【AI面试秘籍】| 第22期:进行SFT时,基座模型选用Chat还是Base模型?

1. 理解SFT与基座模型选择
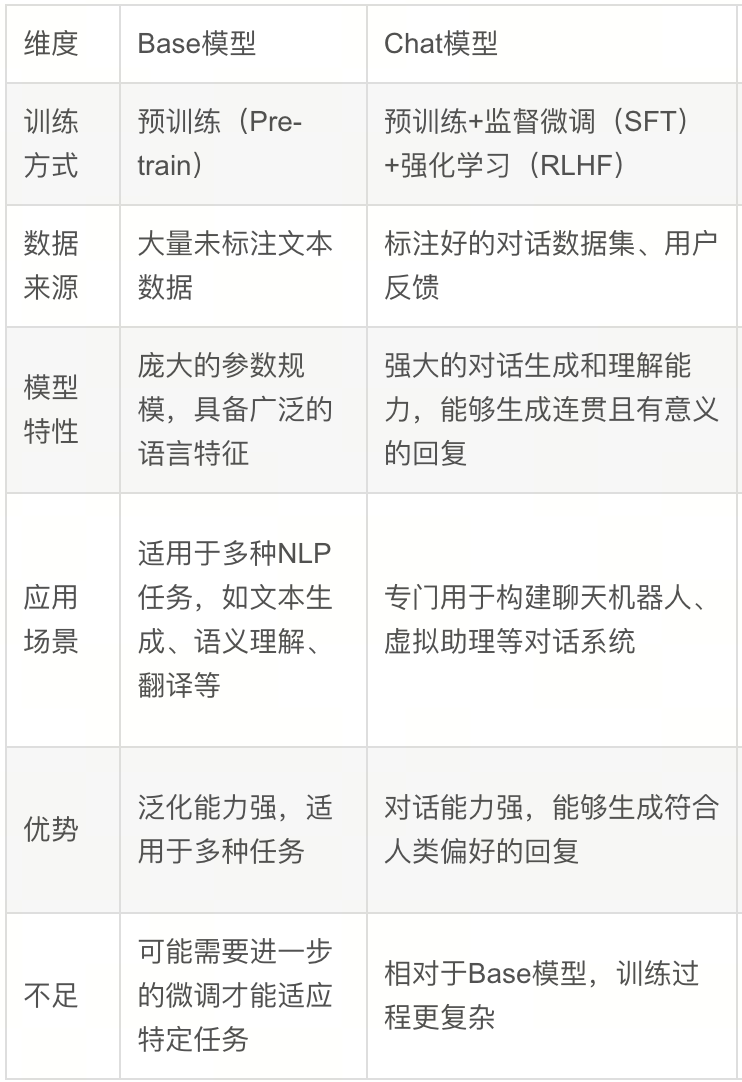
SFT,即有监督微调,是指在一个预训练好的大模型基础上,使用带有标签的数据集进行进一步训练,使其更好地适应特定任务或领域。基座模型,顾名思义,就是SFT的起点,可以是Chat模型(对话模型)或Base模型(基础模型)。
1.1 Chat模型
Chat模型通常在Base模型的基础上,经过大量的对话数据训练,使其具备理解和生成自然流畅对话的能力。例如,ChatGPT、LLaMA-2-chat等。
1.2 Base模型
Base模型是未经特定对话数据训练的原始预训练模型,它拥有强大的语言理解和生成能力,但在对话方面可能不如Chat模型。例如,LLaMA-2、GPT-3等。
2. 基座模型选择的考量因素
选择Chat模型还是Base模型作为SFT的基座,需要综合考虑以下几个方面:
2.1 任务类型
- 对话类任务: 如果你的目标是构建一个对话系统,例如客服机器人、智能助手等,那么选择Chat模型作为基座通常会更高效。Chat模型已经具备了良好的对话能力,SFT可以在此基础上进行针对性的优化,缩短训练周期,提高模型性能。
- 非对话类任务: 如果你的任务是文本分类、摘要、翻译、代码生成等非对话任务,那么Base模型可能是一个更合适的选择。Base模型更注重对通用语言知识的学习,SFT可以在此基础上更好地适配特定任务的需求。
2.2 数据集特点
- 对话数据充足: 如果你拥有大量的高质量对话数据,即使选择Base模型作为基座,也能通过SFT训练出优秀的对话模型。但如果数据量有限,Chat模型的优势会更加明显。
- 领域专业性强: 如果你的SFT任务涉及特定领域,且该领域的语料与通用对话语料差异较大,那么Base模型可能更容易通过SFT来学习和适应领域知识。
2.3 训练资源与成本
- 计算资源: 通常情况下,对Chat模型进行SFT所需的计算资源可能相对较少,因为其已具备一定对话能力。对Base模型进行SFT,如果想达到与Chat模型相近的对话效果,可能需要更多的计算资源和更长的训练时间。
- 时间成本: Chat模型在对话任务上可以更快地收敛,节省训练时间。
2.4 模型对齐与安全性
- 对齐: Chat模型通常已经经过RLHF(Reinforcement Learning from Human Feedback)等对齐训练,使其输出更符合人类偏好和价值观。如果你的应用对模型对齐有较高要求,选择Chat模型会省去一部分对齐的工作。
- 安全性: Chat模型在训练过程中通常会加入安全限制,避免生成有害、偏见或不当内容。如果你的应用对安全性有严格要求,Chat模型会是一个更安全的起点。
3. 具体案例分析与建议
3.1 案例1:开发通用型智能客服
- 目标: 构建一个能够处理用户常见问题的智能客服。
- 建议: 选用Chat模型作为基座。Chat模型天生具备对话能力,通过SFT引入行业特定知识和话术,能够快速构建高效且用户体验良好的智能客服。例如,基于LLaMA-2-chat进行SFT。
3.2 案例2:特定领域文本摘要工具
- 目标: 开发一个针对法律文献的自动摘要工具。
- 建议: 选用Base模型作为基座。法律文本的专业性很强,通用Chat模型可能难以很好地理解其中的专业术语和逻辑关系。从Base模型开始,使用大量法律文献进行SFT,能够更好地学习领域知识,生成高质量的摘要。例如,基于LLaMA-2进行SFT。
3.3 案例3:代码生成助手
- 目标: 构建一个辅助程序员生成代码片段的工具。
- 建议: 选用Base模型。代码生成并非典型的对话任务,更侧重于对语法、逻辑和API的理解。Base模型在代码领域进行预训练后,通过SFT在特定编程语言和框架上进行微调,效果会更好。
4. 干货总结与SFT策略
- 任务导向原则: 核心是根据SFT任务的类型来选择基座模型。对话任务优先考虑Chat模型,非对话任务优先考虑Base模型。
- “延续”与“重塑”:
- Chat模型 + SFT: 可以看作是“延续”模型已有的对话能力,在其基础上进行领域知识的注入和行为的微调。
- Base模型 + SFT: 更多的是“重塑”模型的能力,使其从通用语言模型转向特定任务或领域模型。
- 数据质量是关键: 无论选择哪种基座模型,SFT的效果最终都取决于微调数据集的质量和数量。高质量的指令遵循数据和领域数据是SFT成功的基石。
- 考虑多轮对话能力: 如果你的SFT任务需要模型具备多轮对话能力,Chat模型通常会提供更好的起点,因为它们在预训练阶段已经学习了对话上下文的维护。Base模型可能需要通过SFT引入更多多轮对话的机制。
- 评估与迭代: SFT是一个迭代的过程。即使选择了合适的基座模型,也需要通过详细的评估指标(如困惑度、BLEU、ROUGE,或特定任务指标)来衡量模型性能,并根据结果调整数据、模型结构或训练策略。
- RLHF的价值: 对于需要良好对齐和遵循人类指令的模型,即使以Base模型为起点进行SFT,后续也可能需要引入RLHF来进一步提升模型的效果和安全性。
5. 面试官考察点
在面试中,面试官不仅会关注你的答案,还会关注你对以下细节的理解:
- 对两种模型特点的清晰理解。
- 对选择依据的逻辑推理能力。
- 能否结合具体场景进行分析。
- 对SFT流程和相关技术(如RLHF)的了解。
- 对模型评估和迭代优化的认识。
6. 总结
选择Chat模型还是Base模型进行SFT,没有绝对的答案,需要根据具体任务需求、数据情况、资源限制和对齐安全性等因素进行权衡。深入理解两种模型的特点,并结合实际场景进行分析,才能做出最优选择。希望本文能帮助你更好地理解SFT中的基座模型选择问题,并在面试中游刃有余!
想学习AI更多干货可查看往期内容
- 【AI面试秘籍】| 第4期:AI开发者面试指南-大模型微调必考题QLoRA vs LoRA-CSDN博客
- 【AI面试秘籍】| 第3期:Agent上下文处理10问必考点-CSDN博客
- 【AI面试秘籍】| 第7期:多轮对话如何实现长期记忆?高频考点解析+代码实战-CSDN博客
- 💡大模型中转API推荐
技术交流:欢迎在评论区共同探讨!更多内容可查看本专栏文章,有用的话记得点赞收藏噜!
