论文阅读:Matting by Generation
今天介绍一篇关于 matting 抠图的文章,抠图也算是计算机视觉里面非常经典的一个任务了。从早期的经典算法到如今的深度学习算法,已经有很多的工作和这个任务相关。这两年 diffusion 模型很火,大家又开始用 diffusion 模型做各种 CV 任务了,也包括抠图这个经典任务。
Abstract
本文提出了一种图像抠图的创新方法,将传统基于回归的任务重新定义为生成式建模挑战。我们的方法利用潜在扩散模型的能力,结合大量预训练知识来规范抠图过程。我们提出了新颖的架构创新,使模型能够生成具有更高分辨率和细节的遮罩(matte)。所提方法具有通用性,可执行无引导和有引导的图像抠图,适应多种附加线索。我们在三个基准数据集上的综合评估表明,该方法在定量和定性方面均表现出优异性能。结果不仅反映了我们方法的稳健有效性,还突出了其生成视觉效果逼真、接近照片级质量遮罩的能力。
Introduction

- 图 1 生成式抠图。我们以条件生成的方式破解了无需三值图(trimap)的抠图问题,这有别于以往基于回归的方式。仅以一幅图像作为输入,借助丰富的生成先验知识,我们的方法能够自动提取前景(如人物)并生成高质量的边界细节,实现逼真的图像合成效果。在这个示例中,与人工标注结果相比,我们的结果呈现出更清晰的细节,且与输入图像的契合度更高。
图像抠图作为计算机视觉中的一个基础问题,已被研究数十年 [Li 等人,2023d]。它支持许多实际应用,如视觉效果合成 [Li 等人,2022a]、图像编辑 [Kawar 等人,2023] 等。其目标是从输入图像中预测前景和 alpha 遮罩(透明度蒙版)。这是一个典型的不适定逆问题 —— 仅有输入图像已知。正向模型为 Porter 和 Duff 于 1984 年提出的合成方程,形式如下:
C = α F + ( 1 − α ) B (1) C = \alpha F + (1-\alpha) B \tag{1} C=αF+(1−α)B(1)
其中, 𝐶 𝐶 C 为输入图像, 𝐹 𝐹 F 为前景, 𝐵 𝐵 B 为背景, α ∈ [ 0 , 1 ] \alpha \in [0, 1] α∈[0,1] 为线性组合系数。该问题的核心挑战源于其不适定性 —— 这是一种混合难题:既要确定前景的位置,又要推断边界区域的不透明度值。
现有方法(无论是传统方法还是基于学习的方法)均需借助额外输入来缓解不适定性问题。例如,可通过捕获另一张背景图像来减少未知参数𝐵的影响 [Lin 等人,2021;Sengupta 等人,2020],或通过用户标注的三分图(trimap)为𝛼添加先验信息。除利用人工提供的额外输入外,部分方法 [Li 等人,2023a;Yu 等人,2021] 还采用其他算法(如 Segment Anything(SAM)[Kirillov 等人,2023a])生成的粗糙掩码,旨在减轻分割任务的训练负担并聚焦于边界遮罩质量。然而,这些方法仍存在局限性,主要原因在于其依赖分割网络的准确性 —— 初始分割不精确会显著影响抠图结果质量(尤其是在边界区域)。这种依赖性引发了对 “仅依靠粗糙分割掩码能否实现高质量抠图” 的有效性质疑。
近年来,端到端抠图方法 [Ke 等人,2022;Li 等人,2021] 试图通过消除对额外输入的依赖来解决上述局限性,从而减少对人工生成数据的依赖。然而,由于任务本身的复杂性,从头开发一种有效的端到端抠图算法仍面临重大挑战。这些方法通常采用以下策略:将应用领域限定于人像图像 [Li 等人,2021;Ma 等人,2023],或引入隐式分割先验 [Ke 等人,2022]。尽管这些方法减少了分割与抠图之间的模糊性,并促使模型更有效地捕捉边界细节,但如图 1 所示,实现高质量的边界遮罩仍然困难。现有抠图方法的主要问题在于对边界区域的处理 —— 由于低可见性(对比度、图像质量)和不完美的人工标注等因素,边界区域往往难以处理。这些局限性可能导致合成效果不自然,凸显了对更复杂解决方案的需求。
在本文中,我们提出了一种简单而有效的生成式抠图技术,将传统的回归问题转化为条件生成建模问题,利用融合了图像语义和遮罩细节预训练知识的扩散模型实现抠图。该方法具有以下核心优势:
- 生成模型的不确定性处理能力,生成模型擅长捕捉数据中的固有不确定性,相比回归模型能更高效地学习遮罩分布。这一特性可缓解不完美标签(如人工或机器生成的真实遮罩 GT)的负面影响 —— 这类标签常基于低层图像特征生成,难免存在缺陷(如图 1 所示)。使用有瑕疵的 GT 训练回归模型易导致过拟合,产生次优结果(如图 2 所示)。而我们的生成先验使模型能够识别语义正确的边界,甚至生成质量超越原始 GT 遮罩的结果。
- 预训练扩散模型的图像分布理解,我们的预训练扩散模型基于数十亿图像的海量数据训练,能够捕捉更全面的图像分布。这种对图像的深度理解可规范训练过程,提供更细致的低层特征和语义信息,使模型在图像可见性低(如低对比度、低质量)的场景中仍能生成细节丰富的遮罩,显著提升复杂条件下的鲁棒性。
- 无引导与有引导抠图的灵活性,方法支持无引导和有引导两种模式:1) 无引导模式:多数情况下无需额外提示即可完成精准抠图,降低对人工标注或辅助输入的依赖;2) 有引导模式:当前景语义模糊时,用户可通过补充交互(如粗略标注)引导模型提取目标遮罩,平衡自动化与可控性。通过将抠图重新定义为生成任务,我们的方法突破了传统回归框架的局限性,为高质量边界处理和复杂场景泛化提供了新路径。

- 图 2 不完美的人工标注。训练数据通常要么模糊不清,要么缺乏某些细节。因此,基于回归的模型会对不完美的真实标签产生过拟合现象。
Method
我们以条件生成的方式解决抠图问题,通过训练扩散模型对 alpha 遮罩的分布 p ( α ) p(\alpha) p(α) 进行联合建模,并根据输入图像 x \mathbf{x} x 从该分布中生成 alpha 遮罩 α \alpha α。得益于模型的生成能力和预训练的丰富图像知识,无需引导即可准确定位前景并生成具有精细边界细节的 alpha 遮罩(第 3.2 节)。我们定制的高分辨率推理技术支持处理任意分辨率的图像(第 3.3 节)。除无引导抠图外,我们还可将三分图、粗掩码、涂鸦和文本等额外引导信息无缝集成到已训练模型中,以缓解抠图中的语义模糊问题(第 3.4 节)。
Generative Formulation
我们使用预训练的潜在扩散模型 [Rombach 等人,2022] 对 alpha 遮罩的分布 p ( α ) p(\alpha) p(α) 进行建模。给定一个服从分布 α ∼ p ( α ) \alpha ∼ p(\alpha) α∼p(α) 的 alpha 遮罩,我们通过预训练的编码器 E \mathcal{E} E 对其进行编码,以获得其潜在表示 z ( α ) = E ( α ) z(\alpha)=\mathcal{E}(\alpha) z(α)=E(α)。接下来,我们对该潜在表示应用扩散过程。设 z 0 = z ( α ) z_{0} = z(\alpha) z0=z(α),前向过程会在 𝑇 𝑇 T 步中将少量高斯噪声逐步添加到 alpha 遮罩的潜在表示 z 0 z_0 z0 中。因此,构建了一个离散马尔可夫链 { z 0 , z 1 , . . . z T } \{z_0, z_1,...z_T \} {z0,z1,...zT},使得
z t = 1 − β t z t − 1 ( α ) + β t ϵ t − 1 = σ t z 0 + 1 − σ t ϵ (2) \mathbf{z}_t = \sqrt{1 - \beta_t} \mathbf{z}_{t-1}^{(\boldsymbol{\alpha})} + \sqrt{\beta_t} \boldsymbol{\epsilon}_{t-1} = \sqrt{\sigma_t} \mathbf{z}_0 + \sqrt{1 - \sigma_t} \boldsymbol{\epsilon} \tag{2} zt=1−βtzt−1(α)+βtϵt−1=σtz0+1−σtϵ(2)
其中步骤 t ∈ { 1 , … , T } t \in \{1, \ldots, T\} t∈{1,…,T}, ϵ t \boldsymbol{\epsilon}_t ϵt、 ϵ ∼ N ( 0 , I ) \boldsymbol{\epsilon} \sim \mathcal{N}(0, \mathbf{I}) ϵ∼N(0,I) 为高斯噪声,且 σ t : = ∏ s = 1 t β s \sigma_t := \prod_{s = 1}^t \beta_s σt:=∏s=1tβs 。方差调度 { β 1 , … , β T } \{\beta_1, \ldots, \beta_T\} {β1,…,βT} 使得能够以多种尺度向 z 0 \mathbf{z}_0 z0 添加高斯噪声 。为了对 z ( α ) \mathbf{z}(\boldsymbol{\alpha}) z(α) 的分布进行建模,反向过程训练一个基于分数的模型 ϵ θ \boldsymbol{\epsilon}_\theta ϵθ,以预测在步骤 t 中引入到含噪样本 z t \mathbf{z}_t zt 的噪声。训练的目标是最小化
E ϵ ∼ N ( 0 , I ) , t , z 0 [ ∥ ϵ t − ϵ θ ( z t , t ) ∥ 2 2 ] (3) \mathbb{E}_{\boldsymbol{\epsilon} \sim \mathcal{N}(0, \mathbf{I}), t, \mathbf{z}_0} \left[ \left\| \boldsymbol{\epsilon}_t - \boldsymbol{\epsilon}_\theta(\mathbf{z}_t, t) \right\|_2^2 \right] \tag{3} Eϵ∼N(0,I),t,z0[∥ϵt−ϵθ(zt,t)∥22](3)
在一组 alpha 遮罩 { α i } i = 1 N ∼ p ( α ) \{\boldsymbol{\alpha}_i\}_{i=1}^N \sim p(\boldsymbol{\alpha}) {αi}i=1N∼p(α) 上训练模型,能够对其分布 p ( α ) p(\boldsymbol{\alpha}) p(α) 进行建模。训练完成后,我们可以执行祖先采样 [Song 等人,2020],从正态分布变量 z T ∈ N ( 0 , I ) \mathbf{z}_T \in \mathcal{N}(0, \mathbf{I}) zT∈N(0,I) 生成样本 z 0 \mathbf{z}_0 z0。随后,将 z 0 \mathbf{z}_0 z0 输入解码器 D,即可得到一个服从分布 p ( α ) p(\boldsymbol{\alpha}) p(α) 的遮罩 α ^ \hat{\boldsymbol{\alpha}} α^。
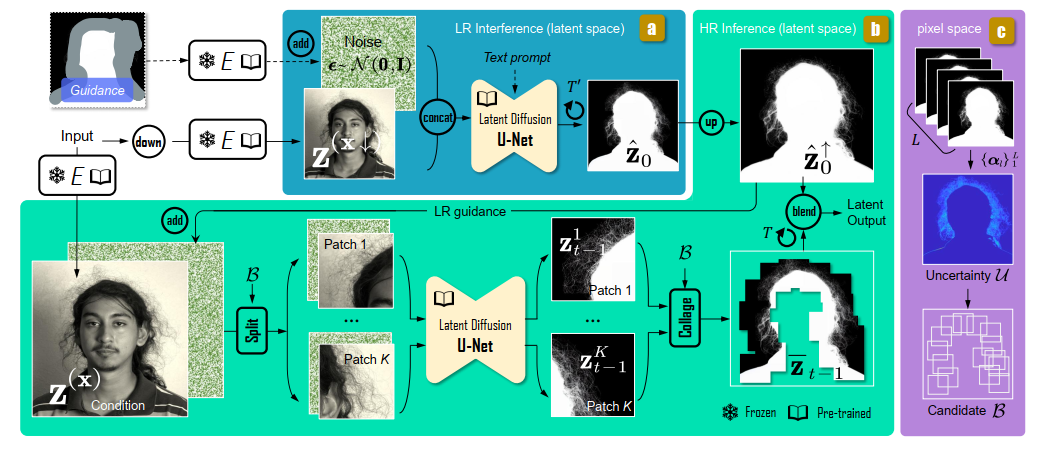
- 图 3 (a) 若不需要极高质量的遮罩,或计算预算有限,可单独使用低分辨率推理路径。输入为下采样图像 x ↓ \mathbf{x}^\downarrow x↓ 的低分辨率潜在特征 z ( x ↓ ) \mathbf{z}(\mathbf{x}^\downarrow) z(x↓) 以及采样噪声 ϵ t \boldsymbol{\epsilon}_t ϵt 。若存在空间引导 c S \mathbf{c}_S cS ,我们会将其与采样噪声结合,作为含噪样本。若提供文本提示 c T \mathbf{c}_T cT ,则会将其输入 U-Net 。该路径的输出是去噪后的潜在特征 z ^ 0 \hat{\mathbf{z}}_0 z^0 ,此路径仅需少量步骤( T ′ ∼ 10 T' \sim 10 T′∼10 步 )。© 我们使用不同随机种子多次执行该步骤,在像素空间得到 L 个预测结果。借助这些结果,估计不确定性映射 U \mathcal{U} U ,以及候选区域集合 B = { b i } i = 1 B \mathcal{B} = \{b_i\}_{i=1}^B B={bi}i=1B 。(b) 高分辨率路径。我们先将上采样后的潜在特征与采样噪声相加。接着,依据 B \mathcal{B} B ,将高分辨率潜在输入和噪声分割为重叠补丁。这些补丁分别输入扩散去噪网络。最后,合并所有去噪后的补丁,得到拼接结果。在每个去噪步骤 t ∈ { 1 , … , T } t \in \{1, \ldots, T\} t∈{1,…,T} 中,都执行 “分割” 和 “拼接” 操作。若低分辨率(LR)路径中使用了文本提示,此处会采用特定文本提示 “增强细节” 。
Conditional Generation with a Single Input Image
抠图任务旨在生成与给定输入图像 x 对应的 alpha 遮罩,而非生成随机的 alpha 遮罩。因此,我们将生成过程以输入图像 x 为条件。具体而言,我们将输入图像 x x x 的潜在表示 z ( x ) : = E ( x ) z(x) := E(x) z(x):=E(x) 与含噪样本 z t z_t zt 进行拼接,然后将拼接后的张量输入模型。为了让模型学习生成以输入图像 x x x 为条件的 alpha 遮罩 α \boldsymbol{\alpha} α,我们使用配对数据 { ( x i , α i ) } i = 1 N ∈ p data \{(x_i, \boldsymbol{\alpha}_i)\}_{i=1}^N \in p_{\text{data}} {(xi,αi)}i=1N∈pdata 训练模型,通过最小化以下损失函数来实现:
L = E ϵ ∼ N ( 0 , I ) , t , z 0 , z ( x ) [ ∥ ϵ t − ϵ θ ( z t , z ( x ) , t ) ∥ 2 2 ] (4) \mathcal{L} = \mathbb{E}_{\boldsymbol{\epsilon} \sim \mathcal{N}(0, \mathbf{I}), t, \mathbf{z}_0, \mathbf{z}(x)} \left[ \left\| \boldsymbol{\epsilon}_t - \boldsymbol{\epsilon}_\theta(\mathbf{z}_t, \mathbf{z}(x), t) \right\|_2^2 \right] \tag{4} L=Eϵ∼N(0,I),t,z0,z(x)[∥ϵt−ϵθ(zt,z(x),t)∥22](4)
我们使用来 Stable Diffusion [Rombach 等人,2022] 的预训练权重初始化模型 ϵ θ \boldsymbol{\epsilon}_\theta ϵθ。在十亿级自然图像 [Schuhmann 等人,2022] 上学习到的权重,具备丰富的图像语义和细节知识 。为了使基于去噪分数的模型 ϵ θ \boldsymbol{\epsilon}_\theta ϵθ 适配 alpha 遮罩生成任务,我们通过复制其输入层来扩展模型架构,这些新增层的权重初始化为 0 。完成这一修改后,我们继续对基于去噪分数的模型进行微调 。训练过程结束后,借助祖先采样和解码操作,我们能够基于输入图像 x x x,从条件分布 p ( α ∣ x ) p(\boldsymbol{\alpha} | x) p(α∣x) 中生成样本 α ^ \hat{\boldsymbol{\alpha}} α^
HR Inference with LR Guidance
当前图像分辨率通常很高,往往超过 2K。将扩散模型应用于此类高分辨率(HR)输入需要大量计算资源,而这些资源并非随时可得。使用低分辨率(LR)图像进行推理,对于生成具有精细边界的遮罩而言,效果欠佳。为解决这一问题,我们提出一种利用基于补丁推理的高分辨率推理方法。然而,将像 MultiDiffusion [Bar - Tal 等人,2023] 这类基于补丁的推理方法应用于高分辨率抠图,存在两大主要挑战:上下文信息缺失以及计算冗余。为克服上下文有限的问题,我们使用预测的低分辨率遮罩来引导该过程。为降低计算量,我们利用 alpha 遮罩中固有的稀疏性。
Patch sampling 扩散模型在不同随机种子下会生成随机的 alpha 遮罩。不过,随机结果一般出现在边界区域,这些区域的遮罩质量欠佳,而其他区域是确定性的,其遮罩质量足够好。我们关注这些边界区域,它们仅占输入的一小部分。其他区域可通过对低分辨率(LR)推理得到的遮罩进行上采样直接确定。利用遮罩中分数形式 alpha 值的稀疏性,我们能够在保持良好质量的同时减少计算量。首先,对高分辨率(HR)图像进行下采样,然后将其输入扩散模型,得到低分辨率遮罩预测结果 α ^ i \hat{\boldsymbol{\alpha}}_i α^i。我们使用不同的随机种子执行L次低分辨率推理,得到L个低分辨率预测结果。 A = { α ^ 1 , α ^ 2 , … , α ^ L } \mathcal{A} = \{\hat{\boldsymbol{\alpha}}_1, \hat{\boldsymbol{\alpha}}_2, \ldots, \hat{\boldsymbol{\alpha}}_L\} A={α^1,α^2,…,α^L} 。计算它们的标准差,以此近似不确定性映射 U = E [ ( A − E ( A ) ) 2 ] \mathcal{U} = \sqrt{\mathbb{E}\left[ (\mathcal{A} - \mathbb{E}(\mathcal{A}))^2 \right]} U=E[(A−E(A))2] 。我们将不确定性映射 U \mathcal{U} U 中信息熵高的区域识别为需要细化的候选补丁 B = { b i } i = 1 B \mathcal{B} = \{b_i\}_{i=1}^B B={bi}i=1B 。如图 3 所示,在复杂区域(如头发边界)周围通常会观测到高不确定性。因此,基于该不确定性映射,我们选取候选区域以作进一步处理。
Patch-Based Inference 我们对选定的补丁集合 B \mathcal{B} B 进行推理。每个补丁的噪声潜在表示并非独立采样。这一策略确保不同补丁(尤其是重叠区域)的预测保持一致性。我们采样一个与输入图像尺寸相同的噪声 z T ∈ N ( 0 , I ) \mathbf{z}_T \in \mathcal{N}(0, \mathbf{I}) zT∈N(0,I)。随后,从采样噪声 z T \mathbf{z}_T zT 中裁剪出补丁集合 { z T 1 , z T 2 , … , z T K } \{\mathbf{z}_{T1}, \mathbf{z}_{T2}, \ldots, \mathbf{z}_{TK}\} {zT1,zT2,…,zTK},其中 z T k = F ( z T ∣ b i ) \mathbf{z}_{T}^k = \mathcal{F}(\mathbf{z}_T | b_i) zTk=F(zT∣bi), F \mathcal{F} F 表示裁剪操作符。用于条件化模型的图像条件,同样从输入图像的潜在表示中裁剪得到。我们将补丁的噪声和图像潜在表示输入扩散模型。在祖先采样过程中,每一步 t 都会为补丁集合 { b 1 , b 2 , … , b K } \{b_1, b_2, \ldots, b_K\} {b1,b2,…,bK} 生成潜在样本 { z t 1 , z t 2 , … , z t K } \{\mathbf{z}_{t1}, \mathbf{z}_{t2}, \ldots, \mathbf{z}_{tK}\} {zt1,zt2,…,ztK}。在将这些样本传递到下一步 t − 1 t-1 t−1 之前,我们通过以下方式将它们合并:
z ˉ t = ∑ k = 1 K F − 1 ( z t k ∣ b k ) (5) \bar{\mathbf{z}}_t = \sum_{k=1}^K F^{-1}\left( \mathbf{z}_t^k \big| b_k \right) \tag{5} zˉt=k=1∑KF−1(ztk bk)(5)
其中 F − 1 F^{-1} F−1 是逆裁剪操作符,它会将潜在补丁 z t k \mathbf{z}_t^k ztk 放回从输入图像中裁剪出该补丁的位置 b k b_k bk 处。然后,我们从 z ˉ t \bar{\mathbf{z}}_t zˉt 中获取下一步所需的潜在补丁。在完成祖先采样后,我们将得到去噪后的潜在表示 z ˉ 0 \bar{\mathbf{z}}_0 zˉ0 。最终,在潜在空间中,它会与上采样后的低分辨率(LR)遮罩相融合,以得到最终的 alpha 遮罩。这种由粗到精的策略与先前的高分辨率抠图方法 [Lin 等人,2021] 类似;不过,主要区别在于为扩散模型提出的引导机制 。
Guidance Mechanism 在裁剪出的补丁上执行模型操作时,往往会产生有缺陷的结果,因为模型无法感知整个图像的上下文信息,还可能被局部补丁误导。为解决这一问题,我们提出使用预测得到的低分辨率(LR)遮罩作为引导。尽管从低分辨率输入预测出的遮罩在边界细节方面不尽完善,但对于其他区域,它有着足够准确的预测结果。因此,我们并非从纯噪声 ϵ ∈ N ( 0 , I ) \boldsymbol{\epsilon} \in \mathcal{N}(0, \mathbf{I}) ϵ∈N(0,I) 开始,而是从如下形式启动反向过程。
z T = ( 1 − σ T ) / σ T ϵ + z ^ 0 ↑ (6) \mathbf{z}_T = \sqrt{(1 - \sigma_T) / \sigma_T} \, \boldsymbol{\epsilon} + \hat{\mathbf{z}}_0^\uparrow \tag{6} zT=(1−σT)/σTϵ+z^0↑(6)
其中 z ^ 0 ↑ \hat{\mathbf{z}}_0^\uparrow z^0↑ 表示与预测的低分辨率(LR)遮罩集合 { α ^ l } l = 1 L \{\hat{\boldsymbol{\alpha}}^l\}_{l=1}^L {α^l}l=1L 中某一个对应的上采样潜在表示。这种策略简单却有效。在训练过程中, z T \mathbf{z}_T zT 是真实 alpha 遮罩潜在表示 z 0 \mathbf{z}_0 z0 与高斯噪声 ϵ \boldsymbol{\epsilon} ϵ 的总和。 z 0 \mathbf{z}_0 z0 包含低频信息(前景和背景)和高频信息(边界),而 ϵ T \boldsymbol{\epsilon}_T ϵT 是高频噪声。该噪声会淹没 z 0 \mathbf{z}_0 z0 中的高频信息。换句话说, z T \mathbf{z}_T zT 近似为 z 0 \mathbf{z}_0 z0 的低频部分与 ϵ \boldsymbol{\epsilon} ϵ 的高频部分的组合。模型学习从含噪样本中提取低频数据。在推理阶段,给定的 z ^ 0 ↑ \hat{\mathbf{z}}_0^\uparrow z^0↑ 同样包含低频信息(前景和背景)和高频信息(边界)。其中可能不准确的高频信息会被淹没,而模型能够提取出正确的低频信息。这种策略还能促进下一节中用户引导信息的融入。
Additional Guidance
如果抠图过程没有任何引导,可能会产生歧义。例如,当图像中有多个人物时,可能很难确定要提取哪一个。在这种情况下,额外的引导信息会有所帮助,比如人工标注的 trimap(三值图 )、通过语义分割得到的粗略掩码、涂鸦、点击操作以及文本提示等。我们的方法能够在有这些额外引导信息时,将其融入抠图流程。
Text Guidance 由于我们使用的是文本到图像的生成式扩散模型,添加文本引导相对容易。我们使用 BLIP2 [Li 等人,2023b] 为训练图像标注文本描述。每个标注描述训练图像中的目标前景。给定文本提示 T 的 CLIP 特征 c T \mathbf{c}_T cT,我们使用交叉注意力机制将控制信息注入去噪模型。我们通过最小化(目标函数,原文未完整给出,若有后续可补充完整 ),用带标注的提示训练去噪模型。
L = E ϵ ∼ N ( 0 , I ) , t , z 0 , z ( x ) , c T [ ∥ ϵ t − ϵ θ ( z t , z ( x ) , c T , t ) ∥ 2 2 ] (7) \mathcal{L} = \mathbb{E}_{\boldsymbol{\epsilon} \sim \mathcal{N}(0, \mathbf{I}), t, \mathbf{z}_0, \mathbf{z}(x), c_T} \left[ \left\| \boldsymbol{\epsilon}_t - \boldsymbol{\epsilon}_\theta(\mathbf{z}_t, \mathbf{z}(x), c_T, t) \right\|_2^2 \right] \tag{7} L=Eϵ∼N(0,I),t,z0,z(x),cT[∥ϵt−ϵθ(zt,z(x),cT,t)∥22](7)
在训练过程中,对于小尺寸的图像补丁,我们使用特定提示词 “增强细节”,以避免模型产生混淆。
Spatial Guidance 在图像抠图任务中,像三值图(trimap)、粗掩码 [Yu 等人,2021] 和涂鸦(scribbles)这类空间引导,比文本提示更为常用。受第 3.3 节所述引导机制的启发,我们采用类似方法来注入空间引导 S。我们提取该引导的潜在表示 c S \mathbf{c}_S cS,以及一个指示未知区域的掩码 m unknown m_{\text{unknown}} munknown。对于粗掩码, m unknown = I m_{\text{unknown}} = \mathbf{I} munknown=I;对于涂鸦, m unknown m_{\text{unknown}} munknown 表示没有涂鸦标记的区域。在推理阶段,我们从如下公式执行祖先采样。
z T = ( 1 − σ T ) / σ T ϵ + ( 1 − m unknown ) c S (8) \mathbf{z}_T = \sqrt{(1 - \sigma_T) / \sigma_T} \, \boldsymbol{\epsilon} + (1 - m_{\text{unknown}}) \, \mathbf{c}_S \tag{8} zT=(1−σT)/σTϵ+(1−munknown)cS(8)
我们能够在推理阶段直接应用各类引导信息,而无需使用这些引导信息进行训练。