【数据库】关系数据库标准语言-SQL(金仓)下
4、数据查询
语法:
SELECT [ALL | DISTINCT] <目标列表达式> [,<目标列表达式>] …
FROM <表名或视图名>[, <表名或视图名> ] …
[ WHERE <条件表达式> ]
[ GROUP BY <列名1> [ HAVING <条件表达式> ] ]
[ ORDER BY <列名2> [ ASC | DESC ] ] ;
注:
➢ SELECT子句:指定要显示的属性列;
➢ FROM子句:指定查询对象(基本表或视图);
➢ WHERE子句:指定查询条件;
➢ GROUP BY子句:对查询结果按指定列的值分组,该属性列值
相等的元组为一个组。通常会在每组中使用集函数;
➢ HAVING短语:筛选出只有满足指定条件的组;
➢ ORDER BY子句:对查询结果按指定列值升序或降序排序。
如果你用金仓数据库,请设置好你自己的模式
金仓数据库提示找不到数据表,一般都是模式路径问题
SET search_path TO “S-T”;
SET search_path TO PUBLIC;
SET search_path TO “S-T”,PUBLIC;
注意:在金仓V8,设置搜索模式路径之后,这个路径(查找和插入)优先,如果需要删除数据、删除表格,最好加前缀
4.1单表查询–只涉及到一个表的查询
- SELECT+列名
[例1]查询全体学生的学号与姓名。
SELECT Sno,Sname
FROM “S-T”.Student; //等价于 πsno,Sname (Student)–投影,但是投影会去重复,SELECT不会去重复
[例2] 查询全体学生的详细记录。
SELECT * FROM “S-T”.Student;//表示将表中的列全部按序输出
😎实战
[步骤1] 设置默认搜索路径
SET search_path TO “S-T”;
<无论是查找还是插入,都会默认到"S-T"模式下>
[步骤2] 在Student表插入一个记录
INSERT INTO student (sno,sname,ssex,sage,sdept)
VALUES(‘231803001’,‘张三’,‘M’,18,‘网络与信息安全学院’);
<在设置了默认搜索路径后(要插入的表在默认搜索路径所包含的模式中),插入记录的时候就不用加前缀了>
[步骤3] 查看插入情况,执行单表查询例子
SELECT Sno,Sname From Student;
SELECT * From Student ;
- SELECT+目标列表达式
[例1] 查全体学生的姓名及其出生年份(假设这个表是2025年的)
SELECT Sname, 2025-Sage
FROM Student;
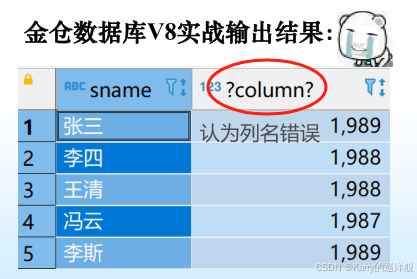
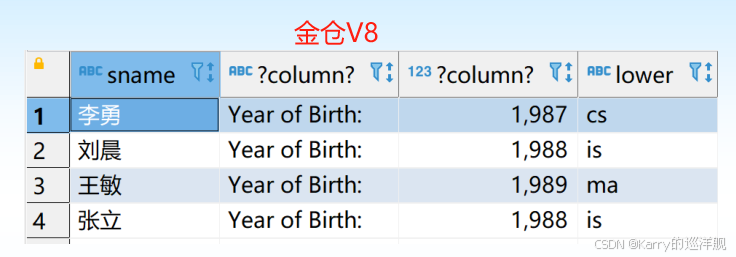
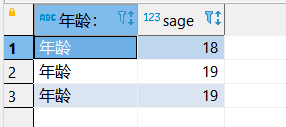
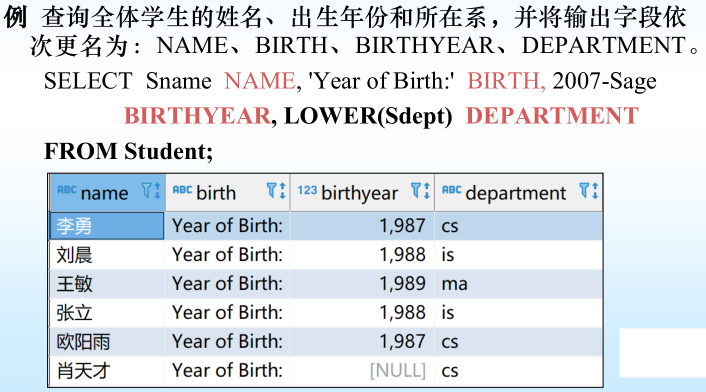
[例2]查询全体学生的姓名、出生年份和所在系,要求用小写字母表示所在系名。
SELECT Sname, ‘Year of Birth:’, 2007-Sage, LOWER(Sdept)
FROM Student ;
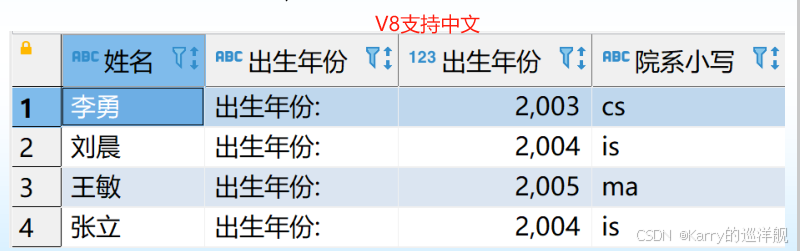
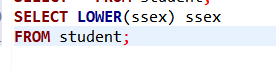
使用列别名改变查询结果的列标题
;
SELECT Sname 姓名, ‘出生年份:’ 出生年份, 2025-Sage 出生年份, LOWER(Sdept) 院系小写
FROM Student;
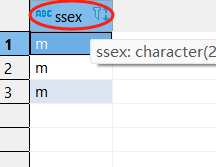
LOWER和UPPER的使用
原表中的数据并没有改变
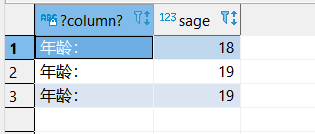
SELECT语句想显示出一整列解释语句,但原始表的内容并不变,只是执行本次SELECT才会显示。
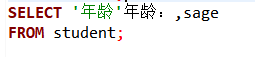
但是,如果这样,列名会出错:

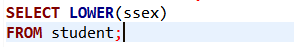

- 消除结果中取值重复的行--在SELECT子句中使用DISTINCT短语。
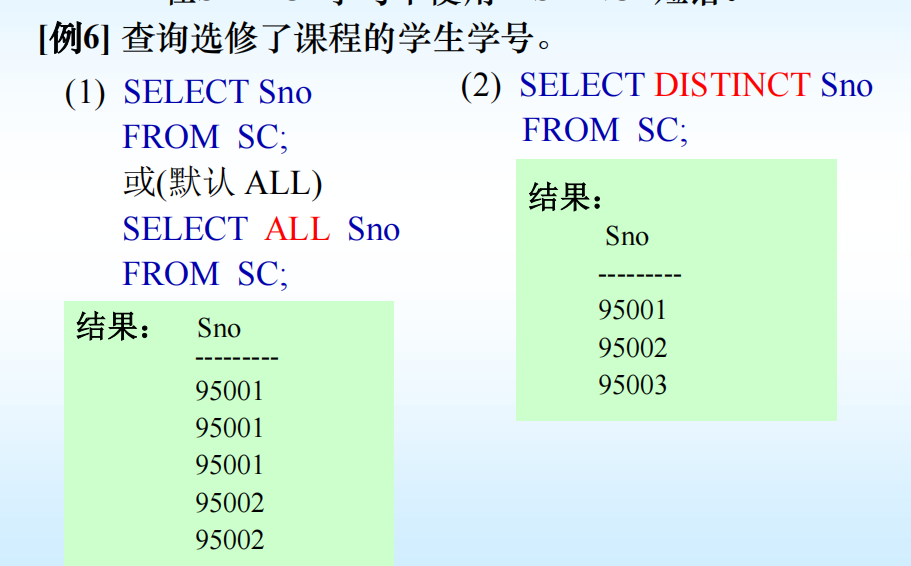
💥注意:DISTINCT短语的作用范围是所 - 有目标列。返
回的所有目标列中必须有一个属性不同。



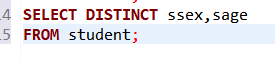

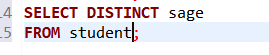


注:在关系代数投影(π)运算的定义中直接去掉了结果中的重复元组,在SQL中必须在SELECT子句中用DISTINCT明确指定才能去掉重复列。
4.2单表查询–使用WHERE子句
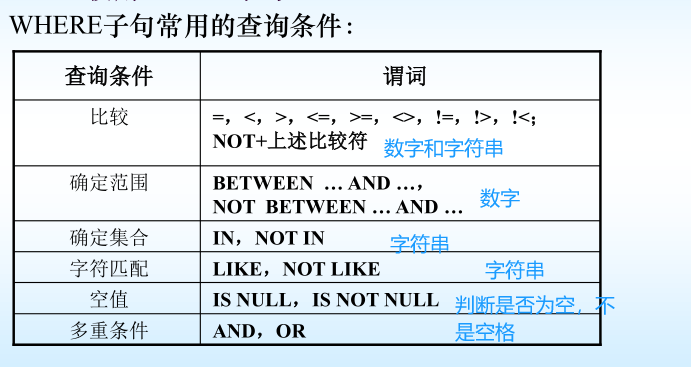
4.2.1比较

4.2.2确定范围(BETWEEN AND)

4.2.3确定集合(IN、NOT IN)

4.2.4字符串匹配


💥注意:没有模糊查询的要求就不要使用LIKE,效率会低很多


4.2.5涉及空值的查询


4.2.6多重条件的查询(将上面五种查询结合一下)
用逻辑运算符AND和OR来联结多个查询条件
➢ AND的优先级高于OR
➢ 可以用括号改变优先级


💜SQL代码优化:
/如果建立了WHERE子句中的属性列的索引/,[NOT]BETWEEN … AND … 和 [NOT] IN将不会利用索引提高查询效率,应改为多重条件查询,效率会提高,如上例。(比较的效率更高)
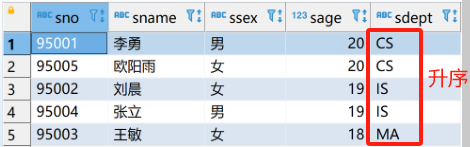
4.3单表查询–对查询结果排序输出
使用ORDER BY子句
● 可以按一个或多个属性列排序
➢ 升序:ASC;
➢ 降序:DESC;
➢ 缺省值为升序
● 当排序列含空值时
➢ ASC:排序列为空值的元组最后显示
➢ DESC:排序列为空值的元组最先显示
(将空值作为最大值来理解)


4.4单表查询–集函数
5类主要集函数:(默认为ALL)
(1) 计数
COUNT ([DISTINCT|ALL] *)
COUNT ([DISTINCT|ALL] <列名>)
(2) 计算总和
SUM ([DISTINCT|ALL] <列名>)
(3) 计算平均值
AVG ([DISTINCT|ALL] <列名>)
(4) 求最大值
MAX ([DISTINCT|ALL] <列名>)
(5) 求最小值
MIN ([DISTINCT|ALL] <列名>)




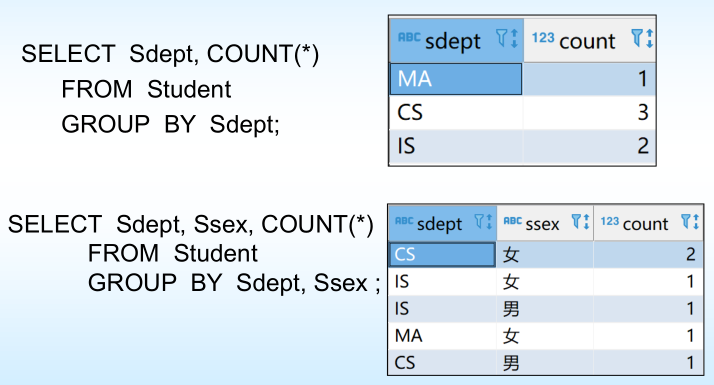
4.5单表查询–对查询结果分组输出
使用GROUP BY子句分组
分组方法:按指定的一列或多列值分组 ,值相等的为一组;
执行顺序:WHERE->GROUP BY->HAVING->SELECT
💥注意:使用GROUP BY子句后,SELECT子句的列名列表中只能出现分组属性和集函数。



4.6连接查询
连接查询--将两个(以上)表连接进行查询
同时涉及多个表的查询
连接查询的意义等价于关系代数中的θ连接、等值连接和自然连接。

由于连接采用的是笛卡尔积,当数据非常大时,效率很低。
💥提高查询效率的方法:
(1) 对表2按连接字段建立索引
(2) 对表1中的每个元组,依次根据其连接字段值查询表2的索引,从中找到满足条件的元组,找到后就将表1中的第一个元组与该元组拼接起来,形成结果表中一个元组。
4.6.1连接查询–自身连接
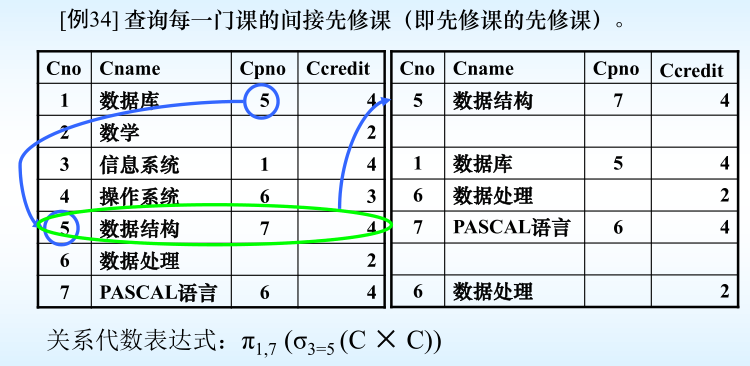

注:
(1) 一个表与其自己进行连接,称为表的自身连接
(2) 需要给表起别名以示区别
(3) 由于所有属性名都是同名属性,因此必须使用别名前缀
❓如何求一个课程的先修课的先修课的先修课❓

4.6.2连续查询–外连接
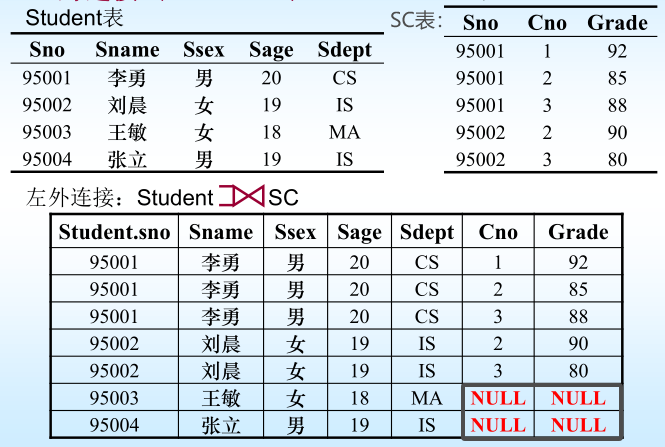

注:
(1)USING表示在两个关系的某些同名列上进行连接
(2)右外连接:RIGHT OUTER JOIN
(3)全外连接:FULL OUTER JOIN
(4)内连接:INNER JOIN
4.6.3复合条件连接
WHERE子句中含多个连接条件


4.7嵌套查询
4.7.1不相关子查询
一个SELECT-FROM-WHERE语句称为一个查询块;
将一个查询块嵌套在另一个查询块的WHERE子句或HAVING短语的条件中的查询称为嵌套查询。

注:
子查询的限制--不能使用ORDER BY子句,也没有意义;
层层嵌套方式反映了SQL语言的结构化;
有些嵌套查询可以用连接运算替代。

执行过程:
(1) 先执行子查询,得到结果集{IS}
(2) 再执行父查询WHERE Sdept IN {IS}
这种查询称为不相关子查询,即子查询的执行不依赖于父查询的条件。

注意:内查询是不相关子查询
该查询也可用连接来完成。
注:通常采用不相关子查询的效率要优于连接查询。

当能确切知道内层查询返回单值时,可用比较运算符(>,<,=,>=,<=,!=或< >)。
注意:是不相关子查询
注意:有些数据库管理系统要求子查询一定要跟在比较符之后!
4.7.2相关子查询

此查询的执行过程:
➢ (1)首先取外层查询中表的第一个元组,将Sno值传递给内层查询;
➢ (2)执行内层查询,根据结果再执行外层查询;
➢ (3)取外层表的下一个元组,重复这一过程,直至外层表全部检查完为止。
这种查询称为相关子查询,即子查询的条件与父查询当前值相关。
4.7.3带有ANY或ALL谓词的子查询
谓词语义:(1) ANY ( SOME ):某些值 (2) ALL:所有值
➢ > ANY
大于子查询结果中的某个值
➢ > ALL
大于子查询结果中的所有值
➢ < ANY
小于子查询结果中的某个值
➢ < ALL
小于子查询结果中的所有值
➢ >= ANY
大于等于子查询结果中的某个值
➢ >= ALL
大于等于子查询结果中的所有值
➢ <= ANY
小于等于子查询结果中的某个值
➢ <= ALL
小于等于子查询结果中的所有值
➢ = ANY
等于子查询结果中的某个值
➢ =ALL
等于子查询结果中的所有值(没有实际意义)
➢ !=(或<>)ANY
不等于子查询结果中的某个值
➢ !=(或<>)ALL
不等于子查询结果中的任何一个值

执行过程
- 执行此查询时,首先处理子查询,找出IS系中所有学生的年龄,构成一个集合(19,18)
- 处理父查询,找所有不是IS系且年龄小于19 或 18的学生
注意:是不相关子查询


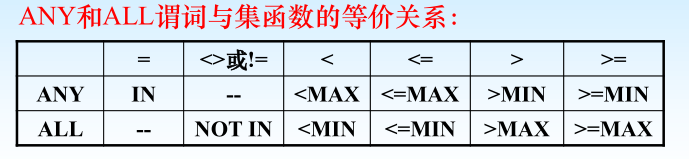
注:用集函数实现子查询通常比直接用ANY或ALL查询效率要高,因为前者通常能够减少比较次数。
4.7.4带有EXISTS谓词的子查询
▪ EXISTS谓词的意义:
▪ 是存在量词在SQL中的应用;
▪ 带有EXISTS谓词的子查询不返回任何数据,只产生逻辑真值“true”或逻辑假值“false”;
➢若内层查询结果非空,则返回真值
➢若内层查询结果为空,则返回假值
▪ 由EXISTS引出的子查询,其目标列表达式通常都用* ,因为带EXISTS的子查询只返回真值或假值,给出列名无实际意义。


注: (1) 所有带EXISTS或NOT EXISTS谓词的子查询能够被其他形式的子查询等价替换
(2)所有带IN谓词、比较运算符、ANY和ALL谓词的子查询都能用带EXISTS谓词的子查询等价替换。
4.7.5用EXISTS/NOT EXISTS实现全称量词(难点)


💦上述详细逻辑实现:
假设有张三和李四两个学生,一共有ABC三门课,张三选了ABC,李四选了AC。
首先,从第一重查询里选出张三,从第二重查询里选择A,在第三重查询里判断,第三重的WHERE返回true,进入第二重,经过NOT EXISTS,第二重的WHERE是false,接着,在第二重查询里面选择B,在第三重查询里判断,即判断张三是否选择了B,返回true,进入第二重,经过NOT EXISTS,第二重的WHERE是false,接着,在第二重查询里面选择C,在第三重查询里判断,返回true,进入第二重,经过NOT EXISTS,第二重的WHERE是false。现在,第二重的遍历结束且WHERE语句全是false,故第二重返回false,经过第一重的NOT EXISTS ,第一重的WHERE语句是true,是true就立马输出,输出张三的信息。
对于李四,从第一重查询里选出李四,从第二重查询里选择A,在第三重查询里判断,第三重的WHERE返回true,进入第二重,经过NOT EXISTS,第二重的WHERE是false,接着,在第二重查询里面选择B,在第三重查询里判断,即判断张三是否选择了B,返回false,进入第二重,经过NOT EXISTS,第二重的EXISTS变成true,此时返回到第一重,经过NOT EXISTS变为false,不输出李四,结束!!!
也就是说:当遇到true时会立即返回到上一重,到遇到false时,会接着在该重遍历直到遇到true立马返回或者遍历结束全是false,返回false进行下一重的遍历。
当遇到true,本重后面的遍历就会结束掉,直接返回到上一重。



若95002选了ABC
张三:ABC
李四:AC
李五:D
上面的程序中,只要某个学生遍历到和95002一样的课就会结束(不输出),只有李五输出,即实现了输出和与95002同学的课程没有交集的的同学。

若95002选了ABC
张三:ABC
李四:AC
李五:D
上面的程序,实现了只要有一门与95002相同,就会输出该学生。

若95002选了ABC
张三:ABC
李四:AC
李五:D
上面的程序,输出李四和王五,实现了只要不选95002中的一门(只要不是ABC)就能输出。
4.8集合查询
💜 集合查询--将两个SELECT-FROM-WHERE查询块用集合操作语句联结起来。
💜集合操作命令:
并操作(UNION)
交操作(INTERSECT)
差操作(EXCEPT)
💜语句形式:
<查询块>
操作
<查询块> ;
注:参加操作的各结果表的列数必须相同;对应项的数据类型也必须相同



4.9查询注意事项
一、别名的使用
(1) 别名用于对输出属性列的重命名
(2) 别名用于自身连接查询和对同一表的相关子查询中,用于区别对同一表的不同引用

(3) 对不相关子查询可以不使用别名

二、DISTINCT的使用
DISTINCT用于区分相同的记录,将多条相同的记录作为一条处理。

三、集函数的使用
集函数只能用于 SELECT子句和 HAVING短语之中,而绝对不能出现在 WHERE子句中。


四、GROUP BY的使用
使用了分组的查询语句,其SELECT子句中只能出现分组属性和集函数,而不能有在GROUP BY没有出现的属性。


五、ORDER BY子句在复合查询中的应用
ORDER BY子句用于对查询结果进行排序后再输出,故只用于最外层的查询,而子查询中不应该出现ORDER BY子句。


六、输出多个表的属性的查询
查询的输出只能取自最外层查询所使用的表,对于子查询中的属性是不能作为最终的输出的。如果输出的属性涉及多个表,则最外层查询只能使用这些表的连接查询。

5.数据更新
插入数据
修改数据
删除数据
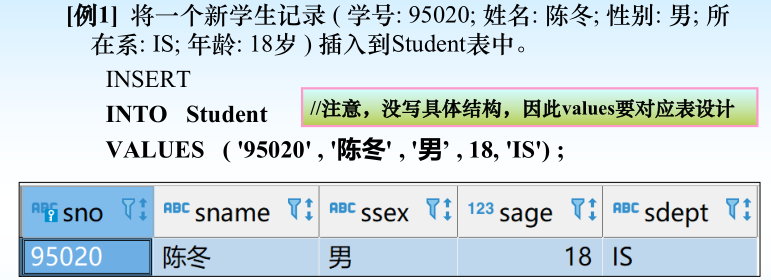
一、插入数据
(1) 插入单个元组--新元组插入指定表中。
语句格式:
INSERT
INTO <表名> [(<属性列1>[,<属性列2 >…)]
VALUES (<常量1> [,<常量2>] … ) ;
INTO子句
➢ 指定要插入数据的表名及属性列
➢ 属性列的顺序可与表定义中的顺序不一致
➢ 没有指定属性列:表示要插入的是一条完整的元组,且属性列属
性与表定义中的顺序一致
➢ 指定部分属性列:插入的元组在其余属性列上取空值
VALUES子句
➢ 提供的值的个数和值的类型必须与INTO子句匹配

(2) 插入子查询结果
语句格式:
INSERT
INTO <表名> [(<属性列1> [,<属性列2>… )]
子查询;
注:
INTO子句(与插入单条元组类似)
➢ 指定要插入数据的表名及属性列
➢ 属性列的顺序可与表定义中的顺序不一致
➢ 没有指定属性列:表示要插入的是一条完整的元组
➢ 指定部分属性列:插入的元组在其余属性列上取空值
子查询
➢ SELECT子句目标列属性的个数和类型必须与INTO子句匹配。

二、修改数据(用的比较少)
语句格式:
UPDATE <表名>
SET <列名>=<表达式>[, <列名>=<表达式>]…
[WHERE <条件>];
功能:
修改指定表中满足WHERE子句条件的元组。
注:
➢ SET子句--指定修改方式,要修改的列和修改后取值
➢ WHERE子句
➢ 指定要修改的元组
➢ 缺省表示要修改表中的所有元组



三、删除数据(较常用)
语句格式:
DELETE
FROM <表名>
[WHERE <条件>] ;
功能:
删除指定表中满足WHERE子句条件的元组
注:
WHERE子句
指定要删除的元组
缺省表示要修改表中的所有元组





在执行插入、修改、删除语句时会检查是否会破坏表上已定义的完整性规则。如果破坏,系统会提示语句无效。
在建立表时,可以设置参照完整性:
⚫ 不允许修改/删除
⚫ 级联修改/删除
定义SC的外码Sno: //选课表记录,受制于学生表
FOREIGN KEY (Sno) REFERENCES Student(Sno)
ON DELETE CASCADE ON UPDATE CASCADE;
6.空值
空值的产生:插入时不提供值、设为空值
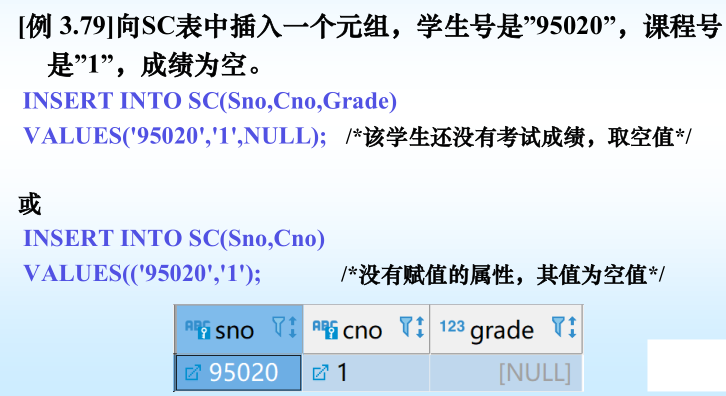

判断一个属性的值是否为空值,用IS NULL或IS NOT NULL来表示。

7.总结

8.视图
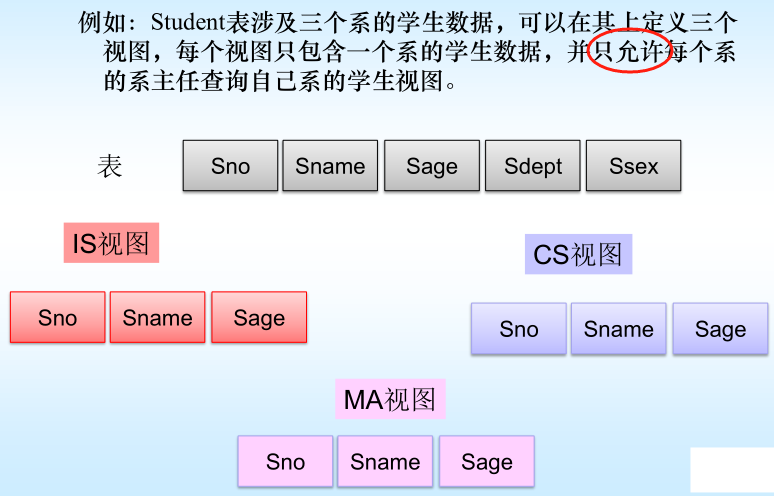
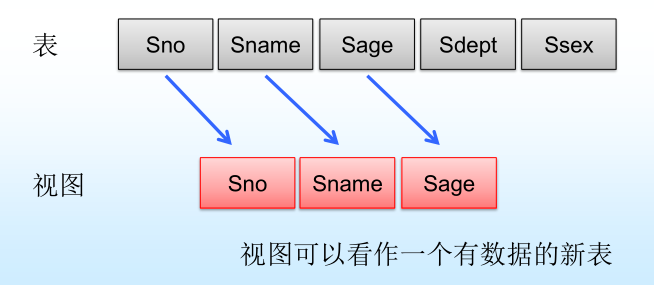
8.1什么是视图(View)?
😍视图是从一个或几个基本表(或视图)导出的表,它与基本表不同,是一个虚表。
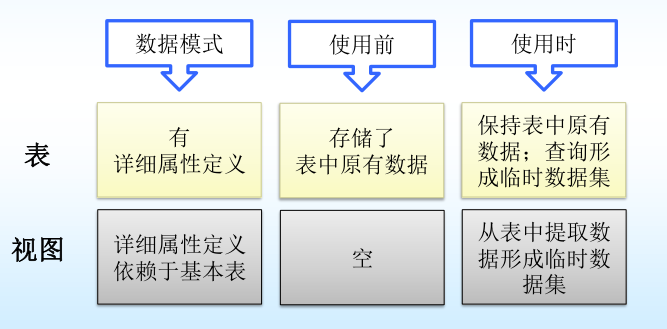
基表中的数据发生变化,从视图中查询出的数据也随之改变。
视图一经定义,就可以和基本表一样被查询和删除,并且可以在视图之上再定义新的视图。
视图的更新(增加、删除、修改)操作会受到一定的限制。
视图对应三级模式体系结构中的外模式。

8.2视图定义
😴视图定义语法:
CREATE VIEW <视图名> [(<列名> [,<列名>]…)]
AS <子查询>
[WITH CHECK OPTION];
😴CREATE VIEW 子句中的列名可以省略,此时视图的属性由子查询中SELECT目标列中的诸字段组成。
😴子查询中的属性列不允许定义别名,不允许含有ORDER BY子句和DISTINCT短语。
😴执行CREATE VIEW语句时只是把视图的定义存入数据字典,并不执行其中的SELECT语句。在对视图进行查询时,按视图的定义从基本表中将数据查出(执行视图定义中的SELECT语句)。
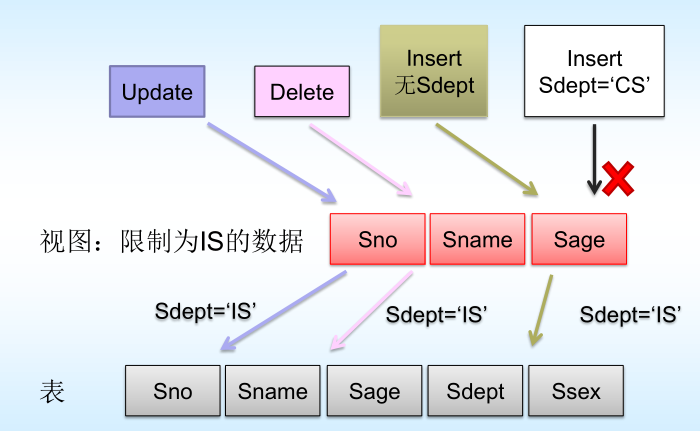
😴WITH CHECK OPTION表示对视图进行更新操作的数据必须满足视图定义的谓词条件(子查询的条件表达式)。


针对此视图,当进行以下操作时,
➢ 修改操作:DBMS自动加上Sdept= 'IS’的条件
➢ 删除操作:DBMS自动加上Sdept= ‘IS’的条件
➢ 插入操作:DBMS自动检查Sdept属性值是否为’IS’





8.3视图的删除
语法:
DROP VIEW <视图名> [CASCADE] ;
注:
➢ 该语句从数据字典中删除指定的视图定义;
➢ 如果该视图导出了其他视图,则使用CASCADE级联删除,或者先显式删除导出的视图,再删除该视图;

8.4视图的查询
此视图查询的方法:
(1) 视图实体化法:
通过视图定义建立视图结构下的临时表并对临时表进行查询,在查询结束后删除临时表。
(2) 视图消解法:
根据视图定义将对视图的查询转换为对基本表的查询


8.5更新视图
和基本表一样,视图定义之后也可以进行插入、删除和修改操作。
(1) 用户角度:更新视图与更新基本表相同;
(2) 实现视图更新的方法
➢ 视图实体化法(View Materialization)
➢ 视图消解法(View Resolution)
(3) 指定WITH CHECK OPTION子句后,在更新视图时会进行检查,防止用户通过视图对不属于视图范围内的基本表数据进行更新。



一些视图是不可更新的,因为对这些视图的更新不能唯一地有意义地转换成对相应基本表的更新(对两类方法均如此)。
💜从理论上讲,对其更新能够唯一转换为对应基本表更新的视图是可更新的。

8.6视图的作用–安全保护