【大模型应用开发】Qwen2.5-VL-3B识别视频
0. 编写代码并尝试运行
克隆以下代码
git clone https://gitee.com/ai-trailblazer/qwen-vl-hello.git尝试运行qwen-vl-hello.py,报错原因缺少modelscope:

1. 安装qwen-vl-utils工具包
pip install qwen-vl-utils[decord]==0.0.8
尝试运行,不出意外的话肯定运行不了,报错原因依然是缺少modelscope:
2. 安装modelscope
pip install modelscope -i https://pypi.tuna.tsinghua.edu.cn/simple再次尝试运行,依然无法运行,报错原因modelscope下未找到Qwen2_5_VLForConditionalGeneration:

3.安装transformers
pip install git+https://github.com/huggingface/transformers accelerate
经历10分钟的漫长等待,终于下载安装完成。再次尝试运行,依然运行失败,报错原因缺少torchvision模块:

4.安装torchvision
pip install torchvision
5.尝试进行视频识别(失败)
再次尝试运行,事情出现转机,开始下载模型,并进行漫长的等待(在等待过程中,顺手去清理一些爆红的C盘!)
经历九九八十一分钟后,发生了意外(我没有碰它呀)

再次尝试运行,执行失败,报错原因是TypeError: process_vision_info() got an unexpected keyword argument 'return_video_kwargs':
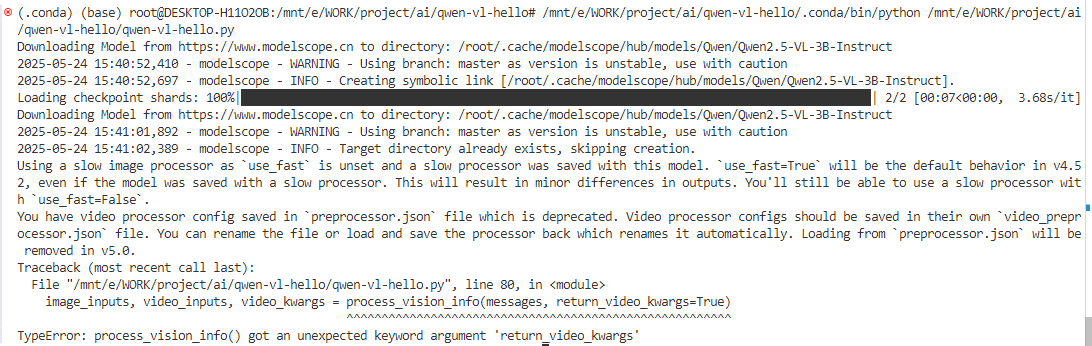
下面先进行图片识别,排查一下是否是环境问题。
6. 尝试图片识别(成功)
先运行图片识别的代码(qwen-vl-img-hello.py)吧,没想到又发生更大意外惊喜,wsl系统连不上了!
Reload Window后,重新连接了
再次运行,图片识别成功。
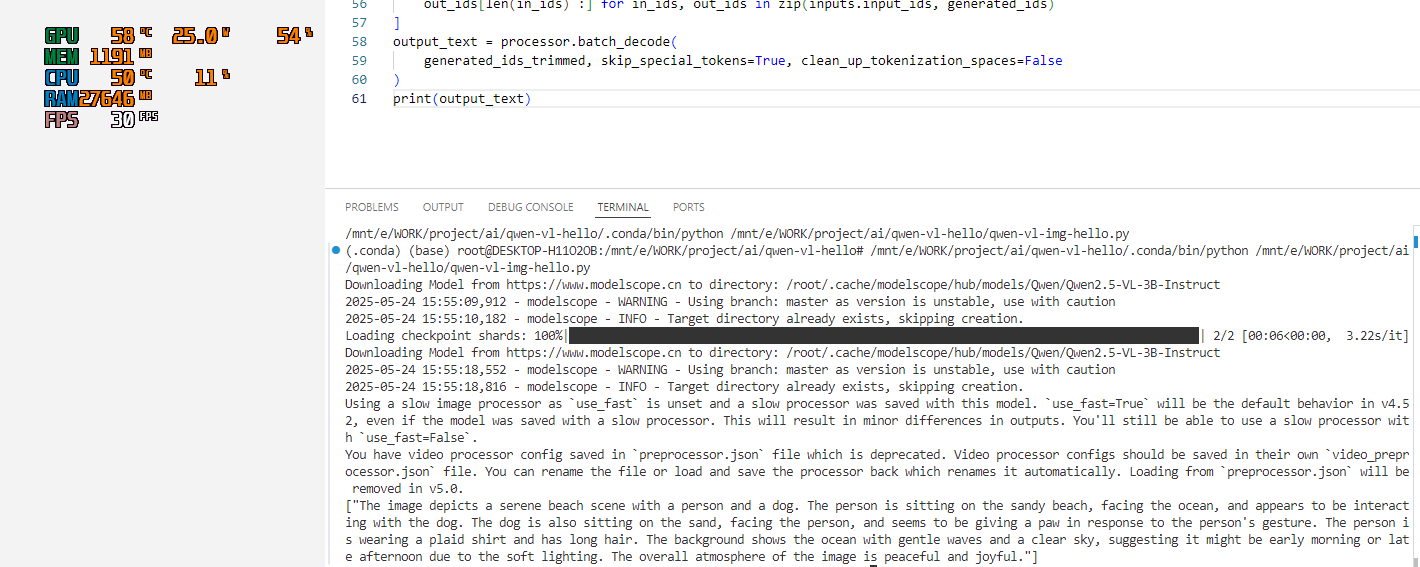

图片识别成功,初步假设运行环境已经没有问题了,下面再次尝试视频识别。
7.尝试进行视频识别(失败)
依然是第5节的执行失败原因:
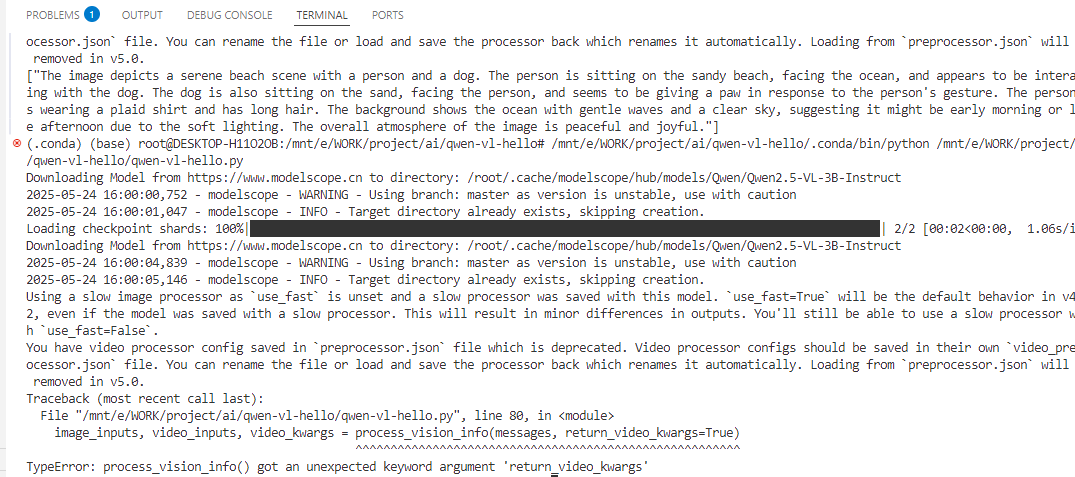
检查代码问题。先删除当前不必要的代码
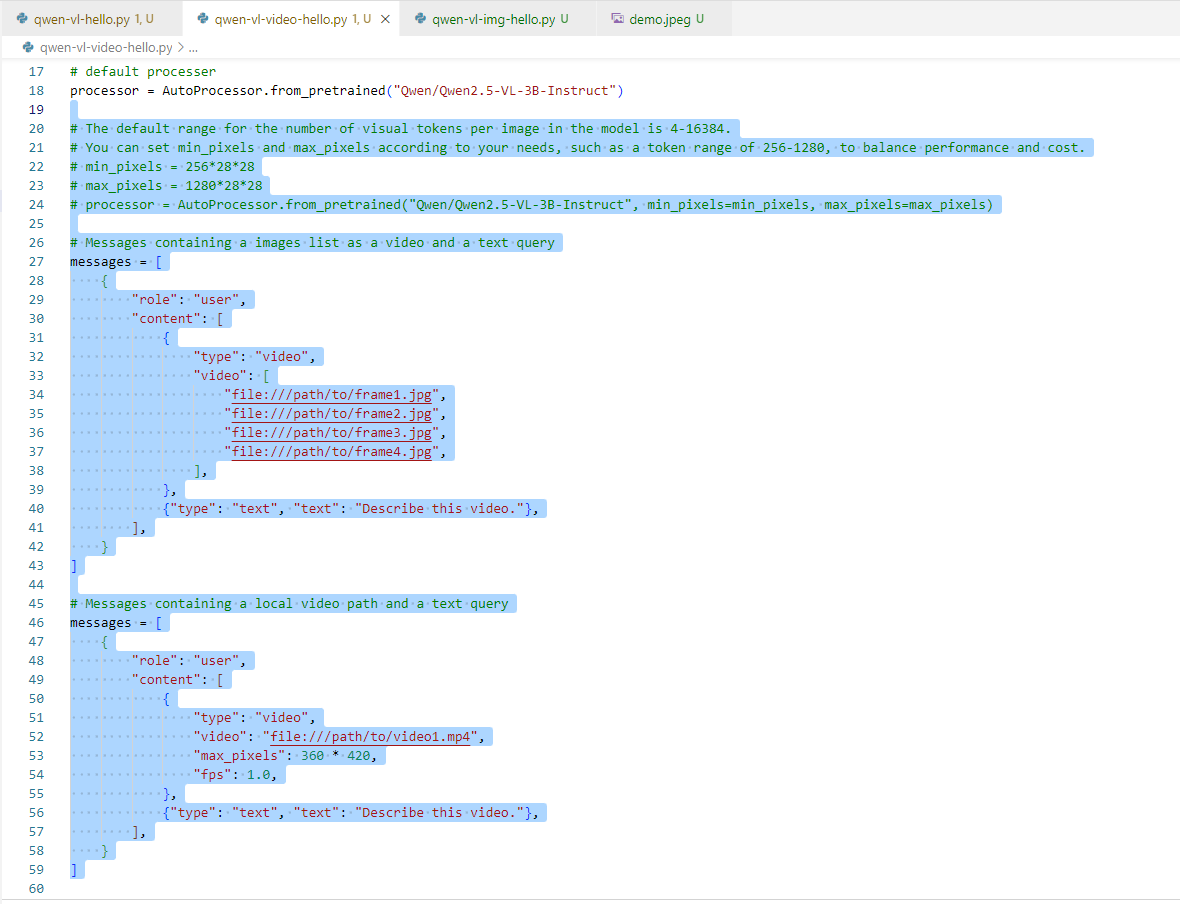
然后脑袋总算是要清醒一点了,即这一行代码就是设置一个意料之外的参数return_video_kwargs。
image_inputs, video_inputs, video_kwargs = process_vision_info(messages, return_video_kwargs=True)
inputs = processor(text=[text],images=image_inputs,videos=video_inputs,fps=fps,padding=True,return_tensors="pt",**video_kwargs,
)
inputs = inputs.to("cuda")继续思考解决方案:后面又要使用到这个video_kwargs,如果不配置它会不会无法返回这个参数......,管它呢,先删除return_video_kwargs=True,反正电脑又不会炸掉!(继续Run Python,并战术性的喝了一口水)。
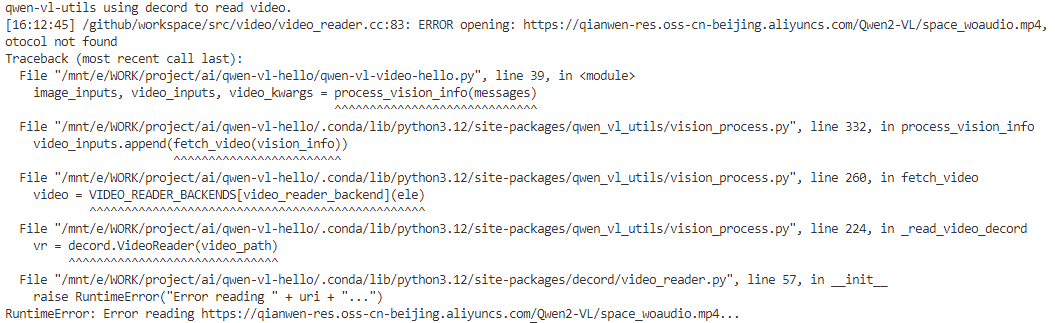
嗯哼,报错了:Error reading?难道是视频链接失效了,复制到浏览器查看没问题呀,视频链接是有效的。
https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2-VL/space_woaudio.mp4下面将继续排查,瞅一眼qwen-vl-utils的版本为0.0.8,没错儿呀,是文档里的版本咧。
![]()
看看源码,这个函数返回了None,但是这个函数的源码又看不到!暂且不继续了看源码了,换个方向再试试。
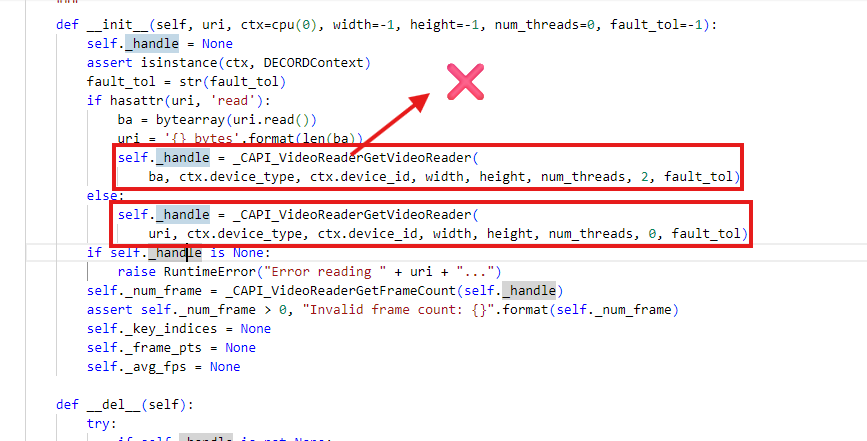
继续排查,尝试识别本地视频。(再喝一口水缓解一下压力)
messages = [{"role": "user","content": [{"type": "video","video": "file:///mnt/e/WORK/project/ai/qwen-vl-hello/demo.mp4",},{"type": "text", "text": "Describe this video."},],}
]wsl又无法连接了!
再次连接后,再次尝试运行,虽然报错了,但是至少视频是能读取了,报错只是说明video_kwargs这个不能用了。
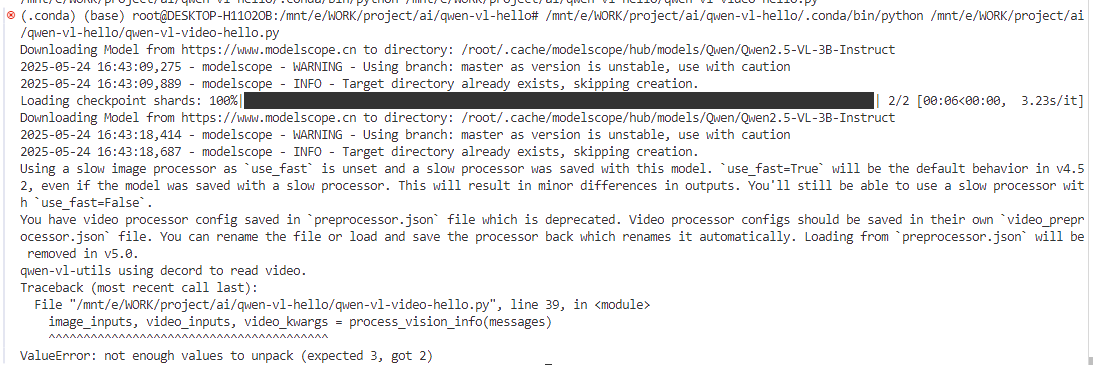
修改代码再次尝试运行,wsl又断连接了
直接在命令行执行
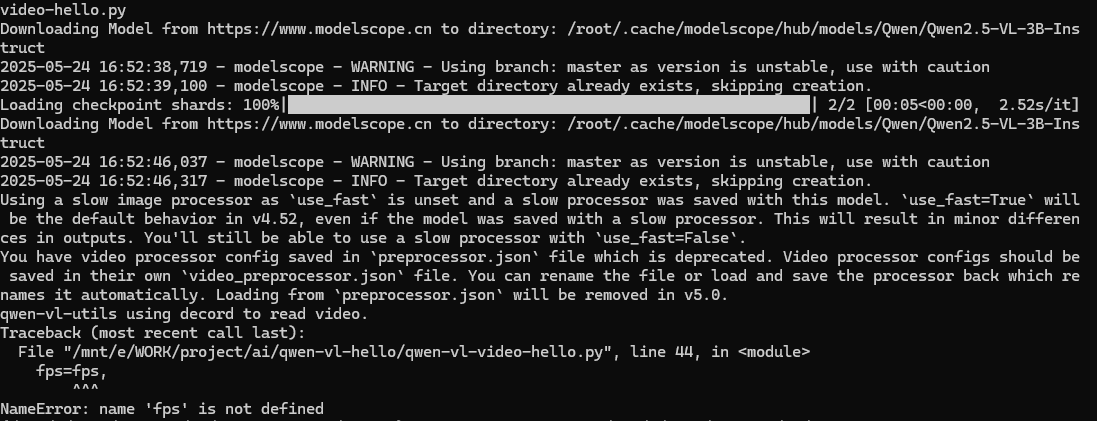
运行失败,报错原因fps未定义(这官方教程存在问题哦,艾特一下qwen官方)。修改代码,删除fps=fps。修改后再次运行
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(text=[text],images=image_inputs,videos=video_inputs,padding=True,return_tensors="pt"
)
inputs = inputs.to("cuda")显存溢出!我不服,再次尝试还是显存溢出,我服了。
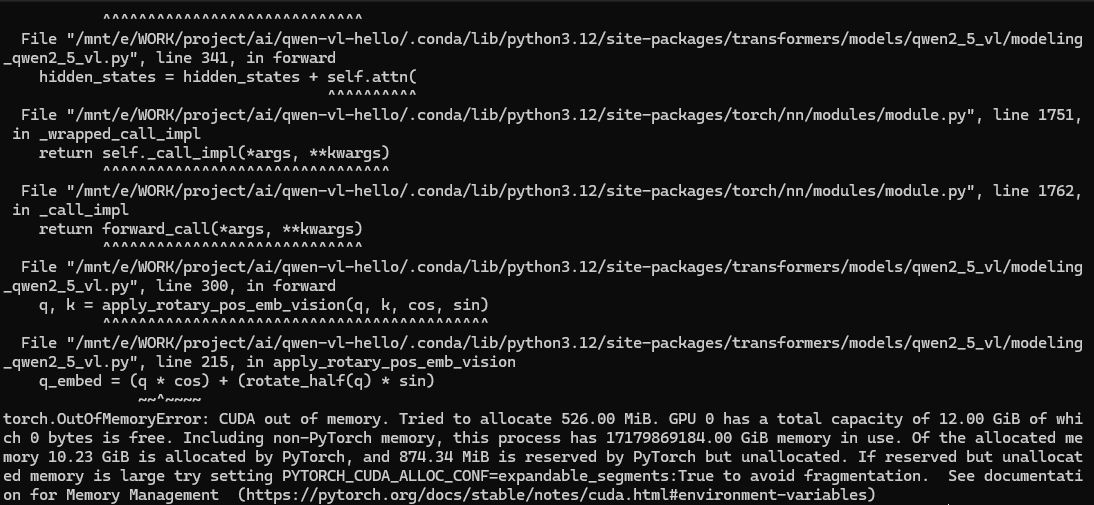
继续尝试量化模型Qwen/Qwen2.5-VL-3B-Instruct-AWQ
# 第一处修改
model = Qwen2_5_VLForConditionalGeneration.from_pretrained("Qwen/Qwen2.5-VL-3B-Instruct-AWQ", torch_dtype="auto", device_map="auto"
)# 第二处修改
processor = AutoProcessor.from_pretrained("Qwen/Qwen2.5-VL-3B-Instruct-AWQ")继续运行,开始下载模型,然后继续漫长的等待(顺便打开音乐播放器,放一首DJ串烧缓解一下情绪)
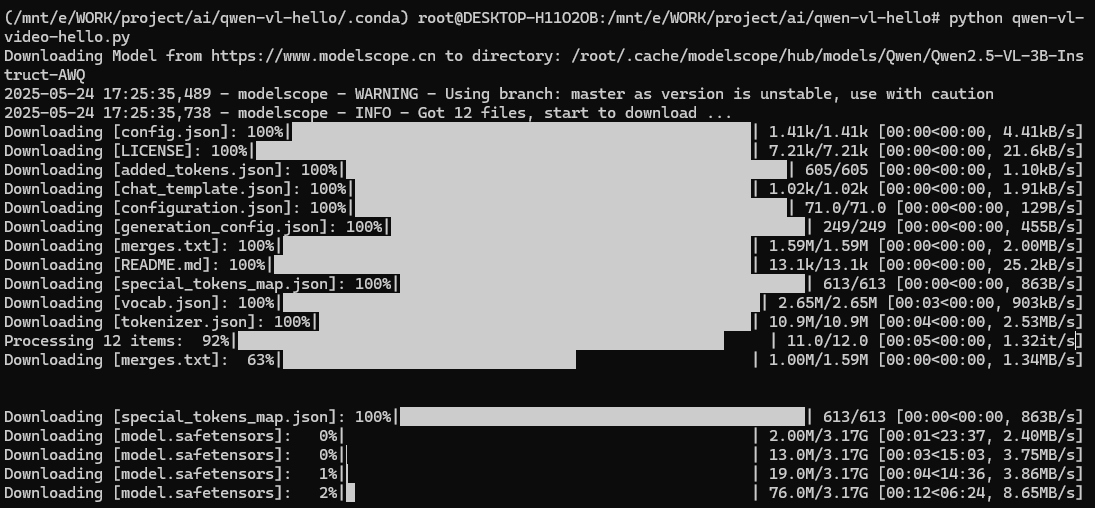
经过九九八十一天的等待后,模型下载完了,但是紧接着又报了一个错,报错意思是`autoawq`的版本太低。
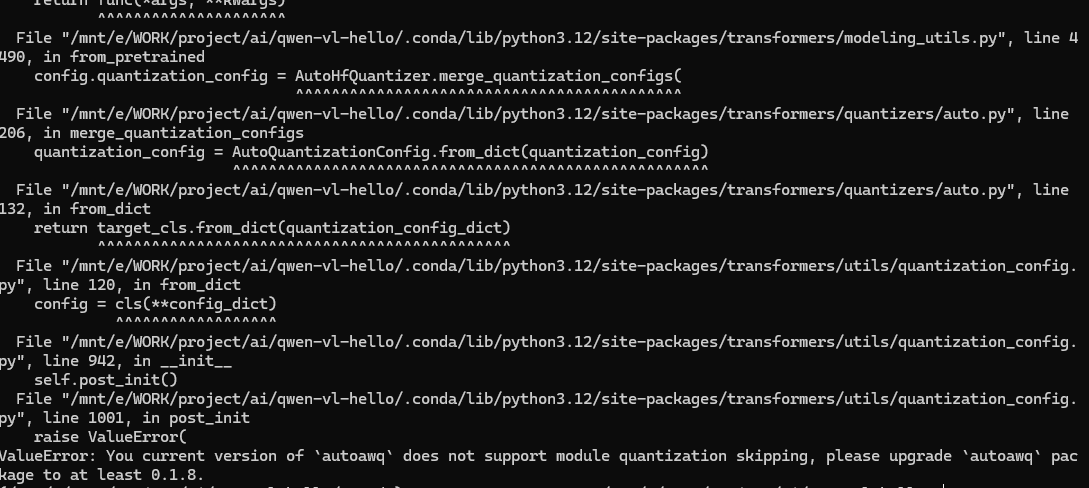
先不急,再运行一次看看,报错依然如此。通过pip list|grep autoawq发现并没有安装autoawq,那就尝试用pip安装一个autoawq
pip install autoawq
继续尝试运行,显存溢出!
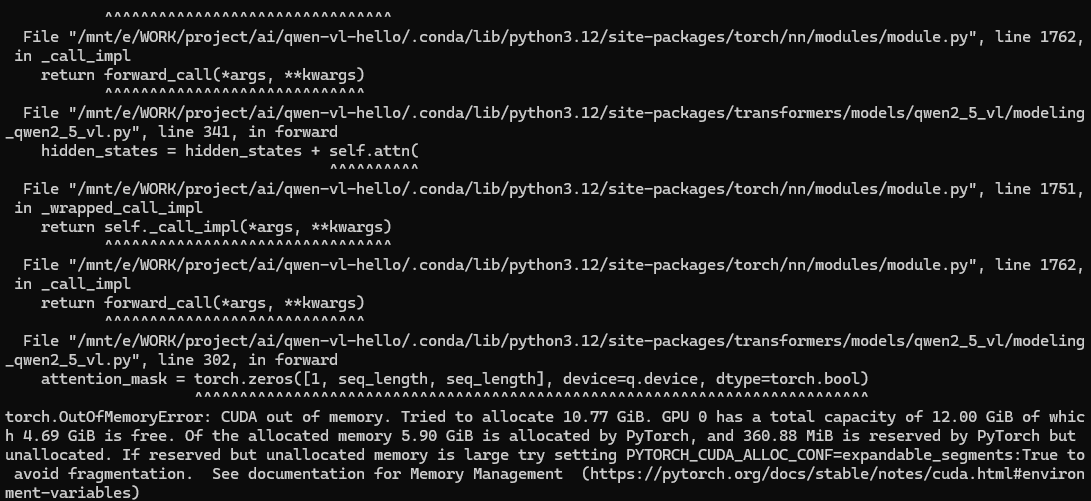
但是,细心的我发现这样一行输出,于是我虚心的请教了Deepseek
Unused or unrecognized kwargs: return_tensors, fps.
修改代码
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(text=[text],images=image_inputs,videos=video_inputs,fps=30,padding=True,return_tensors="pt"
)
inputs = inputs.to("cuda")仍然报错显存溢出!但是这个输出内容有点奇怪,区别如下(虚心的我又去查了一下这个单词的意思unrecognized-无法识别的,也就是说:这两个参数没有意义加和不加都一样!):
# 不添加fps参数
Unused or unrecognized kwargs: return_tensors, fps.# 添加fps=30后
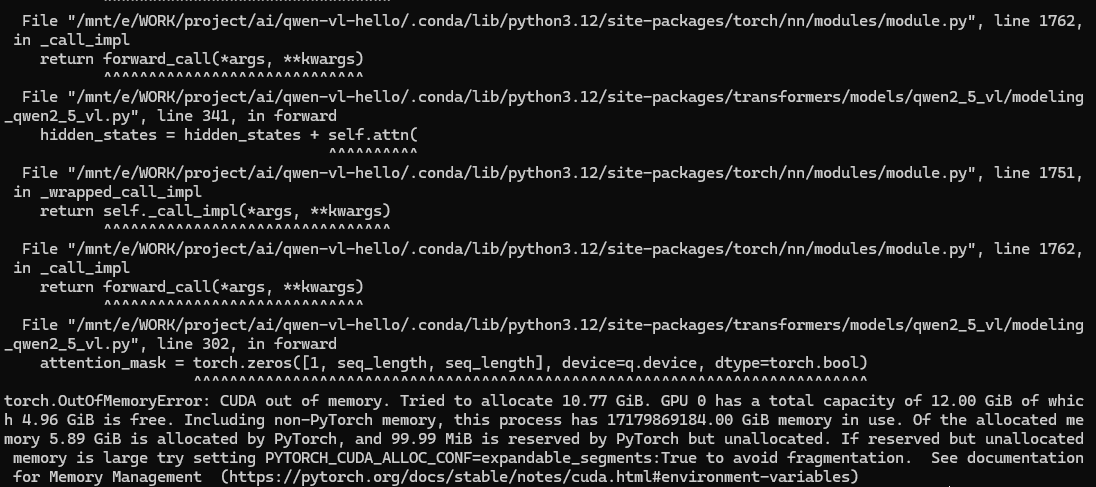
Unused or unrecognized kwargs: fps, return_tensors.有进行了多次尝试,添加PYTORCH_CUDA_ALLOC_CONF环境变量、指定torch_dtype,都以显存溢出为结局
from modelscope import Qwen2_5_VLForConditionalGeneration, AutoTokenizer, AutoProcessor
from qwen_vl_utils import process_vision_info
import torchimport os
os.environ["PYTORCH_CUDA_ALLOC_CONF"] = "expandable_segments:True"# default: Load the model on the available device(s)
model = Qwen2_5_VLForConditionalGeneration.from_pretrained("Qwen/Qwen2.5-VL-3B-Instruct-AWQ", torch_dtype=torch.float16, device_map="auto"
)
于是,我不得不承认本地的GPU显存确实有限,下面我改变策略,在云服务进行尝试。
8.借用云服务器进行视频识别(失败)
在魔塔选择赠送的GPU服务器使用时长,点击启动并稍等2分钟左右
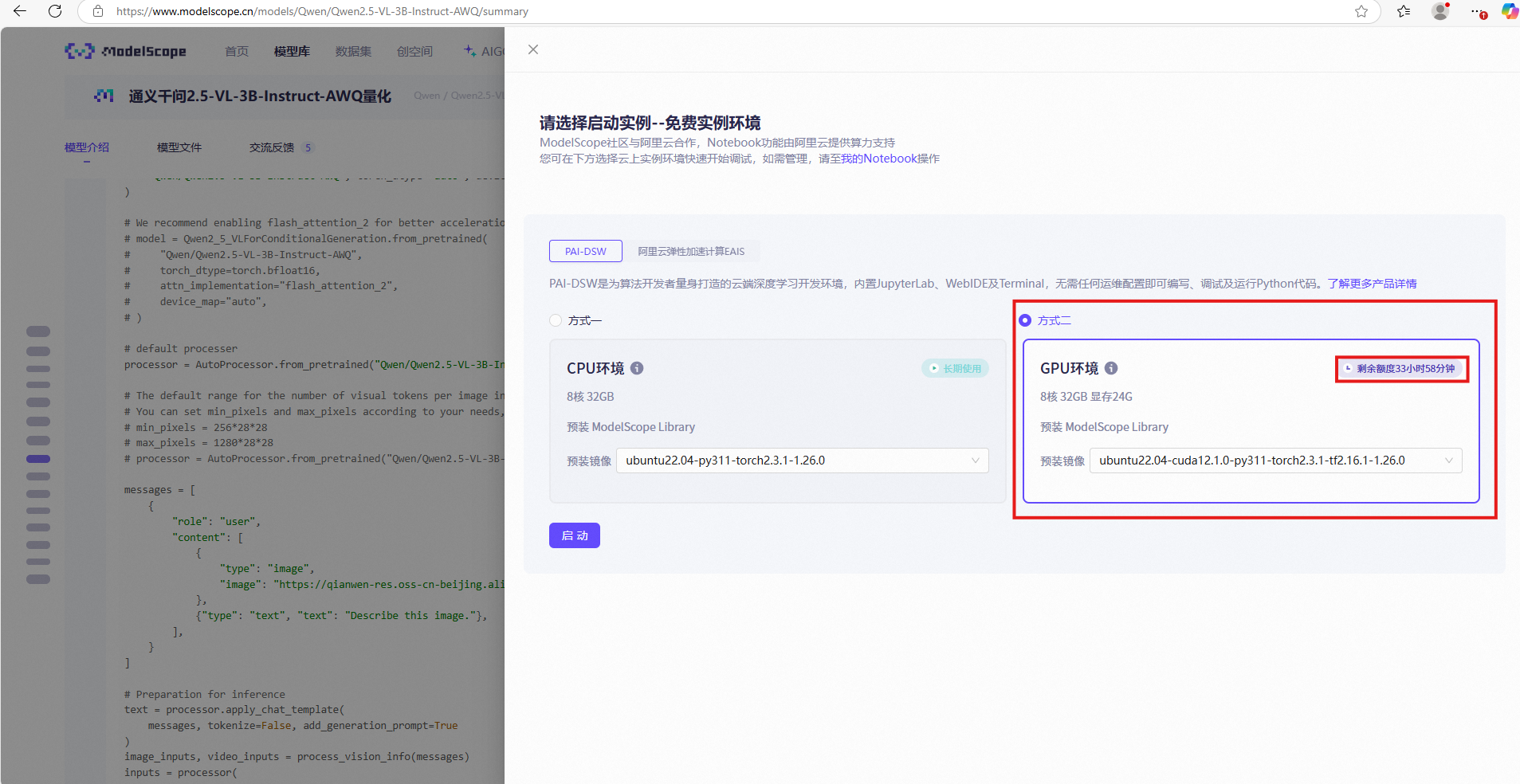
克隆代码仓库
https://gitee.com/ai-trailblazer/qwen-vl-hello.git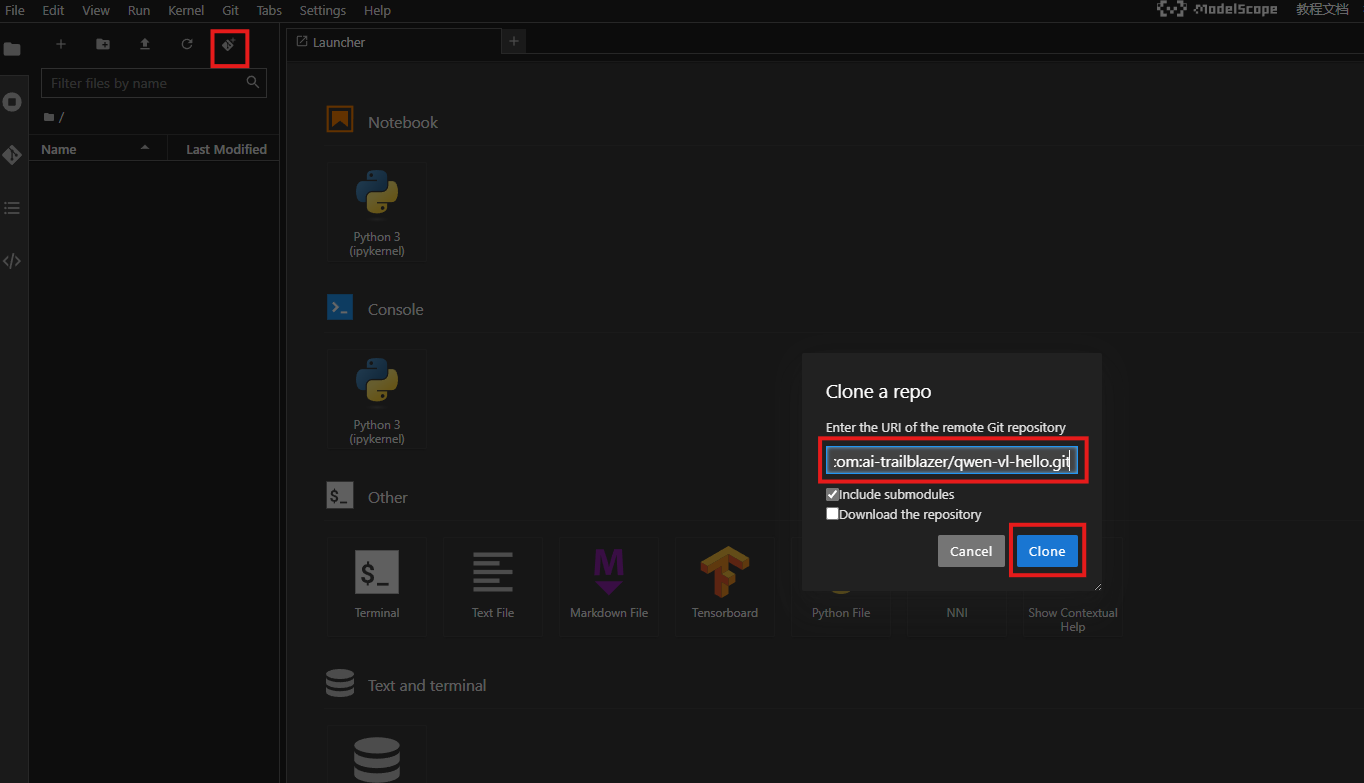
代码拉取完成后,继续查看conda版本和显存。
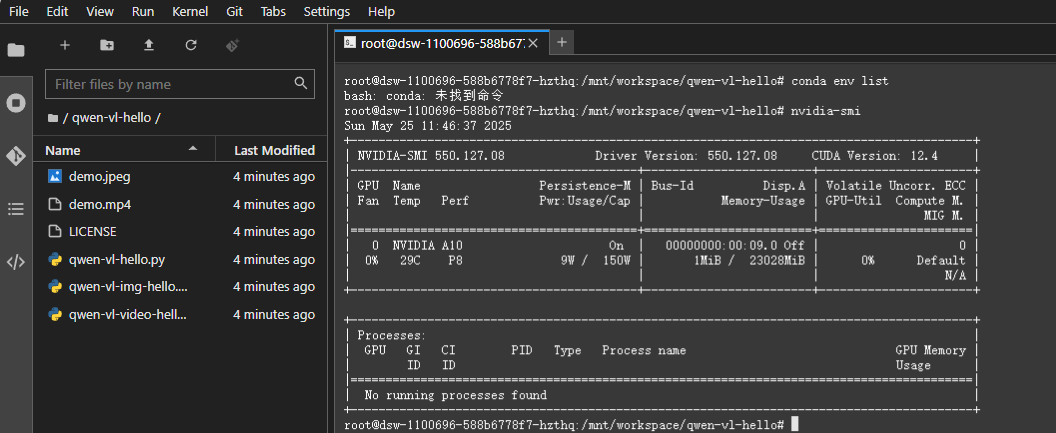
发现没有conda,那就先在常规python环境尝试。
pip install qwen-vl-utils[decord]==0.0.8
pip install modelscope -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install git+https://github.com/huggingface/transformers accelerate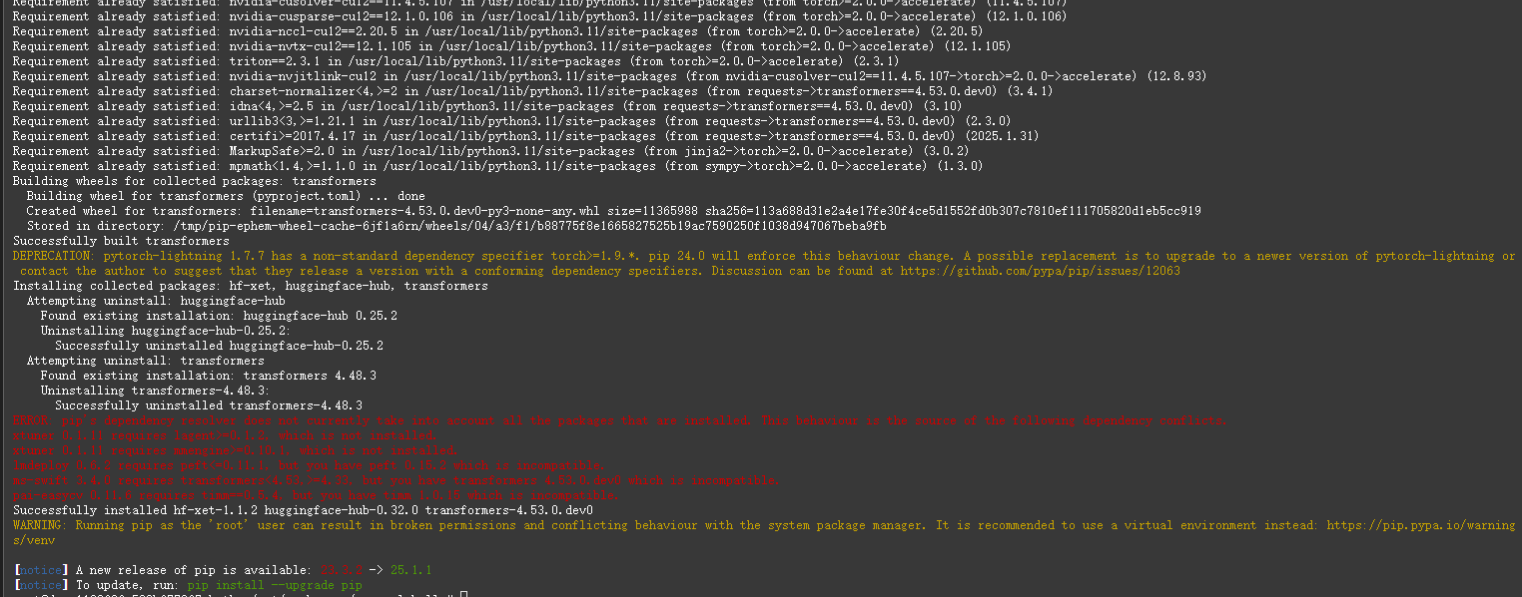
安装transformers报错了,暂且不管,先运行代码
python qwen-vl-video-hello.py第一行运行报错,找不到Qwen2_5_VLForConditionalGeneration

此时回忆一下在本地的经验,安装transformers可是花费了十分钟之久,并且下载了很多内容,但是此时马上下载完毕并且还报错了,仔细分析错误原因,发现是很多python三方库版本不兼容的问题。所以后面还是启动一个conda环境吧
【AI训练环境搭建】在Windows11上搭建WSL2+Ubuntu22.04+Tensorflow+GPU机器学习训练环境
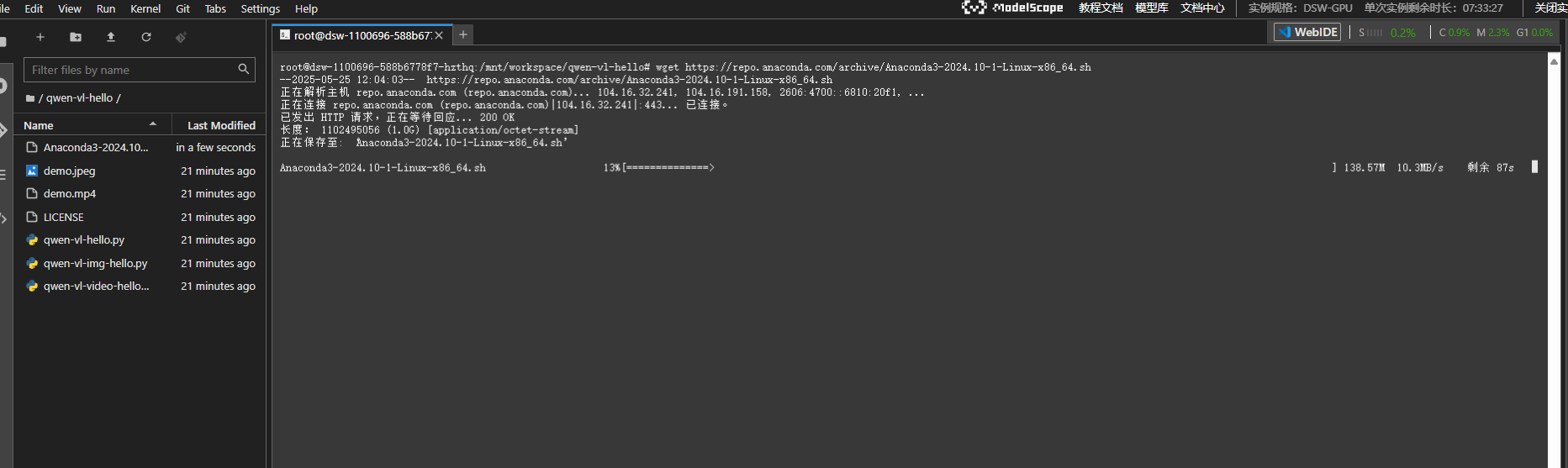
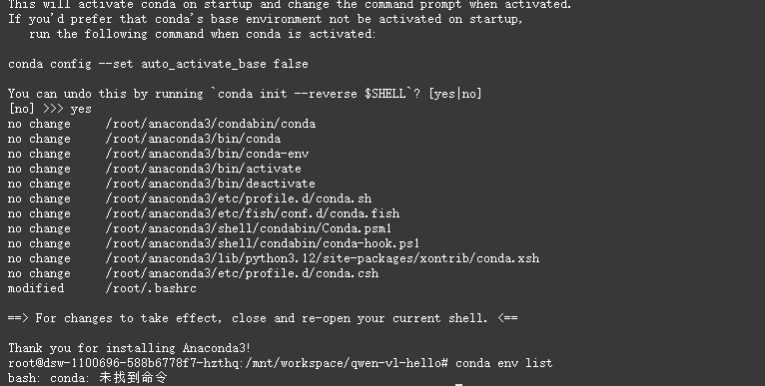
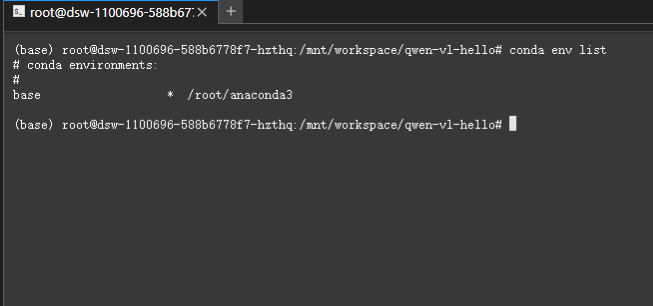
创建新的conda环境,名称为vlenv
conda create -n vlenv python=3.12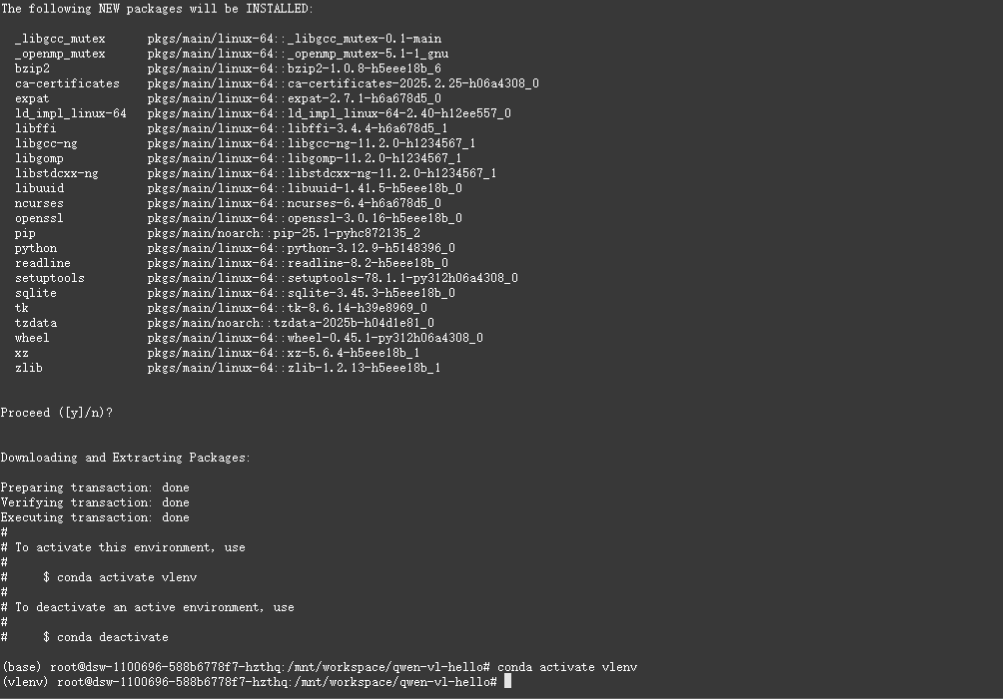
安装依赖
pip install qwen-vl-utils[decord]==0.0.8
pip install modelscope
pip install git+https://github.com/huggingface/transformers accelerate安装transformers报错了
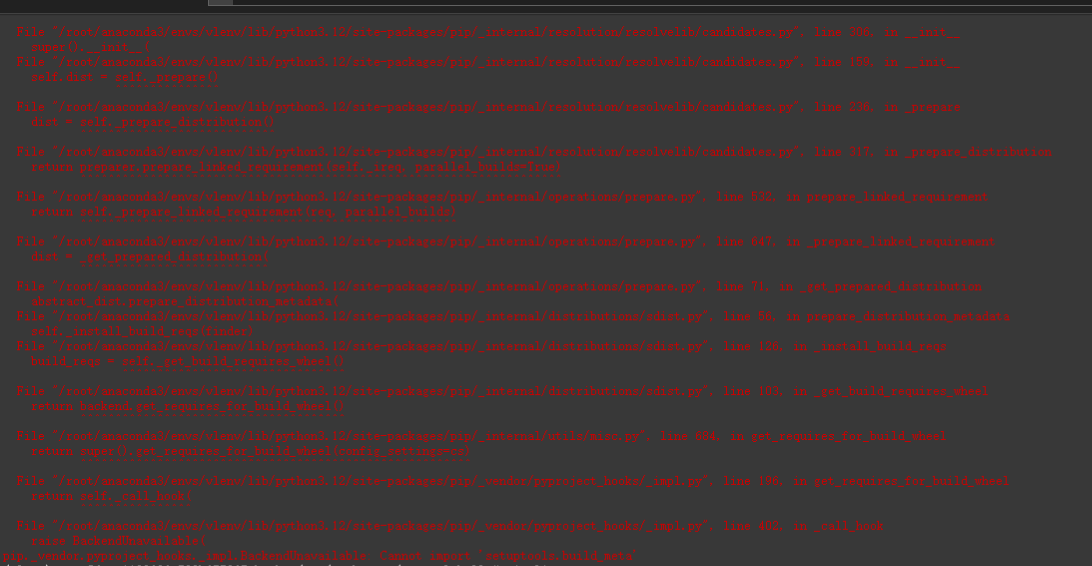
重新创建一个3.11 python版本的conda环境,名称为t1
conda create -n t1 python=3.11
尝试安装
pip install qwen-vl-utils[decord]==0.0.8
pip install modelscope -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install git+https://github.com/huggingface/transformers accelerate这次看起来能正常安装了
安装完成
尝试运行,报出熟悉的异常

安装torchvision
pip install torchvision
再次尝试运行
python qwen-vl-video-hello.py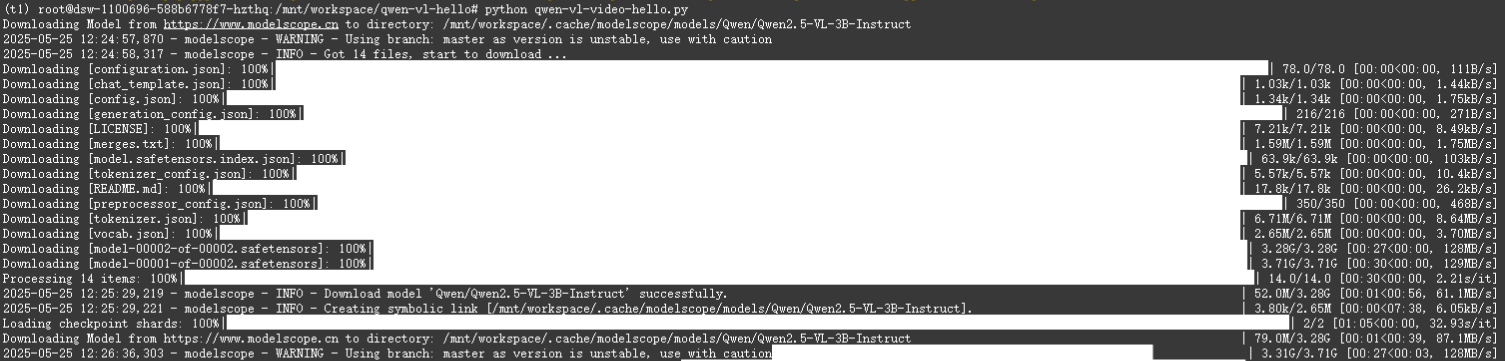
依然报显存溢出(这可是20多个G的显存哦)
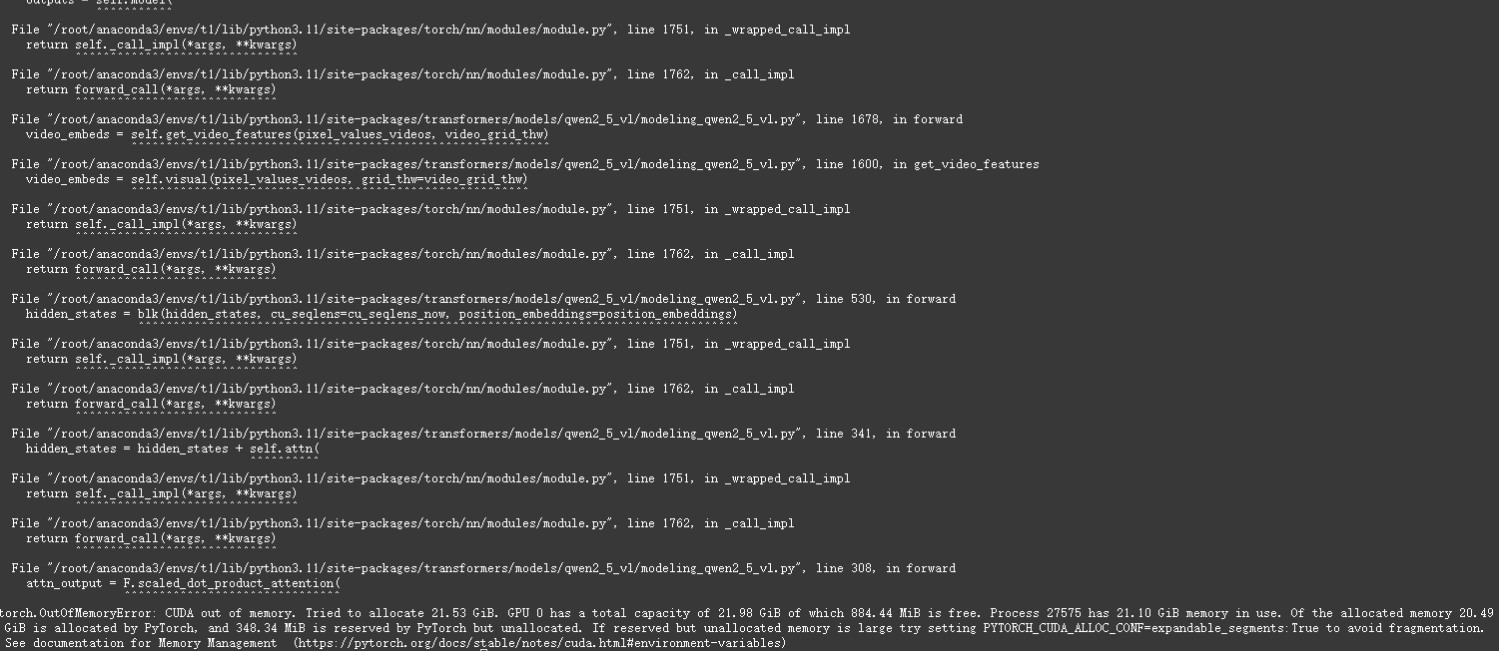
(本次实践从本地到云服务,共花费7个多小时光阴,虽然目前没有运行成功,但是至少在这过程中实践了很多经验,后续我将尝试找一个比较小的视频再次验证。)
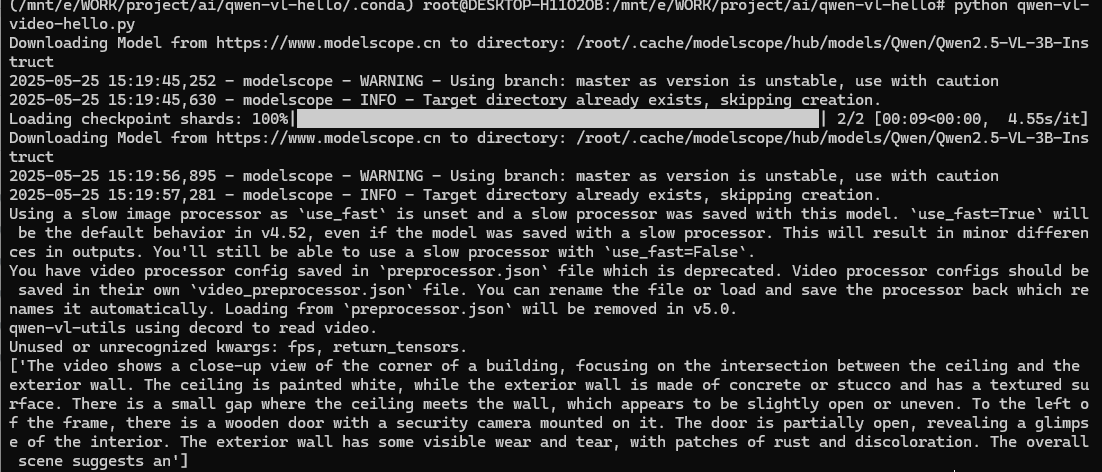
9.使用一个较小的视频进行识别(成功)
在以上实践中,使用的是一个21M的视频,视频时长约三分钟。而后我又拿了一个只有291KB的视频,视频时长只有1s。
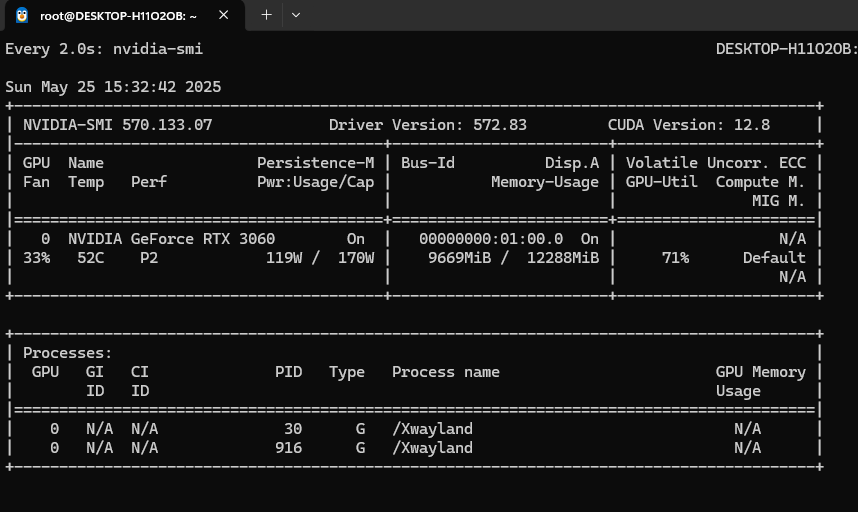
功夫不负有心人,终于成功识别了一个视频!尽管这个视频只有1s,可以看到GPU也占用了9G(该显卡总共只有12G)。
10. 总结和展望
在本次实践中,主要采用transformers拉起Qwen2.5-VL-3B大模型进行视频识别,尽管这并不是工程化的运行方式,但是有作为入门实践的价值。
在整个过程中,总结出以下经验:
(1)鉴于网络原因,最好使用modelscope来下载模型;
(2)在vscode中使用wsl的conda环境,可能会出现无响应的情况,此时直接使用cmd命令行可能更加方便;
(3)当一条路走不通时,可以换一条路,如果换一条路还是走不通,这时在回头看方法是否有问题,很多时候就是在你回头思考的过程中解决掉问题的,但是你还是得感谢你在另一条路上探索,因为你至少知道了那条路行不通,否则你的思维陷入到不确定中;
(4)云服务器的网络和硬件优势可以加速我们进行AI方面的实践,本次实践中在云服务器上花费的实践仅仅只占总时长的30%,但是产生的效果却很显著,在这里也非常感谢modelscope社区和阿X云为我们提供的免费实例环境,非常感谢;
(5)conda是个好东西,其提供的强大的隔离式python环境,在解决各种依赖库版本库问题的时候非常有用,本次实践中,在云服务器最终使用的是python3.11版本,而我本地电脑是使用的python3.12,这些经验在工程成产过程中也很有价值;
后续的实际计划和展望:
(1)达到这个目标“Qwen2.5-VL 可以理解超过1小时的视频”,所需要的条件和方式有哪些?
(2)考虑更加工程化和轻量化的通过Qwen2.5-VL进行视频识别的方案;
(3)其它模型或方案进行视频识别的使用资源和效果对比;