食品计算—Food Portion Estimation via 3D Object Scaling
🌟🌟 欢迎来到我的技术小筑,一个专为技术探索者打造的交流空间。在这里,我们不仅分享代码的智慧,还探讨技术的深度与广度。无论您是资深开发者还是技术新手,这里都有一片属于您的天空。让我们在知识的海洋中一起航行,共同成长,探索技术的无限可能。
🚀 探索专栏:学步_技术的首页 —— 持续学习,不断进步,让学习成为我们共同的习惯,让总结成为我们前进的动力。
🔍 技术导航:
- 人工智能:深入探讨人工智能领域核心技术。
- 自动驾驶:分享自动驾驶领域核心技术和实战经验。
- 环境配置:分享Linux环境下相关技术领域环境配置所遇到的问题解决经验。
- 图像生成:分享图像生成领域核心技术和实战经验。
- 虚拟现实技术:分享虚拟现实技术领域核心技术和实战经验。
🌈 非常期待在这个数字世界里与您相遇,一起学习、探讨、成长。不要忘了订阅本专栏,让我们的技术之旅不再孤单!
💖💖💖 ✨✨ 欢迎关注和订阅,一起开启技术探索之旅! ✨✨
文章目录
- 1. 背景介绍
- 2. 相关工作
- 2.1 **基于立体视觉的方法**。
- 2.2 **基于模型的方法**。
- 2.3 **基于深度相机的方法**。
- 2.4 **基于深度学习的方法**。
- 3. 方法
- 3.1 对象检测与分割模块
- 3.2 姿态估计模块
- 3.2.1 相机姿态估计
- 3.2.2 物体姿态估计
- 3.3 渲染模块
- 3.4 体积估计
- 3.5 SimpleFood45 数据集采集
- 4. 实验结果
- 4.1 与其他方法的对比
- 4.2 泛化到其他数据集
- 4.3 消融分析
- 4.4 讨论
- 5. 结论
1. 背景介绍
Vinod G, He J, Shao Z, et al. Food portion estimation via 3d object scaling[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024: 3741-3749.
🚀以上学术论文翻译由ChatGPT辅助。
基于图像的方法缓解了传统方法中用户负担重和主观偏差大的问题。
然而,由于智能手机或可穿戴设备拍摄的食物图像是二维表示,导致三维信息的丢失,因此精确的食物分量估计仍然是一项主要挑战。
在本文中,我们提出了一个新框架,能够从二维图像中估计食物的体积和能量,该方法结合了三维食物模型和用餐场景中的物理参照物。
我们的方法会估计输入图像中相机和食物对象的姿态,并利用估计出的姿态渲染三维食物模型图像,从而重建用餐场景。
我们还引入了一个新数据集 SimpleFood45,该数据集包含了 45 种食物的二维图像,以及与之相关的注释信息,包括食物体积、重量和能量。
我们的方法在该数据集上达到了 31.10 31.10 31.10 kCal 的平均误差(相对误差为 17.67 % 17.67\% 17.67%),超越了现有的分量估计方法。
饮食评估对于理解和促进健康的饮食习惯至关重要,它是衡量个人健康状况的关键指标之一。
传统方法(如 24 小时回忆法)严重依赖用户自行报告的数据,存在固有的局限性和偏差。
近年来,基于图像的饮食评估方法引起了广泛关注,它们在缓解传统方法带来的用户负担的同时,也展现出了较高的准确性。
然而,依赖纯二维图像的方法面临一个重要挑战——在将三维食物对象投影到二维图像平面时会丢失关键信息。
为了解决这一问题,研究者们开始探索多视角图像和基于深度的方法,旨在获取比单张图像更丰富的信息。
近年来可获取的三维数据的出现缓解了二维图像信息缺失的问题。
像 ShapeNet、Omni-Object3D 等数据集丰富了三维数据资源。
最新的工作 NutritionVerse3D 提供了食物对象的三维表示,为解决现有公开数据集中缺乏三维信息的问题提供了关键工具。
然而,目前尚无方法将这些新出现的三维数据应用于单张图像的分量估计任务中。
在本研究中,我们提出了一个新的框架,利用三维模型的能力,并结合二维食物图像的简单性与广泛性,实现食物分量估计。
我们方法的核心思想是:基于可用的三维食物模型,在输入的二维图像中重建并渲染用餐场景。
在三维空间中,重建二维图像的关键参数包括:相机的位置与朝向,以及图像中食物的位置与朝向。
我们提出的方法能够估计这些参数,并利用它们渲染出与图像中食物对应的三维模型图像。
已知的三维模型体积与一个缩放因子被用于计算食物的估计体积。
缩放因子是渲染图像中食物所占面积与输入图像中食物所占面积的比值。
输入图像中食物的面积由神经网络分割模型生成的分割掩码获得。
最终,我们通过 USDA 食品与营养数据库 (FNDDS) 获取估计体积对应的能量值。
与以往依赖神经网络的图像方法不同,我们的方法不依赖复杂神经网络结构进行分量估计。
神经网络只被用于标准任务,如食物分类和分割;而分量估计完全基于三维几何信息与估计出的相机和物体姿态。
目前许多食物分量估计方法都在私有数据集上进行评估,使得方法之间的比较变得困难。
此外,目前尚无同时包含真实食物体积与对应三维模型的图像数据集,供我们的方法进行评估。
一些已有研究使用 Nutrition5k 数据集,它是一个公开的大规模真实食物图像数据集,包含营养信息。
其中约有 3000 张图像带有深度图(即每个像素到相机的距离映射)。
然而,该数据集中的相机位置是固定的,并且只能从食物的俯视角拍摄,极大地限制了其泛化能力。
相比之下,日常用智能手机或可穿戴设备拍摄的食物图像具有多种不同角度。
因此,我们引入了一个新数据集 SimpleFood45,包含了用智能手机从不同角度拍摄的真实食物图像,图像中带有棋盘格作为物理参照。
每张图像都包含真实的体积(毫升)、重量(克)和能量(千卡)标注,旨在为食物分量估计方法提供更可靠的评估基线。
本文的主要贡献包括:
- 我们提出了一个轻量级、基于几何的框架,使现有三维数据可以用于从二维图像中估计食物分量。
- 我们构建了一个新数据集 SimpleFood45,使用手机拍摄图像,并包含用于分量估计的物理参照与真实体积。
- 在 SimpleFood45 数据集上,我们的方法优于现有基于神经网络和三维表示的方法。
2. 相关工作
食物分量估计或体积分析大致可以分为四类。
2.1 基于立体视觉的方法。
这类方法依赖多帧图像来重建食物的三维结构。
例如,文献 [28] 中基于极几何从多视角立体重建中估计食物体积。
文献 [29] 实现了基于双视图的密集重建。
文献 [5] 则使用了同时定位与地图构建(SLAM)技术,实现连续和实时的食物体积估计。
这类方法的主要限制在于需要多张图像,限制了其在真实场景中的应用。
2.2 基于模型的方法。
这类方法使用预定义的形状或模板来估计目标体积。
文献 [38] 中的模型方法通过从模板库中选择合适的模板分配给不同食物,并基于一些物理参照进行变换,估计食物的大小与位置。
文献 [12] 中使用了类似的模板匹配方法,从单张图像中估计食物体积。
然而,这种对预定义模板的精确匹配无法涵盖食物的多样性和变化。
2.3 基于深度相机的方法。
该方法使用能够生成深度图的深度相机,捕捉图像中相机到食物的距离。
文献 [20, 33] 中使用深度图生成图像的体素表示,并据此估计食物体积。
这种方法的主要限制在于需要高质量的深度图,并且消费级深度传感器还需额外后处理步骤。
2.4 基于深度学习的方法。
基于神经网络的方法利用大量图像数据来训练复杂模型,从而实现食物分量估计。
文献 [31, 36] 使用回归网络从单张图像输入或“能量分布图”(即图像中每个像素与对应食物能量分布之间的映射)中估计能量值。
文献 [35] 使用图像和深度图作为输入,训练回归网络预测图像中食物的能量、质量和三大营养素信息。
这类基于深度学习的方法依赖大量训练数据,通常缺乏可解释性,且当输入图像与训练数据差异较大时性能会下降。
各种食物分量估计方法所使用的数据集(详见表 1)凸显了公开数据集在食物分量或能量估计方面的空缺。

此外,非深度学习方法往往依赖于结构简单、几何形状固定的食物。
Nutrition5k 数据集仅提供带有物理参照(深度图)的俯视图图像,但不包含真实分量信息。
因此,亟需一个公开数据集,具备物理参照、真实分量标注,以及刚性食物图像,以支持分量估计方法的验证。
本论文提出了一种新的视角,即利用三维食物模型,同时仅依赖二维食物图像作为输入来进行食物分量估计。
我们还引入了 SimpleFood45 数据集,用于食物分量估计的基准评估。
3. 方法
我们提出了一个端到端的框架,输入一张二维图像,估计图像中相机的姿态和食物的姿态,并使用估计出的姿态渲染该食物的三维模型图像。
通过输入图像与渲染图像中食物所占区域的相对面积差异,来缩放已知的三维模型体积,从而获得体积估计值。
该三维模型是通过三维扫描仪对真实食物进行扫描获得的。
我们为 SimpleFood45 数据集中的每种食物类型采集了一个三维模型,构成了我们的三维数据库。
框架结构如图 1 所示。
该方法由三个模块组成:
对象检测与分割模块 负责分类和分割,用于获取输入图像中食物所占的面积;
姿态估计模块 用于估计三维世界坐标系中相机和食物的位置与朝向,是渲染三维模型的关键;
渲染模块 则根据食物分类结果和姿态估计,使用对应的三维模型进行图像渲染。
通过比较渲染图像和输入图像中食物占据的面积比例,可缩放三维模型,从而估计图像中食物的体积。
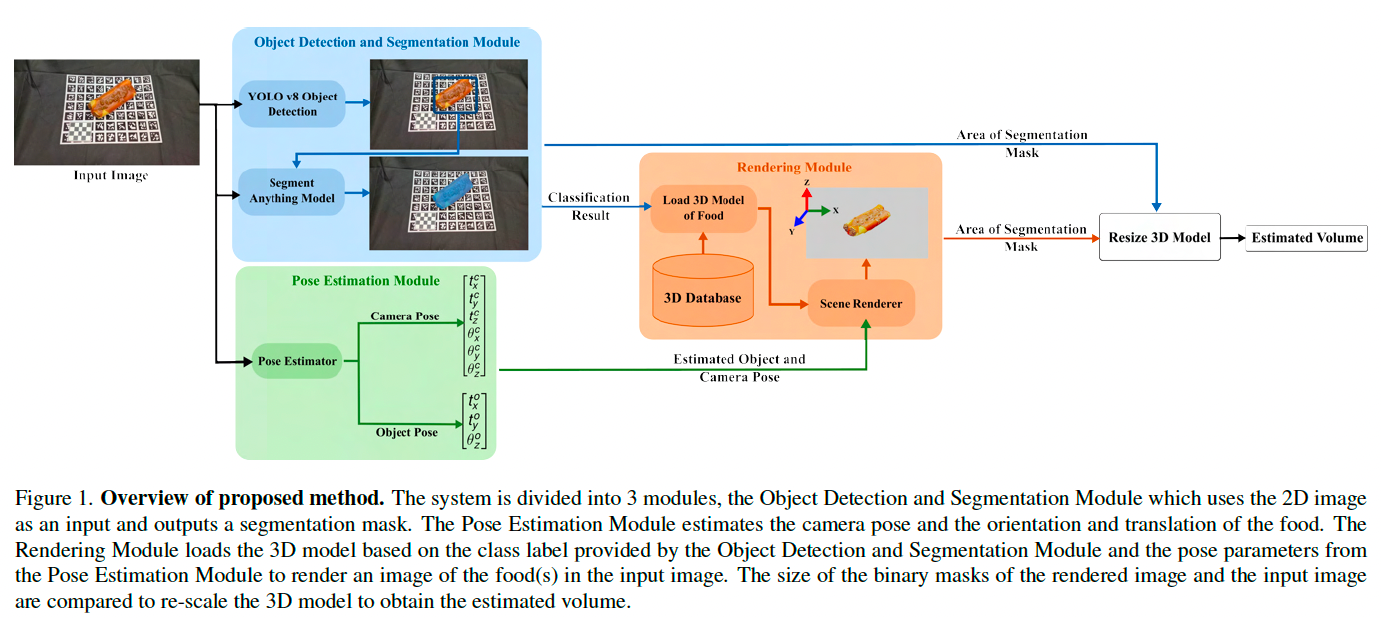
3.1 对象检测与分割模块
该模块的目标是获取图像中食物的分割掩码和分类标签。
分类标签用于确定食物类型,从而选取对应的三维模型进行渲染;
分割掩码提供图像中食物所占的面积信息。
Segment Anything Model (SAM) [15] 提供了零样本泛化能力,省去了为训练准备带掩码和精细分类数据集的麻烦。
为了向 SAM 提供更准确的边界框提示,我们使用 YOLOv8 [14] 来对图像进行检测,输出每个食物的类别和对应边界框。
本工作中,我们使用在 VIPER-FoodNet (VFN) 数据集 [11, 23, 24] 上预训练的 YOLOv8 网络,该数据集包含美国最常见的食物类型。
具体过程为:输入图像先通过 YOLOv8 网络获取类别和边界框,作为提示传给 SAM 进行分割,从而获得每个类别对应的分割掩码。
3.2 姿态估计模块
3.2.1 相机姿态估计
相机姿态估计的目标是,在已知相机内参矩阵 K K K(由相机标定 [41] 得到)以及棋盘格 12 个角点在二维像素和三维世界坐标中的对应关系下,估计相机在三维空间中的朝向。
第 k k k 个角点的 3D 到 2D 映射为:
[ u k v k 1 ] = K 3 × 3 [ R ∣ t ⃗ ] 3 × 4 [ X k Y k Z k 1 ] ( 1 ) \begin{bmatrix} u_k \\ v_k \\ 1 \end{bmatrix} = K_{3 \times 3} \begin{bmatrix} R | \vec{t} \end{bmatrix}_{3 \times 4} \begin{bmatrix} X_k \\ Y_k \\ Z_k \\ 1 \end{bmatrix} \quad (1) ukvk1 =K3×3[R∣t]3×4 XkYkZk1 (1)
其中 ( u k , v k ) (u_k, v_k) (uk,vk) 是第 k k k 个角点的像素坐标, ( X k , Y k , Z k ) (X_k, Y_k, Z_k) (Xk,Yk,Zk) 是其三维世界坐标。
( X k , Y k , Z k ) (X_k, Y_k, Z_k) (Xk,Yk,Zk) 被设定为一个规则网格。
R 3 × 3 R_{3 \times 3} R3×3 表示旋转矩阵, t ⃗ 3 × 1 \vec{t}_{3 \times 1} t3×1 表示平移向量。
由于上述矩阵可能秩亏,无法直接求解 [8],因此采用 PnP(Perspective-n-Point)算法 [17],将该问题转化为最小化重投影误差的优化问题。
得到的外参矩阵 [ R c ∣ t ⃗ c ] [R_c | \vec{t}_c] [Rc∣tc] 表示从世界坐标系到相机坐标系的映射。
若 X ⃗ c \vec{X}_c Xc 是相机坐标系中的点,对应世界坐标为 X ⃗ w \vec{X}_w Xw,则有:
X ⃗ w = R c X ⃗ c + t ⃗ c ( 2 ) \vec{X}_w = R_c \vec{X}_c + \vec{t}_c \quad (2) Xw=RcXc+tc(2)
为获得相机在世界坐标系中的位置,将 X ⃗ w = 0 ⃗ \vec{X}_w = \vec{0} Xw=0 代入上式得:
0 ⃗ = R c X ⃗ c + t ⃗ c ⇒ X ⃗ c = − R c − 1 t ⃗ c ( 3 ) \vec{0} = R_c \vec{X}_c + \vec{t}_c \Rightarrow \vec{X}_c = -R_c^{-1} \vec{t}_c \quad (3) 0=RcXc+tc⇒Xc=−Rc−1tc(3)
由于旋转矩阵 R c R_c Rc 是正交矩阵,有 R c − 1 = R c ′ R_c^{-1} = R_c^{\prime} Rc−1=Rc′,
因此相机姿态可表示为:
R = R c ′ , t ⃗ = − R c ′ t ⃗ c ( 4 ) R = R_c^{\prime}, \quad \vec{t} = -R_c^{\prime} \vec{t}_c \quad (4) R=Rc′,t=−Rc′tc(4)
3.2.2 物体姿态估计
使用分割掩码和棋盘格估计输入图像中食物在世界坐标中的位置与朝向。
首先将分割掩码中的像素坐标作为二维点,应用主成分分析(PCA) [26],主方向对应最大特征值的特征向量。
该方向与水平轴夹角 θ z o \theta_z^o θzo 表示食物在 Z 轴方向上的旋转。
假设 X 和 Y 方向旋转为 0 0 0,即 θ x o = θ y o = 0 \theta_x^o = \theta_y^o = 0 θxo=θyo=0。
位置估计基于棋盘格。
由于食物通常放置于棋盘格表面,Z 轴方向平移设为 0 0 0。
棋盘格每格间距为 1.2 1.2 1.2 cm,通过图像校正(DLT [8])获得像素到厘米的映射。
计算分割掩码中心点与棋盘格右上角的距离,获得 X 和 Y 轴上的平移 t x o , t y o t_x^o, t_y^o txo,tyo。
最终食物姿态为:
O = ( t x o , t y o , θ z o ) O = (t_x^o, t_y^o, \theta_z^o) O=(txo,tyo,θzo)
3.3 渲染模块
通过姿态估计模块,获得像素坐标系与世界坐标系之间的映射。
根据 YOLOv8 的分类标签加载对应三维模型。
根据估计出的食物姿态 O O O 和相机姿态(式 4),以及相机内参 K K K,构建相机投影矩阵:
P 3 × 4 = K 3 × 3 [ R ∣ t ~ ] 3 × 4 P_{3 \times 4} = K_{3 \times 3} [R | \tilde{t}]_{3 \times 4} P3×4=K3×3[R∣t~]3×4
将三维模型点 X i X_i Xi 映射到图像坐标:
x i = P X i ′ ∀ i ( 5 ) x_i = P X_i' \quad \forall i \quad (5) xi=PXi′∀i(5)
渲染过程中,仅需目标的二值掩码,因此不使用纹理。
如图 2 所示,图 2b 是输入图像,图 2a 是对应三维模型,图 2d 是实际用于体积估计的渲染掩码图像。
由于姿态估计误差,图 2b 与图 2d 可能不完全一致。

3.4 体积估计
渲染图像复现了使用三维模型生成的输入图像。
因此可假设渲染图像与输入图像中食物面积比例,与实际体积比例相同。
食物面积通过分割掩码中像素数量估计:
A = ∑ p ∈ S 1 ( 6 ) A = \sum_{p \in S} 1 \quad (6) A=p∈S∑1(6)
渲染图中面积:
A ′ = ∑ p ∈ S ′ 1 ( 7 ) A' = \sum_{p \in S'} 1 \quad (7) A′=p∈S′∑1(7)
三维模型缩放因子:
s = A / A ′ ( 8 ) s = \sqrt{A / A'} \quad (8) s=A/A′(8)
估计体积为缩放模型的体积,能量密度 ρ \rho ρ 由 FNDDS 数据库 [25] 提供,乘以体积得能量估计值:
e ~ = ρ v ~ ( 9 ) \tilde{e} = \rho \tilde{v} \quad (9) e~=ρv~(9)
3.5 SimpleFood45 数据集采集
SimpleFood45 包含 12 种食物,总计 513 张真实图像,带有真实类别、体积(mL)、重量(g)、能量(kCal)标签。
图像使用三星 Galaxy S22 Ultra 拍摄,每张图包含一个 5×4 的棋盘格,共有 4×3 个内部角点,每个角点间距为 1.2cm。
图 3 展示了数据集图像样例。

使用 Revopoint POP2 三维扫描仪 [30] 对食物进行扫描。
每种食物类型对应一个三维模型,但每种模型对应 3–4 个不同实物。
每个实物至少拍摄 10 张图像,拍摄角度和食物位置均不同。
模型在三维空间中占据的体积作为其真实体积,因其物理尺寸与真实食物一致。
能量由 FNDDS 数据库根据真实质量和类别映射得出。
4. 实验结果
4.1 与其他方法的对比
我们在 SimpleFood45 数据集上验证了所提出的方法。
将我们的方法与已被证明精度较高的现有神经网络方法 [22, 31, 35] 进行比较。
由于我们的方法使用了食物的三维表示,因此也与基于体素的三维方法 [33] 进行对比。
数据集按 80%-20% 的比例划分训练集与测试集,并确保类别在两部分中均衡分布。
所有方法仅在测试集上评估,以保证与神经网络方法的公平性。
我们使用标准指标进行对比,包括平均绝对误差(MAE)与平均绝对百分比误差(MAPE),定义如下:
MAE = 1 N ∑ i = 1 N ∣ v ^ i − v i ∣ \text{MAE} = \frac{1}{N} \sum_{i=1}^N |\hat{v}_i - v_i| MAE=N1i=1∑N∣v^i−vi∣
MAPE (%) = 1 N ∑ i = 1 N ∣ v ^ i − v i v i ∣ \text{MAPE (\%)} = \frac{1}{N} \sum_{i=1}^N \left| \frac{\hat{v}_i - v_i}{v_i} \right| MAPE (%)=N1i=1∑N viv^i−vi
其中 v i v_i vi 是第 i i i 张图像的真实值, v ^ i \hat{v}_i v^i 是估计值, N N N 为图像总数。
体积估计误差用 VMAE 与 VMAPE 表示,能量估计误差用 EMAE 与 EMAPE 表示。
VMAE 和 EMAE 的单位分别为 mL 和 kCal。
我们选择以下方法与我们的方法在 SimpleFood45 数据集上对比,它们在份量估计方面表现出较低误差:
- Baseline:该基线方法常用于回归任务,在 [35] 中也使用过。它为每个样本预测数据集体积或能量的均值。例如体积均值为:
v ˉ = 1 N ∑ i = 1 N v i \bar{v} = \frac{1}{N} \sum_{i=1}^N v_i vˉ=N1i=1∑Nvi
则每张图像的预测体积为:
v ^ i = v ˉ \hat{v}_i = \bar{v} v^i=vˉ
-
基于深度学习的方法:
- RGB Only:使用 ResNet50 主干 + 两个全连接层,仅根据 RGB 图像预测能量值 [31]。
- Distribution Map Only:使用真实的 “能量密度图” [31] 作为输入,直接回归能量值。
- Distribution Map Summing:直接对能量密度图像素值求和 [22]。
- 2D Direct Prediction:使用与 [35] 相同架构,仅使用图像输入进行能量回归。
- Depth as 4th Channel:使用 ZoeDepth [1] 生成深度图,将其作为第4通道添加至 RGB 图像,输入到与 2D 直接预测相同的网络中 [35]。
-
基于三维表示的方法:
- VREPF (Voxel Representation Estimation Per Food):基于输入图像和对应的深度图构建体素体积 [33]。
对于第 i i i 类食物中第 k k k 张图像,估计体素体积为 V ~ k \tilde{V}_k V~k,真实体积为 V k V_k Vk,比例因子为:
- VREPF (Voxel Representation Estimation Per Food):基于输入图像和对应的深度图构建体素体积 [33]。
ρ k i = V k V ~ k \rho_k^i = \frac{V_k}{\tilde{V}_k} ρki=V~kVk
平均比例因子为:
ρ ˉ i = 1 N ∑ k = 1 N ρ k i \bar{\rho}^i = \frac{1}{N} \sum_{k=1}^N \rho_k^i ρˉi=N1k=1∑Nρki
估计体积为:
V ^ k = V ~ k ρ ˉ i \hat{V}_k = \tilde{V}_k \bar{\rho}^i V^k=V~kρˉi
我们提出的方法在多数情况下明显优于神经网络方法,并超过体素表示方法。
尽管神经网络已在 SimpleFood45 上训练,但它们在能量估计方面表现不佳,可能因数据量小、食物能量差异大所致,反映出我们方法的优势。
4.2 泛化到其他数据集
我们的方法要求图像中包含物理参考和该食物的三维模型。目前没有公开数据集完全满足这个要求。
因此我们从 Nutrition5k 数据集中选择了与 SimpleFood45 重叠的三种食物类型:苹果、贝果和披萨。
Nutrition5k 中图像为俯视图,摄像头位置固定,并提供摄像头与盘子之间的距离作为参考。
摄像头参数依据 [35] 的模型估算。
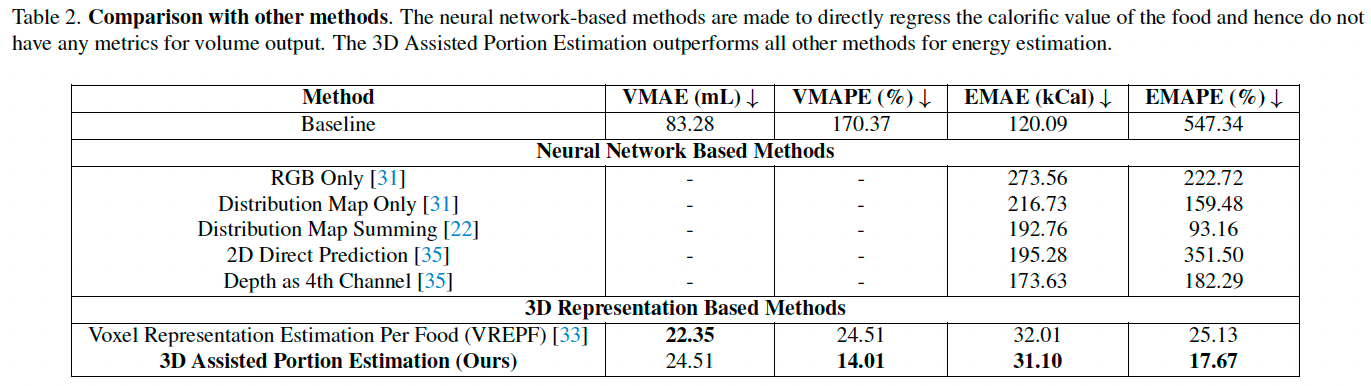
表 3 显示了我们方法和 VREPF 在 Nutrition5k 数据集上的估计结果。
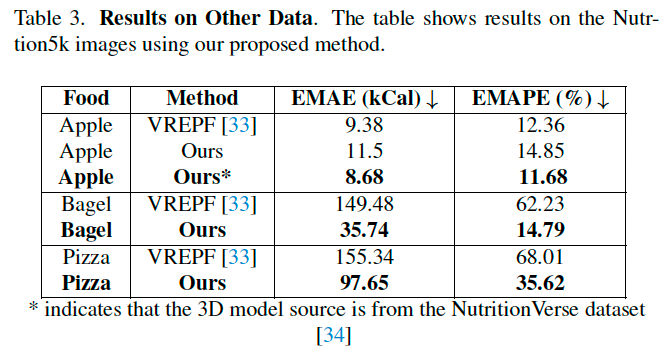
VREPF 使用数据集中提供的深度图构建体素体积。
NutritionVerse [34] 与 SimpleFood45 的唯一重叠食物是苹果,因此我们还使用 NutritionVerse 的三维模型在 Nutrition5k 上评估苹果图像,不使用任何自有数据。
结果显示我们方法在所有食物上都优于 VREPF,误差率极低。
VREPF 在部分食物上表现不佳,原因是深度图质量低,导致体素重建误差大。
而我们的方法无需训练数据即可适配新数据集,泛化能力强。
尽管食物类型重叠有限,但结果依然优于使用真实深度图的 VREPF,验证了方法的强泛化性。
4.3 消融分析
为理解物体姿态估计对我们方法的重要性,我们在 SimpleFood45 上进行消融实验。
设物体姿态向量为 O = ( t x o , t y o , θ z o ) O = (t_x^o, t_y^o, \theta_z^o) O=(txo,tyo,θzo),我们分析当部分或全部设为 0 0 0(即不估计)时的影响。
- t x o = 0 t_x^o = 0 txo=0:食物仅沿 Y 轴平移;
- t y o = 0 t_y^o = 0 tyo=0:食物仅沿 X 轴平移;
- θ z o = 0 \theta_z^o = 0 θzo=0:模型在 Z 轴不旋转。
表 4 显示 Y 轴平移对结果影响最大,因为 Y 轴平移影响物体与摄像头的距离,从而改变图像中物体的大小。
X 轴平移对占据面积影响较小,因此影响有限。
θ z o = 0 \theta_z^o = 0 θzo=0 主要影响非对称食物,对苹果、贝果等对称物体影响不大。
结果表明,姿态估计是我们方法的关键,考虑所有参数时能获得最低的 EMAPE。
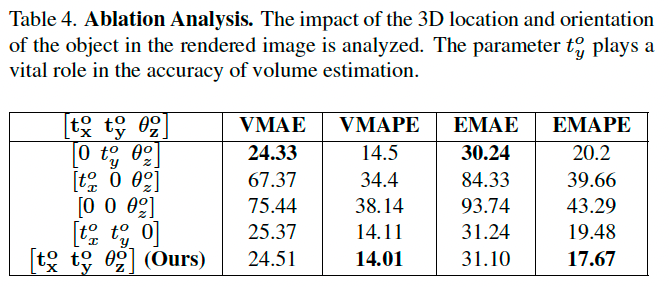
4.4 讨论
我们方法的主要限制是:每种食物需要一个三维模型。
若三维模型与实际食物不一致,会产生较大误差。
例如使用完整牛油果建模,但图像中为切片时,预测会出错。
这种结构差异影响是几何方法的共性问题。
但表 4 显示,即便在通用场景中,我们方法仍能合理估计食物能量,并超过现有方法。
该限制可通过采集更多三维模型缓解。
三维模型越多,估计精度越高。
5. 结论
我们提出了一种结合二维图像与三维数据的方法,以克服传统图像中缺失三维信息的限制。
本方法成功连接了二维食物图像与三维建模之间的桥梁,用于份量估计。
显著特点包括:无需依赖复杂神经网络结构或训练数据。
我们还发布了 SimpleFood45 数据集,包含真实食物图像及体积标注,供份量估计研究使用。
实验表明,我们方法在 SimpleFood45 上超过了现有的神经网络方法与三维表示方法,且在无训练数据条件下仍具良好泛化能力。
本研究为三维食物分析提供了坚实基础。
主要限制在于每种食物都需对应的三维模型。
未来将致力于降低这一依赖,通过使用三维重建技术将这些模型作为训练数据,而非推理阶段所必需。
🌟 在这篇博文的旅程中,感谢您的陪伴与阅读。如果内容对您有所启发或帮助,请不要吝啬您的点赞 👍🏻,这是对我最大的鼓励和支持。
📚 本人虽致力于提供准确且深入的技术分享,但学识有限,难免会有疏漏之处。如有不足或错误,恳请各位业界同仁在评论区留下宝贵意见,您的批评指正是我不断进步的动力!😄😄😄
💖💖💖 如果您发现这篇博文对您的研究或工作有所裨益,请不吝点赞、收藏,或分享给更多需要的朋友,让知识的力量传播得更远。
🔥🔥🔥 “Stay Hungry, Stay Foolish” —— 求知的道路永无止境,让我们保持渴望与初心,面对挑战,勇往直前。无论前路多么漫长,只要我们坚持不懈,终将抵达目的地。🌙🌙🌙
👋🏻 在此,我也邀请您加入我的技术交流社区,共同探讨、学习和成长。让我们携手并进,共创辉煌!
