图像处理基础
图像读取与保存
图像是由一个个像素点组成,像素点就是颜色点,而颜色最简单的方式就是用RGB或RGBA表示
图像保存
图像将像素信息按照 一定格式,一定顺序(即编码) 存在硬盘上的 二进制文件 中
保存图像需要以下必要信息:
1. 文件名和路径
2. 文件格式
3. 压缩参数(jpeg图像的压缩质量等)
图像读取
将而二进制文件还原为 像素排布
图像编码
目的:压缩 (有损压缩,无损压缩)减小数据大小
有损压缩: 解压缩后的数据与压缩前的数据不一致.在压缩的过程中要丢失一些人眼和人耳所不敏感的图像或音频信息,而且丢失的信息不可恢复。
无损压缩: 压缩前和解压缩后的数据完全一致。优化数据的排列等。
补充:【端到端指的是直接输入原始数据,让模型自己去学习特征,最后输出结果
非端到端呢,简单来说,就是我们的输入数据首先经过人工处理,在喂给模型去训练】
常见编码:PNG 无损压缩,BMG 无损压缩,JPEG 有损压缩
PNG
PNG图像格式文件(或者称为数据流)由一个8字节的PNG文件署名(PNG file signature)域和按照特定结构组织的3个以上的数据块(chunk)组成。
PNG定义了两种类型的数据块,一种是称为关键数据块(critical chunk),这是必需的数据块,另一种叫做辅助数据块(ancillary chunks),这是可选的数据块。
Critical Chunk(关键数据块),有四种类型:
IHDR,header chunk,包含有图像基本信息,作为第一个出现的数据块并且只出现一次。
PLTE,palette chunk,调色板数据块,必须存放在图像数据块之前。
IDAT,image data chunk,存储实际的图像数据。PNG数据包允许包含多个连续的图像数据块。
IEND,image trailer chunk,图像结束数据,表示PNG数据流结束。

其中ihdr的结构为:4字节为chunk length,4字节为chunk type
剩下13字节的ihdr为:
宽(无符号整,4字节)
高(无符号整,4字节)
bit deep位深(无符号char,1字节)
颜色类型(无符号char,1字节)
压缩方法/滤波方法/隔行扫描法(都是unsigned char 1字节)
https://www.jb51.net/article/199586.htm
# 首先读取二进制文件
f = open("E:/DeepLearning/计算机视觉/cv101-master/dataset/lena.png", 'rb')
print(f)
# <_io.BufferedReader name='E:/DeepLearning/计算机视觉/cv101-master/dataset/lena.png'># head
file_sign = f.read(4)
print("head:", file_sign)
#换行符文件结束符
sign1 = f.read(4)
print("换行符和文件结束符:", sign1)
#head: b'\x89PNG'
#换行符和文件结束符: b'\r\n\x1a\n'length = struct.unpack('I', f.read(4))
print(length)
type = f.read(4)
print(type)
#(218103808,)
#b'IHDR'width = struct.unpack('I', f.read(4))
print("宽度:", width)
height = struct.unpack('I', f.read(4))
print("高度:", height)
# 感觉有点问题
#宽度: (131072,)
#高度: (131072,)
bit = struct.unpack('B',f.read(1))
print("位深:", bit)
color = struct.unpack('B',f.read(1))
print("颜色:", color)
#位深: (8,)
#颜色: (2,)a = struct.unpack('B',f.read(1))
b = struct.unpack('B',f.read(1))
c = struct.unpack('B',f.read(1))
print("a,b,c: ",a,b,c)
# a,b,c: (0,) (0,) (0,)BMP
-- 文件头:文件类型、文件大小、位图数据的起始位置
-- 位图信息头:图像尺寸、位深图、压缩方式
-- 调色板: 存储位深小于8的像素点信息
-- 位图数据:存储图像中每个像素点的颜色信息
位深的概念:
BMP格式中,每个像素点的颜色信息可以使用不同的位深度表示,如1位(单色)、4位(16色)、8位(256色)、16位、24位(真彩色)和32位等。其中,1位表示每个像素点只有黑和白两种颜色;4位表示每个像素点可以有16种颜色;8位(0~255)表示每个像素点可以有256种颜色;16位、24位和32位则表示每个像素点的颜色可以用不同的颜色通道(如红、绿、蓝)进行表示
基本规则如下:
- 文件头(14b):
- 表示符:BM(2b)
- 文件大小 (4b)
- 保留量 (4b)
- 偏移量 (4b)
- 位图头 (40b)
- 字节头大小 4b
- 宽 4b
- 高 4b
- 颜色通道数 2b
- 位深 2b
- 位图数据
- 从左到右,从上到下
- 所占空间为宽乘以高乘以位数除以8
- 补齐4字节
读取一张BMP图片全过程
# 以bmp为例
# 首先读取二进制文件
f = open("E:/DeepLearning/计算机视觉/cv101-master/dataset/lena.bmp", 'rb')
print(f)
#<_io.BufferedReader name='E:/DeepLearning/计算机视觉/cv101-master/dataset/lena.bmp'># 先读取头文件
# 2字节标识符
file_sign = f.read(2)
print("标识符:", file_sign)
#标识符: b'BM'# 4字节文件大小
file_size_byte = f.read(4)
# 需要解码
import struct
file_size = struct.unpack("i", file_size_byte)
print("文件大小:", file_size)
#文件大小: (786486,)# 4字节保留
f.read(4)
# 4字节数据偏移量
offset = struct.unpack("i", f.read(4))[0]
print("偏移量:", offset)
#偏移量: 54# 位图头读取
# 字节头解码
bm_header_size = struct.unpack('i', f.read(4))
print("字节头大小:", bm_header_size)
width = struct.unpack('i', f.read(4))
print("宽度:", width)
height = struct.unpack('i', f.read(4))
print("高度:", height)
channels = struct.unpack('<H', f.read(2))
print("通道:", channels)
color_bit = struct.unpack('<H', f.read(2)) # 2字节解码,低位字节在前
print("位深:", color_bit)
#字节头大小: (40,)
#宽度: (512,)
#高度: (512,)
#通道: (1,)
#位深: (24,)# 读取像素
f.seek(offset)
data = f.read()
# print(data[0], data[1], data[2])
print("总像素值数量为:", len(data))
print("像素点个数为:", len(data) // (color_bit[0] // 8))
print("长(512)*宽(512)= ", 512 * 512)
#总像素值数量为: 786432
#像素点个数为: 262144
#长(512)*宽(512)= 262144# 解码数据
# 一个像素占用的字节:24位深,一个像素三个数字表示rgb通道数值,用三个字节表示;8位深用1个字节表示(灰度图像);1位深用1个比特来存储(二值图像)
# 因此,计算方式为:int(位深/8)
pixel_bit = int(color_bit[0] / 8)
print("一个像素占用%d字节" % pixel_bit)
row_bit = pixel_bit * width[0]
print("一行占用%d字节" % row_bit)
#一个像素占用3字节
#一行占用1536字节# 建立一个空矩阵用于存储像素
import numpy as np
img = np.zeros((height[0], width[0], 3), dtype=np.uint8)
# 依次填充像素值
for i in range(height[0]):for j in range(width[0]):index = i * height[0] * 3 + j * 3img[i, j, 2] = data[index]img[i, j, 1] = data[index + 1]img[i, j, 0] = data[index + 2]
# 展示结果
import matplotlib.pyplot as plt
plt.imshow(img, origin='lower')
plt.show()
JPEG
-- joint photographic experts group
-- 有损压缩格式
-- DCT和量化实现
-- 具体步骤:
1. 预处理:rgb->YCbCr
2. DCT变换:
- 图像划分成8*8的patch
- 每个patch做DCT变换
3. 量化:
- 量化频域信号
- 舍弃高频信号
4. 编码:
- 熵编码技术对DCT信号编码
- 保留主分量,舍去噪声分量
- 常见的两种实现方式:
* baseline jpeg:常规方式,编码顺序为从左至右从上至下
* progressive jpeg:内容从模糊到清晰,将图像分为多个扫描,每个扫描中先编码大致轮廓,然后在后续扫描中添加细节
图像读取和保存的第三方库
PIL
安装:pip install pillow
读写使用
from PIL import Image
# 读取图像
img = Image.open('E:/DeepLearning/计算机视觉/cv101-master/dataset/lena.bmp')
plt.imshow(img)
plt.show()# 查看图像大小
print('image shape:', img.size)
# 查看图像格式
print('format:', img.format)
# 查看图像通道数
print('mode:', img.mode)# 获取像素值
# 通常是将其转换为其他格式来使用像素值,例如
import numpy as np
img_array = np.asarray(img)
print(img_array[:3, :3, 0])输出:

image shape: (512, 512)
format: BMP
mode: RGB
[[226 226 223]
[226 226 223]
[226 226 223]]
保存
# PIL提供了保存图像的方法,即
img.save('../../dataset/pil_lena.bmp')opencv
安装:pip install python-opencv
读取使用:默认读取bgr需转化为rgb
import cv2
img = cv2.imread('E:/dataset/lena.bmp')#路径中不能有中文!!!plt.imshow(img)
plt.show()#读取默认bgr
img = cv2.imread('E:/notebook/lena.bmp')
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)plt.imshow(img)
plt.show()
# 在读取图像时,imread还有个隐藏参数,可以直接将彩色图像转化为灰度图像
img = cv2.imread('E:/notebook/lena.bmp', 0)
img = cv2.cvtColor(img, cv2.COLOR_GRAY2RGB)plt.imshow(img)
plt.show()
图片保存
opencv提供函数保存图像,其格式为:
cv2.imwrite(filename, image, [params])
其中,参数分别是: 文件名, 图像数据,可选参数:文件格式
img = cv2.imread('E:/notebook/lena.bmp')
cv2.imwrite('E:/notebook/lena.png', img)
cv2.imwrite('E:/notebook/lena_90.jpg', img, [cv2.IMWRITE_JPEG_QUALITY, 90])#压缩质量90kb
cv2.imwrite('E:/notebook/lena_10.jpg', img, [cv2.IMWRITE_JPEG_QUALITY, 10])#压缩质量10kb质量10kb(第一张)和90kb对比


两者区别
cv2直接读取到图像的内容,pil读取图像的区块
cv2支持的图像格式更多,保存图像时能够控制图像质量,需要空间转换
pil适合简单的图像查看应用场景,opencv适合处理计算机视觉任务。
assignment
PNG2JPG
#方法一:使用PIL库
from PIL import Image
img = Image.open('test.jpg')
img.save('testpil.png')
#方法二:使用opencv库
from cv2 import imread, imwrite
image = imread("test.jpg", 1)
imwrite("testcv.png", image)不使用第三方库怎么做?
def png2jpg(filename, quality_value, save_folder):# 不依赖opencv或者pil库,从二进制文件直接解析png文件,并保存成jpeg格式。# 其中,jpeg格式的压缩参数由输入指定。# # 输入: # filename: str, png图像路径# quality_value: 压缩质量参数# save_folder: 保存的目标路径# # 图像保存文件名:# # 返回值:# 返回0
后面多使用opencv
图像算术和逻辑运算
数字图像在计算机中是以矩阵形式表示。对于矩阵的所有运算,都会在其以图像为核心的物理意义上进行体现。本质上,任何对图像的PS,都有矩阵的数学运算过程。
图像的算数运算是对图像进行加减运算,而图像的逻辑运算是对图像进行与、或、非、异或等逻辑运算。通过算术运算可以让图像来达到图像增强的效果;通过逻辑运算对图像进行分割、图像增强、图像识别、图像复原等操作。
算术运算
1. 加法与减法
图像的减法运算就是将图像中的每个像素,都减去一个相应的数值。 **对于小于0的部分常常截断为0**
其通常的应用有:
- 背景减除:从包含前景与背景的图像/视频中,提取出前景的内容
- 差距估计:例如去噪、重建等任务中,如何评价新产生的图像的生成质量,只需要估计其与原图的差距即可
图像的加法则常常用于图像融合或图像混合,将两张图像加权平均,可以实现图像的融合。
比如,红外图像与可见光图像,通过加权后,就可以实现简单的图像融合。
把一张图"变白":加上一个像素值;“变黑”:减去一个像素值
1:1加权融合:

opencv提供了更加方便的图像相加工具,即`cv2.addWweighted(img1, alpha, img2, beta, 0)`
其参数的意义为:
- img1,img2:图像1和图像2
- alpha,beta:图像1和2的系数
- 最后一个参数为亮度调节
因此,上述融合过程可以通过以下方式实现:
# numpy
fused_img = 0.5 * infrad_img + 0.5 * visual_img
fused_img = fused_img.astype(np.uint8)
# opencv
fused_img = cv2.addWeighted(infrad_img, 0.5, visual_img, 0.5, 0)
plt.imshow(fused_img)
plt.axis('off')
plt.show()
逻辑运算
颜色空间
除rgb颜色空间外,hsv也是重要的颜色空间表达。
* H:色调
* s:饱和度
* v:亮度
hsv更符合人类感知颜色的方式,更长用于设计领域。
opencv提供了rgb图像向hsv图像转换的接口
图像的逻辑运算在不同场景中,有不同的物理意义。
以增加饱和度为例,图像逻辑运算的过程:
二值化
二值化的图像往往是要对图像进行分割,通过阈值的区分,来实现物体分割
import cv2
import matplotlib.pyplot as pltimg = cv2.imread('../../dataset/greenscreen.png')
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
plt.imshow(img)
plt.show()gray = img[:, :, 1]
# ret, thresh = cv2.threshold(green_channle, 40, 130, cv2.THRESH_BINARY)
thresh1 = np.where(gray < 130, 255, 0) #像素值<130变为255,>130变为0
plt.imshow(thresh1, cmap='gray')
plt.show()img[thresh1 == 0] = 0
plt.imshow(img)
plt.show()


与
dst = bitwise_and(img1, img2[, dst[, mask]])
– img1表示第一张图像的像素矩阵
– img2表示第二张图像的像素矩阵
– dst表示输出的图像,必须和输入图像具有相同的大小和通道数
– mask表示可选操作掩码(8位单通道数组),用于指定要更改的输出数组的元素。
或
dst = bitwise_or(img1, img2[, dst[, mask]])
异或
dst = bitwise_xor(src1, src2[, dst[, mask]])
取反即非
鬼影图:cv2.bitwise_not(img)
import cv2
img = cv2.imread('../../dataset/lena.bmp')
neg = cv2.bitwise_not(img)
plt.imshow(neg)
plt.show()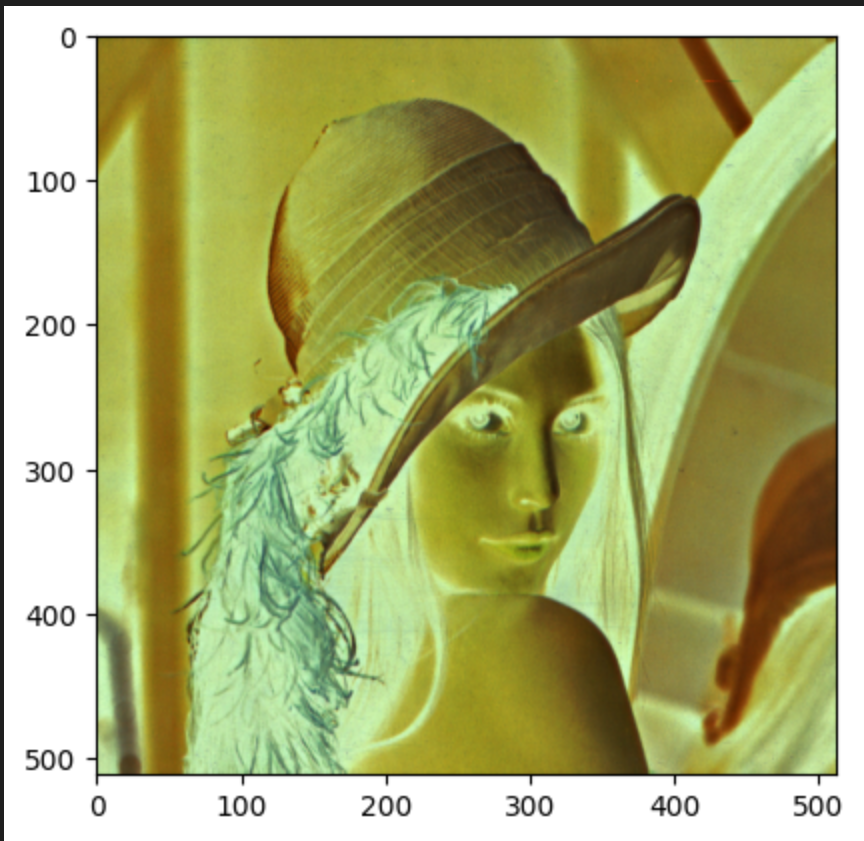
其他参考:
https://blog.csdn.net/qq_52131774/article/details/121490512
https://blog.csdn.net/Eastmount/article/details/122692101