怎样用 esProc 提速主子表关联时的 EXISTS
数据库中,大主子表之间进行 EXISTS 计算往往会导致较差的性能。这样的计算本质上是在做连接,如果能预先将主子表都按照主键有序存储,就可以使用有序归并算法有效提速。这种算法只需要对两个表依次遍历,不必借助外存缓存,可以大幅降低计算量和 IO 量。
esProc 支持有序归并算法,可以把主子表的 EXISTS 转化为有序归并,从而显著提升计算性能。
下面通过订单和订单明细的例子,比较一下 esProc SPL 和 MYSQL 数据库计算主子表关联时 EXISTS 和 NOT EXISTS 的性能。
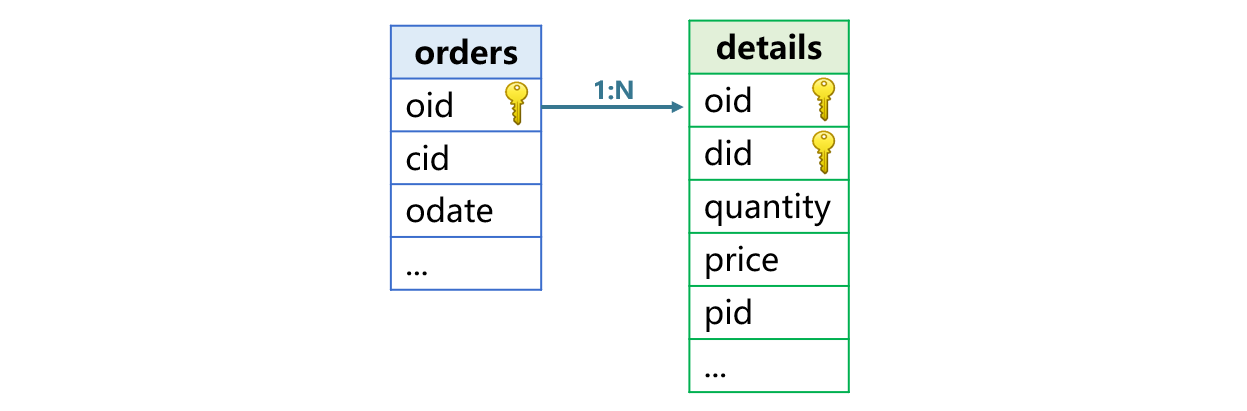
MYSQL 数据库中,订单表 orders 存储了 2024 年全年订单,主键是订单号 oid,字段有客户号 cid,日期 odate,数据量一千万。订单明细表 details,主键是 oid 和明细号 did,字段有数量 quantity,单价 price,产品号 pid,数据量 3 千万。
测试环境:VMWARE 虚拟机,8 核 CPU,8G 内存,SSD 硬盘。操作系统是 Win11,MYSQL 版本是 8.0。
先下载 esProc » esProc Download - esProc SPL Official Website,用标准版就可以了。
安装 esProc 后,试一下 IDE 是否可以正常访问数据库。先把 MYSQL 数据库的 JDBC 放到目录 "[安装目录]\common\jdbc",这是 esProc 的类路径之一:

在 esProc 中建立 MYSQL 数据源:
返回到数据源界面并连接刚才配置的数据源,如果数据源名变成粉色,说明配置成功。
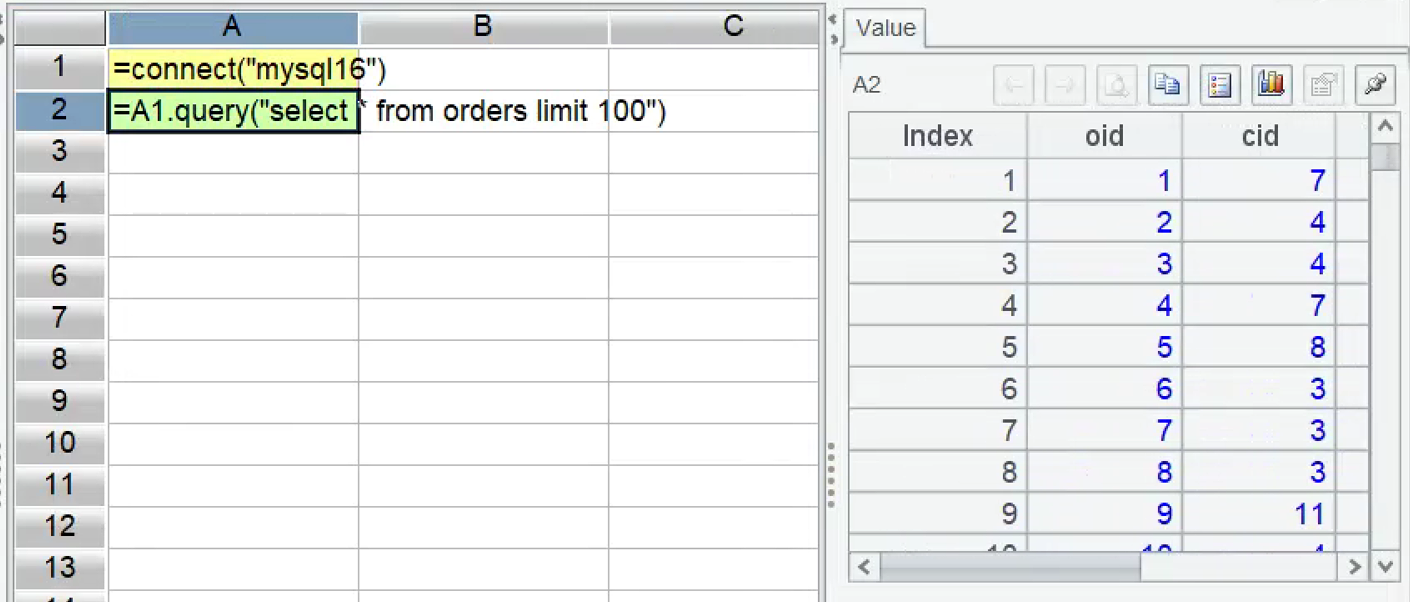
在 IDE 中新建脚本,编写 SPL 语句,连接数据库,执行 SQL 读入 orders 表部分数据:
| A | B | |
| 1 | =connect("mysql16") | |
| 2 | =A1.query("select * from orders limit 100") | |
按 ctrl-F9 执行,可以在 IDE 右边看到 A2 的执行结果,很方便。
接下来完成数据准备,把历史数据从数据库导出到 esProc 的高性能文件:
| A | |
| 1 | =connect("mysql16") |
| 2 | =A1.cursor("select oid,cid,eid from orders order by oid") |
| 3 | =file("orders.ctx").create(#oid,cid,eid) |
| 4 | =A3.append(A1) |
| 5 | =A1.query("select oid,did,quantity,price from details order by oid") |
| 6 | =file("details.ctx").create@p(#oid,did,quantity,price) |
| 7 | =A6.append(A5) |
| 8 | >A1.close(),A3.close(),A6.close() |
A2 生成 orders 表的数据库游标。
A3 建立组表对象,# 表示组表对 oid 有序。A4 将数据库游标数据追加到组表中。
A5 到 A7 照样生成明细表 details。注意 A6 中 create 函数增加了 @p 选项,这是因为子表 details 中的关联字段 oid 值并不是唯一的,@p 表示第一个字段 oid 是分段键,这样可以防止分段读取时,把一个 oid 的明细记录拆分开。
数据准备完成后,就可以利用 esProc 实现 EXISTS 提速了。
问题一,指定日期范围内,对包含 7 号产品的订单,按照客户号分组统计个数。
SQL 这样写:
select o.cid, count(o.oid)
from orders o
where o.odate >= '2024-12-31'and o.odate < '2025-01-01'and exists
(select * from details dwhere d.oid = o.oidand d.pid=7)
group by o.cid日期范围只有一天,MYSQL 就执行了 114 秒。
esProc 把 EXISTS 转换为主子表的关联:
| A | |
| 1 | =file("orders.ctx").open().cursor@m(oid,cid;odate>=date(2025,12,31) && odate<date(2026,01,01)) |
| 2 | =file("details.ctx").open().cursor(oid;quantity==7;A1) |
| 3 | =A2.group@1(oid) |
| 4 | =joinx(A1:o,oid;A3:d,oid) |
| 5 | =A4.groups(o.cid;count(o.oid)) |
A1、A2 按照条件过滤主子表。
A3 把 7 号产品的订单明细,按照 oid 有序分组,每组只保留第一个 oid,这样不用生成分组子集,性能更好。分组结果在 A4 中和订单表有序归并,再在 A5 中分组统计订单数量。
特别注意的是,A2 中游标的最后一个参数是 A1,表示多线程并行时,details 表会跟随 orders 表分段,保证后面两个表有序归并的正确性。
执行时间:0.8 秒。
问题二,产品号为 6 的订单明细,有多少条在订单表中找不到记录:
select count(d.oid)
from details d
where d.pid = 6and not exists (select * from orders owhere o.oid = d.oid)
MYSQL 跑了 9 分钟。
esProc 的写法:
| A | |
| 1 | =file("orders.ctx").open().cursor@m(oid) |
| 2 | =file("details.ctx").open().cursor(oid;quantity==6;A1) |
| 3 | =joinx@d(A2,oid;A1,oid) |
| 4 | =A3.skip() |
A3 中 joinx 的选项 @d,表示用订单表过滤明细表,只保留在订单表中找不到的 oid。
A4 对 A3 游标计数,就是想要的结果了。
执行时间:1 秒。
问题三,找出明细不止一条,而且不包含 9 号产品的订单,按照日期分组统计订单数量。SQL 用一个 EXISTS 和一个 NOT EXISTS:
select o.odate,count(distinct o.oid)
from orders o
where exists ( select 1from details dwhere d.oid = o.oidgroup by d.oidhaving count(*) > 1)and not exists (select 1from details dwhere d.oid = o.oid and d.pid = 9)MYSQL 跑了 10 分钟没有出来结果。
esProc 写法:
| A | |
| 1 | =file("orders.ctx").open().cursor@m(oid,odate) |
| 2 | =file("details.ctx").open().cursor(oid,quantity;;A1) |
| 3 | =A2.group(oid) |
| 4 | =A3.select(~.count(oid)>1 && !~.pselect(pid==9)) |
| 5 | =joinx(A1:o,oid;A4:d,oid) |
| 6 | =A5.groups(o.odate;count(o.oid)) |
A3 把明细表按照 oid 有序分组。
A4 循环计算每一组,~ 表示当前组。只保留 oid 个数大于 1 且不包含 pid 为 9 的组。
执行时间:4 秒。
测试结果:
| MYSQL | esProc | |
| 计算一 | 114 秒 | 0.8 秒 |
| 计算二 | 9 分钟 | 1 秒 |
| 计算三 | 10 分钟没出来结果 | 4 秒 |
用 esProc 提速主子表关联时的 EXISTS,效果非常显著。
esProc 提速方案的前提是主子表数据都按照主键 oid 有序存储。如果有新增数据的话,一般来说都是新的主键 oid,直接在已有的组表基础上追加就可以了。
如果历史数据需要变动,比如修改、插入或者删除,就要麻烦一些。变动的数据量不大时,esProc 会写到一个单独的补区。在读取时补区与正常数据一起归并计算,这样访问时感觉不到补区的存在。
变动的数据量较大时,要重新生成全量有序数据,但是这个过程需要排序,耗时较长,不能频繁进行。
实际上,针对固定不变的历史数据的计算场景就非常多了,也有不少大主子表关联时的 EXISTS 计算亟需加速。这些场景采用 SPL 有序存储可以有效加速,而且实施起来非常方便。