GPU时间与transformer架构计算量分析
GPU时间与transformer架构计算量分析
GPU时间的介绍
-
GPU时间是指在深度学习训练和推理过程中,GPU执行计算任务所花费的时间。与CPU相比,GPU具有大量的并行计算单元,能够高效地处理矩阵运算,因此在深度学习领域被广泛应用。
GPU时间主要包括以下几个方面:
- 计算时间:执行数学运算的时间
- 内存访问时间:数据在GPU内存中的读写时间
- 数据传输时间:CPU与GPU之间的数据传输时间
- 同步时间:不同操作之间的同步等待时间
-
影响GPU时间的因素包括:
- 模型的参数量和计算复杂度
- GPU的计算能力(如CUDA核心数量、频率等)
- 内存带宽
- 批处理大小(Batch Size)
- 优化器选择
- 并行化程度
Transformer模型的参数计算
-
这里主要讨论Decode-Only架构,所以下面的都是基于Decoder模块,且不包含encoder-decoder attention,即不包含Decoder中蓝色框的部分
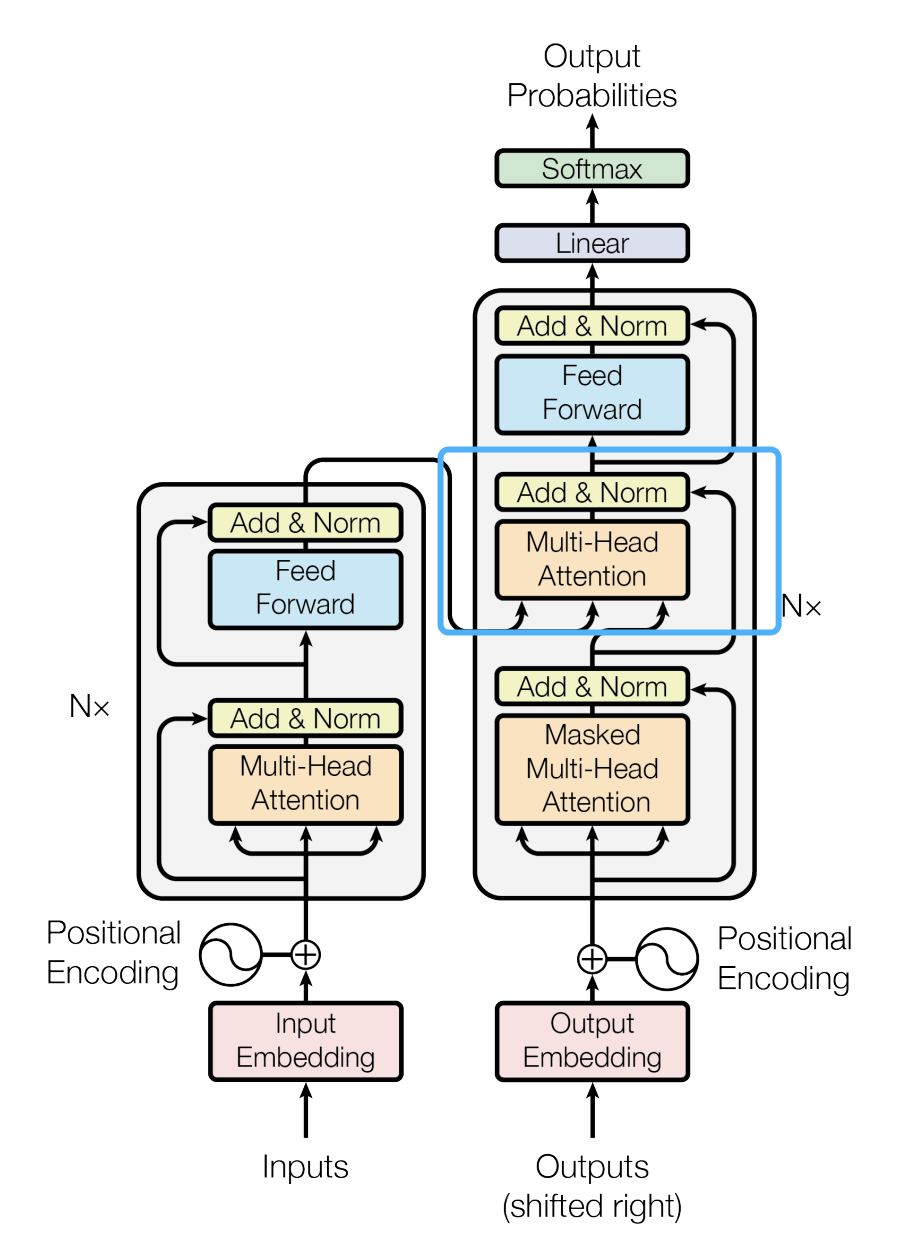
-
后续的缩写如下
解释 缩写 b a t c h _ s i z e batch\_size batch_size batch大小 b s e q _ l e n seq\_len seq_len 序列长度 s v o c a b _ s i z e vocab\_size vocab_size 词汇表大小 v d _ m o d e l d\_model d_model 模型维度 d layer_num transformer模块个数 l
Embedding层参数
-
Embedding层将输入的token ID映射为连续的向量表示,其参数量取决于词汇表大小和嵌入维度,假设词汇表大小为vocab_size, 模型维度为d_model,则embedding层参数量为:
θ _ e m b e d = v o c a b _ s i z e ⋅ d _ m o d e l = v ⋅ d \begin{aligned} \theta\_embed &= vocab\_size \cdot d\_model \\ &=v\cdot d \end{aligned} θ_embed=vocab_size⋅d_model=v⋅d
MultiHead-Self-Attention模型参数
-
Self-Attention模块的参数主要来自于三个投影矩阵:Query (Q)、Key (K)和Value (V),以及输出投影矩阵。
假设输入维度为 d_model,注意力头数为 n_heads ,每个头的维度为d_k(通常d_k = d_model/n_heads):
Q、K、V投影矩阵以及输出投影矩阵共四个,单个参数量为 (考虑bias)
θ _ s i n g l e = d _ m o d e l × d _ m o d e l + d _ m o d e l = d _ m o d e l 2 + d _ m o d e l = d 2 + d \begin{aligned} \theta\_single &= d\_model × d\_model + d\_model \\ &= d\_model^2 + d\_model\\ &=d^2+d \end{aligned} θ_single=d_model×d_model+d_model=d_model2+d_model=d2+d因此,一个完整的Multi-Head Attention模块的参数量为:
θ _ M u l t i H e a d = 4 × ( d _ m o d e l 2 + d _ m o d e l ) = 4 × d _ m o d e l 2 + 4 × d _ m o d e l = 4 d 2 + 4 d \begin{aligned} \theta\_MultiHead &= 4\times (d\_model^2 + d\_model)\\ &= 4 \times d\_model^2 + 4\times d\_model\\ &=4d^2+4d \end{aligned} θ_MultiHead=4×(d_model2+d_model)=4×d_model2+4×d_model=4d2+4d
MLP模型参数(FeedForward层)
-
Transformer中的MLP(前馈神经网络)通常包含两个全连接层,结束输入维度为d_model, 中间隐藏层维度为hidden_size(通常为4倍d_model), 输出层维度为d_model,则
- 第一层参数量:d_model → hidden_size(通常hidden_size = 4 × d_model,这里考虑bias)
θ _ M L P 1 = d _ m o d e l ⋅ h i d d e n _ s i z e + h i d d e n _ s i z e = d _ m o d e l ⋅ 4 ⋅ d _ m o d e l + 4 ⋅ d _ m o d e l = 4 ⋅ d _ m o d e l 2 + 4 ⋅ d _ m o d e l = 4 d 2 + 4 d \begin{aligned} \theta\_MLP1 &= d\_model \cdot hidden\_size + hidden\_size \\ &= d\_model \cdot 4\cdot d\_model +4\cdot d\_model\\ &= 4 \cdot d\_model^2 + 4\cdot d\_model\\ &=4d^2+4d \end{aligned} θ_MLP1=d_model⋅hidden_size+hidden_size=d_model⋅4⋅d_model+4⋅d_model=4⋅d_model2+4⋅d_model=4d2+4d
- 第一层参数量:d_model → hidden_size(通常hidden_size = 4 × d_model,这里考虑bias)
- 第二层参数量:hidden_size → d_model
θ _ M L P 2 = h i d d e n _ s i z e ⋅ d _ m o d e l + d _ m o d e l = 4 ⋅ d _ m o d e l ⋅ d _ m o d e l + d _ m o d e l = 4 ⋅ d _ m o d e l 2 + d _ m o d e l = 4 d 2 + d \begin{aligned} \theta\_MLP2 &= hidden\_size \cdot d\_model + d\_model \\ & = 4\cdot d\_model \cdot d\_model + d\_model\\ & = 4 \cdot d\_model^2 + d\_model\\ &=4d^2+d \end{aligned} θ_MLP2=hidden_size⋅d_model+d_model=4⋅d_model⋅d_model+d_model=4⋅d_model2+d_model=4d2+d
需要注意的是,第一层bias参数量为 hidden_size = 4d_model,第二层bias参数量为d_model
MLP总参数量
θ _ M L P = θ _ M L P 1 + θ _ M L P 2 = 4 ⋅ d _ m o d e l 2 + 4 ⋅ d _ m o d e l + 4 ⋅ d _ m o d e l 2 + d _ m o d e l = 8 ⋅ d _ m o d e l 2 + 5 ⋅ d _ m o d e l = 8 d 2 + 5 d \begin{aligned} \theta\_MLP &= \theta\_MLP1 +\theta\_MLP2\\ &=4 \cdot d\_model^2 + 4\cdot d\_model + 4 \cdot d\_model^2 + d\_model \\ &=8 \cdot d\_model^2 + 5\cdot d\_model \\ &=8d^2+5d \end{aligned} θ_MLP=θ_MLP1+θ_MLP2=4⋅d_model2+4⋅d_model+4⋅d_model2+d_model=8⋅d_model2+5⋅d_model=8d2+5d
Layer Normalization参数
-
Layer Normalization包含两组参数:缩放因子 γ \gamma γ 和偏置 β \beta β ,每个参数的维度等于特征维度d_model。
每个Layer Norm的参数量为 2 ⋅ d _ m o d e l 2\cdot d\_model 2⋅d_model , 而在ransformer中,每个编码器/解码器层通常有两个Layer Norm(一个在Self-Attention后,一个在MLP后),因此每层的Layer Norm参数量为:
θ _ L a y e r N o r m = 4 ⋅ d _ m o d e l = 4 d \theta\_LayerNorm = 4\cdot d\_model = 4d θ_LayerNorm=4⋅d_model=4d
TransformerBlock参数
-
每个Transformer块的参数为 (注意这里是Transformer块,不包含Embedding层和最后的Linear层)
θ _ T r a n s B l o c k = θ _ M u l t i H e a d + θ _ M L P + θ _ L a y e r N o r m = 12 ⋅ d _ m o d e l 2 + 13 ⋅ d _ m o d e l ≈ 12 ⋅ d \begin{aligned} \theta\_TransBlock &=\theta\_MultiHead + \theta\_MLP + \theta\_LayerNorm \\ & = 12\cdot d\_model^2 + 13\cdot d\_model\\ &\approx 12\cdot d \end{aligned} θ_TransBlock=θ_MultiHead+θ_MLP+θ_LayerNorm=12⋅d_model2+13⋅d_model≈12⋅d
Linear层
-
最后的Linear层作用是将TransformerBlock的输出映射到词汇表大小,假设词汇表大小为vocab_size, 模型维度为d_model
θ _ L i n e a r = v o c a b _ s i z e ⋅ d _ m o d e l = v ⋅ d \begin{aligned} \theta\_Linear &= vocab\_size \cdot d\_model \\ &=v\cdot d \end{aligned} θ_Linear=vocab_size⋅d_model=v⋅d
示例-LLaMA模型参数量
-
LLaMA模型介绍
LLaMA-1是Meta AI在2023年2月发布的一系列大型语言模型。LLaMA-1模型有四种不同规模的版本
模型架构特点
-
词汇表大小:LLaMA-1使用的词汇表大小为32,000个token。
-
主要组件参数量:
-
Embedding层:vocab_size × d_model
- 例如7B模型:32,000 × 4,096 ≈ 131M参数
-
每个Transformer层:
- Self-Attention: 4 × d_model²
- MLP: 8 × d_model² (使用SwiGLU激活函数)
- Layer Normalization: 4 × d_model
-
7B模型每层参数量:
- Self-Attention: 4 × 4,096² ≈ 67.1M
- MLP: 8 × 4,096² ≈ 134.2M
- Layer Norm: 4 × 4,096 ≈ 0.016M
- 每层总计: ≈ 201.3M
- 32层总参数量: 32 × 201.3M ≈ 6.44B
-
-
特殊优化:
- 使用了RMSNorm进行归一化
- 采用了旋转位置编码(RoPE)
- 使用SwiGLU激活函数替代ReLU
- 去除了绝对位置编码
-
训练数据:LLaMA-1模型在约1.4万亿tokens的数据上进行了训练
与GPT-3相比,LLaMA-1在相同参数量级别下,通过更高效的架构设计和更多的训练数据,实现了相当或更好的性能。例如,LLaMA-13B的性能可以与GPT-3(175B)相媲美,而参数量只有后者的约7.5%。
-
-
以LLaMA模型为例,我们可以估算其参数量。LLaMA有多个版本,以LLaMA-1为例:
注意这里没有加上embedding层和最终归一化层
模型版本 参数量 隐藏层维度(d_model) 层数 12 ⋅ l ⋅ d _ m o d e l 2 12 \cdot l \cdot d\_model^2 12⋅l⋅d_model2 LLaMA-7B 6.7B 4,096 32 6,442,450,944 LLaMA-13B 13.0B 5,120 40 12,582,912,000 LLaMA-33B 32.5B 6,656 60 31,897,681,920 LLaMA-65B 65.2B 8,192 80 64,424,509,440
常见操作的FLOPs计算:
Floating Point Operation简介
-
浮点运算(Floating Point Operation,简称FLOP)是指计算机进行的浮点数数学运算。在深度学习中,我们通常使用FLOPs(Floating Point Operations Per Second)来衡量计算速度,使用总FLOPs来衡量计算量。
-
一个FLOP代表一次浮点运算,包括:加法操作、减法操作、乘法操作、除法操作以及平方根等特殊函数操作
在深度学习领域,通常将每次基本的数学运算(如加、减、乘、除)都计为1个FLOP。 -
需要注意的是,FLOPs(浮点运算次数)与FLOPs/s(每秒浮点运算次数)是两个不同的概念:
- FLOPs :表示完成一个计算任务所需的浮点运算总数,是一个绝对数值,用于衡量算法或模型的计算复杂度。
- FLOPs/s (或FLOPS,全大写):表示计算设备每秒能执行的浮点运算次数,是衡量计算设备性能的指标。通常以GFLOPS(10^9 FLOPs/s)或TFLOPS(10^12 FLOPs/s)为单位。
向量点积:
-
向量点积是最常见的向量乘法运算,定义为:
x ⋅ y = ∑ i = 1 m x i y i = x 1 y 1 + x 2 y 2 + . . . + x m y m x \cdot y = \sum_{i=1}^{m} x_i y_i = x_1y_1 + x_2y_2 + ... + x_my_m x⋅y=i=1∑mxiyi=x1y1+x2y2+...+xmym
计算点积涉及的FLOPs数量为:- 每对元素相乘:m次乘法操作
- 将所有乘积相加:(m-1)次加法操作
-
因此,两个长度为m的向量点积所需要的FLOPs数约等于
2 m F L O P s 2m FLOPs 2mFLOPs
矩阵乘法
-
矩阵乘法,当两个矩阵A[m,k]和B[k,n]相乘时,结果是一个m×n的矩阵C。
矩阵C中的每个元素C[i,j]的计算公式为:
C [ i , j ] = ∑ p = 1 k A [ i , p ] × B [ p , j ] C[i,j] = \sum_{p=1}^{k} A[i,p] \times B[p,j] C[i,j]=p=1∑kA[i,p]×B[p,j] -
上述公式意味着C矩阵的每个元素都是A矩阵的一行与B矩阵的一列的点积。是不是很熟悉,其实就是没个元素都是两个长度为k的向量点积
对于C矩阵中的每个元素C[i,j],我们需要执行以下操作:
- 乘法操作:k次乘法(A[i,1]×B[1,j], A[i,2]×B[2,j], …, A[i,k]×B[k,j])
- 加法操作:(k-1)次加法(将k个乘积相加需要k-1次加法操作)
因此,计算C[i,j]一个元素需要的FLOPs数为:
k + ( k − 1 ) = 2 k − 1 k + (k-1) = 2k - 1 k+(k−1)=2k−1 -
由于C矩阵有m×n个元素,每个元素需要(2k-1)个FLOPs,所以总的FLOPs数为:
m × n × ( 2 k − 1 ) m \times n \times (2k - 1) m×n×(2k−1) -
简约表示,当k非常大时 $2k-1\approx$2k ,所以可简约表示为
2 × m × n × k F L O P s 2 × m × n × k FLOPs 2×m×n×kFLOPs
矩阵加法
-
矩阵加法 (A[m,n] + B[m,n]): m × n FLOPs
矩阵加法,当两个矩阵A[m,n]和B[m,n]相加时,结果是一个m×n的矩阵C。
矩阵C中的每个元素C[i,j]的计算公式为:
C [ i , j ] = A [ i , j ] + B [ i , j ] C[i,j] = A[i,j] + B[i,j] C[i,j]=A[i,j]+B[i,j]
-
上述公式意味着C矩阵的每个元素都是A矩阵和B矩阵对应位置元素的简单加法。
对于C矩阵中的每个元素C[i,j],我们需要执行以下操作:
加法操作:1次加法(A[i,j] + B[i,j])
因此,计算C[i,j]一个元素需要的FLOPs数为:
1 F L O P s 1 FLOPs 1FLOPs
由于C矩阵有m×n个元素,每个元素需要1个FLOPs,所以总的FLOPs数为:
m × n F L O P s m \times n FLOPs m×nFLOPs
计算量估计
MultiHead self-Attention
-
假设数据数据的形式为[batch_size, seq_len],对于Self-attention模块(包含QKV投影矩阵和输出投影矩阵):
Q = x W Q , K = x W K , V = x W V Q = xW_Q,\quad K=xW_K,\quad V=xW_V Q=xWQ,K=xWK,V=xWVx o u t = s o f t m a x ( Q K T d _ m o d e l ) ⋅ V ⋅ W O + x x_{out} = \mathbf{softmax}(\frac{QK^T}{\sqrt{d\_model}})\cdot V\quad \cdot W_O + x xout=softmax(d_modelQKT)⋅V⋅WO+x
其中:
- Q、K、V:QKV投影矩阵
- W O W_O WO :输出投影矩阵的权重
- 后面加上一个x是残差连接
如 Q = x W Q Q=xW_Q Q=xWQ , x 维度为 [b,s,d] , W Q W_Q WQ 维度为[d,d],则按照矩阵乘法的FLOPs计算有
b ⋅ s ⋅ d ⋅ ( 2 d − 1 ) ≈ 2 b s d 2 b \cdot s \cdot d \cdot (2d-1) \approx 2bsd^2 b⋅s⋅d⋅(2d−1)≈2bsd2
其他计算类似FLOPs 计算Q,K,V 3 ⋅ 2 b s d 2 3\cdot 2bsd^2 3⋅2bsd2 计算 Q K T QK^T QKT 2 b s 2 d 2bs^2d 2bs2d 计算 s o f t m a x ( . ) @ V softmax(.)@ V softmax(.)@V 2 b s 2 d 2bs^2d 2bs2d 计算输出投影 2 b s d 2 2bsd^2 2bsd2
MLP模块
-
假设数据的形式为[batch_size, seq_len],对于MLP模块,假设隐藏层hidden_size等于4倍d_model
x = f r e l u ( x o u t W 1 ) W 2 + x o u t x = f_{relu}(x_{out}W_1)W2+x_{out} x=frelu(xoutW1)W2+xout
继续使用b替代batch_size, s替代seq_len, d替代d_model如第一层的MLP,是将x_out从 [batch_size,seq_len,d_model] --> [batch_size, seq_len , hidden_size],所以FLOPs等于
$$
\begin{aligned}
FLOPs &= batch_size\cdot seq_len\cdot hidden_size \cdot (2\cdot d_model - 1)\
&\approx b\cdot s \cdot 4d \cdot 2d\
&\approx 8bsd^2\end{aligned}
$$
其他计算类似FLOPs 第一层MLP 8 b s d 2 8bsd^2 8bsd2 第二层MLP 8 b s d 2 8bsd^2 8bsd2
Linear层
-
假设数据的形式为[batch_size, seq_len],对于最后的Linear层,是将输入映射到词汇表大小,即
[batch_szie, seq_len, d_model] --> [batch_size,seq_len,vocab_size]
F l O P s = b a t c h _ s i z e ⋅ s e q _ l e n ∗ v o c a b _ s i z e ∗ ( 2 d _ m o d e l − 1 ) = b s v ⋅ ( 2 d − 1 ) ≈ 2 b s v d \begin{aligned} FlOPs &= batch\_size \cdot seq\_len * vocab\_size * (2d\_model -1)\\ &=bsv\cdot(2d-1)\\ &\approx 2bsvd \end{aligned} FlOPs=batch_size⋅seq_len∗vocab_size∗(2d_model−1)=bsv⋅(2d−1)≈2bsvd
一个batch的计算量
-
对于其中一个[batch_size, seq_len],其计算量self-attention模块 + MLP模块 + Linear层t o t a l _ F L O P s = l ⋅ ( 24 b s d 2 + 4 b s 2 d ) + 2 b s v d total\_FLOPs = l\cdot(24bsd^2+4bs^2d) + 2bsvd total_FLOPs=l⋅(24bsd2+4bs2d)+2bsvd
计算量与参数量之间的关系
-
根据我们前面我们计算的参数量,transform blok为 l 的参数量为
12 ⋅ d 2 ⋅ l 12\cdot d^2\cdot l 12⋅d2⋅l -
对于1个[batch_szie,seq_len]的数据,计算量约等于
l ⋅ 24 b s d 2 l \cdot 24 bsd^2 l⋅24bsd2 -
在forward过程中
l ⋅ 24 b s d 2 12 ⋅ d 2 ⋅ l ⋅ b ⋅ s = F L O P s 参数量 ⋅ T o k e n 数 = 2 \frac{l \cdot 24 bsd^2}{12\cdot d^2\cdot l \cdot b\cdot s} = \frac{FLOPs}{参数量\cdot Token数} = 2 12⋅d2⋅l⋅b⋅sl⋅24bsd2=参数量⋅Token数FLOPs=2
其中 t o k e n 数 = b a t c h _ s i z e ∗ s e q _ l e n token数=batch\_size * seq\_len token数=batch_size∗seq_len对于1个token,没个模型参数需要进行2个float运算
-
如果forward过程需要1个单位的计算,那么backward大约需要2个单位的计算,中间变量大约需要1个单位计算,总共需要4个单位
-
所以Forward,Backward,中间变量,
对于一个token,每个模型参数需要进行8个Float运算。
训练时长
-
训练时长计算公式如下
训练时间 = 计算量 G P U 数 × G P U 峰值 f l o p s × G P U 利用率 = 8 × t o k e n s × 参数量 G P U 数 × G P U 峰值 f l o p s × G P U 利用率 \begin{aligned} 训练时间 &= \frac{计算量}{GPU数\times GPU峰值flops \times GPU利用率} \\ &= \frac{8 \times tokens \times 参数量}{GPU数\times GPU峰值flops \times GPU利用率} \\ \end{aligned} 训练时间=GPU数×GPU峰值flops×GPU利用率计算量=GPU数×GPU峰值flops×GPU利用率8×tokens×参数量