OramaCore 是您 AI 项目、答案引擎、副驾驶和搜索所需的 AI 运行时。它包括一个成熟的全文搜索引擎、矢量数据库、LLM界面和更多实用程序
一、软件介绍
文末提供程序和源码下载

OramaCore 是您的项目、答案引擎、副驾驶和搜索所需的 AI 运行时。
它包括一个成熟的全文搜索引擎、矢量数据库、LLM具有行动计划和推理功能的接口、用于根据数据编写和运行您自己的自定义代理的 JavaScript 运行时,以及更多实用程序。
二、Getting Started 开始
绝对简单的入门方法是按照您可以在此存储库中找到的 docker-compose.yml 文件进行作。
You can either clone the entire repo or setup oramasearch/oramacore:latest as image in your docker-compose.yml file under the oramacore service.
您可以克隆整个存储库,也可以在 oramacore 该服务下的 docker-compose.yml 文件中设置为 oramasearch/oramacore:latest 映像。
Then compile your configuration file and run it:
然后编译您的配置文件并运行它:
docker compose up
This will create the following architecture, allowing you to perform high-performance RAG with little to zero configuration.
这将创建以下架构,允许您以很少甚至零的配置执行高性能 RAG。
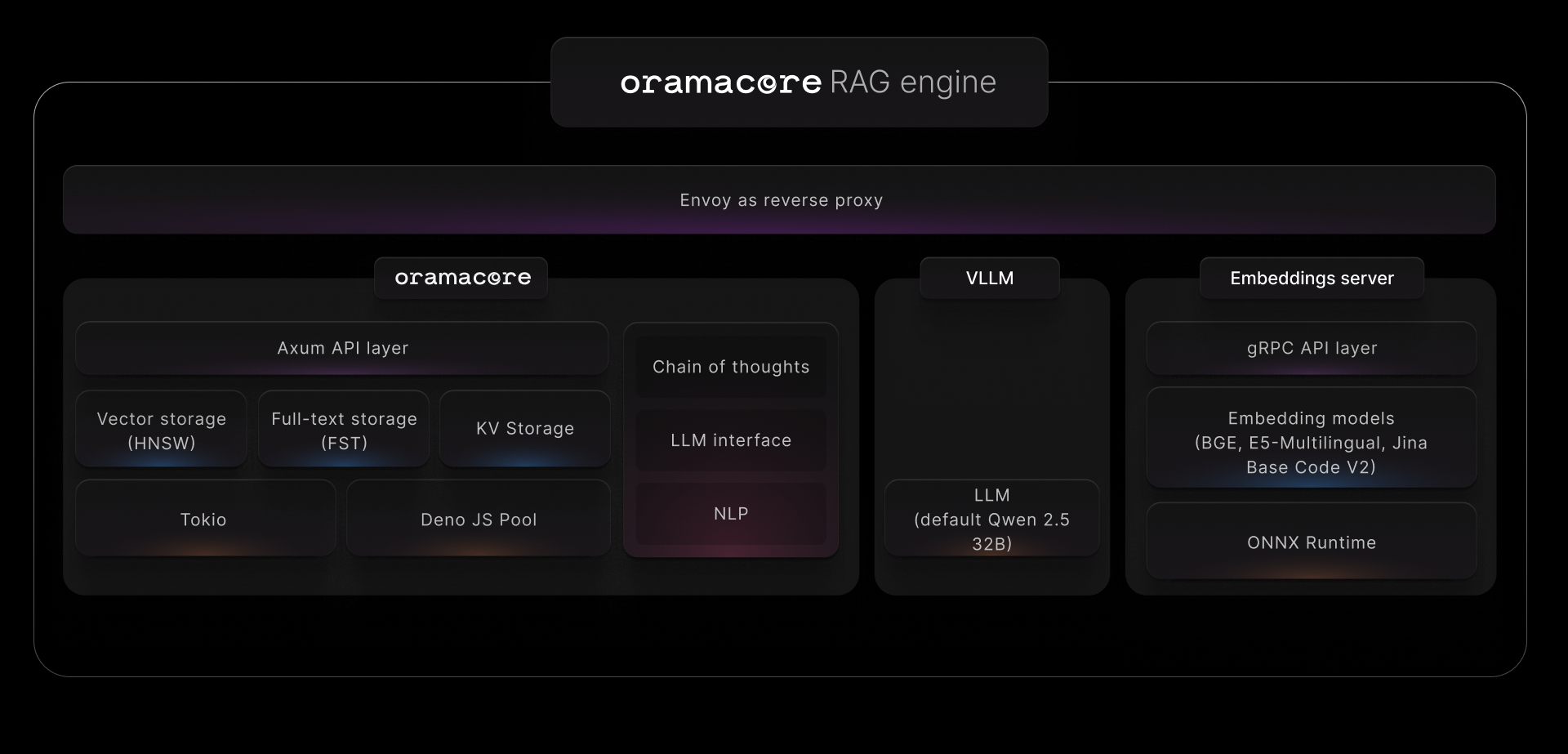
An NVIDIA GPU is highly recommended for running the application. For production usage, we recommend using minimum one NVIDIA A100. Optimal configuration would include four NVIDIA H100.
强烈建议使用 NVIDIA GPU 来运行应用程序。对于生产用途,我们建议至少使用一个 NVIDIA A100。最佳配置将包括四个 NVIDIA H100 。
三、Available Dockerfiles 可用的 Dockerfile
Depending on your machine, you may want to use different Docker images.
根据您的计算机,您可能希望使用不同的 Docker 映像。
| Application 应用 | CPU/GPU CPU/图形处理器 | Docker image Docker 镜像 |
|---|---|---|
| OramaCore OramaCore 公司 | X86_64 | oramasearch/oramacore |
| OramaCore OramaCore 公司 | ARM64 (Mac M series for example) ARM64(例如 Mac M 系列) | oramasearch/oramacore-arm64 |
| AI Server AI 服务器 | Any CPU architecture, no CUDA access 任何 CPU 架构,无需 CUDA 访问 | oramasearch/oramacore-ai-server |
| AI Server AI 服务器 | Any CPU architecture, CUDA available 任何 CPU 架构,CUDA 可用 | coming soon |
Using the JavaScript SDK 使用 JavaScript SDK
You can install the official JavaScript SDK with npm:
你可以使用 npm 安装官方的 JavaScript SDK:
npm i @orama/core
Then, you can start by creating a collection (a database index) with all of the data you want to perform AI search & experiences on:
然后,你可以开始创建一个集合(数据库索引),其中包含你想要执行AI搜索和体验的所有数据:
import { OramaCoreManager } from "@orama/core";const orama = new OramaCoreManager({url: "http://localhost:8080",masterAPIKey: "<master-api-key>", // The master API key set in your config file
});const newCollection = await orama.createCollection({id: "products",writeAPIKey: "my-write-api-key", // A custom API key to perform write operations on your collectionreadAPIKey: "my-read-api-key", // A custom API key to perform read operations on your collection
});
Then, insert some data:
然后,插入一些数据:
import { CollectionManager } from "@orama/core";const collection = new CollectionManager({url: "http://localhost:8080",collectionID: "<COLLECTION_ID>",writeAPIKey: "<write_api_key>",
});// You can insert a single document
await collection.insert({title: "My first document",content: "This is the content of my first document.",
});// Or you can insert multiple documents by passing an array of objects
await collection.insert([{title: "My first document",content: "This is the content of my first document.",},{title: "My second document",content: "This is the content of my second document.",},
]);
OramaCore will automatically generate highly optimized embeddings for you and will store them inside its built-in vector database.
OramaCore 将为您自动生成高度优化的嵌入,并将其存储在其内置的向量数据库中。
Now you can perform vector, hybrid, full-text search, or let OramaCore decide which one is best for your specific query:
现在,您可以执行矢量、混合、全文搜索,或者让 OramaCore 决定哪一个最适合您的特定查询:
import { CollectionManager } from "@orama/core";const collection = new CollectionManager({url: "http://localhost:8080",collectionID: "<COLLECTION_ID>",readAPIKey: "<read_api_key>",
});const results = await collection.search({term: "The quick brown fox",mode: "auto", // can be "fulltext", "vector", "hybrid", or "auto"
});
You can also perform Answer Sessions as you'd do on Perplexity or SearchGPT, but on your own data!
您还可以像在 Perplexity 或 SearchGPT 上一样执行 Answer Sessions,但使用您自己的数据!
import { CollectionManager } from "@orama/core";const collection = new CollectionManager({url: "http://localhost:8080",collectionID: "<COLLECTION_ID>",readAPIKey: "<read_api_key>",
});const answerSession = collection.createAnswerSession({initialMessages: [{ role: "user",content: "How do I install OramaCore?"},{role: "assistant",content: "You can install OramaCore by pulling the oramasearch/oramacore:latest Docker image",},],events: {onStateChange(state) {console.log("State changed:", state);},},
});
软件下载
夸克网盘分享
本文信息来源于GitHub作者地址:GitHub - oramasearch/oramacore: OramaCore is the AI runtime you need for your AI projects, answer engines, copilots, and search. It includes a fully-fledged full-text search engine, vector database, LLM interface, and many more utilities.