YOLO系列面试冲刺
YOLO系列面试冲刺
- YOLOV3
- 网络结构简述
- 为什么Darknet-53相比于同时期更深层的网络ResNet-101、ResNet-152效果更好些呢?
- 样本分配策略
- 损失函数
- 改进点
- 1. YOLOv1/v2中使用IoU作为置信度标签有何不好?
- YOLOV4
- 改进点
- 马赛克(Mosaic)数据增强:
- Mish激活函数
- PAN_FPN
- 样本分配策略
- 损失函数
- YOLOV5
- 改进点
- 自适应 Anchor 计算
- 激活函数
- 损失函数
- focus结构
- 训练速度更快
- YOLOV8
- 改进点
- anchor free
- 为配合Anchor-Free、以及提升泛化性,在v8中,增加了DFL损失, 使用Decoupled-Head
- 样本分配策略
YOLOV3
参考面试问题总结——关于YOLO系列(三)
网络结构简述
Backbone(骨干网络):Darknet-53网络结构(因为有53个卷积层)
(原论文中Darknet53的尺寸是在图片分类训练集上训练的,所以输入的图像尺寸是256x256,而在YOLOv3中输入尺寸是416×416)
(因为Backbone骨干网络是全卷积网络,可以兼顾任意尺度的输入,则可以输入32倍的任意尺度图像。所以对于YOLOv3来说,输入的图像越大,则单张输出的特征数也越多。)
Neck(颈部网络):用于汇总、融合不同尺度的特征,类似于FPN(特征金字塔)
Head(输出头):获得各个尺度目标检测的预测结果。输入是416×416,输出了三个尺寸的特征层52×52、26×26、13×13。作者在三个特征层上分别用了3个预设边界框的尺寸,一共是9个anchor boxes,都是根据COCO数据集聚类得到的。
为什么Darknet-53相比于同时期更深层的网络ResNet-101、ResNet-152效果更好些呢?
在两个模型的主干网络中,我发现基本都是通过一系列的残差结构堆叠来实现的主干网络,唯一不同的是Darknet-53网络中没有最大池化层即Maxpooling层,而Darknet-53中所有的下采样基本都是通过卷积层来实现的,我猜想是这个原因。
样本分配策略
YOLOV3使用MaxIoUAssigner策略来给gt分配样本,基本上保证每个gt都有唯一的anchor对应。匹配的原则是该anchor与gt的IOU最大且大于FG_THRESH,这种分配制度会导致正样本比较少,cls和bbox分支训练起来可能比较慢。在剩余的anchor中,如果有anchor跟所有gt的IOU都小于BG_THRESH,则将此类anchor设为负样本,如果有anchor跟所有gt的IOU大于BG_THRESH且小于FG_THRESH,则忽视掉此类anchor。
另一种说法:
在原论文中,针对每一个ground truth(简称GT,真值,就是你打标签时标注的目标矩形框),都会分配一个bounding box,表示针对每一个GT,都会分配一个正样本,则一张图片有几个GT,就会有几个正样本。
YOLOv3中正负样本的定义:YOLOv3中就不再看中心点落在哪个grid cell(网格)里面就由哪个grid cell预测了,而是看谁的anchor与待检测目标的grouth truth的iou值最大,才由那个anchor去预测,也就是在YOLOv3里面正样本是指与grouth truth的iou值最大的预测框或anchor,对于和grouth truth有iou值且大于设定iou阈值(原论文中设为0.5)但不是最大值的预测框或anchor,就忽略它们;对于小于设定iou阈值的预测框或anchor而言就是负样本。
此外,在原论文中也提到,对于当前的bounding box,若其不是正样本的话,则它既没有定位损失,也没有类别损失,仅仅只有置信度损失(confidence loss)。
损失函数
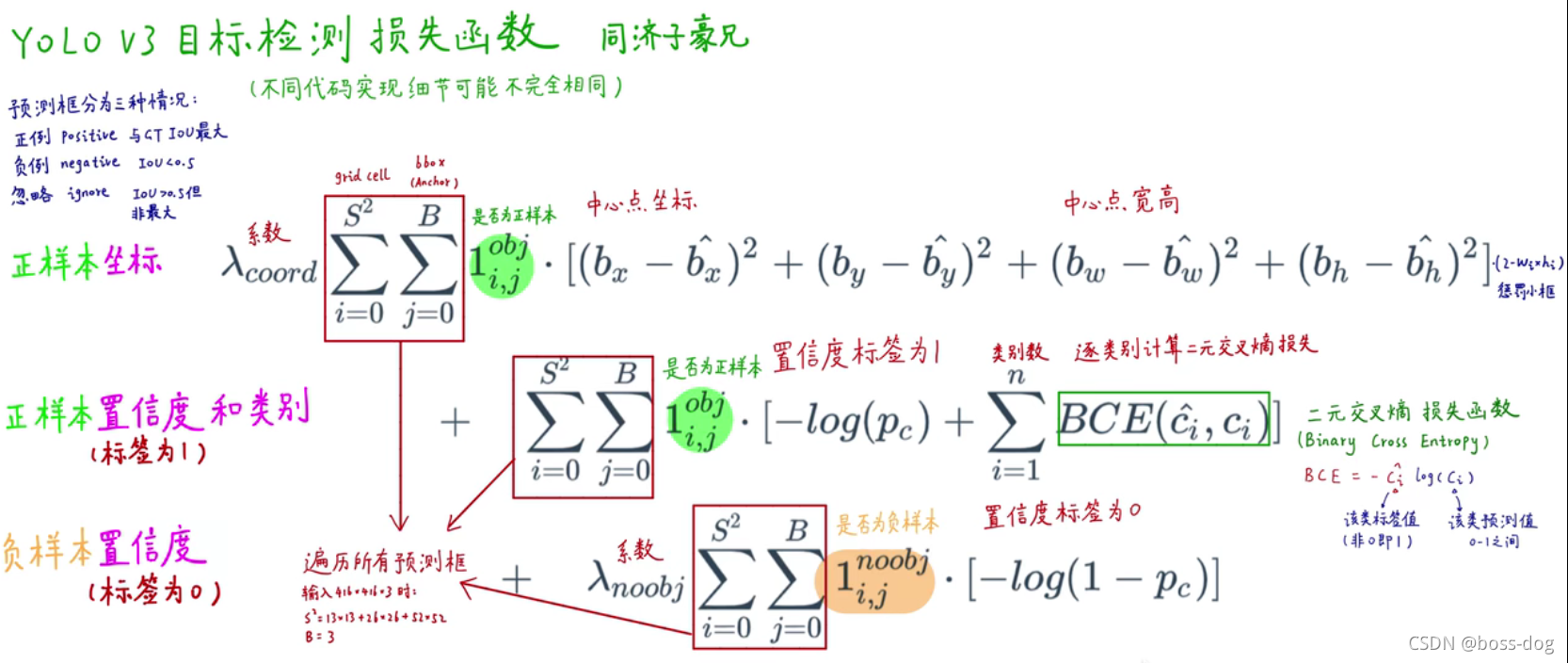
YOLOv3的损失函数主要分为三个部分:目标定位偏移量损失,目标置信度损失以及目标分类损失,其中λ1、λ2、λ3是平衡系数。
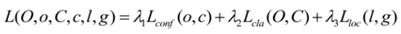
原论文中损失函数写的很粗略,比如坐标损失采用的是误差的平方和,类别损失采用的是二值交叉熵,在github上也找了很多YOLO v3的公开代码,有的采用的是YOLOv1或者YOLOv2的损失函数。
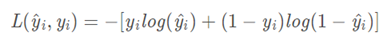
(二值交叉熵):y为样本的期望输出,y^为样本的实际输出
改进点
1. YOLOv1/v2中使用IoU作为置信度标签有何不好?
①很多预测框与ground truth的IoU最高只有0.7。
②COCO中的小目标IoU对像素偏移很敏感无法有效学习。
而在YOLOv3中正样本的标签都用1表示,负样本用0表示。只有正样本对分类和定位学习产生贡献(与YOLOv1和YOLOv2思想一致),负样本只对置信度学习产生贡献。
YOLOV4
参考
yolov4算法及其改进
改进点
马赛克(Mosaic)数据增强:

首先随机取4张图片,分别对4张图片进行数据增广操作,并分别粘贴至与最终输出图像大小相等的掩模的对应位置,进行图片的组合和框的组合
优点:
丰富数据集:使用4张图片,随机缩放,随机分布进行拼接,大大丰富了目标检测的数据集,增加了很多小目标,让网络模型对小目标的稳健性变的更好。
减少GPU使用:mosaic增强训练时,可以在单图像尺度的情况下直接计算4张图片的数据,使得mini-batch size并不需要很大,即使用1个GPU就可以达到比较好的收敛效果
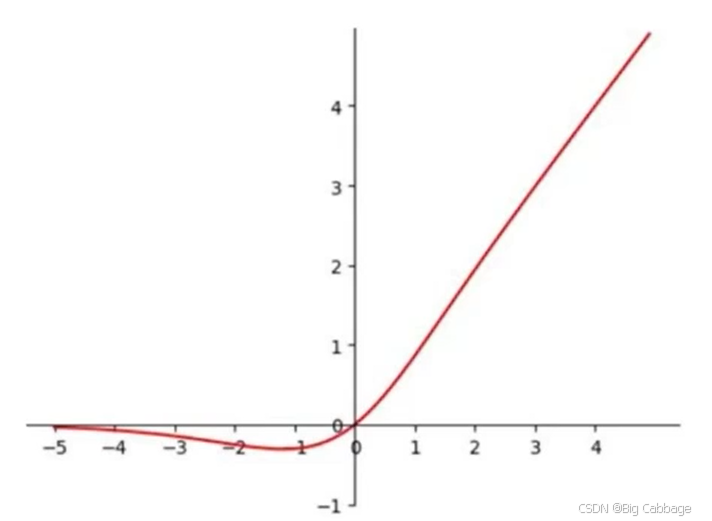
Mish激活函数
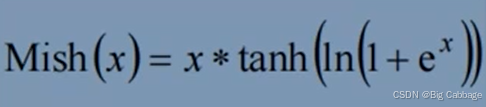
mish激活函数是自带正则的非单调激活函数,平滑的激活函数可以让模型获得更好的非线性,从而得到更好的准确性和泛化,Mish激活函数的数学表达式如上式。
首先函数和relu一样都是无正向边界的,可以避免梯度饱和,其次,mish函数时光滑的,并且在绝对值较小的负值区域允许一些负值。
注意,mish激活函数的计算复杂度比relu要高,在计算资源不足的情况下,可以考虑使用leakyrelu激活函数代替mish激活函数
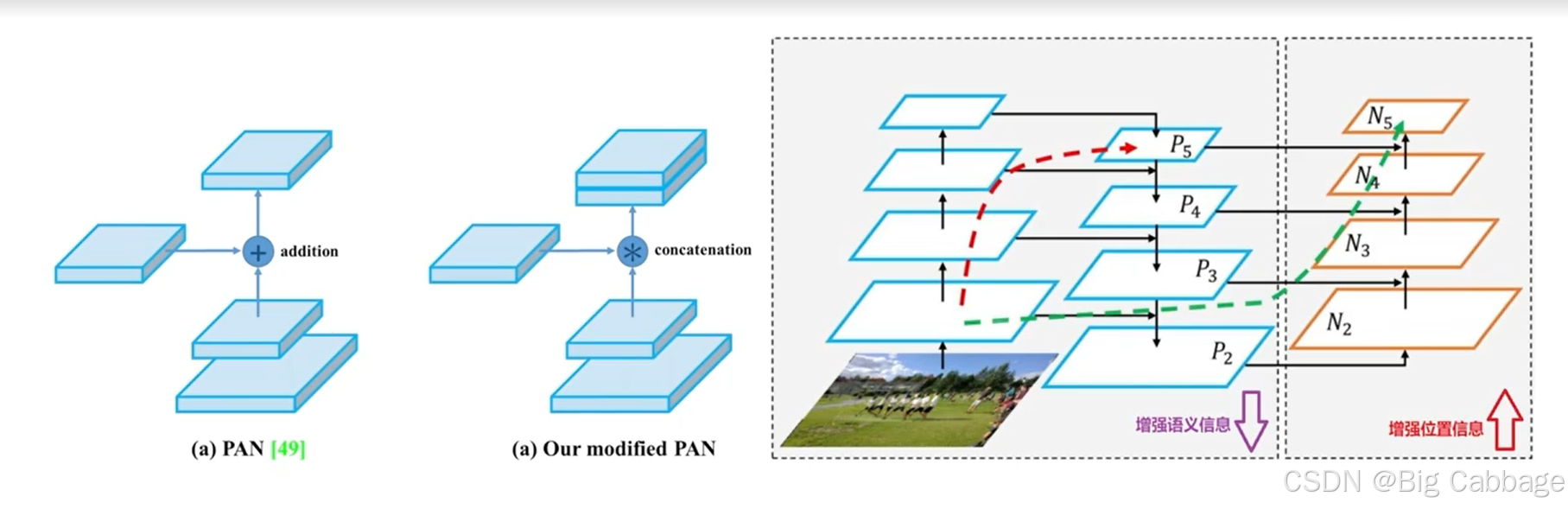
PAN_FPN
FPN是自顶向下将高层的强语义特征传递下来,对整个特征金子塔进行增强,但是FPN只增强语义信息,对定位信息没有很好的传递,因此YOLOV4增加了PAN来增强定位信息的传递。
FPN+PAN借鉴的是PANet,主要应用于图像分割领域,如上图所示,FPN采用自顶向下,将高层的强语义特征传递下来,而PAN+FPN针对这一点,在FPN的后面添加一个自底向上的金字塔,这样的操作是对FPN的补充,将底层的强定位特征传递上去。这样不仅能增强高级语义信息,还能增强定位信息。
样本分配策略
yolov4为了增加正样本,采用multi anchor策略,只要大于IoU阈值的anchor,都视为正样本
损失函数
使用CIoU损失
详解各种iou损失函数的计算方式(iou、giou、ciou、diou)
YOLOV5
改进点
自适应 Anchor 计算
在 YOLOv3、YOLOv4 中,训练不同的数据集时,计算初始 Anchor 的值是通过单独的程序运行的。但 YOLOv5 中将此功能嵌入到代码中,每次训练时会自适应的计算不同训练集中的最佳 Anchor 值。
激活函数
leakyReLU和Sigmoid
损失函数
yolov5中的边界框损失前期采用的是GIoU Loss,后期使用CIoU Loss,yolov4中采用的是CIoU Loss,与其他方法相比,CIoU带来了更快的收敛和更好的性能。
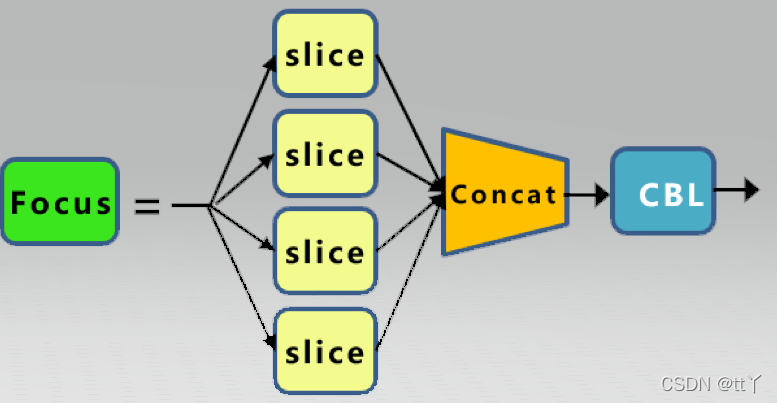
focus结构
参考YOLOv5中的Focus层详解|CSDN创作打卡
Focus层原理和PassThrough层很类似。它采用切片操作把高分辨率的图片(特征图)拆分成多个低分辨率的图片/特征图,即隔列采样+拼接。原理图如下:
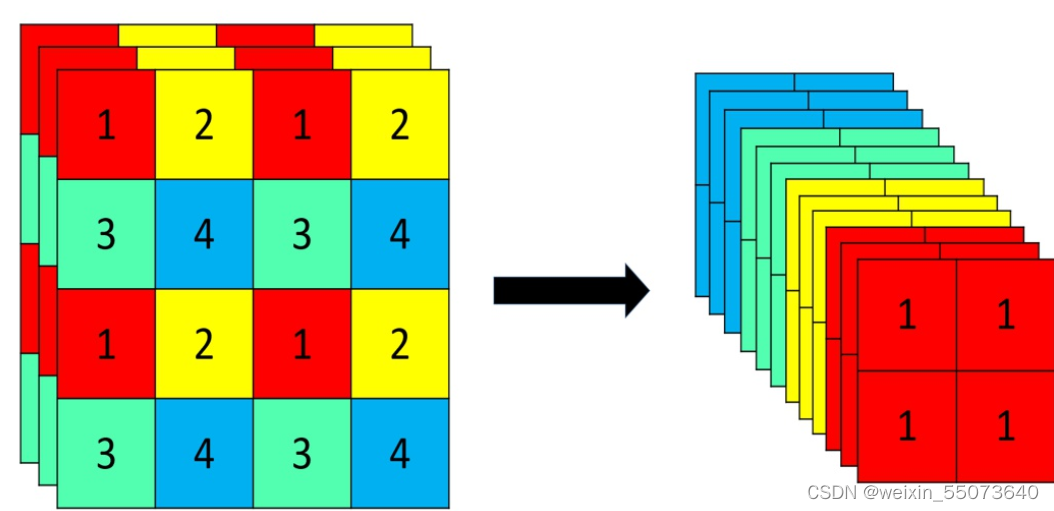
原始的640 × 640 × 3的图像输入Focus结构,采用切片(slice)操作,先变成320 × 320 × 12的特征图,拼接(Concat)后,再经过一次卷积(CBL(后期改为SiLU,即为CBS))操作,最终变成320 × 320 × 64的特征图。
Focus层将w-h平面上的信息转换到通道维度,再通过3*3卷积的方式提取不同特征。采用这种方式可以减少下采样带来的信息损失 。
训练速度更快
YOLOV8
改进点
anchor free
用离散分布的期望值分别去计算anchor center与四条边的距离
为配合Anchor-Free、以及提升泛化性,在v8中,增加了DFL损失, 使用Decoupled-Head
回归头的通道数也变成了4*reg_max的形式
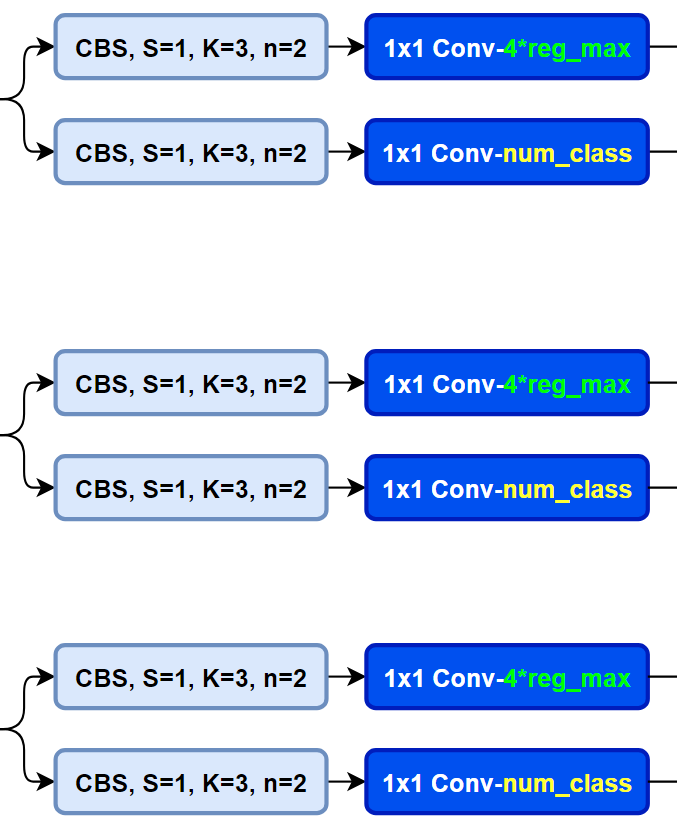
样本分配策略
在Task Alignment Learning(TAL)中,正负样本的分配机制是通过任务对齐度量 t 来实现的。以下是详细的分配过程:
- 任务对齐度量 t 的计算
任务对齐度量 t 是通过分类得分 s 和IoU值 μ 的加权组合来衡量锚框的任务对齐程度:
t=s α ×μ β
其中:
s 是锚框的分类得分。
μ 是锚框与真实框(GT box)的IoU值。
α 和 β 是超参数,用于控制分类和定位任务的权重。 - 正样本的分配
对于每个真实框(GT box),选择具有最大 t 值的 m 个锚框作为正样本。这里的 m 是一个超参数,用于控制每个GT框分配的正样本数量。 - 负样本的分配
未被选为正样本的锚框则被分配为负样本。 - 重复分配的处理
如果一个锚框被多个GT框同时分配为正样本,则选择与该锚框具有最大IoU值的GT框作为其最终的正样本。 - 过滤负样本
通过任务对齐度量 t,可以进一步过滤掉那些虽然在GT框内部但IoU值或分类得分较低的锚框,确保负样本的质量。
总结
TAL通过任务对齐度量 t 动态地选择高质量的正样本,并过滤掉低质量的负样本,从而提高分类和定位任务之间的一致性。这种机制使得模型能够更专注于那些分类得分高且定位准确的锚框,从而提升整体性能。