显卡及相关大模型部署需求概述
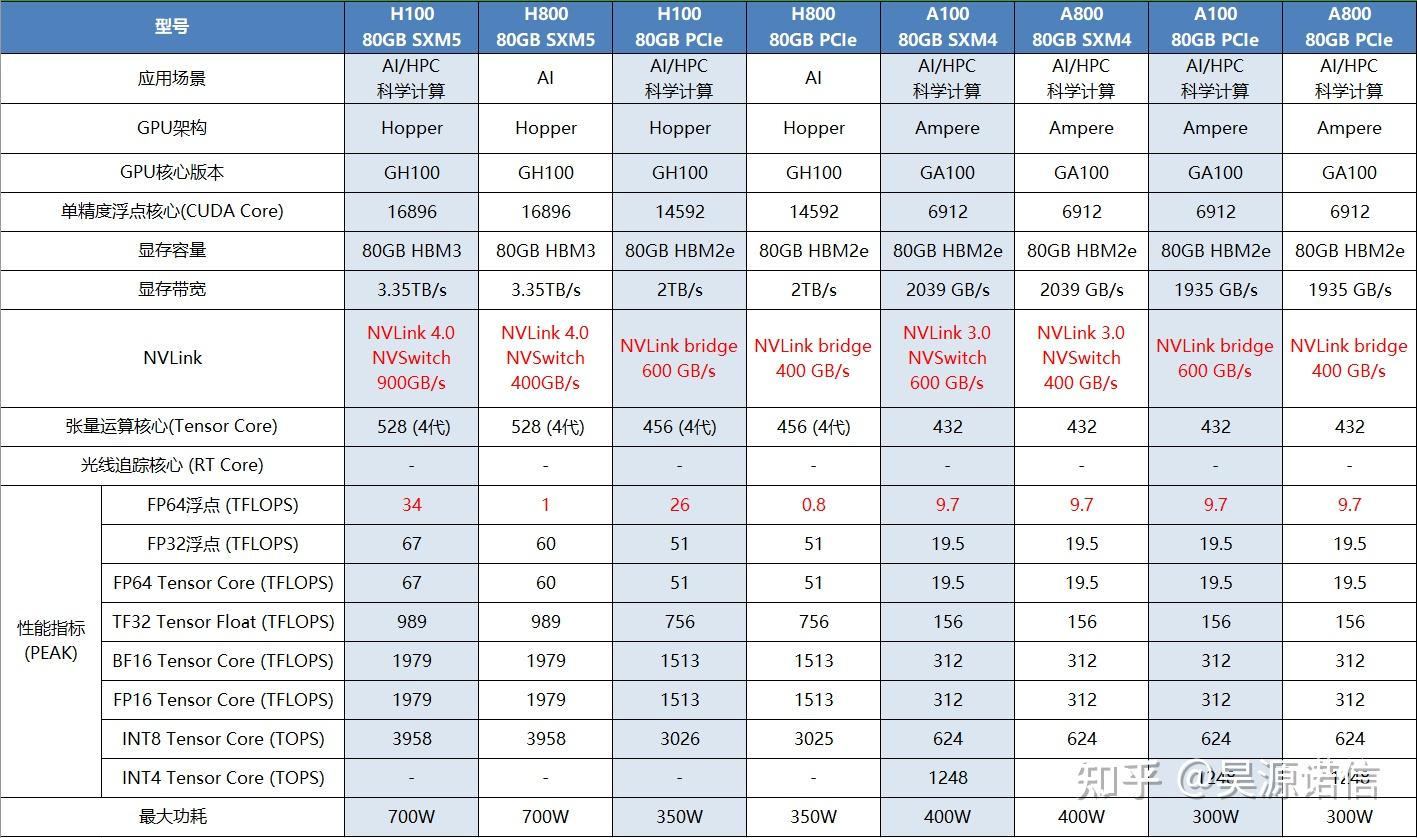
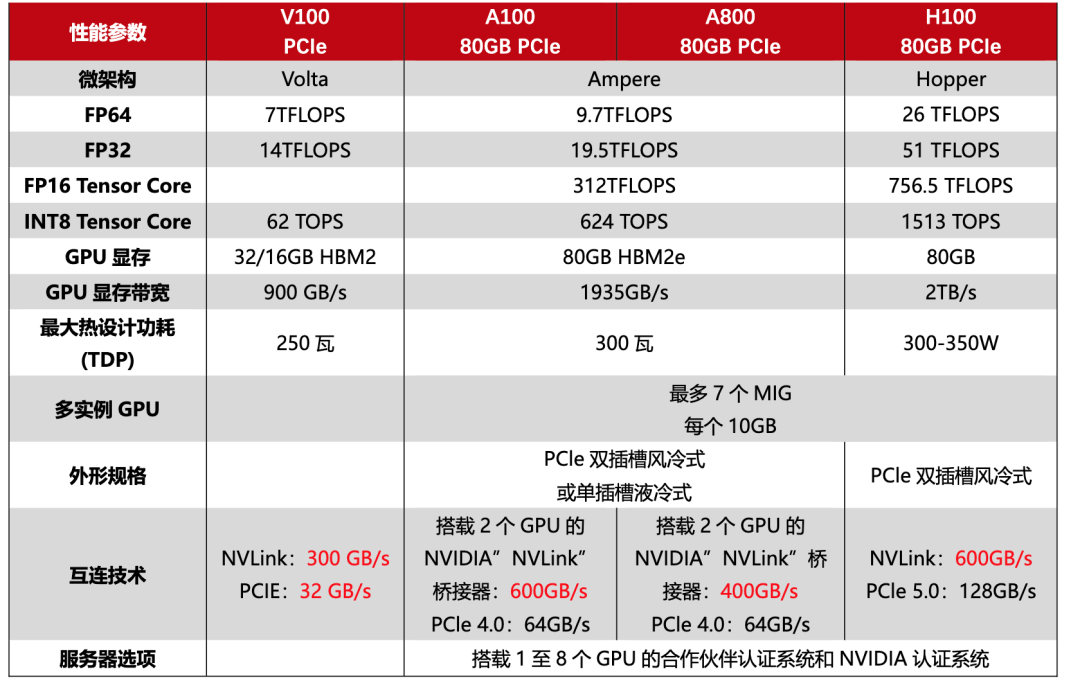
显卡性能对比
FP8 和 FP16 是两种不同的浮点数表示方式,它们主要用于计算领域,特别是在深度学习和高性能计算中,用于高效地进行数值运算。
FP16 是一种 16 位的浮点数表示方式,总长度:16 比特,
内存效率高:相较于 FP32,FP16 减少了内存使用量,使得计算和数据传输快速。
适中精度: 提供足够的计算精度,适用于大多数深度学习应用
硬件支持广泛: 许多现代 GPU 包括 NVIDIA 的 Tensor Core,都支持 FP16 优化计算
1.DeepSeek R1 671B(FP16) * 2= 1342
DeepSeek R1 原生(FP8)版:使用FP8数据精度,显存需求大概在750GB以上,是DeepSeek官方最推荐的配置。
DeepSeek R1 量化版本(INT8甚至INT4精度):显存虽然变小(335G即可),但模型表现却大打折扣
96G*16卡=1536(ADP卡)
2.运行qwen2-72b, FP16(2个字节),依赖显存:72*2=140G
1).华为910B,支持FP32和FP16精度,单卡性能对标英伟达A100:
64G,3张卡
2).海光k100-ai,64G,3张卡
2).nvidia-A800-80G ,2张卡
A100, 40/80GB
H100(特供版),FP16算力高达756 TFLOPS,显存带宽达3.35 TB/s
A800
H800(特供版)
H20