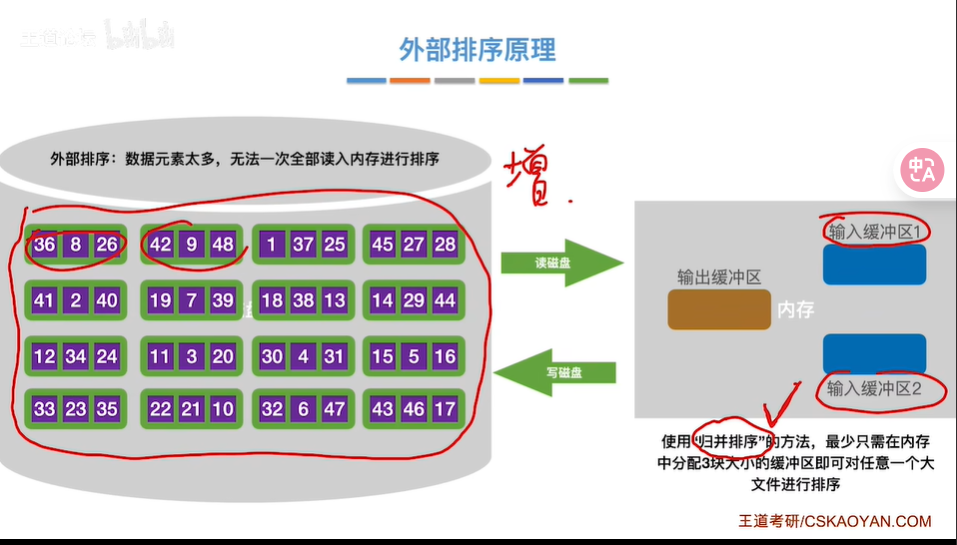
在处理大规模数据时,内存往往无法一次性容纳全部数据,传统的内部排序算法难以胜任。外部排序应运而生,主要通过“排序-归并”的策略,将数据分块处理,最终合并为有序的数据集。
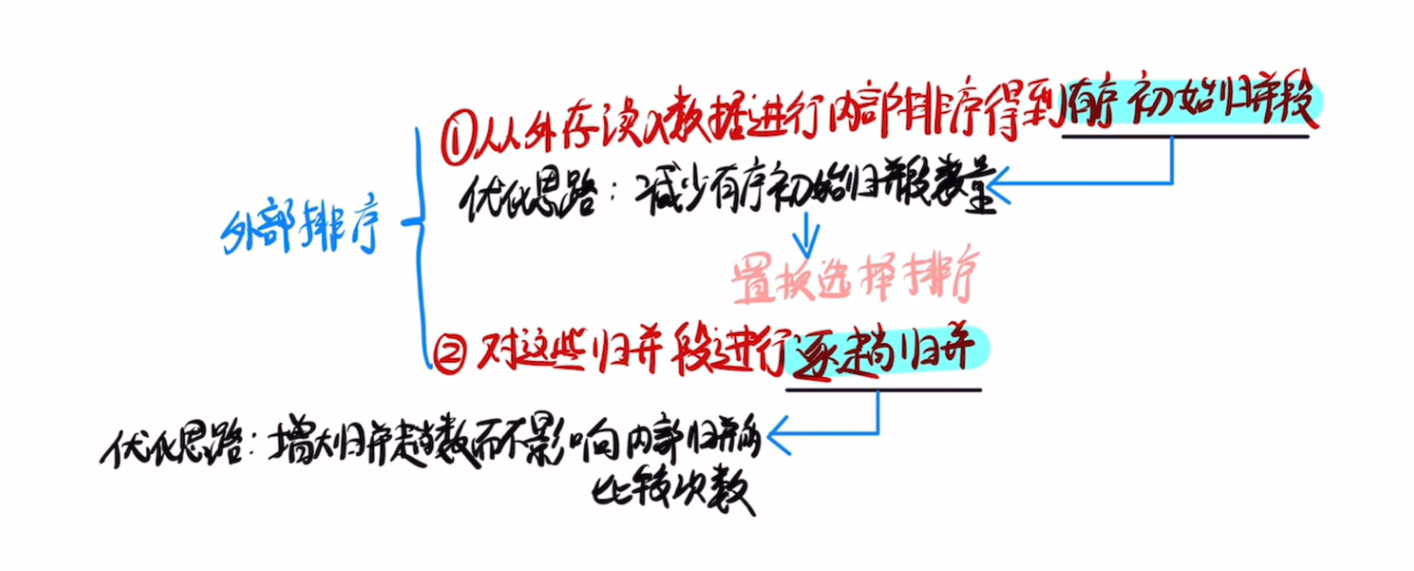
一、外部排序的基本流程
1. 生成初始归并段
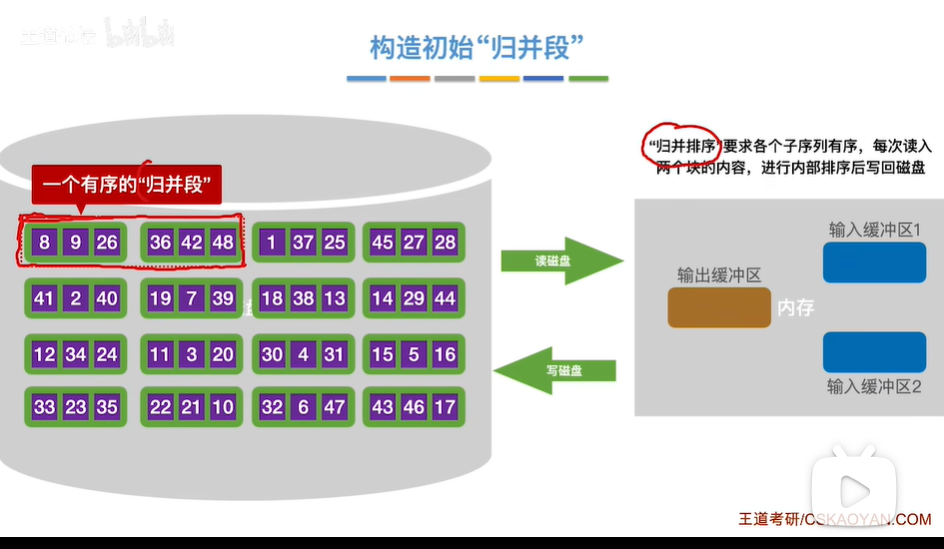
- 分块读取:将外部存储中的数据按内存容量分块读取,每次读取一块数据到内存中。
- 内部排序:使用内部排序算法(如快速排序、堆排序)对读取的数据进行排序。
- 写回外存:将排序后的数据写回外部存储,形成有序的初始归并段。
2. 多路归并排序
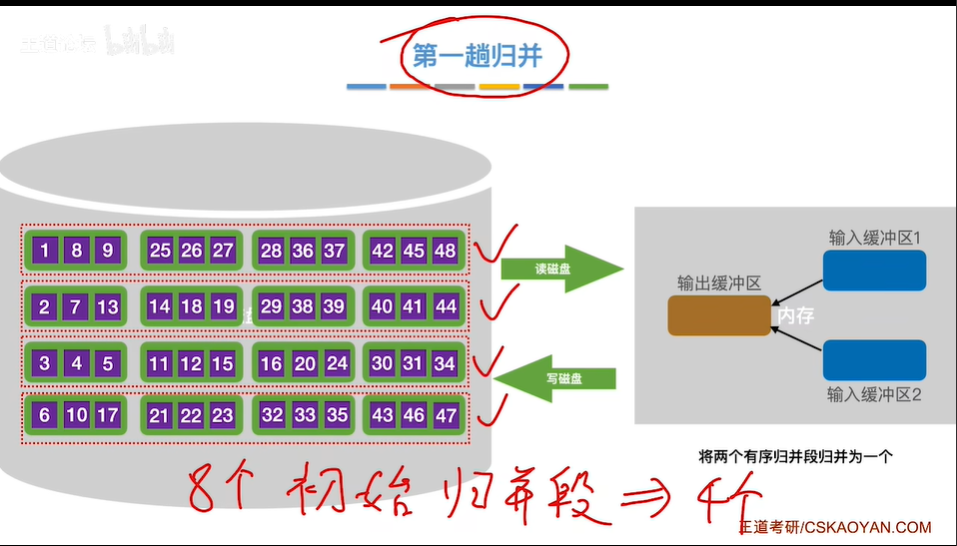
- 归并操作:将多个初始归并段进行归并,逐步合并成更大的归并段,直到最终形成一个有序的完整文件。
- 缓冲区管理:为每个归并段分配输入缓冲区,并设置输出缓冲区,合理管理内存和外存之间的数据交换。
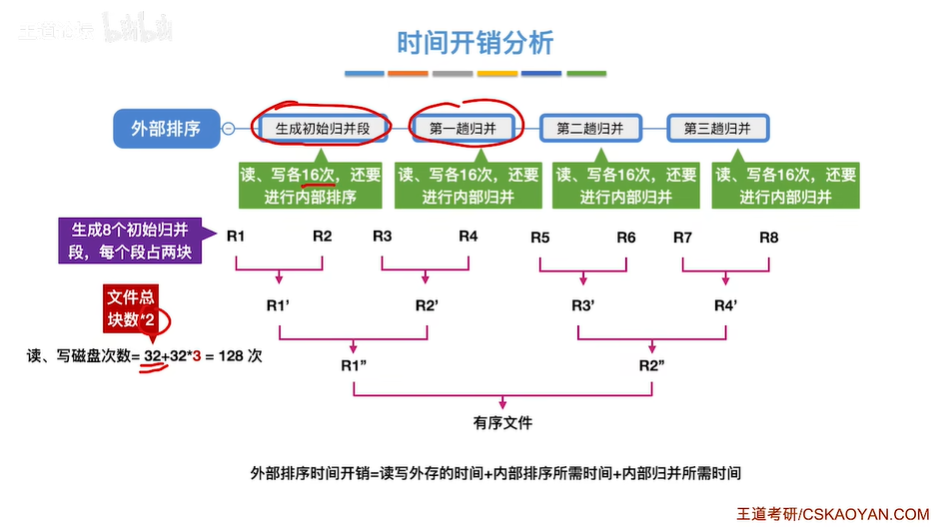
二、优化策略
1. 置换选择排序
置换选择排序通过在内存中维护一个最小堆,动态生成长度大于内存容量的归并段,平均长度约为内存容量的两倍,从而减少归并的趟数。
2. 多路归并与败者树
- 多路归并:一次合并多个归并段,减少归并的趟数。
- 败者树:在多路归并中,使用败者树结构高效地选出当前最小的记录,减少关键字比较次数。
3. 最佳归并树
最佳归并树通过构建最优的归并顺序,最小化总的磁盘I/O次数。构建方法类似于哈夫曼树,将初始归并段视为叶子节点,权值为段的长度,构建严格的k叉树。若叶子节点数不满足构建要求,可添加权值为0的虚拟归并段。
补充虚段的数量计算公式如下:(blog.csdn.net)
-
设初始归并段数量为 $n$,归并路数为 $k$,则:
-
若 ( n − 1 ) m o d ( k − 1 ) = 0 (n - 1) \mod (k - 1) = 0 (n−1)mod(k−1)=0,则不需要添加虚段。(blog.csdn.net)
-
否则,需要添加 ( k − 1 ) − ( ( n − 1 ) m o d ( k − 1 ) ) (k - 1) - ((n - 1) \mod (k - 1)) (k−1)−((n−1)mod(k−1)) 个虚段。(blog.csdn.net, blog.csdn.net)
-
参考资料:
-
外部排序快速入门详解:基本原理,败者树,置换-选择排序,最佳归并树(blog.csdn.net)
-
最佳归并树虚段数 - CSDN博客(blog.csdn.net)
三、性能分析
- 归并趟数:使用置换选择排序生成的归并段更长,归并趟数减少。
- 时间开销:败者树在多路归并中减少关键字比较次数,提高归并效率。
- 空间开销:需要为每个归并段分配输入缓冲区,以及一个输出缓冲区。败者树和最佳归并树的构建需要额外的内存空间,但相对于整体排序过程,这些开销是可以接受的。
四、总结
外部排序通过合理的分块、排序和归并策略,结合置换选择排序、败者树和最佳归并树等优化技术,有效地处理了大规模数据的排序问题。理解并掌握这些技术,对于在实际应用中处理大数据排序任务具有重要意义。