Spring AI Image Model、TTS,RAG
文章目录
- Spring AI Alibaba
- 聊天模型
- 图像模型
- Image Model API接口及相关类
- 实现生成图像
- 语音模型
- Text-to-Speech API概述
- 实现文本转语音
- 实现RAG
- 向量化
- RAG
- RAG工作流程概述
- 实现基本 RAG 流程
Spring AI Alibaba
Spring AI Alibaba实现了与阿里云通义模型的完整适配,如果需要对接国内一些大模型来生成图像、语音,SpringAi官网目前支持模型有限,这时Spring AI Alibaba可能更适用。
使用前请先申请api_key:
- 访问阿里云百炼页面并登录账号 https://www.aliyun.com/product/bailian
- 申请api_key
官方文档:https://java2ai.com/docs/1.0.0-M6.1/get-started/?spm=4347728f.13ae80de.0.0.6fe5175cWxPTJZ
注意:因为 Spring AI Alibaba 基于 Spring Boot 3.x 开发,因此本地 JDK 版本要求为 17 及以上。
聊天模型
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>org.example</groupId><artifactId>deepseek-apringai</artifactId><version>1.0-SNAPSHOT</version><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>3.2.5</version><relativePath/> <!-- lookup parent from repository --></parent><properties><maven.compiler.source>17</maven.compiler.source><maven.compiler.target>17</maven.compiler.target><spring-ai.version>1.0.0-M5</spring-ai.version></properties><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><dependency><groupId>com.alibaba.cloud.ai</groupId><artifactId>spring-ai-alibaba-starter</artifactId><version>1.0.0-M5.1</version></dependency></dependencies><repositories><repository><id>spring-milestones</id><name>Spring Milestones</name><url>https://repo.spring.io/milestone</url><snapshots><enabled>false</enabled></snapshots></repository></repositories>
</project>
@RestController
public class DeepSeekController {private static final String DEFAULT_PROMPT = "你是一个博学的智能聊天助手,请根据用户提问回答!";@Autowiredprivate ChatClient dashScopeChatClient;public DeepSeekController(ChatClient.Builder chatClientBuilder) {this.dashScopeChatClient = chatClientBuilder.defaultSystem(DEFAULT_PROMPT)// 实现 Chat Memory 的 Advisor// 在使用 Chat Memory 时,需要指定对话 ID,以便 Spring AI 处理上下文。.defaultAdvisors(new MessageChatMemoryAdvisor(new InMemoryChatMemory()))// 实现 Logger 的 Advisor.defaultAdvisors(new SimpleLoggerAdvisor())// 设置 ChatClient 中 ChatModel 的 Options 参数.defaultOptions(DashScopeChatOptions.builder().withTopP(0.7).build()).build();}@GetMapping("/simple/chat")public String simpleChat(String query) {return dashScopeChatClient.prompt(query).call().content();}
}
图像模型
-
在Spring AI框架中,Image Model API旨在为与专注于图像生成的各种AI模型进行交互提供一个简单且可移植的接口,使开发者能够以最小的代码改动切换不同的图像相关模型。这一设计符合Spring模块化和互换性的理念,确保开发者可以快速调整其应用程序以适应不同的图像处理相关的AI能力。
-
此外,通过支持像ImagePrompt这样的辅助类来进行输入封装以及使用ImageResponse来处理输出,图像模型API统一了与致力于图像生成的AI模型之间的通信。它管理请求准备和响应解析的复杂性,为图像生成功能提供直接而简化的API交互。
-
Image Model API建立在Spring AI通用模型API之上,提供了特定于图像的抽象和实现。
Image Model API接口及相关类
ImageModel(图像模型)
这里展示的是ImageModel接口定义:
@FunctionalInterface
public interface ImageModel extends Model<ImagePrompt, ImageResponse> {ImageResponse call(ImagePrompt request);
}
ImagePrompt(图像提示)
ImagePrompt是一个封装了ImageMessage对象列表及可选模型请求选项的ModelRequest。下面显示的是ImagePrompt类的一个简化版本,省略了构造函数和其他工具方法:
public class ImagePrompt implements ModelRequest<List<ImageMessage>> {private final List<ImageMessage> messages;private ImageOptions imageModelOptions;@Overridepublic List<ImageMessage> getInstructions() {...}@Overridepublic ImageOptions getOptions() {...}
}
ImageMessage(图像消息)
ImageMessage类封装了用于影响生成图像的文本及其权重。对于支持权重的模型,它们可以是正数或负数。
public class ImageMessage {private String text; private Float weight;public String getText() {...}public Float getWeight() {...}
}
ImageOptions(图像选项)
表示可以传递给图像生成模型的选项。ImageOptions接口扩展了ModelOptions接口,并用于定义可以传递给AI模型的一些可移植选项。
public interface ImageOptions extends ModelOptions {Integer getN();String getModel();Integer getWidth();Integer getHeight();String getResponseFormat(); // openai - url or base64 : stability ai byte[] or base64
}
ImageResponse(图像响应)
持有AI模型的输出,每个ImageGeneration实例包含来自单一提示的可能多个输出结果之一。
public class ImageResponse implements ModelResponse<ImageGeneration> {private final ImageResponseMetadata imageResponseMetadata;private final List<ImageGeneration> imageGenerations;@Overridepublic ImageGeneration getResult() {// get the first result}@Overridepublic List<ImageGeneration> getResults() {...}@Overridepublic ImageResponseMetadata getMetadata() {...}
}
ImageGeneration(图像生成)
最终,ImageGeneration类扩展自ModelResult,代表输出响应及有关此结果的元数据。
public class ImageGeneration implements ModelResult<Image> {private ImageGenerationMetadata imageGenerationMetadata;private Image image;@Overridepublic Image getOutput() {...}@Overridepublic ImageGenerationMetadata getMetadata() {...}
}。
实现生成图像
@Autowired
private DashScopeImageModel imageModel;@GetMapping(value = "/getImage")public void getImage(@RequestParam(value = "msg",defaultValue = "生成一条龙")String msg, HttpServletResponse res) {ImageResponse response = imageModel.call(new ImagePrompt(msg,DashScopeImageOptions.builder().withModel(DashScopeImageApi.DEFAULT_IMAGE_MODEL).withN(1)//要生成的图像数。必须介于 1 和 10 之间。.withHeight(1024)//生成的图像的高宽度。.withWidth(1024).build()));//获取生成图像地址String imageUrl = response.getResult().getOutput().getUrl();try {//使用输出流在浏览器输出URL url = URI.create(imageUrl).toURL();InputStream in = url.openStream();res.setHeader("Content-Type", MediaType.IMAGE_PNG_VALUE);res.getOutputStream().write(in.readAllBytes());res.getOutputStream().flush();}catch (Exception e) {}
}
语音模型
Text-to-Speech API概述
在Spring AI框架中,Text-to-Speech API提供了一个基于OpenAI的TTS(文本转语音)模型的语音端点,
使用户能够:
-
朗读写好的博客文章。
-
生成多种语言的语音音频。
-
使用流媒体实现实时音频输出。
这一功能强大的API让用户可以轻松地将文字内容转化为语音内容,不仅支持多语言转换,还能满足实时语音输出的需求,极大地提升了内容的可访问性和用户的体验感。
实现文本转语音
-
本示例基于spring ai alibaba开源框架
-
SpeechSynthesisModel 类是Spring AI Alibaba框架中用于表示和管理文本转语音模型的核心组件之一。
-
DashScopeSpeechSynthesisOptions 类通常用于配置文本转语音(TTS)服务的选项,这个类允许开发者指定一系列参数(比如:语速、音调、音量等)来定制化语音合成的结果,从而满足不同的应用场景需求。
@Autowired
private DashScopeSpeechSynthesisModel speechSynthesisModel;private static final String TEXT = "床前明月光, 疑是地上霜。 举头望明月, 低头思故乡。";
private static final String FILE_PATH = "src/main/resources/tts";@GetMapping("/tts")
public void tts() throws IOException {// 使用构建器模式创建 DashScopeSpeechSynthesisOptions 实例并设置参数DashScopeSpeechSynthesisOptions options = DashScopeSpeechSynthesisOptions.builder().withSpeed(1.0) // 设置语速.withPitch(0.9) // 设置音调.withVolume(60) // 设置音量.build();SpeechSynthesisResponse response = speechSynthesisModel.call(new SpeechSynthesisPrompt(TEXT,options));File file = new File(FILE_PATH + "/output.mp3");try (FileOutputStream fos = new FileOutputStream(file)) {ByteBuffer byteBuffer = response.getResult().getOutput().getAudio();fos.write(byteBuffer.array());} catch (IOException e) {throw new IOException(e.getMessage());}
}
实现RAG
向量化
-
向量数据库(Vector Database)是一种以数学向量的形式存储数据集合的数据库,通过一个数字列表来表示维度空间中的一个位置。在这里,向量数据库的功能是可以基于相似性搜索进行识别,而不是精准匹配。比如说在使用一个商城系统的向量数据库进行查询的时候,用户输入“北京”,其可能返回的结果会是 “中国、北京、华北、首都、奥运会” 等信息;输入“沈阳”,其返回结果可能会是“东北、辽宁、雪花、重工业”等信息。当然,返回的信息取决于向量数据库中存在的数据。用户可以通过参数的设置来限定返回的情况,进而适配不同的需求。
-
嵌入模型(Embedding Model)和向量数据库(Vector Database/Vector Store)是一对亲密无间的合作伙伴,也是 AI 技术栈中紧密关联的两大核心组件,两者的协同作用构成了现代语义搜索、推荐系统和 RAG(Retrieval Augmented Generation,检索增强生成)等应用的技术基础。
RAG
RAG,全称 Retrieval-Augmented Generation ,中文叫做检索增强生成。RAG是一种结合了检索系统和生成模型的新型技术框架,其主要目的有:
- 利用外部知识库
- 帮助大模型生成更加准确、有依据、最新的回答
通过使用RAG,解决了传统LLM存在的两个主要问题:
- 知识局限性:LLM的知识被固定在训练数据中,无法知道最新消息。
- 幻觉现象:LLM有时候会编造出并不存在的答案。
通过检索外部知识,RAG让模型突破了知识局限性,也让LLM(大语言模型)的幻觉现象得到解决。
RAG工作流程概述
第一,用户输入问题
用户在输入窗口输入自己的问题,这一数据被接收,并作为后续处理的查询入口
例如:用户提问
“我的智能手表出现蓝牙连接问题,怎么办?”
第二,问题向量化
根据用户初始输入的问题,调用Embedding模型,将问题转换为高维向量,以便于后续的想来那个相似度检索。
文本:"我的智能手表出现蓝牙连接问题,怎么办?"
→ 向量:[0.123, 0.582, ..., 0.001]
第三,向量数据库检索
系统会连接到一个向量数据库(如FAISS、Milvus、Pinecone、Weaviate)。然后用刚才生成的问题向量,检索知识库中与之最相似的文档片段。
当检索的时候,常见的检索参数包括:
- Tok-K :检索最相关的K条记录
- 相似度阈值:控制检索到内容的相关性
最后输出的结果往往是K条知识片段
1. "蓝牙连接问题通常可以通过重启设备和重新配对解决。"
2. "如果手表固件版本较旧,请更新到最新版本以兼容蓝牙。"
3. "某些环境下,如电磁干扰,也会导致连接失败。"
第四,构建上下文
这一阶段需要组织提示词(Prompt),让LLM更好地理解背景信息。
这一部分包括:
-
系统提示词(System Prompt)
提前告诉LLM需要遵循的行为规范,比如
你是一个专业的智能手表客服助理。请基于提供的背景资料,准确回答用户的问题。如果资料中没有明确答案,请如实告诉用户而不是编造。系统提示词可以有效地设定模型角色、控制回答风格、防止幻觉
-
构造最终输入(Final Prompt)
一般会结合以上内容,按照如下格式进行组织
【背景资料】 1. 蓝牙连接问题通常可以通过重启设备和重新配对解决。 2. 如果手表固件版本较旧,请更新到最新版本以兼容蓝牙。 3. 某些环境下,如电磁干扰,也会导致连接失败。【用户问题】 我的智能手表出现蓝牙连接问题,怎么办?【回答要求】 请结合以上资料,用简洁明了的方式回答用户的问题。如果答案无法直接从资料中找到,请礼貌告知用户。
第五,调用LLM
将构造好的Prompt提交给LLM(比如Deepseek、Qwen、GPT-4o、Claude等)
- 模型读取检索到的内容和问题
- 组织自然、连贯、准确的回答
生成结果示例:
“您好! 根据我们的资料,您可以尝试重启智能手表并重新进行蓝牙配对。如果问题仍未解决,请检查手表固件是否为最新版本。如处于高电磁干扰环境,也可能影响连接质量,建议更换使用环境。”
第六,返回最终回答给用户
最终系统将生成的回答返回前端,展示给用户。
总结:
在RAG工作时,其运行流程大致为:
- 用户输入问题
- 问题向量化
- 向量数据库检索
- 构建上下文(含系统提示词)
- 携带检索内容,调用大模型进行回答
- 返回最终答案给用户
实现基本 RAG 流程
创建配置类
@Configuration
public class RagConfig {@BeanChatClient chatClient(ChatClient.Builder builder) {return builder.defaultSystem("你将作为一名行天下公司的客服,对于用户的使用需求作出解答").build();}@BeanVectorStore vectorStore(EmbeddingModel embeddingModel) {SimpleVectorStore simpleVectorStore = SimpleVectorStore.builder(embeddingModel).build();//1 提取文本内容String filePath="file.txt"; //resources目录下TextReader textReader = new TextReader(filePath);textReader.getCustomMetadata().put("filePath",filePath);List<Document> documents = textReader.get();//2 文本切分段落TokenTextSplitter splitter =new TokenTextSplitter(1200,350, 5,100, true);splitter.apply(documents);//3 添加simpleVectorStore.add(documents);return simpleVectorStore;}}
file.txt
公司主营养猪业务,公司总部在山西省临汾市
- 通过这个配置类,完成以下内容:
1、配置 ChatClient 作为 Bean,其中设置系统默认角色为Java开发语言专家, 负责处理用户查询并生成回答向量存储配置。
2、初始化 SimpleVectorStore,加载Java开发语言说明文档,将文档转换为向量形式存储。
Controller
@Autowired
private ChatClient dashScopeChatClient;@Autowired
private VectorStore vectorStore;@GetMapping(value = "/chat", produces = "text/plain; charset=UTF-8")
public String generation(String userInput) {// 发起聊天请求并处理响应return dashScopeChatClient.prompt().user(userInput).advisors(new QuestionAnswerAdvisor(vectorStore)).call().content();
}
- 通过添加 QuestionAnswerAdvisor 并提供对应的向量存储,可以将之前放入的文档作为参考资料,并生成增强回答。
测试结果
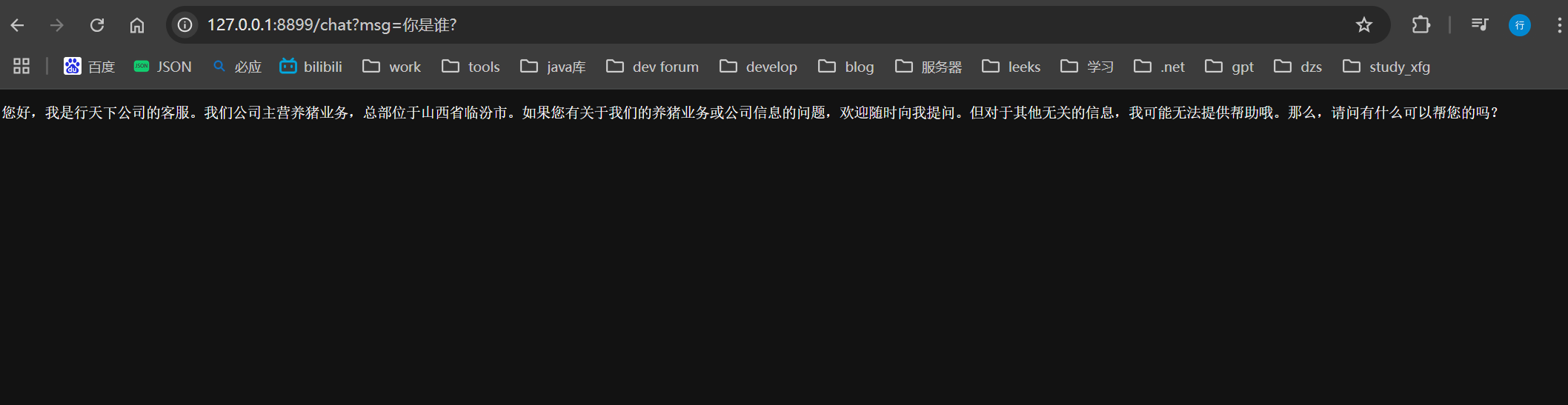
通过RAG可以构建更专业的知识库来让AI模型回答更具体化,支持的文档可以是word、pdf等其他格式,向量数据也可以持久化存储在向量数据库中。