SymAgent:一种用于知识图谱复杂推理的神经符号自学Agent框架
目录
摘要
Abstract
1 引言
2 相关工作
2.1 知识图谱上的复杂推理
2.2 基于大型语言模型的智能体
3 预备知识
3.1 符号规则
3.2 任务公式化
4 SymAgent
4.1 Agent-Planner
4.2 Agent-Executor
4.2.1 行动空间
4.2.2 交互过程
4.3 自学习
4.3.1 在线探索
4.3.2 离线迭代策略更新
5 实验设计
5.1 实验设置
5.2 性能比较
5.3 消融实验
5.4 对自学习框架的分析
5.4.1 迭代次数
5.4.2 自优化与启发式合并的作用
5.4.3 蒸馏轨迹与自合成轨迹
5.5 提取三元组的质量
5.6 错误类型分析
总结
摘要
本周阅读的论文题目是《SymAgent: A Neural-Symbolic Self-Learning Agent Framework for Complex Reasoning over Knowledge Graphs》(《SymAgent:一种用于知识图谱复杂推理的神经符号自学Agent框架》)。在解决复杂推理问题时,大型语言模型容易产生幻觉,导致结果错误。为了解决这个问题,研究人员将知识图谱引入其中,以提高大语言模型的推理能力。然而,现有方法存在两个局限性:1)它们通常假设所有问题的答案都包含在知识图谱中,忽视了知识图谱的不完整性问题;2)它们将知识图谱视为一个静态的存储库,忽略了知识图谱中固有的隐式逻辑推理结构。在本文中,提出了一个创新的神经符号代理框架SymAgent,实现了知识图谱和大语言模型之间的协同增强。将大语言模型概念化为动态环境,并将复杂的推理任务转化为多步交互过程,使知识图谱能够深度参与推理过程。SymAgent由两个模块组成:Agent-Planner 和 Agent-Executor。Agent-Planner利用大语言模型的归纳推理能力从知识图谱中提取符号规则,指导高效的问题分解。 Agent-Executor自主调用预定义的动作工具,以整合知识图谱和外部文档中的信息,解决知识图谱不完整的问题。此外,设计了一个自学习框架,包含在线探索和离线迭代策略更新阶段,使代理能够自动合成推理轨迹并提升性能。实验结果表明,具有弱大语言模型主干(即 7B 系列)的SymAgent与各种强基线相比,性能更优或相当。进一步分析表明,SymAgent可以识别缺失的三元组,从而促进知识图谱的自动更新。
Abstract
This week's paper is titled "SymAgent: A Neural-Symbolic Self-Learning Agent Framework for Complex Reasoning over Knowledge Graphs." When solving complex inference problems, large language models are prone to hallucinations, leading to wrong results. To solve this problem, researchers introduced knowledge graphs into it to improve the reasoning ability of large language models. However, existing methods have two limitations: 1) they usually assume that the answers to all questions are contained in the knowledge graph, ignoring the incompleteness of the knowledge graph; 2) They treat the knowledge graph as a static repository and ignore the implicit logical reasoning structure inherent in the knowledge graph. In this paper, an innovative neural symbolic agent framework SymAgent is proposed, which realizes the collaborative enhancement between knowledge graph and large language model. Conceptualize large language models as dynamic environments and transform complex inference tasks into multi-step interactive processes, enabling knowledge graphs to be deeply involved in the inference process. SymAgent consists of two modules: Agent-Planner and Agent-Executor. Agent-Planner uses the inductive reasoning ability of large language models to extract symbolic rules from the knowledge graph to guide efficient problem decomposition. Agent-Executor autonomously invokes predefined action tools to integrate information from the knowledge graph and external documents to solve the problem of incomplete knowledge graph. In addition, a self-learning framework is designed, which includes online exploration and offline iterative policy update phases, so that the agent can automatically synthesize inference trajectories and improve performance. Experimental results show that SymAgent with weak large language model backbone (i.e., 7B series) has better or comparable performance than various strong baselines. Further analysis shows that SymAgent can identify the missing triples, thereby promoting the automatic update of the knowledge graph.
1 引言
知识图谱 (KG) 以图结构格式存储大量事实三元组,为各种语义网技术提供关键支持信息。近年来,大型语言模型 (LLM) 在语言理解和跨不同领域的信息整合方面展现出令人印象深刻的性能。然而,它们受限于缺乏精确知识,且在响应中容易产生幻觉。考虑到知识图谱封装了数据互联的本质,提供明确且可解释的知识,将LLM和KG进行整合已引起广泛关注。这种整合促进了各种基于网络的应用,包括搜索引擎推荐、假新闻检测和社交网络。
现有工作主要采用检索增强或语义解析方法来提升LLM在KG数据上的复杂推理性能。前者方法依赖向量嵌入来检索和序列化相关子图作为LLM的输入提示,而后者则利用LLM在知识图谱上执行结构化搜索(例如SPARQL)以获取答案。尽管这些方法取得了成功,但它们都存在显著局限性。首先,它们将知识图谱仅仅视为静态知识库,忽略了知识图谱符号结构中嵌入的内在推理模式。这些模式能够显著帮助LLM分解复杂问题并使语义这些模式能够显著帮助LLM分解复杂问题并调整自然语言问题和KG元素之间的语义粒度。
如下图所示,对于问题“《我要喝醉了扮演汉克·威廉姆斯》这首歌的演唱者出生在哪里?”,SymAgent由一个规划器和执行器组成,配备了动作工具库,能够自主与知识图谱环境交互进行推理,SymAgent从知识图谱中推导出的符号规则𝑓𝑒𝑎𝑡𝑢𝑟𝑒𝑑_𝑎𝑟𝑡𝑖𝑠𝑡 .𝑟𝑒𝑐𝑜𝑟𝑑𝑖𝑛𝑔𝑠 (𝑒, 𝑒)∧𝑝𝑒𝑟𝑠𝑜𝑛.𝑝𝑙𝑎𝑐𝑒 _𝑜𝑓 _𝑏𝑖𝑟𝑡ℎ(𝑒, 𝑒)作为问题的抽象表示,揭示了问题分解与知识图谱结构模式之间的内在联系。相比之下,基于检索的方法常常受到表面关联的影响,检索语义相似但无关的信息,甚至产生有害的干扰,导致模型性能下降。此外,这两种方法通常假设每个问题所需的所有事实三元组都完全由知识图谱覆盖,这对于人工构建的知识图谱来说是不现实的。当知识图谱无法覆盖必要信息时,基于解析的方法难以有效执行SPARQL查询,限制了它们提供准确答案或参与复杂推理任务的能力。
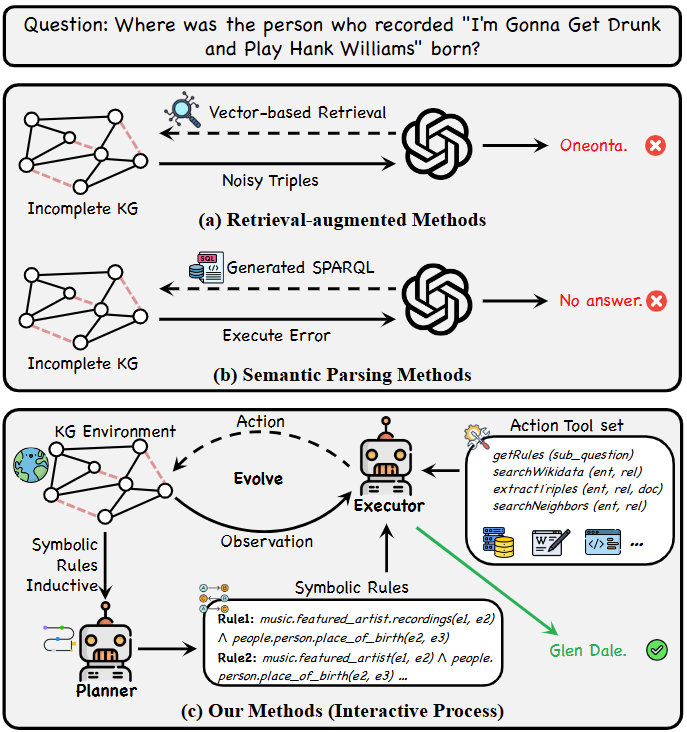
鉴于这些局限性,本文深入探索了KG和LLM的有效融合,使其在复杂推理任务中协同增强。从根本上说,实现这种集成面临着几个重大挑战:
- 语义鸿沟。为了让知识图谱深度参与大型语言模型的推理过程,需要将知识图谱的符号结构与大型语言模型的神经表示进行对齐;
- 知识图谱的不完整性。当遇到信息不足时,在推理过程中需要检索相关的非结构化文档,并在知识图谱的语义粒度一致性下识别缺失的三元组;
- 有限监督学习。任务的复杂性和目前仅限于自然语言输入输出对的限制,使得难以充分发挥 LLMs 的推理潜力。
为应对这些挑战,本文中提出了SymAgent,这是一个旨在自主且有效地整合LLM和KG能力的新型框架。通过将KG视为一个动态环境,将复杂的推理任务转化为多步骤的交互过程,从而实现对复杂问题的深入分析和合理分解。具体而言,SymAgent包含两个关键组件:一个规划模块和一个执行模块:
- 规划模块利用LLM的归纳推理从KG中推导出符号规则,为将自然语言问题与KG结构对齐并作为导航工具创建高级计划。
- 在执行模块中,通过构建一个多功能工具箱扩展了代理的能力,使其能够操作结构化数据和非结构化文档。通过参与思考-行动-观察循环,代理持续反思所推导的计划、行动执行结果以及过去的交互,以自主地协调行动工具。 这个过程不仅能够收集回答问题所需的必要信息,还能同时识别出缺失的事实三元组以完善知识图谱,从而解决知识图谱不完整性的挑战。
由于缺乏经过良好标注的专家轨迹,本文中还引入了一个自学习框架,该框架包括在线探索和离线迭代策略更新。通过与知识图谱环境的持续交互,Agent可以在无需人工标注的情况下自我合成和优化轨迹数据,从而提升性能。
2 相关工作
2.1 知识图谱上的复杂推理
在知识图谱上的复杂推理旨在使用知识图谱作为主要信息来源来回答多跳自然语言问题。现有方法可以大致分为语义解析和检索增强。语义解析方法将问题解析为可执行的正式语言(例如,SPARQL),并在知识图谱上执行精确查询以获取答案。早期工作采用逐步生成查询图的策略,并搜索解析。后续工作采用Seq2Seq模型(例如,T5)直接生成SARSQL表达式,这利用了预训练语言模型的能力来增强语义解析过程。最近,ChatKBQA进一步微调大型语言模型(例如,LLaMA)以提高正式语言生成的准确性。尽管取得了这些进展,但语义解析方法严重依赖于生成查询的质量,如果查询不可执行,则无法获得答案。
检索增强方法从知识图谱中检索相关的事实三元组,然后将它们输入到LLM中以帮助生成最终答案。一些方法开发专门接口来从结构化数据中收集相关证据,而另一些方法通过评估问题和相关事实之间的语义相似性来检索事实。与此同时,某些方法利用LLM来分解问题,然后检索相应三元组进行生成,提高了检索过程的精确性。值得注意的是,ToG采用探索-利用策略,允许LLM遍历知识图谱以收集信息,实现了最先进的性能。GoG进一步提出了思考-搜索-生成范式来解决知识图谱的不完整性问题。然而,这些方法大多数依赖于功能强大的闭源LLM API(例如 GPT4),当使用弱 LLM 作为主干时,会导致性能显著下降。
2.2 基于大型语言模型的智能体
在 LLM中展现出的令人惊讶的长期规划和推理能力,研究人员已探索构建基于LLM的智能体系统以开启通用人工智能的大门。最具代表性的LLM智能体ReAct提出了一种提示方法,使LLM能够与外部环境交互并接收反馈。后续研究进一步聚焦于智能体规划、函数调用和代码生成,提升了 LLM在各种复杂任务上的能力。最近,人们越来越关注通过在从教师模型中提炼的专家数据上进行微调来赋予开源LLM智能体能力。然而,AutoAc和AgentGym等方法提出了自交互轨迹合成,在蒸馏方法之上展现出更优越的性能,并显示出巨大的潜力。此外,近期研究强调了将强化学习技术与LLM相结合的重要性,以增强动态场景中的决策能力。 值得注意的是,像这样的研究强调了强化学习框架如何通过精心设计的提示使LLM能够持续调整其策略,从而显著提高它们在实际应用中的性能。
3 预备知识
3.1 符号规则
知识图谱是由事实三元组组成的集合,表示为 ,其中
和
分别代表实体集和关系集。知识图谱中的符号规则通常表示为一阶逻辑公式:
(1)
其中左侧表示规则头,包含可通过()右侧规则体推导出的关系
,规则体形成封闭链,连续关系共享中间变量(例如
),由体关系的合取(
)表示。知识图谱可以被视为通过将所有变量
替换为特定实体来对符号规则进行实例化。例如,给定三元组(Sam, workFor, OpenAI)、(OpenAI locatedIn SF)和(Sam liveIn, SF),长度为2的符号规则的实例化为𝑙𝑖𝑣𝑒𝐼𝑛(𝑆𝑎𝑚, 𝑆𝐹 ) ← 𝑤𝑜𝑟𝑘𝐹𝑜𝑟 (𝑆𝑎𝑚, 𝑂𝑝𝑒𝑛𝐴𝐼 ) ∧ 𝑙𝑜𝑐𝑎𝑡𝑒𝑑𝐼𝑛(𝑂𝑝𝑒𝑛𝐴𝐼, 𝑆𝐹 ).
3.2 任务公式化
在本文中,将KG上的推理任务转化为基于LLM的智能体任务,其中知识图谱作为提供执行反馈的环境,而不仅仅是作为知识库。因此,推理过程可以被视为与知识图谱的部分观察进行多步交互。这种交互过程可以形式化为一个部分可观察马尔可夫决策过程(POMDP):,其中
为问题空间,
为状态空间,
为动作空间,
为观察空间,
为状态转移函数,
。请注意,在我们的语言智能体场景中,
都是自然语言空间的子空间,转移函数
由环境决定。
给定一个问题 和知识图谱
,LLM智能体会根据其策略
生成动作
。这个动作会导致状态转移,智能体接收到作为观察
的执行反馈。然后,智能体继续探索环境,直到找到合适的答案或满足其他停止条件。由一系列动作和观察组成的步骤
处的历史轨迹
可以表示为:
,
, (2)
其中, 是总交互步数。
最后,计算最终奖励,1表示答案正确。
4 SymAgent
SymAgent为一个结合知识图谱(KGs)和 LLMs 来自主解决复杂推理任务的框架,包括:
- Agent-Planner:它从 KG 中提取符号规则来分解问题并规划推理步骤;
- Agent-Executor:它从反思和环境反馈中综合见解来回答问题;
- 自学习框架:为了解决标注推理数据的缺乏问题,引入了一个通过自主交互进行协同改进的自学习框架。
SymAgent整体架构如下图所示:
- (a)SymAgent中的规划器,它从知识图谱(KG)中推导出符号规则来指导推理;
- (b)SymAgent中的执行器,它进行自动动作调用以获取答案;
- (c)用于迭代增强代理的自学习框架;
- (d)合成动作调用轨迹的示例。
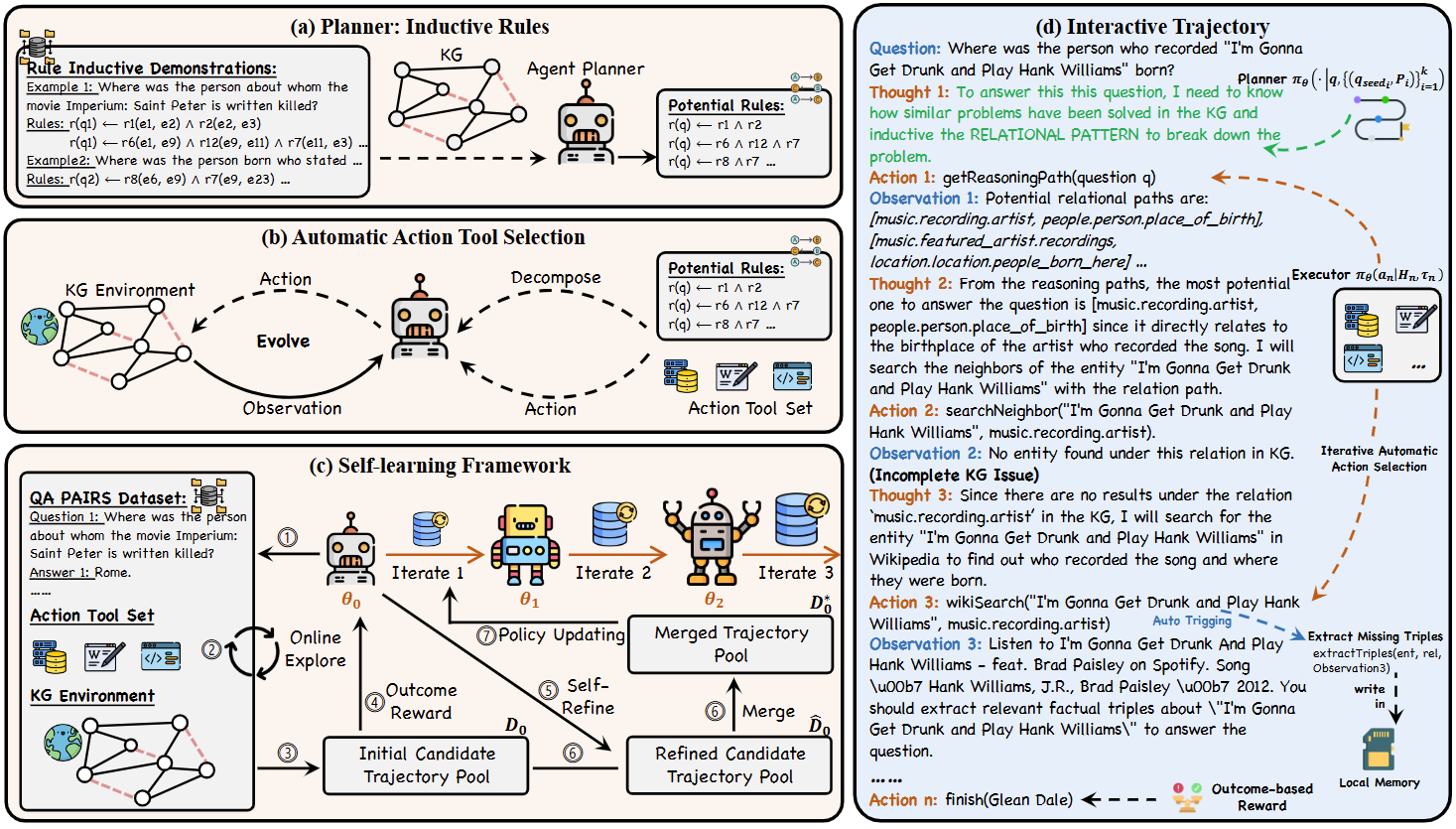
4.1 Agent-Planner
Agent-Planner作为一个高级规划器,利用LLM的推理能力将问题分解为可执行的推理链。然而,仅仅提示LLM规划整个推理工作流程并不能获得令人满意的效果。当前的LLM难以将复杂问题与KG的语义和连接模式相匹配,导致推理链粒度过粗,无法有效地进行精确信息检索和整合。
为解决这一局限性,利用LLM识别KG中可能回答问题的潜在符号规则,而不是生成详细的逐步计划。一方面,LLM已被证明是有效的归纳推理者,但却是糟糕的演绎推理者。另一方面,符号规则本质上反映了知识图谱的推理模式,作为隐含信息帮助分解复杂问题。通过这种方式,Agent-Planner在自然语言问题和知识图谱的结构信息之间建立了桥梁,提高了推理过程的准确性和泛化能力。
具体来说,给定一个问题 ,采用BM25从训练集中检索一组种子问题
,其中每个
与
具有相似的问题结构,可能需要类似的解决方案策略。对于每个
,采用广度优先搜索(BFS)从知识图谱G中的查询实体
到答案实体
采样一组封闭路径
,其中
是一个关系序列。这些封闭路径可以被视为回答问题的符号规则的语义映射。然后,通过用变量替换特定实体来泛化这些封闭路径,将它们转换为公式1中所示的规则体。
该过程构建了少量样本演示 ,以提示我们的 SymAgent 为𝑞生成适当的规则体:
(3)
其中代表用于指导规则体生成的提示。
生成的与知识图谱对齐的符号规则 用于指导SymAgent的全局规划,并防止其在推理过程中陷入盲目的试错。
4.2 Agent-Executor
基于从KG 生成的符号规则,Agent-Executor参与观察、思考和行动的循环范式,以导航自主推理过程。与现有方法从KG中检索信息可能引入大量不相关数据不同,Agent-Executor利用KG结构的专家反馈来动态调整推理过程。这种方法使存储大量信息和符号事实的KG能够与LLM深度参与推理过程,而不仅仅是被视为静态信息库。
4.2.1 行动空间
鉴于LLM无法直接处理知识图谱(KGs)中的结构化数据,并且考虑到在推理过程中需要依赖外部非结构化文档来处理知识图谱中信息不完整的问题,将Agent的行动空间定义为一组功能工具。通过利用LLM的函数调用能力,SymAgent不仅克服了LLM在处理结构化数据方面的局限性,还提供了一种灵活的机制来整合多样化的信息源,从而增强了代理的推理能力和适应性。动作空间由以下功能工具组成:
- getReasoningPath(sub_question):接收子问题作为输入并返回潜在的符号规则。如图 3 所示,此操作利用 LLMs 的归纳推理能力生成与知识图谱(KG)对齐的符号规则,这些规则能有效分解子问题,从而引导推理过程。
- wikiSearch(ent, rel):当知识图谱信息不足时,从维基百科或互联网中检索相关文档。此操作连接结构化的知识图谱数据与非结构化文本,增强在信息不完整情况下的推理能力。
- extraTriples(ent, rel, doc):提取与从检索到的文档中提取当前查询的实体和关系。值得注意的是,该操作并非由代理显式调用,而是在调用𝑤𝑖𝑘𝑖𝑆𝑒𝑎𝑟𝑐ℎ后自动触发。提取出的三元组与知识图谱的语义粒度相匹配,可以集成到知识图谱中,从而促进其扩展。
- searchNeighbor(ent,rel):是一个图探索函数。它返回知识图谱中给定关系下特定实体的邻居,从而实现高效遍历和发现相关实体。
- finish(e_1,e_2,...,e_n):返回一组答案实体,表示最终答案已获得,推理过程已结束。
4.2.2 交互过程
将KG视为环境,将动作执行的结果视为观察结果,整个推理过程就变成了一个由智能体动作调用和相应观察组成的序列。采用一种响应式方法,在采取行动之前生成一个思维链(chain-of-thought,CoT)推理过程,反思当前环境的状况。形式上,扩展了公式2,在第𝑛步的交互轨迹可以进一步表示为:
(4)
其中, 是智能体通过反思历史轨迹产生的内部思考,
是从上述工具集中选择的一个动作,
是由执行一个动作确定的观察结果。基于这个历史轨迹,生成后续思考
和动作
的过程可以表示为:
,
, (5)
其中, 和
分别表示第
个token和
的总长度,
和
分别表示第
个token和
的总长度。Agent循环会持续进行,直到调用𝑓𝑖𝑛𝑖𝑠ℎ()动作或达到预定义的最大迭代步数。
4.3 自学习
鉴于初始数据集仅包含问答对,缺乏完善的逐步交互标注数据,提出一种自我学习框架。与从更强大的模型(例如GPT-4)中提炼推理链不同,我们的方法使弱策略LLM 能够充分与环境交互,并通过自我训练进行改进。自我学习过程包含两个主要阶段:在线探索和离线迭代策略更新。
4.3.1 在线探索
在此阶段,基础Agent 根据4.2.2节通过思维-行动-观察循环自主与环境交互,合成一组初始轨迹
。对于每个轨迹
,采用基于结果的奖励机制,将奖励定义为最终答案的召回值:
, (6)
其中:
是从轨迹
的最终动作中提取的答案实体集合;
是真实答案实体集合。
这个过程产生了一个自我探索的轨迹集合 。
为了解决Agent动作调用中的潜在错误(例如,不正确的工具调用格式)可能损害探索效果的问题,利用LLM的自我反思能力来优化轨迹。使用 作为参考,策略LLM
重新生成新的优化轨迹,表示为
。应用相同的奖励机制后,我们可以得到一个优化的轨迹集合
。
在自我探索和自我反思后,我们获得了两个大小相等的轨迹集: 和
。为了提升候选轨迹的质量,采用启发式方法合并这两个集合,从而得到一个优化的轨迹集。遵循最终答案一致性原则,我们得到了合并后的轨迹集合
:
(7)
在这个方程中, 表示当奖励相等且非零时,选择长度较短的轨迹。
4.3.2 离线迭代策略更新
给定合并的轨迹 ,一种直观的提高Agent性能的方法是使用这些轨迹进行微调。在自回归的方式下,智能体模型的损失可以表示为:
,
(8)
其中是指示函数,用于判断
是否为代理生成的思想或行动中的标记。
更新策略模型参数后,采用迭代优化方法来持续提升代理的性能。更新后的模型在初始数据集上经历反复的自我探索、自我反思和轨迹合并,生成新的轨迹数据以进行进一步微调。此迭代过程持续进行,直到验证集上的性能提升变得微不足道,此时终止迭代。
5 实验设计
5.1 实验设置
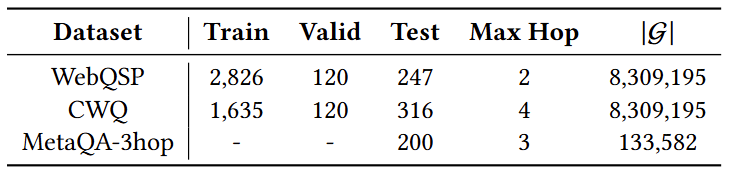
采用三个流行的知识图谱问答数据集进行评估:WebQuestionSP(WebQSP)、复杂网络问题(CWQ)和MetaQA-3hop。WebQSP和CWQ数据集由常识知识图谱Freebase构建,其中包含最多4跳的问题。MetaQA-3hop基于特定领域的电影知识图谱,特别选择这个数据集来评估模型在特定领域场景中的零样本推理性能。这意味着仅在CWQ和WebQSP上训练,然后在MetaQA-3hop上进行情境推理,以评估模型对特定领域的泛化能力。为了进一步模拟不完整的知识图谱,采用广度优先搜索方法从问题实体提取到答案实体的路径,然后根据的设置随机移除一些三元组。在这种情况下,由于形式化表达式不可执行,语义解析方法无法获得正确答案。为了更好地评估模型在复杂推理任务上的性能,从测试集中采样一个需要多跳推理才能解决问题的子集。 结果数据集的统计数据如下表, 表示每个数据集中背景知识图谱中的三元组数量:
5.2 性能比较
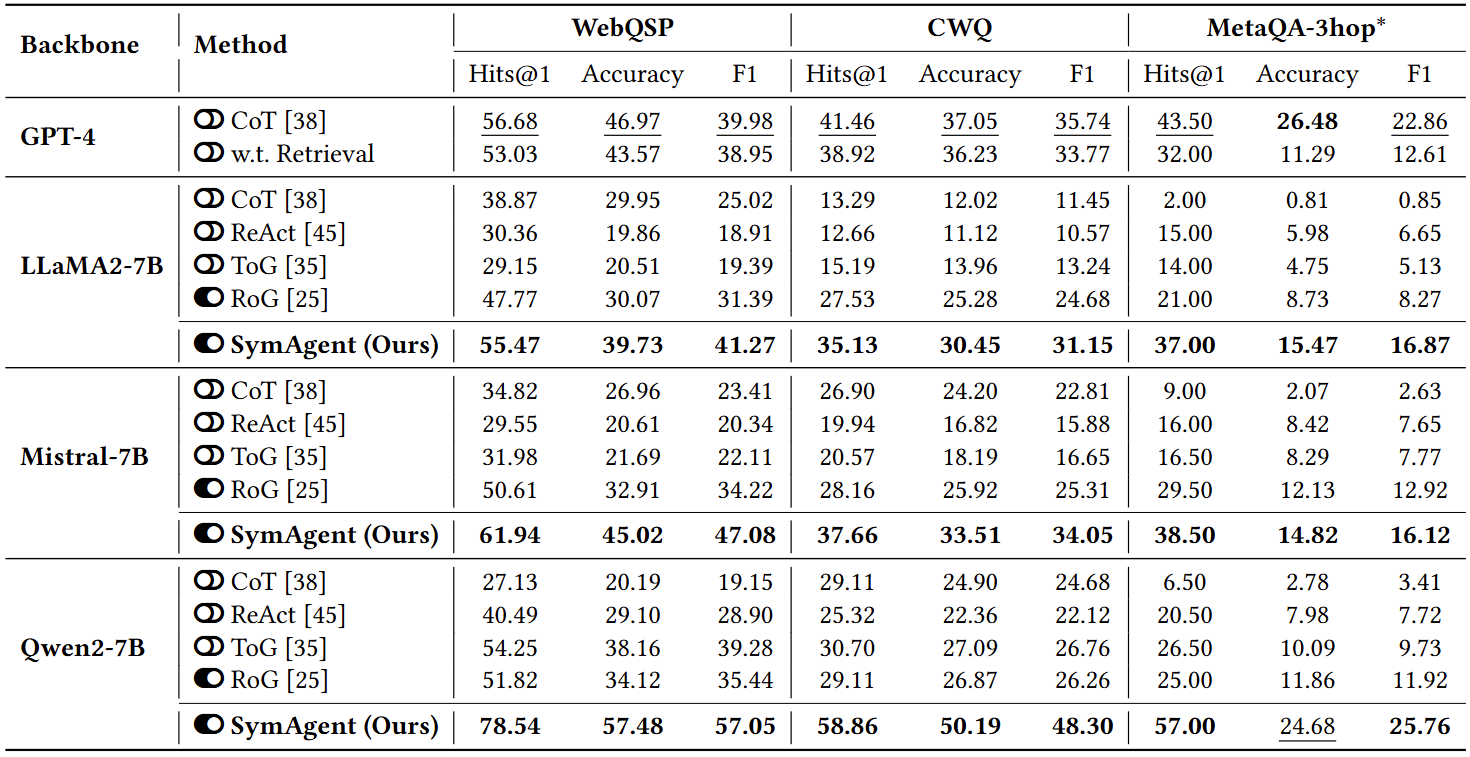
实验结果如上表所示。总体结果表明,SymAgent在所有数据集上都始终表现出优越的性能,验证了SymAgent方法的有效性。首先,与基于提示和微调的方法相比,SymAgent在所有LLM主干网络上都表现出持续的性能提升,这突显了SymAgent的适应性和鲁棒性。特别是,使用Qwen2-7B主干网络的SymAgent取得了最佳性能,在所有三个数据集上都超越了GPT-4,平均提升分别为 Hits@1的37.19%、准确率的16.87%和F1分数的30.17%。这种优越性能可归因于Qwen2在功能调用能力上优于其他两个主干网络,后者经常遇到动作工具调用错误(例如,额外的参数)。这表明我们的方法能够有效利用更先进LLM的优势,从而在复杂推理任务中提升整体性能。
此外,CoT与检索之间的GPT-4性能揭示,对于复杂问题直接进行文档检索会损害性能,尤其是在特定领域的任务中。例如,在MetaQA-3hop中,当使用检索增强时,F1分数下降了10.25(从22.86降至12.61)。潜在的原因是浅层向量检索引入了语义相似但无关的噪声信息。对于较弱的LLM也观察到了类似的趋势。有趣的是,当基础模型具有足够的指令跟随能力(例如,Qwen2-7B)时,ToG的性能优于微调的RoG。原因是探索-利用策略可以利用LLM的固有知识来解决KG的不完整性问题,而RoG则严重依赖路径检索,在这种场景下表现不佳。相比之下,SymAgent能够充分利用KG和LLM的优势,有效地分解问题并取得优异的性能。
最后,通过比较SymAgent在不同数据集上的性能,观察到SymAgent在更具挑战性的CWQ数据集上显示出更大的改进率,这证明了其处理复杂推理的能力。此外,从MetaQA-3hop的结果中可以观察到,缺乏领域知识的LLM表现更差,而SymAgent可以显著提升骨干网络的能力。这种改进在零样本设置中尤为明显,SymAgent相较于基础LLM实现了F1分数的6倍提升,突显了其泛化和在特定领域有效推理的能力。在接下来的消融实验和进一步分析中,除非另有说明,采用Qwen2-7B作为SymAgent的骨干网络,因其性能更优。
5.3 消融实验
在本节中,进行了一系列消融实验,以分析 SymAgent 中每个组件的贡献。
为了验证规划器模块(PM)、执行器模块(EM)和自学习框架(SL),系统地移除这些组件,以创建用于比较的变体。下表中的消融结果表明,所有组件都是必要的,因为它们的缺失会对性能产生不利影响:
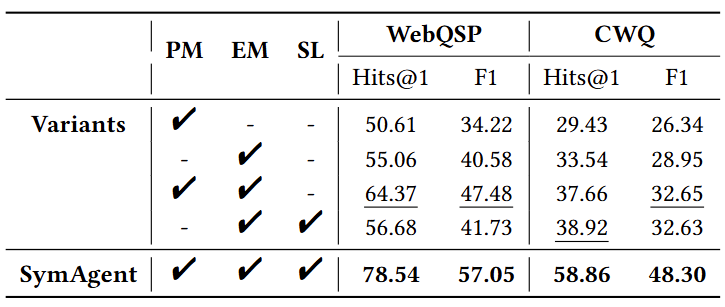
具体而言:
- 认为从KG中推导符号规则至关重要,这可以通过比较SymAgent与EM+SL,以及PM+EM和EM-only;
- 通过比较PM-only和PM+EM,可以发现为模型配备动作工具以访问非结构化文档和结构化知识图谱能够显著提升性能;
- 通过比较EM-only和EM+SL的结果,发现自学习能带来轻微的改进,这可能是由于缺乏规划器模块导致自合成轨迹的质量潜在较低。
总体而言,这些发现表明每个组件在SymAgent处理复杂推理任务时都做出了独特的贡献。
5.4 对自学习框架的分析
5.4.1 迭代次数
下图展示了自学习阶段迭代次数对模型性能影响的对比分析:
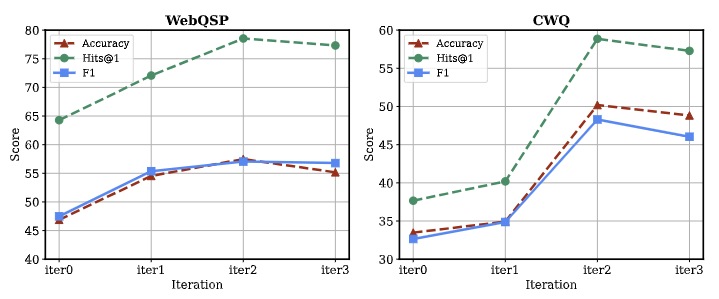
在迭代训练的初始阶段,观察到模型性能的快速提升,这验证了自改进和启发式合并方法在获取大量轨迹数据方面的有效性。
这种迭代方法使模型能够全面探索环境,从而提高其性能。这些发现证实了在拒绝采样下迭代训练的有效性,有助于增强模型对训练数据的理解。然而,随着迭代次数的增加,注意到模型性能出现波动。这种现象可以归因于使用基于结果的奖励机制。在实践中,模型可能在中间步骤出现错误,但最终结果仍然正确。对这些轨迹的持续迭代可能导致模型拟合这些虚假关联。这一观察结果表明,在自学习框架的未来迭代中,需要更精细的评价指标和奖励机制。
5.4.2 自优化与启发式合并的作用
为了进一步探索自学习框架中自优化和启发式合并的作用,设计了两种变体训练方案:
- −𝑠𝑒𝑙𝑓-𝑟𝑒𝑓𝑖𝑛𝑒,该模型仅使用拒绝采样来获取轨迹数据;
- −𝑚𝑒𝑟𝑔𝑒,该模型直接使用精细化的轨迹作为训练集而不进行合并。
如下表所示的实验结果表明,移除任何一个组件都会对模型的性能产生负面影响:
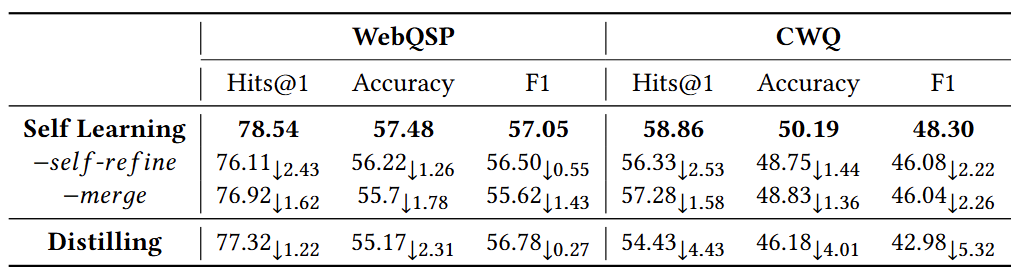
完整的自学习模型在WebQSP和CWQ数据集上的所有指标上均优于其变体。在WebQSP上,移除自精细化会导致Hits@1下降2.43个百分点,而移除合并会导致1.62个百分点的下降。在准确率和F1分数上以及CWQ数据集上也观察到了类似的趋势。这些发现突出了SymAgent框架中自精细化和启发式合并的协同效应。自精细化可能增加了轨迹数量,而合并进一步提升了质量。
5.4.3 蒸馏轨迹与自合成轨迹
SymAgent采用一种传统的数据合成方法,从能够胜任的教师模型(GPT-4)生成轨迹数据,并使用这些数据来微调模型。观察到,虽然蒸馏方法表现出有竞争力的性能,但在所有数据集上始终表现不如自学习框架。性能差距在CWQ数据集上更为明显,Hits@1、Accuracy和F1分数分别下降了 4.43、4.01和5.32个百分点。这是因为来自相似模型的响应比来自更强大模型的响应更容易拟合,导致记忆减少。考虑到极其高昂的成本和繁琐的提示优化,与自学习框架相比,这种训练方法远非可持续。
5.5 提取三元组的质量
凭借全面的行为工具集,SymAgent通过利用结构化和非结构化数据来解决KG的不完整性。WikiSearch行为触发提取动作,从检索到的文本中识别缺失的三元组,有效地通过外部信息对KG进行对齐和丰富。为了验证这种方法,使用 SymAgent 识别的三元组增强KG,并在增强的KG上测试检索增强生成模型RoG。如下图所示,结果表明RoG的性能显著提高,为SymAgent方法识别的三元组质量足以集成到现有的KG中提供了经验证据。
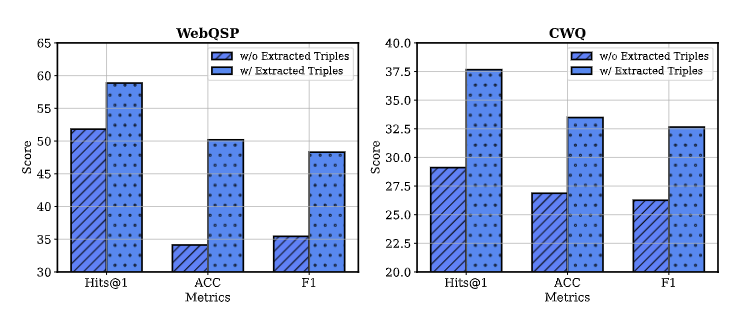
这一发现不仅验证了SymAgent方法,还表明通过SymAgent,LLM和KG之间存在潜在的协同增强可能性。
5.6 错误类型分析
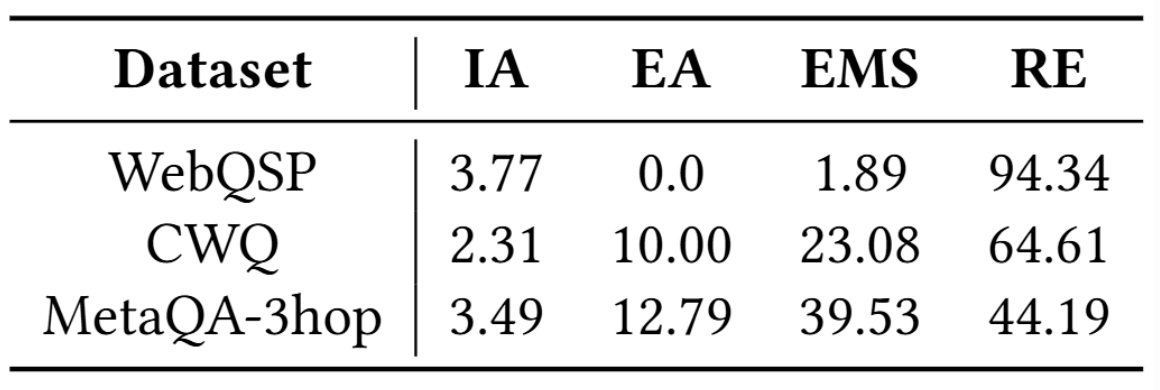
为了更深入地了解模型的性能,通过将失败案例分为四类进行了错误分析:
- 无效动作(IA),即模型调用了动作工具集中未定义的动作;
- 参数错误(EA),即提供的参数不足或过多;
- 超出最大步数(EMS),即推理步骤超过了预定义的最大步数;
- 推理错误(RE),即尽管动作和步骤有效,但最终答案不正确。
下表展示了这些错误类型在WebQSP、CWQ和MetaQA-3hop数据集上的分布情况。WebQSP错误主要是RE(94.34%),而CWQ和MetaQA3hop则显示出更多样化的分布,存在显著的EMS错误,这表明未来有针对性的改进空间。
总结
在本文中,介绍了一个基于神经符号驱动的LLM智能体框架SymAgent,它将LLM与结构化知识相结合,以在知识图谱上进行复杂推理,有效整合了LLM和知识图谱的优势。SymAgent包括利用知识图谱中的符号规则来指导问题分解,自动调用动作工具来解决知识图谱的不完整性问题,并采用一个自学习框架来进行轨迹合成和持续改进。这种多方面的方法不仅增强了代理的规划能力,而且在复杂推理场景中证明是有效的。大量的实验展示了SymAgent的优越性,展示了知识图谱和LLM之间相互促进的潜力。