【Elasticsearch入门到落地】13、DSL查询详解:分类、语法与实战场景
接上篇《12、索引库删除判断以及文档增删改查》
上一篇我们讲解了如何判断索引库是否存在并删除它,以及如何对索引库中的文档进行增删改查操作。本篇我们进入ElasticSearch的DSL语法的详解。
Elasticsearch(ES)作为强大的分布式搜索引擎,其核心功能之一是通过DSL(Domain Specific Language)实现灵活的数据查询。本文将深入解析ES DSL查询的三大核心分类:全文检索查询、精确查询和地理查询,结合实际场景和语法示例,帮助开发者快速掌握ES查询精髓。
一、DSL查询基础结构
ES查询的基本结构遵循JSON格式,主要包含以下两部分:
GET /indexName/_search
{"query": {// 查询条件定义"查询类型":{"查询条件":"条件值"}},"from": 0, // 分页起始位置"size": 10, // 每页返回数量"sort": [ // 排序规则{"price": "asc"}]
}二、全文检索查询
1. 使用场景
●博客文章内容搜索
●电商商品描述匹配
●日志分析中的文本挖掘
●任何需要基于文本相似度匹配的场景
2. 核心查询类型
(1)match查询(最常用)
GET /indexName/_search
{"query": {"match": {"title": {"query": "Elasticsearch教程","operator": "and", // 可选:and/or"minimum_should_match": "75%", // 最小匹配度"fuzziness": "AUTO" // 模糊匹配}}}
}关键参数:
●operator:控制多个查询词的逻辑关系(默认OR)
●minimum_should_match:设置最低匹配词比例
●fuzziness:允许的拼写错误容忍度(AUTO/0/1/2)
案例测试1:
# 模糊搜索
GET /hotel/_search
{"query": {"match": {"all": "外滩如家"}}
}案例结果1:
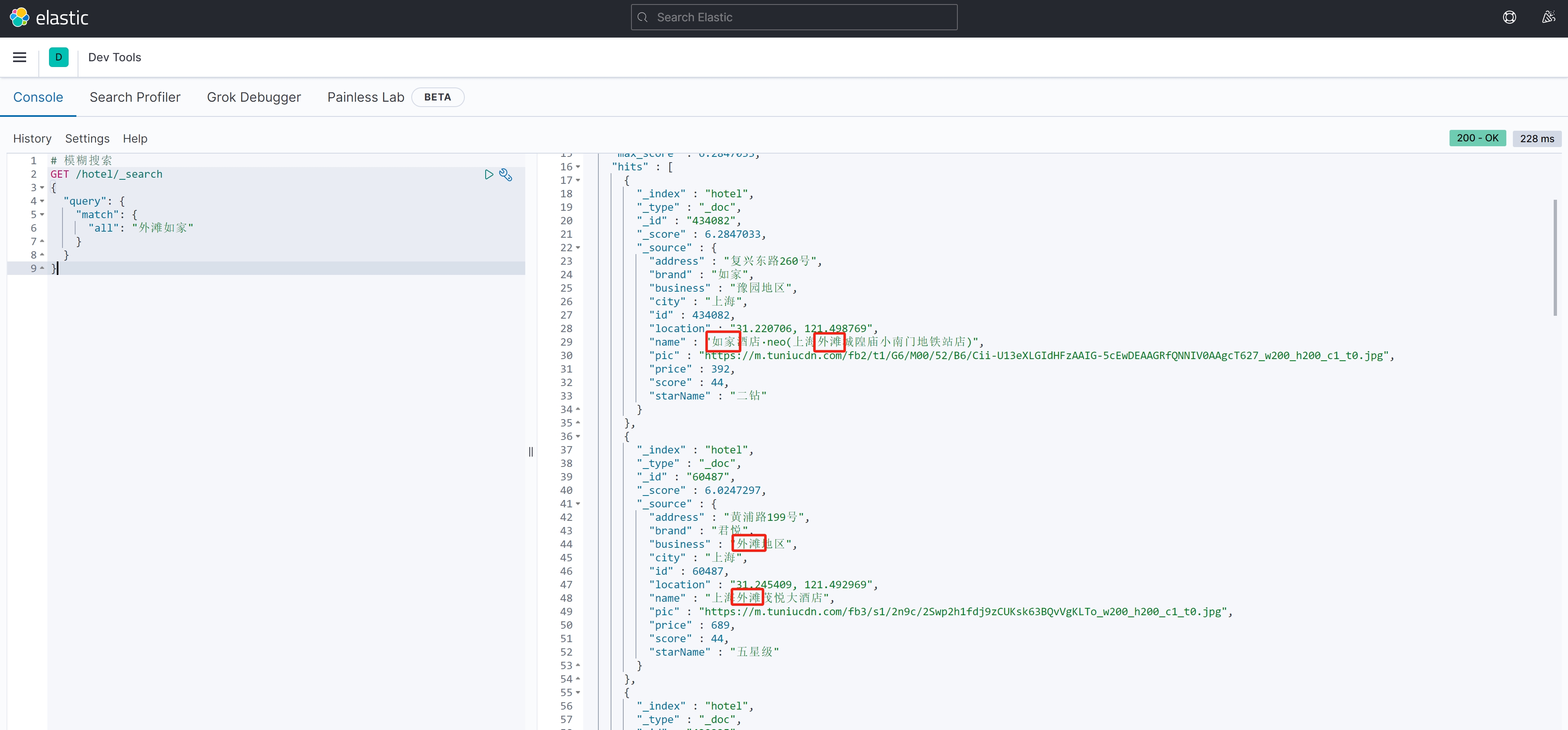
案例测试2:
# 模糊搜索
GET /hotel/_search
{"query": {"match": {"name": {"query": "7天酒店","operator": "and", "minimum_should_match": "75%","fuzziness": "AUTO"}}}
}案例结果2:
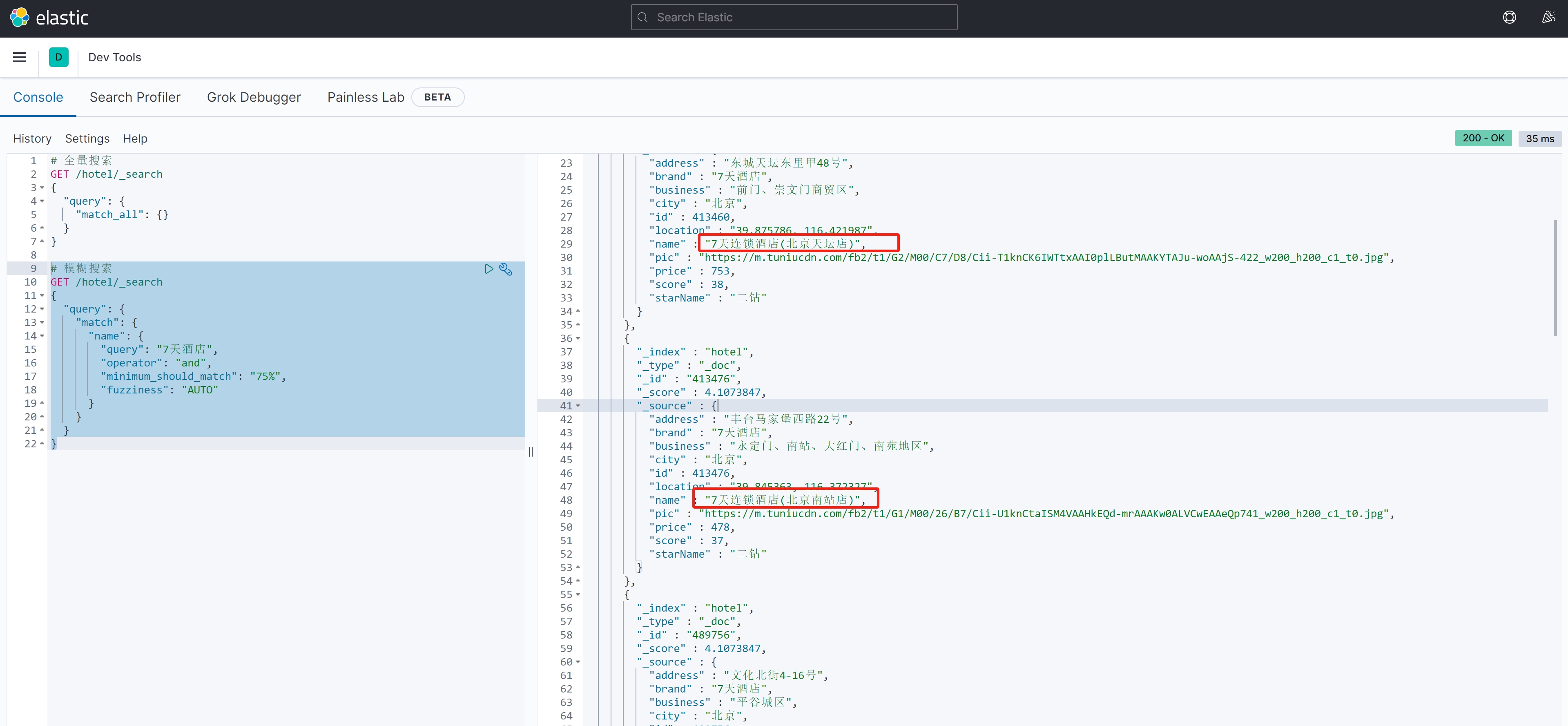
(2)multi_match查询(多字段匹配)
GET /indexName/_search
{"query": {"multi_match": {"query": "大数据分析","fields": ["title^3", "content", "tags"], // ^3表示权重"type": "best_fields" // 匹配策略}}
}匹配策略:
●best_fields:最佳字段匹配(默认)
●most_fields:多数字段匹配
●cross_fields:跨字段匹配
●phrase:短语匹配
●phrase_prefix:短语前缀匹配
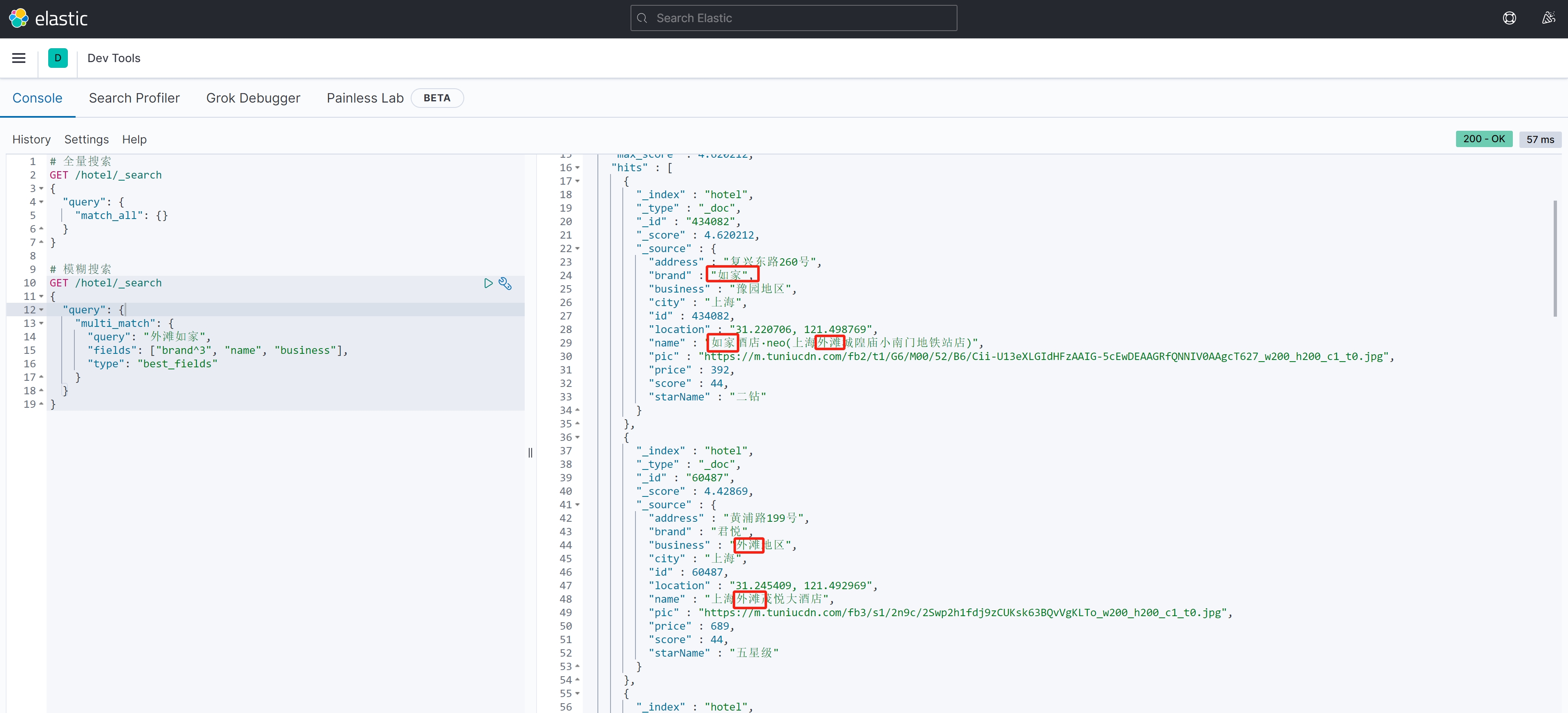
案例测试:
GET /hotel/_search
{"query": {"multi_match": {"query": "外滩如家","fields": ["brand^3", "name", "business"], "type": "best_fields" }}
}案例结果:
(3)match_phrase查询(短语匹配)
GET /indexName/_search
{"query": {"match_phrase": {"content": "快速排序算法","slop": 1 // 允许词间最大距离}}
}match_phrase查询用于精确匹配短语,同时允许指定词间最大距离(通过 slop 参数)
slop表示允许的词序调整次数(例如将"上海 浦东 东站"调整为"上海浦东 东站"需要1次调整)
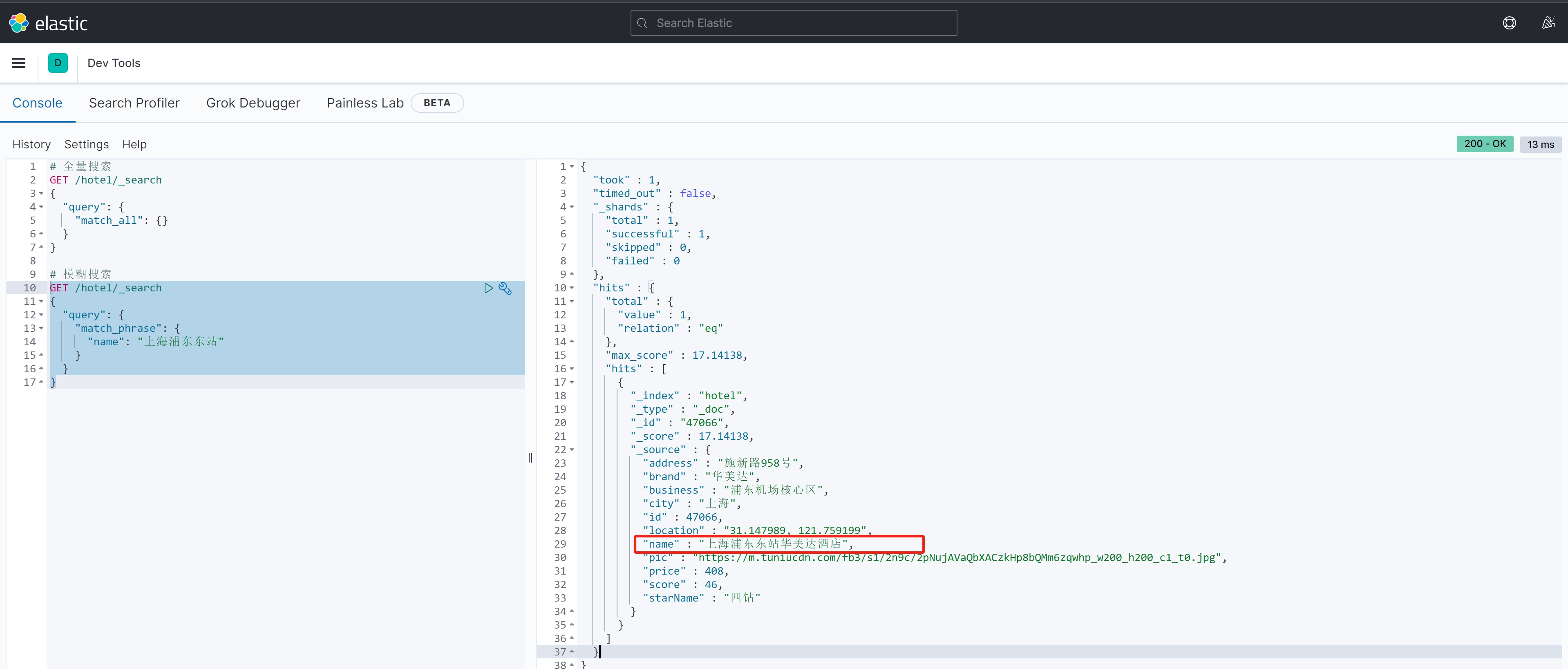
案例测试:
GET /hotel/_search
{"query": {"match_phrase": {"name": "上海浦东东站"}}
}案例结果:
(4)query_string查询(复杂查询)
GET /indexName/_search
{"query": {"query_string": {"query": "(Java OR Python) AND 开发","default_field": "content","fields": ["title^2", "content"]}}
}特点:
支持Lucene查询语法
可指定多个字段及权重
适合复杂查询需求
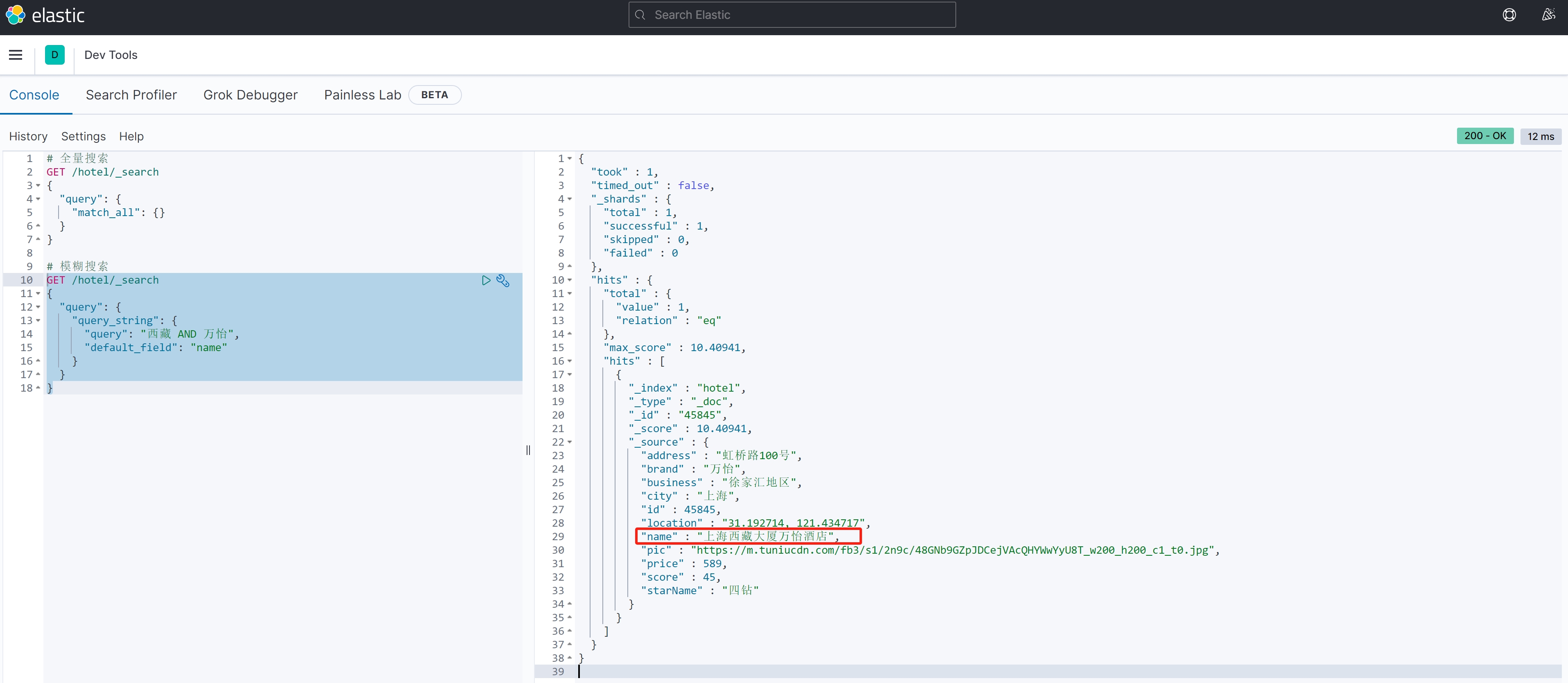
案例测试1:
GET /hotel/_search
{"query": {"query_string": {"query": "西藏 AND 万怡","default_field": "name"}}
}案例结果1:
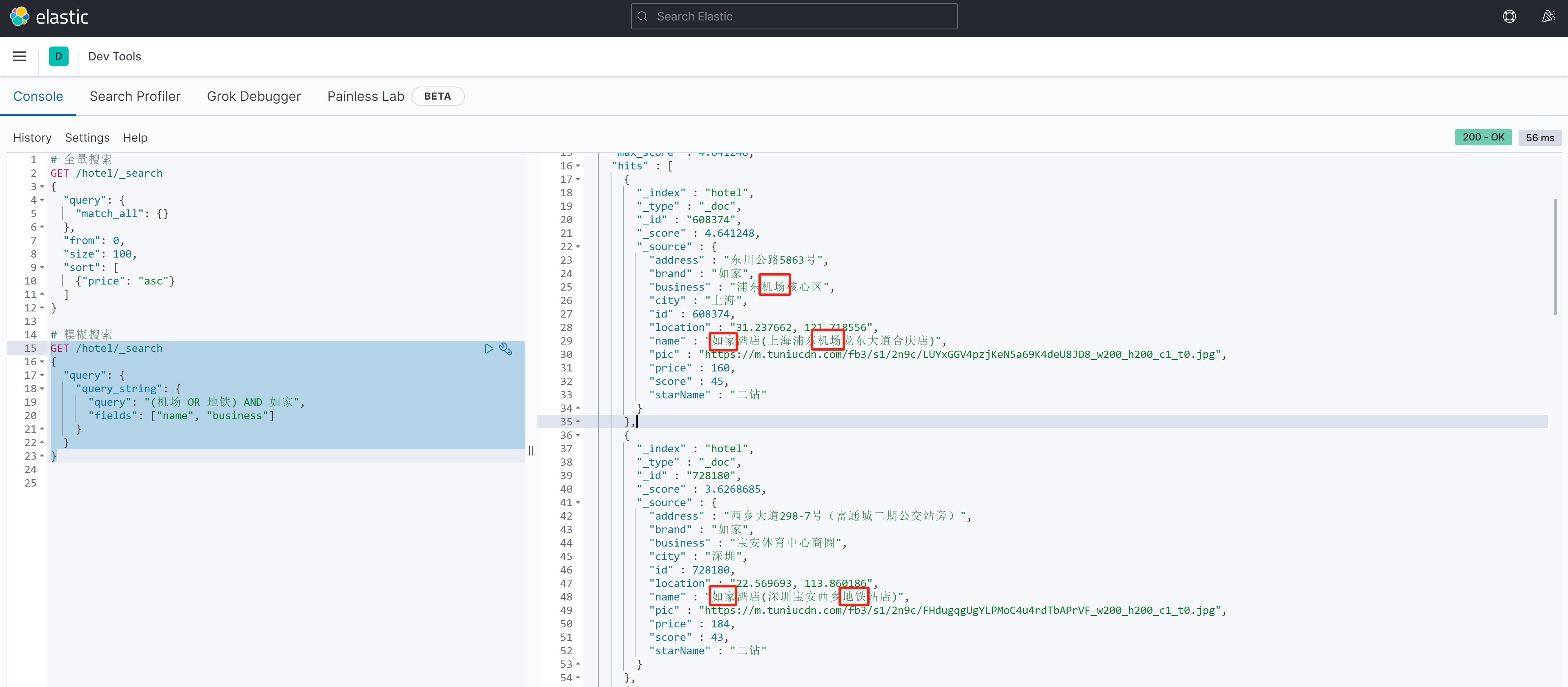
案例测试2:
GET /hotel/_search
{"query": {"query_string": {"query": "(机场 OR 地铁) AND 如家","fields": ["name", "business"]}}
}案例结果2:
注意:query_string查询默认会对文本进行分词处理,如果name字段被映射为keyword类型而不是text类型,查询可能不会按预期工作。例如"商业区"可能被分词为"商"、"业"和"区"三个词,查询要求同时包含这三个词,但很多"商业区"酒店标识可能被分词为单个词,搜索时可以将"商业区"用引号括起来表示短语匹配:
"query": "(地铁 OR \"商业区\") AND 7天"
三、精确查询(Term-level Queries)
1. 使用场景
●用户ID精确查找
●订单状态筛选
●价格范围查询
●日期区间查询
●需要精确匹配而非文本分析的场景
2. 核心查询类型
(1)term查询(精确匹配)
GET /indexName/_search
{"query": {"term": {"status": "active" // 不进行分词,直接匹配}}
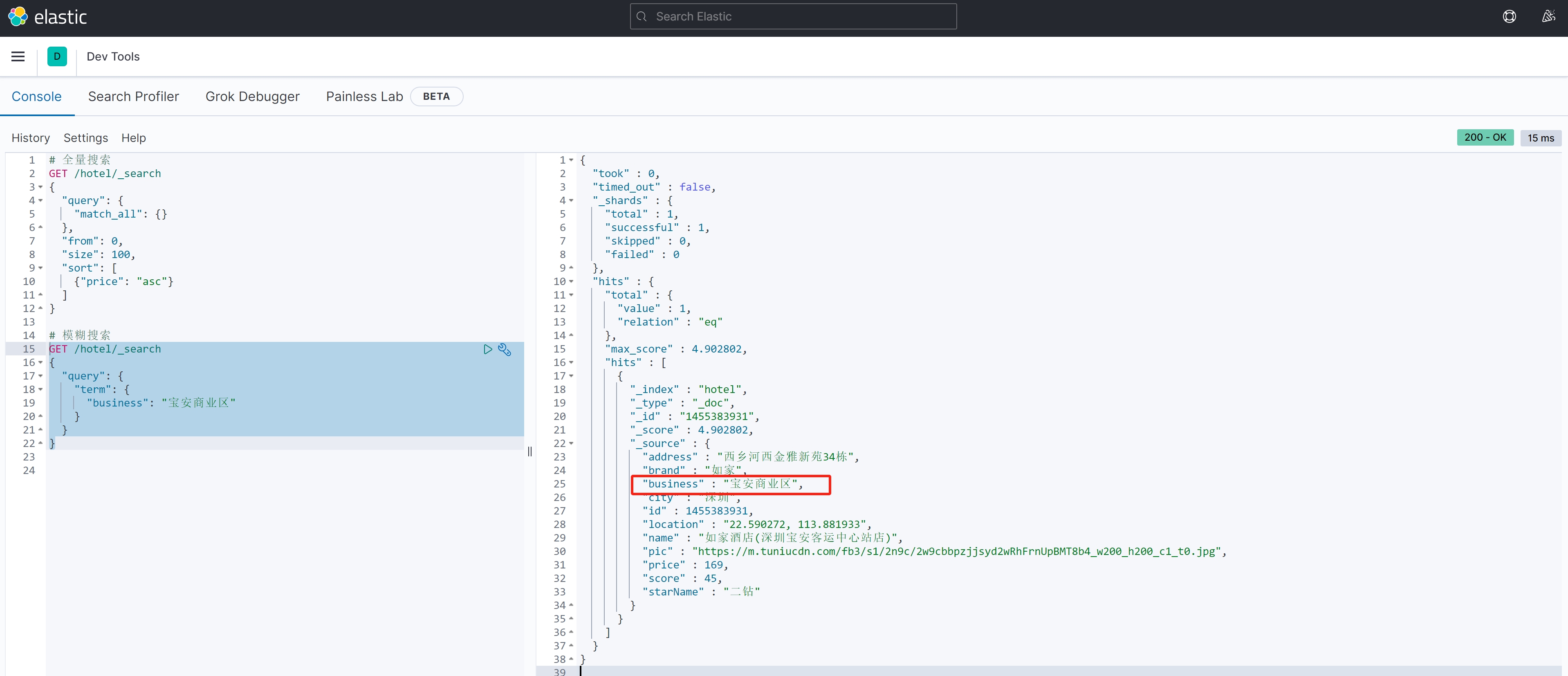
}案例测试:
GET /hotel/_search
{"query": {"term": {"business": "宝安商业区" }}
}案例结果:
(2)terms查询(多值精确匹配)
GET /indexName/_search
{"query": {"terms": {"tags": ["java", "elasticsearch", "分布式"]}}
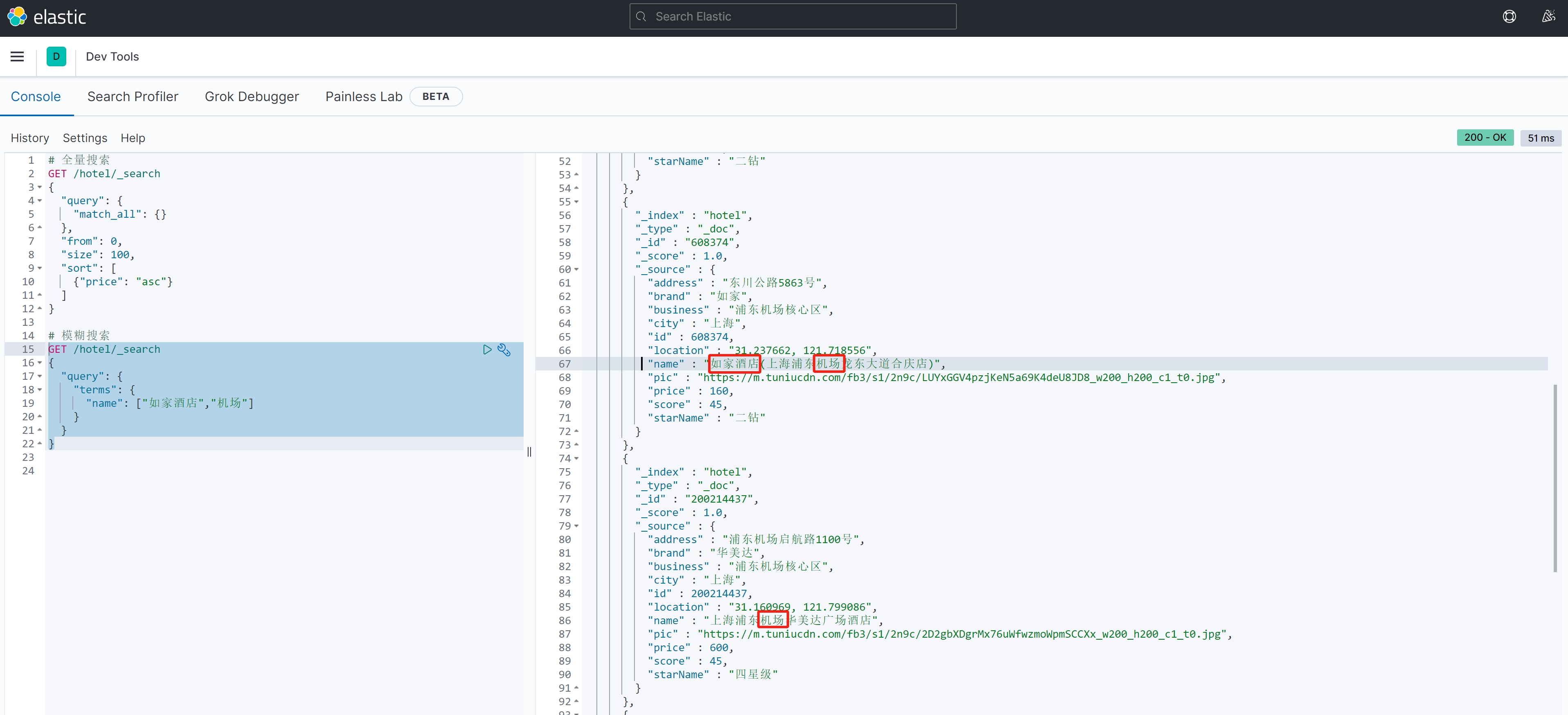
}案例测试:
GET /hotel/_search
{"query": {"terms": {"name": ["如家酒店","机场"] }}
}案例结果:
(3)range查询(范围查询)
GET /indexName/_search
{"query": {"range": {"price": {"gte": 100,"lte": 500,"boost": 2.0 // 权重}}}
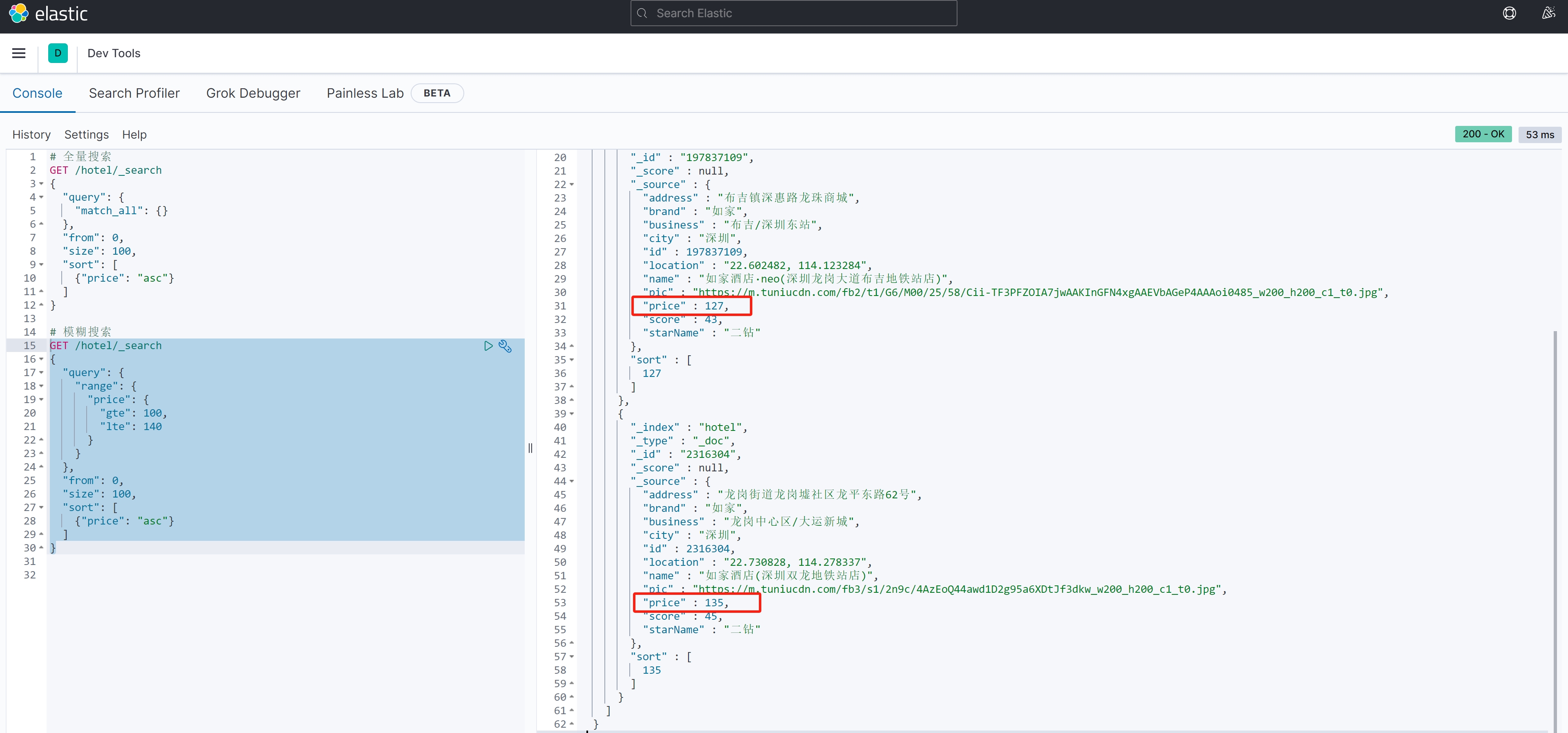
}案例测试:
GET /hotel/_search
{"query": {"range": {"price": {"gte": 100,"lte": 140}}},"from": 0, "size": 100, "sort": [ {"price": "asc"}]
}注:这里加了分页和排序,按照价格从低到高
案例结果:
(4)exists查询(字段存在性检查)
GET /indexName/_search
{"query": {"exists": {"field": "description"}}
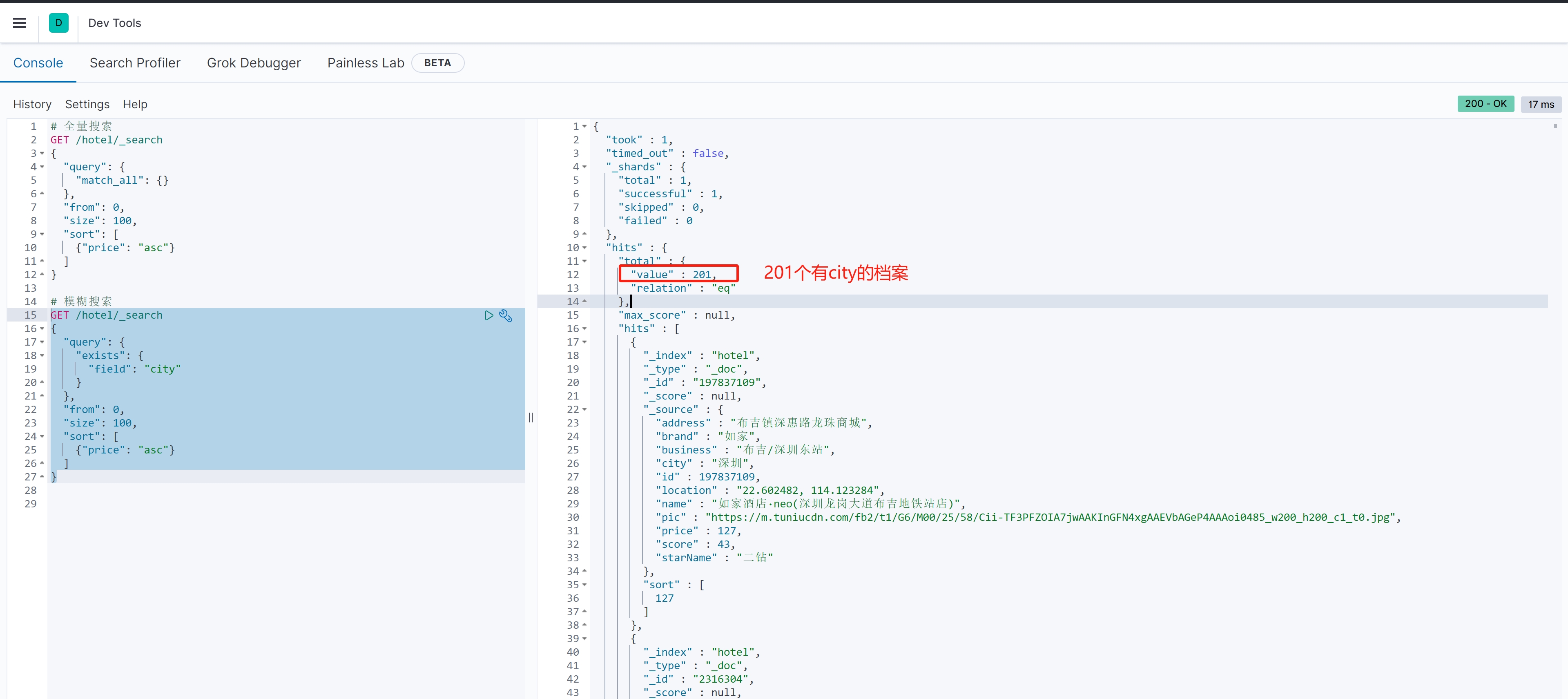
}案例测试:
GET /hotel/_search
{"query": {"exists": {"field": "city"}},"from": 0, "size": 100, "sort": [ {"price": "asc"}]
}案例结果:
(5)bool组合查询(逻辑组合)
GET /indexName/_search
{"query": {"bool": {"must": [{"term": {"status": "active"}},{"range": {"price": {"gte": 100}}}],"filter": [ // filter过滤,但不参与评分{"term": {"category": "electronics"}}],"should": [ // 可选条件{"term": {"is_recommended": true}}],"minimum_should_match": 1}}
}注:minimum_should_match只影响bool查询中的should部分,minimum_should_match参数用于控制should子句中的匹配条件,它指定了在should子句中至少需要匹配多少个条件才能使整个bool查询匹配。
案例测试:
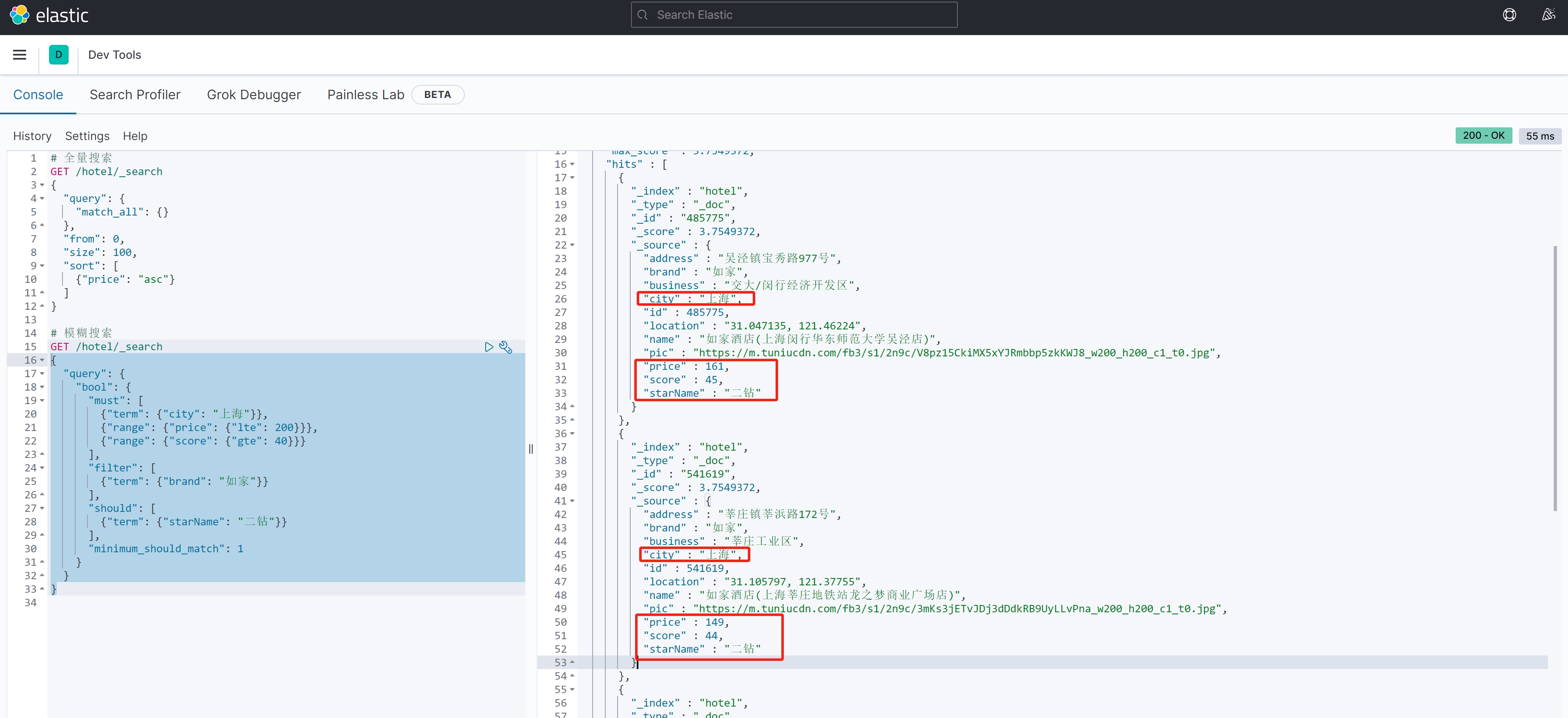
寻找在上海,打分超过40分以上,价格不超过200元,且是如家的酒店,可选条件是二钻:
{"query": {"bool": {"must": [{"term": {"city": "上海"}},{"range": {"price": {"lte": 200}}},{"range": {"score": {"gte": 40}}}],"filter": [ {"term": {"brand": "如家"}}],"should": [ {"term": {"starName": "二钻"}}],"minimum_should_match": 1}}
}案例结果:
四、地理查询(Geo Queries)
此场景不再举例子,大家按照需要查询关键坐标匹配即可。
1. 使用场景
●附近商家搜索
●物流配送范围查询
●基于地理位置的推荐系统
●轨迹分析
2. 核心查询类型
(1)geo_distance查询(距离查询)
GET /indexName/_search
{"query": {"bool": {"filter": {"geo_distance": {"distance": "10km","location": { // 中心点坐标"lat": 39.57,"lon": 106.55}}}}}
}(2)geo_bounding_box查询(矩形区域查询)
GET /indexName/_search
{"query": {"bool": {"filter": {"geo_bounding_box": {"location": {"top_left": {"lat": 30.0,"lon": 106.0},"bottom_right": {"lat": 29.0,"lon": 107.0}}}}}}
}(3)geo_polygon查询(多边形区域查询)
GET /indexName/_search
{"query": {"bool": {"filter": {"geo_polygon": {"location": {"points": [{"lat": 30.0, "lon": 106.0},{"lat": 30.0, "lon": 107.0},{"lat": 29.0, "lon": 107.0},{"lat": 29.0, "lon": 106.0}]}}}}}
}(4)geo_shape查询(复杂形状查询)
GET /indexName/_search
{"query": {"bool": {"filter": {"geo_shape": {"location": {"shape": {"type": "envelope", // 矩形"coordinates": [[106.0, 30.0], [107.0, 29.0]]},"relation": "intersects" // 空间关系}}}}}
}五、性能优化建议
1、全文检索优化:
●合理设置分词器
●使用minimum_should_match控制匹配精度
●避免在高频字段上使用match_all
2、精确查询优化:
●为常用精确查询字段设置keyword类型
●使用filter上下文提高缓存效率
●避免在bool查询中嵌套过多条件
3、地理查询优化:
●使用geo_point类型存储地理位置
●对地理查询使用filter上下文
●合理设置distance_type(arc/plane)
下一篇我们继续讲解DSL查询语法中“相关性算分”、“FunctionScoreQuery”和“BooleanQuery”的相关内容。
转载请注明出处:https://blog.csdn.net/acmman/article/details/148195366