GATED DELTA NETWORKS : IMPROVING MAMBA 2 WITH DELTA RULE
TL;DR
- 2024 年 Nvidia + MIT 提出的线性Transformer 方法 Gated DeltaNet,融合了自适应内存控制的门控机制(gating)和用于精确内存修改的delta更新规则(delta update rule),在多个基准测试中始终超越了现有的模型,如 Mamba2 和 DeltaNet。
Paper name
GATED DELTA NETWORKS : IMPROVING MAMBA 2 WITH DELTA RULE
Paper Reading Note
Paper URL:
- https://arxiv.org/pdf/2412.06464
Code URL:
- https://github.com/NVlabs/GatedDeltaNet
Introduction
背景
- 线性Transformer作为标准Transformer的高效替代方案已受到关注,但其在检索任务和长上下文任务中的表现一直有限
- 为解决这些局限性,近期研究探索了两种不同的机制:用于自适应内存控制的门控机制(gating)和用于精确内存修改的delta更新规则(delta update rule)。本文发现这两种机制是互补的——门控机制能够实现快速内存清除,而 delta 规则则有助于有针对性的更新。
本文方案
- 提出了 Gated DeltaNet(gated delta rule),并开发了一种针对现代硬件优化的并行训练算法
- 提出的架构 Gated DeltaNet 在多个基准测试中始终超越了现有的模型,如 Mamba2 和 DeltaNet,涵盖语言建模、常识推理、上下文检索、长度外推和长上下文理解等任务。
- 进一步通过开发混合架构来提升性能,将 Gated DeltaNet 层与滑动窗口注意力机制或 Mamba2 层相结合,在提高训练效率的同时实现了更优的任务表现
Methods
回顾
- linear attention 的一般形式
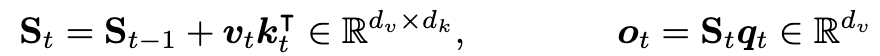
- mamba2 增加了一个 data-dependent decay 项
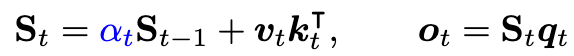
- delta net rule:动态擦除与当前输入 kt 想关联的 vold,然后写入一个新值 vnew,后者是当前输入值和旧值的线性组合
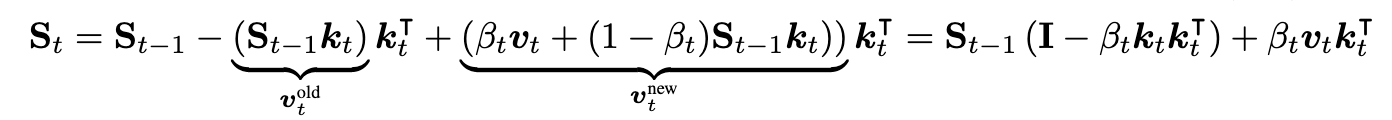
Gated Delta Net
- 本文提出的 Gated Delta Net
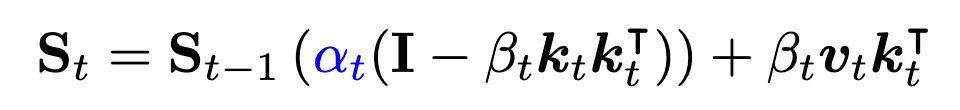
数据依赖的门控项 α t ∈ ( 0 , 1 ) \alpha_{t} \in (0, 1) αt∈(0,1) 控制状态的衰减
该公式统一了门控机制和 Delta 规则的优点,使模型能够通过选择性遗忘实现动态内存管理,在过滤无关信息方面具有潜在优势:
- 门控项 α t \alpha_{t} αt 实现自适应内存管理;
- Delta 更新结构有助于有效的键值关联学习
单针在 haystack 中(S-NIAH)验证
在 RULER(Hsieh 等,2024)提出的 Single Needle-In-A-Haystack(S-NIAH) 基准套件上进行案例分析。在这个任务中,一个键值对作为“针”隐藏在上下文(即 haystack)中,模型需要在给定键的情况下回忆出对应的值。

衰减机制损害记忆保持能力
在最简单的 S-NIAH-1 设置中,使用重复的合成上下文,模型仅需记忆少量信息,测试的是长期记忆保留能力。
- DeltaNet 在所有序列长度下都接近完美表现;
- Mamba2 在超过 2K 长度时性能显著下降,因为其衰减历史信息过快;
- Gated DeltaNet 的性能下降较轻,得益于 Delta 规则的记忆保留能力。
门控机制有助于过滤无关信息
在 S-NIAH-2/3 使用真实世界文章作为上下文的任务中,模型需要存储所有可能相关的信息,测试的是高效的内存管理能力。
- 固定状态大小下,缺乏清除机制会导致“内存冲突”——信息叠加、难以区分;
- DeltaNet 在长序列中性能大幅下降,因其内存清除能力不足;
- Mamba2 和 Gated DeltaNet 则通过门控机制过滤无关信息,维持了更好的性能。
Delta 规则增强记忆能力
在 S-NIAH-3 中,值从数字变为 UUID,测试的是复杂模式的记忆能力。
- Mamba2 性能迅速下降;
- Gated DeltaNet 表现更优,验证了 Delta 规则确实具备更强的记忆能力。
Gated DeltaNet 与混合模型设计
基本的 Gated DeltaNet 架构沿用 Llama 的宏观架构,堆叠 token mixer 层和 SwiGLU MLP 层,但将自注意力替换为基于 Gated Delta 规则 的 token mixing 方法。
-
查询、键和值 {q,k,v} 通过线性投影、短卷积和 SiLU 激活生成,且 q,k 经过 L2 归一化以提升训练稳定性。参数 α,β 仅通过线性投影生成。输出经过归一化和门控处理后再应用输出投影
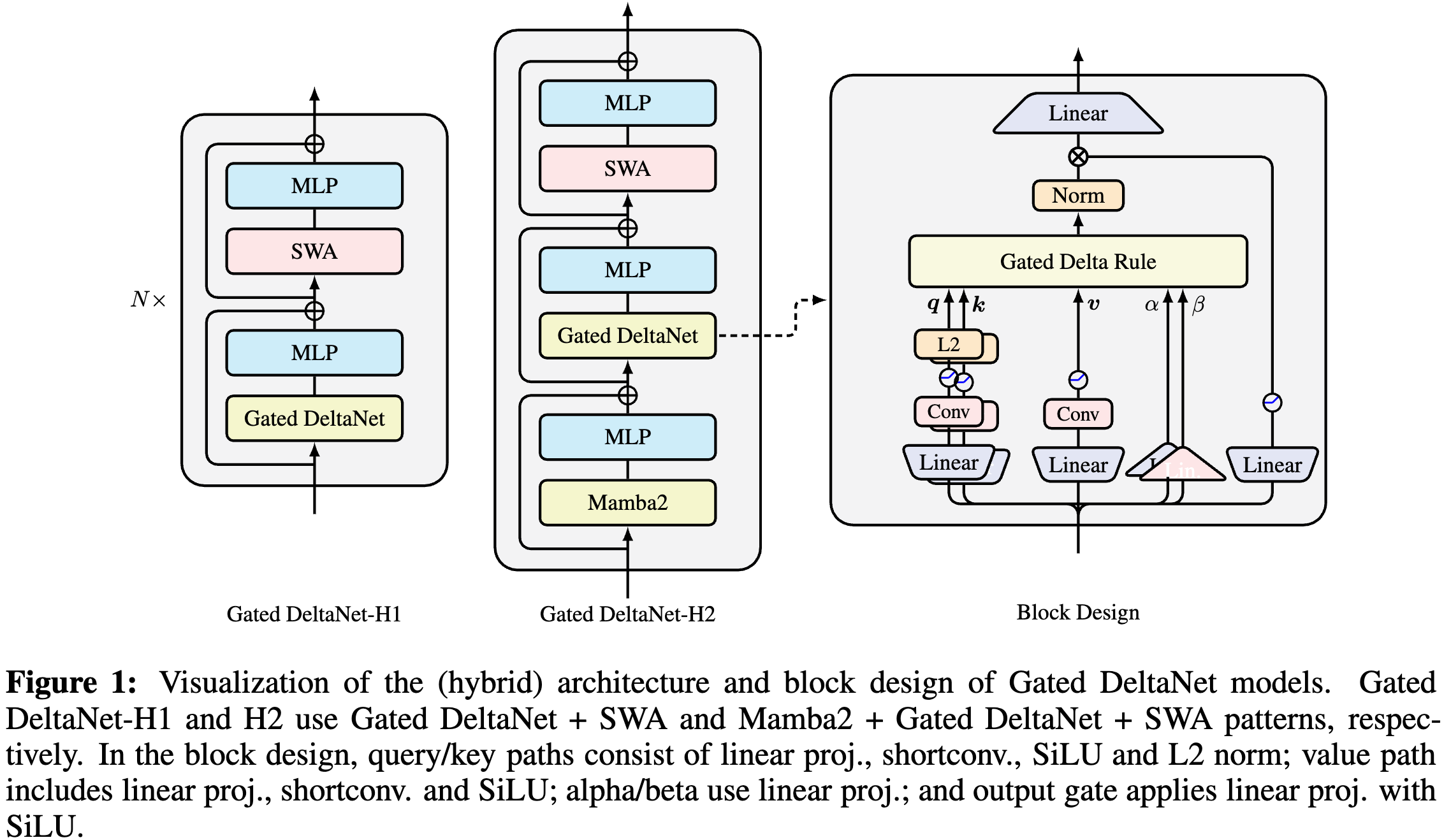
-
线性 Transformer 在建模局部变化和比较方面存在局限,固定的状态大小也使得检索任务困难。
- 将线性循环层与滑动窗口注意力(Sliding Window Attention, SWA)结合,构建了 GatedDeltaNet-H1
- 进一步堆叠 Mamba2、GatedDeltaNet 和 SWA,构建了 GatedDeltaNet-H2
Experiments
实验配置
- 为了保证公平比较,所有模型均在相同条件下训练,参数量均为 13 亿(1.3B),训练数据为从 FineWeb-Edu 数据集 (Penedo 等,2024)中采样的 1000 亿(100B)个 token
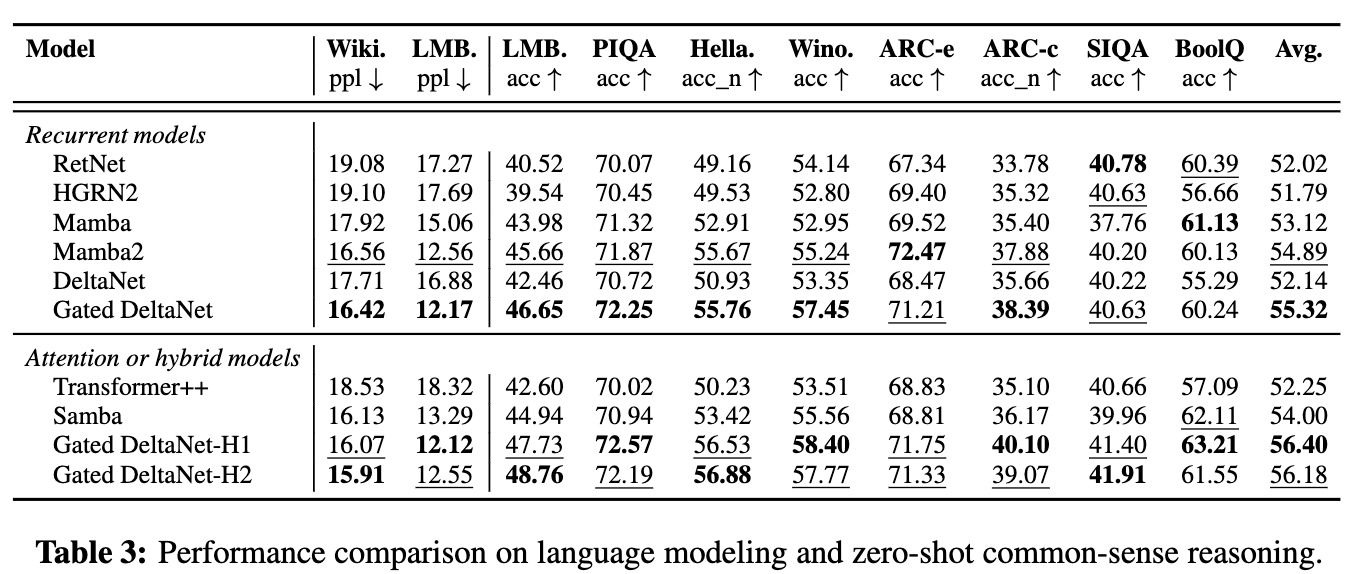
常识推理
- Gated DeltaNet 在两个参数规模上均持续优于其他线性模型
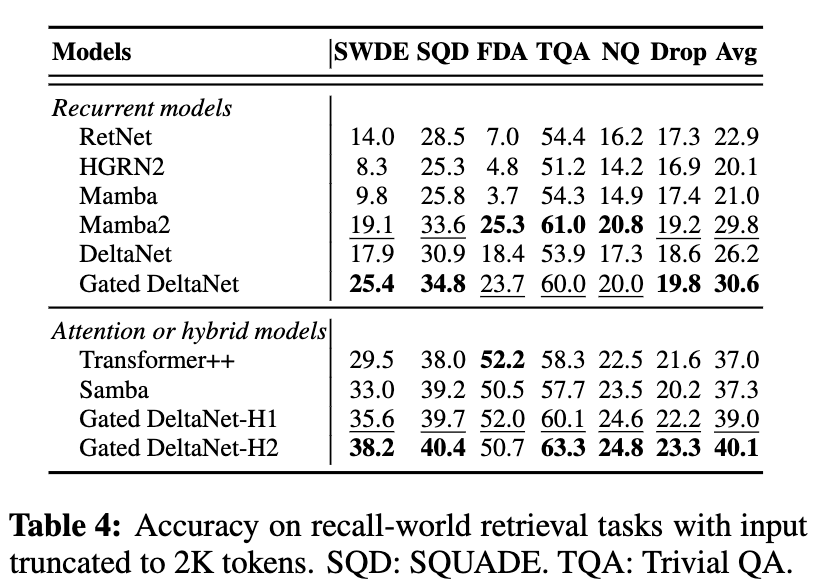
真实世界数据中的上下文检索(In-Context Retrieval on Real-World Data)
- 与标准 Transformer 相比,纯线性循环模型存在显著性能差距;而将线性循环机制与注意力结合的混合模型在检索任务中优于纯注意力模型。
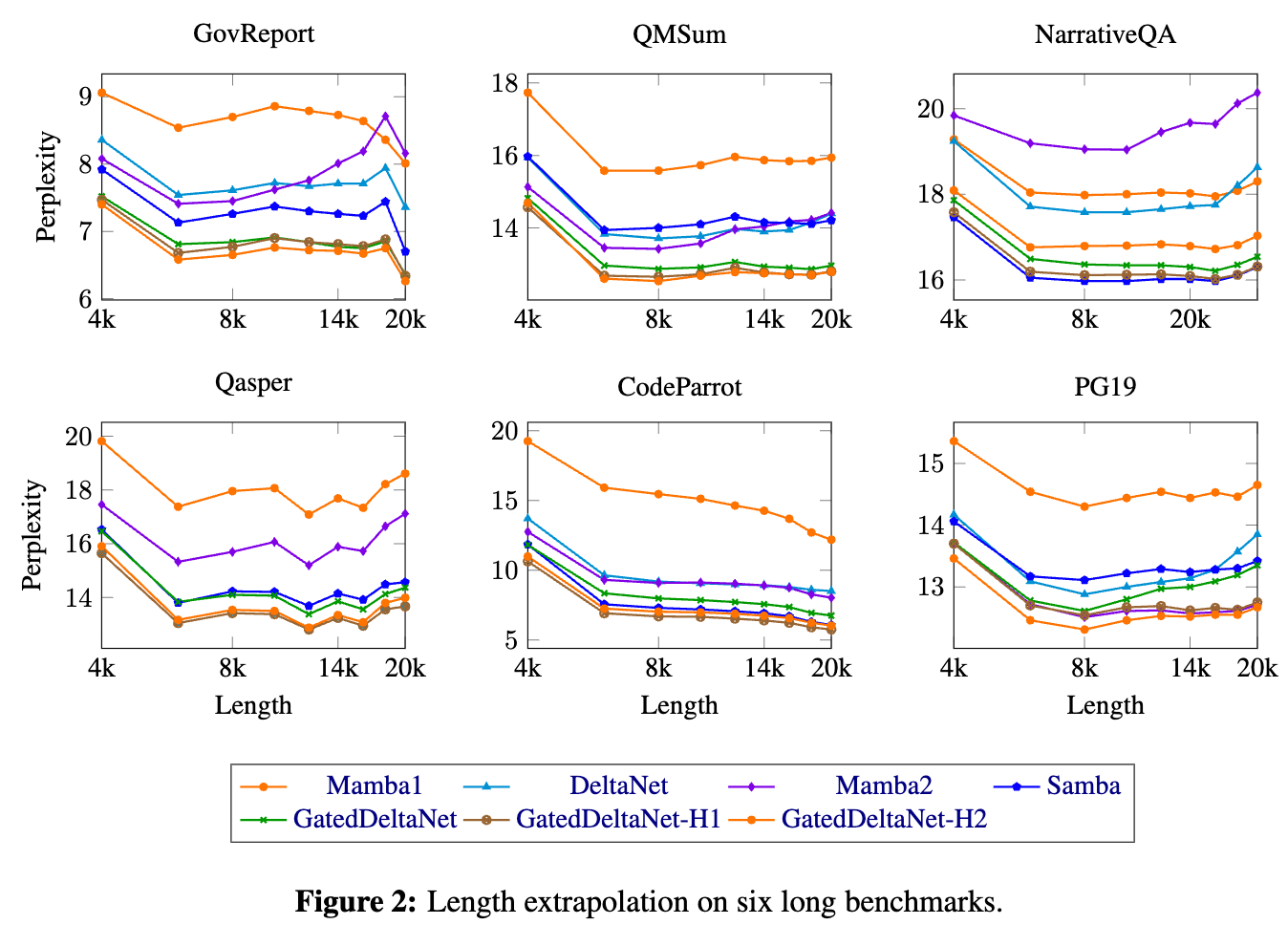
长序列上的长度外推能力(Length Extrapolation on Long Sequences)
- 在六个长上下文基准任务中评估了模型对长达 20K token 序列的外推能力。在所有 RNN 模型中,Gated DeltaNet 实现了最低的整体困惑度。
长上下文理解(Long Context Understanding)
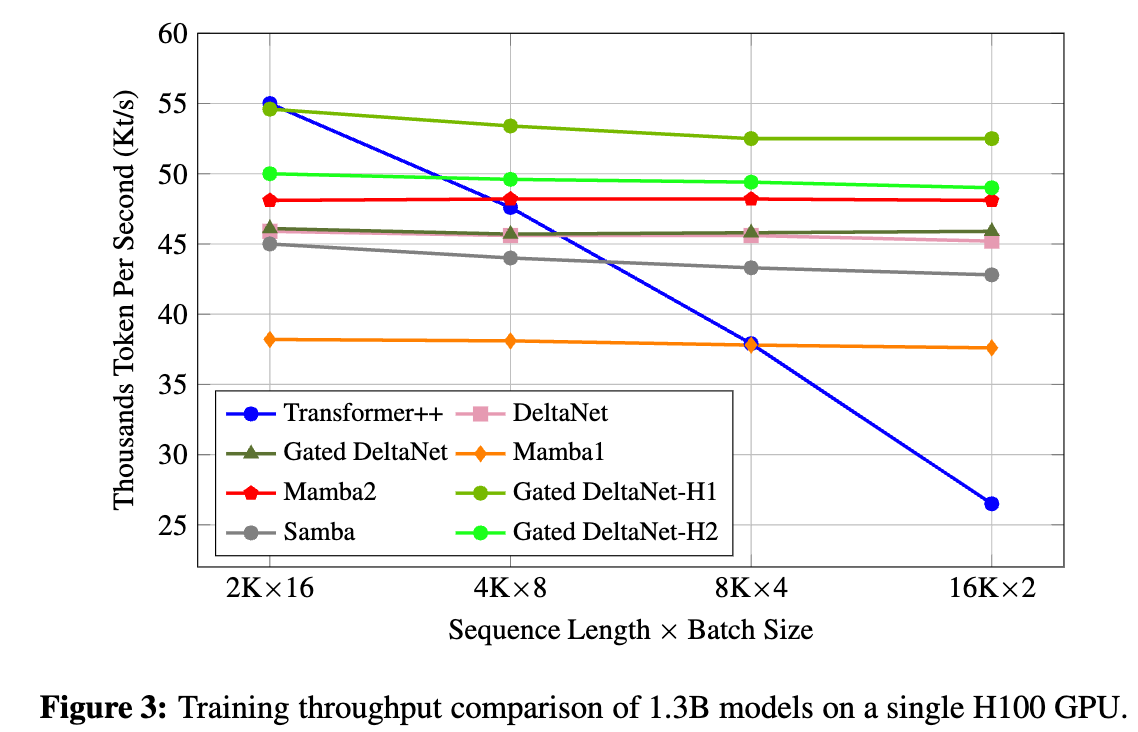
- 基于 LongBench 测试,在线性循环模型中,Gated DeltaNet 展现出稳定优势,特别是在单文档问答(single-doc QA)、少量样本上下文学习(few-shot in-context learning)和代码任务(Code)中,分别体现了其在信息检索、上下文学习和状态追踪方面的优越能力。
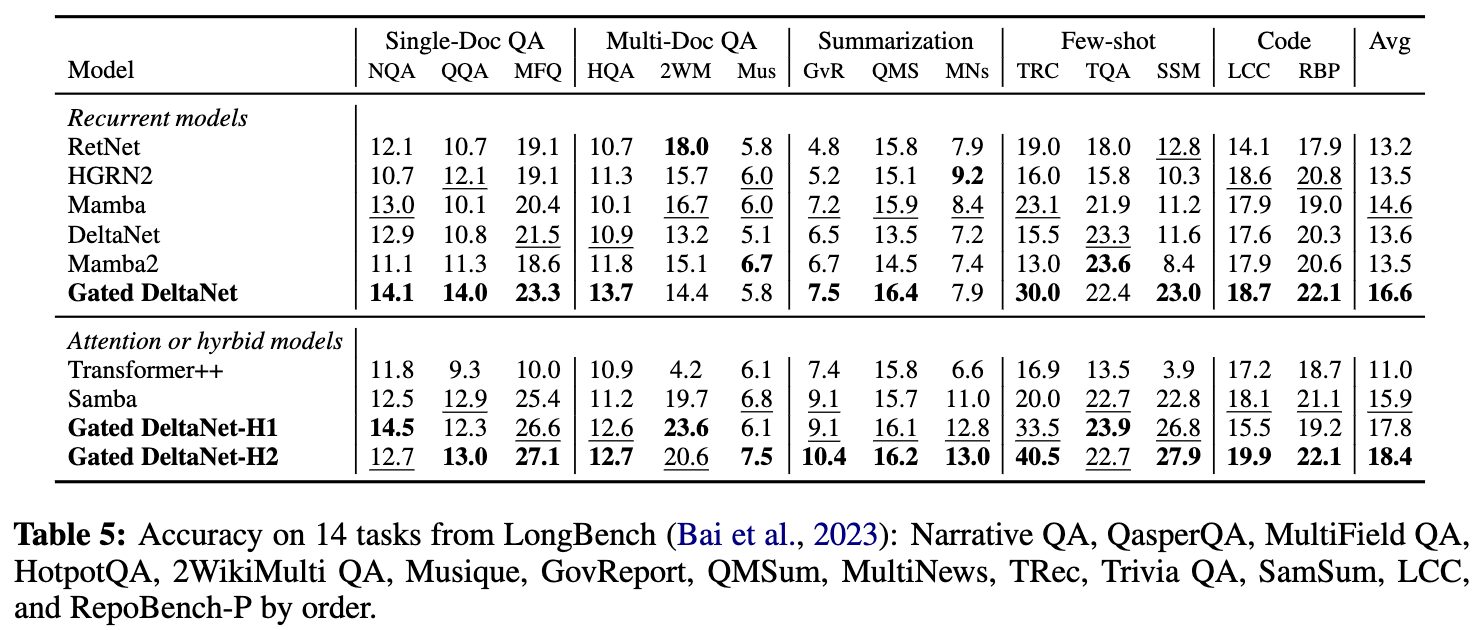
吞吐量对比(Throughput Comparison)
- 图3展示了不同模型的训练吞吐量对比。
- 相比原始 Delta 规则,提出的门控 Delta 规则仅引入了轻微的额外开销,Gated DeltaNet 与 DeltaNet 的吞吐量基本相当。由于采用了更具表达力的状态转移矩阵,它们的训练速度略慢于 Mamba2(约2–3K token/秒)。
- 滑动窗口注意力(SWA)能提速,Gated DeltaNet-H1 和 -H2 优于 Gated DeltaNet。
Conclusion
- 提出了 Gated DeltaNet ,相比 Mamba2 具备更强的键值关联学习能力,相比 DeltaNet 具备更灵活的内存清除机制