【PINN】DeepXDE学习训练营(33)——pinn_forward-fractional_Poisson_1d.py
一、引言
随着人工智能技术的飞速发展,深度学习在图像识别、自然语言处理等领域的应用屡见不鲜,但在科学计算、工程模拟以及物理建模方面,传统的数值方法仍然占据主导地位。偏微分方程(Partial Differential Equations, PDEs)作为描述自然界中众多复杂现象的重要数学工具,在物理、化学、工程、金融等领域具有广泛应用。然而,伴随着高维度、多变量、复杂边界条件等挑战,传统数值求解方法面临效率低、适应性差等困境。
近年来,深度学习的崛起为科学计算带来了全新的解决思路。其中,以深度偏微分方程(Deep PDE)为代表的研究方向,通过结合神经网络与偏微分方程的理论,成功开发出高效、灵活的求解方案。这种方法不仅可以克服传统方法的局限,还能应对高维、复杂几何等问题。
作为深度偏微分方程领域的开源工具库,DeepXDE(Deep Learning for Differential Equations)由lululxvi团队精心开发,凭借其强大的功能、易用的接口和丰富的示例,受到学术界与工业界的广泛关注。本文将系统介绍DeepXDE的基本内容与应用价值,深入探讨其核心技术原理,分享环境配置与运行技巧,并结合实际案例进行分析,最后对未来发展趋势进行展望。
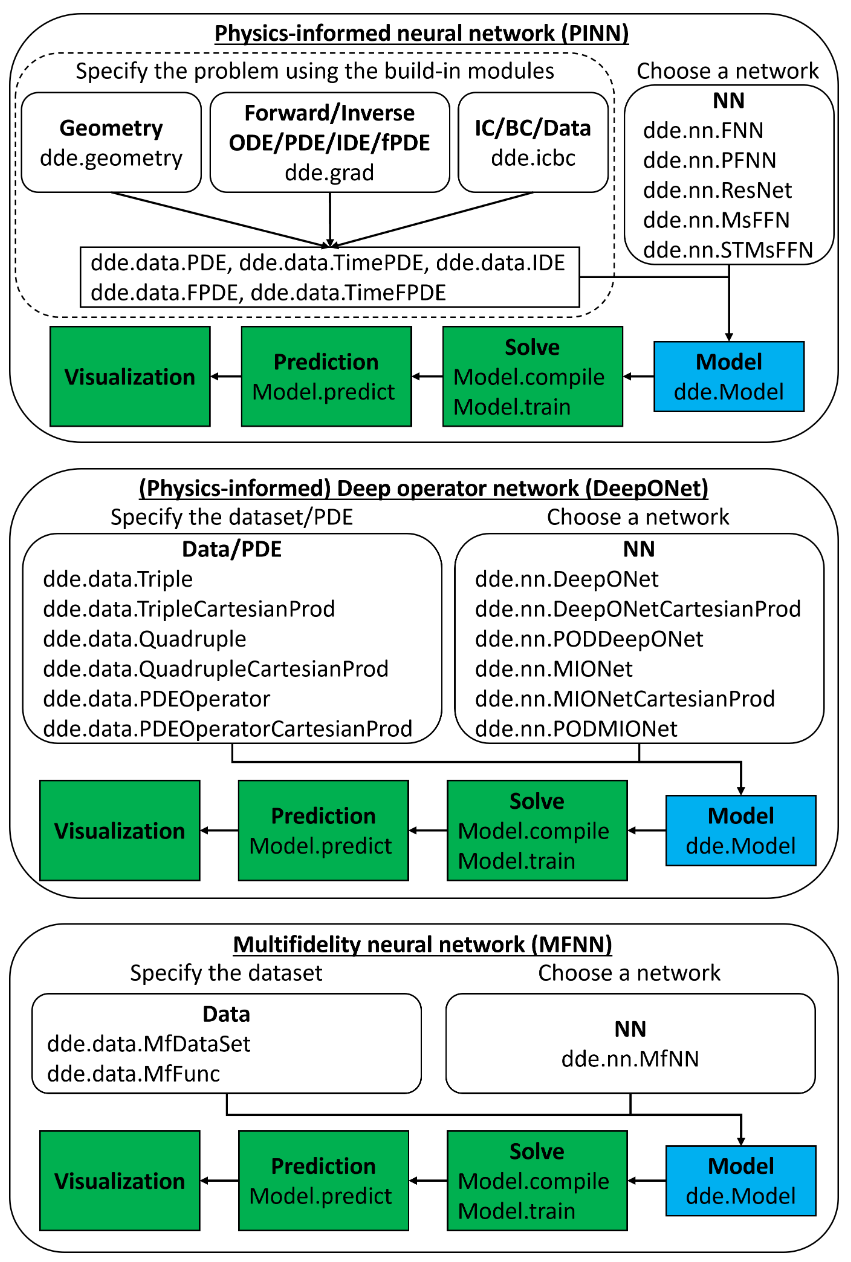
二、DeepXDE的用途
DeepXDE,一个基于TensorFlow和PyTorch的深度学习微分方程求解库,应运而生。它提供了一个简洁、高效且易于使用的框架,使得研究人员和工程师能够利用深度学习技术求解各种类型的微分方程,包括常微分方程(ODEs)、偏微分方程(PDEs)、积分微分方程(IDEs)以及分数阶微分方程(FDEs)。
DeepXDE旨在提供一站式的深度学习框架,用于高效求解各种偏微分方程,包括但不限于:
1. 传统偏微分方程求解
- 定常和非定常问题:热传导方程、波动方程、拉普拉斯方程、扩散方程等。
- 线性和非线性方程:支持线性边界条件,也能处理非线性、非局部问题。
2. 高维偏微分方程
在高维空间中,传统数值方法面临“维数灾难”。DeepXDE利用神经网络天然的高维逼近能力,有效解决高维PDE,如贝尔曼方程、多体问题等。
3. 复杂几何和边界条件
支持任意复杂的几何区域、非均匀边界条件,极大扩展了求解的适用范围。
4.参数逆问题和数据驱动建模
整合数据,使模型在已知部分信息的基础上进行参数识别、反演问题求解。
5. 动态系统和时间演化
支持带有时间变量的演化问题,模拟动态过程。
6. 结合有限元、有限差分等方法
虽然核心为神经网络,但兼容各种数值方法,提供灵活的求解策略。
7. 教育科研与工程实践
丰富的案例与接口帮助科研人员快速验证理论,工程师实现快速设计优化。
总结而言,DeepXDE不仅是一个纯粹的数学工具,更是工程实践中的“聪明助手”,帮助用户以信赖深度学习的方式突破传统技术瓶颈,实现创新性的科学计算。
三、核心技术原理
DeepXDE的核心思想是利用神经网络作为逼近器,通过构造损失函数,使网络能在满足偏微分方程边界条件的前提下逼近真实解。以下详细阐释其原理基础。
1. 神经网络逼近偏微分方程解
假设待求解的偏微分方程可以写成:
配合边界条件
这里,代表微分算子,
代表边界条件算子。
DeepXDE利用深度神经网络 𝑢𝜃(𝑥) 作为解的逼近,参数为 𝜃 。通过自动微分(AutoDiff),网络可以自然求出 𝑢𝜃 的各阶导数,从而在网络定义的每个点上计算微分方程的残差。
2. 损失函数设计
训练模型的目标是最小化残差,使神经网络逼近满足偏微分方程的解。损失函数由两部分组成:
- 方程残差部分:
其中, 为采样点,用于评估微分残差。
- 边界条件部分:
结合整体目标函数:
这里 、
为调节系数。
3. 自动微分(AutoDiff)技术
深度学习框架如TensorFlow或PyTorch提供自动微分功能,方便快速计算神经网络输入的微分,自动应用链式法则求导,极大简化偏微分方程的数值差分表达。
4. 训练优化方法
利用成熟的梯度下降(SGD)、Adam等优化算法,通过反向传播调节神经网络参数,使损失函数达到最小。
5. 样本生成和采样策略
- 采样点生成:采用随机采样、拉丁超立方(Latin Hypercube Sampling)或网格采样来选取训练点。
- 自适应采样:在训练过程中,根据误差分布调整采样点,提高训练效率。
6. 复杂边界与几何的处理
采用非结构化的几何描述和SDF(Signed Distance Function)结合,保证不同几何形状的灵活支持。
7. 逆问题与数据融合
在已知数据集上引入数据损失,使模型不仅满足PDE,也通过端到端训练实现数据匹配,增强实际适用性。
五、代码详解
"""Backend supported: tensorflow.compat.v1, paddle"""
import deepxde as dde
import numpy as np
# 导入 deepxde 以及 numpy
# 根据使用的后端不同,下面导入对应的深度学习框架
from deepxde.backend import tf # 使用 tensorflow.compat.v1 作为后端
# 如果使用 paddle 后端,可以取消下面的注释:
# import paddlefrom scipy.special import gamma # 导入 gamma 函数,用于伽马函数计算# 设置分数阶微积分的阶数
alpha = 1.5# 定义分数偏微分算子(FPDE)方程
def fpde(x, y, int_mat):"""方程:(D_{0+}^α + D_{1-}^α) u(x) = f(x)这里实现了左分数阶导数和右分数阶导数的和,作用于未知函数 y。参数:x - 位置变量,tensory - 目标函数在 x 处的预测值,tensorint_mat - 表示积分算子的矩阵或稀疏矩阵"""# 判断 int_mat 是否为稀疏矩阵,需要特殊处理if isinstance(int_mat, (list, tuple)) and len(int_mat) == 3:# 如果是稀疏矩阵的表示(indices, values, shape)int_mat = tf.SparseTensor(*int_mat)lhs = tf.sparse_tensor_dense_matmul(int_mat, y) # 稀疏矩阵乘以向量else:# 非稀疏,直接矩阵乘法lhs = tf.matmul(int_mat, y)# 右侧的已知函数项 f(x),由解析表达式给出rhs = (gamma(4) / gamma(4 - alpha) * (x ** (3 - alpha) + (1 - x) ** (3 - alpha))- 3 * gamma(5) / gamma(5 - alpha) * (x ** (4 - alpha) + (1 - x) ** (4 - alpha))+ 3 * gamma(6) / gamma(6 - alpha) * (x ** (5 - alpha) + (1 - x) ** (5 - alpha))- gamma(7) / gamma(7 - alpha) * (x ** (6 - alpha) + (1 - x) ** (6 - alpha)))# 返回残差(待优化的目标)# 注意这里做了切片,确保lhs和rhs形状一致return lhs - rhs[: tf.size(lhs)]# Paddle框架的实现(注释掉,如果使用paddle则取消注释)
# def fpde(x, y, int_mat):
# """(D_{0+}^α + D_{1-}^α) u(x) = f(x)"""
# if isinstance(int_mat, (list, tuple)) and len(int_mat) == 3:
# indices, values, shape = int_mat
# int_mat = paddle.sparse.sparse_coo_tensor(
# [[p[0] for p in indices], [p[1] for p in indices]],
# values,
# shape,
# stop_gradient=False
# )
# lhs = paddle.sparse.matmul(int_mat, y)
# else:
# int_mat = paddle.to_tensor(int_mat, dde.config.real(paddle), stop_gradient=False)
# lhs = paddle.mm(int_mat, y)
# rhs = (
# gamma(4) / gamma(4 - alpha) * (x ** (3 - alpha) + (1 - x) ** (3 - alpha))
# - 3 * gamma(5) / gamma(5 - alpha) * (x ** (4 - alpha) + (1 - x) ** (4 - alpha))
# + 3 * gamma(6) / gamma(6 - alpha) * (x ** (5 - alpha) + (1 - x) ** (5 - alpha))
# - gamma(7) / gamma(7 - alpha) * (x ** (6 - alpha) + (1 - x) ** (6 - alpha))
# )
# return lhs - rhs[: paddle.numel(lhs)]# 定义问题中的已知表达的函数
def func(x):# 定义解或边界条件,比如:x^3 * (1 - x)^3return x ** 3 * (1 - x) ** 3# 1. 构造几何域,区间[0,1]
geom = dde.geometry.Interval(0, 1)# 2. 设置边界条件,采用Dirichlet边界条件
bc = dde.icbc.DirichletBC(geom, func, lambda _, on_boundary: on_boundary)
# 这里边界条件是:在边界上 u(0) = func(0), u(1) = func(1)# 3. 生成静态辅助点数据(空间点,用于离散化)
# 使用静态(固定)节点进行训练
data = dde.data.FPDE(geom, fpde, alpha, bc, [101], meshtype="static", solution=func)
# 参数说明:
# - 101个节点
# - meshtype="static" :静态网格
# - solution=func :已知的解析解,用于验证或辅助训练# 如需动态采样,可以启用下面代码(目前注释掉)
# data = dde.data.FPDE(
# geom, fpde, alpha, bc, [100], meshtype="dynamic", num_domain=20, num_boundary=2, solution=func, num_test=100
# )# 4. 构建神经网络
net = dde.nn.FNN([1] + [20] * 4 + [1], "tanh", "Glorot normal")
# 输入层:1个节点(x)
# 四个隐藏层:每个20个节点,激活函数tanh
# 输出层:1个节点(u的预测值)# 输出变换层(可选):调整输出形状
net.apply_output_transform(lambda x, y: x * (1 - x) * y)
# 这个变换确保预测值在边界满足一定条件(如在0和1处为0)# 5. 创建模型,将数据和网络组合
model = dde.Model(data, net)# 6. 编译模型,使用优化器和学习率
model.compile("adam", lr=1e-3)# 7. 训练模型,指定迭代次数
losshistory, train_state = model.train(iterations=10000)# 8. 保存和绘制训练结果
dde.saveplot(losshistory, train_state, issave=True, isplot=True)
- 定义分数阶微分的方程(fpde)及其对应的主动函数
- 构建几何域和边界条件
- 生成训练所需的数据点(静态或动态)
- 构建神经网络模型
- 编译、训练模型
- 最后展示训练过程和结果
六、总结与思考
DeepXDE作为深度偏微分方程求解的先进工具,展现出强大的学术研究与工程应用潜力。其基于自动微分的深度学习框架,使得复杂偏微分方程在高维、多几何场景下的求解变得更为高效、灵活。相比传统数值方法,DeepXDE具有架构简单、扩展性强、支持数据融合等优点,极大地拓展了偏微分方程的应用边界。
然而,深度学习方法仍面临一些挑战,比如训练的不稳定性、超参数调优的复杂性、理论基础的逐步完善等。未来,随着硬件性能的提升、算法的不断创新,DeepXDE有望在更高维度、更复杂的物理场景中表现出更强的竞争力。
在科学研究中,DeepXDE不仅是验证创新理论的实验平台,更是推动工程实践创新的桥梁。从基础数学模型到端到端的数据驱动建模,深度偏微分方程代表了科学计算的未来方向。我们应积极探索其潜力,推动其在实际问题中的落地,为解决复杂系统的大规模仿真提供更强的工具。
【作者声明】
本文为个人原创内容,基于对DeepXDE开源项目的学习与实践整理而成。如涉及引用他人作品,均注明出处。转载请注明出处,感谢关注。
【关注我们】
如果您对神经网络、群智能算法及人工智能技术感兴趣,请关注【灵犀拾荒者】,获取更多前沿技术文章、实战案例及技术分享!