day 22 练习——泰坦尼克号幸存者预测
一、kaggle使用指南
Kaggle:免费 GPU 使用指南,Colab 的理想替代方案_免费gpu-CSDN博客
Kaggle入门指南(Kaggle竞赛)-CSDN博客
泰坦尼克号教程 --- Titanic Tutorial
二、数据集地址
Titanic - Machine Learning from Disaster | Kaggle
三、代码实例
# 上接平台代码
# 导入需要的库
# 基础工具
import time
import warnings
warnings.filterwarnings("ignore") # 数据可视化
import matplotlib.pyplot as plt
import seaborn as sns# 机器学习预处理
from sklearn.preprocessing import StandardScaler# 模型选择与验证
from sklearn.model_selection import train_test_split, StratifiedKFold, cross_val_score, GridSearchCV# 模型
from lightgbm import LGBMClassifier
from sklearn.ensemble import RandomForestClassifier
from xgboost import XGBClassifier# 评估指标
from sklearn.metrics import classification_report, confusion_matrix, accuracy_score, precision_score, recall_score, f1_score# 中文显示配置
plt.rcParams['font.sans-serif'] = ['SimHei'] # 查看基本信息
data = pd.read_csv("/kaggle/input/titanic/train.csv")
print("数据形状:",data.shape)
print("\n前5行数据:")
print(data.head())
print("\n数据基本信息:")
print(data.info())
print("\n描述性统计:")
print(data.describe())# 全局预处理(无统计量依赖)
# 删除对结果影响不大的列以及缺失值太多的列(Cabin)
data.drop(['PassengerId', 'Name', 'Ticket', 'Cabin'], axis=1, inplace=True)
# 创建新特征
data['FamilySize'] = data['SibSp'] + data['Parch']
data.describe()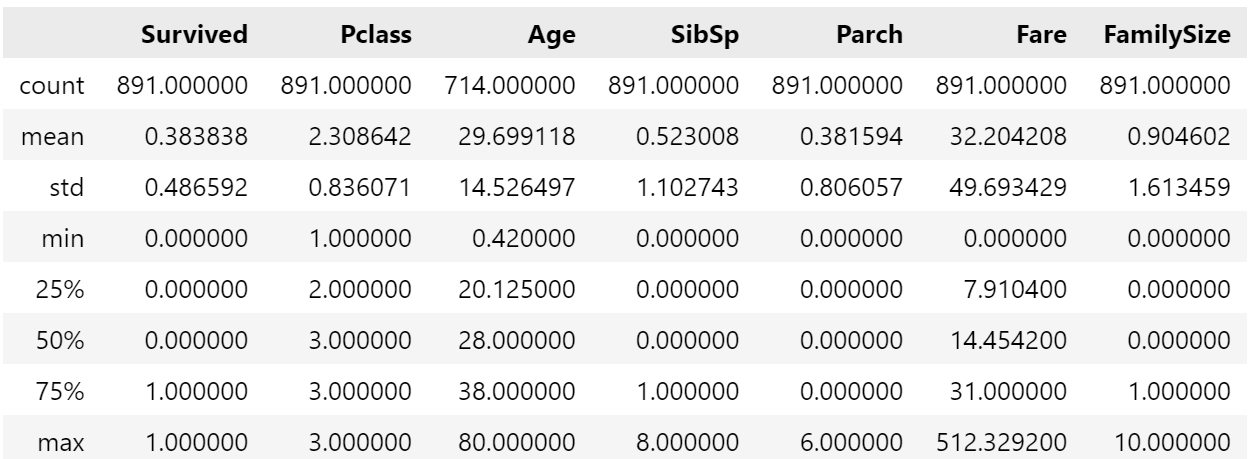
# 划分数据集(先于任何统计量计算!)
X = data.drop('Survived', axis=1)
y = data['Survived']
# 使用 stratify=y 这种分层抽样方式有助于防止数据集不平衡问题在划分数据集时加剧
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)# 缺失值处理(用训练集统计量)
age_median_train = X_train['Age'].median()
embarked_mode_train = X_train['Embarked'].mode()[0]
# 填充训练集
X_train['Age'].fillna(age_median_train, inplace=True)
X_train['Embarked'].fillna(embarked_mode_train, inplace=True)
# 用相同的统计量填充测试集
X_test['Age'].fillna(age_median_train, inplace=True) # 关键!不用X_test的统计量
X_test['Embarked'].fillna(embarked_mode_train, inplace=True)
# 验证缺失值已处理
print("训练集缺失值:\n", X_train.isnull().sum())
print("\n测试集缺失值:\n", X_test.isnull().sum()) 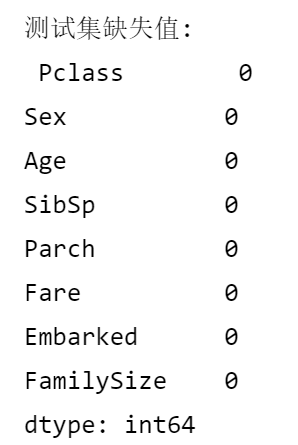
# 识别特征类型
continuous_features = data.select_dtypes(include=['float64']).columns.tolist()
discrete_features = data.select_dtypes(include=['int64']).columns.tolist() # 整数型(可能是分类)
categorical_features = data.select_dtypes(include=['object', 'category', 'bool']).columns.tolist()
target = 'Survived'
discrete_features.remove(target)print("\n连续特征:", continuous_features)
print("分类特征:", categorical_features)
print("离散特征:", discrete_features)
print(data['Age'].value_counts())
print(data['FamilySize'].value_counts())
# 特征处理
# 在训练集上定义所有转换规则用训练集规则处理测试集
# 1. 连续特征分箱(Age)
age_bins = [0, 18, 40, 80] # 根据训练集分布定义分箱边界
# ['0','1','2']对应['child', 'adult', 'senior']这样不用在分箱后再数值化处理
X_train['Age_bin'] = pd.cut(X_train['Age'], bins=age_bins, labels=['0','1','2'])
X_test['Age_bin'] = pd.cut(X_test['Age'], bins=age_bins, labels=['0','1','2'])
# 仅当类别有真实顺序且顺序间隔均匀时(如 ['low', 'medium', 'high']),数值映射才是安全的。
# 如果使用的模型对顺序敏感,需要谨慎考虑数字标签的赋值方式,或者采用其他编码方式(如独热编码)。
# 树模型对数值顺序不敏感,优先选择数值映射(减少维度爆炸)可以直接对分箱后的特征进行数值映射# 2. 连续特征标准化(Fare)
fare_scaler = StandardScaler().fit(X_train[['Fare']]) # 注意:输入需是二维数组
# 转换训练集和测试集
X_train['Fare_scaled'] = fare_scaler.transform(X_train[['Fare']])
X_test['Fare_scaled'] = fare_scaler.transform(X_test[['Fare']]) # 关键:使用训练集的scaler# 3. 分类特征数值映射(Sex)
sex_mapping = {'male': 0, 'female': 1}
X_train['Sex_encoded'] = X_train['Sex'].map(sex_mapping)
X_test['Sex_encoded'] = X_test['Sex'].map(sex_mapping)# 4. 分类特征及无数值顺序意义的离散特征独热编码(Embarked, Pclass)
train_embarked = pd.get_dummies(X_train['Embarked'], prefix='Embarked').astype(int)
train_pclass = pd.get_dummies(X_train['Pclass'], prefix='Pclass').astype(int)
# 按列合并
X_train = pd.concat([X_train, train_embarked, train_pclass], axis = 1)test_embarked = pd.get_dummies(X_test['Embarked'], prefix='Embarked').astype(int)
test_pclass = pd.get_dummies(X_test['Pclass'], prefix='Pclass').astype(int)
# 确保测试集包含训练集的所有列(缺失列补0)
# 这里没有考虑测试集中出现新列的情况(已经查看了test的类别计数,与训练集一致)
for col in train_embarked.columns:if col not in test_embarked.columns:test_embarked[col] = 0
for col in train_pclass.columns:if col not in test_pclass.columns:test_pclass[col] = 0
# 确保列顺序一致(按训练集的列顺序排序)
test_embarked = test_embarked[train_embarked.columns]
test_pclass = test_pclass[train_pclass.columns]
# 按列合并
X_test = pd.concat([X_test, test_embarked, test_pclass], axis=1)# 5. 离散特征分箱(FamilySize)
family_bins = [-1, 0, 3, 6, 10]
# ['0','1','2','3']分别对应['alone', 'small', 'medium', 'large']
X_train['FamilySize_bin'] = pd.cut(X_train['FamilySize'], bins=family_bins, labels=['0','1','2','3'])
X_test['FamilySize_bin'] = pd.cut(X_test['FamilySize'], bins=family_bins,labels=['0','1','2','3'])# 删除原始列
to_drop = ['Age', 'Sex', 'SibSp', 'Parch', 'FamilySize', 'Embarked', 'Pclass', 'Fare']
X_train_final = X_train.drop(to_drop, axis=1)
X_test_final = X_test.drop(to_drop, axis=1)# 验证列名一致性
assert set(X_train_final.columns) == set(X_test_final.columns), "训练集和测试集特征列不一致!"print("最终特征:")
print(X_train_final.head(10))
print('*' * 20)
print(X_test_final.head(10))print("再次检查缺失值情况:")
print(X_train_final.isnull().sum())
print(X_test_final.isnull().sum())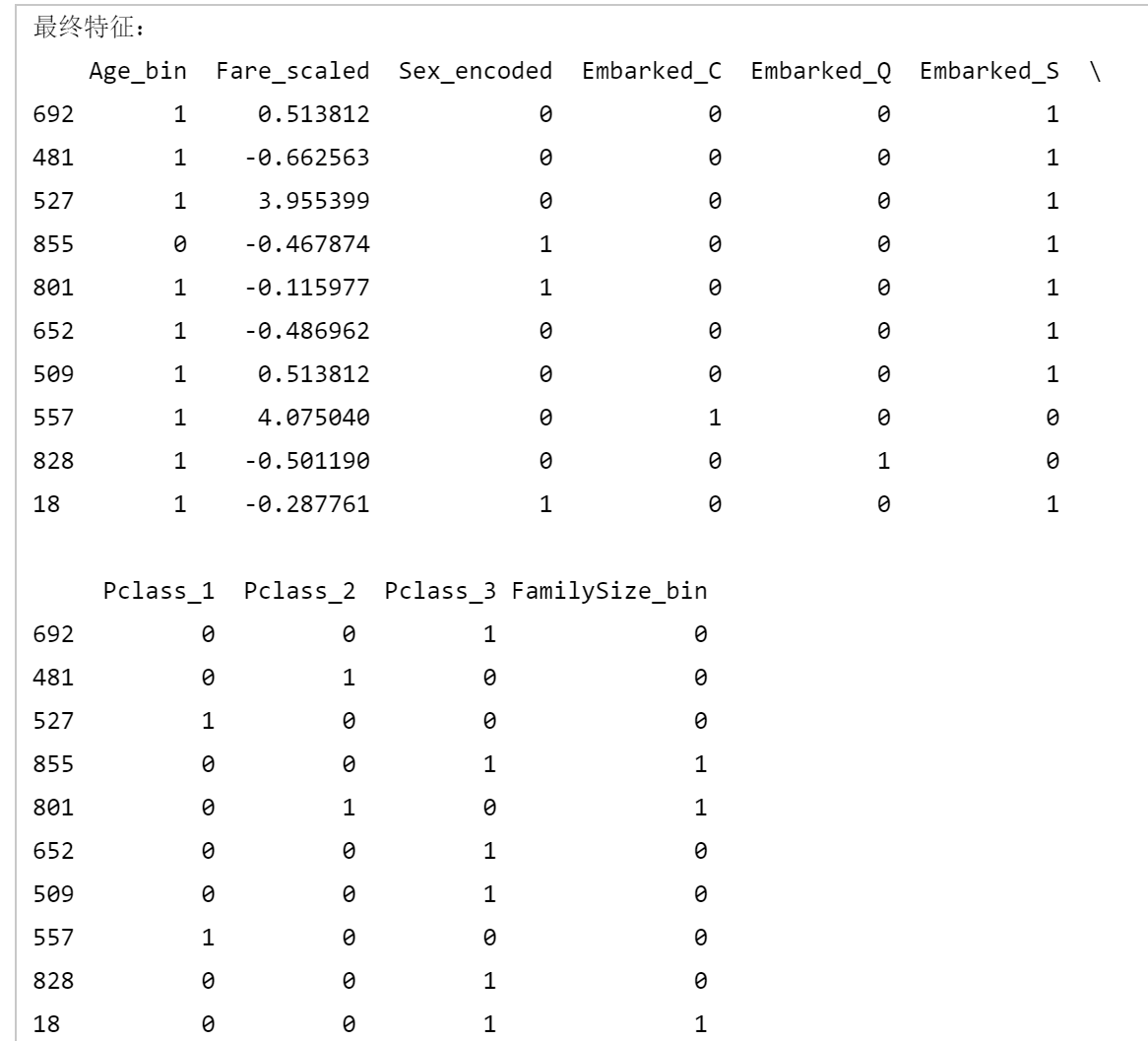
# 描述性统计
# 1. 标签分布
plt.figure(figsize=(10, 8))
custom_palette = ['red','blue']
sns.countplot(x=y_train,palette=custom_palette)
plt.title('Distribution of the number of survivors')
plt.show()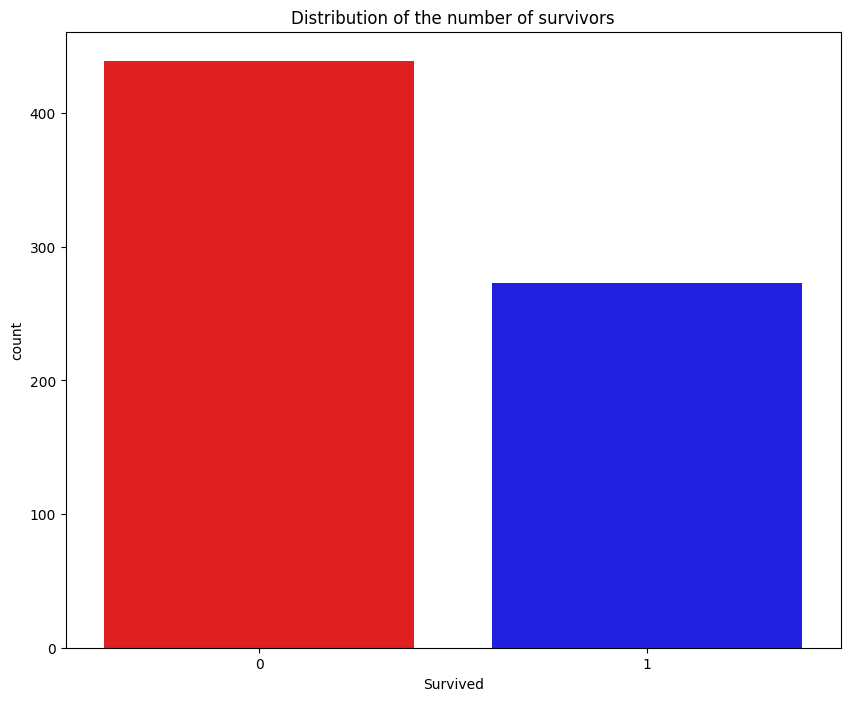
# 定义部分离散特征列表(已处理后的特征)
discrete_features = ['Age_bin', 'Sex_encoded','FamilySize_bin']
# 设置图形
plt.figure(figsize=(15, 10))
for i, feature in enumerate(discrete_features):plt.subplot(1, 3, i + 1)X_train_final[feature].value_counts().plot.pie(autopct='%1.1f%%')plt.title(f'{feature}')
plt.tight_layout()
plt.show()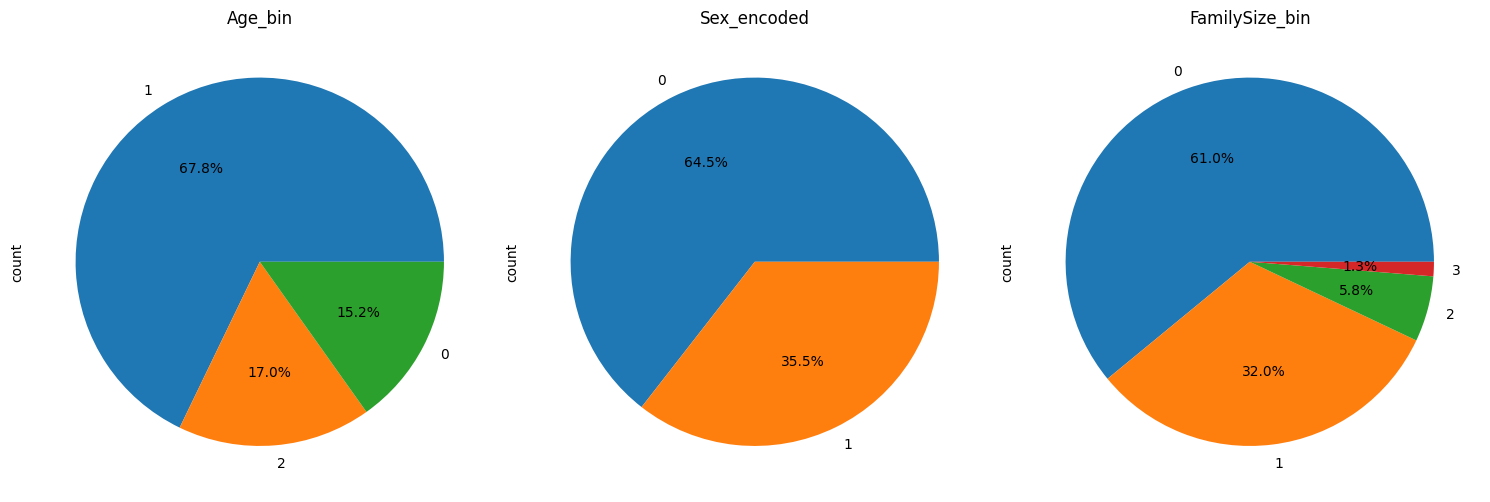
# 特征和标签关系
# 连续特征:带核密度曲线的分类直方图
plt.figure(figsize=(15, 10))
sns.histplot(data=X_train_final, x='Fare_scaled', hue=y_train, kde=True,element="step")
plt.title("Fare")
plt.show()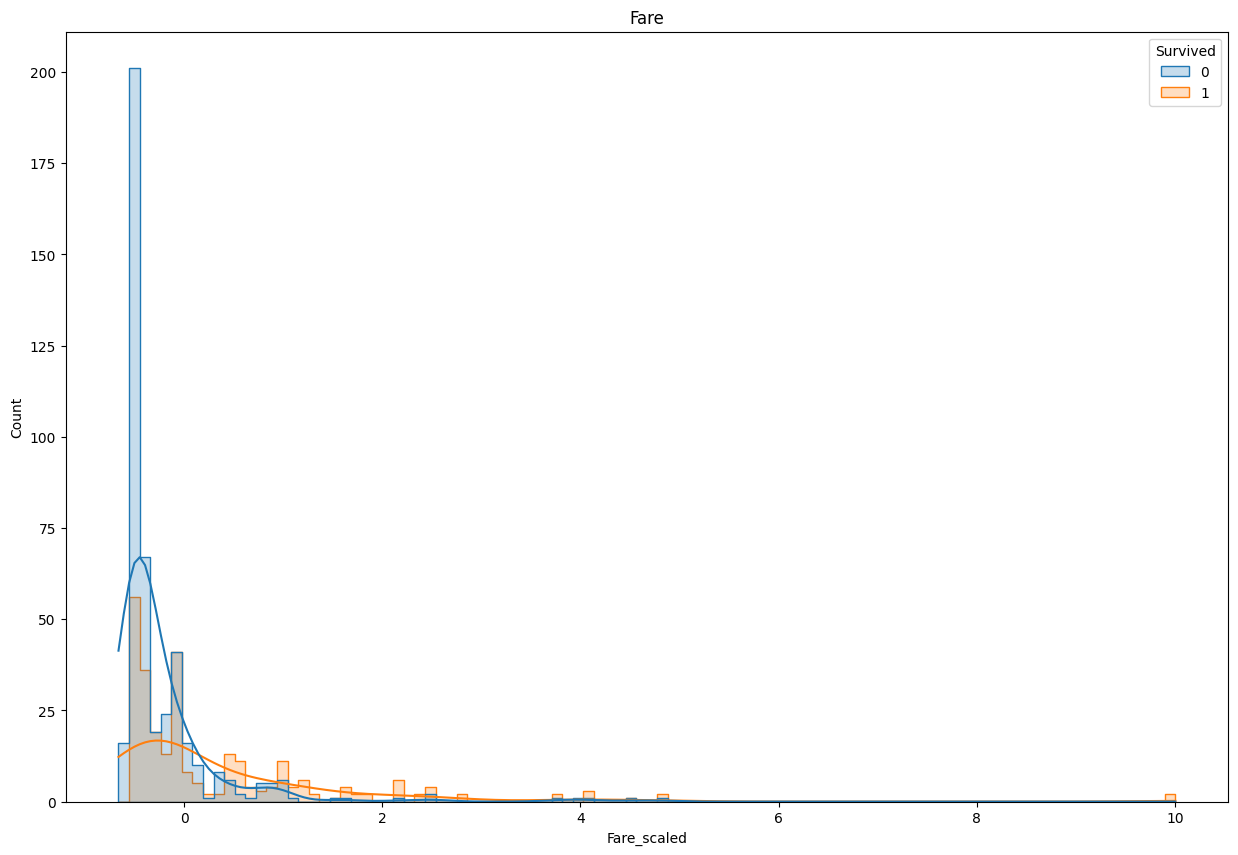
# 离散特征:带核密度的分类条形图
plt.figure(figsize=(10, 8))
features = ['Age_bin', 'Sex_encoded', 'FamilySize_bin']
for i, feature in enumerate(features):plt.subplot(2, 2, i+1)sns.countplot(x=feature, hue=y_train, data=X_train_final)
plt.tight_layout()
plt.show()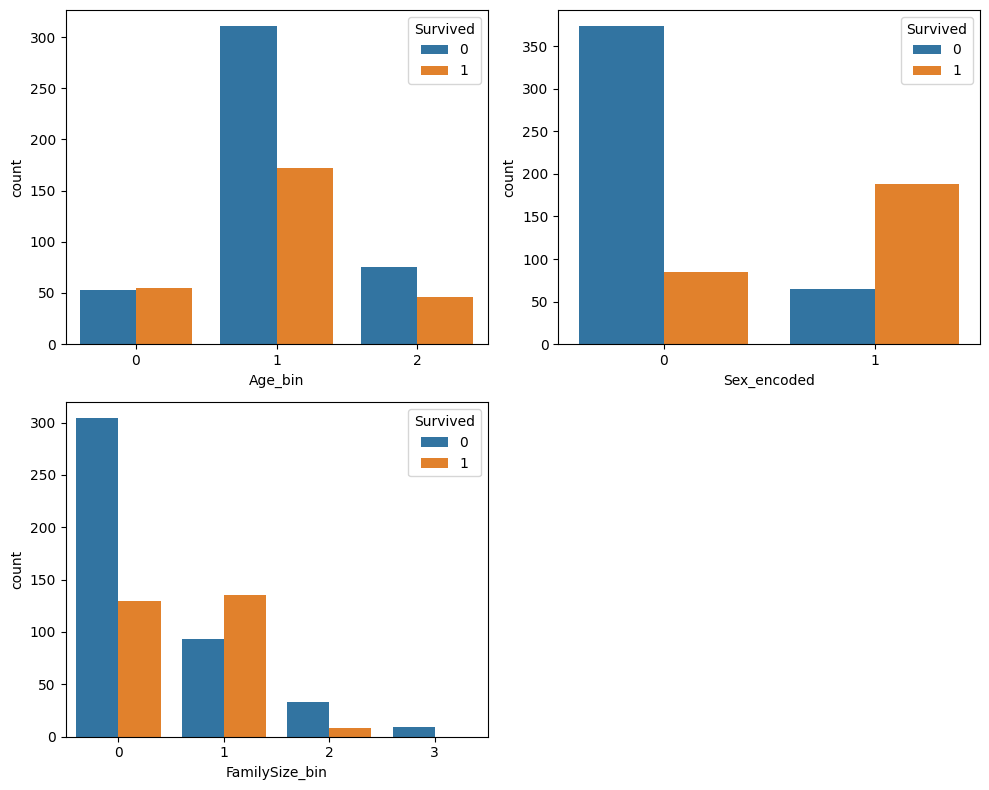
# 预处理:创建合并舱位列(独热编码会生成三列)
X_train_final['Pclass_combined'] = X_train_final[['Pclass_1', 'Pclass_2', 'Pclass_3']].idxmax(axis=1)
plt.figure(figsize=(10, 8))
sns.countplot(x=y_train, hue='Pclass_combined', data=X_train_final)
plt.title('pclass vs survior')
plt.show()
X_train_final.drop('Pclass_combined',axis=1,inplace=True)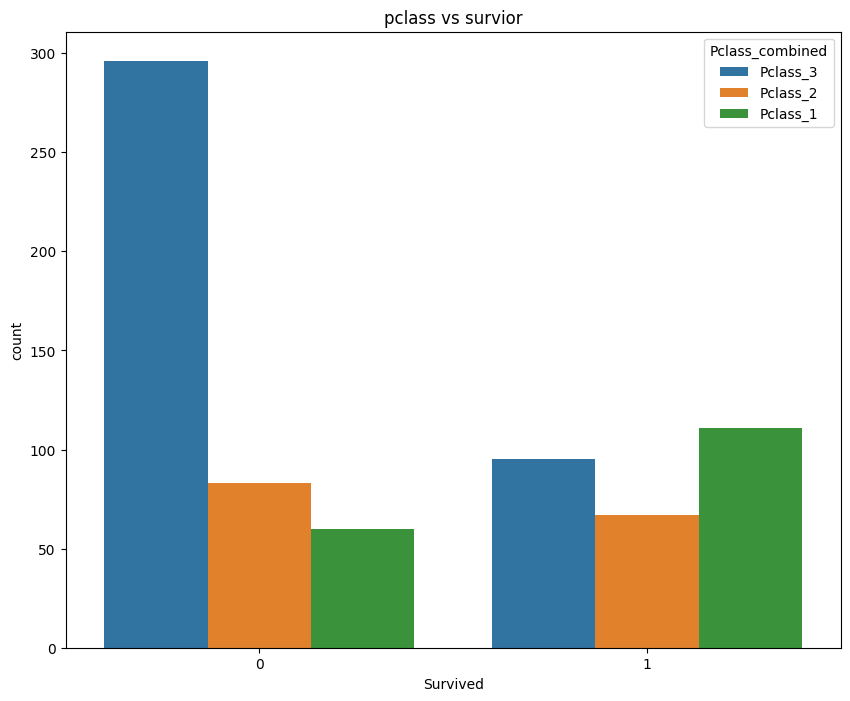
# 隐式分类特征:虽然数据为数值型,但Age_bin/FamilySize_bin等分箱列本质是离散类别
# XGBoost类型限制:默认不接受category类型,所以此处强制转换为整型
X_train_final = X_train_final.astype(int)
X_test_final = X_test_final.astype(int)
X_train_final.head(10)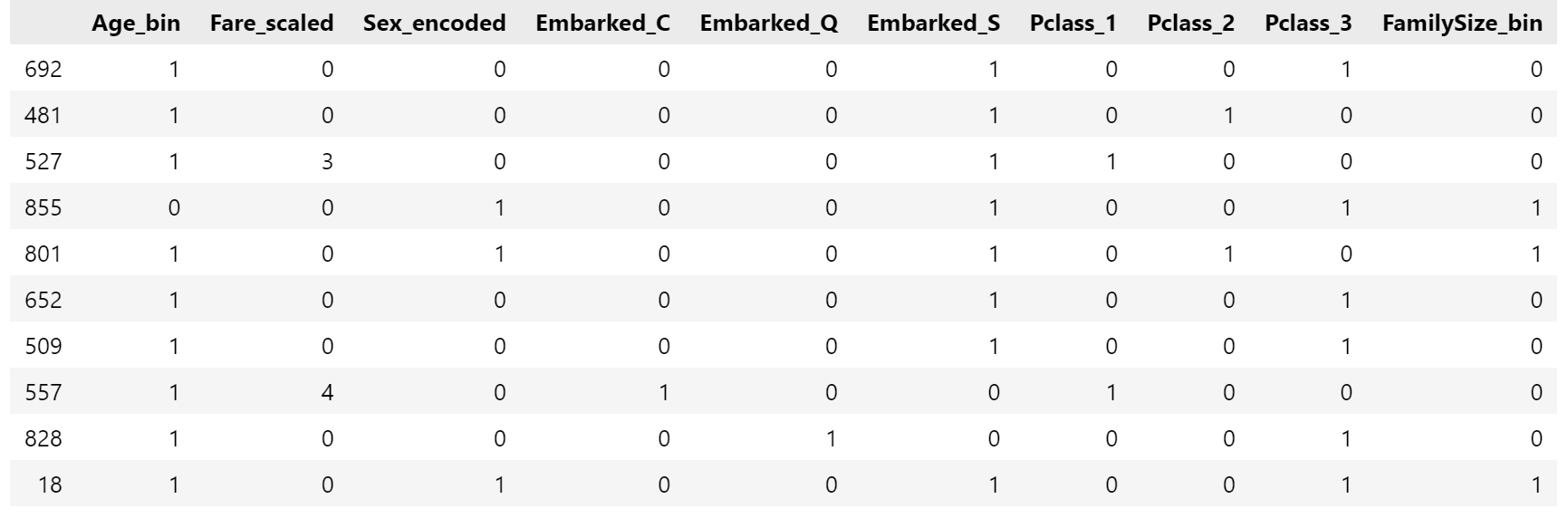
# 自定义评估函数
def evaluate_model(model, model_name):model.fit(X_train_final, y_train)y_pred = model.predict(X_test_final)print(f"\n{model_name} 分类报告:")print(classification_report(y_test, y_pred))print(f"{model_name} 混淆矩阵:")print(confusion_matrix(y_test, y_pred))accuracy = accuracy_score(y_test, y_pred)precision = precision_score(y_test, y_pred, average='weighted')recall = recall_score(y_test, y_pred, average='weighted')f1 = f1_score(y_test, y_pred, average='weighted')print(f"{model_name} 模型评估指标:")print(f"准确率: {accuracy:.4f}")print(f"精确率: {precision:.4f}")print(f"召回率: {recall:.4f}")print(f"F1值: {f1:.4f}")# LightGBM
lgb_model = LGBMClassifier(random_state=42)
evaluate_model(lgb_model, "LightGBM")# 随机森林
rf_model = RandomForestClassifier(random_state=42)
evaluate_model(rf_model, "随机森林")# XGBoost
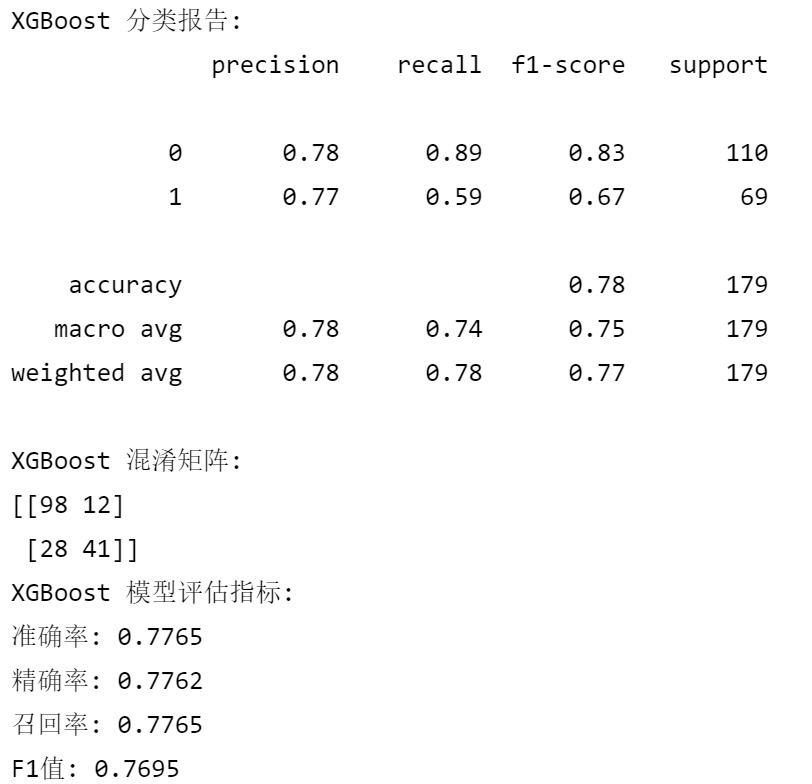
xgb_model = XGBClassifier(random_state=42)
evaluate_model(xgb_model, "XGBoost")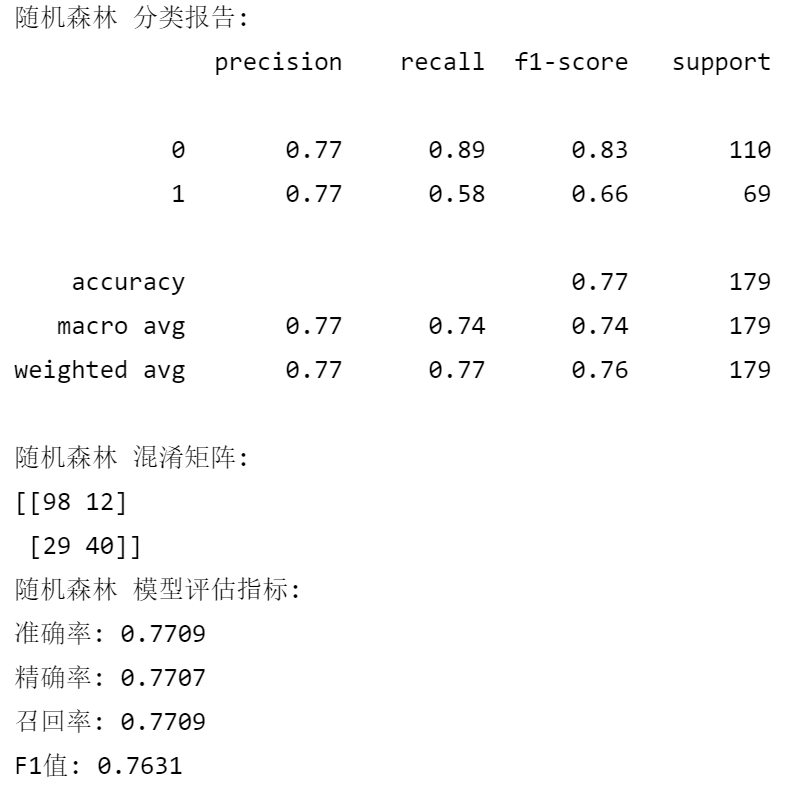

print("\n--- 网格搜索调优 ---")
xgb_param_grid = {'n_estimators': [50, 100, 150],'max_depth': [3, 5, 7],'learning_rate': [0.01, 0.1, 0.2],'subsample': [0.7, 0.8, 0.9],'colsample_bytree': [0.7, 0.8, 0.9]
}
# 在网格搜索前添加权重计算
from sklearn.utils.class_weight import compute_class_weight
class_weights = compute_class_weight('balanced', classes=np.unique(y_train), y=y_train)# 保持原有网格搜索代码不变
xgb_grid_search = GridSearchCV(estimator=XGBClassifier(random_state=42,scale_pos_weight=class_weights[1],eval_metric='mlogloss',enable_categorical=True # 新增关键参数),param_grid=xgb_param_grid,cv=5,scoring='f1_weighted',n_jobs=-1,verbose=1
)xgb_grid_search.fit(X_train_final, y_train) # 使用原始特征数据
print("最佳参数:", xgb_grid_search.best_params_)best_xgb_model = xgb_grid_search.best_estimator_
xgb_y_pred = best_xgb_model.predict(X_test_final)
print("\n网格搜索优化后的分类报告:")
print(classification_report(y_test, xgb_y_pred))
accuracy = accuracy_score(y_test, xgb_y_pred)
print(f"准确率: {accuracy:.4f}")
from bayes_opt import BayesianOptimization
print("\n--- XGBoost贝叶斯优化 ---")
def xgb_eval(n_estimators, max_depth, learning_rate, subsample, colsample_bytree):model = XGBClassifier(n_estimators=int(n_estimators),max_depth=int(max_depth),learning_rate=learning_rate,subsample=subsample,colsample_bytree=colsample_bytree,scale_pos_weight=class_weights[1],eval_metric='mlogloss',use_label_encoder=False,random_state=42)scores = cross_val_score(model, X_train_final, y_train, cv=5, scoring='f1_weighted')return np.mean(scores)# 参数搜索空间
pbounds = {'n_estimators': (50, 200),'max_depth': (3, 10),'learning_rate': (0.01, 0.3),'subsample': (0.6, 1.0),'colsample_bytree': (0.6, 1.0)
}# 执行优化
optimizer = BayesianOptimization(f=xgb_eval,pbounds=pbounds,random_state=42
)
optimizer.maximize(init_points=5, n_iter=15)# 输出最佳参数
best_params = optimizer.max['params']
print("XGBoost贝叶斯优化最佳参数:", {k: round(v, 4) if isinstance(v, float) else int(v) for k, v in best_params.items()})# 使用最佳参数训练最终模型
best_xgb = XGBClassifier(n_estimators=int(best_params['n_estimators']),max_depth=int(best_params['max_depth']),learning_rate=best_params['learning_rate'],subsample=best_params['subsample'],colsample_bytree=best_params['colsample_bytree'],scale_pos_weight=class_weights[1],eval_metric='mlogloss',use_label_encoder=False,random_state=42
)
best_xgb.fit(X_train_final, y_train)# 评估模型
y_pred = best_xgb.predict(X_test_final)
print("\n优化后XGBoost分类报告:")
print(classification_report(y_test, y_pred))
accuracy = accuracy_score(y_test, y_pred)
print(f"准确率: {accuracy:.4f}")
# 1. 加载测试集数据
test_data = pd.read_csv("/kaggle/input/titanic/test.csv")
passenger_ids = test_data['PassengerId'] # 保存乘客ID用于最终提交# 2. 完全相同的预处理流程
# 2.1 删除相同列
test_data.drop(['PassengerId', 'Name', 'Ticket', 'Cabin'], axis=1, inplace=True)# 2.2 创建相同新特征
test_data['FamilySize'] = test_data['SibSp'] + test_data['Parch']# 2.3 使用训练集的统计量填充缺失值
test_data['Age'].fillna(age_median_train, inplace=True) # 使用之前保存的训练集中位数
test_data['Fare'].fillna(X_train['Fare'].median(), inplace=True) # 测试集可能有新的缺失值# 2.4 相同特征工程
# 年龄分箱(使用训练集的分箱边界)
test_data['Age_bin'] = pd.cut(test_data['Age'], bins=age_bins, labels=['0','1','2'])# Fare标准化(使用训练集的scaler)
test_data['Fare_scaled'] = fare_scaler.transform(test_data[['Fare']])# 性别编码
test_data['Sex_encoded'] = test_data['Sex'].map(sex_mapping)# Embarked和Pclass独热编码(确保列一致)
test_embarked = pd.get_dummies(test_data['Embarked'], prefix='Embarked').astype(int)
test_pclass = pd.get_dummies(test_data['Pclass'], prefix='Pclass').astype(int)# 补齐可能缺失的列(以训练集为基准)
for col in train_embarked.columns:if col not in test_embarked.columns:test_embarked[col] = 0
for col in train_pclass.columns:if col not in test_pclass.columns:test_pclass[col] = 0# 按训练集的列顺序排序
test_embarked = test_embarked[train_embarked.columns]
test_pclass = test_pclass[train_pclass.columns]# 家庭规模分箱
test_data['FamilySize_bin'] = pd.cut(test_data['FamilySize'], bins=family_bins, labels=['0','1','2','3'])# 2.5 删除原始列
test_data_final = test_data.drop(['Age', 'Sex', 'SibSp', 'Parch', 'FamilySize', 'Embarked', 'Pclass', 'Fare'], axis=1)# 2.6 合并独热编码列
test_data_final = pd.concat([test_data_final, test_embarked, test_pclass], axis=1)# 2.7 确保列顺序与训练集一致
test_data_final = test_data_final[X_train_final.columns]# 2.8 类型转换(与训练集相同)
test_data_final = test_data_final.astype(int)# 3. 使用贝叶斯优化后的模型进行预测
final_predictions = best_xgb.predict(test_data_final)# 4. 生成提交文件
output = pd.DataFrame({'PassengerId': passenger_ids, 'Survived': final_predictions})
output.to_csv('submission.csv', index=False)
print("Your submission was successfully saved!")
print("\n预测结果统计:")
print(output['Survived'].value_counts())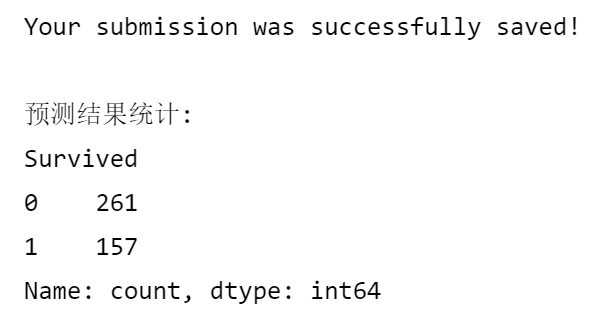
四、参考资料
【机器学习实战】基于python对泰坦尼克幸存者进行数据分析与预测_泰坦尼克号生存预测python-CSDN博客
@浙大疏锦行