《Pytorch深度学习实践》ch3-反向传播
------B站《刘二大人》
1.Introduction
- 在神经网络中,可以看到权重非常多,计算 loss 对 w 的偏导非常困难,于是引入了反向传播方法;
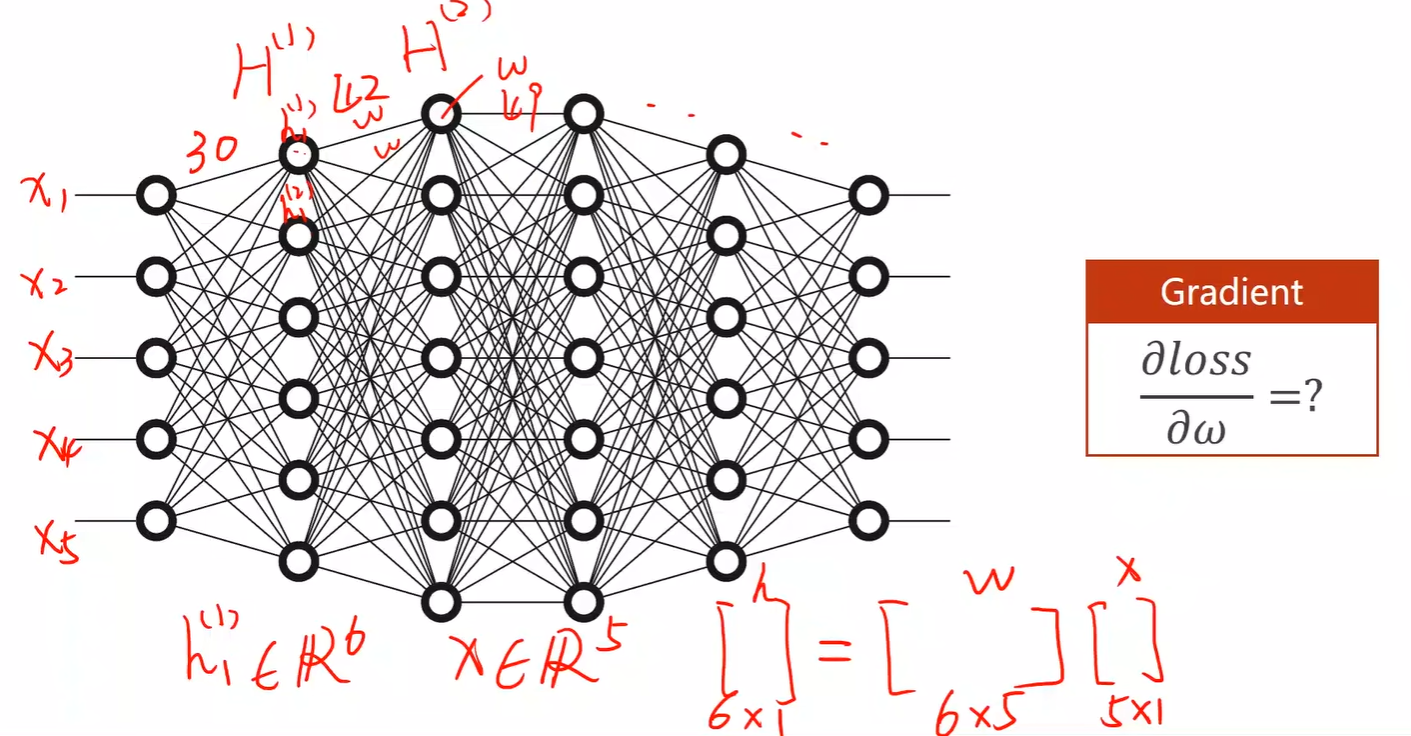
2.Backward
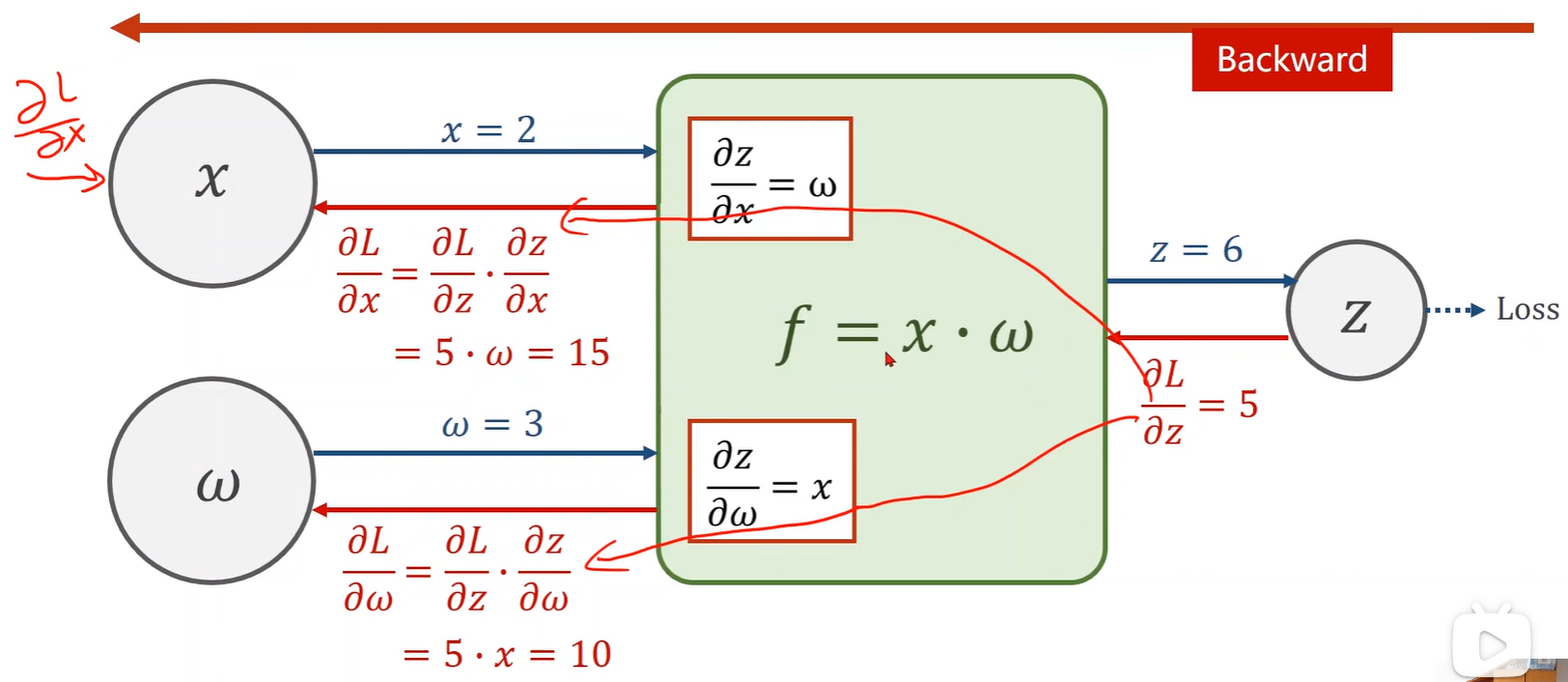
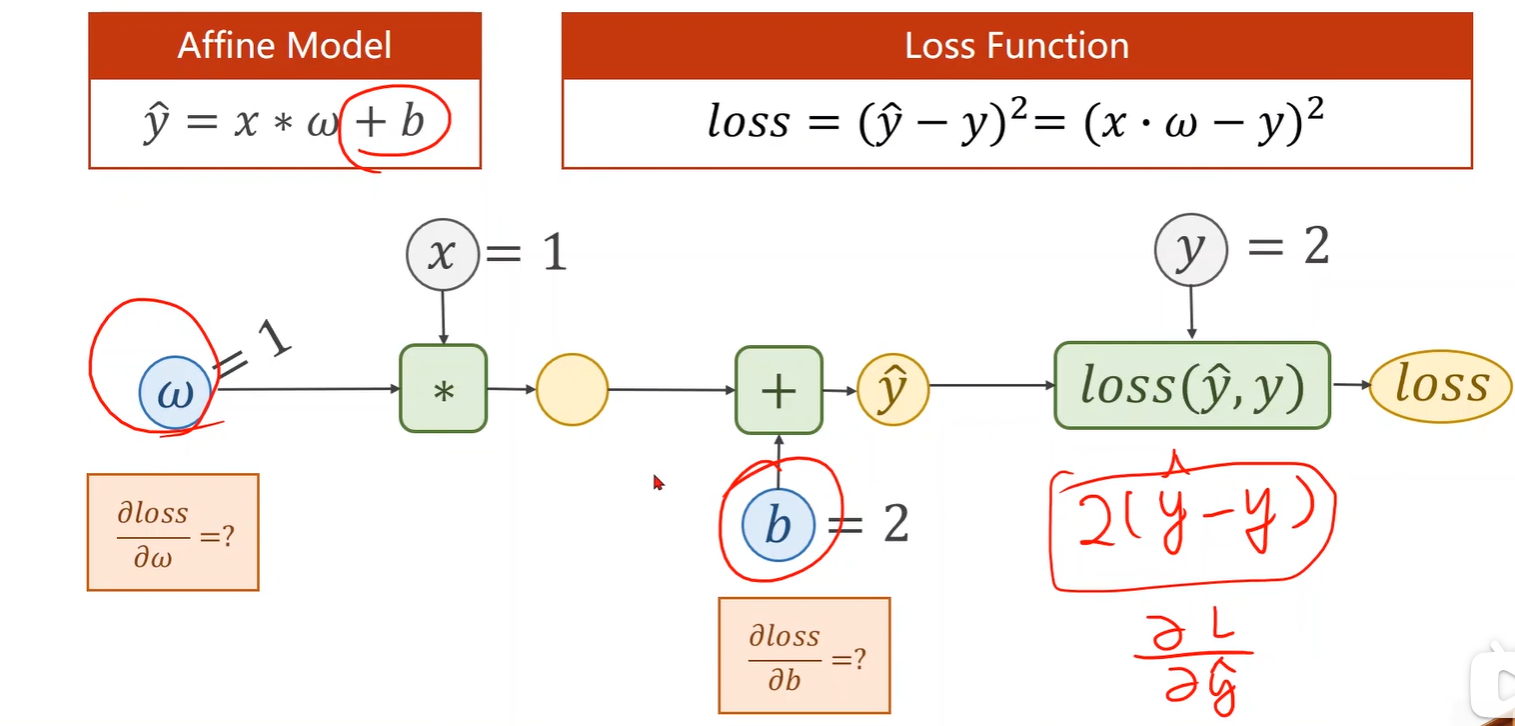
- 这里模型为 y = x * w,所以要计算的偏导数为 loss 对 w;
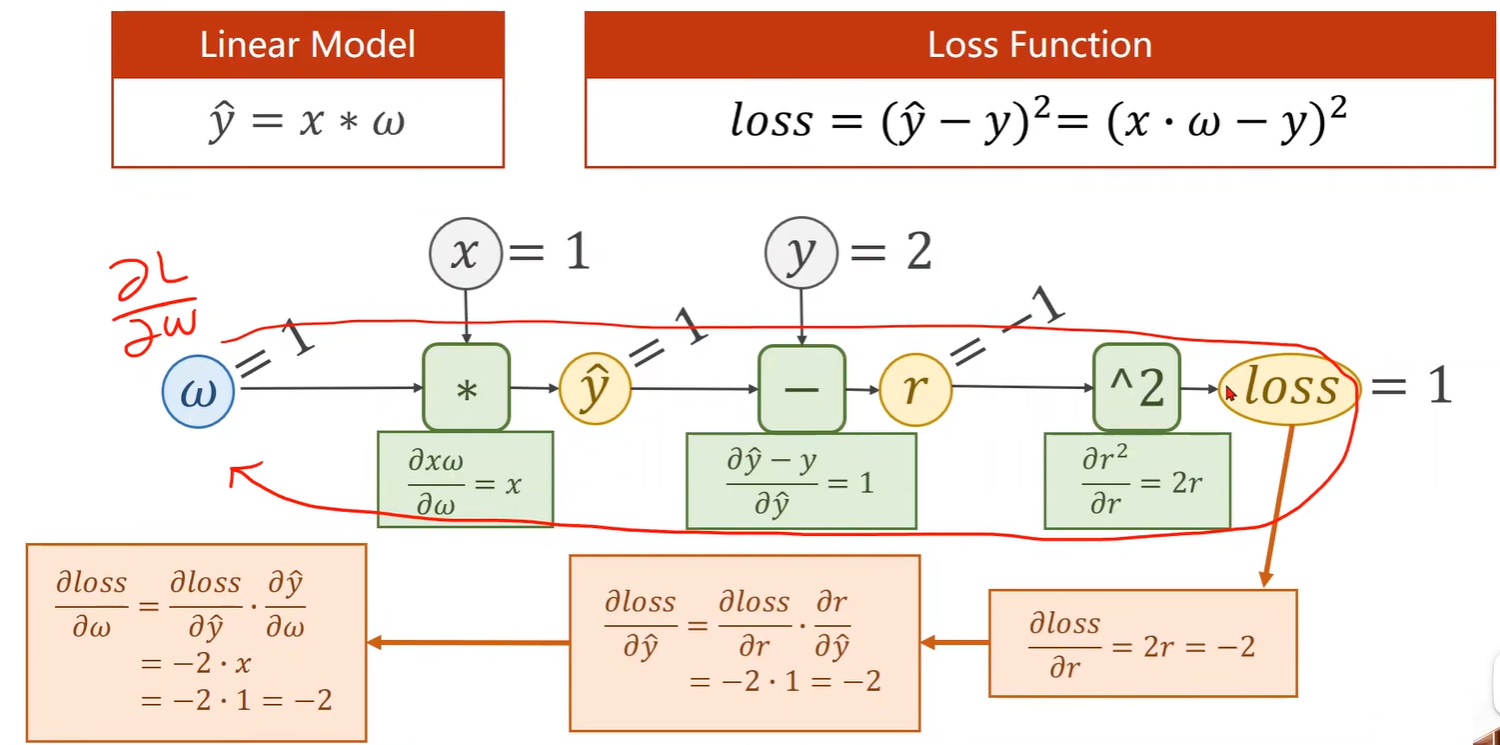
- 这里模型为 y = x * w + b,所以要计算的偏导数为 loss 对 w 和 loss 对 b;
- 模型有几个初始变量,就要求几个偏导;
3.Tensor
- Pytorch 里常用的一种数据类型为 Tensor,包含两种值;
- item():提取数值,不会保留 Tensor 结构,也不能用于更新权重。
data:直接修改 Tensor 数据(可以更新权重等),但不会影响梯度计算或反向传播。它允许修改 Tensor,而不会触发梯度计算。- 直接用原梯度才会触发梯度计算。

4.Implementation
import torch
import matplotlib.pyplot as plt# 数据集
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]# 权重(Tensor)
w = torch.Tensor([1.0])
w.requires_grad = True# 模型(自动变为 Tensor 间的运算)
def forward(x): return x * w# 损失函数
def loss(x, y):y_pred = forward(x)return (y_pred - y) ** 2# 训练轮数 epoch 为横坐标,损失 loss 为纵坐标
epoch_list = []
loss_list = []# 计算 loss - epoch
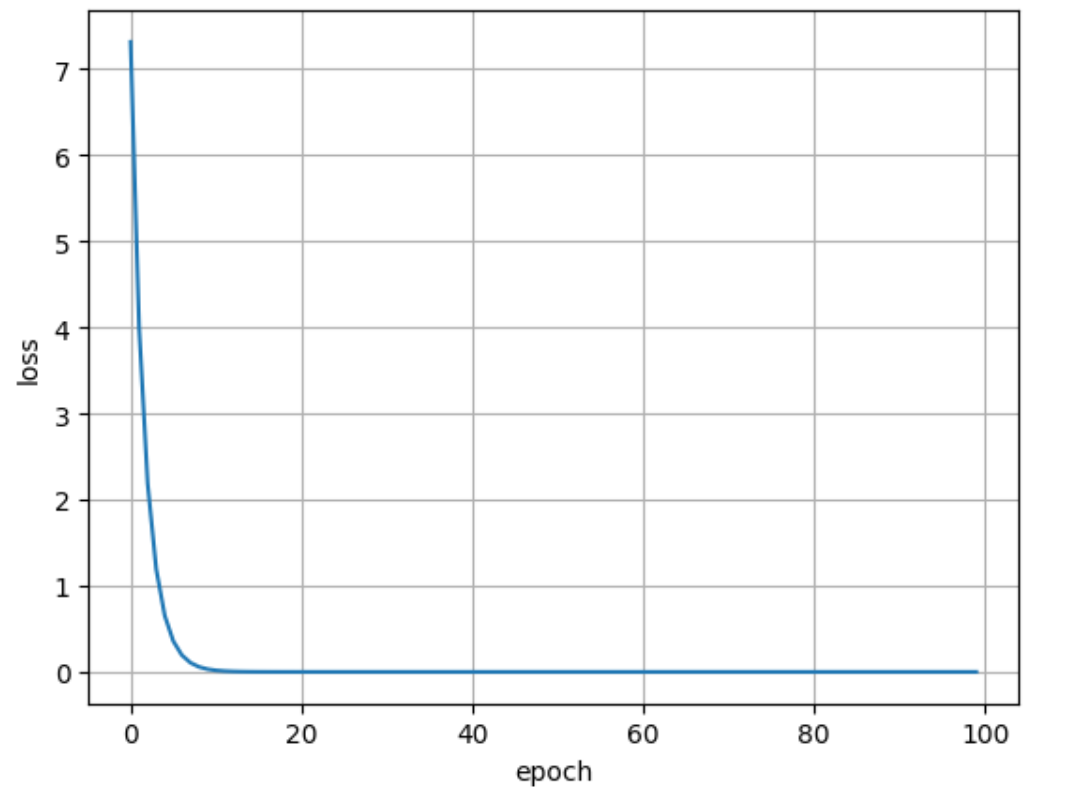
print('Predict (before training)', 4, forward(4).item())for epoch in range(100):for x, y in zip(x_data, y_data):loss_val = loss(x , y)loss_val.backward() # 反馈完计算图会被释放print('\tgrad:', x, y, w.grad.item())w.data -= 0.01 * w.grad.data # data 不会加入计算图w.grad.data.zero_() # 清除当前梯度,以防止累积epoch_list.append(epoch)loss_list.append(loss_val.item())print('progress:', epoch, loss_val.item())print('Predict (after training)', 4, forward(4).item())# 绘图
plt.plot(epoch_list, loss_list)
plt.xlabel('epoch')
plt.ylabel('loss')
plt.grid()
plt.show()- 绘图如下: