聚类之层次聚类与密度聚类
注:本文中所有公式和思路来自于邹博先生的《机器学习升级版》,我只是为了加深记忆和理解写的本文。
讲密度聚类之前,想先介绍一个聚类的评价标准:轮廓系数(Silhouette)
先抛出两个概念:
簇内不相似度:计算样本i到同簇其他样本的平均距离ai,ai越小,说明i越应该被分到该类中,那么ai称为i的簇内不相似度
计算簇内所有的样本的ai的均值叫簇C的簇不相似度。
簇间不相似度:计算样本i到其他簇Cj所有样本的平均距离bij,那么bij称为i的簇间不相似度。
我们可以对所有簇间不相似度取一个最小值:
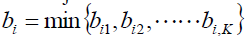
那么b越大,说明b越不属于其他的簇。
轮廓系数定义:
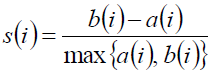
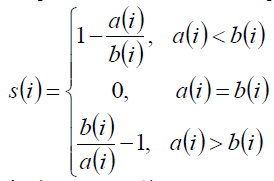
当si接近1时,则说明分类合理;若si接近-1,那么说明更应该分为其他的类;如果si接近于0,那么说明i在边界上。
所有样本的si均值称为聚类结果的轮廓系数。
层次聚类
凝聚的层次聚类:AGENS算法
一种自底向上的策略,最初将每一个对象作为一个簇,然后这些簇根据某些准则被一步步的合并。
两个簇间的距离由这两个不同簇中距离最近的数据点的相似度来确定。聚类的合并过程反复进行直到所有的对象最终满足簇数目
然后合并这些原子簇为越来越大的簇,直到满足终止条件。
分裂的层次聚类:DIANA算法
该算法是AGENS算法的逆过程,首先将所有的样本划归到一个簇,然后根据一些准则,将簇分开,直到达到所需的簇的数目或者达到了阈值。
簇内不相似度:计算样本i到同簇其他样本的平均距离ai,ai越小,说明i越应该被分到该类中,那么ai称为i的簇内不相似度
密度聚类
密度聚类方法的指导思想是,只要样本点的密度大于阈值,则将该样本点添加到最近的簇中。
密度聚类不仅可以对非圆形的数据进行聚类,并且对噪声不敏感,但是计算密度单元的计算复杂度大,需要建立空间索引来降低计算量。
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)
这是一个有代表性的基于密度的聚类算法。他将簇定义为密度相连的点的最大集合,能够将具有足够高密度的区域划分为簇,并在有噪声的情况下发现任意形状的聚类
听起来就很牛逼。。。。
首先说一下DBSACN的几个概念:
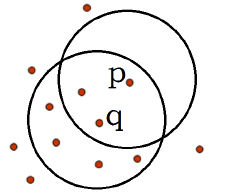
1. 对象的ε-邻域:给定对象在半径ε内的区域
2. 核心对象:对于给定的数目m,如果一个对象的ε邻域至少包含m个对象,则称该对象为核心对象。
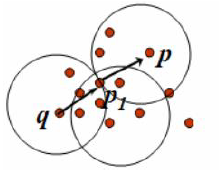
3. 直接密度可达:给定一个对象集合D,如果p是在q的ε邻域内,而q是一个核心对象,我们就说p从对象q是直接密度可达的。
如下图所示,ε=1cm,m=5,q是一个核心对象,从q到p是直接密度可达的:
4. 密度可达:如果存在一个对象链p1,p2...pn,p1=q,p2=p,对pi∈D (1 ≤ i ≤ n),pi+1是从pi关于ε邻域和m直接密度可达的,则对象p是从对象q关于ε邻域和m密度可达的:
5. 密度相连:如果对象集合D中存在一个对象o,使得对象p和q是从o关于ε邻域和m密度可达的,那么对象q和对象p是关于ε邻域和m密度相连的。
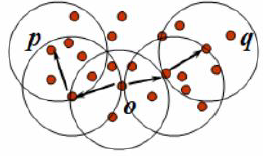
6. 簇:一个基于密度的簇是最大的密度相连对象的集合:
7. 噪声:不包含在任何簇中的对象称为噪声:
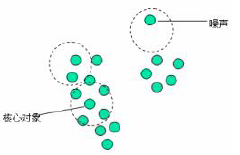
DBSCAN算法流程:
a. 如果一个点p的ε邻域包含多于m个对象,则创建一个p作为核心对象的簇
b. 寻找合并核心对象直接密度可达的对象
c. 没有新的样本点可以更新簇时,算法结束
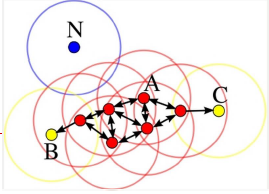
从算法中我们可以看得出,其实每个簇至少有一个核心对象,另外,如果不是核心对象,那么在簇中就一定是边缘。
密度最大值聚类
密度最大值聚类是我个人很喜欢的一种聚类算法,很优雅,很巧妙。一是可以可以识别这种各样的奇葩形状,另外参数比较好确定。
定义局部密度:ρi
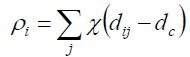
其中:
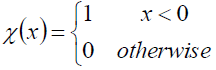
dc是一个类似于阈值或者截距,那么ρi其实是其他样本到i样本的距离小于dc的个数。
密度最大值聚类其实只对这个ρi是敏感的,所以对dc的选择是稳健的,推荐的dc的选法是,使得平均每个点的邻居数为所有点的1%-2%
高局部密度点距离:
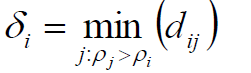
解释一下这个公式,假设i的局部密度为6,那么其他所有样本点的局部密度假设为3,5,8,9,那么我们就选择密度比i大的,也就是8,9,计算i到8,9这两个点的距离,然后从这些密度比i大的但是距离最小那个点的距离,这就高局部密度点距离的含义。换句话说,就是找所有比我有钱的人,然后计算我到所有比我有钱的人的距离,选择一个最小的距离就是我的高局部密度点距离。
那么我们试想一下,如果一个样本,它的高局部密度点距离很大,并且,他的局部密度很大,那说明是什么呢?说明了比他密度大的点离他很远很远,并且她身边有很多点,那他不就是聚类中心么。再想一下,如果一个点高局部密度点距离很大,但是身边没几个点,说明什么啊,他就是噪声嘛。再想一下,如果一个点的高局部密度点距离很小,身边很多点,这又是什么呢?那他就是围绕在聚类中心的一个普普通通的点嘛。是不是特别有趣,当然了,如果用金钱来说明这个问题,也很有意思的,我就不罗嗦了。
那么我们通过一幅图,就可以很清楚地说明白上边这段话:
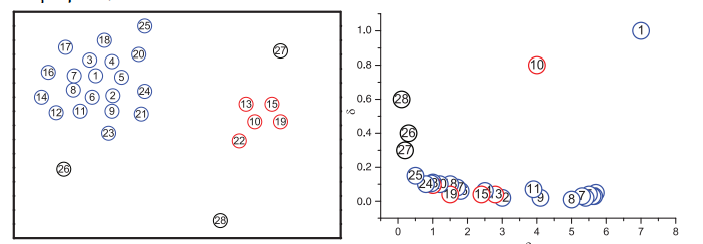
很简单,我就不解释了
到此密度聚类就介绍完了,下文将会介绍一个很重要的聚类算法-谱聚类。