通光散基因组-文献精读139
Marsdenia tenacissima genome reveals calcium adaptation and tenacissoside biosynthesis
通光散基因组揭示了钙适应性和通关藤苷生物合成

摘要
通光散(Marsdenia tenacissima)是一种广泛分布于中国西南部富钙喀斯特地区的药用植物。然而,缺乏参考基因组限制了分子技术在其育种、药理学和驯化中的应用。我们通过结合SMRT测序和Hi-C技术,构建了夹竹桃科的染色体级基因组装配。该基因组长度为381.76 Mb,98.9%的序列位于11条染色体上。基因组包含222.63 Mb的重复序列和21,899个预测基因模型,contig N50为6.57 Mb。系统发育分析显示,通光散在大约1343万年前从大戟属植物Calotropis gigantea分化。比较基因组学显示,通光散经历了古老的共有全基因组复制事件。该事件以及串联复制共同促成了基因家族扩展的70.71%。伪基因分析和选择压力计算表明,通光散基因组中存在与钙相关的适应性进化。钙诱导的差异表达基因(DEGs)主要富集在细胞壁相关过程。域(如Fasciclin和Amb_all)和顺式作用元件(如MYB和MYC)分别频繁出现在细胞壁差异表达基因的编码区和启动子区,这些基因的表达水平与钙信号相关的转录因子的表达水平显著相关。此外,钙的添加增加了通光散苷I、G和H的含量。该高质量基因组的可用性为遗传育种和分子设计提供了宝贵的基因组信息,并为通光散在喀斯特地区的钙适应提供了见解。
引言
钙是喀斯特地区最丰富的元素之一,是植物生长所必需的营养元素(Gao等,2019;Tang等,2019)。与其他元素相比,喀斯特土壤富含钙(Ca²⁺),其浓度可达37.68 g kg⁻¹。相比之下,铁和锌等其他营养元素的浓度要低10倍(Hui等,2015;Maranhão等,2020)。这些石灰岩土壤的钙可用性可达77.91%,其平均可用性为50.9%(Wang等,2011)。然而,关于生物如何适应喀斯特地区如此高浓度的钙(Ca²⁺)的数据,仅在长臂猿(即动物)中有所报道(Liu等,2019);对于附生植物尚未有此类数据报道。通光散(Marsdenia tenacissima)是一种多年生攀援植物,广泛分布于热带和亚热带亚洲的喀斯特地区(图1a)(Li等,2016)。根据新的被子植物系统发育组(APG)IV分类,该植物属于夹竹桃科的Marsdenia属(Madani等,2017)。与其他夹竹桃科植物相比,Marsdenieae分支似乎广泛分布于喀斯特地区的石灰岩中(Rodda等,2020;Santo等,2018),但其适应高钙浓度的机制尚不清楚。根据我们的调查,通光散能够在藤茎中积累大量钙(≥3 g kg⁻¹),为将其他植物引入喀斯特地区提供了钙适应模型。此外,其抗旱和抗盐等优良特性使得通光散成为恶劣环境中重建林地的理想植物。
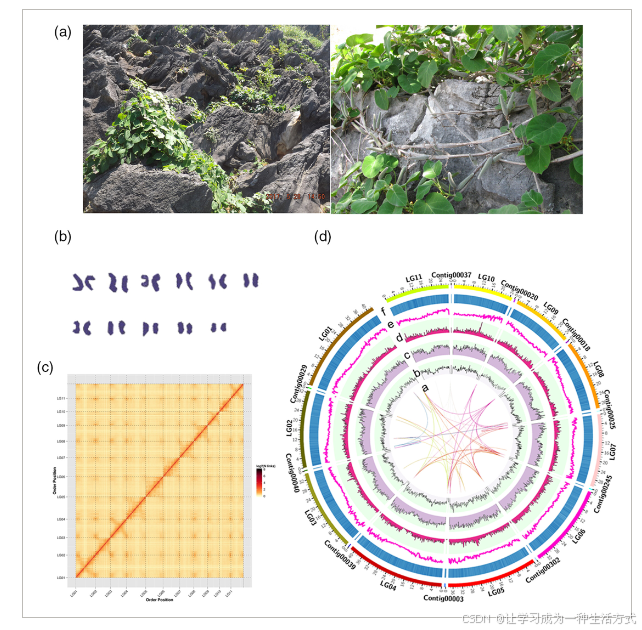
通光散的自然栖息地与染色体级基因组概述
(a) 通光散在喀斯特地区生长的照片。
(b) 基于染色体压片技术的核型分析。
(c) 高通量染色体构象捕获(Hi-C)的接触热图。
(d) 基因密度的Circos图展示。a,通光散中基因对的同源性;b,染色体上的大反转座衍生物(LARD)分布;c,SINE分布;d,LINE分布;e,染色体的基因密度;f,GC含量。
通光散传统上被用来治疗因哮喘、气管炎、咽炎和尿道炎引起的炎症(Zheng等,2014),其干茎提取物被用来开发一种新的抗癌药物“消癌平”,并已在临床试验中证明其有效性(Li等,2015)。通光散的主要生物活性成分是多氧孕烯糖苷,这些成分来源于与各种糖结合的C21类固醇(Panda等,2006)。迄今为止,已成功分离出六种类固醇骨架,包括40多种多氧孕烯糖苷,这些都是通光散苷B的衍生物(Deng等,2005;Li等,2014)。药理学研究表明,通光散苷B酯类衍生物能有效抑制癌细胞的增殖,并增强其他抗癌物质的体内抗肿瘤活性(Xie等,2019)。
随着“消癌平”需求的不断增加,当供应不足时,通光散的自然来源可能面临过度开发的问题。野生的通光散广泛种植在中国云南省的红河地区。然而,获取具有高品质和高产量的种质资源的需求促使我们从多个角度研究这种植物的遗传学。由于大多数研究集中在其最终产品的使用上,因此关于通光散的分子育种知识非常有限,主要是因为缺乏遗传信息。这一知识空白促使我们研究该植物在喀斯特地区长期适应过程中所发展出的基因组特征。
尽管长读长序列技术的快速发展已使许多作物的驯化和进化相关的遗传信息得以探索(Zeng等,2019),但关于夹竹桃科植物的研究却非常少。此外,通光散及其相关种(属于夹竹桃亚科)的参考基因组尚不可用。
本研究的目的是为理解通光散苷生物合成和钙适应性在脆弱的喀斯特地区提供遗传数据和理论支持。我们采用单分子实时(SMRT)测序和高通量染色体构象捕获(Hi-C)技术揭示了通光散的完整基因组。此外,我们还利用我们开发的高质量染色体级基因组序列,研究了通光散在喀斯特土壤中对钙(Ca²⁺)适应的转录调控机制。
结果
基因组的测序与组装
通过17 k-mer调查预测通光散基因组的大小为355.89 Mb,预计杂合率为0.50%,重复序列率为55.94%(图S1)。采用长读长SMRT平台获得了清洁数据(100.60 Gb,约263.51 ×),平均读取长度为29.64 kb,最大读取长度为264.29 kb。经过修正后,最终组装的基因组大小为381.76 Mb,得到的草图基因组的N50 contig值为6.57 Mb,LTR组装指数(LTR Assembly Index)为10.59。为了进一步评估组装基因组的完整性,我们首先将基因模型映射到1440个植物基因组基准(BUSCO)中的普遍单拷贝同源基因,注释了91.11%的基因。根据核心真核基因映射方法(CEGMA)分析,整个基因组包含了96.07%的458个核心真核基因(CEGs)(表S1)。然后,我们将315,071,505个Illumina HiSeq清洁读段映射回基因组,获得了约97.20%的比对率,表明组装基因组的质量和准确性较高。
利用Hi-C技术,我们生成了110 Gb(约288.14 ×)的清洁读段,Q30分数超过92.66%。我们成功地将218,898,765个读对唯一映射到草图基因组,其中85.30%的读对被验证为有效。基于染色体核型(图1b)及其碎片化、聚类、排序和定向,成功将草图基因组组装为11个簇,377.56 Mb(约98.9%)的基因组成功定位于11个染色体水平的超级框架(假染色体)。剩余的400个contig(约4.2 Mb)未定位。Hi-C组装的高质量通过基因组内染色体相互作用图的紧凑反对角线模式得以揭示,表明染色体组群明确(图1b)。六个最大假染色体包含了95%的组装基因组和96.44%的确认链方向。基于细化基因组,我们计算出基因密度为每Mb 57个,平均GC含量为31.55%(图1d)。总之,我们为通光散重新组装了一个染色体尺度的参考基因组,总长度约为381.76 Mb,位于11个染色体上。
基因注释与重复序列
通过结合de novo与同源性分析方法,我们发现通光散基因组中有222.63 Mb包含重复元件。重复序列占组装基因组的58.3%,其中转座元件(TEs)占92.29%。I类转座元件、II类转座元件和简单序列重复分别占基因组的47.76%、6.05%和1.06%。对于I类转座元件,逆转座、吉普赛、LARD(大反转座衍生物)和copia是最为丰富的超家族,分别占基因组的21.38%、12.77%和10.70%(表S2)。在RepeatMasker处理后,整个基因组的重复序列被屏蔽,以便进行注释。在通光散基因组中预测出21,899个基因模型,其中19,740个(90.14%)和17,857个(81.54%)分别通过同源蛋白和RNA-seq数据得到验证。总共21,015个基因转译蛋白(95.96%)可以功能性注释到五个公共数据库:NCBI非冗余数据库(NR)、蛋白质同源群体(COG)、基因本体(GO)、京都基因与基因组百科全书(KEGG)和TrEMBL(表S3)。进一步的COG分类发现,涉及翻译后修饰、蛋白质转运、分子伴侣和信号转导机制的序列在已知功能的基因中最为突出(图S2)。此外,我们还鉴定了非编码基因,包括107个rRNA、510个tRNA、69个微小RNA和1180个假基因。这些结果进一步加深了我们对通光散基因组序列的理解。
基因家族与系统发育
通光散基因组的基因家族以及来自Calotropis gigantea、Apocynum venetum、Gentiana dahurica、Cucumis sativus、Catharanthus roseus、Coffea canephora、Arabidopsis thaliana、Vitis vinifera和Amborella trichopoda的蛋白质序列在OrthoFinder中进行了聚类。总体上,15,118个正交基因簇包含228,507个基因,覆盖了79.91%的所有基因;所有物种的基因都以每个基因的单拷贝数为主(图S3)。这10个物种共享7992个正交基因簇,这些基因簇代表了一个祖先核心基因集(图2a)。然而,412个正交基因簇包含5170个物种特异性基因。共有233个基因属于115个特有的正交基因簇,这些基因特有于通光散。对这些基因的拟南芥同源基因进行KEGG富集分析,表明它们与氨基/核苷糖代谢和脂肪酸降解相关。基于它们的GO背景的富集分析显示,这些基因富集于NADH脱氢酶、氧化还原酶活性和离子结合途径。然而,只有51.33%的通光散物种特有基因有表达信号。通过将1170个对齐的单拷贝基因拼接成一个超级矩阵构建了10个物种的系统发育树,以揭示这些物种的系统演化。图2(c)显示,通光散与Calotropis gigantea关系较近。目前的系统发育位置与文献一致,表明它们属于同一个夹竹桃科亚科(Hassan等,2015),验证了我们构建的树。为了估算分歧时间,我们从TimeTree数据库中获取了Calotropis gigantea和Amborella trichopoda的校准点,并将其作为正常先验约束所有节点的年龄。通光散与Calotropis gigantea的分歧时间估计约为1343万年(图3a),紧随其后的是它们从共同祖先Apocynum venetum分化。
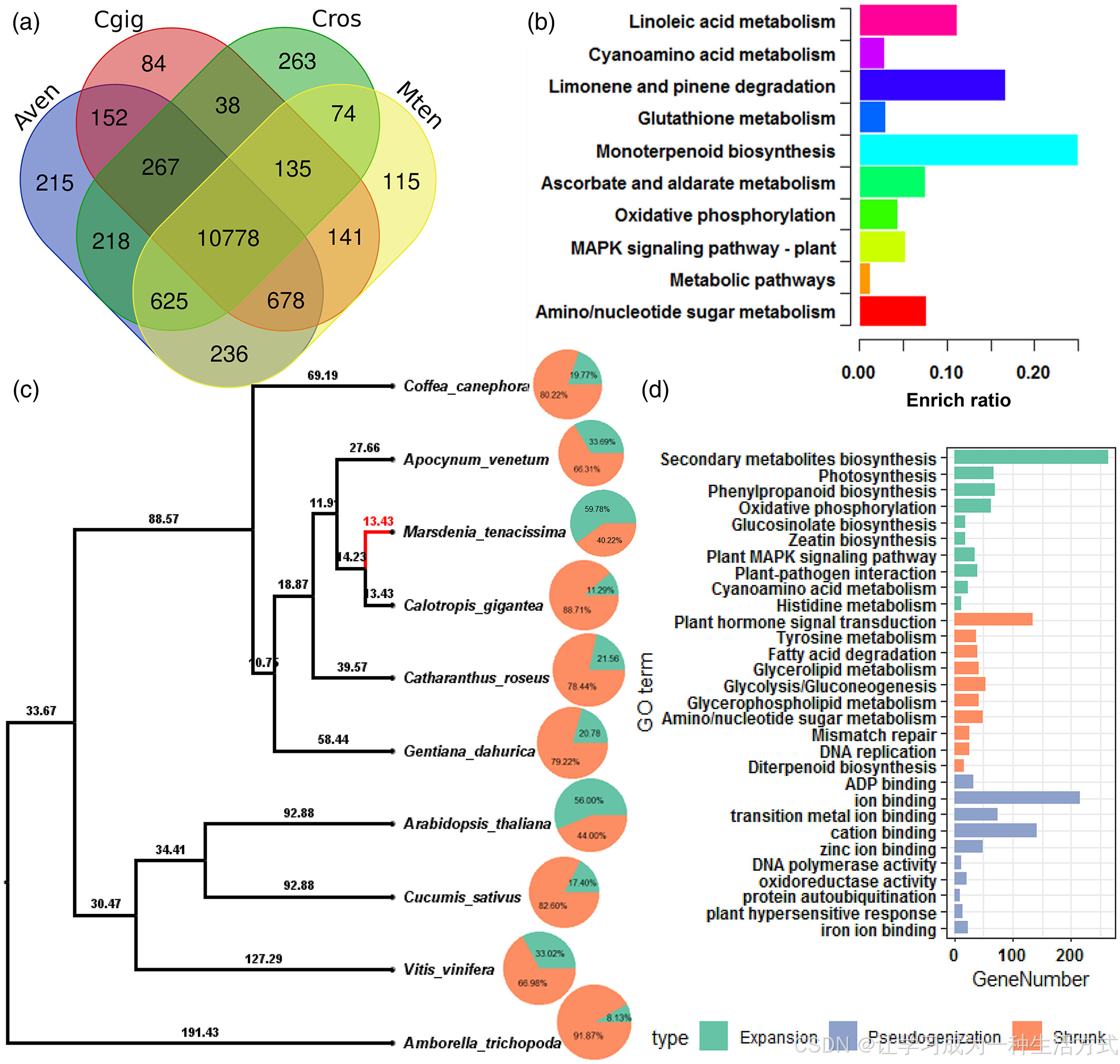
*通光散*的比较基因组分析
(a) Coffea arabica(Cara)、Calotropis procera(Cpro)、Catharanthus roseus(Cros)和通光散(Mten)中正交基因簇的维恩图。
(b) 通光散特有正交基因簇的基因本体(GO)富集分析。
(c) 通光散与10种已测序植物的系统发育树。树是通过1170个单拷贝基因的超级矩阵构建的。橙色区域表示基因家族的收缩比例,蓝色区域表示基因家族的扩展比例。
(d) 扩展、收缩和伪基因化基因家族的GO富集分析。
*通光散*与其他物种的比较基因组分析
(a) Coffea arabica(Cara)、Calotropis procera(Cpro)、Catharanthus roseus(Cros)和通光散(Mten)中正交基因簇的维恩图。
(b) 通光散特有正交基因簇的基因本体(GO)富集分析。
(c) 通光散与Calotropis gigantea的基因组共线性分析。
(d) 扩展、收缩和伪基因化基因家族的GO富集分析。
基因家族的扩展与收缩在开花植物适应性进化中的深远作用(Shang等,2020),因此我们进一步通过使用CAFÉ程序比较了通光散与其祖先基于系统发育的基因家族动态。与其共同祖先相比,通光散中492个基因家族显著扩展,而331个基因家族显著收缩(图2c)。其中,2492个基因通过GO数据库进行了注释。这些扩展的基因家族主要与次级代谢、光合作用、苯丙烷类生物合成和氧化磷酸化相关。相比之下,收缩的基因主要参与植物激素信号转导、酪氨酸代谢、脂肪酸降解和甘油脂代谢(图2d)。值得注意的是,72.5%的扩展基因家族成员对Ca²⁺处理有响应,且转录本每千碱基的片段数(FPKM)折叠变化至少为1.5(图S4)。然而,与某些其他离子(如锌和铁)结合的基因则已成为伪基因(图2d;图S4)。
基因组复制分析
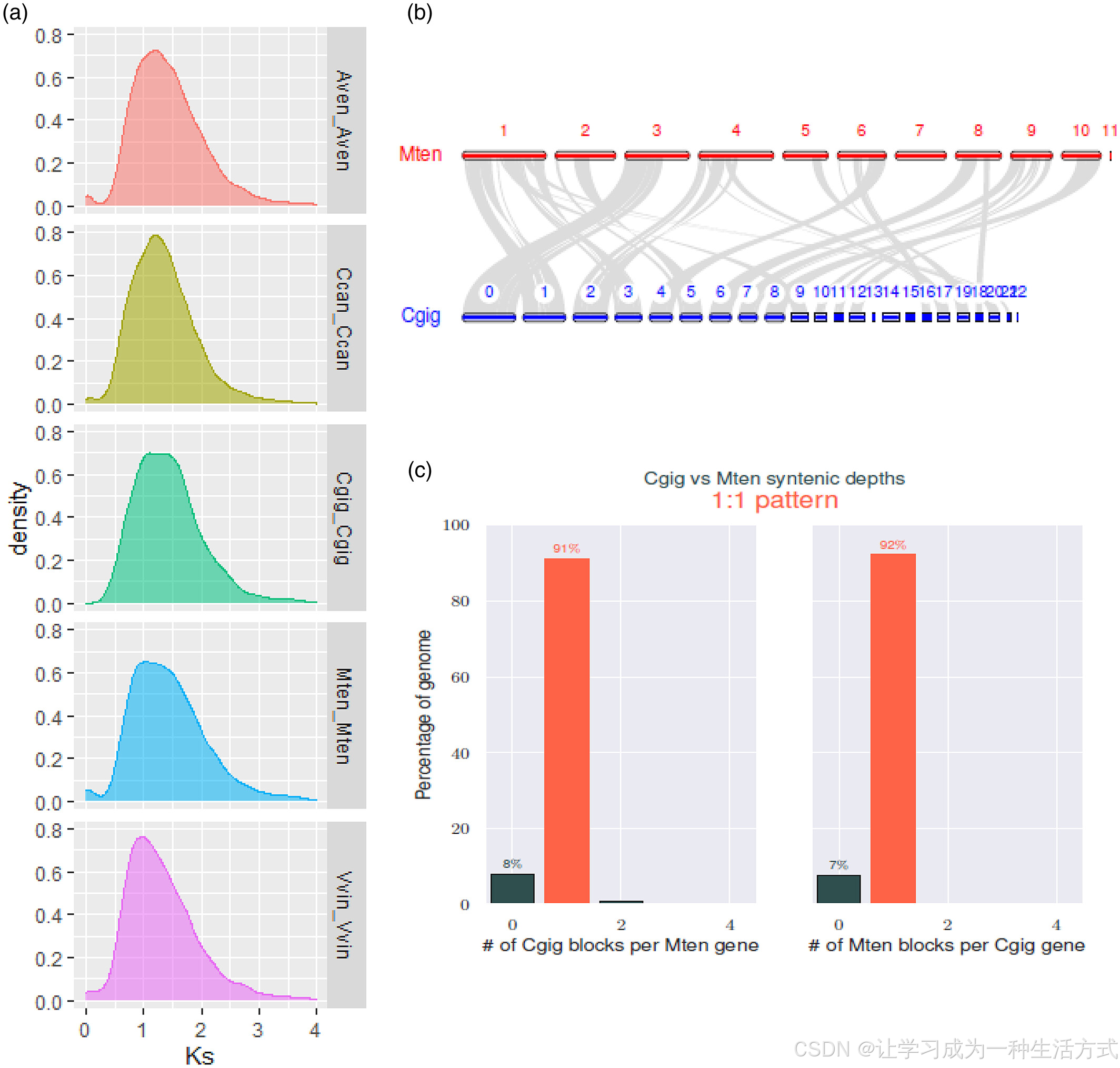
我们在通光散中识别出3092个包含9675个基因的共线性区块,这些区块代表了该物种的全基因组复制(WGD)事件,占21,899个注释基因模型的44.18%。近端重复、串联重复、离散重复和单拷贝基因的比例分别为4.76%(1043个)、11.52%(2523个)、25.12%(5501个)和14.42%(3157个)。由于WGD占据了基因对的最大比例,因此整个通光散基因组可能已发生复制。
所有同源基因的同义替代分布(Ks)表示与进化谱系相关的背景核苷酸的自然发生(Hasegawa等,1985;Li等,2009)。我们观察到通光散在~1.04的Ks值处经历了一个共同的WGD,这与其他物种的观察结果一致(图3a)。通光散基因组内同源基因对的共线性良好(图S5),且通光散与Calotropis gigantea基因组之间广泛的共线性也提供了Apocynaceae科中共同WGD的证据(图3b,c;图S5)。随后,我们调查了WGD在生成模式中的作用。有趣的是,扩展的同源基因主要来自WGD(37.61%)和串联重复(37.43%),而收缩的基因主要来自WGD(49.35%)。通光散特有的基因家族主要与WGD和离散重复(32%)相关,暗示其在物种形成过程中可能发生了适应性进化。
为了探究通光散的选择压力,我们对1170个单拷贝基因的编码序列进行了比对,并进行了正选择分析。我们观察到116个基因可能包含正选择位点。这些基因在硫胺素代谢、错配修复、N-糖基合成、肌醇磷酸代谢、甘油磷脂代谢等KEGG通路中功能富集,表明这些细胞组分可能在适应过程中发生了功能性进化。由于喀斯特土壤中磷含量与钙含量相关(Gao等,2019;Wei等,2018),我们评估了磷相关基因的非同义替代(Ka)与同义替代(Ks)比值。Ka/Ks比值表明,大多数参与磷稳态和获取的基因受到净化选择,作为功能性约束(图S6),这可能有助于通光散的环境适应。然而,锌和铁相关的离子结合基因已成为伪基因(图2d)。
通光散在喀斯特土壤中的钙适应性
由于通光散在基因组上表现出对高土壤Ca²⁺水平的适应,我们探讨了这一过程的转录调控作用。我们通过在三种不同Ca²⁺浓度下进行水培实验,研究了钙对幼苗生长的作用,即0 mmol L−1(无钙)、15 mmol L−1(正常钙)和50 mmol L−1(添加钙)。实验结果证实,钙对于正常幼苗生长至关重要,因为在无钙培养基中培养9天后,约90.9%的幼苗死亡,而所有幼苗在正常水培培养基中均生长良好(图4a)。
钙离子对通光散植物生长和基因表达的影响
(a) 通光散幼苗在正常(左)和无钙(右)营养液中的水培培养。
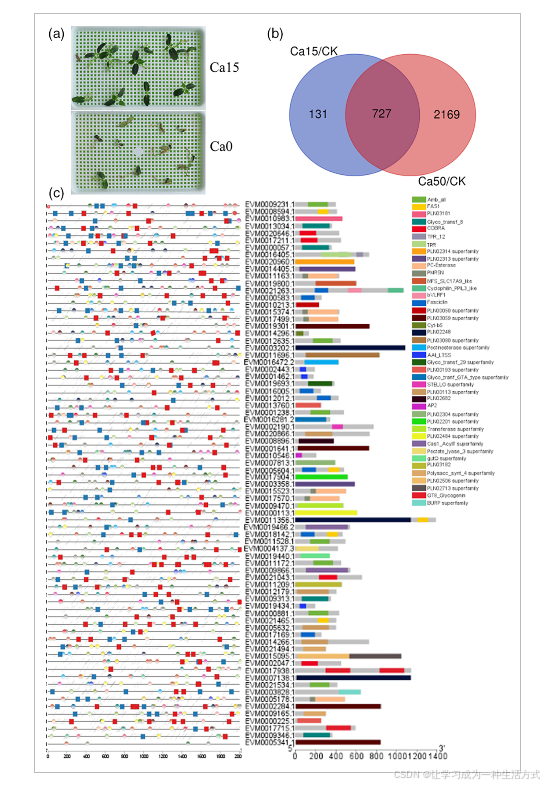
(b) 在水培培养中,15 mmol L−1钙(Ca15)和50 mmol L−1钙(Ca50)处理下差异表达基因(DEGs)的维恩图。
(c) 细胞壁相关差异表达基因(DEGs)的功能域。左侧为启动子顺式元件;右侧为基因功能基序。
通光散幼苗的表达谱显示,相较于在正常钙条件下生长的幼苗,补充额外钙离子的幼苗中有3027个差异表达基因(DEGs)(图4b)。来自基因组复制的扩展基因表达水平显著(P < 0.05)高于通光散特有基因模型的基因表达水平(图S4)。这些差异表达基因主要富集在细胞壁组织或生物合成(GO:0071554)以及细胞壁多糖代谢过程(GO:0010383;图S7)相关的通路中,并主要参与“转运蛋白”、“信号传导过程”和“苯丙烷类生物合成”以及其他“次级代谢产物”途径(表S4)。在钙离子通路中,某些钙离子受体基因(如编码环核苷酸通道、质膜ATP酶、谷氨酸受体家族、信号传感器如钙调素样基因、钙调素反应基因、钙调蛋白、钙调素B样/钙调素B样相互作用蛋白激酶及钙依赖性蛋白激酶等)在钙离子处理下上调(图5)。所有这些基因已被报告直接或间接与转录因子如Myb类蛋白(MYB)和bZIP相互作用(Kawamoto等,2015;Wang等,2017;Yoo等,2005)。
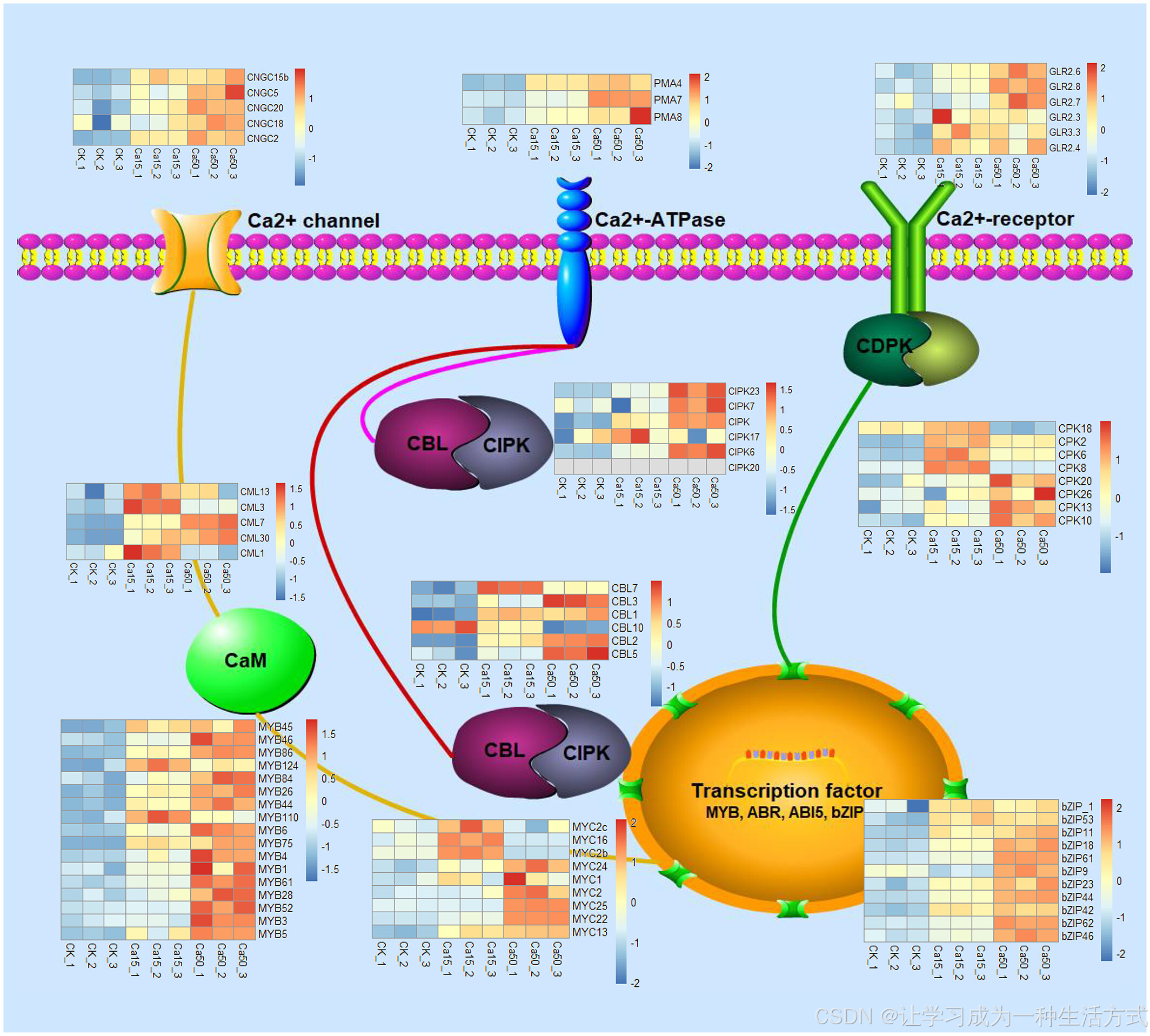
功能域预测显示,细胞壁相关的差异表达基因(DEGs)中的果胶相关酶,如果胶酯酶(PF01095)、果胶裂解酶(PF00544)和果胶甲酯酶抑制因子(PMEI;PF04043)最为丰富(图4c)。有趣的是,在这76个细胞壁相关的差异表达基因中,MYB和Myc原癌基因(MYC)调控元件分别出现在66个(86.84%)和65个(85.53%)启动子中。相关性分析显示,26个转录因子与76个果胶相关酶之间有71.74%的配对显示出显著(R > 0.7)相关性(图S8)。
正如我们之前在克隆的多氧孕烯糖苷途径基因的启动子中发现了MYB和MYC等顺式元件(Long等,2020),我们还研究了Ca²⁺对通光散苷类次级代谢物的影响。高效液相色谱(HPLC)分析显示,Ca²⁺处理提高了通光散苷I、G和H的含量(图6),表明这些活性代谢物是基因组适应喀斯特钙水平的结果。
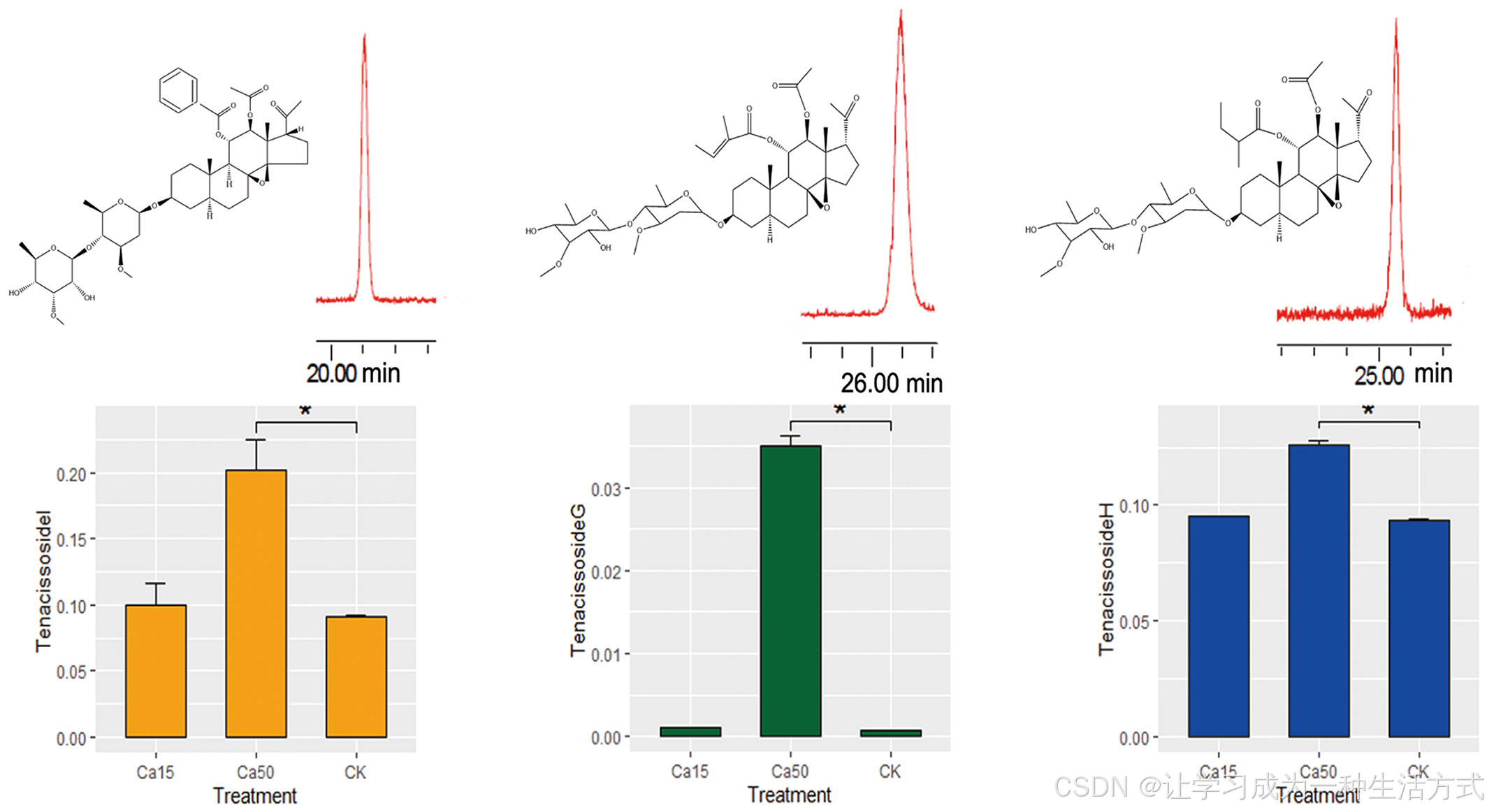
钙离子对通光散苷含量的影响:在水培培养中使用15 mmol L−1 Ca²⁺(Ca15)和50 mmol L−1 Ca²⁺(Ca50)条件下的研究
通光散苷生物合成途径预测
为了更好地理解通光散苷的生物合成,我们通过对整个基因组的搜索确定了推测的生物合成途径(图7)。根据之前的研究(Fujita等,2006;Lindemann & Luckner,1997;Morikawa等,2009;Rieck等,2019),假定细胞色素P450(CYP)催化胆固醇转化为孕烯醇,之后经过逐步转化为3β-羟基-5α-孕烯-20-酮、过渡中间体5α-8,14-氧代孕烯-3,12β,11α-醇-20-酮,最终在UDP-葡萄糖醛酸转移酶(UGT)和ACT等酶的作用下转化为通光散苷。
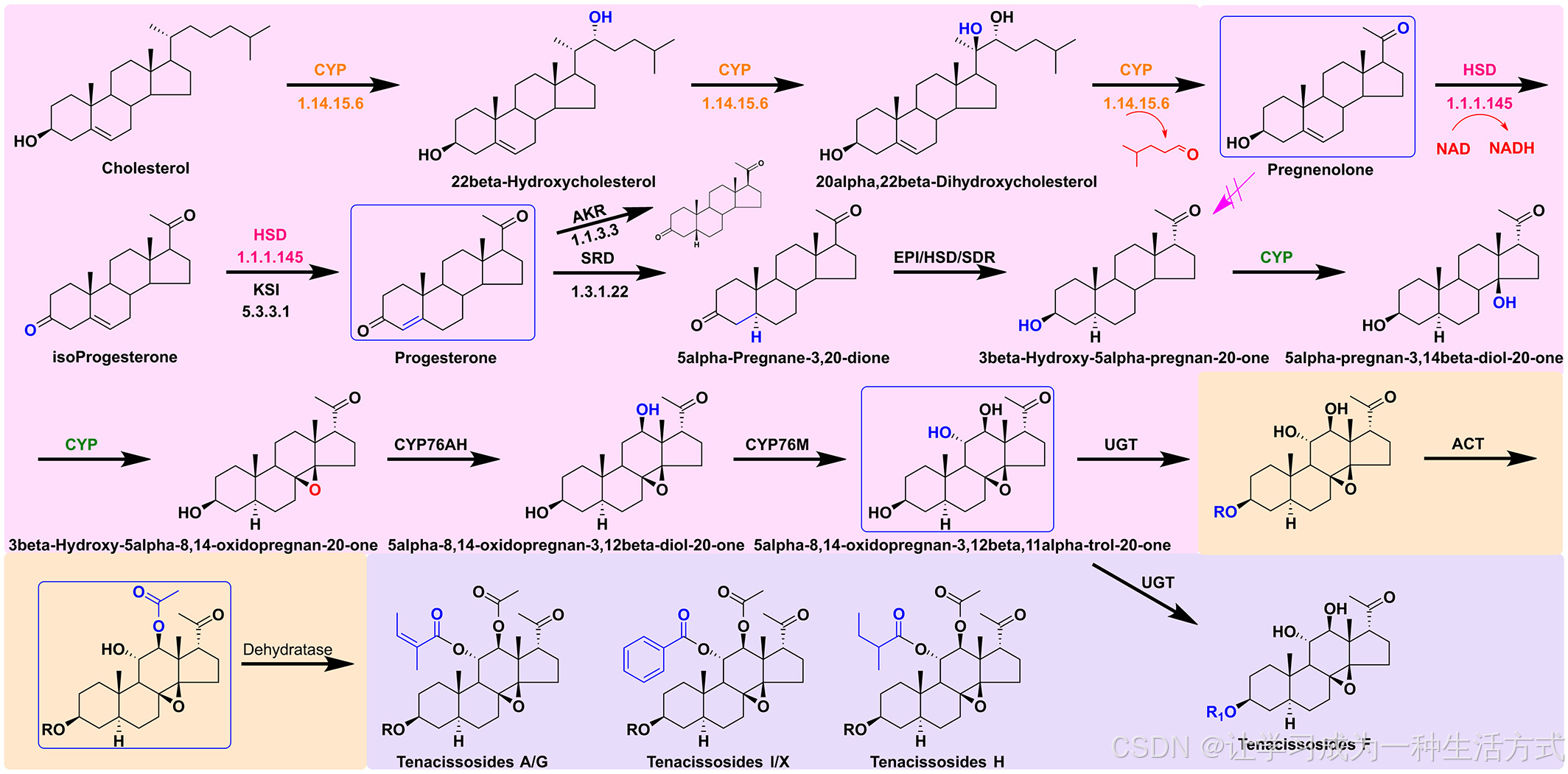
通光散苷生物合成的推测途径
讨论
目前仅有少数夹竹桃亚科基因组已被测序,且均采用Illumina短读长技术(Hoopes等,2018),然而尽管通光散具有潜在的药用价值,但该属的基因组尚未有公开数据。通光散,作为一种具有抗炎、抗哮喘、治疗疖病和抗癌效果的夹竹桃亚科物种,广泛分布于热带和亚热带的喀斯特地区。本研究通过结合长读长测序技术、短读长修正和染色体构象捕获技术,生成了通光散的染色体级基因组组装。尽管两者的基因组大小相似,通光散基因组(21,899个基因)远低于MSU水稻基因组(Kawahara等,2013)的55,986个基因模型。这可能归因于夹竹桃科基因研究的稀缺以及通光散基因组中较高的重复序列比例(58.32%,而水稻为39.50%)。这一高质量的通光散基因组为比较基因组学和进一步的功能研究提供了参考。
随着参考基因组和重测序数据的可用,我们有机会将通光散与其他遗传背景的物种进行比较。Ks峰值和共线性分析揭示了通光散物种形成过程中发生了一次共同的全基因组复制(WGD)事件,这可能推动了其适应喀斯特地区的殖民。WGD不仅促进了基因家族的扩展和物种特有基因的起源,还导致了基因家族的收缩,这可能在强烈的选择压力下重新塑造。我们沿系统发育树追踪了扩展基因对Ca²⁺的响应,发现这一响应在夹竹桃科的共同祖先(如Apocynum venetum)处达到了75.53%的峰值,提示这一事件可能至少在夹竹桃亚科分化之前就已经存在。Santo等(2019)也发现了其他几个Marsdenieae物种的喀斯特分布。我们还发现,在研究的九个物种中,通光散新起源了两个无机磷酸盐转运蛋白(EVM0003134.1 和 EVM0003701.1)。通光散与Gentiana dahurica的Ka/Ks比值表明,编码磷获取转运蛋白的基因在自然选择的作用下受到了更强的功能约束(图S6),促使钙和磷的沉淀以及它们在喀斯特型土壤中的存在(Wei等,2018)。例如,钙结合磷是喀斯特农田-湿地生态系统中的主要成分(Gao等,2019)。相比之下,我们还发现,像锌和铁这样的阳离子受到了相关基因伪基因化的约束,因为富含石灰质的土壤导致这些离子的缺乏(Hemmaty等,2012)。因此,本研究支持钙推动通光散适应性进化的假设。由于新基因通常推动适应性进化(Chen等,2013),该物种特有的基因也可能参与钙适应。然而,在钙相关的差异表达基因(DEGs)研究中,扩展基因的表达水平明显高于通光散特有基因模型(图S4)。这与新基因的低表达特征一致,并表明扩展基因在适应过程中起到的作用超过了物种特有基因。
喀斯特土壤中高含量的钙离子促使植物吸收这一丰富元素。在植物细胞中,细胞质中的Ca²⁺通过被动的Ca²⁺通道流动和通过细胞壁、质膜以及内膜上的Ca²⁺相关转运蛋白受到严格调控(Lecourieux等,2006)。因此,细胞壁的基因在很大程度上会受到Ca²⁺的调节,因为细胞壁是抵御外界因素的第一道屏障(Loix等,2017;Miedes等,2014)。细胞中过多的钙对植物的生存是有害的(Case等,2007;White & Broadley,2003)。因此,植物通常会采取预防措施来应对过多的钙。首先,它们可以通过隔离作用将多余的离子封存在细胞器中(Orrenius等,2003;Petersen,2002)。其次,植物可以通过受控吸收或离子排出缓解离子的积累(Gilliham等,2011;Jin等,2018;Li等,2007)。然而,植物自身抑制吸收或排放的能力是非常有限的(Jin等,2018)。在本研究中,通光散似乎采用了另一种策略来克服这一难题,即利用Ca²⁺在细胞壁生物合成中的局部作用。这可以解释我们在纤维素酶裂解的细胞壁部分中观察到的高Ca²⁺浓度(表1)。
Table 1. Ca2+ concentration in supernatant and residual of cellulase-treated cell wall (mg L–1)
| Component | CK | Ca15 | Ca50 |
|---|---|---|---|
| Supernatant | 1.96 ± 0.02a | 2.42 ± 0.02b | 3.48 ± 0.02c |
| Residual | 11.09 ± 0.04a | 12.84 ± 0.04b | 13.62 ± 0.06c |
同一行中不同字母表示Ca²⁺处理水平之间差异显著。 对这些Ca²⁺诱导的细胞壁蛋白功能结构域的分析显示,Fasciclin结构域和Amb_all(果胶裂解酶)结构域出现频率最高,这与果胶和纤维素是细胞壁主要组成成分的事实一致(Broxterman & Schols, 2018;Jamet等,2008)。类Fasciclin阿拉伯半乳聚糖蛋白通常参与纤维的起始与发育(Huang等,2013)。果胶裂解酶则通过去聚合作用催化细胞伸长和细胞壁降解(Leng等,2017;Sun等,2020)。Ca²⁺结合的碱性残基可能参与果胶与其他多糖(如纤维素)之间的结构支架构建,从而重塑细胞壁完整性(Broxterman & Schols, 2018;Feng等,2018)。在候选基因中,一个果胶裂解酶(EVM0004001)、一个SHN型角质和木栓质合成相关基因(EVM0019724)以及一个COBRA样纤维素微纤丝与半纤维素互作蛋白(EVM0021043)在根部的表达量最高,可能直接促进其对高钙土壤的适应。
总结
本研究成功组装了通光散的基因组,并报告了其染色体级别的测序、组装与注释。基因组分析揭示了与Ca²⁺信号通路相关的基因家族,可能参与环境适应和通光散苷的生物合成。幼苗对高Ca²⁺胁迫的转录组响应表明,细胞壁相关基因被显著诱导,并与MYB和MYC类转录因子相关。因此,我们提出了一个模型:在喀斯特土壤中适应的植物中,通过将过量钙用于细胞壁的生物合成与重塑,从而缓解Ca²⁺胁迫。未来我们可在更多喀斯特植物中深入研究Ca²⁺适应机制,并进一步聚焦细胞壁层的详细研究。
实验方法
植物材料
通光散幼苗预培养1个月后,选取长势一致的植株于Hoagland水培营养液中继续培养。营养液分别添加Ca²⁺至0、15和50 mmol L⁻¹,分别设为无钙处理、正常钙处理和高钙处理,每3天更换一次营养液。每组设4株植株,3个生物重复。培养15天后,在人工气候箱内(光暗周期12/12 h,光照强度8000 Lux,相对湿度65–70%)收集样本并冷冻保存(−80°C)以备后续分析。组织特异性RNA测序样本采自蒙自科研示范基地(23°8'8'' N, 103°22'50'' E)生长的3年生植株。基因组测序材料采自新鲜嫩叶。
转录组分析
RNA提取使用Omega植物RNA提取试剂盒(R6827, Omega Bio-Tek, Norcross, GA, USA),经琼脂糖凝胶电泳、微量分光光度计(Nanodrop 2000)和Agilent 2100检测RNA完整性。带polyA尾的mRNA用oligo(dT)磁珠富集并通过超声打断。随后在M-MuLV反转录酶反应体系中使用随机引物合成第一链cDNA,接着以dNTP和DNA聚合酶I合成第二链cDNA。纯化的cDNA经末端修复并连接polyA接头,最终通过AMPure XP磁珠纯化筛选长度约200 bp的片段并扩增建库。RNA测序在Illumina HiSeq 2000平台进行。
转录组数据已上传至NCBI,登录号为PRJNA715100。原始reads经质量控制和截短处理后,使用HISAT2(Kim等,2019)默认参数将多个RNA-seq数据集比对至通光散基因组,并通过StringTie(Pertea等,2015)进行表达量定量。使用DESeq2(Love等,2014)筛选差异表达基因(阈值:log₂FC > 1,P < 0.01)。提取了与细胞壁相关基因的比对数据,并统计其在不同组织和处理条件下的FPKM值。
DNA提取
按照Xu等(2021)的方法从新鲜叶片材料中提取基因组DNA。通过Thermo Fisher NanoDrop 8000分光光度计和Invitrogen Qubit荧光计评估DNA质量。其260/280吸光比为1.84,260/230吸光比在1.84至2.35之间。基因组DNA浓度为546 ng/μL,总产量为30.24 μg。随后取100 ng进行0.3%琼脂糖凝胶电泳,结果显示主要DNA条带大于48.5 kb,符合测序文库构建的质量标准。高质量DNA被剪切为约20 kb的片段,并通过Agencourt AMPure XP磁珠进行富集与纯化。
基因组大小估算与初步组装
短读长测序文库按制造商协议构建。通过k-mer分析法估算通光散的基因组大小(Chor等,2009)。杂合度通过k-mer分布并借助GenomeScope软件(Vurture等,2017)确定。
在SMRT测序中,取2 μg高分子量的基因组DNA,在SonicMan微孔板超声仪(Brooks Automation)中剪切,并使用NEB Next FFPE DNA修复试剂盒(M6630,NEB,美国)进行修复,随后依据Oxford Nanopore Technologies(ONT)的文库构建试剂盒(SQK-LSK109,英国)流程操作。候选DNA文库经Qubit荧光计纯化和定量。大片段文库与加载珠预混后,注入洁净的R9流动池,并在ONT PromethION平台上使用ONT测序试剂盒(EXP-FLP001.PRO.6,英国)进行测序。短读长和长读长测序的原始数据已提交至NCBI,登录号为PRJNA715027。
Hi-C文库构建与测序
Hi-C文库构建方法参照Rao等(2014)。上述新鲜叶组织在含36%甲醛的固定液中真空固定90分钟以交联DNA。经HindIII酶切后,粘性末端用生物素标记的dNTP进行填充并连接形成环。之后去交联并将DNA片段剪切为300–700 bp,用链霉亲和素磁珠富集构建DNA互作文库。使用Qubit 2.0荧光计和Agilent 2100生物分析仪分别检测文库浓度与插入片段大小。Hi-C原始数据由Illumina高通量PE150平台产生。
基因组纠错与组装
首先对单分子测序的原始reads进行Q20和Q30质量评估,剔除低质量reads与接头序列以获得清洁reads。从中筛选长reads作为种子数据,其余reads用于在Canu v1.5(Koren等,2017)中进行纠错。初始纠错后的reads在Canu中组装,并通过Racon(Vaser等,2017)进行两轮自我纠错,随后在Pilon中结合超过200×的Illumina数据进行三轮精修,获得初步基因组草图。
结合通光散的染色体核型图(图1b),利用Hi-C数据将基因组组装为11条拟染色体。清洁的Hi-C数据在去除原始数据中的连接部分后,通过Burrows–Wheeler Aligner(BWA,Li & Durbin,2009)比对至草图基因组。Hi-C-Pro筛选出有效的空间互作而非线性接近的配对reads。草图基因组被划分为50 kb的片段,随后对scaffold进行聚类、排序与定向。最终,在LACHESIS(Burton等,2013)中根据有效互作配对数据重新组装高精度基因组。通过CEGMA预测、BUSCO分析以及RNA-seq reads比对评估基因组草图的完整性。
基因组注释
通过LTR_FINDER和RepeatScout对M. tenacissima的物种特异性重复序列进行了去 novo 和结构性提取,在PASTEClassifier中进行了分类,并与Repbase合并,构建了一个综合的背景数据库。最后,通过RepeatMasker中的WUBlast比对算法完成了重复序列的注释(Tarailo-Graovac & Chen, 2009)。
基因预测基于集成的从头预测、同源性比对和RNA-seq证据策略。基因模型最初通过GENSCAN、AUGUSTUS(v2.4)、GlimmerHMM、GeneID v1.4和SNAP进行去 novo 预测,然后在GeMoMa中将同源基因与拟南芥(A. thaliana)、水稻(O. sativa)、咖啡(C. canephora)和长春花(C. roseus)的基因组信息进行比对。RNA-seq数据的基因结构在TransDecoder(v2.0)和GeneMarkS-T(v5.1)中根据参考组装预测,或在非参考组装的Trinity中通过PASA(v2.0.2)进行预测。所有相关结果通过EVM(v1.1.1)集成并合并为一个gff文件。伪基因预测通过GeneWise(Birney等,2004)进行。基因的功能注释通过BLAST(v2.2.3)对GO、KEGG、KOG、TrEMBL和NR数据库进行比对,默认参数下,e值设定为1×10−5。使用Circos工具(Introduction to Circos, Features and Uses // CIRCOS Circular Genome Data Visualization;Krzywinski等,2009)展示基因密度、GC含量、重复分布和基因同源性。
系统发育构建与基因家族比较
在Orthofinder v2.2.6中提取了八个物种(M. tenacissima、Calotropis procera、C. roseus、Coffea arabica、V. vinifera、C. sativus、Geum montanum 和A. trichopoda)中最长的蛋白质异构体,用于识别基因家族(Emms & Kelly,2015)。基于blastp算法,所有蛋白质序列被聚类为不同的直系同源基因组。通过将单拷贝基因序列合并成超级矩阵,选择单拷贝基因家族来估计八个物种的系统发育。单拷贝基因的串联蛋白序列在MAFFT(v7.429)中进行多重比对,并使用PAL2NAL(v14)将其恢复为密码子。基因超级矩阵在IQ-Tree中提交模型测试,然后使用RAxML(v8.2.12)以最佳GTRGAMMAIX模型构建系统发育树。通过采用paml4.9中的MCMCTree模块,将每个节点的分化时间校准为TimeTree(TimeTree :: The Timescale of Life;Kumar等,2017)中已知物种的参考时间。选择了TimeTree网站上的两个校准点作为先验,用于限制节点的年龄。树图在FigTree中进行可视化。
基于获得的系统发育结果,我们比较了每个物种与其最近祖先之间的簇大小差异,并使用CAFÉ软件(v4.2)分析了基因家族的扩展和收缩。对扩展或收缩基因家族的GO富集分析在KOBAS 3.0中进行(http://kobas.cbi.pku.edu.cn/index.php;Bu等,2021)。
正向选择
正向选择分析在单拷贝基因家族上进行。每个基因的树基于系统发育构建。将单拷贝基因家族的对齐密码子输入paml4.9中的codeML进行计算。将Marsdenia tenacissima设为基因树的前景分支。每个基因的正向位点通过控制文件中的分支位点模型确定。正向选择基因的GO功能富集分析在KOBAS中进行。
基因组复制和突变分析
基因的同源区通过MCScanX进行检测,基于每个物种最长蛋白异构体的全到全BLASTP比对。每个基因的最佳比对通过互惠最佳比对进行识别,然后通过MAFFT比对并恢复为密码子,以计算Ks。寄生基因对(物种内)的峰值代表WGD,而直系同源基因对(物种间)的峰值代表物种分化。通过paml中的yn00方法估算不同基因对之间的Ks值(Yang,2007)。Ks分布的可视化通过R脚本进行。
钙含量检测
为检测细胞壁中的钙含量,取0.1 g样品,在含有3 mL 250 mmol L−1蔗糖、14 mL 50 mmol L−1Tris–HCl和3 mL 1 mmol L−1二硫化物甘露醇溶液的冷提取液中浸泡过夜,然后以7000 rpm的速度在4°C下离心20分钟,获得细胞壁。通过去除上清液,采用HNO3:HClO4(4:1)消化细胞壁残渣,并用纤维素酶或果胶酶消化后进行钙含量的测定。样品中钙的含量通过原子吸收光谱法测定。
通关藤苷含量检测
从1 g研磨的样品中提取通关藤苷 I、G和H,采用50 mL甲醇超声处理45分钟,随后进行旋转蒸发、过滤和重溶至10 mL溶液。通过反相HPLC与蒸发光散射检测法,结合商业标准对这三种成分的定量进行校准。使用XBridge C18柱分离成分,样品用梯度流动相(40-45%的乙腈和60-55%的水)进行洗脱。