【AI论文】LLaDA-V:具备视觉指令微调能力的大型语言扩散模型
摘要:在这项工作中,我们引入了LLaDA-V,这是一种纯粹基于扩散的多模态大语言模型(MLLM),它将视觉指令调整与掩蔽扩散模型相结合,与当前多模态方法中占主导地位的自回归范式有所不同。 基于LLaDA,一个具有代表性的大型语言扩散模型,LLaDA-V包含一个视觉编码器和MLP连接器,可以将视觉特征投影到语言嵌入空间中,从而实现有效的多模态对齐。 我们的实证研究揭示了一些有趣的结果:首先,尽管LLaDA-V的语言模型在纯文本任务上的表现不如LLaMA3-8B和Qwen2-7B等模型,但它展现出了有希望的多模态性能。 当在相同的指令数据上进行训练时,LLaDA-V在多模态任务中与LLaMA3-V相比具有更高的竞争力,并且具有更好的数据可扩展性。 这也缩小了与Qwen2-VL的性能差距,表明其架构在多模态任务中的有效性。 其次,与现有的混合自回归扩散和纯扩散基MLLM相比,LLaDA-V在多模态理解方面达到了最先进的性能。 我们的研究结果表明,大型语言扩散模型在多模态环境中显示出前景,值得在未来的研究中进一步研究。 项目页面和代码:https://ml-gsai.github.io/LLaDA-V-demo/。Huggingface链接:Paper page,论文链接:2505.16933
研究背景和目的
研究背景
随着人工智能技术的飞速发展,多模态大语言模型(Multimodal Large Language Models, MLLMs)已成为自然语言处理和计算机视觉领域的研究热点。MLLMs能够处理包括图像、音频、视频在内的多种输入模态,并结合文本信息生成自然语言响应,从而在多种任务中展现出强大的能力。然而,现有的MLLMs大多依赖于自回归(autoregressive)模型,这些模型在处理序列数据时虽然有效,但也存在一些局限性,如训练和推理速度较慢,以及对长序列的处理能力有限。
与此同时,扩散模型(diffusion models)作为一种新兴的生成模型,在图像生成、语音合成等领域取得了显著成果。扩散模型通过逐步去噪的过程来生成数据,具有训练稳定、生成质量高的优点。特别是离散扩散模型(discrete diffusion models),在语言建模任务中展现出了与自回归模型相媲美的性能,同时保留了扩散模型的独特优势。
在此背景下,将扩散模型应用于多模态大语言模型中,探索非自回归的多模态理解和生成方法,成为了一个具有潜力的研究方向。LLaDA(Large Language Diffusion Model)作为一种具有代表性的大型语言扩散模型,已经在语言建模任务中取得了不错的成绩,但其多模态理解和生成能力尚未得到充分探索。
研究目的
本研究旨在引入LLaDA-V,一个纯粹基于扩散的多模态大语言模型,通过视觉指令调整(visual instruction tuning)将掩蔽扩散模型与视觉编码器相结合,以探索非自回归范式在多模态理解和生成任务中的有效性。具体研究目的包括:
- 验证扩散模型在多模态任务中的潜力:通过构建LLaDA-V模型,验证扩散模型在多模态理解和生成任务中的性能,探讨其相对于传统自回归模型的优势和局限性。
- 提升多模态理解和生成能力:通过视觉指令调整,使LLaDA-V模型能够更好地理解和处理视觉信息,提升其在多模态任务中的表现。
- 探索数据可扩展性:研究LLaDA-V模型在不同规模指令数据上的表现,探讨其数据可扩展性,为未来更大规模数据集上的应用提供参考。
- 推动多模态大语言模型的发展:通过本研究,为多模态大语言模型的研究提供新的思路和方法,推动该领域的进一步发展。
研究方法
模型架构
LLaDA-V模型基于LLaDA构建,LLaDA是一种具有代表性的大型语言扩散模型。LLaDA-V在LLaDA的基础上,引入了视觉编码器和多层感知机(MLP)连接器,用于将视觉特征投影到语言嵌入空间中,实现多模态对齐。具体来说,LLaDA-V包含以下几个关键组件:
- 语言塔(Language Tower):采用LLaDA作为语言塔,负责处理文本输入和生成文本输出。LLaDA通过掩蔽扩散过程进行语言建模,具有训练稳定、生成质量高的优点。
- 视觉塔(Vision Tower):采用SigLIP等视觉编码器,负责将图像输入编码为视觉特征。这些视觉特征随后通过MLP连接器投影到语言嵌入空间中。
- MLP连接器(MLP Connector):用于将视觉特征投影到语言嵌入空间,实现视觉和语言信息的融合。
训练策略
LLaDA-V的训练过程分为三个阶段:
- 语言-图像对齐阶段(Language-Image Alignment Stage):在这个阶段,仅训练MLP连接器,以对齐视觉表示和LLaDA的词嵌入。语言塔和视觉塔保持冻结状态。使用LLaVA-Pretrain数据集进行训练。
- 视觉指令跟随阶段(Visual Instruction Following Stage):在这个阶段,训练整个模型以建立强大的视觉指令跟随能力。使用MAmmoTH-VL数据集中的单图像和多图像/视频数据进行训练。训练过程分为两个子阶段,分别处理单图像和多图像/视频数据。
- 多模态推理增强阶段(Multimodal Reasoning Enhancement Stage):在这个阶段,通过训练LLaDA-V处理来自VisualWebInstruct的推理聚焦多模态数据,增强其多模态推理能力。
推理过程
在推理阶段,LLaDA-V通过迭代响应生成来处理多轮对话。给定一个新的提示,模型利用之前的提示和响应来生成适当的后续响应。每个响应通过掩蔽扩散模型的反向过程生成,而不是自回归模型中的下一步预测。
研究结果
数据可扩展性
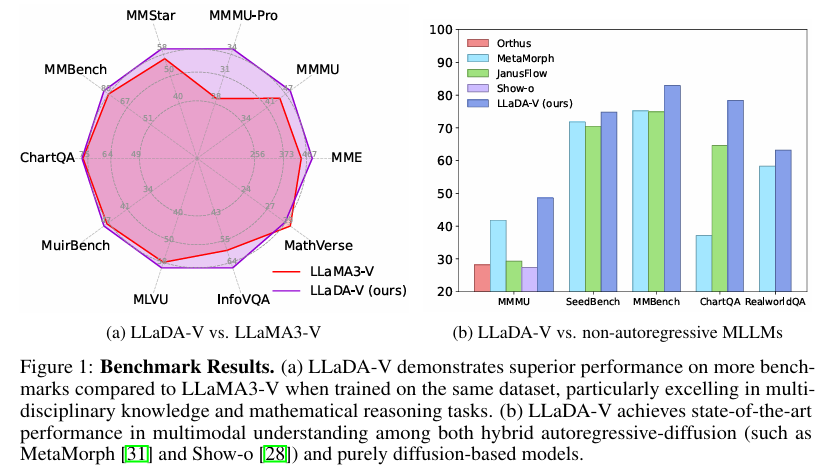
实验结果表明,LLaDA-V在数据可扩展性方面表现出色。与自回归基线模型LLaMA3-V相比,LLaDA-V在多学科知识和数学推理任务上展现出了更强的数据可扩展性。特别是在训练数据量较少的情况下,LLaDA-V仍然能够取得不错的性能。
多模态基准测试
在多模态基准测试中,LLaDA-V在多个任务上取得了显著的性能提升。与现有的混合自回归-扩散和纯扩散基MLLM相比,LLaDA-V在多模态理解方面达到了最先进的性能。特别是在多学科知识、数学推理、多图像和视频理解任务上,LLaDA-V展现出了明显的优势。
消融研究
通过消融研究,验证了LLaDA-V中各个组件的有效性。特别是无掩蔽(no mask)注意力机制在多个基准测试中表现优于对话因果(dialogue causal)注意力机制,表明其能够提供更全面的对话上下文理解。
研究局限
尽管LLaDA-V在多模态理解和生成任务中取得了显著成果,但仍存在一些局限性:
- 语言塔性能限制:LLaDA-V的性能在一定程度上受到其语言塔(LLaDA)性能的限制。由于LLaDA在纯文本任务上的表现不如一些先进的自回归模型(如LLaMA3-8B和Qwen2-7B),这在一定程度上影响了LLaDA-V在多模态任务中的整体性能。
- 高分辨率图像处理:对于高分辨率图像,LLaDA-V采用分割和调整大小的方式处理图像段,然后通过SigLIP2视觉塔处理并连接特征。这种方法可能降低视觉表示的效率和准确性。未来需要开发更先进的图像处理策略来提高性能。
- 幻觉问题:与许多先进的多模态大语言模型一样,LLaDA-V也可能生成幻觉内容,即事实不正确或输入中不存在的信息。尽管通过扩展数据和开发更先进的对齐技术可能有助于缓解这一问题,但幻觉仍然是多模态生成模型面临的一个挑战。
未来研究方向
针对LLaDA-V的局限性和潜在发展方向,未来研究可以关注以下几个方面:
- 提升语言塔性能:探索更先进的语言扩散模型或结合其他语言建模技术,以提升LLaDA-V的语言塔性能,从而进一步提高其在多模态任务中的整体表现。
- 优化图像处理策略:开发更先进的图像处理策略,以更高效、准确地处理高分辨率图像,提高LLaDA-V在视觉理解和生成任务中的性能。
- 减少幻觉生成:研究减少多模态生成模型中幻觉生成的方法,如通过引入更严格的验证机制、结合外部知识库或开发更先进的对齐技术等。
- 探索更多应用场景:将LLaDA-V应用于更多实际场景中,如智能客服、教育辅助、内容创作等,以验证其在实际应用中的有效性和实用性。
- 结合其他技术:探索将LLaDA-V与其他先进技术(如强化学习、知识图谱等)相结合的可能性,以进一步提升其多模态理解和生成能力。